검색 품질 향상을 위한 동의어 활용
이전 게시물에서 알 수 있듯이 Elasticsearch를 사용하면 역색인 처리로 매우 빠른 검색이 가능하다는 것을 확인할 수 있었습니다. 그런데 Elasticsearch의 또 다른 장점 중 하나는 텍스트를 여러 단어로 변형하거나 텍스트의 특징을 이용한 동의어나 유의어를 활용한 검색이 가능한 것입니다.
즉, 원문에 특정 단어가 존재하지 않더라도 색인 데이터를 토큰화해서 저장할 때 동의어나 유의어에 해당하는 단어를 함께 저장해서 검색이 가능하도록 만드는 기술입니다.
역색인
키워드를 통해 문서를 찾아내는 방식, 책에서 맨 뒤에 나와 있는 찾아 보기
동의어를 추가하는 방법
동의어를 매핑 설정 정보에 미리 파라미터로 등록하는 방식
PUT my_synonym
{
"mappings": {
"properties": {
"my_field": {
"type": "text",
"analyzer": "my_analyzer"
}
}
},
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"tokenizer": "standard",
"filter": ["lowercase", "my_synonyms"]
}
},
"filter": {
"my_synonyms": {
"type": "synonym",
"synonyms": [
"coke, coca-cola => cola"
]
}
}
}
}
}
다음과 같이 필터를 만들어 "coke, coca-cola => cola"처럼 "coke, coca-cola" "cola"라는 동의어를 등록한것입니다.
특정 파일을 별도로 생성해서 관리하는 방식
es.indices.create(
index='dictionary',
body={
"settings": {
"index": {
"analysis": {
"analyzer": {
"nori_token": {
"type": "custom",
