데이터베이스에는 50만 데이터가 있습니다.
상품 검색 API의 latency를 줄이고 Vus를 늘리게된 성능개선을, k6를 통해 확인한 기록일지입니다. k6로 부하테스트를 쓴 이유와 각 테스트의 목적에 대해서는 이전글(전체 데이터 조회 성능 테스트 기록)을 참고하시면 될 것 같습니다.
ilike연산자
상품 데이터를 검색하기 위한 검색 API를 구현하기 위해 다음과 같이 ilike연산으로 조회를 하도록 했습니다. ilike 연산자는 like연산자와 달리 대소문자를 구분하지 않고 문자열을 비교하는 연산자입니다. 검색 시 한 페이지당 최대 80개의 데이터가 응답됩니다.
search = '%%{}%%'.format(kw)
pagination = Products.query.filter(Products.class_name.ilike(search))
.paginate(page=page, per_page=80, error_out=False)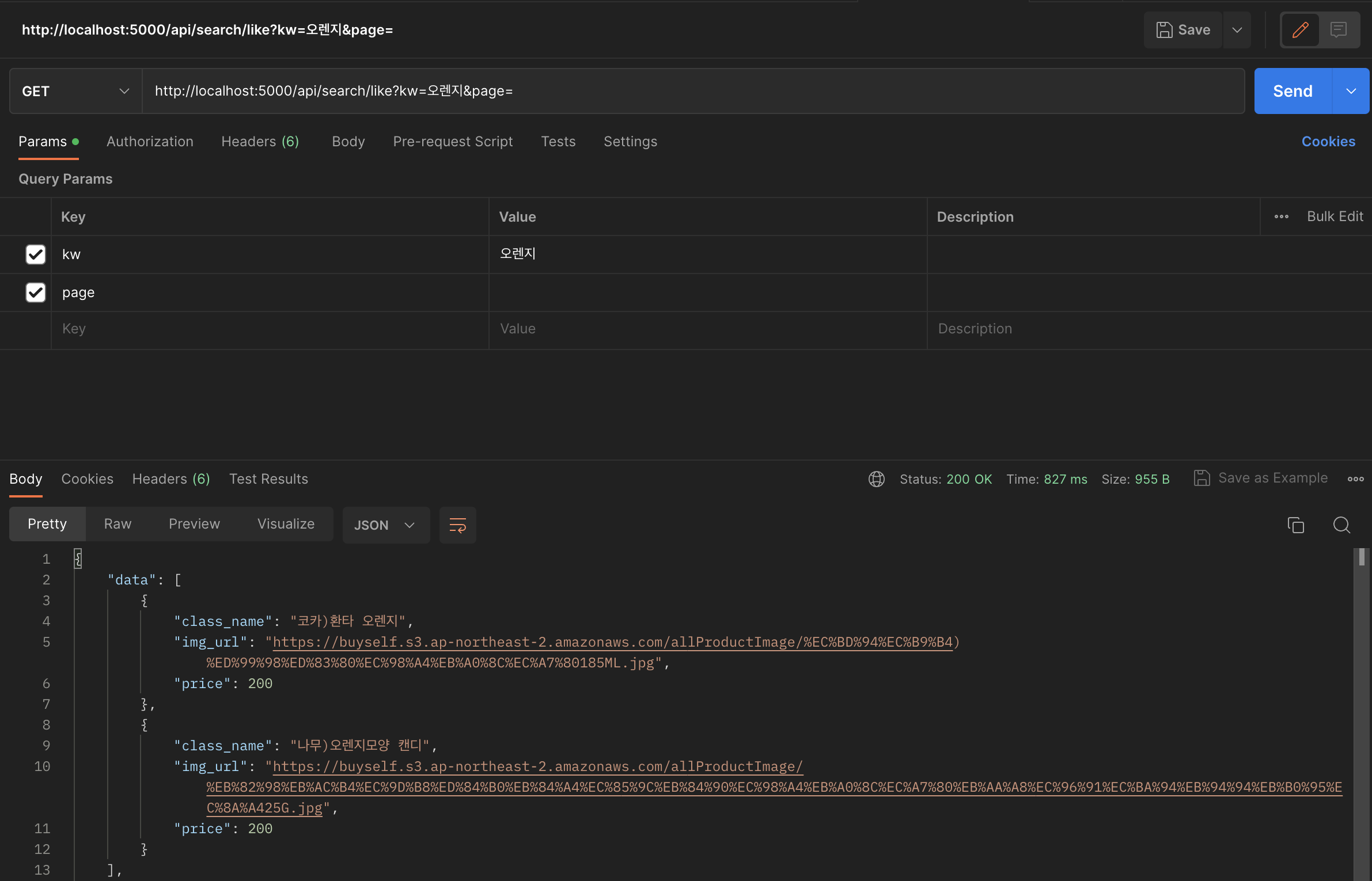
한글로 검색했을 때는 평균 827ms, 영어로 검색했을 때는 567ms 정도가 나왔습니다. latency은 측정할 때마다 더 오래걸릴 때도 많았습니다.
대부분의 한글 문자는 UTF-8 인코딩에서 3바이트를 사용하고, 영어 문자는 1바이트를 사용합니다. 이로 인해 한글 문자열을 검색할 때는 더 많은 데이터를 처리해야 하므로 응답 속도가 느릴 수 있습니다.
ilike연산자 + index
검색의 조회 속도를 높이기 위해 상품명 컬럼에 index를 생성해 보았습니다.
상품명 컬럼은 insert / update / delete 가 상대적으로 자주 발생하지 않는 컬럼임으로 데이터베이스가 페이지 분할과 사용안함 표시로 인덱스의 조각화가 심해져 성능이 저하되는 일(데이터베이스 성능 이슈)이 잘 없다고 생각했습니다. 50만 데이터가 들어있는 규모가 작지 않은 테이블이라 인덱스의 성능을 볼 수 있을 것이라고 생각했습니다.
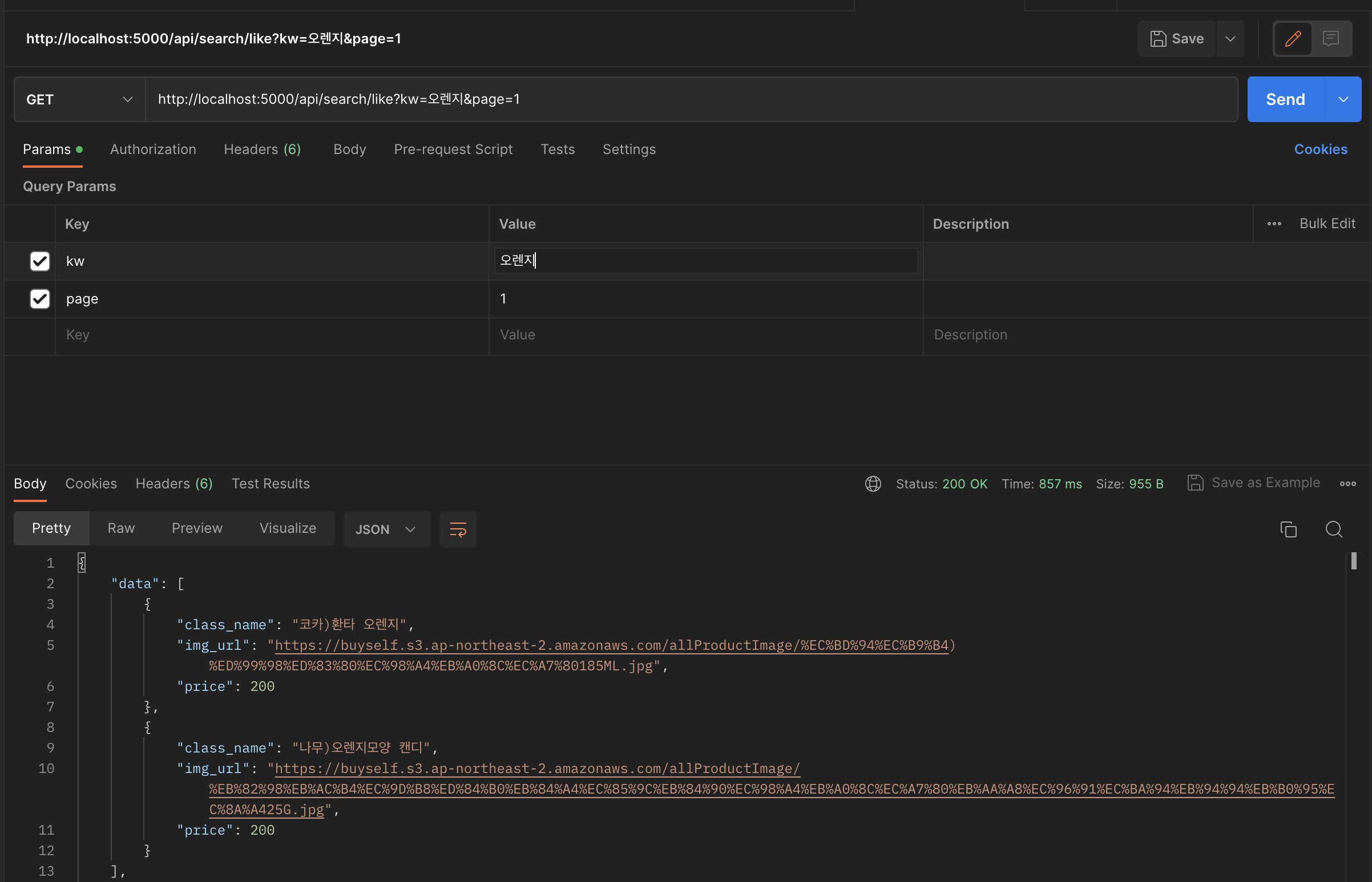
그러나 인덱스의 효과는 미미했습니다. 대부분 latency가 800ms 이상으로 측정되었습니다.
이때 저는 '아 그냥 인덱스가 적용되어도 데이터가 너무 많아서 인덱스의 효과를 보지 못하나 보다.'라고만 생각하고 그냥 넘어가 버렸습니다. 정확한 이유를 한 번 살펴보았습니다.
search = '%%{}%%'.format(kw) pagination = Products.query.filter(Products.class_name.ilike(search)) .paginate(page=page, per_page=80, error_out=False)다음 코드는 mysql native query 이런식으로 변경이 됩니다.
