지난 포스팅에서 Operating System의 핵심을 구성하는 3대 Concept를 각각 Virtualization, Concurrency, Persistence라고 소개한 바 있다. 우리는 그 중 '가상화(Virtualization)'에 대해서 먼저 알아볼 것이다.
가상화에는 다음과 같이 두 가지 유형이 있다고 했다.
-
Process Virtualization
- Process Context Switch를 통한 Time-Sharing이 기반
-
Memory Virtualization
- Virtual Memory Address Space가 기반
우리는 먼저 Process Virtualization에 대해 알아볼 것이다. 오늘은, 기본적으로 Process란 것이 무엇인지, 그리고 Process와 관련한 API는 무엇이 있는지, OS에서는 이 Process를 어떤 원리로 가상화하는지에 대해 다룬다. 내용이 길어 복수의 포스팅으로 다룰 것이다.
Process
우리는 지난 System Programming 연재에서 Process란 'Running instance of a program'이라 배운 바 있다.
Process : Running Program
-
OS 입장에서 Program은 단순히 Main Memory에 올라가 있는 Byte 덩어리이다. OS에선 이를 Process라고 칭하는 것이다.
-
Program을 바라보는 두 가지 관점이 존재한다. 관점에 따라 관습적으로 Program이라 부르거나, 또는 Process라고 부르는 것이다.
-
"Program is a Passive Entity"
- Program이 Disk에 저장되어 있을 때, Program은 아무런 일을 하지 않는다. 그냥 컴퓨터에 저장되어 있을 뿐이다. 그저, Disk에 Executable File 형태로 저장되어 있는 'List of Instructions' File에 불과하다.
-
"Process is a Running Entity"
- Program이 Disk로부터 Main Memory로 올라가면, CPU는 Program Counter를 이용해 Program을 실행한다. 이때의 Running Program을 OS에선 Process라고 일컫는다.
-
즉, Program이 Disk에서 Executable File로 존재하다가, Main Memory로 Load되면 Process라고 불리는 것이다. ★
-
알다시피, 여러 Processes가 Program에서 생성될 수 있다.
-
우리는 이러한 Process에 대해, 'Job' or 'Task'라고 부르기도 한다.
- 다 같은 말이라고 보면 된다.
-
Process는 Main Memory에 'Code(Text)-Data-Heap-Stack'의 Sections와 Program Counter의 구조로 구성되어 올라간다.
- Disk에 저장된 Program File은 단순한 Byte 묶음이다. 이것이 메모리 올라가면, 아래 그림과 같은 구성으로 취급된다는 것이다.
- OS가 바라보는 Process의 구조 (아래 그림)
- Disk에 저장된 Program File은 단순한 Byte 묶음이다. 이것이 메모리 올라가면, 아래 그림과 같은 구성으로 취급된다는 것이다.
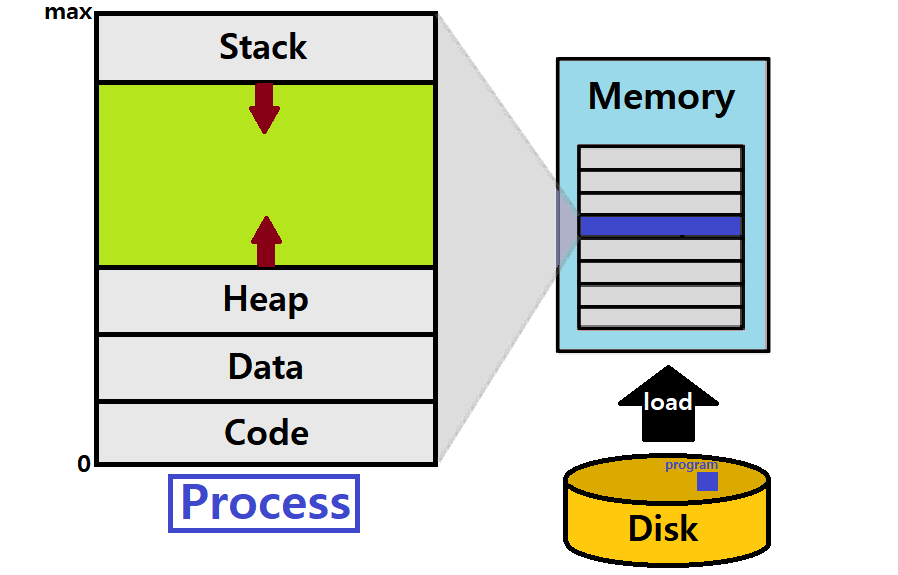
Time-Sharing
우리는 이미 'Process Virtualization'에 대해 지난 포스팅과 과거 SP 연재에서 다음과 같이 학습한 바 있다.
