
target변수가 회귀인지 분류인지를 구분하여 알맞은 알고리즘을 사용하자
Linear Regression
: 실제값 / : 예측값 / : 평균값
선형회귀 식:
: 기울기(가중치, coefficient)
: y절편(편향, intercept)
최적의 회귀모델: 전체 데이터의 오차 합이 최소가 되는 모델로 가중치와 편향을 찾는다.
단순 회귀: 하나의 독립변수가 종속변수에 영향, 위의 회귀식 사용
다중 회귀: 여러 독립변수가 종속변수에 영향, 여러개의 가중치를 찾아야 한다.
회귀계수 확인
model.coef_ : 가중치, 다중 회귀인 경우 배열로 return
model.intercept_ : 편향
특징
-
회귀 모델에만 사용가능하다. (분류모델x)
-
변수가 많아질수록 과적합 발생한다. 독립변수가 많아짐에 따라 복잡해지기 때문이다.
-
위의 이유로 feature engineering이 중요하다. 예를들어 같은 독립변수끼리의 서로의 값을 설명하고 있는지를 확인하고 맞다면 제거해본다. 이를 검증하는 방법은 기존 target label은 없애고 의심 독립변수를 target으로 하여 모델링 후 평가했을 때 정확도가 예측 결과가 높다면 가능성이 크다.
코드
# 불러오기
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_absolute_error, r2_score
# 선언하기
model = LinearRegression()
# 학습하기
model.fit(x_train, y_train)
# 예측하기
y_pred = model.predict(x_test)
# 평가하기
print(mean_absolute_error(y_test, y_pred))
print(r2_score(y_test, y_pred))
#회귀계수 확인
print(list(x)) #dataframe에 list로 감싸면 columns만 출력!!
print('가중치', model.coef_)
print('편향', model.intercept_)시각화, 예측값과 실제값 비교
plt.plot(y_test.values) #y_test의 인덱스가 정렬되지 않아서 series y_test를 넣으면 그래프가 이상하게 그려지는 것 !!! 값만 가져오기 위해 values를 써준다.
plt.plot(y_pred)
plt.show()K-Nearest Neighbor
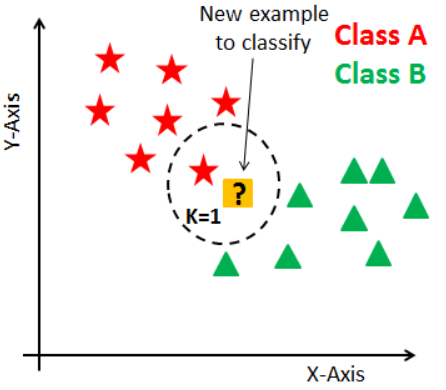
특징
- k개 최접근(거리가 가장 가까운) 이웃의 값을 찾아 새로운 값을 예측하는 알고리즘
- 데이터의 갯수가 많아질수록 복잡해지고(최접근 찾는데 오래걸림), 너무 적으면 신뢰성이 없다.
- k개수가 작을수록 복잡해진다
회귀모델: 근접값들의 평균, 라이브러리 sklearn.neighbors.KNeighborsRegressor
분류모델: 최빈값 선택, 라이브러리 sklearn.neighbors.KNeighborsClassifier
적절한 k값(n_neighbors)을 찾기 (기본값 5)
k를 1로 설정X : 하나의 이웃으로만 판단하면 편향된다.
k를 홀수로 설정 : 분류모델인 경우 과반수 이상의 이숫이 나오지 않을 수 있다.
스케일링 방법
최접근 데이터를 찾기 위해서 Scaling이 필요하다.
변수마다 값의 범위가 모두 다르기 때문에 거리 계산이 틀어지기 때문이다.
- 정규화 (Normalization): 변수의 값이 0~1 사이
식:- 표준화 (Standardization): 변수의 평균이 0, 표준편차가 1 (이번 글에는 사용 X)
평가용 데이터도 학습용 데이터 기준으로 스케일링 수행한다.