"tokenizer": "nori_tokenizer",
"filter": ["my_synonyms"]
}
},
"filter": {
"my_synonyms": {
"type": "synonym",
"synonyms_path": "synonym.txt"
}
}
}
}
},
"mappings": {
"properties": {
"id": {
"type": "integer",
},
"class_name": {
"type": "text",
"analyzer": "nori_token"
},
"price": {
"type": "integer",
},
"img_url": {
"type": "text",
},
"analyze": {
"type": "keyword"
}
}
}
}
)검색엔진에서 다루는 분야가 많아지면 많아질수록 동의어의 수도 늘어납니다. 분야별로 파일도 늘어날 것이고 그 안의 동의어 변환 규칙도 많아질 것입니다. 실무에서는 이러한 동의어를 모아둔 파일들을 칭할 때 일반적으로 "동의어 사전"이라는 용어를 사용한다고합니다. 따라서 저는 다음과 같이 synonym.txt이라는 동의어 사전을 등록하였습니다.
동의어 사전
동의어 추가
초콜릿, 페레로로쉐, 초코칩, 제티, 빠삐꼬, 허쉬드링크
다음과 같이 synonym.txt파일에 작성한다면 각각의 단어 모두 서로의 검색어로 검색이 됩니다.
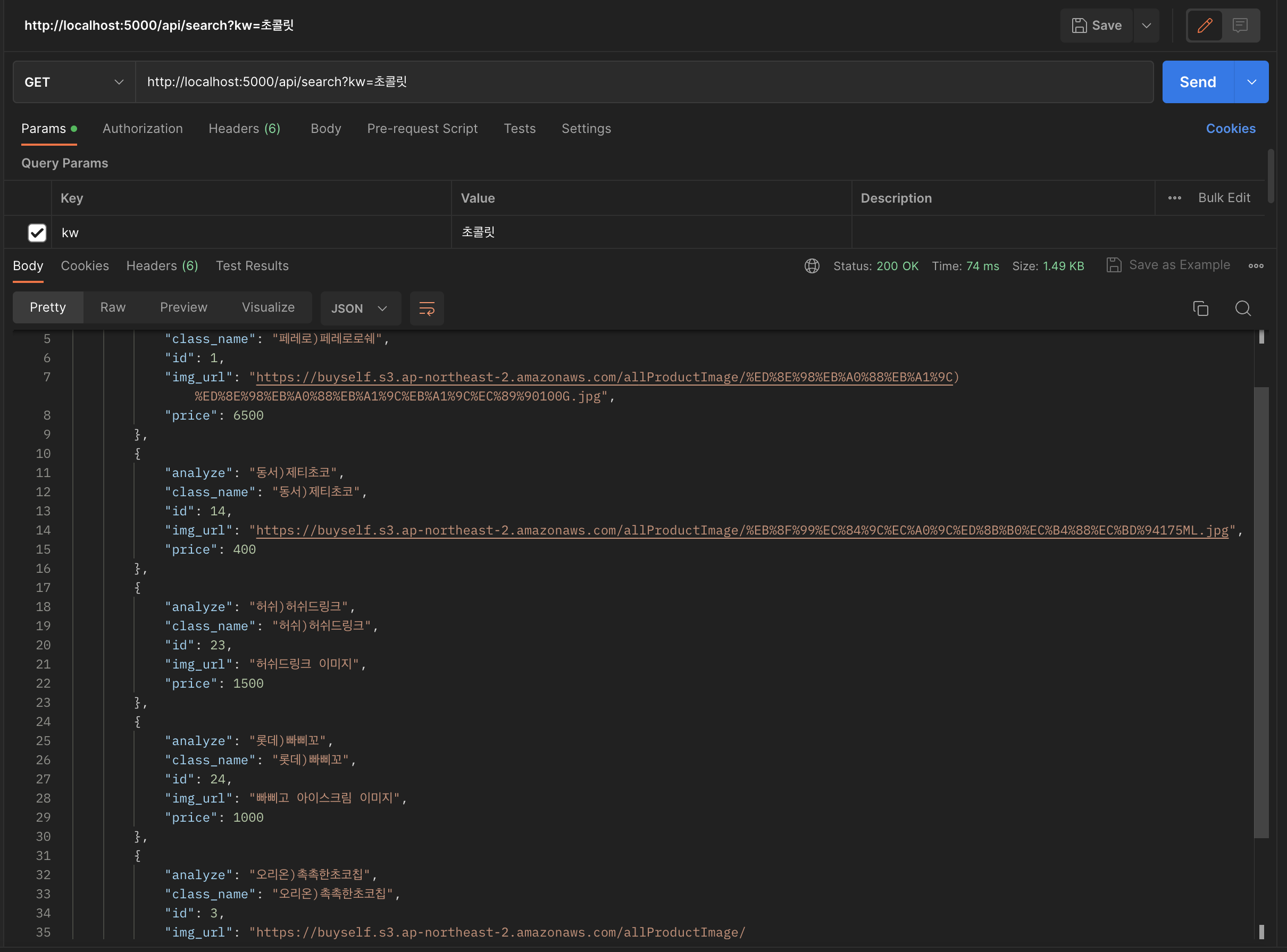 Elasticsearch에는 초콜릿이라는 상품명을 가진 데이터를 가지고 있지 않지만 동의어 사전 덕분에 초콜릿과 관련된 상품을 등록해 검색 품질을 향상시킬 수 있었습니다.
Elasticsearch에는 초콜릿이라는 상품명을 가진 데이터를 가지고 있지 않지만 동의어 사전 덕분에 초콜릿과 관련된 상품을 등록해 검색 품질을 향상시킬 수 있었습니다.
동의어 치환
jelly => 젤리를 동의어 사전에 등록해보았습니다.