'Process Virtualization (Logical Control Flow)' by Process Context Switch
This means "CPU Virtualizing by 'Time-Sharing'"
"모든 Process가 각자의 CPU를 가져 동시에 수행되는 것처럼 보이는 현상"
그렇다. OS는 Process Context Switch를 바탕으로 한 Time-Sharing을 제공해 Process Virtualization, CPU Virtualization을 구현한다.
-
OS의 CPU Virtualization을 통해 '모든 Process가 각자의 가상 CPU를 가지고 있는 것'과 같은 Illusion이 발생한다.
-
Time-Sharing : 하나의 Process가 수행되고, 중간에 멈춘 다음, 이어서 다른 Process가 수행되고,.. 이런 과정이 매우 짧은 시간을 텀으로 두어 반복해 '마치 각 프로세스가 자신의 CPU를 두고 동시에 수행되는 것처럼 보이게 하는 현상'을 일으킴. 이를 Time-Sharing이라 한다.
- 이러한 Time-Sharing에선 'Performance(Potential Cost)'를 고려해야한다.
- Context Switch 시의 Overhead가 존재하기 때문이다.
- 이러한 Time-Sharing에선 'Performance(Potential Cost)'를 고려해야한다.
Process Details
Process Creation
Process Creation 절차를 살펴보자. 특정 API에 대한 언급은 아직 하지 않고, OS 관점에서의 Process 생성 과정을 살펴볼 것이다.
- (1) Program Code를 Memory에 Load한다.
-
가장 처음 할 일은 프로그램을 메인 메모리에 로딩하는 것이다.
-
프로그램은 Disk에 Executable Format의 File로서 저장되어 있다.
-
이러한 Program이 Memory에 Load된다.
-
현대 OS는 Process Loading을 Lazy하게 수행한다.
- Program Execution에 필요한 Code, Data Section만 우선적으로 로딩한다. ★★
Lazy Loading : OS가 Program을 Disk로부터 DRAM에 올릴 때, Program과 관련한 정보를 한꺼번에 모두 올리지 않고, 프로그램 실행에 필수적인 Code와 Data 영역만 로딩하는 것으로, Virtual Memory Concept를 토대로 구현된다. ★★★
프로그램 실행 과정에서 필요한 것이 생길때마다 그때그때 Load한다. ★
-
-
-
-
(2) Program의 Run-Time Stack이 할당된다.
-
메인 메모리에 프로그램이 올라오면, 이어서 Program의 Run-Time Stack을 초기화한다.
-
Stack은 보통 Local Variables, Function Paramaters, Return Address 등을 담는데, 이들은 Program Running의 필수 요소들이다.
- 따라서 Program 동작을 위해 이러한 Stack Set-Up이 이뤄지는 것이다. ★
-
만약 Program의 main Function이 argc, argv Array Arguments를 받는다면, 이들이 main의 Parameter로서 Stack 초기화 시 가장 먼저 마련된다. ★★
-
-
Default Stack을 구성하는 과정!
-
-
(3) Program의 Heap 영역이 생성된다.
-
Heap Section은 Program 수행 중간에 Dynamic하게 Explicit Allocate-Request가 생기는 것을 처리한다.
- 알다시피 C의 malloc()이나 free() 함수가 호출될 경우 사용된다.
-
위의 그림에서도 알 수 있듯, Stack과 Heap은 서로 마주보는 방향으로 진행한다. Stack은 낮은 주소 방향으로, Heap은 높은 주소 방향으로 말이다. ★★★
-
- (4) OS는 그 외의 나머지 초기 작업들도 수행한다.
-
I/O Setup이 이 과정에서 수행된다. ★
-
모든 Process는 Default 상태로서 3개의 Open File Descriptor를 가진다.
- Standard Input, stdin ~> 0번
- Standard Output, stdout ~> 1번
- Standard Error, stderr ~> 2번
-
이러한 과정이 선행되기 때문에 우리가 따로 File Descriptor를 지정해주지 않아도 최초의 Read/Write는 Shell 상에서 진행되는 것! ★
-
-
-
(5) main()이라 불리우는 Entry Point에서 Program Running이 시작된다.
- Program Counter가 Process의 main Function을 가리키면서 Program이 수행되기 시작한다.
