

여러개의 노드와 각각의 가중치 곱셈을 하기 위해서 행렬곱을 사용하고 텐서는 행렬처리를 빠르게 수행해준다.
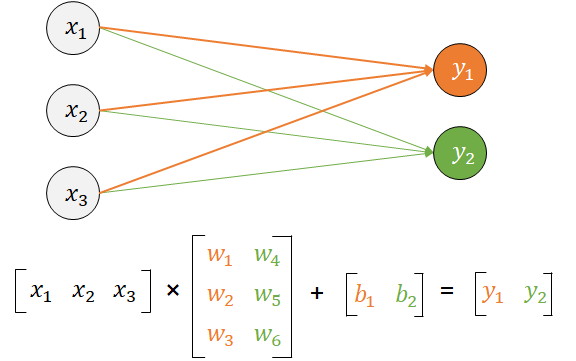
[https://wikidocs.net/150781]
Hidden layer
input layer와 output layer사이에 존재하는층(layer) 여부로 단층, 다층 퍼셉트론이 구분된다.
특징 자동으로 추출하는데 어떤 특징인는 알 수 없다.
input layer의 노드보다 hidden layer의 노드가 더 많을 수 있다.
점차 차원이 줄어들면서 output layer로 향한다.
레이어의 개수와 노드 개수는?
기준은 없으며 데이터의 특성이나 기대하는 연산 속도, 데이터의 양 등에 따라서 조절한다.노드 수가 많을 수록 입력 데이터를 세세하게 뜯어서 다양한 특징을 대상으로 학습하는 효과가 나고, 레이어가 많을 수록 어떤 특징을 심도있게 분석하면서 학습하는 효과가 난다.
Activation
앞 뉴런의 신호를 넘겨준다. 활성화 함수가 없으면 hidden layer를 추가하는 의미가 없어진다
활성화함수 없이 예측: 선형적이고 단순한 예측
활성화함수 포함한 예측: 비선형적이고 복잡한 예측 가능해 진다.
활성화 함수는 히든 레이어에서 사용하는 것과 아웃풋 레이어에서 사용하는 것으로 구분해야 한다.
hidden layer 활성화 함수
hidden layer에는 "항상 활성화 함수를 사용"한다.
ReLU와 ReLU에서 파생된 여러 활성화 함수가 있습니다.
swish 는 회귀, 분류와 상관없이 퍼셉트론에 관련된 학습 모두에 쓸 수 있다. 또한 마지막 레이어가 회귀인지 분류인지에 대한 결정에 큰 영향을 준다.
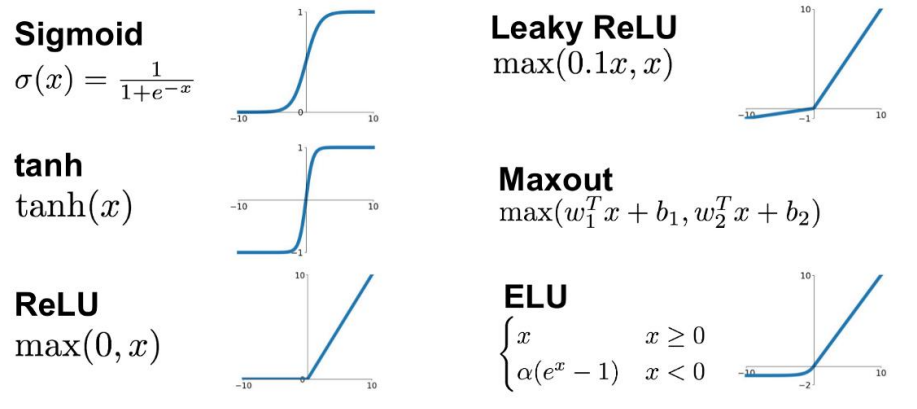
output layer 최종 결과를 도출할 때 사용하는 활성화 함수
회귀: identitiy 사용 (코드에서 따로 명시하지 않는다.)