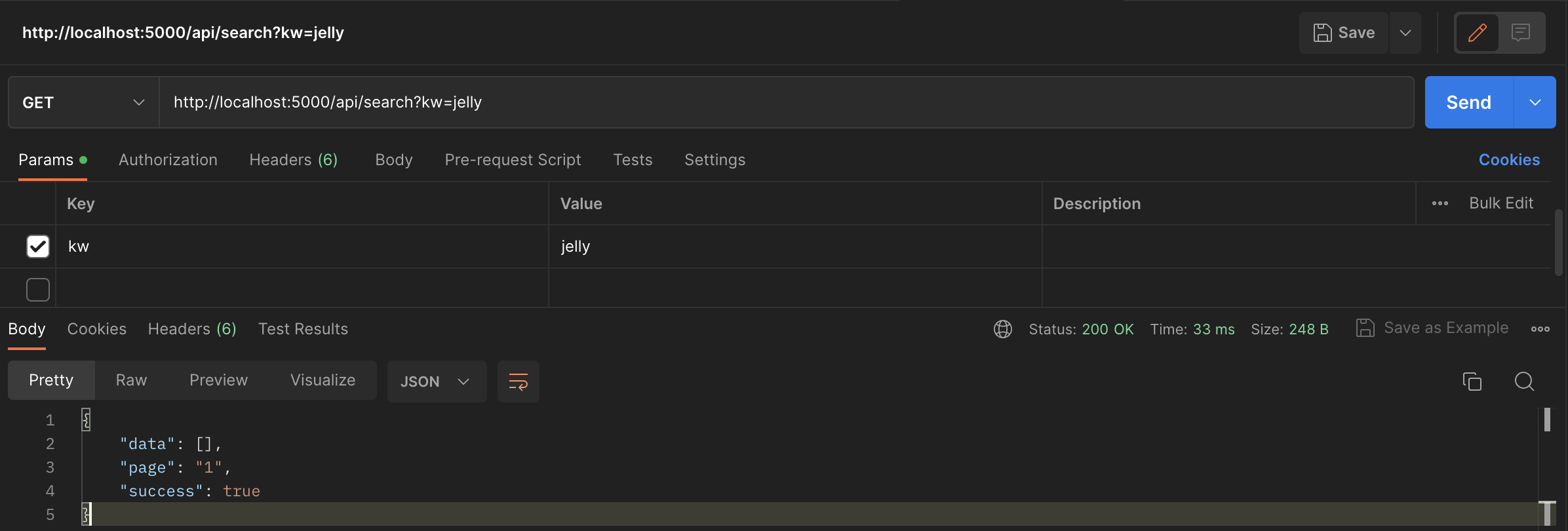
'jelly'로 검색하면 '젤리'라는 검색어로 치환되어 응답될 줄 알았는데 아무런 데이터를 반환해주지 않았습니다. 분명 인덱스에는 상품명이 롯데)마이구미 젤리인 데이터가 있습니다!!
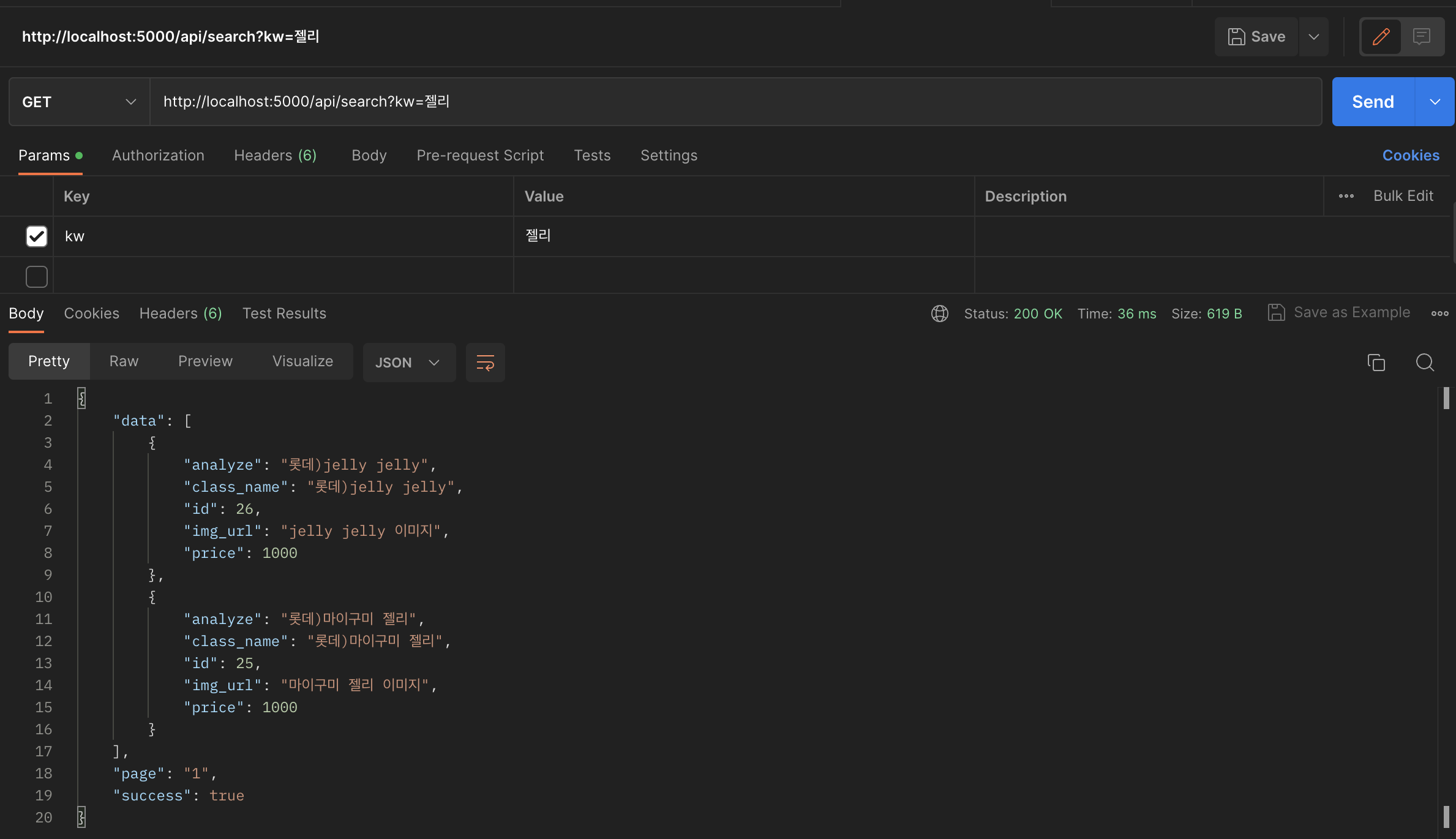
'젤리'로 검색을 하니 'jelly', '젤리'를 가진 두 상품 모두 잘 응답이 되었습니다!!
term 쿼리
search_body = {
"query": {
"term": {
"class_name": str(kw)
}
},
"from": (page - 1) * size,
"size": size
}term 쿼리는 검색어에 analyzer를 적용하지 않고 그대로 검색하기 때문에 term 쿼리로 '젤리'를 검색하면 두 개의 도큐먼트가 모두 검색되고 'jelly'을 검색하면 검색이 되지 않습니다.
match 쿼리