"OS passes control of the CPU to the newly created process!"
Inside the Memory
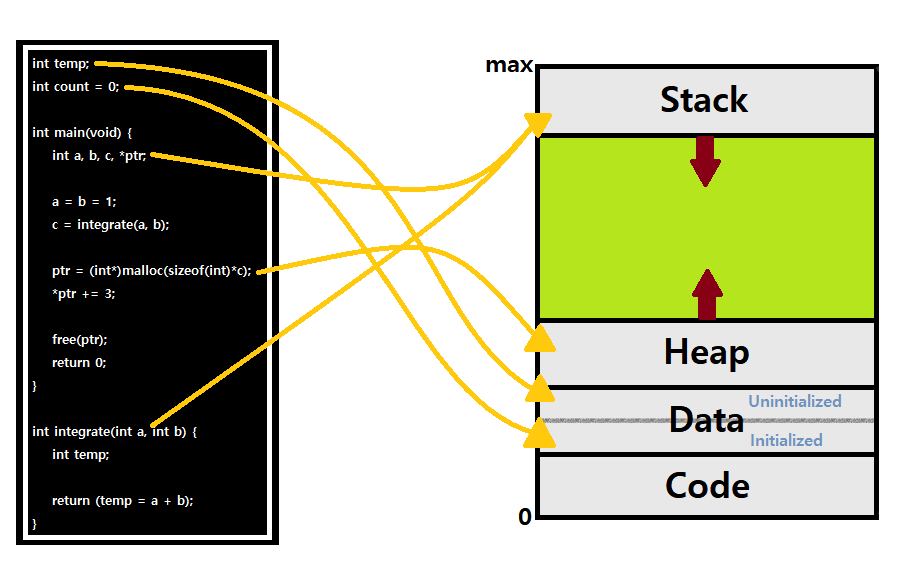
-
Stack : Local Variables, Function Parameters, Return Address와 같은, Program 수행 과정에서 지속적으로 변화하는 Temporary Data를 저장한다.
- LIFO(Last-In, First-Out)의 원리를 따른다.
-
Heap : Process Run-Time에 Explicit Dynamic Memory Allocation으로 생성된 Data들을 저장한다.
-
Data : Global(Non-Local) Variable들을 저장한다.
- Initialized와 Uninitialized로 구분해서 관리한다. (Programming Language 과목에서 확인 가능)
-
Code(Text) : Program Code를 Sequence of Instructions 형태로 저장한다.
Process States
모든 Process에는 State가 존재한다. 대표적으로 3가지 종류의 State가 있고, OS 구현 방식에 따라서 달라질 수 있다. 우리는 기본적으로 UNIX 계열 OS에서의 Process States에 대해 알아볼 것이다.
-
Ready State : Process가 Running할 준비는 되어 있는데, 아직 OS로부터 선택되지 않아 Schedule되어 있지 않은 상태로, '(실행) 대기 상태'이다.
-
Main Memory에는 이미 적재되어 있는 상태이다. ★★★
-
Ready State Process들은 특정한 Queue에 보관되어 있다.
- OS는 Scheduling Algorithm에 의거해 이러한 Queue를 관리한다.
-
-
Running State : Process가 CPU Control를 지닌채 Processor에서 실행되는 상태
- 실제 CPU에서 수행하는 것이 기준이 아니라, Schedule되었는지가 기준이다. ★★★
- 따라서, Single-CPU의 경우, 한 시간 단위에 오로지 하나의 Running State Process만 존재한다. ★★★
- 실제 CPU에서 수행하는 것이 기준이 아니라, Schedule되었는지가 기준이다. ★★★
-
Blocked State : Process가 I/O나 Event 대응 등의 연산을 수행하는 상태로, CPU 제어권을 잃고, Ready되지 않는 한 CPU를 제어할 일이 없는, 그러한 상태이다.
-
예를 들어, Process가 I/O Request를 Disk에 보낸다고 해보자. I/O는 CPU 외부 장치와 소통하는 과정이기 때문에 CPU에 비해 시간 소모가 매우 크다. 만약, I/O를 요청해놓고 마냥 기다리기만 한다면 CPU Cycle이 낭비되는 것이다.
- 따라서, I/O를 요청해놓고, 그 응답을 기다리는 Process를 아예 Block시키고, 다른 Process에게 CPU 이용을 넘기는 것이다.