분류: softmax 사용 ( 값을 0~1 사이인 확률로 변환하기 위해 시그모이드를 통해 만든 softmax 함수 사용) , 'sigmoid'
Optimizer
- Gradient Descent (경사하강법)
함수의 기울기를 구하여 함수의 극값에 이를 때까지의 기울기가 낮은 쪽으로 반복하여 이동하는 방법
SGD (batch학습, 한 번에 모든 데이터가 아닌 나눠서 진행)
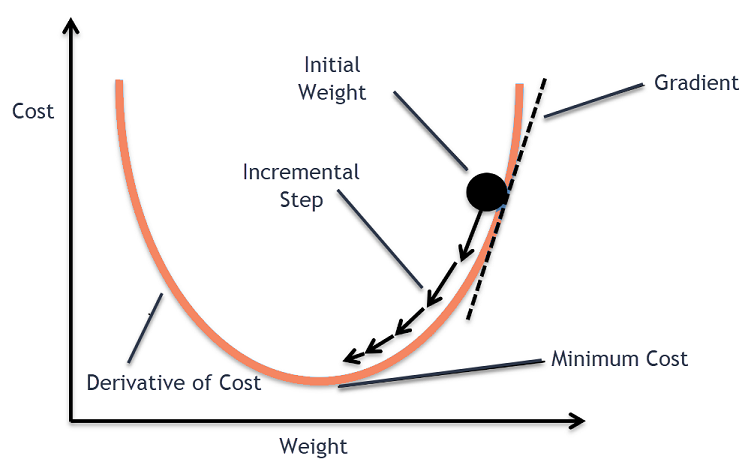
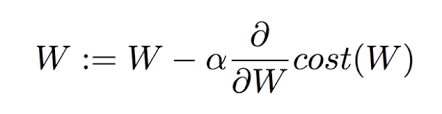
(제가 이해한 것을 토대로만 작성합니다)가중치의 변함에 따라 손실함수의 값을 그래프로 나타낸 것이다.
새로운 가중치 = 기존 가중치 - 학습률(현재 가중치에 따른 손실 값이 얼마나 변했는지 )
학습률(learning rate)로, 경사 하강 단계의 크기를 조절합니다. 학습률의 계산에 따라 여러 optmizer로 나뉜 것이 momentum, adagrad, adam 등이 있다. learning rate optimizer라고도 한다.
-
Momentum (관성)
이전에 이동했던 방향을 기억해서 다음 이동의 방향에 반영
NAG -
Adagrad (Adaptive Gradient)
많이 이동한 변수는 최적값에 근접했을 것이라는 가정하에, 많이 이동한 변수를 기억해서 다음 이동 거리를 줄인다.
RMSprop -
Adam (RMSprop + Momentum)
방향과 스탭사이즈를 적당하게
metrics
모델을 학습할 때 성능을 평가하는 평가지표이다.
(분류 모델인 경우)
model.compile에서 metrics를 지정하지 않으면, 모델은 훈련 중에 정확도(Accuracy)를 기본 메트릭으로 사용하지 않는다. 이렇게 하면 훈련 과정에서 정확도를 모니터링하지 않으며, 훈련이 진행될 때 출력에 정확도 관련 정보가 표시되지 않는다.
메트릭스를 지정하지 않으면 기본적으로 손실 함수(loss)만 모니터링된다. 따라서 모델을 훈련하고 나중에 정확도와 같은 추가 메트릭을 평가하려면 model.evaluate를 사용하여 테스트 데이터에 대한 메트릭을 확인 할 수 있다.
(회귀 모델인 경우)
mse, rmse, r2, mae, mspe, mape, msle 등이 있습니다.
데이터의 차원
데이터 형태 = rank (of tensor)
데이터의 공간 = dimension (of vector space)
🍍태뷸러 데이터의 차원?
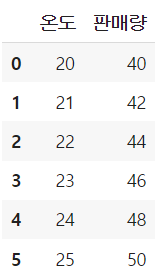
-
공간에서의 맥락
변수의 갯수가 2개임으로 2차원이다.
따라서 차원의 수 = 변수의 개수가 된다. -
데이터 형태
(6,2) 2차원으로 배열의 깊이를 나타낸다.
🍍 이미지 데이터의 차원?
