지난 상반기 System Programming 연재를 열심히 진행하였다. 이번 하반기에는 SP 연재에서 계속 언급했던 '운영체제(Operating System, 약칭 OS)'에 대해 자세히 학습해보고자 한다. SP가 운영체제 위에서 System Program을 구축하는 방법에 대한 이야기였다면, 이번 OS에서는 그러한 System Program을 돌아가게 하는 Operating System이 어떠한 내부 구조를 지녔고, 어떠한 기반 이론을 바탕으로 설계되고 발달되어 왔는지에 대해 알아볼 것이다.
본 연재의 참조 교재는 Remzi H. Arpaci-Dusseau와 Andrea C. Arpaci-Dusseau가 저술한 OS 교재의 Classic 'Operating Systems, Three Easy Pieces'로, 연재에서 다룰 많은 개념 대부분이 본 교재에서 기인할 것이다. 해당 교재는 운영체제를 크게 세 가지 부분으로 나누어 깊이있게 설명한다. 그 '세 가지 핵심 Concept'는 차차 소개할 것이다. 참고로, 두 저자는 서로 부부이다.
금일 포스팅은 OS 연재의 첫 번째 시간으로, 앞으로 본 연재에서 다룰 개념들에 대해 간략하게 소개하는 시간이다. 지난 SP 연재에서 다루었던 많은 개념이 등장하오니, 복습 차원으로 가볍게 확인하면 될 것이다.
What is OS?
프로그램이 돌아간다는 것은 무슨 의미인가. 어떠한 과정을 거쳐서 프로그램이 돌아가는가?
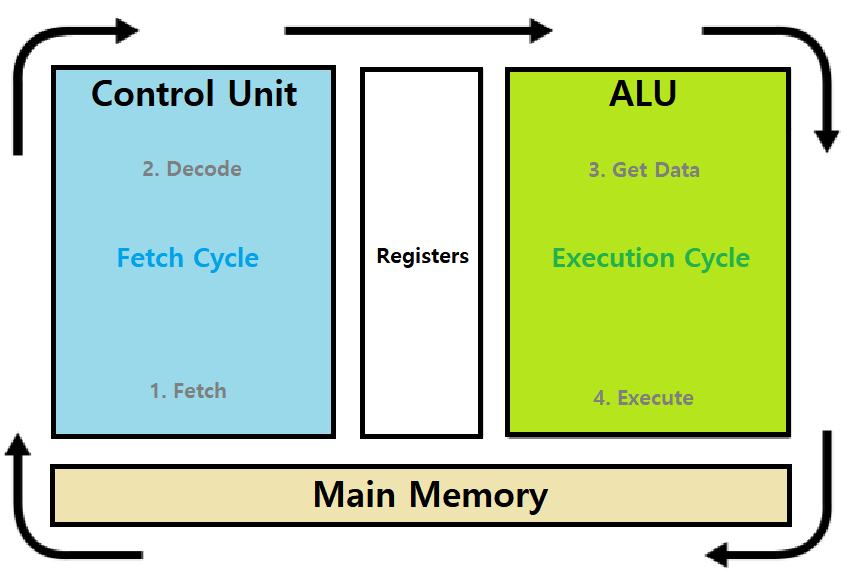
일반적으로 우리는 다음과 같은 Program Running Process를 배운바 있다(Physical Control Flow라는 이름으로).
-
(1) Fetch : Processor가 Memory에서 명령어를 Fetch한다.
- Program은 'Sequence of Instructions'로, CPU Processor는 이 명령어들을 순차적으로 읽고 처리해나가며 프로그램을 수행시킨다. 그 과정의 첫 발자국은 바로 명령어 Fetch, 즉, Main Memory DRAM에 올라간 Program(Process)의 Code 영역에 있는 명령어를 CPU로 가져오는 과정이다.
- Program Counter가 Code 영역의 명령어들을 가리키고, 해당 포인팅 위치에서 명령어 Bit Sequence를 CPU의 Instruction Register로 가져온다. (Architecture)
-
(2) Decode : CPU 내부로 가져온 명령어가 무엇을 의미하는지 알아내는 과정이다.