match 쿼리는 검색어 'jelly'도 analyzer가 적용이 되어 '젤리'로 변환하여 검색을 하기 때문에 '젤리'로 검색을 한 것과 같은 결과가 나타납니다.
search_body = {
"query": {
"bool": {
"must": [
{
"match": {
"class_name": {
"query": str(kw),
"analyzer": "nori_token"
}
}
}
]
}
},
"from": (page - 1) * size,
"size": size
}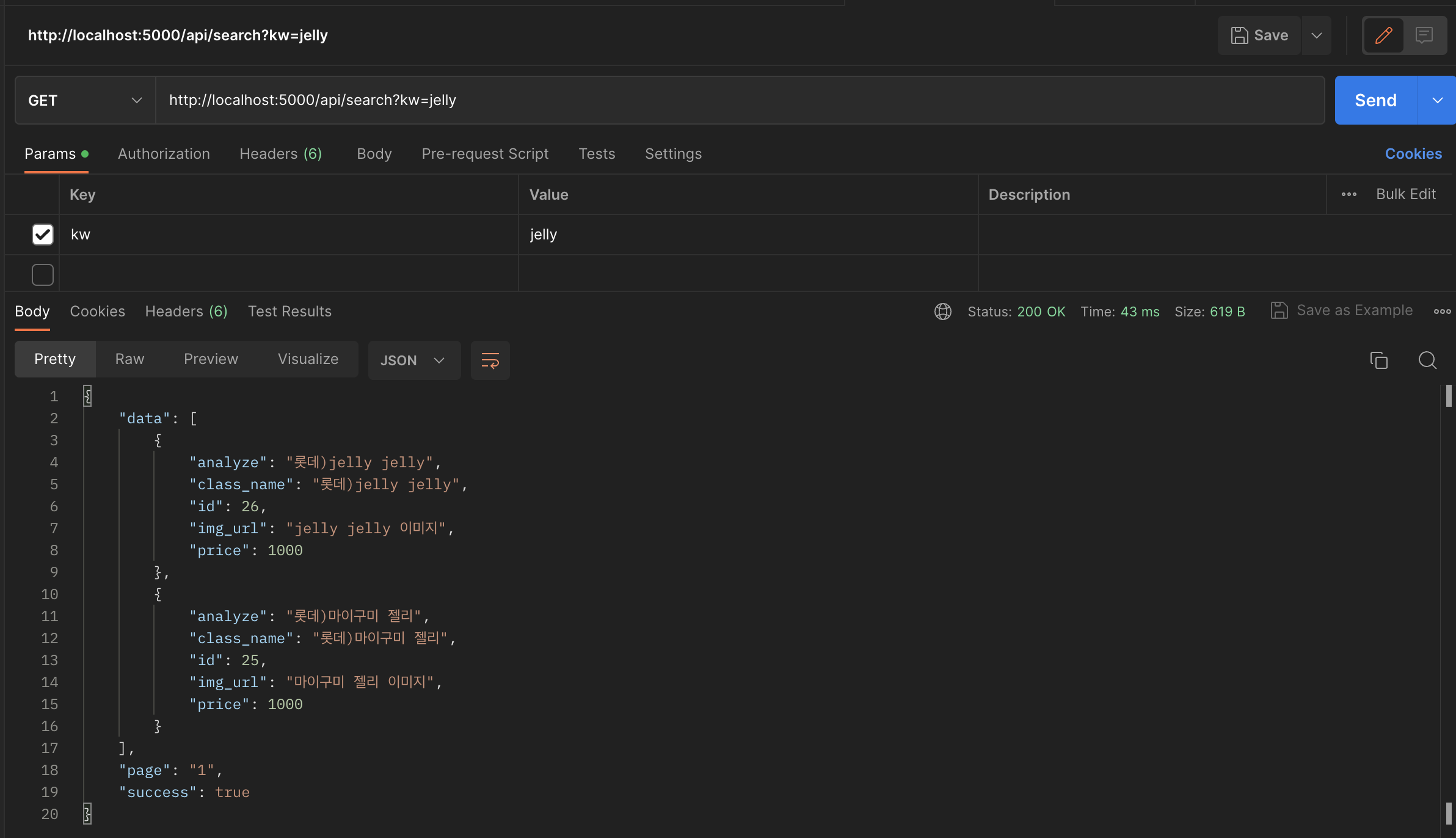
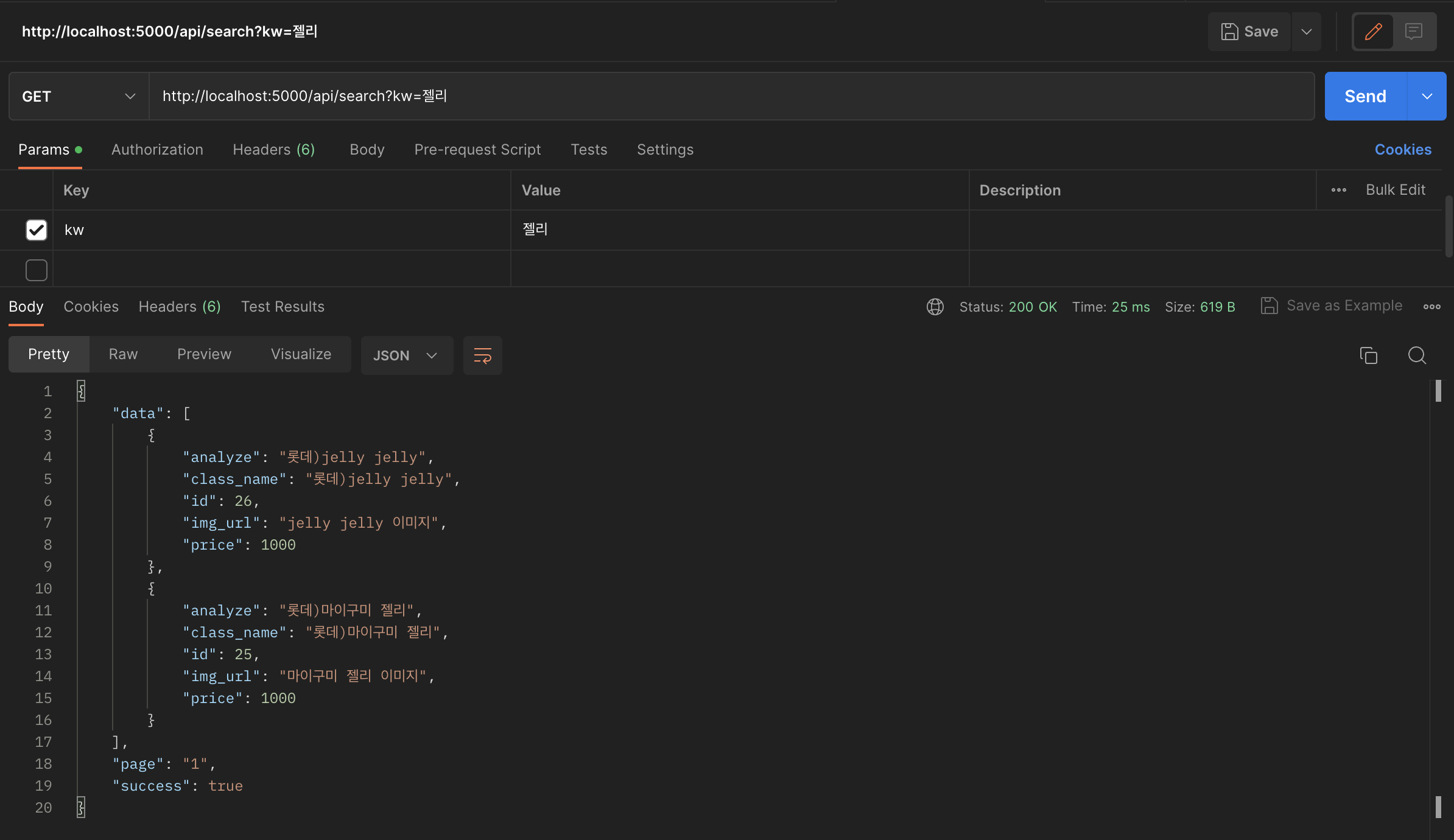
다음과 같이 'jelly'로 검색을 하든 '젤리'로 검색을 하든 결과가 같습니다.
즉, term 쿼리 '젤리' 검색 == match 쿼리 '젤리' 검색
검색 시점, 색인 시점 동이어 사전 필터 적용
색인시점
단점
-