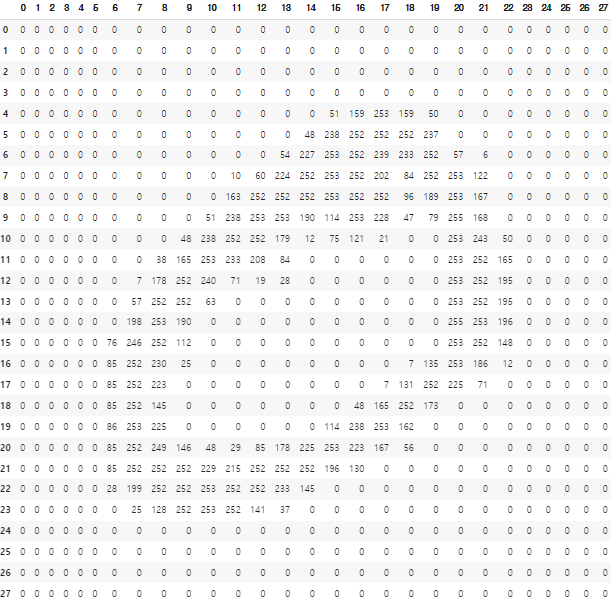
-
공간에서의 맥락
이미지 데이터셋은 이미지의 픽셀 하나하나를 변수로 본다.
MNIST 데이터셋은 가로 세로 픽셀이 28, 28임으로 곱하면 784개의 변수가 된다. 즉 784차원이다. -
데이터의 형태
(60000, 28, 28) 3차원이다. 28x28이 60000개 있다.
즉 데이터의 공간은 하나의 관측치의 형태가 무엇인지를 기준으로 해야한다.
하나의 관측치란?
태뷸러, 즉 엑셀 시트와 같은 데이터는 row 하나 하나가 개별적인 관측치이다.(1차원) 이미지 데이터에서는 "이미지 한 장" 그 자체가 하나의 관측치를 의미한다.(2차원)
관측치의 형태에 따라 공간에서의 차원 형태가 달라진다.
실습

기본
X = tf.keras.Input(shape=[13]) #공간상의 차원
H = tf.keras.layers.Dense(128, activation='swish')(X)
Y = tf.keras.layers.Dense(1)(H)
model = tf.keras.Model(X,Y)
model.compile(loss='mse')
model.summary()
마지막 출력 층의 노드 수는 회귀문제인 경우 결과가 하나임으로 1, 분류문제인 경우 분류의 갯수를 적으면 된다. 데이터와 맞지 않은 값을 넣을 경우 오류가 뜬다.
히든레이어는 반드시 activation함수를 명시해줘야 한다.
iris데이터 학습
iris의 종속변수는 범주형 형태임으로 get_dumies 를 통해 원핫인코딩 해준다.
다중 클래스 분류 문제에 범주형 변수라면 모델의 입력으로 사용할 수 있도록 원핫인코딩을 생각해본다. 다만, decision tree관련된 모델 randomforest, xgbosst, lightgbm 등은 원핫인코딩 없이 진행 가능할 수 있다.
독립변수가 수치형일 때 정규화 하는것을 생각해본다. 특히 거리기반 알고리즘 사용시 중요할 수 있다.
참고: train와 test의 데이터셋을 나누지 않고 train으로 학습하고 평가하고 있다는 점을 감안한다.
import pandas as pd
import tensorflow as tf
# 1. 데이터를 준비
df = pd.read_csv('iris.csv')
df_onehot = pd.get_dummies(df) # # (150, 4) (150, 1) -> # (150, 4) (150, 3)
x_train = df_onehot[['꽃잎길이', '꽃잎폭', '꽃받침길이', '꽃받침폭']]
y_train = df_onehot[['품종_setosa', '품종_versicolor', '품종_virginica']]
print(x_train.shape, y_train.shape) # (150, 4) (150, 3)
# 2. 모델의 구조를 만듭니다
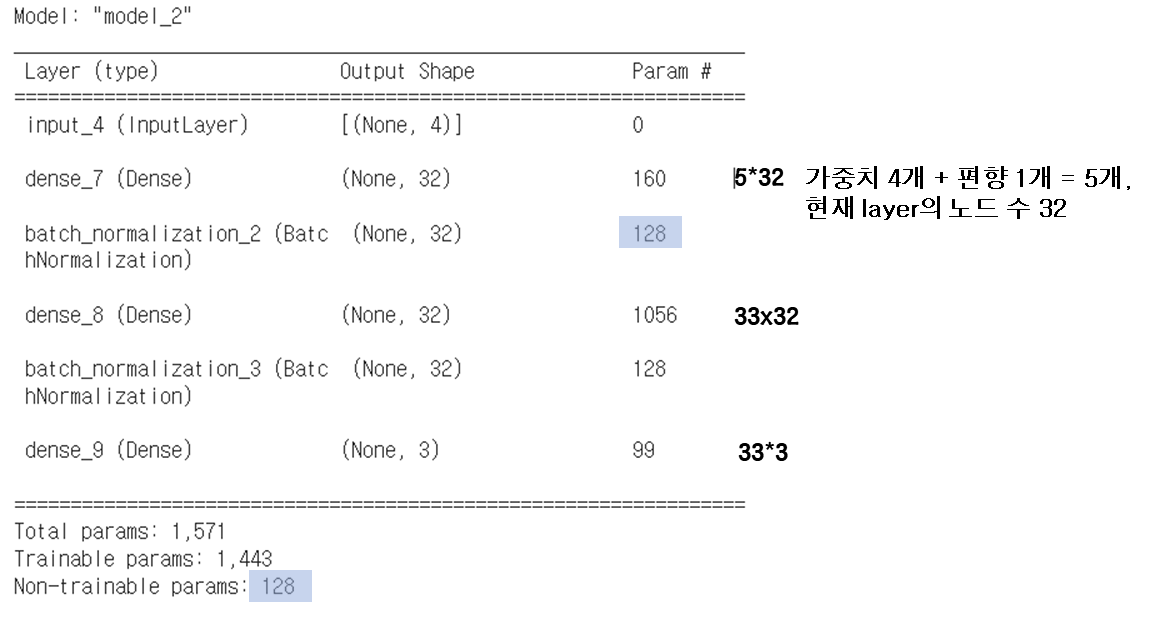
X = tf.keras.Input(shape=[4]) # 공간상의 차원 (변수 갯수)
H = tf.keras.layers.Dense(32)(X) # 32개 노드의 레이어 생성
H = tf.keras.layers.BatchNormalization()(H)
H = tf.keras.layers.Activation('swish')(H)
