Direct Execution
Process Creation 과정을 돌이켜보자.
-
(1) Load : OS는 Program Code를 Memory의 Process Address Space에 Load한다. 즉, Program이 Process가 되는 것이다.
-
Program을 Load하기 전, Program은 Disk에 Executable Format으로 저장되어 있다.
ex) a.out이란 Program이 Disk에 Executable Format으로 Reside! -
이때, OS는 Lazy Loading 방식으로 Process Loading을 진행한다.
Lazy Loading : Code(Text)와 Data Segment에서 Program Execution에 필수적인 일부분만 Loading하는 것으로, Demand Paging, Demand Segmentation이라고도 부른다.
Demand의 의미 : 필요한 것들만 올린다는 것!!!
Virtual Memory Concept를 토대로 구현
-
-
(2) Run-Time Stack Set-Up : Stack은 Local Variable, Function Parameter, Return Address 등을 담는데, 이러한 Run-Time Stack을 초기화한다.
- 이때, main함수의 Parameter인 argv, argc도 초기화된다.
- Registers 초기화도 이 단계에서 진행된다. ★
-
(3) Heap Creation : Explicit Dynamic Memory Allocation 시에 필요한 Heap 영역을 생성한다.
-
(4) OS의 추가적인 Initialiation 작업들이 수행된다.
-
I/O Set-Up
-
Process의 Default File Descriptor 3개가 할당된다.
- STDIN, STDOUT, STDERR
-
File Descriptor Table 초기화 등의 작업이 여기서 이뤄진다.
-
-
-
(5) OS는 main()이라는 Entry Point에서부터 Program Running을 수행한다.
- OS가 CPU 제어권을 새 Process에 넘긴다. ★
~> 기억나는가? 이것이 바로 Process Creation의 과정이었다.
이러한 Flow의 Process Execution을 가장 빠른 성능으로 수행하는 방법엔 무엇이 있을까? 간단히 생각해보면, Process를 그냥 CPU 위에서 Direct하게 돌리면 가장 빠를 것이다. Program 실행 중간에 별다른 처리없이 말이다. 이를 'Direct Execution'이라 한다.
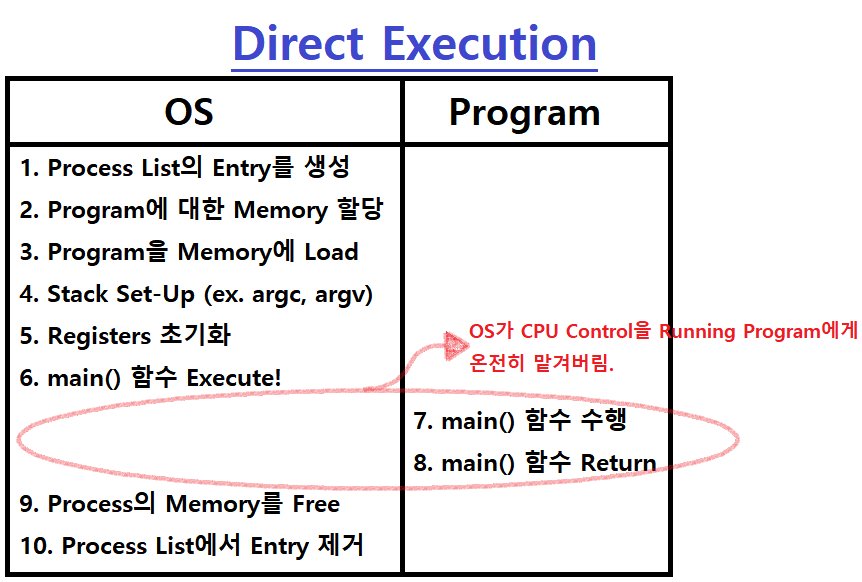
Direct Execution : Program이 수행되기 시작하면, OS의 별다른 도움 없이 Program을 CPU 위에서 Direct하게 돌리는 것
위의 그림처럼, OS가 Program에 대한 초기, 후기 작업만을 담당하고, Program이 시작되고 나선 CPU 제어권을 오로지 Program에게 넘기는 것!
즉, Running Program에게 Limit을 걸지 않는 것이다.
이렇게 되면, OS는 사실상 Program 수행 중간에는 그저 Library로서의 역할만 수행하는 것이다. (Direct Execution) ★★★
~> 즉, 상기한, 여태 소개했던 Process Creation은 Direct Execution 방식이라고 봐도 무방한 것이다. Program Execution이 시작되고 나서의 OS의 업무를 전혀 명시하지 않았으므로!!
Problems
이러한 Direct Execution은 하나의 Process Execution에 대한 Performance는 높아질지 몰라도, 아래와 같은 문제점들이 존재한다.
-
Problem 1 : Process가 Restricted Operations를 수행하고자 할 때 문제가 발생한다.
-
Restricted Operation이라 함은, Disk에 대한 I/O Request나, CPU/Memory와 같은 System Resource에 대한 접근 요청 등을 의미한다.