- Architecture 관점에서 설명하면, Bit Sequence를 Addressing Mode를 기반으로 몇 가지 조각으로 나누어 Opcode, Operand 등으로 구분하는 과정이다.
-
(3) Get Data : Decode의 하위 단계라고도 볼 수 있는 단계로, 명령어가 필요로 하는 Operands를 Fetch하는 과정이다.
- 예를 들어, 현재 읽고 있는 명령어가 add라면, 두 개의 Number Operands를 Fetch한다.
-
(4) Execute : 명령어를 실행(수행)한다.
- 예를 들어, add의 경우, 두 개의 Number Operands를 ALU에 넣어 그 결과를 받아낸 후, 해당 결과를 '미리 Get한' Access할 Memory에 저장한다.
- 명령의 종류에 따라서, Condition Check 결과, Jump, Function Call 등등의 행위가 일어날 것이다.
-
(5) Processor는 이 과정을 반복한다.
- 'Fetch - Decode - Get Data - Execute'
- 교재에 따라서 'Fetch - Decode - Execute - WriteBack'으로 배울 수도 있다. (이전 SP에서 명시했던 방식)
- 물론, 차이는 없다.
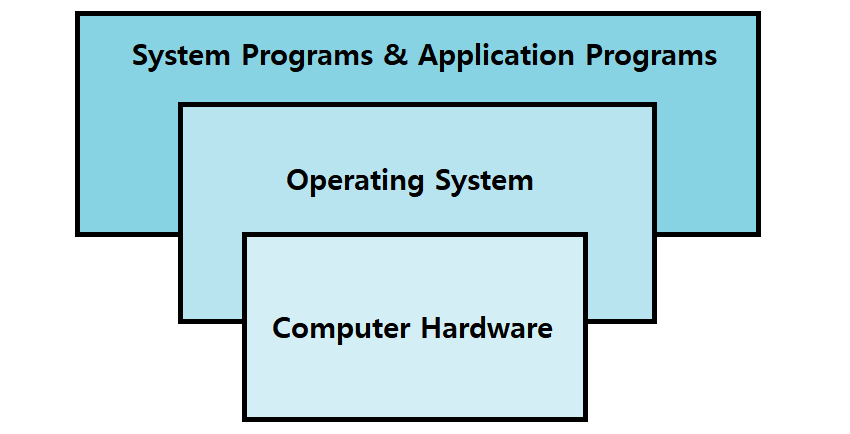
이러한 Physical Control Flow가 일어날 때, HW와 SW(Program)가 소통할 수 있게 해주는 또 다른 SW가 바로 OS(Operating System)이다.
OS : 'Computer Hardware'와 'Computer User / Program' 사이에서 '중재 역할(Intermediary)'을 하는 Program

OS gives Services
HW와 SW의 소통, 중재역할, 이런 말들은 약간 추상적으로 들릴 것이다. OS가 구체적으로 무엇을 하길래 그러한 역할을 한다는 것일까? 이에 대해 알아보자.
OS는...
- 여러 프로그램을 좀 더 쉽게 동시에 돌릴 수 있게 해준다.
- 프로그램들이 Memory를 공유할 수 있게 해준다.
- 프로그램들이 다른 Device와 소통할 수 있게 해준다.
~> OS는 Program과 여러 System이 Computer에서 문제 없이, 정확하게, 효율적으로 돌아갈 수 있게 해주는 SW이다. 다양한 Service를 제공해서 말이다.
=> 이제, 우리는 그러한 'Service'가 무엇이 있는지 자세히 알아볼 것이다.