H = tf.keras.layers.Dense(32)(H)
H = tf.keras.layers.BatchNormalization()(H)
H = tf.keras.layers.Activation('swish')(H)
Y = tf.keras.layers.Dense(3, activation="softmax")(H) #마지막 출력층 layer
model = tf.keras.Model(X, Y)
model.compile(loss='categorical_crossentropy', metrics="accuracy") # 범주형임으로 accuracy사용하며 내부에서 자동적으로 CategoricalAccuracy 로 수행한다.
model.summary()
# 3. 데이터로 모델을 학습(fit)합니다.
model.fit(x_train, y_train, epochs=500, validation_split=0.2, verbose=0)
model.fit(x_train, y_train, epochs=5, validation_split=0.2)
# 모델을 이용합니다.
model.predict(x_train[:5])
'''array([[9.9804842e-01, 1.9512941e-03, 2.8888257e-07],
[9.9344784e-01, 6.5499623e-03, 2.2618324e-06],
[9.9668002e-01, 3.3190064e-03, 9.3357193e-07],
[9.9207556e-01, 7.9209665e-03, 3.4445750e-06],
[9.9838471e-01, 1.6151003e-03, 2.2770047e-07]], dtype=float32)'''
y_train[-5:]
model.evaluate(x_train, y_train)🍋 output layer 및 loss 함수 구분
-
범주형 종속 변수가 2class(2가지)인 경우
학습 결과가 0 또는 1로 노드가 1개만 필요하다.출력 층 노드 갯수 : 1
출력 acvivation function:sigmoid
loss function:binary_crossentropy -
범주형 변수가 2class 이상인 경우
모델 학습 전에 종속변수 onehotencoding 수행하였다.
=> 변수의 종류만큼 컬럼이 생성된다.출력 층 노드 갯수 : class 갯수 만큼
출력 acvivation function:softmax
loss function:categorical_crossentropy
-
범주형 변수인데 원핫인코딩(가변수화)를 하지 않았을 경우
출력 층 노드 갯수 : class 갯수 만큼
출력 acvivation function:softmax
loss function :sparse_categorical_crossentropy -
수치형 변수
출력 층 노드 갯수 : 1
출력 acvivation function:linear기본 값으로 굳이 명시 안해도 된다.
loss function :sparse_categorical_crossentropy
(결론)
2class일때는 1번과 2번 모두 사용 가능하고 loss function도 결과가 동일하게 나온다. 다만 2class라도 가변수화를 진행했을 경우 각각 0, 1 이 나옴으로 2번을 사용해야 한다.