-
OS의 도움없이 Restricted Operation을 수행한다고 해보자. 모든 Process가 어떠한 작업이든 수행할 수 있게 되면, System의 중요 부분에 대한 접근 및 변형이 가능해질 터이고, 나아가 System 전체를 다운시키는 것과 같은 치명적인 문제가 발생할 수 있다. ★
-
- Problem 2 : Process Context Switch를 어떻게 구현할 것인가?
- 만약, Program Running 시 OS가 Library로서의 역할만 수행한다면, Process Virtualization의 핵심인 Process Context Switch와 같은 일을 어떻게 할 것인가.
- CPU로부터 제어권을 가져온다는 것은 쉬운 일이 아니다.
- 어떤 Program이 무한 루프를 돈다고 해보자. exit이 일어나지 않는 구조인 것이다. 만약 이러한 Program이 CPU 위에서 돌아가는데, OS가 별다른 일을 하지 못한다면 CPU 제어권을 어떻게 가져올 것인가? 방법을 생각해보라. 그렇다. 마땅한 방법이 떠오르지 않을 것이다. 그저 Program이 끝나길 하염없이 기다릴 뿐...
- CPU로부터 제어권을 가져온다는 것은 쉬운 일이 아니다.
- 만약, Program Running 시 OS가 Library로서의 역할만 수행한다면, Process Virtualization의 핵심인 Process Context Switch와 같은 일을 어떻게 할 것인가.
Limited Direct Execution
그래서 등장하는 개념이 바로 'Limited Direct Execution'이다. 쉽게 말해, Process를 CPU 위에서 Direct Execution하되, OS를 이용해 몇 가지 Limit을 제공해 Virtualization을 구현하고, Process Switching도 가능케 하는 것이다.
Dual Mode Operation
위에서 소개한 Direct Execution의 Problem 1인 'Restricted Operations'에 대한 Solution이 바로 'Dual Mode의 도입'이다.
Dual Mode는 Direct Execution 시 SW에 아무런 Limit이 없어 생기는 'Restricted Operation 접근 가능성 문제'에 대한 Solution이다.
Dual Mode : 두 개의 Mode를 만들어 Process의 부분과 OS의 부분을 나누어, OS가 자기 자신과 다른 System Component들을 보호할 수 있게 만들어준다.
Dual Mode = User Mode + Kernel Mode ★★★
- User Mode와 Kernel Mode로 구성된다.
- Kernel Mode는 Supervisor Mode, System Mode, Privileged Mode로 구분된다.
-
특정 Instruction들은 'Privileged'로, 오로지 Kernel Mode에서만 수행될 수 있다.
-
즉, User Mode에선 사용할 수 없다.
-
User Mode에 있는 Process는 Privileged Operation을 수행할 수 없다.
- 만약 수행하려고 시도할 경우, CPU는 Exception을 발생시켜 OS가 해당 Process를 죽이도록 만들 것이다. ★
-
이러한 Privileged Operation에는 I/O Request, File System Request 등이 있다.
-
~> 즉, User Mode에 있는 Process에서는 Non-privileged Operation만 수행할 수 있는 것이다. Privileged Operation을 사용하려고 시도하면 OS가 Exception을 발생시켜 해당 User Program을 Kill하는 것이다.
~> Kernel Mode에서는 당연히 Non-privileged/Privileged Operation을 모두 사용할 수 있다.
~> 허나, User Mode의 Program도 당연 I/O Request와 같은 Privileged(Restrictive) Operation이 필요하고, 따라서 User는 System Call과 같은 Interface를 통해 Kernel Mode 전환를 이뤄내는 것이다.
-
System Call은 User Mode를 Kernel Mode로 전환시킨다. System Call이 Return할 때, User로 돌아간다.
- System Call 함수는 내부적으로 Trap(Interrupt) Instruction을 일으키고, OS는 이 Trap(Interrupt) Instruction의 Return 시 Kernel Mode로 전환되도록 해준다. ★★★
-
이러한 Mode는 HW의 Mode Bit라는 것으로 관리된다. ★
- System은 Mode Bit를 통해 User Code가 Running 중인지, Kernel Code가 Running 중인지를 구분한다.
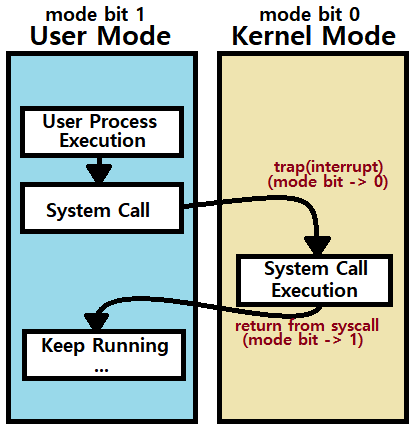
~> read, write와 같은 System Call 시 이처럼 Dual Mode Operation Concept를 이용한 처리가 이루어지는 것이다. ★★★
Interrupt Handling
위에서 Interrupt Handling 과정이 언급되고 있다. 과거 SP에서 다루었던 Exception 개념이 기억나는가? 이때의 개념을 SW 관점에서 간단히 풀어써보겠다.