System Call
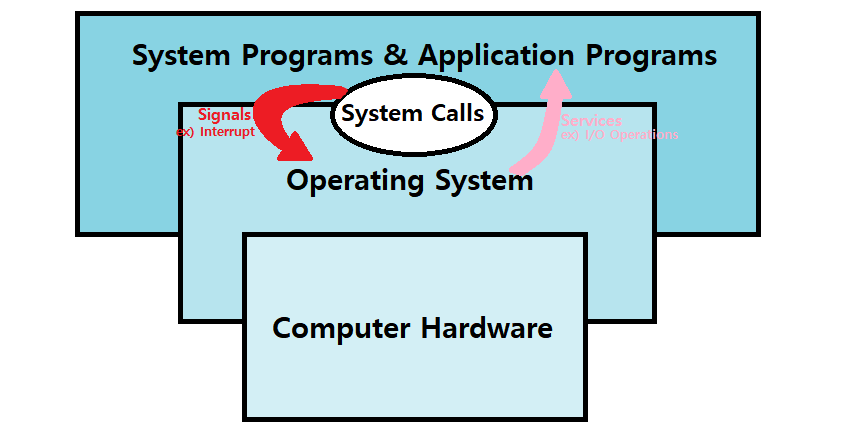
한편, Service를 자세히 알아보기에 앞서, OS의 Service를 사용하는 방법에 대해 간략히 짚고 넘어가자. System Programming 시간에 여러 차례 사용해봤던 System Call들이 기억나는가? read, open, stat 등 말이다. 그 System Call이 바로 대표적인 OS Service 요청 Interface이다.
System Call : User가 OS에게 Service를 요청할 때 사용하는 Interface로, 여러 API와 Standard Library가 있다.
-
System Programming에서 다뤘다시피, System Call의 종류는 생각보다 그렇게 많지는 않다. Linux에선 약 330개 가량의 System Call이 제공된다.
-
OS가 System SW에게 System Call Interface를 받아 여러 Service를 제공한다. ★
- ex) POSIX API, Win32 API, Various Libraries
- "System Call is a Library"
- ex) POSIX API, Win32 API, Various Libraries
-
Program은 이러한 Library를 통해 Interrupt와 같은 Signal을 촉발시키고, 나아가 Kernel Code에 접근할 수 있다.
-
-
이러한 System Call들은 다음과 같은 기능을 수행한다.
- Run Program
- Access Memory
- Access Devices
- 등등
-
OS가 제공하는 Service에는 다음과 같은 것들이 있다.
- Program Execution
- I/O Operations
- File Systems
- Resource Allocation
- Error Detection
- Protection (Security)
- 등등
Virtualization
이제, OS가 제공하는 Service가 제공되는 원리, 기반 개념에 대해 알아보자.
Resource Management
Resource라 함은, CPU, (Main) Memory, Disk 등이 있다. 여러 Program이 단일 CPU 위에서 동시에 돌아가는 그러한 상황에서 이러한 Resource들을 어떻게 관리하는지가 바로 OS가 하는 일이다.
OS does 'Resource Management' including CPU, Memory, etc.
- 많은 프로그램이 동시에 돌아간다는 것은, 이들이 CPU를 Share한다는 것이다.
- Execute가 동시에 이뤄지고 있는 것!
- 많은 프로그램이 동시에 돌아간다는 것은, 이들이 Memory를 Share한다는 것이다.
- 각자의 명령어와 데이터를 동시에 사용하고 있기 때문!
- 많은 프로그램이 동시에 돌아간다는 것은, 이들이 Disk를 Share한다는 것이다.
- 동시에 Device를 함께 접근하고 있는 것!
이 'Sharing'이 Resource Management의 핵심이고, 이러한 자원 관리를 OS가 한다는 것!
How? By 'Virtualization'
'가상화(Virtualization)'은 SP에서 다룬 바 있다. 아래의 개념들이 핵심이었다.
- Logical Control Flow with Context Switch
- Private Address Space with Virtual Memory
기억나는가?
OS는 Physical Resources에 대한 Virtualization을 제공해 Sharing을 구현한다. ★★★
Processor, Memory, Disk와 같은 Physical Resources를 General하고 Powerful한, 동시에 Easy-to-Use한 Virtual Form으로 변환하는 역할을 'OS'가 수행한다. ★★★
이러한 관점에서 OS를 'Virtual Machine'이라고도 부른다.
아래는 Physical Resources를 OS가 Virtualizing하여 Illusion을 만들어낸 것을 묘사한 그림이다.