모델 예측시 평가용 데이터로 새로 스케일링하여 값을 예측한다면 기존 학습용 데이터로 모델링한 것과 일치하지 않아 결과가 맞지 않는다. 테스트 데이터에는 어떤 값들이 있는지 알수없는 것을 가정하기 때문에 미리 스케일링할 수 도 없다. 따라서 평가용 데이터가 학습용 데이터를 포함할 것으로 가정하고 수행한다.
수치형 독립변수에 대해 전체 수행한다.
반환값이 ndarray라서 주의한다.
# 함수 불러오기
from sklearn.preprocessing import MinMaxScaler
# 정규화
scaler = MinMaxScaler()
x_train_s = scaler.fit_transform(x_train) #학습용 데이터 기준으로만 스케일링 함으로 fit_transform 적용
x_test_s = scaler.transform(x_test) # x_test는 변환만 시켜준다.
회귀모델 코드
옵션 / n_neighbors : 기본값 5
from sklearn.neighbors import KNeighborsRegressor
from sklearn.metrics import mean_absolute_error, r2_score
# 선언하기
model = KNeighborsRegressor(n_neighbors=5) #n_neighbors는 기본값 5
# 학습하기
model.fit(x_train, y_train)
# 예측하기
y_pred = model.predict(x_test)
# 평가하기
print(mean_absolute_error(y_test, y_pred))
print(r2_score(y_test, y_pred))
분류모델 코드
# 불러오기
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import confusion_matrix, classification_report
# 선언하기
model = KNeighborsClassifier(n_neighbors=5)
# 학습하기
model.fit(x_train, y_train)
# 예측하기
y_pred = model.predict(x_test)
# 평가하기
print(confusion_matrix(y_test, y_pred))
print(classification_report(y_test, y_pred))Decision Tree
특징
• 분류모델: 마지막 노드 샘플들의 최빈값 반환, target변수가 object여도 가능
• 회귀모델: 마지막 노드 샘플들의 평균 예측값 반환
• 기본값은 깊이제한이 없어 과적합 발생이 쉬움으로 트리 깊이 제한과 같은 튜닝이 필요하다.
• 스케일링 등 전처리 영향도가 크지 않다. 가변수화를 되도록 안하는 것이 좋다!!
• 화이트박스모델로 분석과정이 직관적이고 설명하기 쉽다.
• 의미있는 질문을 먼저 하는 것이 중요하다.
용어
• Root Node: 전체 자료를 갖는 시작하는 마디
• Child Node: 마디 하나로부터 분리된 2개 이상의 마디
• Parent Node: 주어진 마디의 상위 마디
• Terminal Node: 자식 마디가 없는 마디(=Leaf Node)
• Internal Node(중간 마디): 부모 마디와 자식 마디가 모두 있는 마디
• Branch: 연결되어 있는 2개 이상의 마디 집합
• Depth: 뿌리 마디로부터 끝 마디까지 연결된 마디 개수
불순도(Impurity)란?
혼재된 다른 성분들과의 상대적인 양을 나타내는 개념
지니불순도가 낮은 속성을 의사결정 트리 노드 결정 (낮을수록 좋음)
깊이가 커질수록 불순도는 낮아짐
완벽하게 분류되면 0, 완벽하게 섞이면 0.5 즉, 값이 클수록 불순도가 높다!
불순도 지표
1. 지니불순도: 1 − (양성 클래스 비율2+음성 클래스 비율2)
2. 엔트로피
정보이득이란? (Information Gain)
부모 불순도 - 자식 불순도의 값으로 정보 이득이 클수록 좋다.
정보이득이 크다 = 어떤 속성으로 분할할 때 불순도가 줄어든다.
정보이득이 큰 속성부터 분할 시작한다.