-
Interrupt는 CPU 제어권(Control)을 Interrupt Service Routine인 Interrupt Handler로 넘긴다.
-
이때, 'Interrupt Vector Table (IDT, Interrupt Descriptor Table)'이 있는데, 이들은 각각의 Handler에 대한 Address를 담고 있다.
-
일반적으로 이러한 Vector는 Memory의 낮은 주소에 저장되어 있다.
-
각 Interrupt에 대응하는 Interrupt Handler를 포인팅하는 역할인 것!
-
-
이러한 Interrupt Handler들은 OS의 부분으로, 즉, CPU Control이 Kernel로 넘어가는 것이다. ★
-
-
Interrupt Architecture는 Interrupted Instruction의 주소를 반드시 저장해야한다. ★
-
이러한 Interrupt에는 여러 종류가 있는데, 그 중 Trap Exception은 SW가 발생시킨 Interrupt로서, Error 발생 시, 또는 User Request로 인해 발생한다.
- SP에서 다루었던 Exception의 범주가 기억나는가? Interrupt, Trap, Fault, Abort 등이 있었다. Interrupt는 I/O같은 외부 장치 관련, Trap은 System Call과 같은 User Program 관련, Fault는 SegFault와 같은 Paging 관련, Abort는 HW Failure 관련임을 배운 바 있다. 이 중 Trap을 의미하는 것이다.
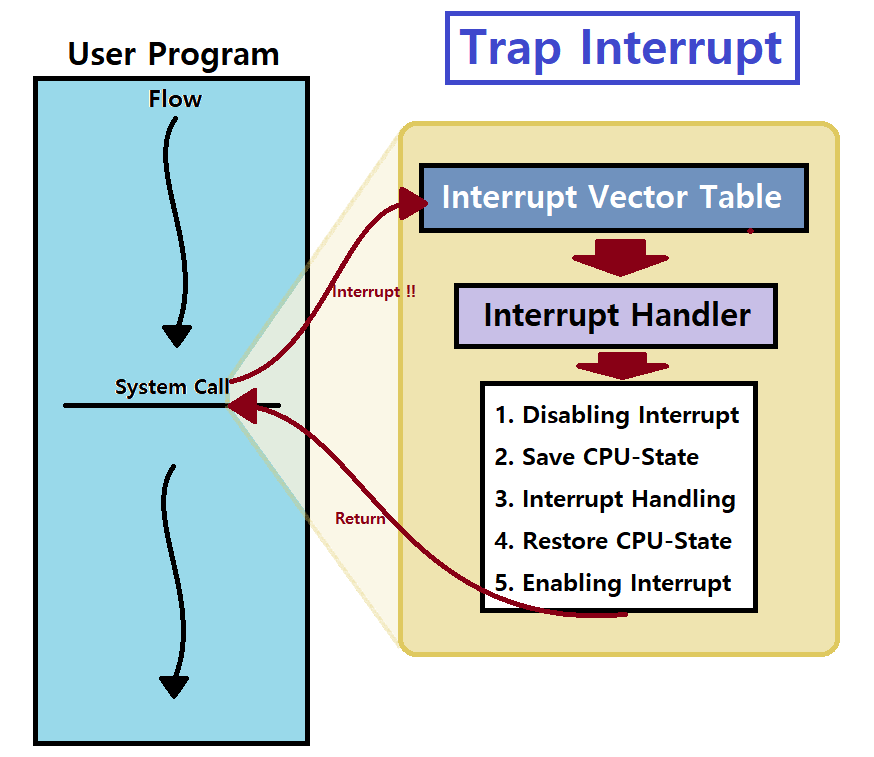
아래 그림은 Trap Interrupt 시의 동작 Flow를 나타낸다.

~> User Program이 쭈욱 수행되다가 Trap Interrupt 발생 시, 해당 Interrupt가 가리키는 Service가 무엇인지를 Interrupt Vector Table을 통해 찾고, 그에 대한 Interrupt Handler가 저장되어 있는 OS 내의 Address가 어딘지를 찾아내 그 주소로 따라간다.
~> 그 다음, Interrupt를 Disabling하고, Interrupt 시점의 Program의 Processor-State를 기억시켜놓는다. (복구 목적으로)
~> 이어서, Interrupt Handler가 Service를 수행하고, 수행을 마치면 다시 Processor-State를 Restore한다. (이 과정에서 'Service'는 간단히 표현한 것이다. 아래에서 그 내막을 좀 더 자세히 알 수 있다.)
~> Interrupt를 Enabling한 후, User Program에서 Trap을 발생시켰던 Instruction 다음의 명령으로 복귀한다. (Trap의 특징)
Overall Flow Description
System Call은 Kernel이 User Program에게 중요 기능을 제공하는 매개체로서, 그러한 중요 기능에는 File System 접근, Process 생성 및 해제, Process 소통, Memory 할당 등이 있다.