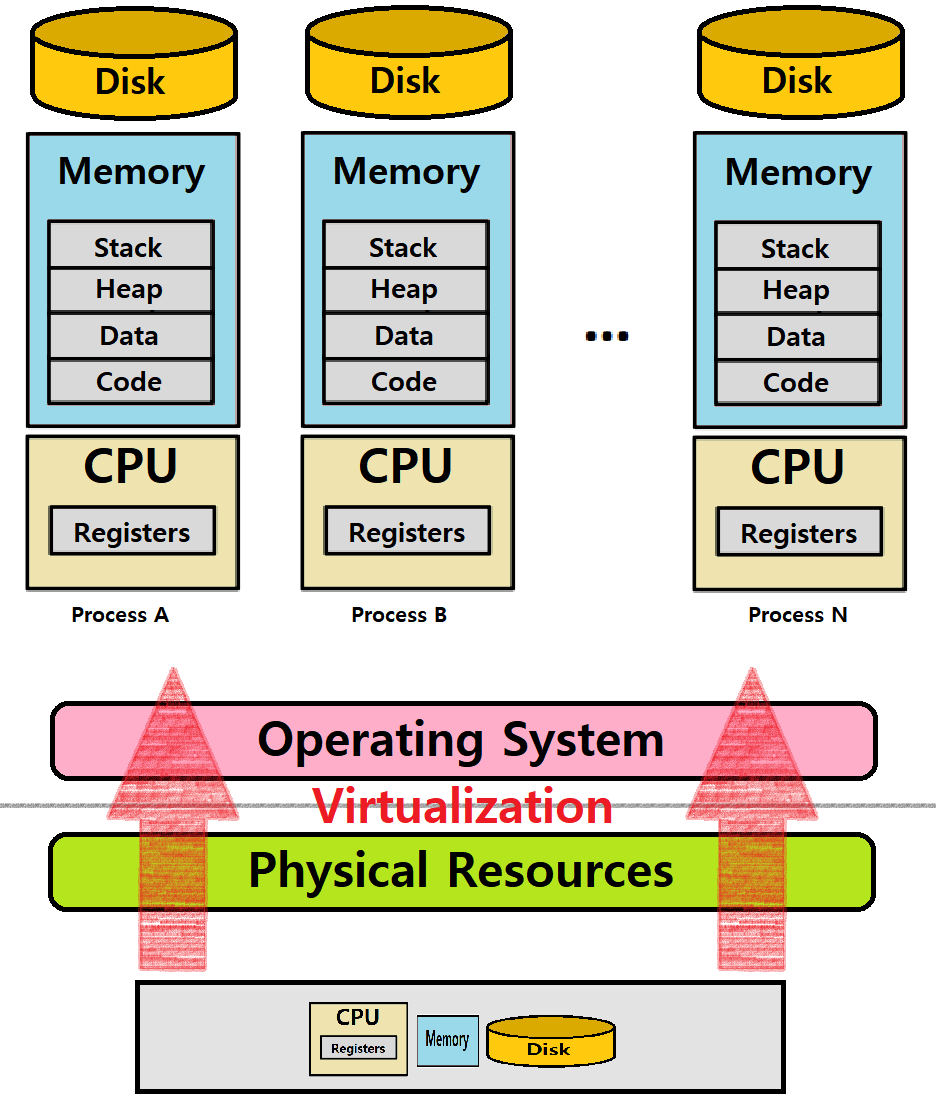
CPU Virtualization
System은 수많은 Virtual CPU를 가지고 있는 것처럼 보인다. 단일 CPU 컴퓨터여도 말이다. 무엇을 통해서? Virtualization을 통해서 말이다. 이를 통해 많은 프로그램들이 동시에 돌아가는것처럼 '보이게 한다'.
아래와 같은 예제 코드를 확인해보자. CPU를 소모하면서 시간을 체크하는 Spin 함수 호출과 함께, '입력받은 String'을 무한루프로 출력하는 프로그램이다. (spin 함수는 쉽게 말해서 Delaying Function임)
#include <stdio.h>
#include <stdlib.h>
#include <sys/time.h>
#include <assert.h>
#include "common.h“ // Spin 함수를 포함한 헤더
int main(int argc, char *argv[]) {
char *str = argv[1];
if (argc != 2) {
fprintf(stderr, "usage: example1 <string>\n");
exit(1);
}
while (1) {
Spin(1); // 매 순회마다 CPU 시간을 소모한다. by Spin 함수
printf("%s\n", str);
}
return 0;
}(출력1)
> ./example1 "ABC"
ABC
ABC
ABC
ˆC (무한루프이므로 Ctrl+C로 종료)
(출력2)
> ./example1 A & ./example1 B & ./example1 C & ./example1 D &
[1] 1234
[2] 1235
[3] 1236
[4] 1237
A
B
D
C (순서대로 출력되고 있지가 않음)
A
B
C
D
A
C
B
D
...