SELECT * FROM products WHERE lower(products.class_name) LIKE lower('%1111%')orm이 select 문에서는 사실 테이블 속성들에 'AS' 키워드로 별칭이 붙여 조회가 되지만 너무 길어 * 로 하겠습니다. 만약에 '1111'이라는 키워드로 검색하면 다음과 같은 query문이 됩니다.
explain 키워드로 실행계획을 보면 class_name 속성에 index가 생성이 되어도 type이 ALL인 full scan을 하는 것을 확인해 볼 수 있었습니다. 대체 왜 index를 사용하지 않는 것 일까요?

이유는 주어진 LIKE 절의 패턴 때문입니다. 패턴이 와일드카드 %를 가지고 있기 때문에 인덱스를 활용하는 것이 어려울 수 있습니다. 이는 와일드카드 %를 만족하는 모든 값들을 찾아야 하기 때문입니다. 따라서 데이터베이스 시스템은 모든 인덱스 항목을 확인해야 하기 때문에 전체 스캔을 수행하는 것이 더 효율적일 수 있어 Full scan을 하는 듯이 보입니다.
ilike연산자 + index + cache
cache.get(str((kw, page)))다음과 같이 검색어와 page 번호를 cache의 키 값으로 설정하여 latency를 줄이고자 했습니다. (이때 page의 default값은 1입니다.)
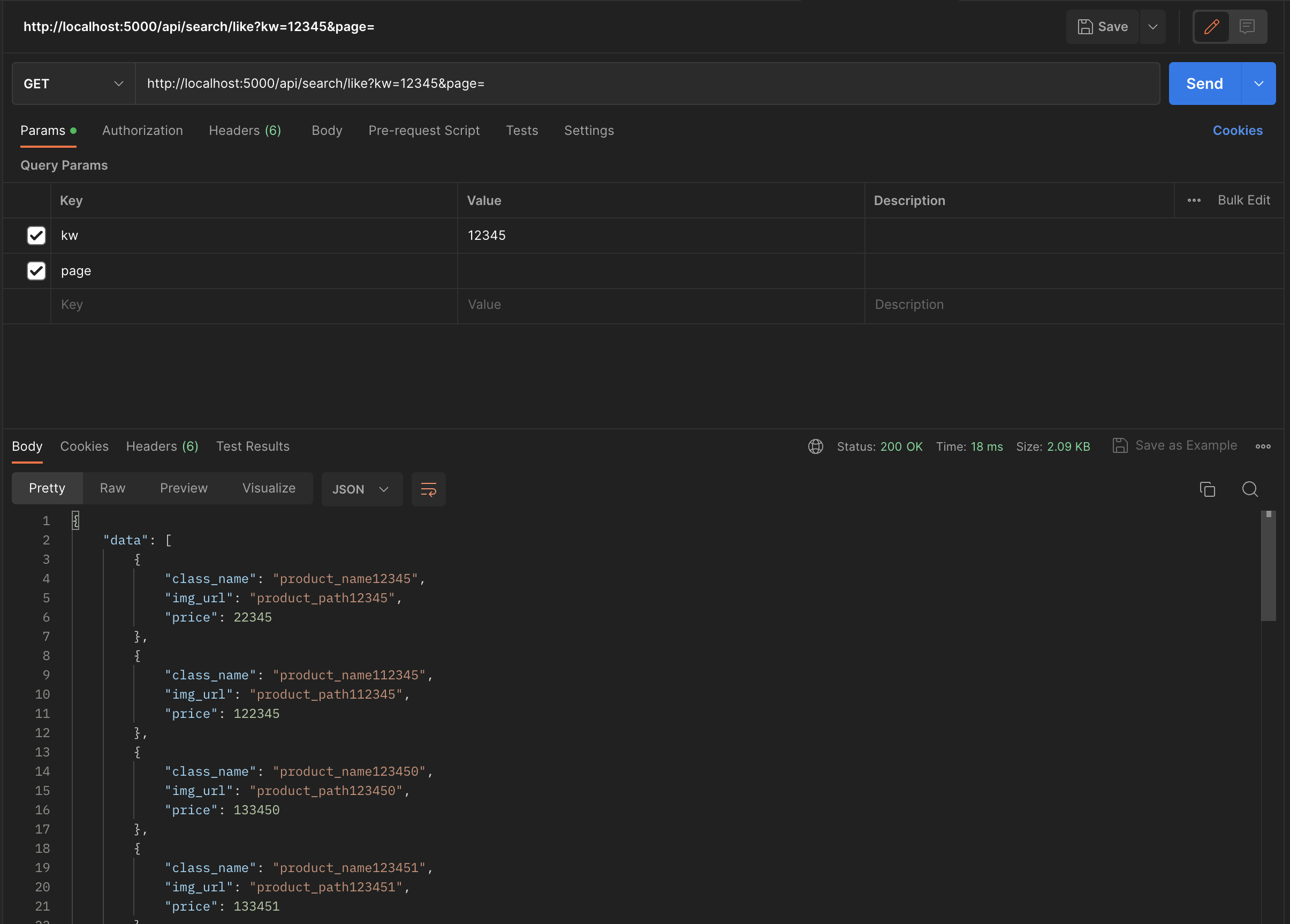
캐시에 데이터가 없을 때(첫 요청)는 latency가 800ms가 나왔지만 캐시 메모리에 저장되니 응답 latency의 속도는 18ms로 굉장히 빨랐습니다.
