지금까지는 Single CPU 환경에서의 Scheduling에 대해 알아보았다. 하지만, Modern Computer는 대부분이 Multiprocessor 환경이다. 따라서, 우리는 Multiprocessor에서의 Scheduling도 고민해봐야한다.
- Multicore : 단일 Chip에 들어간 Multiple CPU Cores -> Multiprocessor
- CPU Closk 속도의 상승엔 발열이라는 한계점이 존재하고, 그로 인해 CPU 성능 자체의 향상 대신 복수의 CPU를 동시에 사용하는 방법론이 대두되었고, 거기서 파생되어 나온 패러다임
- 단순히 CPU를 늘린다고 해서 Application Program의 수행 속도가 증가하거나 그러진 않고, Application이 Multicore의 이점을 살릴 수 있도록 Programming 해주어야 좋아짐.
- Thread 개념을 이용해 Parallel Programming을 해야한다! (Multithreading)
- 단순히 CPU를 늘린다고 해서 Application Program의 수행 속도가 증가하거나 그러진 않고, Application이 Multicore의 이점을 살릴 수 있도록 Programming 해주어야 좋아짐.
- CPU Closk 속도의 상승엔 발열이라는 한계점이 존재하고, 그로 인해 CPU 성능 자체의 향상 대신 복수의 CPU를 동시에 사용하는 방법론이 대두되었고, 거기서 파생되어 나온 패러다임
"Multicore에서 Job Scheduling을 어떻게 할 수 있을까?"
Background Concepts
Multiprocessor에서의 Scheduling을 공부하기에 앞서, 잠시 Multicore에서의 중요한 이론들을 간략하게 살펴보자.
Cache
아래와 같은 간단한 Von-Neumann Computing Architecture를 보자. CPU와 Main Memory 사이에 Cache가 있다. 이 Cache의 역할은 무엇인가.

Cache를 둠으로써 Access 속도가 느린 Main Memory의 단점을 상쇄시킨다. 자주 Access할 Data를 Cache에 두어 CPU의 수행을 더 빠르게 만들어주는 것이다.
