NLP Task
- Natural Language Processing and Natural Language Understanding
- Natural Language Processing
- Low-level parsing: Tokenization, Stemming (Keep word's mean except modifier)
- Word and Phrase level: Named entitiy recognition. part of speech tagging
⇒ Understanding proper noun or word's part of speech - Sentence level
- Multi-sentence & paragraph level: Understanding casual relationship of sentences
- Text mining: Extract useful information and insights from text
⇒ In SNS, used to analysis trend - Information retrieval: Search information from words or sentences
Bag of words
Bag of Words란?
딥러닝을 활용한 NLP Task 이전에 사용되던 단어 및 문장을 숫자로 나타내는 Word Vectorizing 방법
BoW Step
Step 1. Text Dataset에서 Unique한 Word를 모아서 하나의 Vocabulary를 생성한다. 이 때, 중복은 허용하지 않는다.
ex) “John really really loves this movie.”, “Jane really likes this song” 두개의 Text Dataset에서
{”John”, “really”, “loves”, “this”, “movie”, “Jane”, “likes”, “song”}의 Vocabulary 생성
Step 2. 각각의 단어를 하나의 Categorical Variable로 취급할 수 있고 이를 One-hot Vector로 변경
- Unique한 단어의 갯수만큼 Vector Dimension을 생성하고 단어에 대응되는 Dimension은 1 그 외의 Dimension은 0으로 표현한다.
- 임의의 두개의 단어에서, 유클리드 거리법을 통해 두 단어의 거리는 이고 cosine similarity(벡터 유사도)는 0으로 모두 서로 독립적이된다.
- 각 문장은 문장에 포함된 Word의 벡터들을 모두 더한 것으로 표현할 수 있으며, 이러한 표현법을 Bag of Word라고 부른다.
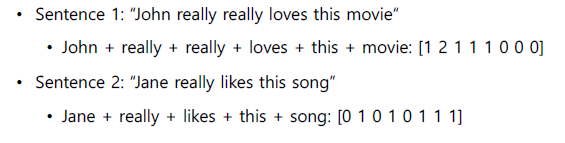
NaiveBayes Classifier
NaiveBayes Classifier란?
NaiveBayes Classifier는 Bag of Words로 나타내진 문장을 특정 Class(Label)로 분류할 수 있는 대표적인 분류기
NaiveBayes 방식
문서의 총 클래스 C가 존재할 때, 각각의 클래스 c에 해당 문서 d가 속할 조건부 확률로 문서를 분류

- 두번째 식에서 P(d)는 문서 d가 뽑힐 확률로 현재 d라는 문서가 고정된 하나의 문서로 볼 수 있기 때문에 P(d)는 상수취급되어 계산식에서 제거가 가능하다.
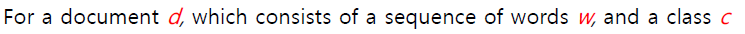
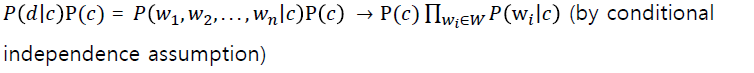
- : Probability of word from predicted sentence can be appeared in class
예시
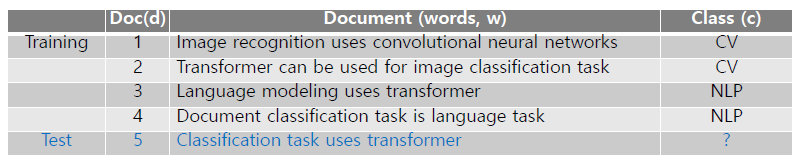
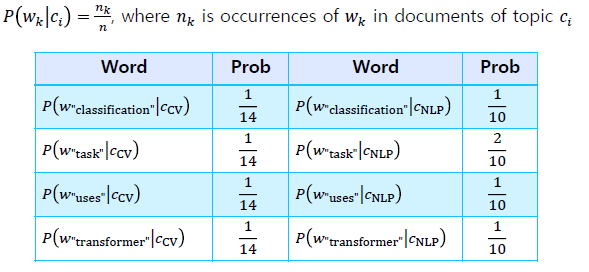
- = = = =
- 는 해당 Class에 속한 문장들의 총 단어 갯수에서 해당 word가 발견될 확률을 의미한다. ⇒ CV Class에서 “classification”이란 단어는 14개의 단어중에서 1번만 등장하므로
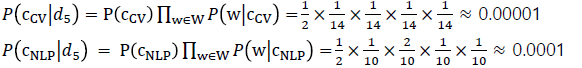
- Test Dataset()는 NLP Class에 속할 확률이 높기 때문에 NLP Class로 분류
- 이 때, 만약 하나의 문장에서 다른 단어들이 Class에서 발견될 확률이 아무리 높다고 하더라도 하나의 단어가 해당 Class에 전혀 등장을 하지 않으면 해당 클래스에 속할 확률은 0이되는 한계를 가지고 있다.