K6 성능테스트
데이터 베이스에는 상품 더미 데이터의 이름이 product_name100, product_name101… product_name500001으로 되어있습니다.
let kw = Math.floor(Math.random() * 200) + 100;
let res = http.get(`http://localhost:5000/api/search/like?kw=${kw}&page=${1}`);검색어에 100~299의 랜덤 숫자가 들어가고 데이터들의 첫 페이지를 응답하여 테스트를 진행하였습니다.
Smoke Testing
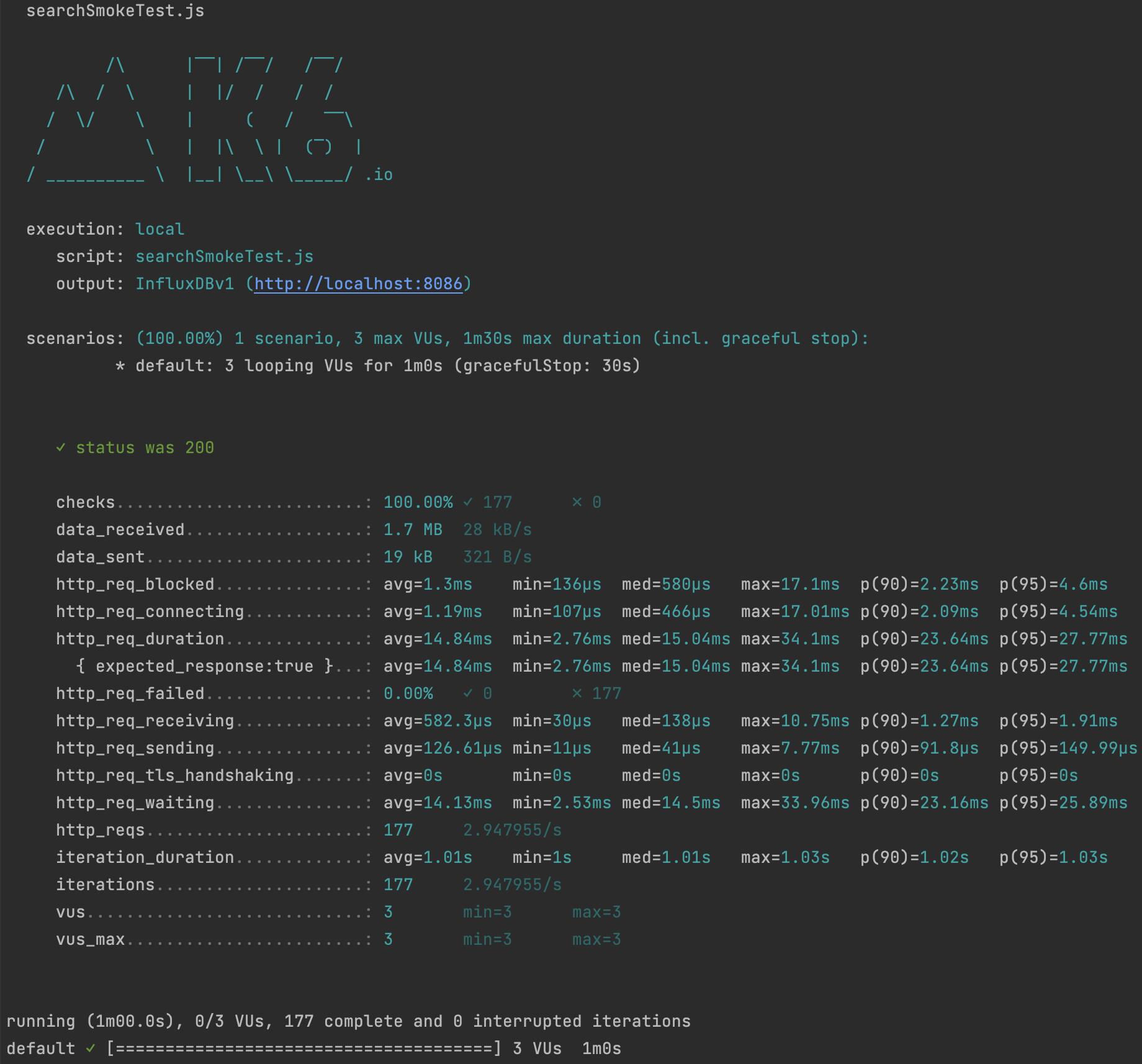
Load Testing
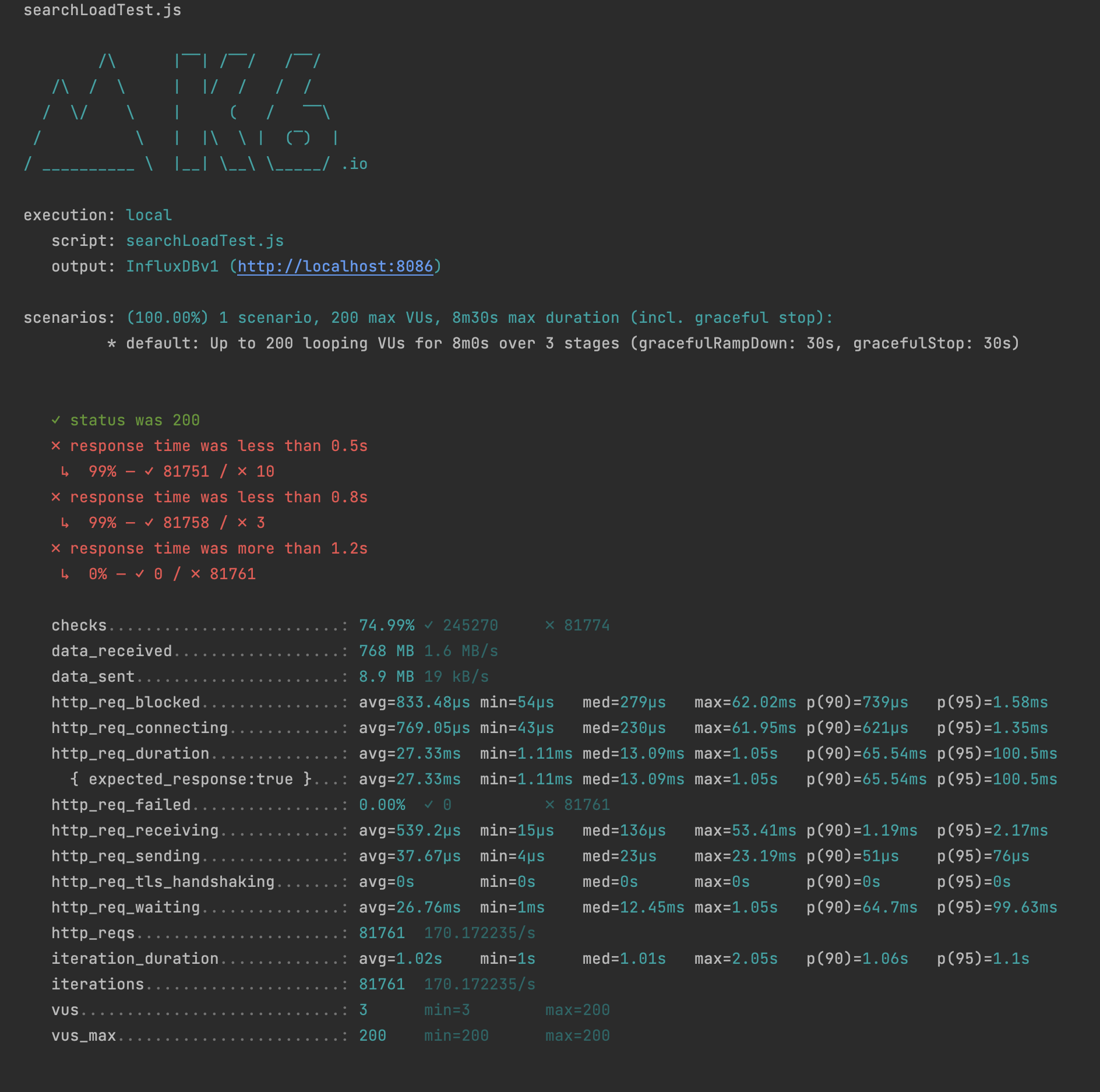
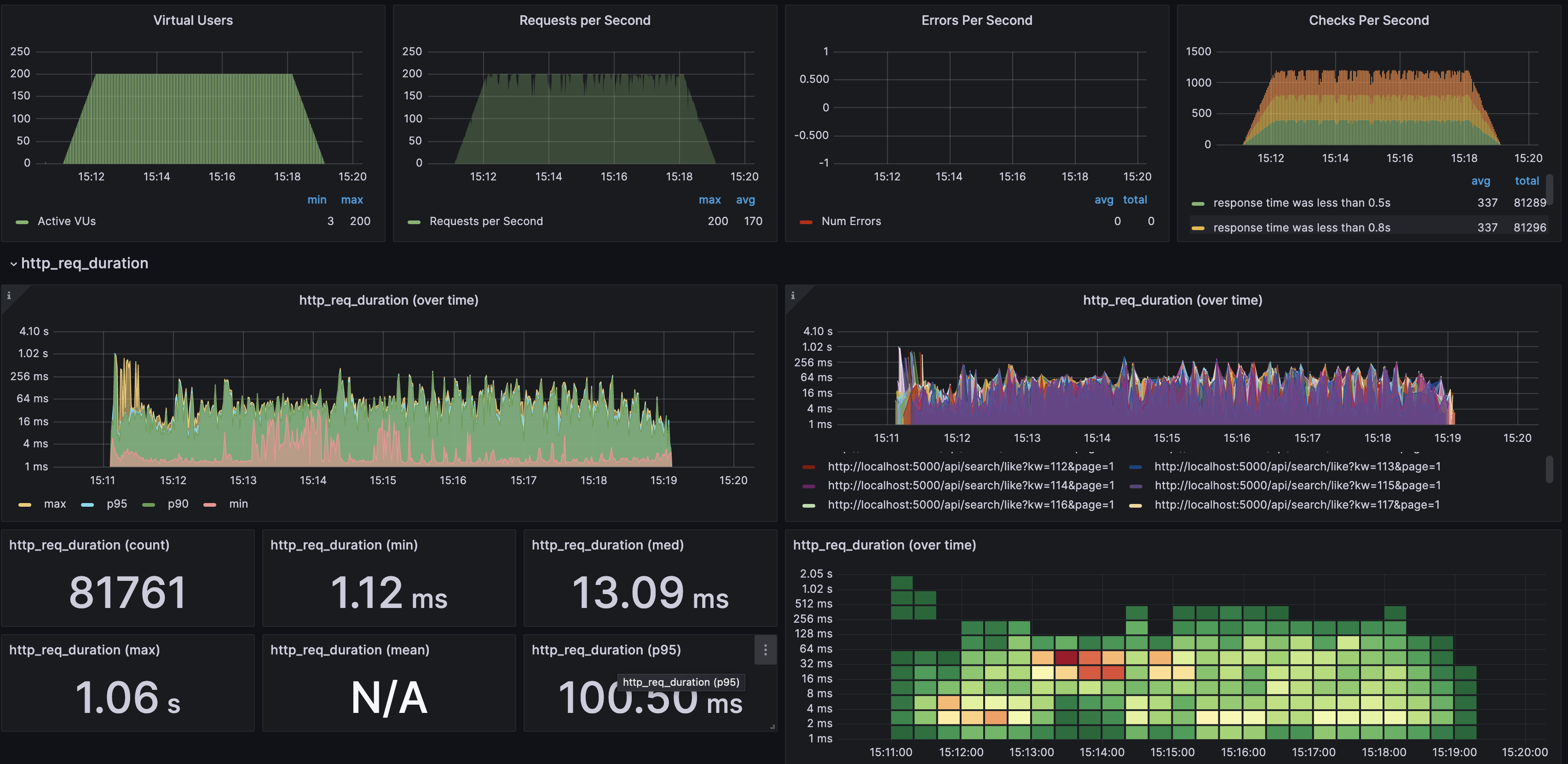
검색어를 100~299를 랜덤하게 생성해 검색을 했을 때 첫 페이지만 반환하도록 하고 200Vus를 유지 했을 때 0.5s 이하 latency가 99% 였습니다.
Stress Testing
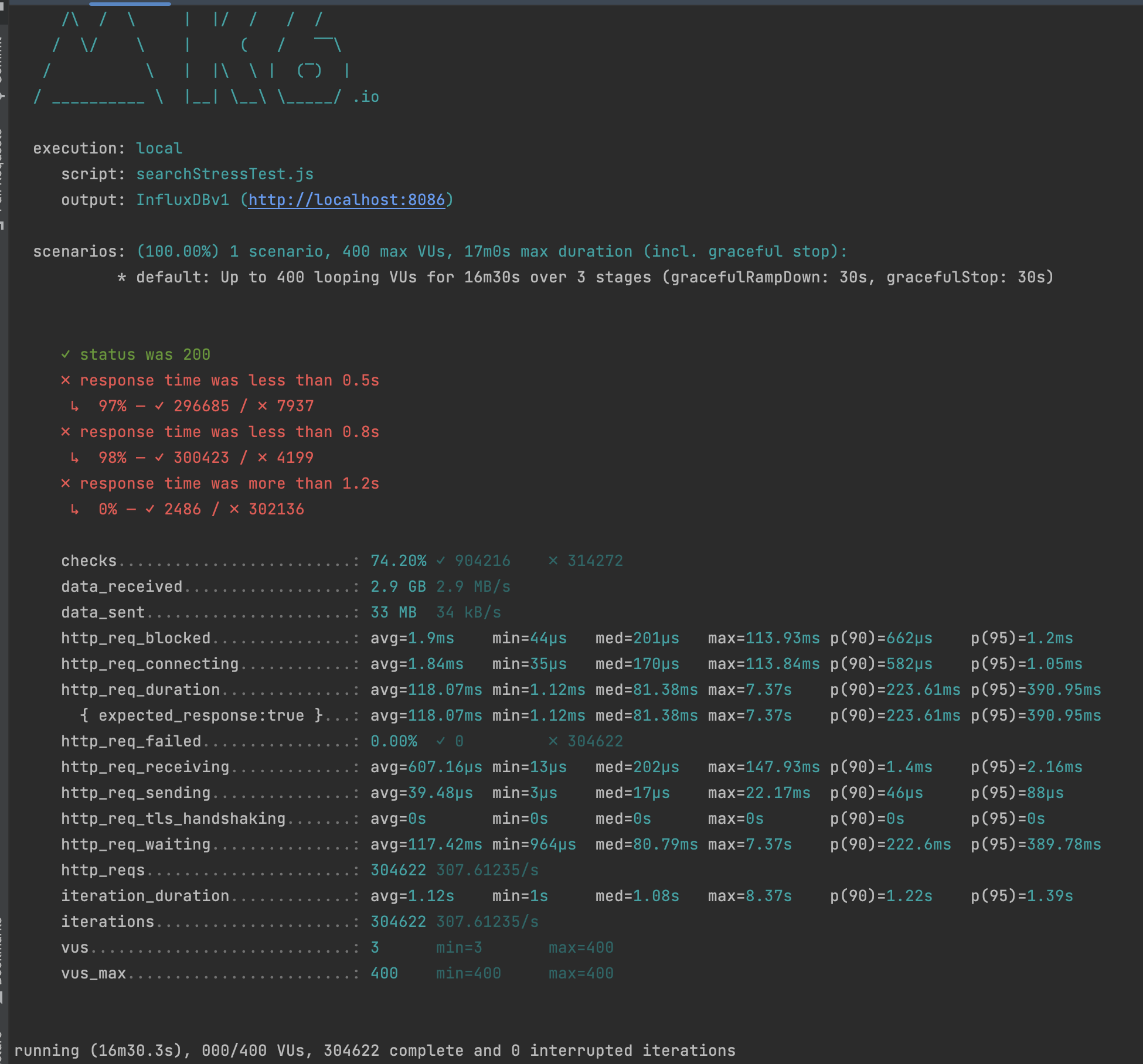

더 강한 부하를 주기 위해 시간을 더 길게하고 400명의 유저를 유지해보았을 때 응답 latency는 0.5s이하 비율이 97%, 0.5이상 0.8이하 비율이 1퍼센트, 1.2s 이상 비율이 1% 이하 였습니다.