System Call : User Program이 원하는 OS의 Fuctionality를 사용할 수 있도록 API 형태로 만들어서 Library로 제공하는 것!
즉, User Program이 System Call을 통해 Trap Interrupt를 발생시키고, 그에 대한 Handler가 동작하면서 각 종 OS Fuctionality를 User Program이 사용할 수 있게 되는 것이다. CPU Control이 User Mode에서 Kernel Mode로 넘어가면서 말이다. 이러한 전체적인 Flow를 우리는 다음과 같은 그림으로 확인할 수 있다. 이제 조금 더 디테일하게 설명할 것이다.
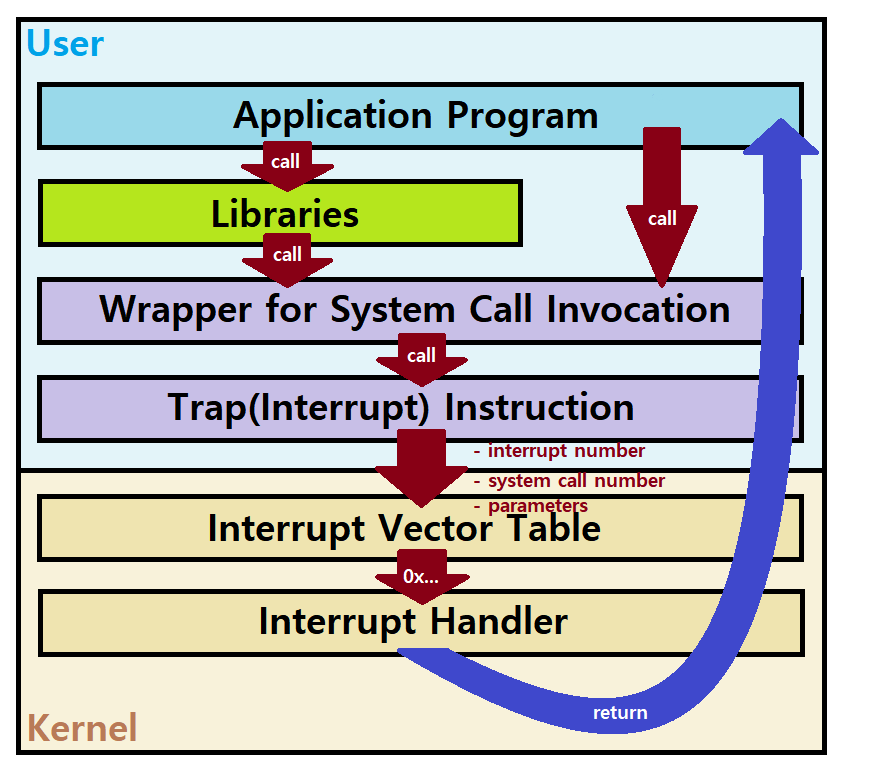
- Application Program에서 Program Execution이 이뤄지다가, 어느 시점, open() 함수를 호출했다고 해보자. (C Language 가정)
-
open 함수를 이루는 가장 겉 껍데기는 당연 C Library open Function이다. 따라서, C 런타임 라이브러리를 참조한다.
-
해당 라이브러리 함수는 System Call을 위한 Wrapper를 호출한다.
-
C 언어와 Unix System을 기준으로, System Call을 할 때, 곧바로 System Call이 시작되는 것이 아니라, 특정 Function이나 Macro의 형태로 System Call Invocation을 담당하는 중간 단계가 포함된다. (이유 ASM 코드를 반복적으로 사용해야하기 때문)
-
즉, 특정 함수나 매크로로 Wrapper를 두어, 그 안에서 System Call을 도모하는 것이다.
-
이러한 Wrapper 내부에는 Interrupt Instruction이란 것이 존재한다. ★★★
-
Trap Instruction이라고도 부르는 이것은, 'Trap Interrupt를 발생시키는 일'을 하는 명령으로, User가 OS에게 Interrupt를 발생시키고자 할 때 사용하는 명령이다. ★★★
-
이러한 Interrupt Instruction은 Assembly Level로 작성된다.
-
x86 System 기준으로 0x80, pintOS 기준으로 0x30이 이러한 Instruction에 해당한다. x86에선 이를 INT라고 줄여 부르기도 한다. Software Interrupt를 발생시키는 Instruction이라고 이해하면 된다.
모든 Software Interrupt는 이 Trap(Interrupt) Instruction을 필요로 한다.
-
여기서 발생한 Interrupt Instruction은 Kernel 내부의 Interrupt Vector Table로 전달된다.
-
이때, 지금까지는 이전 단계에서 이후 단계를 단순히 Call하는 것이었다면, 이 단계에서부턴 몇 가지 중요 Data를 함께 넘긴다.