Code 실습 - NaiveBayes Classifier Implement
Import Necessary Package
# 한국어의 형태소 분석 등 복잡한 한글 구조를 간결한 정보로 처리할 수 있는 Module
$ pip install konlpy
from tqdm import tqdm
from collections import defaultdict
import math
# 다양한 한국어 형태소 분석기가 클래스로 구현되어 있음
from konlpy import tag Dataset Preprocessing
Class TrainDataset:
train_data = [
"정말 맛있습니다. 추천합니다.",
"기대했던 것보단 별로였네요.",
"다 좋은데 가격이 너무 비싸서 다시 가고 싶다는 생각이 안 드네요.",
"완전 최고입니다! 재방문 의사 있습니다.",
"음식도 서비스도 다 만족스러웠습니다.",
"위생 상태가 좀 별로였습니다. 좀 더 개선되기를 바랍니다.",
"맛도 좋았고 직원분들 서비스도 너무 친절했습니다.",
"기념일에 방문했는데 음식도 분위기도 서비스도 다 좋았습니다.",
"전반적으로 음식이 너무 짰습니다. 저는 별로였네요.",
"위생에 조금 더 신경 썼으면 좋겠습니다. 조금 불쾌했습니다."
]
train_labels = [1, 0, 0, 1, 1, 0, 1, 1, 0, 0]
Class TestDataset:
test_data = [
"정말 좋았습니다. 또 가고 싶네요.",
"별로였습니다. 되도록 가지 마세요.",
"다른 분들께도 추천드릴 수 있을 만큼 만족했습니다.",
"서비스가 좀 더 개선되었으면 좋겠습니다. 기분이 좀 나빴습니다."
]
def make_tokenized(data):
# KoNLPy Package에 있는 Okt Tokenizer를 사용하여 Word tokenization
tokenizer = tag.Okt()
# Sentence를 단어 단위로 나눈 List들을 저장하는 List
tokenized = []
for sentence in tqdm(data):
# Sentence를 Tokenization하여 Word의 List로 반환
tokens = tokenizer.morphs(sentence)
tokenized.append(tokens)- Train data set은 sentence sequence data와 각 Sentence가 긍정(1) 혹은 부정(0)인지를 나타내는 2가지 Class로 구성된 Binary Classification dataset이다.
print(train_tokenized[:2}
# ---print---
# [['정말', '맛있습니다', '.', '추천', '합니다', '.'], ['기대했던', '것', '보단', '별로', '였네요', '.']]- Tokenization의 결과를 출력해보니 '것'과 '보단'이 분리되는 것처럼 각각의 의미를 가지는 단어들을 잘 분리하는 것 같다.
def wordToIndex():
word_count = defaultdict(int) # Key: 단어, Value: 등장 횟수
# List로 구성된 Tokenized Sentence들 ex) tokens = ['정말', '맛있습니다', '.', '추천', '합니다', '.']
for tokens in tqdm(train_tokenized):
# Tokenized Sentence에서 하나의 word들 ex) token = '정말'
for token in tokens:
# Key가 없으면 Key를 추가해주고 대응하는 Value는 1, Key가 있으면 Value에 +1을 해주면서 word frequency counting
word_count[token] += 1
# Dictionary의 value값이 큰(가장 빈도수가 높은 단어) key를 순서대로 vocabulary에 정렬
word_count = sorted(word_count.items(), key=lambda x: x[1], reverse=True)
w2i = {} # dict type(key: word, value: index)
for pair in tpdm(word_count)
# 만약 w2i dictionary에 pair에 해당하는 word가 없을 경우
if pair[0] not in w2i:
# len이 0부터 word가 하나씩 추가될 때마다 늘어나기 때문에 index로 사용
w2i[pair[0]] = len(w2i)- w2i dictionary는 {'!': 35, '.': 0, '가': 41, '가격': 23, '가고': 26, '개선': 43, '것': 20,...} 이러한 형태의 dictionary로 구성됨. 이 때, key는 word이고 value는 index, 가장 frequency가 높은 단어가 인덱스가 제일 작음.
NaiveBayesClassifier
class NaiveBayesClassifier():
def __init__(self, w2i, k=0.1):
"""
self.k: Smoothing을 위한 상수.
self.w2i: 사전에 구한 vocab.
self.priors: 각 class의 prior 확률.
self.likelihoods: 각 token의 특정 class 조건 내에서의 likelihood.