Spike Test
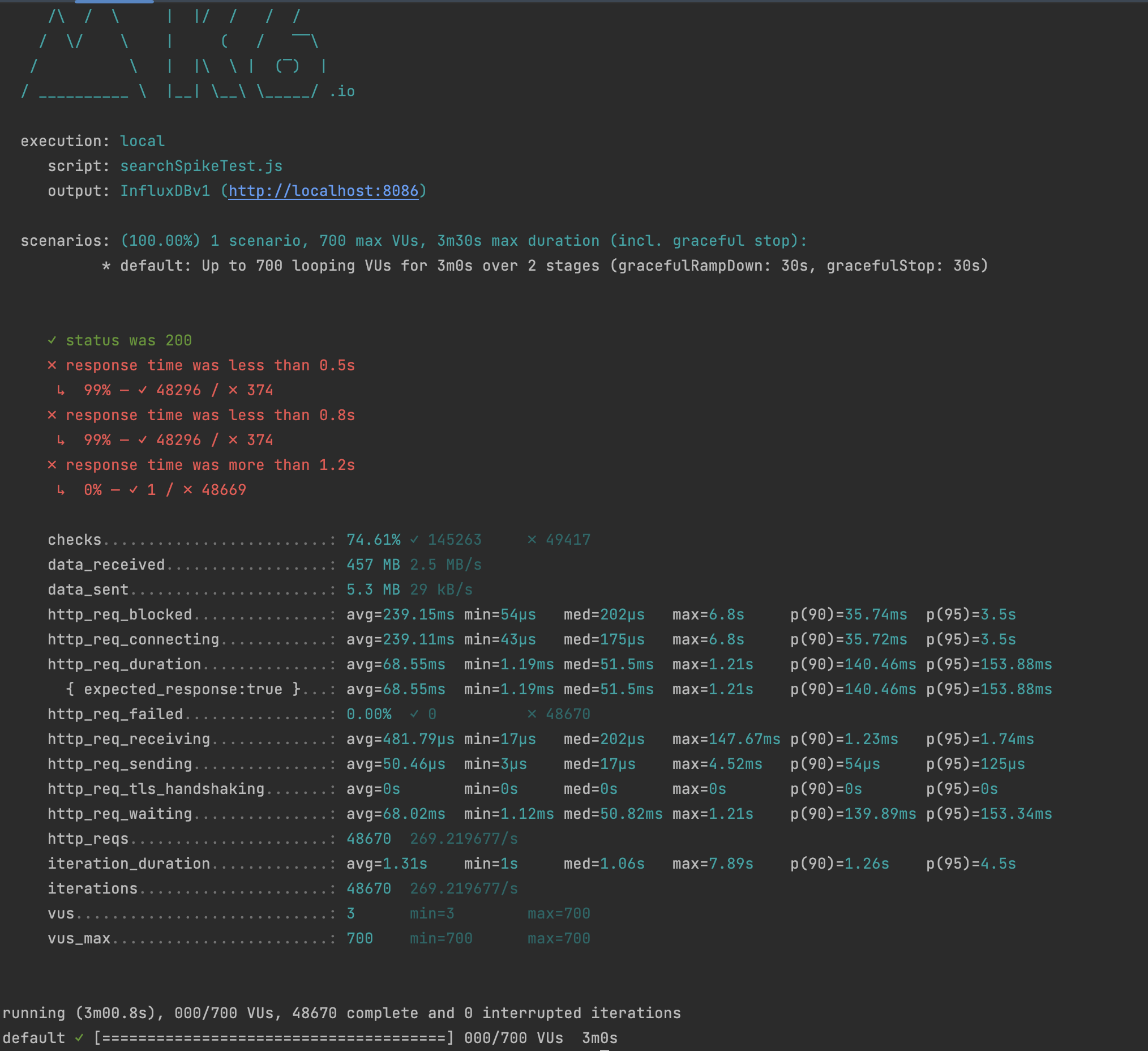
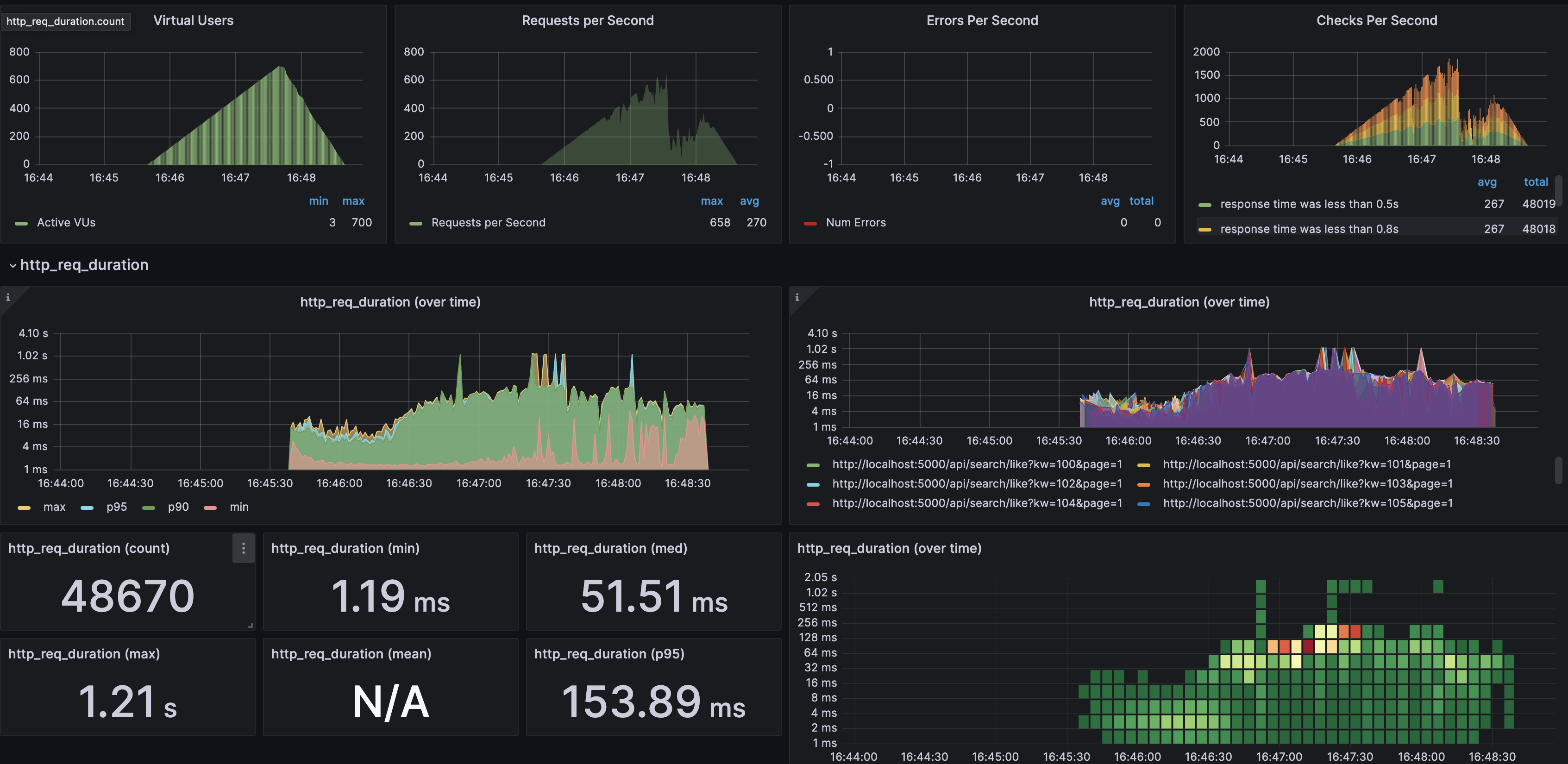
Spike Test를 할 때 http_req_failed 없이 700Vus에서 latency가 0.5s 이하 비율이 99%, 1.2s 이상 비율이 0%에 가까웠습니다.
페이지 번호를 랜덤하게 요청
let kw = Math.floor(Math.random() * 200) + 100;
let page = Math.floor(Math.random() * 30) + 1;
let res = http.get(`http://localhost:5000/api/search/like?kw=${kw}&page=${page}`);다음과 같이 검색어는 100~299, page는 1~30을 랜덤으로 생성하고 요청을 보네도록 했습니다.