-
Interrupt Number, System Call Number, Parameters 등이 Interrupt Vector Table로 넘어간다.
-
Interrupt Vector에서는 넘겨받은 Number 정보를 토대로 상응하는 Interrupt Handler를 호출한다. (Trap Interrupt를 처리하는 Handler를 호출하는 것임)
이 Interrupt Handler는 상기한 Interrupt Instruction에 대응하는 Interrupt Handler로서, 모든 System Call은 이 Handler를 거쳐간다.
-
Interrupt Handler는 System Call Handler를 호출한다. (또는 이 단계 없이, 바로 Interrupt Handler가 System Call Handler로서 작동한다. 따라서, 그냥 두 Handler가 같은 것이라고 봐도 무방하다. 이는 Design Dependent!!!)
Interrupt(or System Call) Handler는 넘겨받은 System Call Number를 토대로 자신이 (주로 논리적으로만) 가지고 있는 System Call Table을 토대로 대응되는 System Call Function을 호출한다.
- Service를 마치면, 연쇄적으로 Interrupt Vector, Library Function 등을 거치며 User Level로 Return 된다.
-
-
-
-
여담) System Call Table은 주로 논리적으로만 존재하는데, 그 말은 무엇이냐면, 따로 Data Structure 형태로 메모리를 잡아먹는 것이 아니라, 그냥 Code 내에서 Switch문 따위로 관리한다는 것이다.
자, 더 깊은 이해를 위해 이 과정을 다시 한 번 더 설명한다. 아래의 그림은 여태 설명한 상황을 조금 다르게 묘사한 것이다. (pintOS 기준으로 설명 ★)
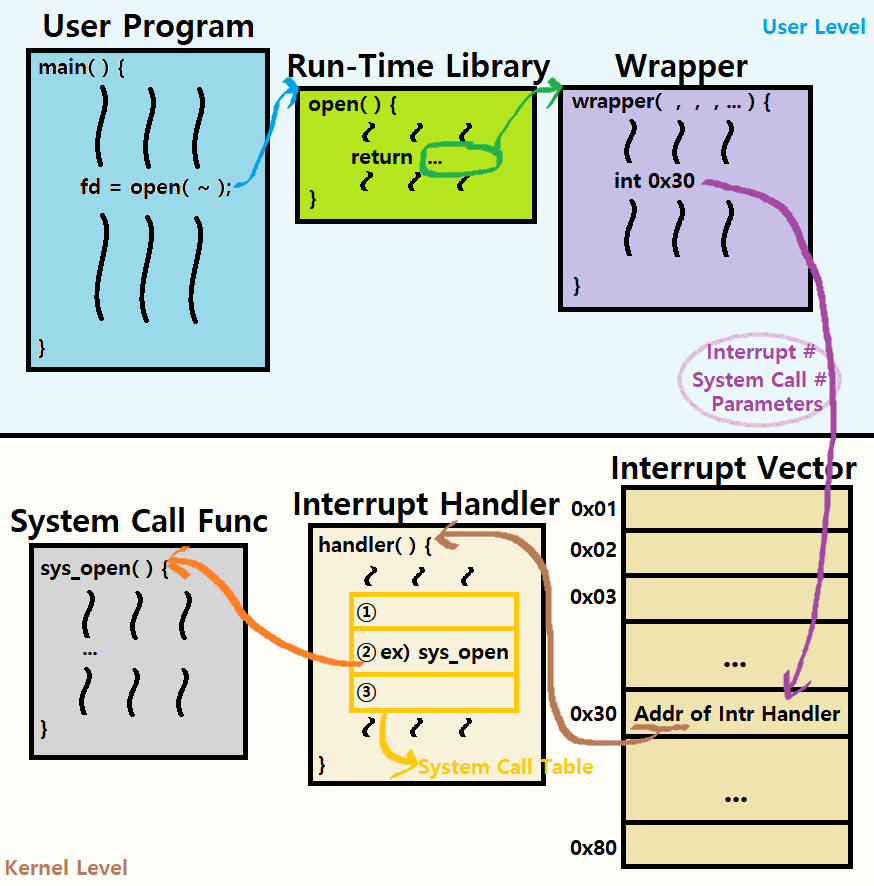
- User Program이 수행되고 있다. User Program Code에는 중간에 open 함수를 호출하는 명령이 포함되어 있다.
- 이 open 함수는 C Library 함수로, C Library를 따라간다.
- C Library의 open 함수는 OS에 Interrupt를 걸기 위해 Wrapper를 호출한다.
- Wrapper는 pintOS 기준으로 매크로로 만들어져 있다. 이 매크로 내부에서 Interrupt Instruction이 실행되어 OS에 Interrupt를 걸어준다. (pintOS 기준 0x30)
- 이때, 이 전달물에는 Interrupt Number, System Call Number, Parameters가 담겨있다.