가지치기
과대적합, 일반화 방지
여러 하이퍼파리미터 값을 조정하여 튜닝
학습데이터에 대한 성능을 떨어뜨리고 평가 데이터에 대한 성능을 높힘
주요파라미터
max_depth: 트리의 최대 깊이 (deafult: None). 값이 작을 수록 모델이 단순해진다.
min_samples_split: 노드를 분할하기 위한 최소한의 샘플 데이터 개수 (default:2, 정이진트리 형태로 생성되기 때문). 값이 클수록 모델이 단순해진다.
min_samples_leaf: 리프노드가 되기 위한 최소한의 샘플 데이터 개수 (default: 1). 값이 클수록 모델이 단순해진다.
max_feature:
max_leaf_node: 리프 노드 최대 개수
- random_sate : 정보이득이 동일할 때 랜덤으로 선택을 하게 됨으로 난수값을 지정할 수 있다
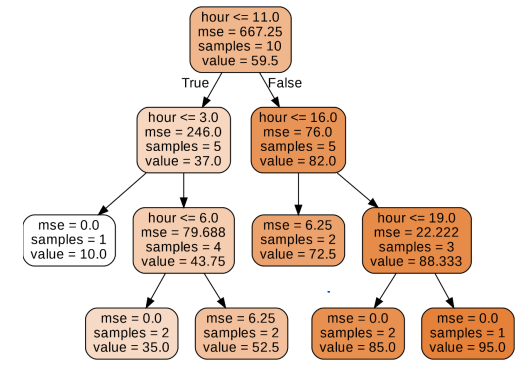
회귀모델 코드
마지막 노드에 있는 샘플들의 평균을 예측값으로 반환한다.
loss function: MSE
from sklearn.tree import DecisionTreeRegressor
from sklearn.metrics import mean_absolute_error, r2_score
# 선언하기
model = DecisionTreeRegressor(max_depth=5)
# 학습하기
model.fit(x_train, y_train)
# 예측하기
y_pred = model.predict(x_test)
# 평가하기
print(mean_absolute_error(y_test, y_pred))
print(r2_score(y_test, y_pred)) 모델 시각화
분류모델 코드
마지막 노드에 있는 샘플들의 최빈값을 예측값으로 반환한다.
loss function: 불순도
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import confusion_matrix, classification_report
# 선언하기
model = DecisionTreeClassifier(max_depth=5)
# 학습하기
model.fit(x_train, y_train)
# 예측하기
y_pred = model.predict(x_test)
# 평가하기
print(confusion_matrix(y_test, y_pred))
print(classification_report(y_test, y_pred))
시각화 해석해보기
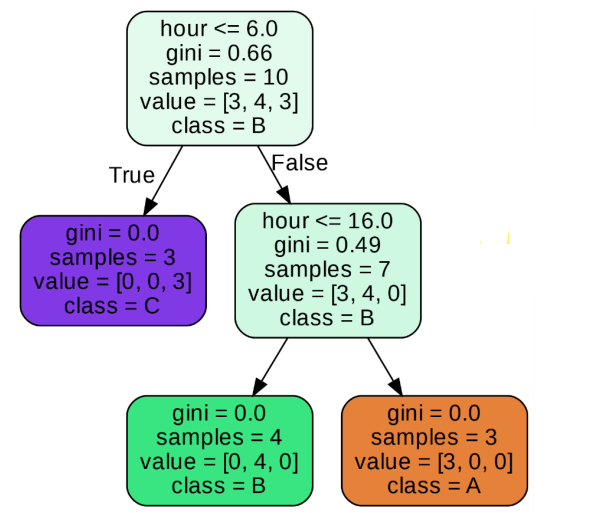
마지막 노드 왼쪽을 설명해보면
- gini: 지니불순도
- smaple: 해당되는 데이터 갯수
- value: 분류의 class의 속하는 개수를 나타낸다.