Load Testing
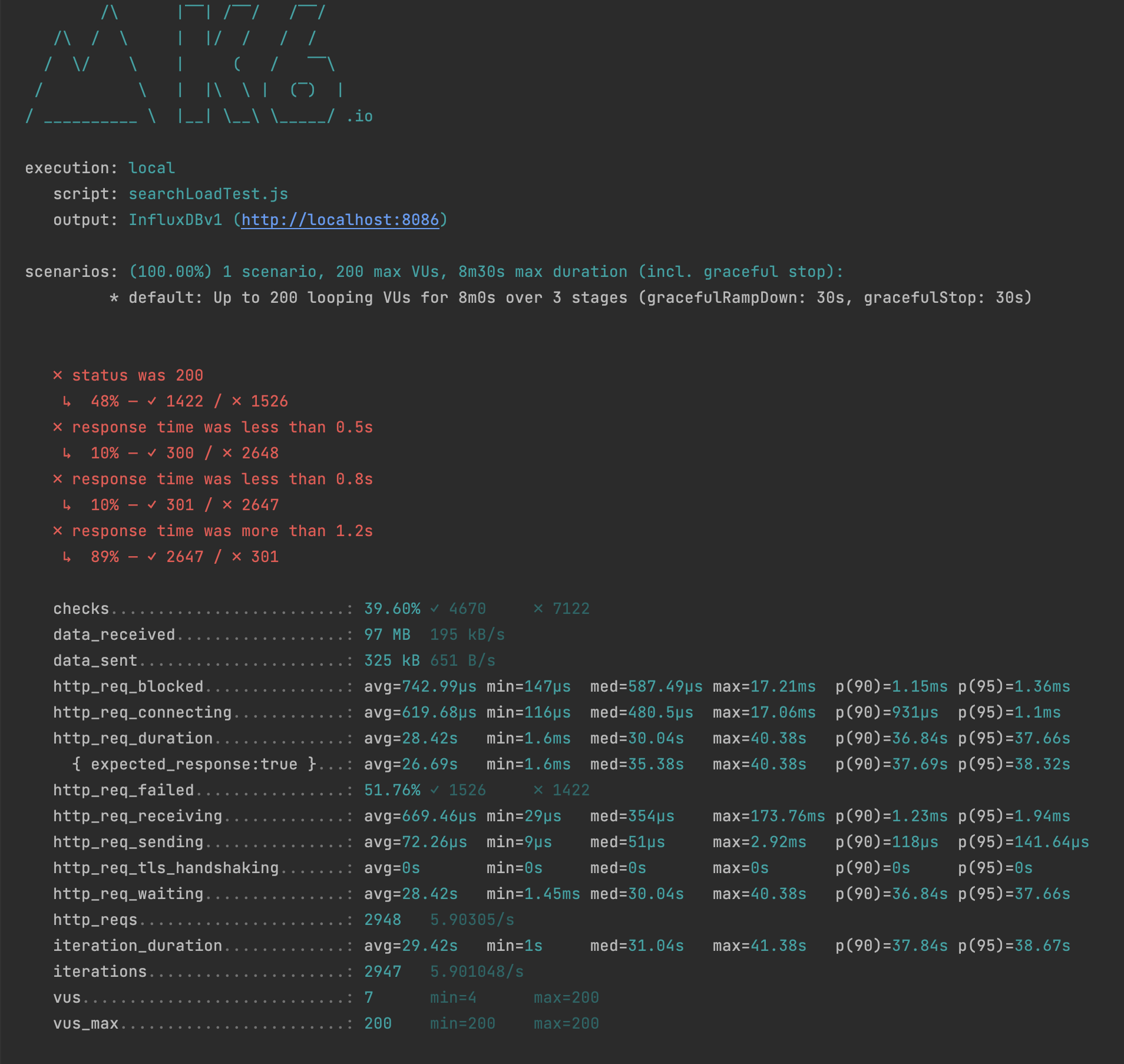
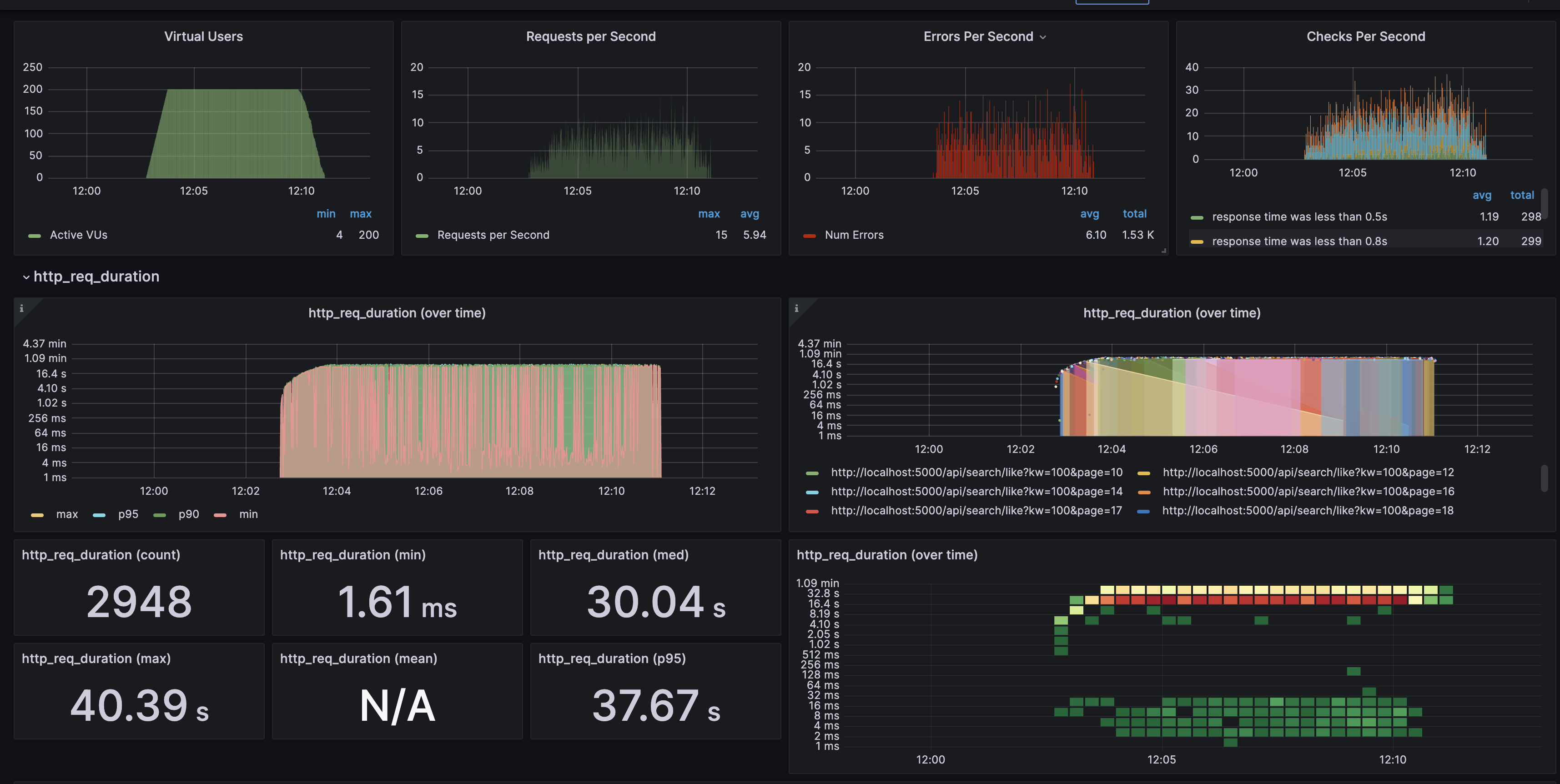
문제 발견
- 랜덤 숫자를 검색어와 페이지에 둘다 적용하니 캐시의 적중률 너무 낮아 캐시의 이용률이 너무 적어 응답시간이 너무 느렸고 오류가 발생하기도 했습니다.
- 캐시의 hit가 너무 낮으면 캐시를 제대로 사용하지 못하며, 캐시 메모리에 있지 않는 데이터는 응답 latency가 너무 늦다는 단점이 있었습니다. ilike 연산자에 인덱스를 적용시켜도 성능개선은 미미하여 근본적인 데이터베이스의 조회 속도는 그리 좋다고 할 수 없었습니다.
elasticsearch 검색엔진을 사용하게된 이유
- 관계형 데이터베이스는 단순 텍스트매칭에 대한 검색만을 제공합니다.
- 상품검색시 MySQL에 LIKE ‘%단어%’ 검색시 완벽한 전문 검색(Full Text Search)은 지원하지 않습니다
- 하지만 엘라스틱서치는 분석기를 통한 역인덱싱 으로 이것을 완벽하게 지원합니다. 물론 요즘 MySQL 최신 버전에서 n-gram 기반의 Full-text 검색을 지원하지만, 한글 검색의 경우에 아직 많이 빈약한 감이 있습니다.
- 텍스트를 여러 단어로 변형하거나 텍스트의 특징을 이용한 동의어나 유의어를 활용한 검색이 가능합니다.
- 엘라스틱서치에서는 형태소 분석을 통한 자연어 처리가 가능합니다.
- 엘라스틱서치는 다양한 형태소 분석 플러그인을 제공합니다.
- 엘라스틱서치에서는 관계형 데이터베이스에서 불가능한 비정형 데이터의 색인과 검색이 가능합니다.
- 이러한 특성은 빅데이터 처리에서 매우 중요하게 생각되는 부분입니다.
- 역색인 지원으로 매우 빠른 검색이 가능합니다.