~> 프로그램을 순차적으로 실행시켰는데, 실제로는 4개의 프로세스가 동시에 수행되고 있다. (결과 출력 간에 출력 순서가 랜덤하므로 동시 수행 중이라고 결론낼 수 있음)
=> 즉, 이처럼 CPU가 Virtualization되어 있다. 단일 CPU인데, 마치 4개의 프로세스가 각자 CPU를 가진 것처럼 동시 수행되고 있음(는 것처럼 보이는 것).
- 이때, 여러 프로그램들의 '수행 순서'는 OS의 정책에 의거해서 결정된다.
- OS의 Scheduling Algorithm이 이를 결정한다. ★★★
- 우리는 이에 대해 배울 것이다.
- OS의 Scheduling Algorithm이 이를 결정한다. ★★★
Memory Virtualization
Physical Memory는 Byte Array라고 볼 수 있다. OS는 이러한 Byte Array를 Virtual Memory화 하는 것이다.
- Program은 자신이 구축하는 Data Structure를 Memory에 올리고, 유지해야한다.
- Load(Read Memory) : Data를 읽기 위해 Access할 특정 Address를 명시한다.
- Store(Write Memory) : 특정 Address에 쓸 Data를 명시한다.
아래와 같은 예시 프로그램을 보자. 특정 메모리 주소를 지정해서, 해당 주소에 Value를 0에서부터 매 시간마다 Incrementing해가는 프로그램이다.
#include <unistd.h>
#include <stdio.h>
#include <stdlib.h>
#include "common.h"
int main(int argc, char *argv[]) {
int *p = malloc(sizeof(int)); // 특정 메모리 주소 할당
assert(p != NULL); // 에러 처리 (조건 불만족 시 에러 발생)
printf("(%d) address of p: %08x\n", getpid(), (unsigned) p);
// 할당된 메모리 주소를 출력한다.
*p = 0; // 해당 주소의 값을 0으로 초기화
while (1) {
Spin(1); // CPU 소모
*p = *p + 1; // Increment
printf("(%d) p: %d\n", getpid(), *p); // 값을 출력(확인)
}
return 0;
}(출력1)
> ./example2
(1012) address of p: 12345678
(1012) p: 1
(1012) p: 2
(1012) p: 3
(1012) p: 4
(1012) p: 5
ˆC
(출력2)
> ./example2 &; ./example2 &
[1] 12345
[2] 12346
(12345) address of p: 12345678
(12346) address of p: 12345678 (주소값은 가정)
(12345) p: 1
(12346) p: 1
(12346) p: 2
(12345) p: 2
(12345) p: 3
(12346) p: 3
(12346) p: 4
(12345) p: 4
...
~> 두 프로그램이 모두 'Address 12345678의 Value를 Incrementing'하고 있다.
=> 이때, 과연 두 프로그램이 똑같은 Physical Memory Address의 Value를 Incrementing하는 것일까? 두 프로그램에서 지정한 Virtual Memory Address가 같은데 말이다.
----> 결과를 보면, 두 프로세스가 Concurrency Issue를 발생시키지 않으면서 각자 잘 Incrementing하고 있다. 즉, 같은 물리 메모리 공간에 대한 오염이 발생하지 않고 있다.
두 프로세스가 각각의 Private Virtual Address Space를 가지고 있다.
즉, 두 프로세스가 각자 자신의 Virtual Memory 상에서 12345678번지의 값을 바꾸고 있지만, 실제로는 두 공간의 Physical Memory Address는 다른 것이다. ★★★
※ VAS(Virtual Address Space) : OS는 각 프로세스에게 고유의 Virtual Address Space를 제공한다. 각 VAS는 Physical Memory에 맵핑되어 있다.
VAS의 의의 : 하나의 Running Program의 Memory Reference가 다른 Process들의 Address Space에 영향을 주지 않게 만들어준다.
Thus, Physical Memory is a shared resource which is managed by the OS.