이때의 Issue는 아래와 같다.
"Cache는 Main Memory보다 작다. 그렇다면, Cache에 어떤 정보들을 넣어야하는가?"
-
Cache Memory
-
크기는 작고 속도는 빠르다. (Main Memory보다 빠름)
-
Main Memory에서 '자주 사용하는 Data(Popular Data)'를 복사해놓는다.
-
Temporal & Spatial Locality를 활용한다. (시/공간적)
-
Temporal Locality : 내가 최근에 접근한 Data도 앞으로 또 접근할 가능성이 높다.
- 교체 정책에 LRU(Least Recently Used) Method 등을 사용할 수 있음.
-
Spatial Locality : 내가 접근한 Data 주변의 Data들도 접근할 가능성이 높다.
- 다수의 Workload들이 물리적으로 가까이 저장되므로.
-
-
주로 CPU 안에 있다.
-
By keeping data in cache, memory accessing can be faster!
Cache Coherence
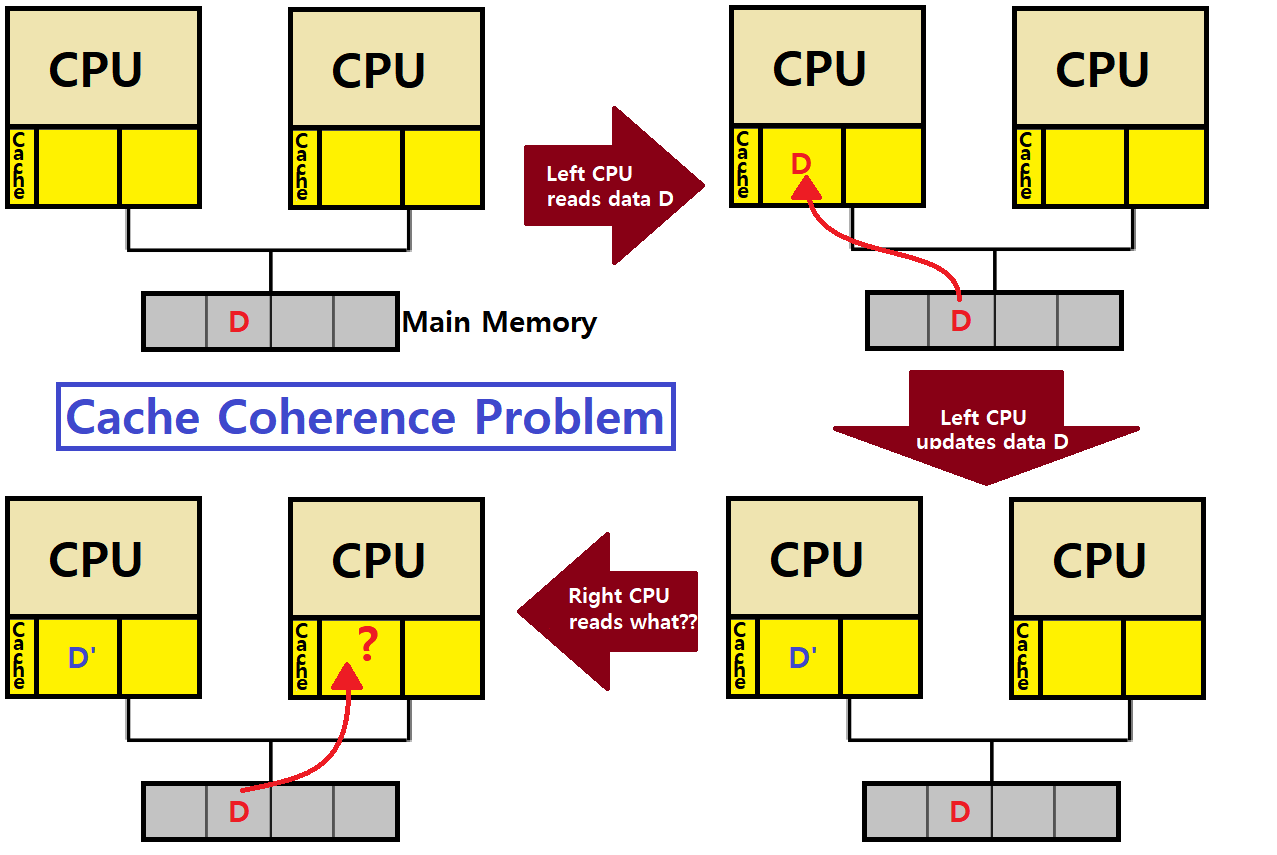
과거 SP나 Computer Architecture를 수강한 사람이라면 이 Cache Coherence 문제가 익숙할 것이다.
Cache Coherence : Multicore 환경에서, 각 CPU Core에는 개별적인 Cache가 존재하고, 이 Core들은 공통된 Bus를 통해 Memory에 접근하는데, 이때, 각 Core의 Cache, 그리고 Main Memory 사이에서 Data들의 Consistency를 어떻게 유지할 것인가?
아래와 같은 'Shared Memory Multiprocessor'를 보자. Multicore의 각 Core에 자신만의 Cache가 있고, 이들이 Bus로 Main Memory와 소통하는 상황이다.
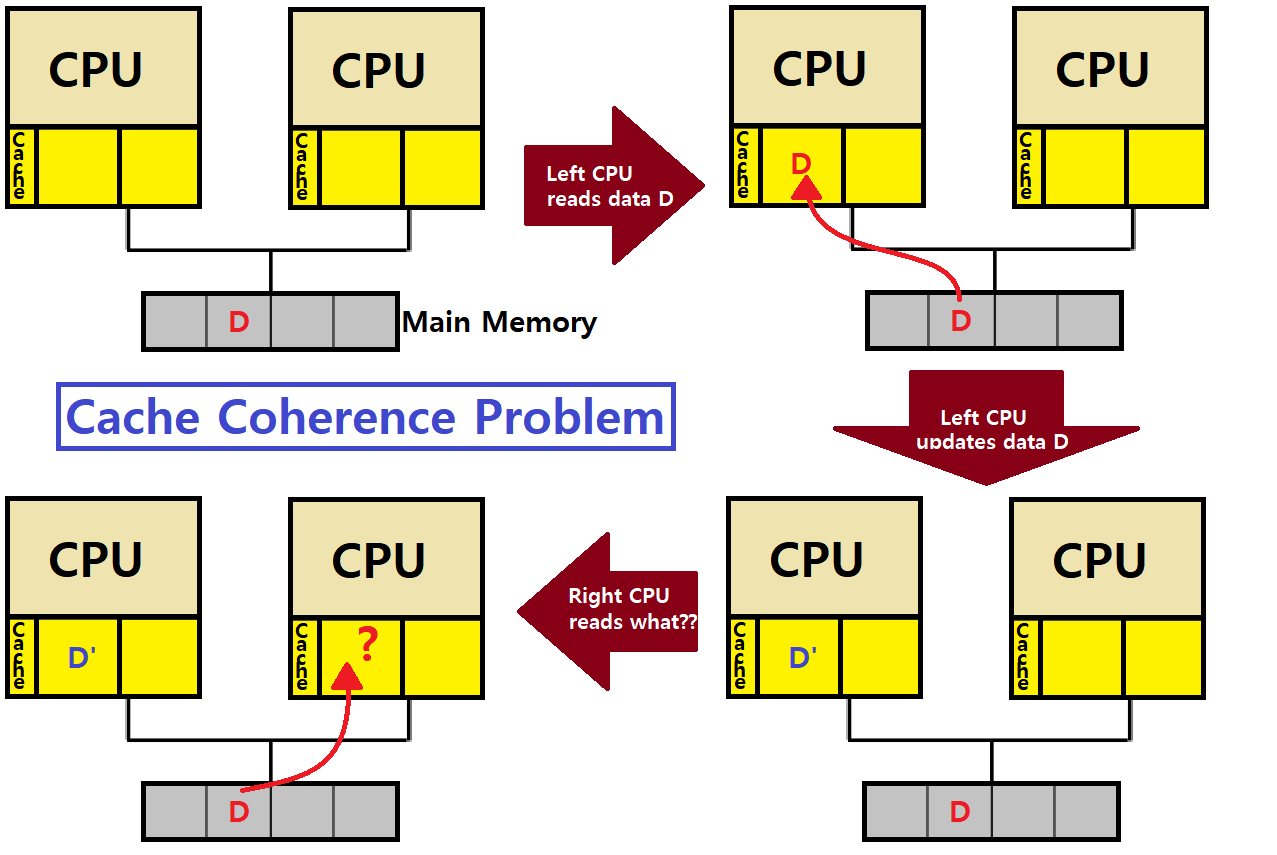
- Left CPU가 Main Memory의 특정 번지에 있는 Data D를 가져온다(Read). 연이어, Left CPU의 특정 Program이 해당 Data를 D'으로 Write(Update)한다.