- 검색 조건으로 Cache Key를 등록하는데 검색조건이 다양하여 Cache 성능이 떨어집니다.
scriptpath = os.path.dirname(__file__)
filename = os.path.join(scriptpath, 'products.json')
with open(filename, 'r', encoding='utf-8') as file:
datas = json.load(file)
chunk_size = 1000 # chunk 크기 설정
chunks = [datas['products'][i:i+chunk_size] for i in range(0, len(datas['products']), chunk_size)]
for chunk in chunks:
body = ""
for i in chunk:
body = body + json.dumps({"index": {"_index": "dictionary"}}) + '\n'
body = body + json.dumps(i, ensure_ascii=False) + '\n'
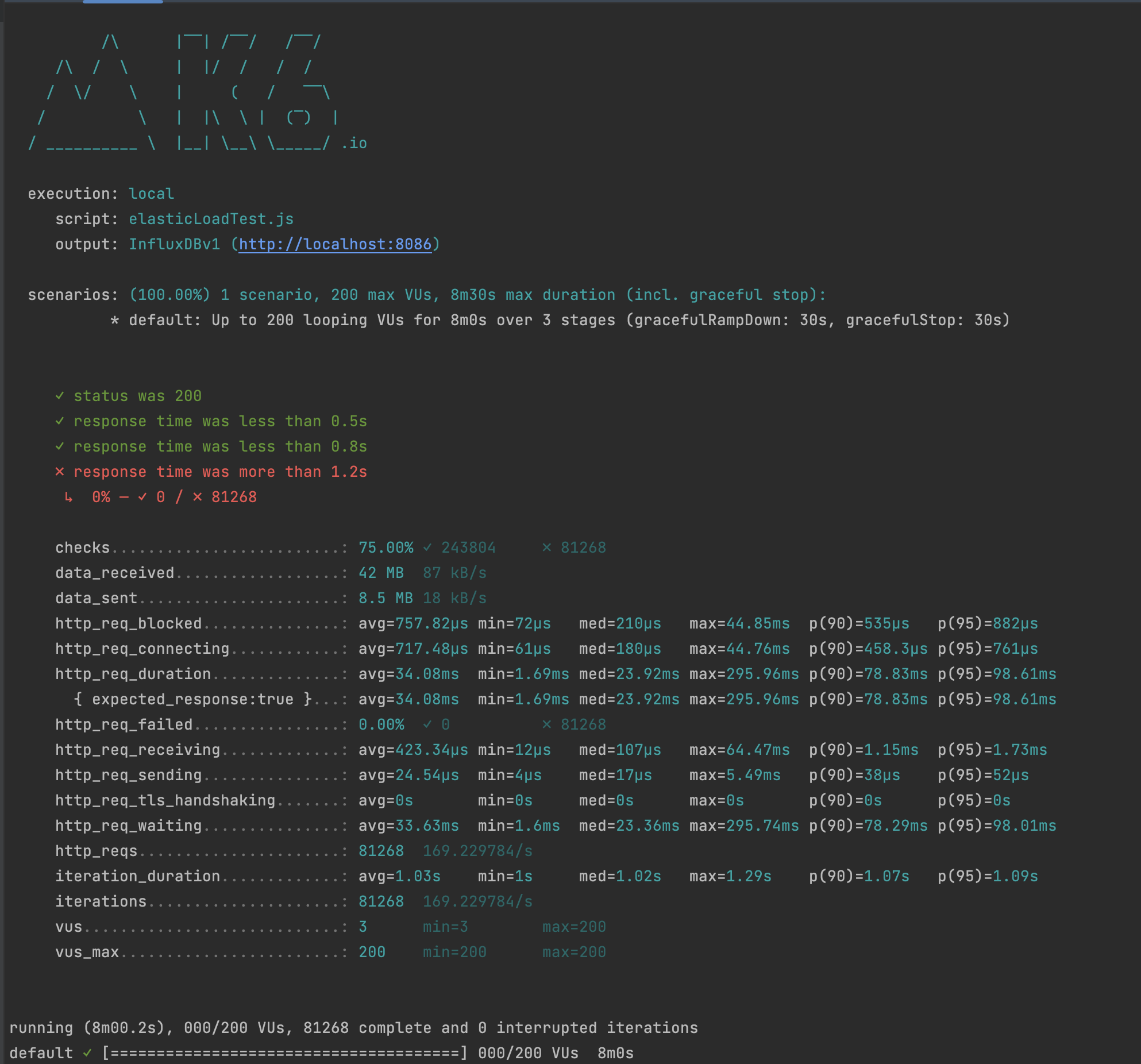
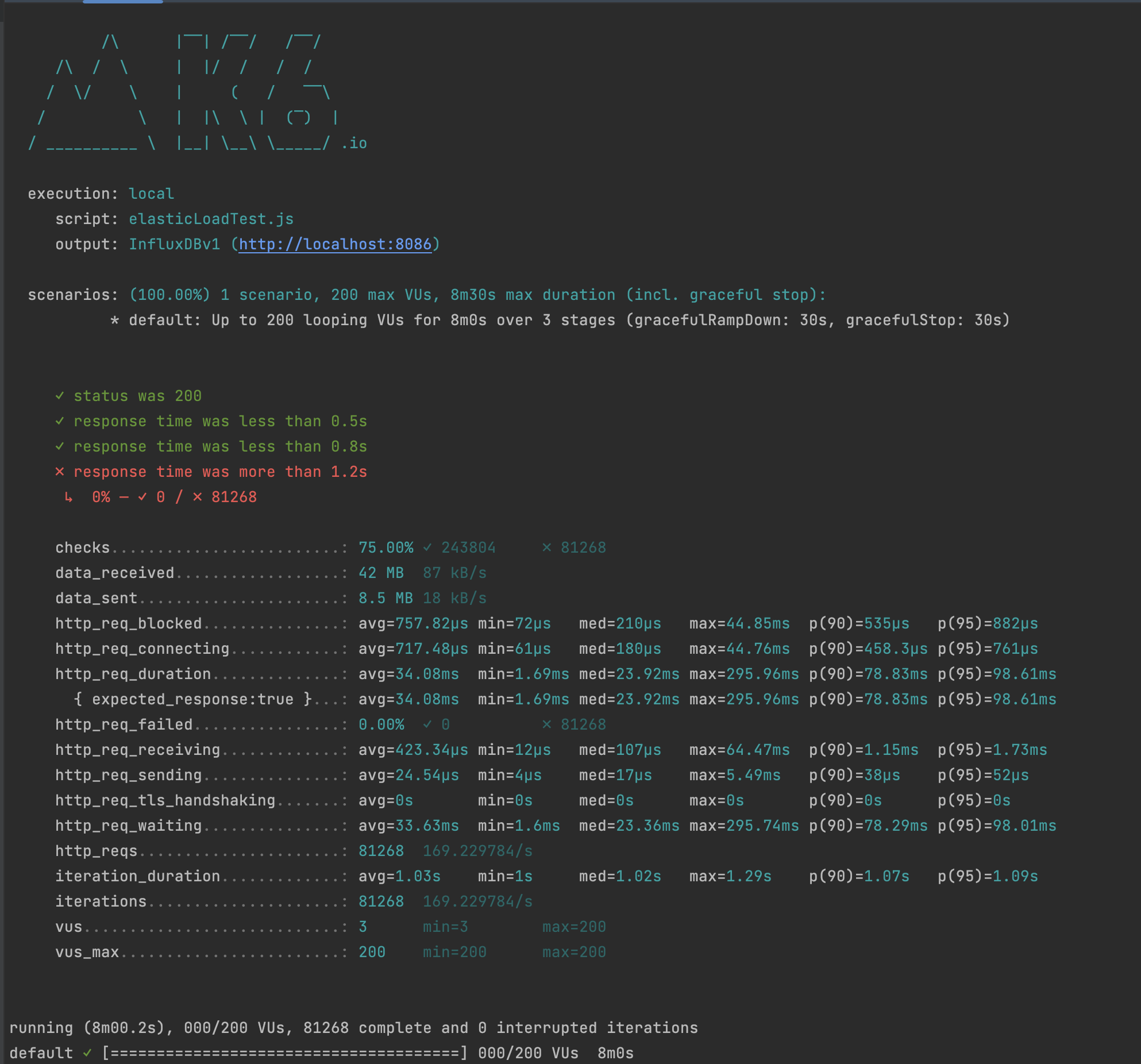
es.bulk(body)products.json에 50만 데이터를 elasticsearch에 한번에 bulk연산하는 것은 굉장한 시간이 걸렸습니다. 따라서 1000개씩 데이터를 나누어서 색인 작업을 하니 50초 이내에 더미 데이터를 삽입할 수 있었습니다. elasticsearch로 검색엔진을 바꾸고 load Test와 Stress Test를 진행할 때 Vus를 100명씩 증가하여 안정성을 확보하고 싶었습니다.