위의 iris데이터는 3class 범주형임으로 2번을 사용하고 있다.
model.summary()
만든 model에 대한 결과 확인하기
mode.fit(X,Y)
model.fit(x_train, y_train, epochs=10, batch_size=128, validation_split=0.2)
x_train: 학습데이터, y_train: 학습레이블 데이터
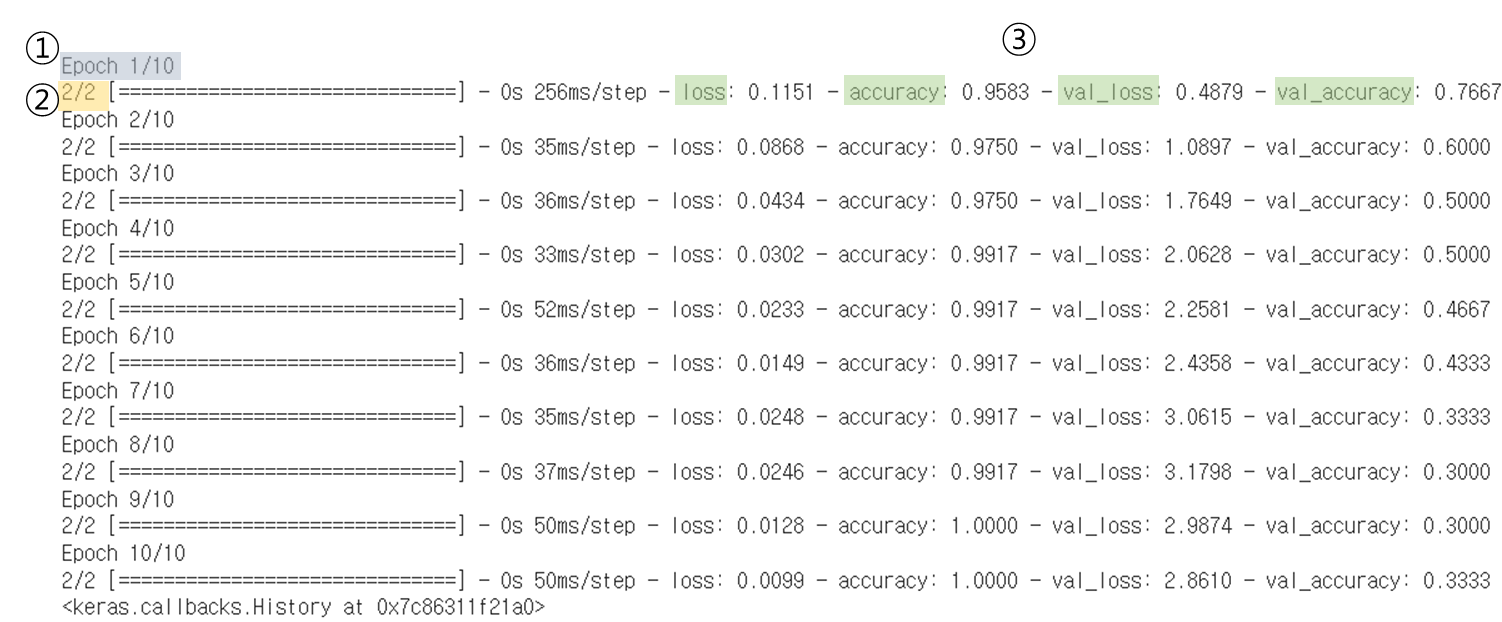
1) Eoch(에폭스): 모델 수행 횟수
2) batch에 따른 수행 횟수
batch : 기본 batch_size는 32, 데이터를 나눠서 수행하는 횟수
따라서 ecpochs가 1번 수행하더라도 데이터분할하여 가중치를 배치사이즈 만큼 수행한다.
iris데이터는 150행이고 batch_size가 128임으로 2번에 나눠서 수행한다.
3) 성능 결과
loss(테스트데이터 loss), accuracy(테스트데이터 정확도), val_loss(검증데이터 loss), val_accuracy(검증 데이터 정확도) 4가지가 나타나있다.
val은 validation의 약자로 fit 할때 수행되도록 validation_split 을 설정하였다.