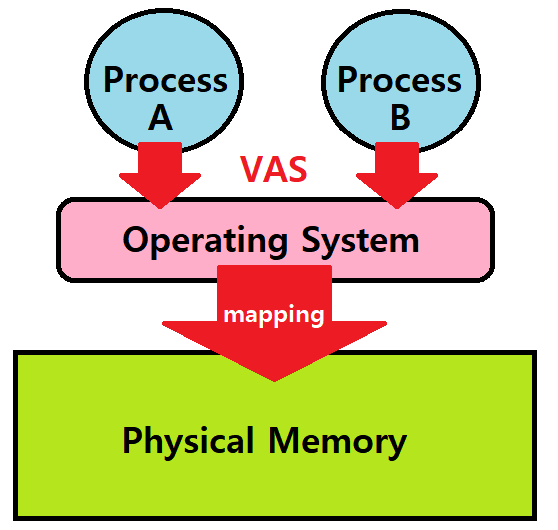
Concurrency
OS는 여러 Process를 동시에 수행시킨다. 그 과정에서 Concurrency Issue가 발생할 수 있음을 우리는 SP에서 학습한 바 있다.
하나의 Process에서 여러 개의 Control Flow를 동시에 실행하는 Multi-threaded Program을 떠올려보자. 알다시피, 이러한 Multi-threaded Program은 Modern Multicore System의 이점을 잘 이용할 수 있다. '잘' 구축했을 때 말이다.
하지만 이러한 Multi-threaded Program 구축 시 '잘' 작성하지 않으면 Shared Data Structures로 인한, 또는 그 외의 Concurrency Issue가 발생할 수 있음도 결코 잊어선 안된다. Race, Deadlock 등의 문제를 피해야한다.
아래의 Multi-threaded Program 예시를 보자.
#include <stdio.h>
#include <stdlib.h>
#include "common.h"
volatile int cnt = 0; int N;
void *thread_routine(void *arg) {
int i;
for (i = 0; i < N; i++)
cnt++;
return NULL;
}
int main(int argc, char *argv[]) {
if (argc != 2) {
fprintf(stderr, "usage: example3 <value>\n");
exit(1);
}
pthread_t p1, p2;
N = atoi(argv[1]);
printf("Initial count : %d\n", cnt);
Pthread_create(&p1, NULL, thread_routine, NULL);
Pthread_create(&p2, NULL, thread_routine, NULL);
Pthread_join(p1, NULL); Pthread_join(p2, NULL);
printf("Final count : %d\n", cnt);
return 0;
}(출력)
> ./example3 1000
Initial count : 0
Final count : 2000
> ./example3 100000
Initial count : 0
Final count : 123053
> ./example3 100000
Initial count : 0
Final count : 165234
~> 사용자로부터 입력받은 N 값에 따라, 두 개의 Thread가 각각 그 N만큼 Increment하여, 최종적으로 2*N만큼의 Count 값을 얻고자 하는 Program이다.
=> 허나, 의도한대로 프로그램이 돌아가지 않는 것을 어렵지 않게 확인할 수 있다.
----> 이유를 알겠는가? SP 연재를 보았다면, 대번에 알아챌 수 있을 것이다. 그렇다. Thread Routine에 있는 Increment Instruction이 High-Level Language 시선에선 Atomic한 단일 명령처럼 보이지만, 실제 Assembly or Machine Language 시선에선 3단계로 이루어진 Non-Atomic 명령 Sequence이기 때문이다.
즉, 'cnt++;' 수행 과정에서 두 Thread가 Context Switch로 인해 서로서로 침범하고 오염시키고 있다.
Concurrency Issue가 발생한 것이다.
- 알다시피, 'cnt++' 명령은 사실 다음과 같이 나뉜다.
- (1) Load : 메모리에서 cnt 값을 뽑아내 Register에 Load한다.
- (2) Increment : 해당 Register 값을 +1한다.
- (3) Store : 업데이트된 값을 다시 Memory에 Write한다.
- 세 명령의 묶음인 것으로, 결과적으로 Atomic하지 않다.
- Interleaving이 발생한다.
- Concurrency Issue!
- Interleaving이 발생한다.
OS는 이러한 Concurrency Issue를 Handling할 수 있는 방법을 제공한다.
