최근에 알고리즘 공부하면서 접하게 된 Stack과 Queue를
정리해 보려고 한다.
먼저 Stack을 알아보자!
Stack이란?
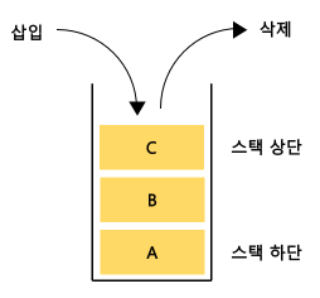
쌓아 올린다 즉 출입구가 하나인 형태의 자료구조 (LIFO last in first out)
장단점
- 구현이 쉽다
- top 을 통해 접근하기 때문에 데이터 접근, 삽입, 삭제가 빠르다.
- top 위치 이외의 데이터에 접근할 수 없기 때문에 탐색이 불가능하다.
- 데이터의 삽입과 삭제에 있어 매우 비효율적이다.
사용법
- push() - 데이터 삽입
- size() - 사이즈 반환
- empty() - 비어있는지 확인
- pop() - 제일 나중에 들어온 데이터 삭제
- top() - 제일 먼저 들어온 데이터 반환
시간 복잡도
최상위 데이터에 바로 접근이 가능하기 때문에 데이터 삽입, 삭제의 시간 복잡도는 O(1) 이다.
활용
- 재귀 알고리즘
- DFS 알고리즘
- 작업 실행 취소와 같은 역추적 작업이 필요할 때(웹 브라우저 뒤로가기)
- 괄호 검사, 후위 연산법, 문자열 역순 출력 등
다음은 Queue를 알아보자!!!
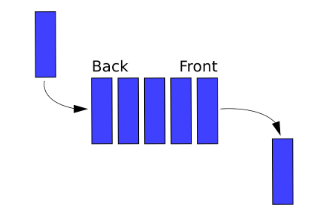
한쪽에서는 삽입만 이루어지고 다른 한쪽 끝에서는 삭제만 이루어지는 형태의 자료구조 (First In First Out)
장단점
- 데이터 접근, 삽입, 삭제가 빠르다.
- 큐의 앞 부분이 비어도 데이터를 삽입할 수 없다.
- 큐 역시 스택과 마찬가지로 중간에 위치한 데이터에 대한 접근이 불가능하다.
사용법
- push() - 데이터 삽입
- pop() - 최상위 데이터 삭제
- front() - 상위 데이터 반환
- back() - 마지막 데이터 반환
- empty() - 비어있는지확인
- size() - 현재 queue의 사이즈 반환,
시간 복잡도
큐도 데이터 삽입, 삭제가 바로 이루어지기 때문에 원소 삽입, 삭제의 시간 복잡도는 O(1) 이다.
활용
- 데이터를 입력된 순서대로 처리해야 할 때
- BFS 알고리즘
- 프로세스 관리
- 은행 창구(대기 순서 관리)

Slow and Steady