validation_split = 0.2 는 train data의 마지막 20%를 validation으로 쓴다는 의미다. (데이터값은 매번 고정)
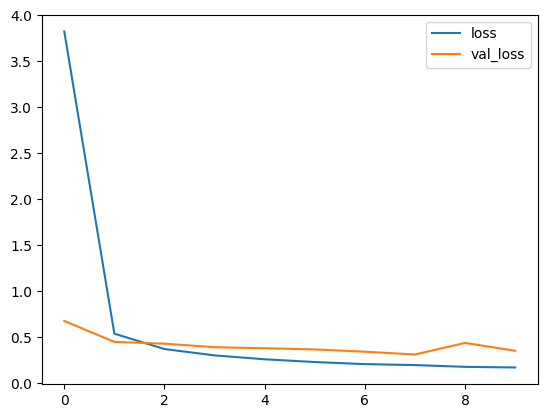
loss는 떨어지지만 val_loss가 증가하고 있으면 overfitting이 발생하고 있다는 것이다.
validation 검증 데이터셋을 사용하는 가장 큰 이유는?
train도중에 overfitting이 발생하는지 확인하기 위해서 필요하다.
validation_split하면 모델 학습에 영향이 있는지?
검증 데이터는 학습 자체에는 영향을 주지 않고, 현재 학습의 경향성을 살피는데 사용된다. 그 자체로는 모델 성능을 개선 시키지 못하지만 이를 참고해서 하이퍼파라미터를 수정하는데 이용함으로써 결과적으로는 모델 성능 개선에 기여하게 된다.
Early Stopping
overffiting이 발생하면 멈춘다!
어떤 현상이 발생했을 때 멈추는지 명시해주면된다.
라이브러리 from tensorflow.keras.callbacks import EalryStopping
early = tf.keras.callbacks.EarlyStopping(monitor='val_loss', #val_loss 수치를 기준으로 확인
min_delta=0,
patience=10, #10번 동안 개선이 없으면 중지
restore_best_weights=True)
result = model.fit(x_train, y_train, epochs=1000, batch_size=128, validation_split=0.2, callbacks=[early])딥러닝 평가
evaluate를 사용해서 바로 결과를 볼수있지만 predict로 예측해야 하는 일이 생기기도 한다. 딥러닝을 predict를 수행하면 위의 코드와 같이 class별로 확률이 나오게 된다. 따라서 가장 높은 값을 하나 가져오는 추가 작업이 필요하다.
- 출력층 Dense가 1인경우
y_pred = model.predict(x_train)
y_pred = np.where(y_pred > 0.5, 1, 0)- 출력층 Dense가 2이상인 경우
y_pred = model.predict(x_train)
y_pred = np.argmax(y_pred, axis=1)BatchNormalization
모델 학습과정에서 가중치가 계속해서 갱심됨에 따라 각 층에서 활성화된 데이터 값들이 지속적으로 변동한다. 데이터들의 분포가 치중 되는 현상을 해소하기 위해 각 층마다 데이터들을 정규화 시켜주는 연산을 해준다. 이로써 한쪽으로 편향되어 있던 데이터들의 활성화 값의 불균형을 해소한다.
Dropout
Dropout은 앙상블의 효과로 오버피팅을 방지한다.
LeNet5
fasion_minist데이터 학습
import tensorflow as tf
import matplotlib.pyplot as plt
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.fashion_mnist.load_data()
import matplotlib.pyplot as plt
num = 1
print(y_train[num])
plt.imshow(x_train[num], cmap='gray')
plt.show()
# shape변경
x_train = x_train.reshape(60000, 28, 28, 1)
x_test = x_test.reshape(10000, 28, 28, 1)
# 텐서플로우의 원핫인코딩 함수
y_train = tf.keras.utils.to_categorical(y_train)
y_test = tf.keras.utils.to_categorical(y_test)
# 모델 생성
X = tf.keras.Input(shape=[28, 28, 1])
H = tf.keras.layers.Conv2D(6, 5, padding="same")(X)
H = tf.keras.layers.BatchNormalization()(H)
H = tf.keras.layers.Activation("swish")(H)
H = tf.keras.layers.MaxPool2D()(H)
H = tf.keras.layers.Conv2D(16, 5)(H)
H = tf.keras.layers.BatchNormalization()(H)
H = tf.keras.layers.Activation("swish")(H)
H = tf.keras.layers.MaxPool2D()(H)
H = tf.keras.layers.Flatten()(H)
H = tf.keras.layers.Dense(120)(H)
H = tf.keras.layers.BatchNormalization()(H)
H = tf.keras.layers.Activation("swish")(H)
H = tf.keras.layers.Dense(84)(H)
H = tf.keras.layers.BatchNormalization()(H)
H = tf.keras.layers.Activation("swish")(H)
Y = tf.keras.layers.Dense(10, activation="softmax")(H)
model = tf.keras.Model(X, Y)
model.compile(loss="categorical_crossentropy", metrics="accuracy")
model.summary()
# 모델 학습
model.fit(x_train, y_train, epochs=20, batch_size=128, validation_split=0.1)
#모델 평가
model.evaluate(x_test, y_test)cifar10데이터 학습
개별 cifar10 shape이 (32,32,3)인 이유?
