
Convolutional neural network
CNN의 아키텍처 중에서 유명한 LeNet5와 AlexNet을 통해 CNN을 이해해본다.
LeNet 5

s : stride
f: filter size (=kernal_size)
기본 정의
1. 필터(filter): 이미지의 특징을 찾기 위한 정사각형 행렬로 정의된 파라미터 커널로도 불린다.
2. 스트라이드(stride): 필터는 입력 데이터를 일정한 간격인 스트라이드로 순회하면서 특징을 추출하는데 결과로 feature map이 만들어진다.
3. 패딩(padding) : 합성곱 계층에서 필터와 스트라이드 적용으로 생성된 특징지도는 입력데이터 크기보다 작은데 해당 출력데이터 크기가 줄어드는 것을 사전에 방지하고자 입력데이터 주변을 특징값으로 채우는 것을 의미한다. 보통 1이나 0으로 채운다.
4. 풀링 (pooling) : 입력데이터의 채널수가 변화되지 않도록 2차원 데이터의 새로 및 가로 방향의 공간을 줄이는 연산으로 Max Pooling, Average Pooling이 있다.
LeNet5 해석
28 x 28 x 6 : H x W x Feature Map
14 x 14 x 6 : Feature Map이 이전과 같은 것만 봐도 pooling 했다는 것을 알 수 있다.
10 x 10 x 16 : 10이 나온 이유는 아래 OH(oput height), OW(output width) 구하는 식에서 볼 수있다. Feature map(필터링 갯수)는 정해진 규칙이 있는 것이 아니라 모델링하는 사람의 마음이다..?
FC(Fully Connected Layer): 마지막 Flatten을 통해 이미지의 형태를 배열 형태로 처리한뒤 Fully Connected Layer를 통해 최종 클래스가 분류된다. 출력과 가까운 층에는 ReLu를 사용하고 마지막 계층에는 Softmax를 조합한다.
softmax가 10으로 표현된 것은 숫자 0~9까지 다중분류 갯수를 표현한 것이다.
🧠 Output Height, Output Width 구하는 식
- 입력크기: (H,W)
- 필터크기: (FH, FW)
- 출력크기 (OH, OW)
- 패딩 : P
- 스트라이드: S
사용되는 Keras Library
Conv2D (convolution)
속성
- filters : 새롭게 제작하려는 feature map의 수, 서로 다른 필터 갯수
- kernal_size : Conv2D 필터의 가로세로 사이즈
- strides : Conv2D 필터의 이동 보폭
- padding : 사용 이유 1.이전 feature map 사이즈 유지 2. 외곽 정보 더 반영
값: 'vaild', 'same'
"valid" means no padding. same results in padding with zeros evenly to the left/right or up/down of the input.
padding="same" and strides=1, the output has the same size as the input. - activation : 활성화 함수
Maxpool2D (pooling)
속성
- pool_size: 풀링 필터의 가로세로 사이즈
- strides : 풀링 필터의 이동 보폭
pool_size와 strides는 보통 같은 사이즈를 따라간다.
AlexNet 해석해보기
3차원 컬러 이미지
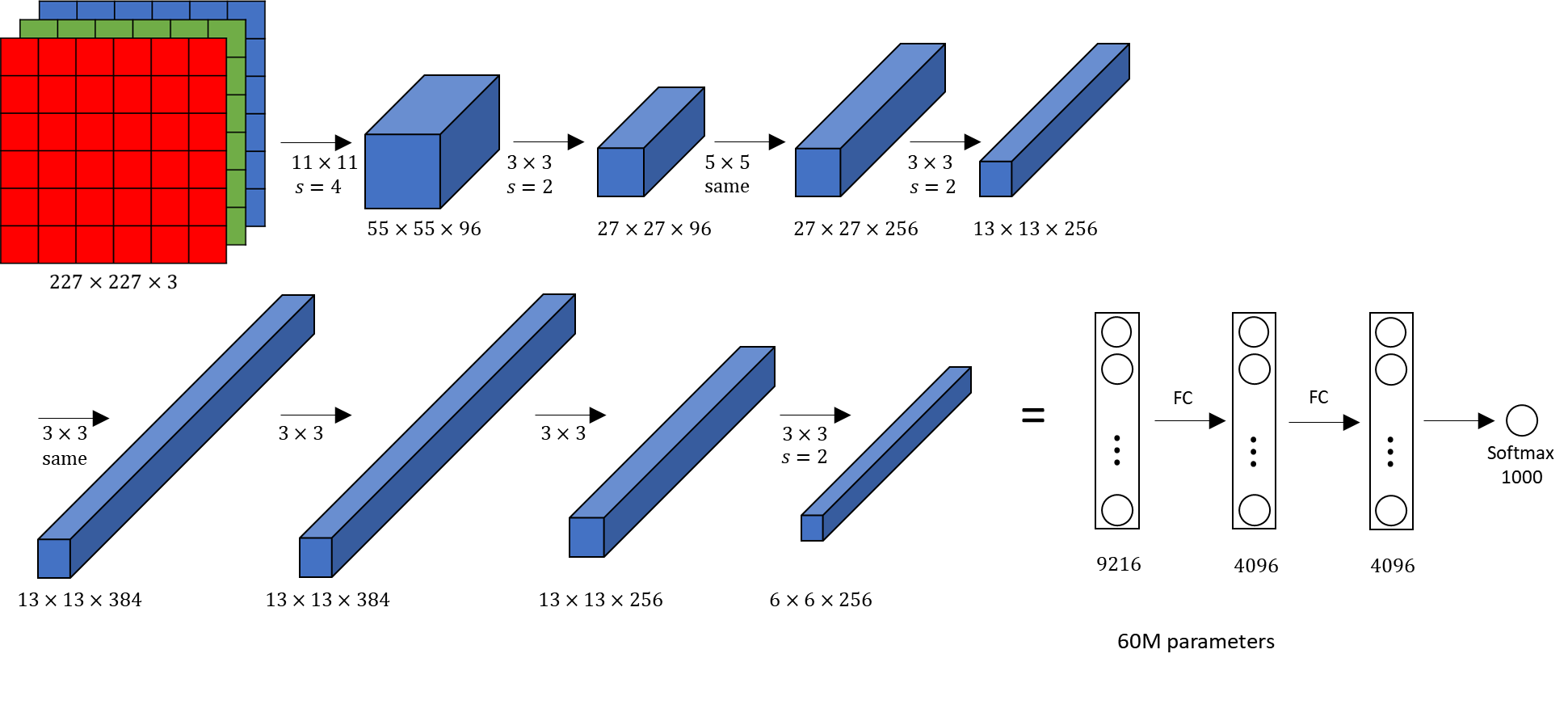
3차원 합성곱 연산에서 입력 데이터 채널 수와 필터의 채널수가 같아야 한다.
필터크기는 임의로 설정가능하나 모든 채널의 필터 크기가 동일해야 한다.
same은 padding을 사용하고 stride가 1이면 크기가 유지되어 width와 height, feature map사이즈는 같지만 더 고도화된 결과물이다.
keras 실습
#데이터불러오기
(train_x, train_y), (test_x, test_y) = keras.datasets.fashion_mnist.load_data()
### 전처리 ###
# 1. X값 Min-Max Scaling (흑백 이미지)
max_n, min_n = train_x.max(), train_x.min()
train_x = (train_x - min_n) / (max_n - min_n)