Smoke Testing
Load Testing
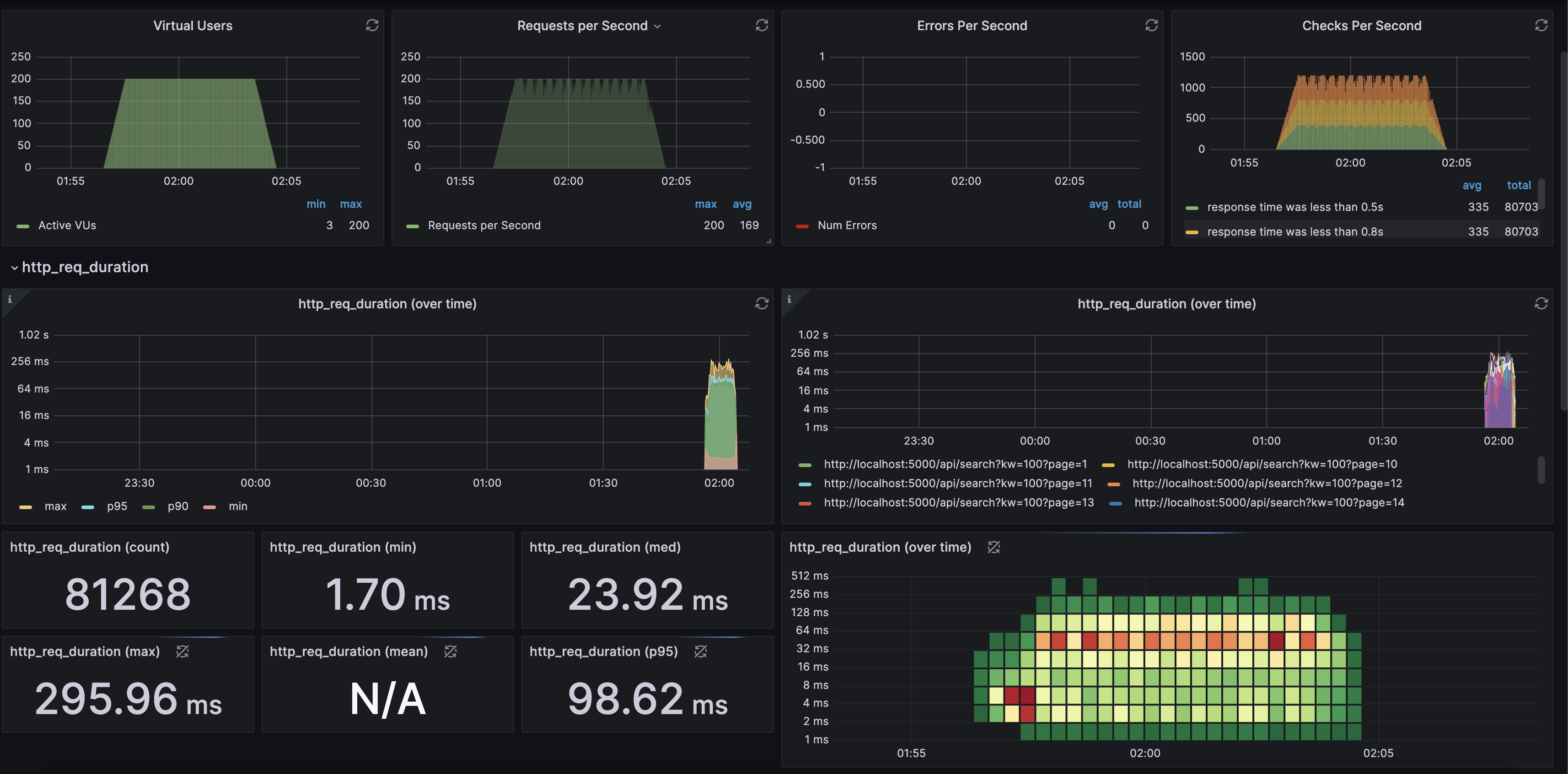
일반적인 날 200Vus를 유지시킬 때 latency는 0.5s가 100%가 나왔습니다. 검색어는 100~299, page는 1~30을 랜덤으로 생성하고 요청을 보네도록 했을때 ilike연산자 + index + cache를 했을 때 latency가 1.2s이상 비율이 89% 이상, http_req_failed가 51.76%가 나왔을 때보다 확실히 개선될 수 있었습니다. elasticsearch를 사용하는 것은 결국 캐시의 적중률을 생각하지 않고 역인덱싱으로 인한 빠른 데이터의 조회가 가능할 수 있었습니다.
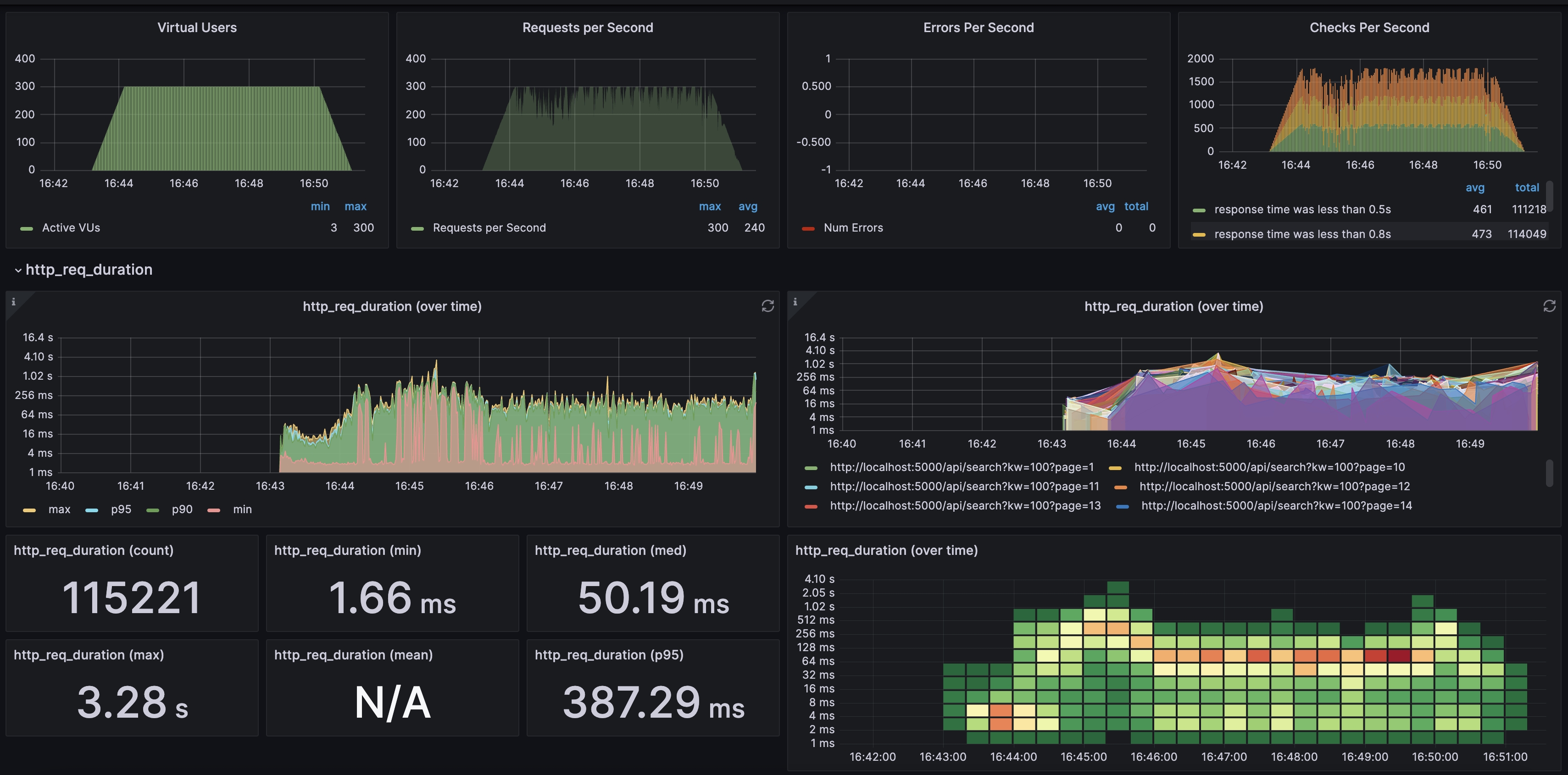
일반적인날 200Vus → 300Vus까지 유지 할 수 있었습니다.
Stress Testing

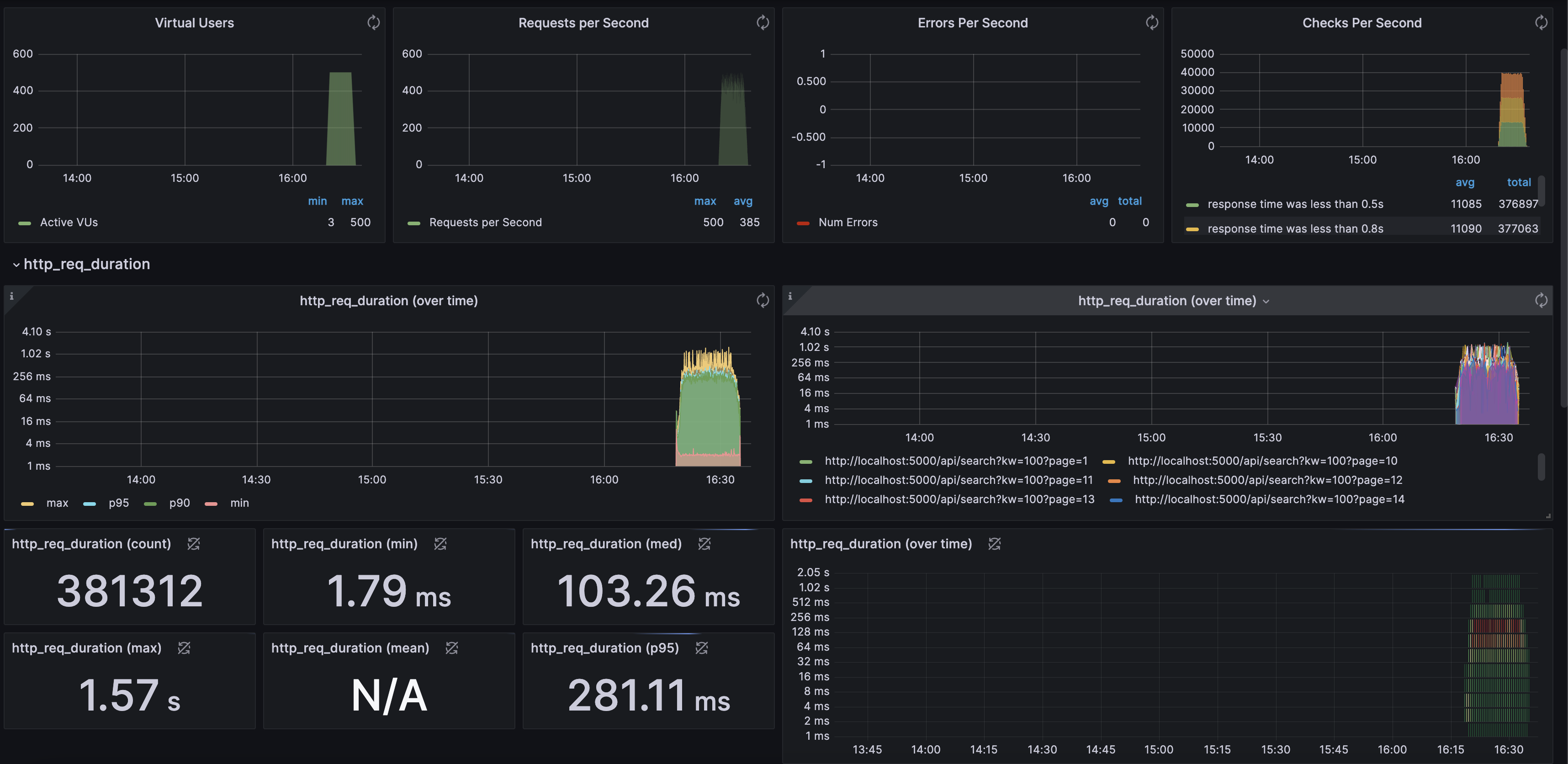
Stress Testing 역시 사용자의 요청 범위를 더 넓혔어도, 범위가 좁았을 때의 ilike + index + cache 적용 시와 비교 했을 때 400Vus에서 500Vus를 유지 시킬 수 있었고 max http_req_duration이 7.32s → 1.57s로 단축 시킬 수 있었습니다. latency가 0.5s 이하 비율이 97%에서 99%로 향상되었습니다.