32*32가 3개의 채널이라는 뜻인데 가공된 데이터셋에 따라 가로, 세로, 채널의 순서는 다를 수 있다.
데이터의 공간: 3072차원
import tensorflow as tf
# cifar10
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.cifar10.load_data()
print(x_train.shape, y_train.shape)
print(x_test.shape, y_test.shape)
#flatten하기
# 범주형: 원핫인코딩
# 수치형: normalize
# x_train = x_train / 255.
# x_test = x_test / 255.
#모델 만들기
X = tf.keras.Input(shape=[32,32,3])
H = tf.keras.layers.Flatten()(X)
H = tf.keras.layers.Dropout(0.6)(H)
H = tf.keras.layers.Dense(1024)(H)
H = tf.keras.layers.BatchNormalization()(H)
H = tf.keras.layers.Activation('swish')(H)
H = tf.keras.layers.Dropout(0.6)(H)
H = tf.keras.layers.Dense(512)(H)
H = tf.keras.layers.BatchNormalization()(H)
H = tf.keras.layers.Activation('swish')(H)
H = tf.keras.layers.Dropout(0.6)(H)
H = tf.keras.layers.Dense(258)(H)
H = tf.keras.layers.BatchNormalization()(H)
H = tf.keras.layers.Activation('swish')(H)
H = tf.keras.layers.Dropout(0.6)(H)
Y = tf.keras.layers.Dense(10, activation='softmax')(H)
model = tf.keras.Model(X, Y)
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=0.0001),
loss='sparse_categorical_crossentropy',
metrics='accuracy')
model.summary()
#모델 학습하기
#모델 평가하기
early = tf.keras.callbacks.EarlyStopping(patience=0,
restore_best_weights=True)
result = model.fit(x_train, y_train, epochs=10, batch_size=128, validation_split=0.2)
model.evaluate(x_test, y_test)cifar10데이터 skip connection으로 학습
ResNet도 skip connection을 사용하고 있다.
잔차 학습을 통해서 성능을 개선시킨다.
X = tf.keras.Input(shape=[32, 32, 3])
H = tf.keras.layers.Flatten()(X)
H = tf.keras.layers.Dense(128)(H)
H = tf.keras.layers.BatchNormalization()(H)
H = tf.keras.layers.Activation('swish')(H)
for i in range(32): #H1과 H의 노드 개수는 같아야한다.
H1 = tf.keras.layers.Dropout(0.5)(H)
H1 = tf.keras.layers.Dense(128)(H)
H1 = tf.keras.layers.BatchNormalization()(H1)
H = tf.keras.layers.Add()([H, H1]) # layer 2개를 Add() 한다.
H = tf.keras.layers.Activation('swish')(H)
Y = tf.keras.layers.Dense(10, activation='softmax')(H)
model = tf.keras.Model(X, Y)
#(뒤에 동일, 생략)모델 history 확인
result = model.fit(x_train, y_train, epochs=10, batch_size=128,
validation_split=0.2 # validation_data=(x_val, y_val))
model.evaluate(x_test, y_test)
print(model.history)
import matplotlib.pyplot as plt
plt.plot(result.history['loss'])
plt.plot(result.history['val_loss'])
plt.legend(['loss', 'val_loss'])
plt.show()
문자열 함수 대체 가능
- tf.keras.activations
- tf.keras.optimizers
- tf.keras.losses
- tf.keras.metrics
간단한 예시
X = tf.keras.Input(shape=[784])
H = tf.keras.layers.Dense(120, activation=tf.keras.activations.swish)(X)
Y = tf.keras.layers.Dense(10, activation=tf.keras.activations.softmax)(H)
model = tf.keras.Model(X, Y)
model.compile(
loss=tf.keras.losses.categorical_crossentropy,
optimizer='adam',
metrics=tf.keras.metrics.categorical_accuracy
)fit대신 내부 동작 코드
[참고]
https://www.youtube.com/watch?v=c7NURwHmM5k&list=PLfLgtT94nNq1DrREU_qG2w4yd2ZzJb-FG&index=6