-
Blocked State Process가 '모종의 이유(예를 들어 요청했던 I/O Operation이 완료)'로 Block 상태가 해제되면, Ready State로 Transition한다. ★★
- 바로 Running State가 되는 것이 아니다. ★★★
-
~> 이처럼, 여러 Process들이 각자 State를 가지고 Transition해가는 일련의 과정을 OS가 관장하는 것이다.
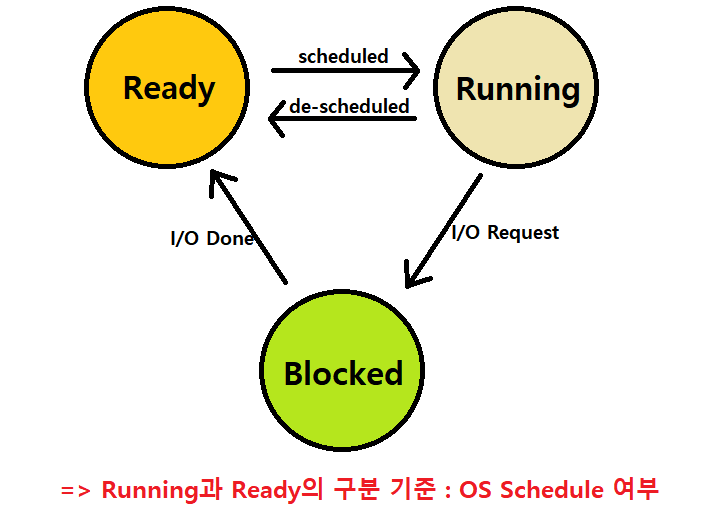
~> 'de-scheduled'를 'preempted'라고도 한다. ★
아래의 Example들을 보면서 위에서 설명한 Transition 관계를 좀 더 자세히 이해해보자. (단일 CPU 상황 가정)

~> 간단한 Example이다. ProcessA가 먼저 Schedule되어 CPU 제어권을 얻어 Running State가 되었다고 가정하자.
~> Running ProcessA가 4-Times를 흐르고 나서 종료되었다.
~> 이어서, Ready State였던 ProcessB가 CPU Control을 얻도록 Schedule되어 Running State가 된다.

~> 이번엔 I/O Event가 있는 Example이다. ProcessA가 먼저 Schedule되어 CPU 제어권을 얻어 Running State가 되었다고 하자.
~> 4번째 Time에서 ProcessA가 I/O Request를 보내 잠시 Blocked된다. ProcessA가 Blocked State가 되었으니, Ready State였던 ProcessB가 CPU Control을 얻어 Running State가 된다.
~> 그러던 중, ProcessA의 I/O Operation이 완료되어 ProcessA가 Blocked State에서 Ready State로 Transition한다.
~> 아직 ProcessB의 Time-Quantam이 지나가지 않아 이 상태로 몇 Time을 더 흐른다.
~> ProcessB가 수행이 종료되고, 이어서 ProcessA가 Schedule되어 Running State로 변화한다.
Blocked State에서 'I/O Operation 완료'와 같은 이유로 Block이 해제되면, 바로 Running State가 되는 것이 아니라, Ready State가 된다.
OS의 Scheduling Algorithm을 따라 추후 Running State로 변화할 것이다. ★
Time-Sharing 시에는 일정 Time-Quantam(일반적으로 10ms)을 기준으로 Process Context Switch가 일어난다.
CPU Control을 얻은 Process가 종료될때까지 무작정 Running하는 것이 아니다. ★
PCB(Process Control Block)
OS는 상기한 Process Context Switch를 구현하기 위해 특정 Data Structures를 운영한다. 대표적으로 PCB(Process Control Block)와 Process List가 있다. 우선, PCB부터 알아보자.
-
PCB(Process Control Block) : Process의 '중요한 정보 Context'를 저장하고 있는 Block으로, 각 Process에 대해 하나씩 존재한다. in Kernel Area
-
Registers 정보도 담고 있다.
- 이를 'Register Context'라고도 하는데, 이를 통해 Process의 State를 알 수 있다.
-
PID(Process ID), PC(Program Counter), Registers(수행하면서 사용한 데이터 값들), Memory 제한, Open File 정보 등을 담고 있다. ★★★
-
이러한 PCB는 Process Creation 시에 동적으로 할당되고, Process 종료 시까지 유지된다. ★★★
-
Process List
앞서, OS는 Ready State Process들에 대해 특정 Queue를 마련해 기록해둔다고 언급했다. 그러한 Queue를 바로 'Process List'라고 부른다.