"""
self.k = k
self.w2i = w2i
self.priors = {}
self.likelihoods = {}
def train(self, train_tokenized, train_labels):
# Tokenized train dataset을 사용하여 priors를 계산
self.set_priors(train_tokenized)
self.set_likelihoods(train_tokenized, train_labels)
def inference(self, tokens):
# Token이 0(부정)을 의미할 확률
log_prob0 = 0.0
# Token이 1(긍정)을 의미할 확률
log_prob1 = 0.0
for token in tokens:
# 학습 당시에 추가했던 단어들만 likelyhoods를 고려한다.
if token in self.likelyhoods:
log_prob0 += math.log(self.likelihoods[token][0])
log_prob1 += math.log(self.likelihoods[token][1])
# Priority를 고려하여 더해준다.
log_prob0 += math.log(self.priors[0])
log_prob1 += math.log(self.priors[1])
if log_prob0 >= log_prob1:
return 0
else:
return 1
# label의 분포에 따라 부여되는 가중치
def set_priors(self, train_labels):
class_counts = defaultdict(int)
for label in tqdm(train_labels):
class_count[label] += 1
for label, count in class_counts.items():
self.priors[label] = class_counts[label] / len(train_labels)
def set_likelihoods(self, train_tokenized, train_labels):
token_dists = {} # 각 word의 특정 class(여기서는 0 or 1) 조건 하에서의 등장 횟수
class_counts = defaultdict(int) # 특정 class에서 등장한 모든 단어의 등장 횟수
# Train label에 index를 주어 반복문 진행
for i, label in enumerate(tqdm(train_labels)):
count = 0
for token in train_tokenized[i]:
if token in self.w2i: # 학습 데이터로 구축한 vocab에 있는 token만 고려, 모든 단어가 vocab을 만들 때 포함되는 건 아님
if token not in token_dists:
token_dists[token] = {0:0, 1:0}
# Token이 등장한 문장의 label에 등장 횟수를 1 더해준다.
token_dists[token][label] += 1
count += 1
class_counts[label] += count
for token, dist in tqdm(token_dists.items()):
if token not in self.likelihoods:
self.likelihoods[token] = {
0:(token_dists[token][0] + self.k) / (class_counts[0] + len(self.w2i)*self.k),
1:(token_dists[token][1] + self.k) / (class_counts[1] + len(self.w2i)*self.k),
}- Likelihood: 해당 token이 특정 Class에서 속할 Probability
⇒ 특정 class에 token이 나타난 횟수 / 특정 class의 전체 token의 수 - 문장의 class를 예측할 때, 특정 단어가 특정 Class에 한 번도 나오지 않게 되면 다른 단어들의
확률과 상관없이 항상 0으로 나오기 때문에 제대로 된 분류가 불가능하다.
⇒ 이 문제를 해결하기 위해 likelihood를 계산할 때 분자에 smoothing value를 분모에 전체 길이 * smoothing value를 더하게 된다
The Zero Frequency Problem
Train and Inference
classifier = NaiveBayesClassifier(w2i)
classifier.train(train_tokenized, train_labels)
preds = []
for test_tokens in tqdm(test_tokenized):
pred = classifier.inference(test_tokens)
preds.append(pred)
for i in range(len(preds)):
print(test_data[i], preds[i], sep=' Predicted Class:')Result
정말 좋았습니다. 또 가고 싶네요. Predicted Class:1
별로였습니다. 되도록 가지 마세요. Predicted Class:0
다른 분들께도 추천드릴 수 있을 만큼 만족했습니다. Predicted Class:1
서비스가 좀 더 개선되었으면 좋겠습니다. 기분이 좀 나빴습니다. Predicted Class:0
- 주어진 Test dataset은 예측을 굉장히 잘한 것 같다. Test dataset이 문장이 꼬여있지 않고 긍정적인 단어와 부정적인 단어들로만 이루어져 있기 때문인 것 같다.
test_sentence = [
"대체로 좋았지만, 서비스가 별로였습니다. 추천하지 않습니다.",
"맛은 있지만 가격이 비쌌습니다. 가성비가 좋지 않습니다.",
"비싼 느낌이 있지만 좋았습니다."
]
test_token = make_tokenized(test_sentence)
preds = []
for test in tqdm(test_token):
pred = classifier.inference(test)
preds.append(pred)
for i in range(len(preds)):
print(test_sentence[i], preds[i], sep=' Predicted Class:')- 문장을 살짝 꼬아서 Test를 진행해보았는데, 1번과 2번은 모두 부정으로 잘 예측했지만 3번은 긍정으로 예측해야할 리뷰를 부정으로 인식하였다.
이유를 생각해보자면 문장에 각각 긍정과 부정의 단어가 1개씩 존재하는데 위에서 log probability를 통해 Class를 예측하게 되는데 probability가 같으면 0으로 예측하도록 돼있다. - 즉, 문맥을 파악하여 예측하는 것이 아닌 갯수와 확률로 예측하다보니 잘못 예측하는 경우가 있다고 생각된다.

Beginner_of_AI_Engineer