
[자주 등장하는 속성]
axis=0 행(기본 값)
axis=1 열
inplace=False(기본 값) #실제 반영되지 않음
inplace=True #변경사항 실제 반영 함
🚘 열 이름 변경
rename()
#sample 특정 열 이름 변경 #columns 명시해야 함
data.rename(columns={'DistanceFromHome' : 'Distance',
'EmployeeNumber' : 'EmpNo',
'JobSatisfaction' : 'JobSat',
'MonthlyIncome' : 'M_Income',
'PercentSalaryHike' : 'PctSalHike',
'TotalWorkingYears' : 'TotWY'}, inplace=True)
# 모든 열 이름 변경
data.columns = ['Age','Dist','EmpNo','Gen','JobSat','Marital','M_Income', 'OT', 'PctSalHike', 'TotWY']🚘 열 삭제
drop
삭제는 리스크가 큼으로 반드시 datafame copy()후 사용한다.
# 열 전체 삭제
dataframe.drop('컬럼명', axis=1, inplace=True)
# 여러 개의 열 삭제
dataframe.drop(['컬럼1','컬럼2'],axis=1, inplace=True)
#5,6 인덱스 행 삭제
dataframe.drop([5,6], axis=0, inplace=True)주의
inplace=True를 지정했는데 반환하는 값을 받으면 안된다!
dataframe = dataframe.drop('컬럼명', axis=1, inplace=True) # 이렇게 하지 말기🚘 데이터 값 변경
1) 열 전체 값 변경
# ex) 0으로 초기화하는 경우
dataframe['컬럼명'] = 02) dataframe.loc: 조건에 의한 값 변경
# ex) 10살 미만은 Age컬럼의 값을 0으로 변경
data.loc[data['Age'] < 10, 'Age' ] = 0
3) np.where: 조건에 의한 값 변경
# ex) Age컬럼이 10살 미만이면 0 아니면 1
data['Age'] = np.where(data['Age']<10, 0, 1)4) dataframe['컬럼'].replace()
data['Gender'].replace({'male':1, 'female':0}, replace=True)
df['Churn'].replace(['male', 'female'], [1, 0], inplace=True)5) map()
- 주로 범주형 변수를 다른 값으로 변경
- map안에는 딕셔너리 사용
# ex) male이면 1, female이면 0으로 벼경
data['Gender'] = data['Gender'].map({'male':1, 'female':0})6) cut() 메소드
- 주로 숫자형 변수를 범주형으로 변경 시 사용
💡 전체 범위 균등 분할하기
age_group = pd.cut(data['Age'],3)
age_group.value_counts()
# --- ex결과 ---
(32.0, 46.0] 590
(17.958, 32.0] 413
(46.0, 60.0] 193
Name: Age, dtype: int64
# 할당된 범주에 이름 붙이기
age_group2=pd.cut(data['Age'],3, labels=['a','b','c'])
#--- ex결과---
b 590
a 413
c 193
Name: Age, dtype: int64💡 내가 원하는 구간에서 자르기, bins=[]
💡bins 요소 갯수와 범위 알아두기
# 'young' : 0 ~ 40
# 'junior' : 40 < =< 50
# 'senior' : 50 <
data['Age'] = pd.cut(data['Age'], bins=[0,40,50,100], labels=['young','junior','senior'])
# --- 결과 ---
young 820
junior 262
senior 114
Name: Age, dtype: int64기타 다른 속성들도 많다.
pandas.cut(x, bins, right=True, labels=None, retbins=False, precision=3, include_lowest=False, duplicates='raise', ordered=True)
자세한 내용은 공식문서 참고
https://pandas.pydata.org/docs/reference/api/pandas.cut.html.
concat: 데이터프레임 구조에 맞게 합친다. 인덱스, 열이름 기준
merge: 데이터 값 기준으로 합친디. 특정 열의 값 기준
🚘 pd.concat(): 데이터프레임 결합
매핑 기준: 인덱스(행), 컬럼이름(열)
axis=0 : 행으로 붙여라 (기본 값)
axis=1 : 열로 붙여라
join : inner(기본 값), outer #join 명시 안하면 inner
df1 = pd.DataFrame({'A':[10,25], 'B':[15,30]})
df2 = pd.DataFrame({'A':[20,30, 50], 'C':[35,30, 40]})
df2.drop([1], inplace = True)
display(df1)
display(df2)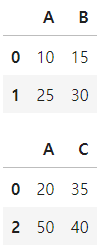
1) axis=0
인덱스는 모두 나타나고 열이 inner/outer에 따라 결과가 달라짐
inner예시
pd.concat([df1, df2], axis = 0, join = 'inner')
outer예시
pd.concat([df1, df2], axis = 0, join = 'outer')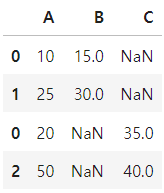
2) axis= 1
열은 전부 나오고 행이(인덱스) inner/outer에 따라 결과가 달라진다.
inner예시
pd.concat([df1, df2], axis = 1, join = 'inner')
outer예시
pd.concat([df1, df2], axis = 1, join = 'outer')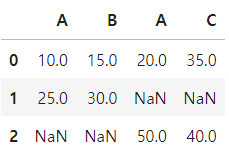
🚘 pd.merge(): 데이터프레임 결합
매핑 기준: 특정 컬럼 값 기준으로 결합
- Sql테이블 join과 유사
- 한번에 2개의 데이터프레임만 merge가능
- 한 데이터프레임에서 일부 컬럼만 merge가능
💡mrege전에 고려사항
✅ dtypes로 컬럼 타입 확인 후 일치시키기
✅ 컬럼명 일치시키기
merge수행
df1 = pd.DataFrame({'A':[10,25], 'B':[15,30]})
df2 = pd.DataFrame({'A':[20,30, 50], 'C':[35,30, 40]})
df2.drop([1], inplace = True)
display(df1)
display(df2)
pd.merge(df1, df2, how='inner', on='컬럼명')
pd.merge(df1,df2['컬럼1','컬럼2'])
- 병합할 데이터프레임 2개 명시
- how
명시 안하면 자동으로 inner 수행
inner, outer, left, right - on
따로 명시 안하면 자동으로 key 결정
pd.merge(df1, df2, how = 'inner', on = 'A')
pd.merge(df1, df2, how = 'left')🚘 pd.pivot() : 데이터프레임 재구성
dataframe.pivot(index, column, values)