- Process List : 메모리에 상주하고 있는, 이미 Creation이 이루어진 Process들을 연결시켜서 유지/관리하는 자료구조로, Queue의 구조를 가지며, PCB를 Node로 한다. ★★★
- Ready Queue : Ready State Process들을 추적한다.
- Blocked Queue : Block State Process들을 추적한다.
- Current Running Processes도 추적한다.
~> 이처럼, 여러 'Process List(Queue)'들이 존재한다. 참고로, 이때 Queue라 함은, 단순히 FIFO(First-In, First-Out) 구조의 Queue를 의미하는 것이 아니라 Deque이나 Priority Queue와 같은 다양한 Queue들을 의미한다. ★★
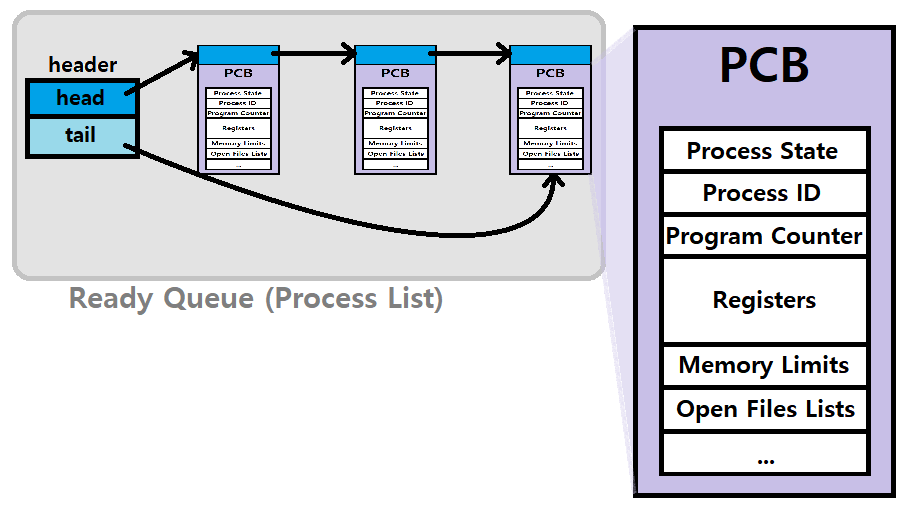
위 그림은 PCB와 Process List를 보여주고 있다. 이러한 Process List에는 상기한 Ready Queue부터, Mag Tape Unit, Disk Unit, Terminal Unit 등 다양한 Queue들이 존재하고, 이들에 대한 상세한 설명은 추후 진행한다.
Structures for PCB
운영체제는 SW다. 즉, 여타 다른 Application Program이나 System Program과 같이, 당연하게도 High-Level Language로 구현된다. 주로 C로 구현하는데, 자세한 것은 차치하고, 앞서 언급한 PCB 역시 마찬가지로 Code로 구현된다(당연한 서술이다). 어떻게? 바로 구조체를 이용해서 말이다.
어떤 Operating System SW든, PCB를 표현하는 Structure는 OS의 가장 중요한 구조체 구현 중 하나이다. ★★★
MIT 대학에서 만든 교육용 운영체제 커널 xv6 Kernel에선 아래와 같은 'proc'이란 구조체로 PCB를 표현한다. Register Context와 State를 어떤 변수들로 표현하는지 주목하자.
struct proc { // xv6의 PCB 구조 ★★★
char *mem; // Process Memory의 시작점
uint sz; // Process Memory의 사이즈
char *kstack; // 해당 Process에 대한 Kernel Stack의 Bottom
enum proc_state state; // Process State (enum Type으로 나타냄)
int pid; // Process ID
struct proc *parent; // Parent Process
void *chan;
int killed; // Killed인 경우 양수를 대입한다.
struct file *ofile[NOFILE]; // Open Files
struct inode *cwd; // Current Working Directory (현위치)
struct context context; // Process 수행을 위해 Switch하는 부분 (Registers)
struct trapframe *tf; // 현재 Interrupt에 대한 Trap Frame
};
struct context { // Register Context (Registers)
int eip; // Index Pointer Register
int esp; // Stack Pointer Register
int ebx; // Base Register
int ecx; // Counter Register
int edx; // Data Register
int esi; // Source Index Register
int edi; // Destination Index Register
int ebp; // Stack Base Pointer Register
};
enum proc_state { UNUSED, EMBRYO, SLEEPING, RUNNABLE, RUNNING, ZOMBIE };
// Process States are in enum type우리가 흔히 접하는 Linux에서의 PCB 구조는 다음과 같다. task_struct라는 이름의 구조체로 구현되어 있다(Linux 'task_struct'의 경우 구조체 하나가 600줄에 육박하기 때문에 Code-Level이 아닌 그림으로 대체한다). Process Descriptor라고도 한다.