test_x = (test_x - min_n) / (max_n - min_n)
# 2. 표준화 스케일링 (컬러 이미지)
# 전체 컬러 값을 합쳐서 표준화 시켰지만 R, G, B 별로 각각 구하여 합치는 것이 정석이다.
train_x = train_x - np.mean(train_x) / np.std(train_x)
test_x = test_x - np.mean(test_x) / np.std(test_x)
# Y : Onel-Hot Encoding
from tensorflow.keras.utils import to_categorical
train_y = to_categorical(train_y, class_n)
test_y = to_categorical(test_y, class_n)
train_y.shape, test_y.shape
### Functional API 형식 모델링 ###
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras.backend import clear_session
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, Dense, Flatten, Conv2D, MaxPool2D, BatchNormalization, Dropout
clear_session() # 세션 클리어
#종류별로 하나씩만 표현한 것임으로 실제는 적절히 엮어 활용해야 한다.
il = Input(shape=(28,28,1)) # 인풋 레이어
hl = Conv2D(filters=32,kernel_size=(3,3),strides=(1,1),padding='same',activation='relu')(il)
hl = BatchNormalization()(hl)
hl = MaxPool2D(pool_size=(2,2),strides=(2,2))(hl)
hl = Dropout(0.25)(hl)
### Fully Connected Layer ###
hl = Flatten()(hl)
hl = Dense(512, activation='relu')(hl)
hl = BatchNormalization()(hl)
ol = Dense(10, activation='softmax')(hl) #아웃풋 레이어
model = Model(il, ol)
model.compile(optimizer='adam', # 경사하강법의 세부 방법 결정!
loss=keras.losses.categorical_crossentropy, # 내 모델의 예측값과 실제 정답을 무엇으로 비교할 지!
metrics=['accuracy'] # 분류 문제의 보조 지표!
)
print(model.summary()) Early Stopping을 활용한 모델 학습하기
from keras.callbacks import EarlyStopping
es=EarlyStopping(monitor='val_loss',
min_delta=0,
patience=3,
verbose=1,
restore_best_weights=True
)
hist = model.fit(train_x, train_y, epochs=10000, verbose=1,
validation_split=0.2, # training set에서 20%를 validation set으로 만듬!
callbacks=[es] # callbacks함수에 여러개 적용 가능함으로 리스트로 묶어준다.
)모델 예측하고 평가하기
y_pred = model.predict(x_test)
# 원핫 인코딩 한 것을 다시 묶어주는 코드 (10행이 -> 1행으로 변경)
# 평가 지표 및 실제 데이터 확인을 위해 필요
y_pred_arg = np.argmax(y_pred, axis=1)
test_y_arg = np.argmax(y_test, axis=1)
from sklearn.metrics import accuracy_score,classification_report
logi_train_accuracy = accuracy_score(train_y, single_pred_train)
logi_test_accuracy = accuracy_score(test_y, single_pred_test)
classification_report