Semaphore를 위시한 많은 Mechanism들이 존재! (추후 다룰 것)
Persistence
OS는 '지속성(Persistence)'에 대한 Service도 제공한다. 지속성이란 무엇을 말하는 걸까?
Main Memory, DRAM과 같은 저장 장치들은 Volatile, 휘발성을 띈다. Power를 Off하면 지니고 있던 데이터들을 모두 잃는 것이다. 반면, HW나 SW들은 Data의 지속, 유지가 중요하다. 왜냐? 이들이 데이터를 잃으면 컴퓨터가 제대로 동작할 수 없으니까.
- HW ex) HDD(Hard Disk)나 SSD(Solid-State Drive)와 같은 I/O 장치들
- SW ex) File System
OS 내의 'File System'이란 SW는 System의 Disk에 있는 File들의 정보를 효율적이고 신뢰성있는 방식으로 관리하고 저장하여 User에게 Persistence를 제공한다. ★
Disk를 Sharing하는데에 있어서 중추적인 역할을 담당한다.
Virtualization과는 다른 측면의 요소이다. ★
OS가 CPU나 Memory에 대해 Virtualization을 제공했던 것과 달리, OS는 Disk에 대해서는 각 Application에 대해 가상화되거나, Private한 무언가를 제공하지 않는다.
대신, File들에 들어있는 정보를 Sharing하는 Mechanism을 제공하는 것이다.
무엇으로? File System SW로!
여담) open, read, write, close와 같은 System Call들은 모두 OS의 File System과 소통하는 System Call들이다. File System을 필요로 하는 User Request를 처리하는 것이다.
-
OS가 Persistence를 제공하는 방식
-
Disk(Device) Write 시 OS가 하는 일
- Data가 Disk 어디에 쓰여질 지를 찾아낸다.
- Device Driver를 통해 해당 Storage Device에 I/O Request를 보낸다.
- 모든 Device에는 Device Driver가 있는데, 그 드라이버에 '어떤 위치에 Data를 읽고 써라~"라고 하는 것이 OS의 File System인 것이다. ★★★
-
Write 시에 발생하는 System Crush도 OS File System이 처리한다.
- Journaling 또는 Copy-On-Write 기법을 통해서! (추후 다룰 것)
- Write Sequence가 들어올 때, 각 Write들을 Ordering하고, 그 과정에서 Fail하는 User에 대해서 정상 State로 Recover하는 것까지 고려한다. ★
- Journaling 또는 Copy-On-Write 기법을 통해서! (추후 다룰 것)
-
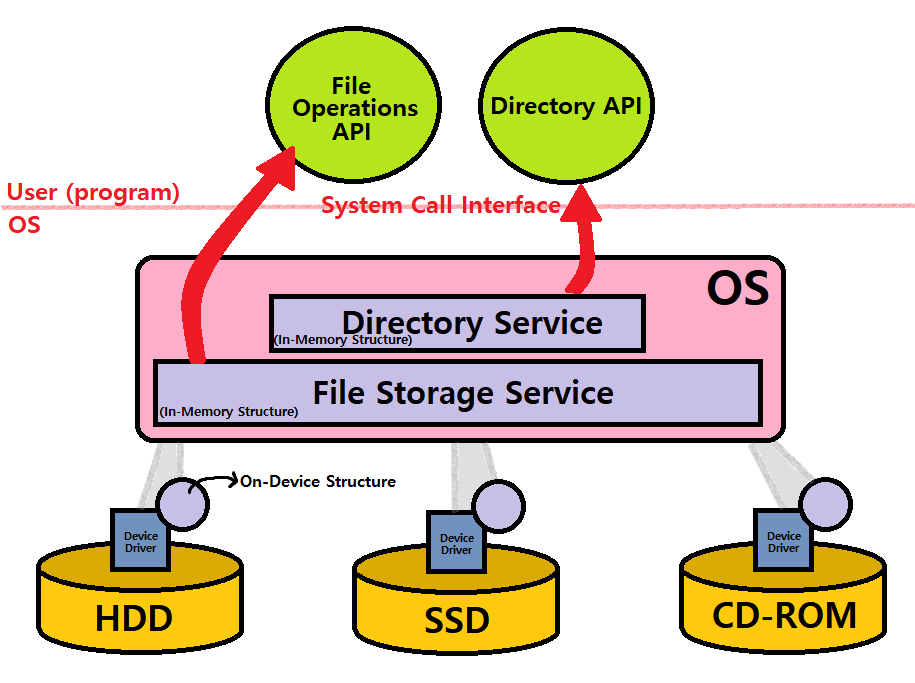
File System = In-Memory Structure + On-Device Structure
In-Memory Structure : Directory Service + File Storage Service
On-Device Structure : on all kinds of storage devicesOS File System services to User with APIs
앞서 이야기했던, OS의 세 가지 핵심 개념은 바로 여태까지 설명한 Virtualization, Concurrency, Persistence이다. OS는 이 세 개념을 구현하기 위한 일련의 노력들이 모여 이루어진 방대한 체계 SW라고 생각하면 된다. 우리는 앞으로 이와 관련된 Detail들에 대해 열심히, 깊이있게 알아볼 것이다.