[0,4,0]임으로 붗꽃 분류 문제임으로 3가지 class로 나뉘고classB에 해당되는 데이터가 4개이다. - class: 분류 결과 B
export_graphviz로 시각화
예시)

# 시각화 모듈 불러오기
from sklearn.tree import export_graphviz
from IPython.display import Image
# 이미지 파일 만들기
export_graphviz(model, # 모델 이름
out_file='tree.dot', # 파일 이름
feature_names=x.columns, # Feature 이름
class_names=[' ',' '], # Target Class 이름
rounded=True, # 둥근 테두리
precision=2, # 불순도 소숫점 자리수
filled=True) # 박스 내부 채우기
# 파일 변환
!dot tree.dot -Tpng -otree.png -Gdpi=300
# 이미지 파일 표시
Image(filename='tree.png')변수 중요도
model.feature_imoprtances_ : DecisionTree를 생성하는데 중요했던 변수들의 비율을 수치로 나타내준다. 모든 값을 합치면 100%이다.
print(list(x))
print(model.feature_importances_)
# feature_importances_ 순서는 x의 df 컬럼 순으로 함께 출력해보았다.시각화
plt.barh(list(x), model.feature_importances_)
plt.show()Logistic Regression
독립 변수의 선형 결합을 이용하여 사건의 발생 가능성을 예측하는 데 사용되는 통계 기법
독립 변수의 선형 결합으로 종속 변수를 설명한다는 관점에서는 선형 회귀 분석과 유사하다. 하지만 로지스틱 회귀는 선형 회귀 분석과는 다르게 종속 변수가 범주형 데이터를 대상으로 하며 입력 데이터가 주어졌을 때 해당 데이터의 결과가 특정 분류로 나뉘다.
이항형 로지스틱 회귀: 범주형 갯수의 결과가 2개
다항 로지스틱 회귀: 범주형 갯수의 결과가 3개 이상 (위키백과)
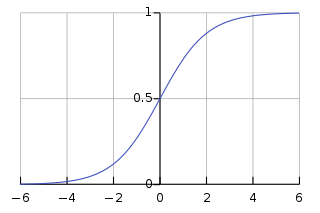
, e의 지수 f(x)는 ax +b 의 선형 판별식
- 시그모이드 함수라고도 한다
- 판별식 f(x)가 ∞ 이면 -∞이 되면서 0에 가까워져서 P는 1에 가까워진다.
- 판별식 f(x)가 -∞ 이면 ∞이 되면서 양의 무한대로 분모가 커지면서 P는 0에 가까워진다.
- (-∞, ∞) 범위를 갖는 선형 판별식 결과로 (0, 1) 범위의 확률 값을 얻게 된다. 0,1은 포함되지 않는다.
- 기본적으로 확률 값 0.5를 임계값(Threshold)로 하여 이보다 크면 1, 아니면 0으로 분류함
- 분류모델에만 사용 가능하다.
- Linear Regression처럼 회귀계수, feature modeling 의 의미가 크고 KNN알고리즘 만큼 정규화의 영향은 없다.
분류 모델 코드
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import confusion_matrix, classification_report
# 선언하기
model = LogisticRegression()
# 학습하기
model.fit(x_train, y_train)
# 예측하기
y_pred = model.predict(x_test)
# 평가하기
print(confusion_matrix(y_test, y_pred))
print(classification_report(y_test, y_pred))
# 예측 확률 확인
p = model.predict_proba(x_test)
# 범주형 갯수가 3개일 때 결과
array([[0.98, 0.02, 0. ],
[0.27, 0.72, 0. ],
[0.01, 0.87, 0.12],
[0.99, 0.01, 0. ],
[0. , 0.02, 0.98],
[0. , 0.59, 0.41],
[0. , 0.13, 0.87],
[0.96, 0.04, 0. ],
[0.97, 0.03, 0. ],
[0. , 0.03, 0.97]])
# 시그모이드 그래프 시각화
plt.plot(np.sort(p[:,0])) # 범주1
plt.plot(np.sort(p[:,1])) # 범주2
plt.plot(np.sort(p[:,2])) # 범주3