Spike Testing
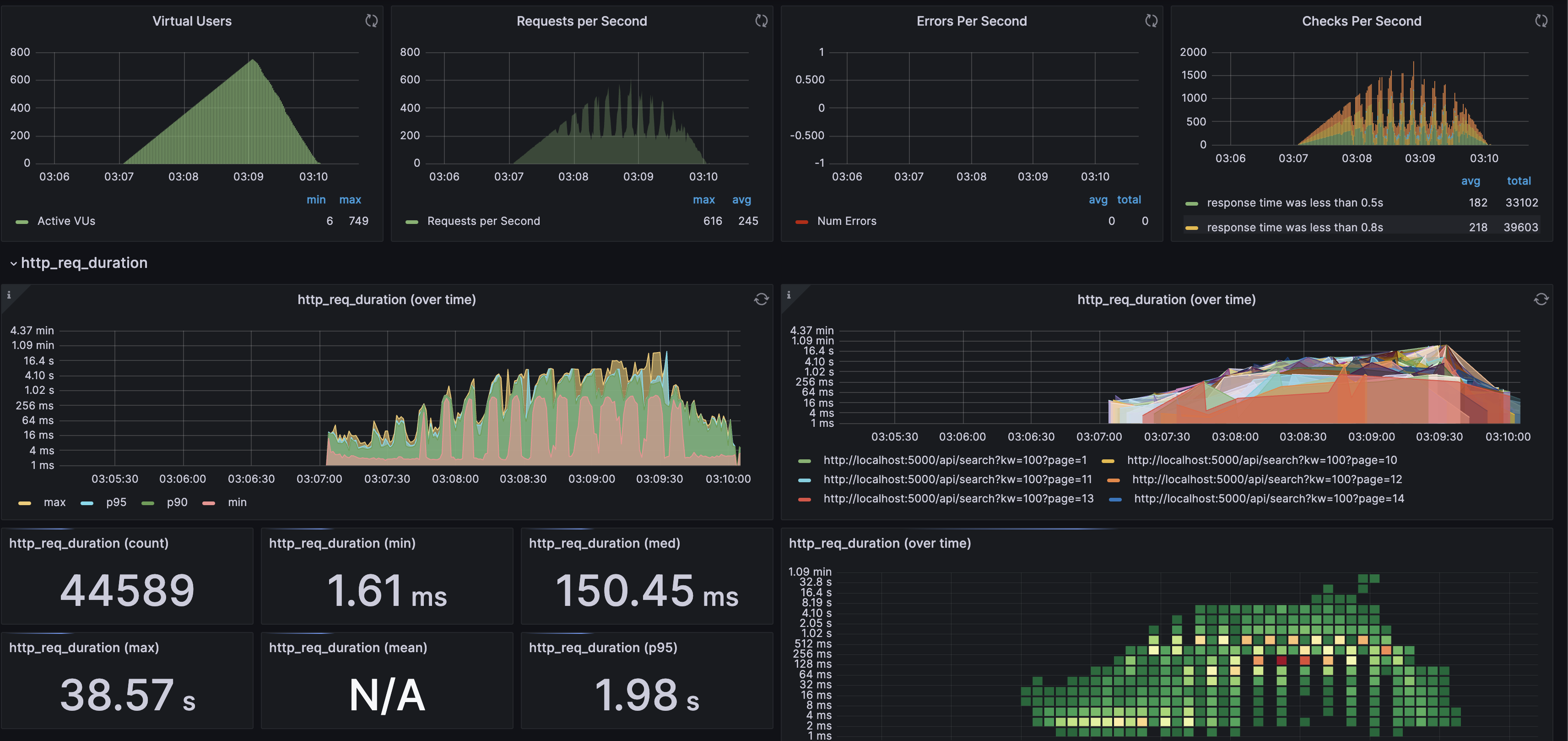
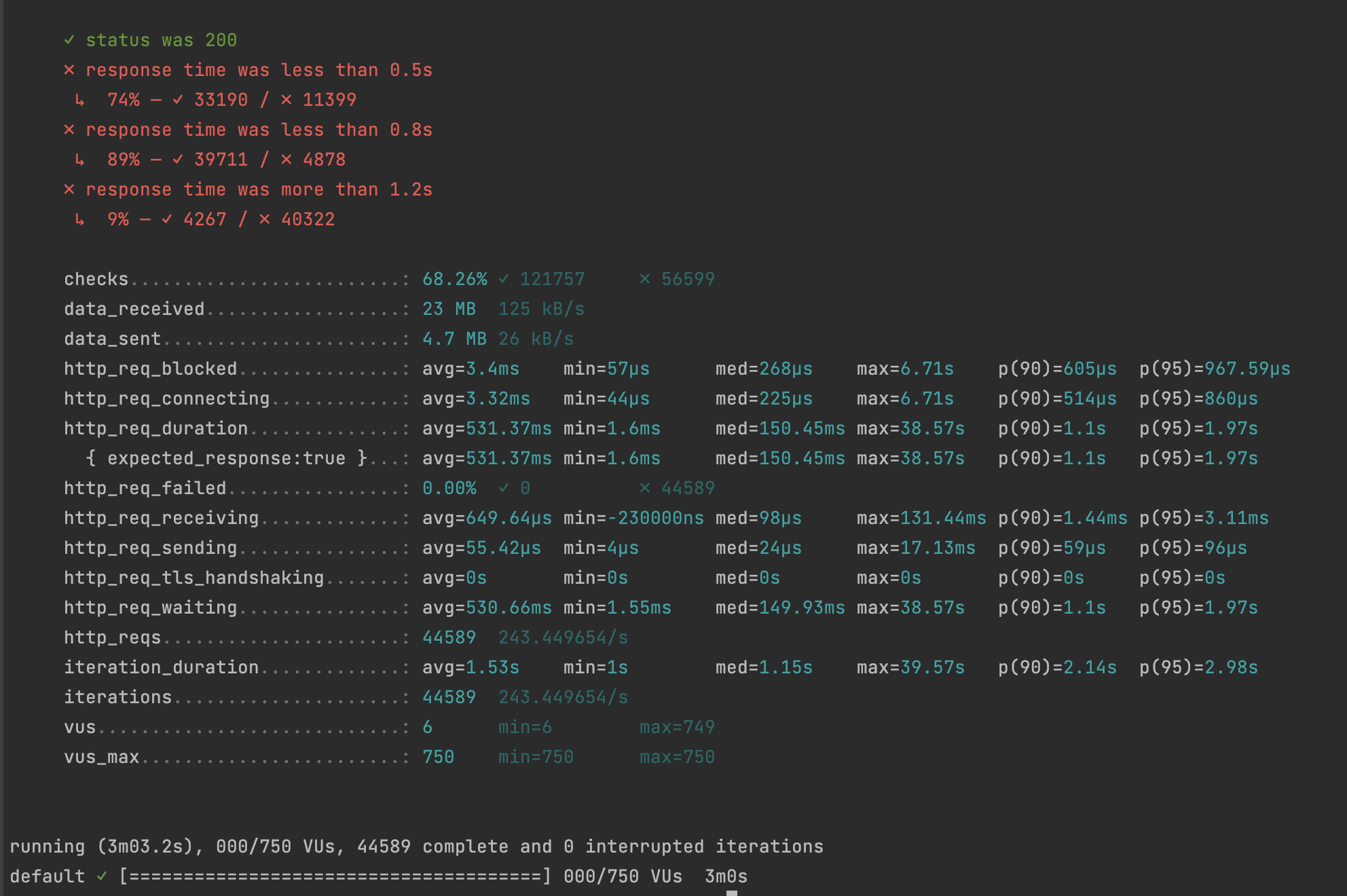
ilike + index + cache를 적용했을 때 Spike Testing을 했을 때보다 50Vus를 증가시킨 750Vus에서 http_req_failed 없이 유지할 수 있었습니다.
정리
- Elasticsearch로 검색엔진을 구축을 하면 cache의 적중률에 따라 천차만별인 응답속도와 달리 역색인 지원으로 항상 빠른 응답을 지원했습니다.
- Load Testing (ilike + index + cache 적용시) 200Vus, latency 1.2s 이상 rate : 89%, http_req_failed : 51.76% → (elasticsearch적용시) 300 Vus, latency 1.2s 이상 rate : 0%, http_req_failed : 0%, 0.5s이하 rate : 97%, 0.8s 이하 rate : 99%로 성능 개선
- Stress Testing (ilike + index + cache 적용시) 400Vus, max http_req_duration : 7.32s, latency 0.5s 이하 rate : 97% → (elasticsarch 적용시) 500Vus, max http_req_duration : 1.57s, latency 0.5s 이하 rate : 99%로 성능 개선
- Elasticsearch는 형태소 분석을 통한 자연어 처리가 가능하고 동의어나 유의어를 활용한 검색이 가능하므로 사용자의 검색 응답 질을 높일 수 있습니다.
후기
전체 상품 조회와 상품 검색 API에 성능 테스트를 하면서 "어떻게 하면 사용자에게 더 쾌적한 응답을 해주는게 좋을까?"라는 고민을 할 수 있었습니다. 기능 요구를 충족시켜주는 개발자가 아닌 비기능 요구도 최적으로 충족시켜주는 개발자가 되어야 겠다고 생각했습니다.