OS Design Principles
지금까지 OS의 기저를 이루는 원리와 Issue들에 대해 간단히 알아보았다. 본격적인 개념 학습에 앞서, OS 설계 시 우리가 중점적으로 목표시해야하는 요소들에 대해 확인해보자.
-
Abstraction을 제공하자.
~> System을 편리하고 사용하기 쉽게 설계해야한다. -
좋은 성능(Performance)을 갖추도록 노력하자.
~> OS의 Overhead를 낮추면서, 동시에 Virtualization을 제공할 수 있어야 한다. -
Application Program들 간의 Protection을 제공하자.
~> Isolation을 통해, 하나의 Process가 다른 Process들, 또는 OS 그 자체에 악영향을 끼치는 것을 방지하자. -
Reliability를 높이자.
~> 중간에 멈춤 현상이 발생해선 안된다. Non-Stop 속성을 가져야 한다. -
Energy-Efficiency, Mobility, Security 등도 고려하자.
=> 이처럼, OS는 다양한 요소를 고려해 설계되어야 하고, 그를 위해선 우리가 이번 Operating Systems 개념을 확실하게 잡아야할 것이다.
OS History
여담으로, OS의 역사도 간단히 알아보자.
-
최초의 컴퓨터들은 OS라는 개념 자체를 가지고 있지 않았다. 컴퓨터가 지니고 있는 각 프로그램들의 Code를 모조리 집어넣어 HW와 연결시킨 후, 이를 동작시켜 오로지 '의도된 행위'만 하는, 그러한 단순한 시스템이었다. (Mainframe Computer)
- 이 과정에서 Operating System에 대한 필요성이 대두되었고, 1956년 IBM에서 최초로 OS를 개발하게 되었다.
-
초기 OS는 단순한 'Library들의 Set'으로서, 많은 일을 수행하질 않았다.
- 주로 Single User OS로서, Batch Processing Jobs에만 사용되었다.
- 당시 컴퓨터는 'Only run one program at a time'이었다.
-
그러던 중, User Mode와 Kernel Mode를 분리함으로써 OS는 Protection Mechanism을 구현하기 시작했다.
- User가 User Mode에서 System Call이라는 Interface를 통해서만 Kernel Mode에 제어권(Control)을 넘길 수 있게 하였음.
- ex) Trap, Interrupt, etc.
- User가 User Mode에서 System Call이라는 Interface를 통해서만 Kernel Mode에 제어권(Control)을 넘길 수 있게 하였음.
-
이후, Multiprogramming 개념이 등장하면서, Machine Resource의 효율적 사용에 대한 논의가 이뤄지기 시작했다.
- 이 과정에서 Memory Protection, Concurrency 등의 Issue들이 등장했다.
- 이 시기에 나온 것이 벨 연구소의 C 기반 'Unix OS'이다.
- 이것이 1960년대의 일이다.
-
현대에 와서는 OS가 모든 Computer System에서 중추적인 역할을 담당하기 시작했다. 단순히 개인용 PC를 넘어, 스마트 기기, 자동차, 비행기, 인공지능 등 여러 분야에서 널리 쓰이면서 말이다.
금일 포스팅은 여기까지이다. 앞으로 OS를 열심히 공부해보자.