- OS Kernel 내부의 Interrupt Descriptor Table에서 이 전달물을 받고, 0x30에 대응하는 Interrupt Handler의 주소를 찾아낸다. (0x30에 해당하는 Slot)
- 상응하는 Interrupt(=System Call) Handler가 수행된다. Interrupt Handler 내부에선 인자로 받은 System Call Number에 따라 대응하는 System Call Function을 호출한다. 이때, 함께 넘겨받은 Parameters를 이용한다.
- System Call Handler가 Service를 수행하고, 일을 마치면 연쇄적으로 Return하면서 다시 Application Program으로 돌아간다.
- 상응하는 Interrupt(=System Call) Handler가 수행된다. Interrupt Handler 내부에선 인자로 받은 System Call Number에 따라 대응하는 System Call Function을 호출한다. 이때, 함께 넘겨받은 Parameters를 이용한다.
- Wrapper는 pintOS 기준으로 매크로로 만들어져 있다. 이 매크로 내부에서 Interrupt Instruction이 실행되어 OS에 Interrupt를 걸어준다. (pintOS 기준 0x30)
- C Library의 open 함수는 OS에 Interrupt를 걸기 위해 Wrapper를 호출한다.
- 이 open 함수는 C Library 함수로, C Library를 따라간다.
-
이때, Mode Bit는 Interrupt Instruction이 실행될 때 내부적으로 자동으로 바뀐다.
-
SW Interrupt가 아닌, 외부의 Interrupt가 걸릴 때는 Application Program의 Request로 인해 이뤄지는 것이 아니기 때문에 Application Program의 '현 상태(Processor-State)'를 잠시 기억시키고, 다시 복구시키는 루틴이 필요하다. ★★★
- 위에서 장황히 설명한 것은 알다시피 Trap Interrupt, 즉, SW Interrupt이다.
즉, Interrupt Instruction이 가리키는 Index는 Interrupt Vector Table에서 System Call 수행을 관장하는 Handler의 주소가 담긴 Index를 나타내고, 이를 따라가 Interrupt(System Call) Handler가 수행되면, 해당 Handler 내부에서 System Call의 종류에 따른 처리를 수행하는 것임. 이 관계성을 반드시 기억해야한다. ★★★★★
이는 OS의 대표 Project 중 하나인 pintOS Project의 User Program 설계 Step의 핵심 Key가 되는 개념이다. ★★★★★
pintOS Example
이제부터, pintOS에서 상기한 과정이 어떻게 돌아가는지를 Code-Level로 살펴보자. pintOS를 예시로 드는 이유는, 1.1 포스팅에서도 언급했듯, OS 학습 과정에서의 유명한 프로젝트가 바로 이 pintOS 프로젝트이고, 본 시리즈에서도 마찬가지로 이를 채택할 것이기 때문이라고 밝힌 바 있다.
pintOS에서 User Program이 write Function을 호출했다고 가정하자.
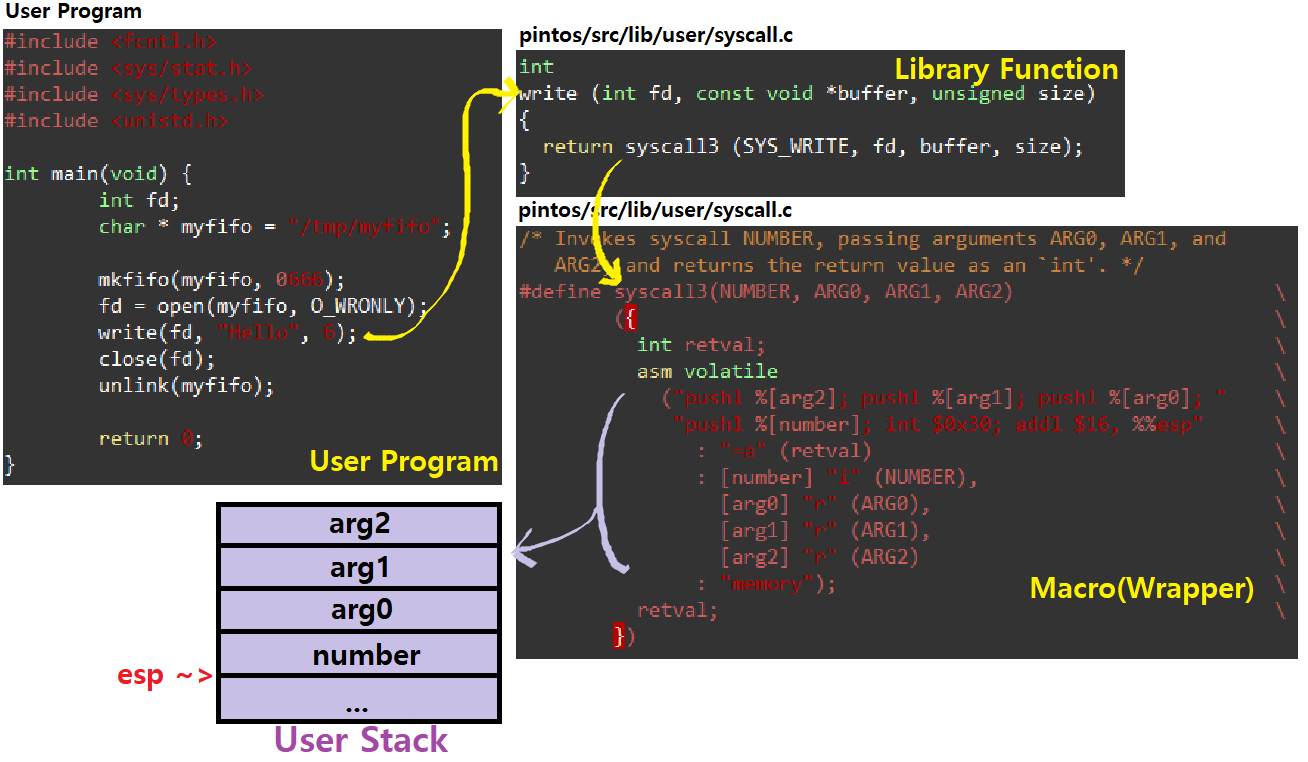
- User Program에서 write 함수를 호출했다. C Library Function인 write 함수가 호출되고, 그 내부에선 Wrapper Macro를 호출하고 있다. 같은 Code 내에 Wrapper Macro들이 정의되어 있는데, write System Call은 3개의 Parameter를 요구하므로 syscall3 Macro를 호출하고 있음에 주목하라.