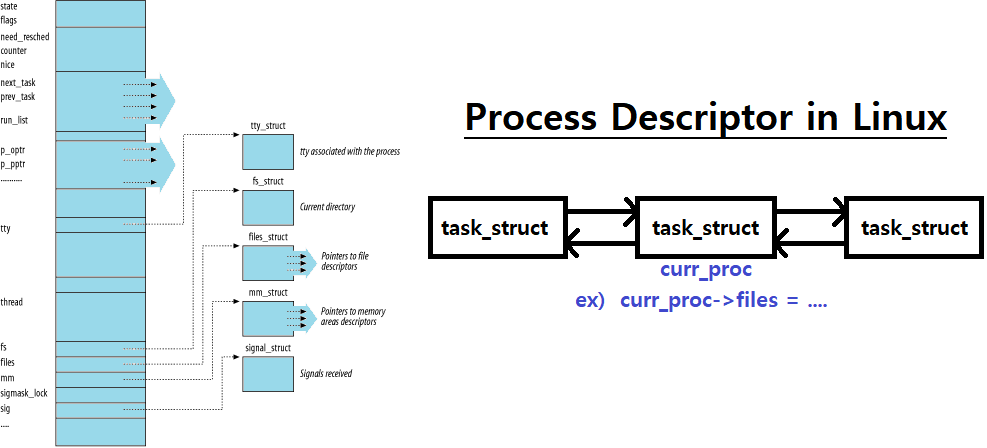
~> 현재 수준에선 Linux Process Descriptor의 각 Field를 일일히 분석하는 것은 중요치 않다. 이러한 Structure를 이용해 PCB를 표현한다는 것을 기억하는 것이 중요하다. (추후, pintOS 구현을 통해 PCB를 좀 더 자세히 이해할 수 있다. pintos/src/threads/thread.h 참고!) ★
~> 이러한 Structure를 Node로 한 Linked List 형태의 Queue(Process List)가 운용된다. 따라서, 이론적으로 Process 생성 가능 개수는 무한대이다.
Process ID & Process Tree
Process는 'Process Identifier'인 'Process ID', 약칭 PID로 구분되고 관리된다. 주민등록번호와 같은 역할을 한다고 보면 된다.
-
Process ID는 Process가 생성될 때마다 특정 규칙에 따라서 할당된다.
-
한편, Process의 생성은 항상 Parent Process가 Child Process를 생성하는 형태로 이뤄진다. 이것이 곧 '다른 Process 생성'이다.
- 이러한 '부모-자식' 관계가 여러 형태로 나타나, 궁극적으로 Process들의 Tree 형태를 형성한다.
- 이러한 관계성에서 기인해 'Process Tree'라는 개념이 등장한다.
- 이러한 '부모-자식' 관계가 여러 형태로 나타나, 궁극적으로 Process들의 Tree 형태를 형성한다.
Linux System에서 Process Tree는 아래와 같다.