새로운 동의어 추가가 어려움: 이미 인덱스에 색인된 문서들은 변경할 수 없으므로, 동의어 사전을 새롭게 추가하거나 수정하는 경우에는 해당 인덱스를 재색인해야 합니다.
-
동의어 충돌 문제: 예를 들어, "배"라는 단어가 "사과"와 "선반" 두 개의 동의어로 등록되어 있다고 가정해 봅시다. 그런데 "사과 선반"이라는 문장이 있다면, 이 문장에서 "배"가 "사과"인지 "선반"인지 알 수 없기 때문에 검색 결과가 이상하게 나올 수 있습니다.
검색시점
-
동적인 동의어 처리: 검색 시점에 동의어 사전 필터를 적용하면, 동적으로 동의어를 추가하거나 변경할 수 있습니다. 즉 동의어 규칙이 수정되더라도 문서를 재색인 할 필요가 없습니다.
-
적은 인덱스 용량: 색인 시점에 동의어 사전 필터를 적용하면, 동의어가 많아질수록 인덱스 용량이 커집니다. 하지만 검색 시점에 동의어 사전 필터를 적용하면, 동의어 사전을 별도로 관리하므로 인덱스 용량이 작아집니다.
-
유연한 적용: 검색 시점에 동의어 사전 필터를 적용하면, 동의어를 적용하고 싶은 필드나 검색 쿼리에만 적용할 수 있습니다. 따라서 필요한 경우에만 동의어 사전을 적용할 수 있습니다.
search_body = {
"query": {
"bool": {
"must": [
{
"match": {
"class_name": {
"query": str(kw),
"analyzer": "nori_token"
}
}
}
]
}
},
"from": (page - 1) * size,
"size": size
}따라서 다음과 같이 검색 시점에 anlyzer를 적용시켰습니다.
정리
- Elasticsearch를 이용하여 동의어 사전을 필터링 하면 검색 품질을 향상 시킬 수 있었습니다.
- 색인 시점보단 검색 시점에서 동의어 사전을 적용시키는 것이 많은 문제를 감소 시킵니다.
잘못된 정보가 있다면 알려주신다면 감사하겠습니다^^
참고 : 동의어 사전 // synonym - elasticsearch 가이드북