- 이때, pintOS는 System Call Parameter Passing에 Stack Method를 채택하고 있는데, 따라서 Stack에 3개의 Parameter와 System Call Number를 포함해 총 4개의 요소를 Push하고 있음에 주목하라.
-
syscall3는 ASM Code로 정의되고 있는데, 이때, pushl은 Stack Push 연산이다. arg2, arg1, arg0, System Call Number 순으로 Stack에 Push하고 있다. 따라서 최종적으로 esp(Stack Pointer)가 가리키는 Stack의 Top은 Number Slot 부분이다.
-
그 다음, int 0x30을 통해 Interrupt Instruction을 실행하고 있다. 이제 본격적으로 Interrupt를 핸들링할 것이다. ★
-
참고로, int 0x30 이후 부분을 보면, esp에 16(4개의 Parameter)을 더해 esp를 원래 위치로 돌려놓는 코드가 존재하는데, 이는 Interrupt가 끝났을 때, Stack의 Top을 System Call 이전으로 돌려놓기 위함임을 기억하라. ★★★
-
-
- 이때, pintOS는 System Call Parameter Passing에 Stack Method를 채택하고 있는데, 따라서 Stack에 3개의 Parameter와 System Call Number를 포함해 총 4개의 요소를 Push하고 있음에 주목하라.
-
이처럼, pintOS에선, pintos/src/lib/user/syscall.c 파일에 각 종 C Library Function들과 이들 중 System Call과 연관된 Function들이 사용하는 Wrapper Macro syscall-k들도 정의되어 있음을 기억하자.
-
참고로, pintos/src/lib/user/syscall-nr.h 파일에는 System Call Number들에 정보가 enum Type으로 정의되어 있다.

- 새로운 System Call을 추가하고자 할 경우, 이 부분에 System Call Number부터 등록해주어야 한다.
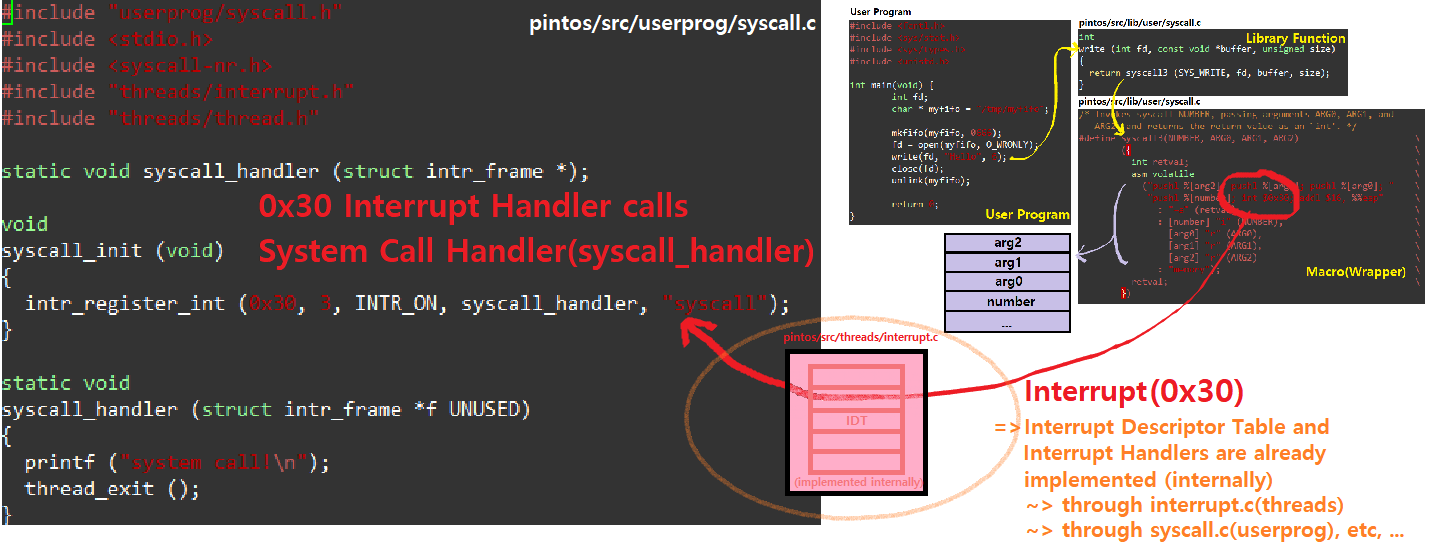
- 한편, 다시 Example Flow로 돌아와서, Interrupt Instruction이 실행되면, 해당 Interrupt가 OS Kernel 내부의 Interrupt Vector Table로 간다. Interrupt Descriptor Table이 미리 준비되어 있어야 한다. pintOS에선 이를 미리 구현해 학습자들에게 제공한다(pintOS 부팅 시 알아서 만들어짐. 여러 File에 걸쳐있음).