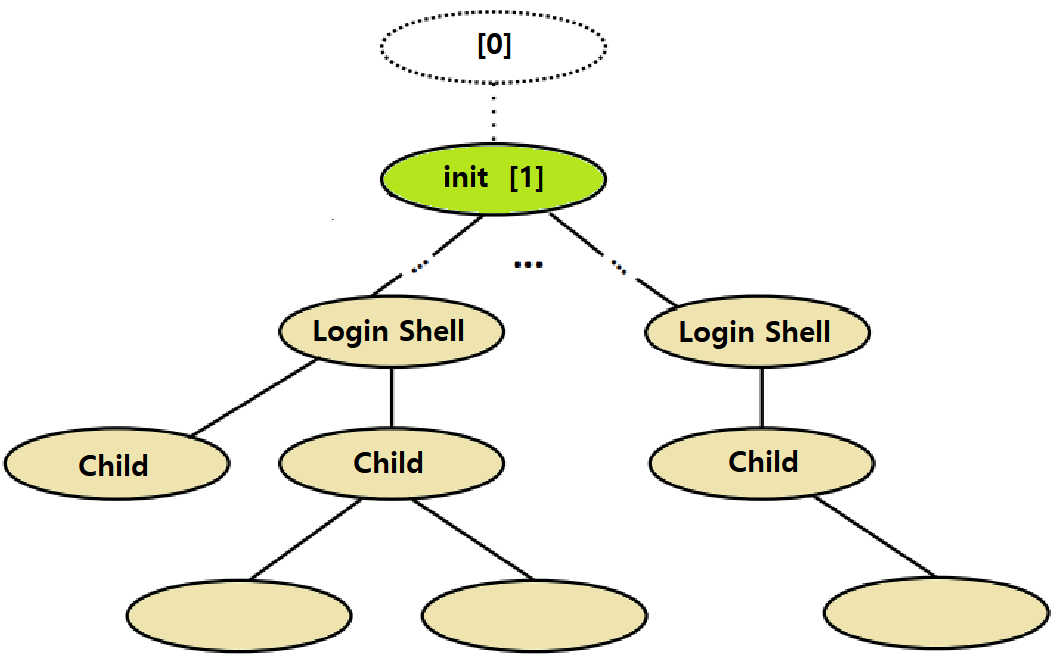
~> Linux 부팅 시 자동 생성되는 '가장 첫 번째 Process'는 init Process로, PID 1번에 해당하며, Process Tree의 Root 역할을 한다. ★
=> 과거 SP 연재에서, 이러한 init Process는 Orphaned Process의 Reaping에 기여한다고 배운 바 있다. 이에 관해서는 이후 좀 더 자세히 설명한다.
~> init으로부터 여러 Process들이 뻗어서 생겨나고, 그 중 상단 Level에는 Login Shell들이 있음을 기억하자.
=> Login Shell에는 bash, tcsh, ssh 등이 있겠다.
Process API
지금까지, Process가 무엇인지, Process Creation 과정은 어떻게 진행되는지, Process Virtualization을 위해 OS에서는 어떤 운영 방식을 채택했는지에 대해 개괄적으로 알아보았다. 해당 개념들에 대한 상세한 학습에 앞서, 잠시 Process 관련 API에 대해서도 짚고 넘어가자.
지난 포스팅에서 우리는 POSIX, Win32 등의 API에 대해 잠시 언급한 바 있다. 이러한 API들은 OS 위에서 Process에 대한 작업을 가능케 한다. 여러 API에는 다음과 같은 기능들이 공통적으로 들어있다.
- Create Process : 새 Process를 생성한다.
- ex) fork() of POSIX
- Destroy Process : 진행되는 Process를 종료(Halt)한다.
- ex) exit() of POSIX
- Wait for Process : Process가 수행을 멈출 때까지 Wait한다.
- ex) wait() of POSIX
- Suspend & Resume Process : Process를 중단시키거나 다시 실행시키는 기능도 포함한다.
- ex) pause() of POSIX
- Status of Process : Process에 대한 몇 가지 정보를 확인한다.
- ex) getpid() of POSIX
여러 API들 중, 우리는 POSIX API에 주목할 것이다. POSIX API는 System Programming 연재에서 이미 수차례 사용한 바 있는 익숙한 API로, POSIX라는 이름은 'Portable Operating System Interface'의 약자이다. UNIX 계열 OS에서 공통으로 사용할 수 있는 API들을 정리한 것으로, Portability가 높은 UNIX Application Program 개발 시에 유용히 사용할 수 있는 API이다. IEEE에서 공식화한 규격이다.
fork( ) System Call
-
Parent Process는 fork( ) System Call을 이용해 Child Process를 생성한다.
- Child Process는 Parent Process의 Address Space를 그대로 복사해 생성된다.
- Code, Data, Heap, Stack은 당연하고, PC, Open Files 등까지 모두 복사한다. ★
- Child Process는 Parent Process의 Address Space를 그대로 복사해 생성된다.
-
fork는 한 번 호출에 두 번의 Return을 수행하는데, Parent Process에게는 Child Process의 PID를, Child Process에게는 0을 Return한다.
- 그말은 즉슨, fork의 Return Value가 음수이면 Error 상황이다.
Parent Process와 Child Process는 fork Return Value와 PID만 다르다.
아래와 같은 간단한 fork 예제를 확인해보자. 익숙할 것이다.