- IDT(Interrupt Descriptor Table)는 넘겨받은 Interrupt Number에 대응하는 Interrupt Handler의 주소를 알려준다. ★

-
스탠포드 대학교 pintOS Project의 첫 번째 Phase인 User Program 개발에서의 Task는, Vector에서 Handler로 넘어온 직후의 일을 만들어주는 것이다.
- 즉, syscall_handler를 작성해야하는 것이다.
- intr_frame 구조체의 인자를 받아들이는데, 따라서 f를 통해 Interrupt 정보를 접근할 수 있다. System Call Number나 Parameter와 같은 것을!
- write 예시를 생각해보면, syscall_handler 내부에 file_write(sys_write 기능) 시스템 함수를 어떻게 호출해서 사용할 것인지를 고민하면 되는 것이다.
- intr_frame 구조체의 인자를 받아들이는데, 따라서 f를 통해 Interrupt 정보를 접근할 수 있다. System Call Number나 Parameter와 같은 것을!
- 즉, syscall_handler를 작성해야하는 것이다.
-
그리고, System Call Handler의 Return Value는 eax Register와 esp Stack Pointer 등에 반영될 것이다.
이렇게 해서, Dual Mode 개념을 말미암은 Limited Direct Execution 이론과, 그 과정에서 Kernel의 기능을 제공하는 방법론인 System Call이 어떤 Flow를 통해서 동작하는지를 알아보았다. 이 개념들을 토대로 스탠포드대학교의 pintOS 첫 번째 Project를 수행할 수 있는 것이다. 잘 기억해두자.
System Call Mechanism
마지막으로, System Call에 대한 이야기를 조금 더 해보겠다. 일반적으로, Interrupt처럼 System Call에도 특정 Number가 부여된다.
-
System Call Interface는 특정 Table인 'System Call Table'을 운용한다. System Call Number를 Index로 한다.
- System Call Interface는 OS Kernel 내부에 저장된 상응하는 System Call을 호출하고, System Call의 Status과 추가적인 Return Value들을 반환한다.
-
내부 Detail은 Programmer에게는 보이지 않는다. Programmer는 오로지 API(Application Programming Interface)를 이용해 이러한 Interface를 사용하기만 하면 된다. 내가 사용하는 Interface를 통해 OS가 무슨 일을 할지만 알면 된다.
-
Run-Time Support Library가 Compiler와 함께 이를 관리한다.
-
System Call의 Parameter Passing 방법에는 대표적으로 아래와 같은 3가지 방식이 존재한다.
-
(1) : Register를 이용해 Parameter를 Passing한다.
- 가장 간단하고 빠른 방법이다.
- 허나, Register의 개수는 한정적이므로 한계점이 명확하다.
-
(2) : 메모리 내부에 Block이나 Table을 두고, 그 안에 Parameter들을 저장한 다음, 해당 Block/Table의 주소를 특정 Register에 Parameter로서 넘긴다.
-
(3) : 복수의 Parameter를 Program이 Stack에 Push하고, OS가 Stack에서 Pop한다.
- pintOS가 채택하는 방법 (앞선 설명에서 이를 유추할 수 있었을 것이다!)
-
-
(2)와 (3)의 Block Method, Stack Method는 Parameter의 개수나 길이에 제한이 없다.
OS마다 이러한 System Call Parameter Passing 방법이 다르며, 이러한 방법론을 ABI(Application Binary Interface)라고 부른다. ★★
API와 구분하자!
- Return Value는 어떤 방법이든 eax Register를 사용하는 것이 일반적이다.
금일 포스팅은 여기까지이다.