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int main(int argc, char *argv[]){
printf("PID : %d\n", (int)getpid());
int ret = fork();
if (ret < 0) {
fprintf(stderr, "fork error\n");
exit(1);
}
else if (ret == 0)
printf("Child PID : %d\n", (int)getpid());
else printf("Parent PID : %d\n", (int)getpid());
return 0;
}(출력1)
> ./fork_example
PID : 12345
Parent PID : 12345
Child PID : 12346
>
(출력2)
> ./fork_example
PID : 12345
Child PID : 12346
Parent PID : 12345
>
~> Scheduling 상황에 따라서 Parent나 Child 중 누가 먼저 Running할지가 결정된다. 따라서 위와 같이 출력 양상이 두 가지가 존재한다.
wait( ) System Call
UNIX 계열 System의 특징은, Process들이 Creation되면, Parent가 반드시 Child를 Care해야한다는 것이다. Child Process가 가지고 있던 PCB를 Parent Process가 직접 회수해주어야 한다. 만약, 이를 그냥 냅두면 Child Process에 대한 Data가 OS 내의 자료구조들에 남아있게 되고, 이는 곧 Zombie Process가 됨을 의미한다.
Zombie Process란, Process가 종료되긴 했지만, OS 내에 PCB 등의 데이터들이 여전히 남아있는 상태의 Process를 의미한다. 이는 알다시피 System 성능 저하의 대표적 요인으로, Memory Leakage, Security Hole 등의 문제를 야기한다.
이때, wait 또는 waitpid와 같은 System Call을 통헤 Child Process의 상태를 알아내고, Reaping할 수 있다.
-
wait(&status) System Call은 Child Process가 종료될 때 Parent Process에게 Exit Status를 전달할 수 있게 한다. ★
- 즉, Parent Process는 wait( )을 통해 Child Process가 '어떻게 종료되었는지' 알 수 있다. ex) WIFEXITED, WNOHANG 등의 인자를 통해!
-
Exit Status는 'Process Table(자신이 생성한 Children에 대한 정보를 담고 있는 Table)'에 저장된다. 그리고 종료된 Process의 Process Table Entry는 Parent Process가 wait( ) Call을 한 후 Signal을 받아 Reaping될 때 해제된다. ★
- 이 모든 과정이 pintOS 구현 시 나타날 것이다. 추후 소개하겠다.
-
만약 Parent Process가 wait( )을 Call하지 않으면, Child Process에 대한 Process Table Entry가 Process Table에 그대로 남아있게 되고, 이는 곧 Zombie Process가 됨을 의미한다. ★★
- "Process Table에 Child Process의 Process Table Entry, 정확히는 PCB가 남아있는 것이 바로 Zombie Process State"
-
Parent는 wait( ), waitpid( )와 같은 System Call을 통해 Child Process의 Exit Status를 알 수 있고, OS Process Table에 남아있는 Zombie Child Process를 제거할 수 있게 한다. (OS가 제거한다) ★★
- 이것이 바로 Reaping인 것!
wait에 대한 이해를 도모하기 위해 아래와 같은 예제를 들 수 있다.
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/wait.h>
int main(int argc, char *argv[]){
int ret, wc;
printf("Hello World! (PID : %d)\n", (int) getpid());
ret = fork();
if (ret < 0) { // fork 실패 시엔 fork 리턴값이 음수!
fprintf(stderr, "fork failed\n");
exit(1);
}
else if (ret == 0) // Child Process Routine
printf("This is Child (PID : %d)\n", (int) getpid());
else { // Parent Process Routine
wc = wait(NULL); // Reaping Routine: get Exit-Status
printf("This is Parent (PID : %d)\n", (int) getpid());
}
return 0;
}(출력)
> ./p2
Hello World! (PID : 12300)
This is Child (PID : 12301)
This is Parent (PID : 12300)
>
~> Parent Process 코드부에 wait System Call을 둠으로써 Parent가 Child Process Termination을 기다리게 하고, 이를 통해 Parent와 Child의 수행 순서를 고정하고 있음에 주목하자. (wait의 또 다른 효능. 나머지는 Exit Status를 알 수 있는 점, 그리고 Reaping할 수 있는 점) ★★★
금일 포스팅은 여기까지이다. 아직까지는 대부분 SP에서 열심히 설명했던 개념들이기 때문에 간단히 설명하고 넘어간다. 따라서 혹여나 개념 설명이 부족할 경우 SP 연재 포스팅들을 찾아보길 권장한다.

비전공자로서 fork에 대한 내용을 찾다가 들어오게 되었는데, 이런 양질의 자료를 볼 수 있게 해주셔서 감사합니다.