- 그 다음, Right CPU가 같은 번지의 Data를 가져오려고 한다.
- 이때, 어떤 데이터를 가져와야하나?
- Data가 달라지면 문제가 발생한다!
- 이때, 어떤 데이터를 가져와야하나?
- 그 다음, Right CPU가 같은 번지의 Data를 가져오려고 한다.
We should focus on a Consistency of shared resource data stored in multiple caches!
-
Cache Update는 알다시피 다음과 같이 크게 두 가지 방식으로 나뉜다.
-
Write-Through : Data Update 시 Cache와 Main Memory를 모두 동시에 Update한다.
- 항상 Consistency가 유지되지만 그 비용이 큼.
-
Write-Back : Data Update 시 Cache만 Udpate하고, 필요 시(예를 들어 다른 Core가 해당 Data를 Read하려고 할 때라든지), 또는 마지막에만 Main Memory에 반영한다.
- Consistency 유지를 위한 여러 테크닉이 필요하지만, 비용이 적어 속도가 빠르다.
- 현실에선 주로 이 방식이 많이 쓰인다.
- Consistency 유지를 위한 여러 테크닉이 필요하지만, 비용이 적어 속도가 빠르다.
-
~> 두 방식 모두 Cache Coherence 문제가 있다. 후자는 말할 것도 없고, 전자(Write-Through)여도 유효하다.
~~> ex) 위 그림에서, Write-Through라고 해보자. Left CPU가 Data D를 가져오고, 연이어 Right CPU도 Data D를 가져온다. 그 다음, Left CPU가 Data D를 D'으로 바꿨다. Left CPU의 Cache와 Main Memory의 Data D가 D'으로 Update될 것이다.
====> 하지만, Right CPU의 Cache에선 Data D가 그대로 남아있다. (Coherence Problem)
Bus Snooping
이 Cache Coherence 문제를 해결하기 위해선 결국 '각 Core의 Cache에 어떤 Data가 있는지를 Core 각자가 인지하고 있어야함'이 필요하다. Core가 서로 서로 Data 변화를 알릴 수 있어야 하는 것이다. 그런데, 이때, 다른 Core에 특정 Data가 있는지를 어떻게 알 수 있을까?
~> Bus Snooping을 통해 알 수 있다.
- Bus Snooping : 각 Core의 Cache가 공통 Bus에 'Memory Update'가 있는지를 계속 확인한다. (HW적으로 구현함)
- 만약, CPU가 자신의 Cache에 있는 Data의 Update를 발견하면, 이것을 Update 방식 또는 Invalidate 방식으로 수정한다. (후술)
- 즉, 각자 CPU가 Bus의 Data 흐름을 계속 관찰하는 것이다. 어떤 Core의 Cache에서 어떤 Update가 있었는지를 알 수 있다. ★
- 자세한 내용은 나중에 임베디드 학습 시 다루겠다.
- 즉, 각자 CPU가 Bus의 Data 흐름을 계속 관찰하는 것이다. 어떤 Core의 Cache에서 어떤 Update가 있었는지를 알 수 있다. ★
- 만약, CPU가 자신의 Cache에 있는 Data의 Update를 발견하면, 이것을 Update 방식 또는 Invalidate 방식으로 수정한다. (후술)
-
1) Write-Update : Multicore 중 특정 Core가 Data D를 Update하면, Bus Snooping을 통해 해당 Data D를 Cache에 담고 있는 모든 Core가 모두 Cache Update를 하도록 만드는 방식
-
2) Write-Invalidate : Multicore 중 특정 Core가 Data D를 Update하면, Bus Snooping을 통해 해당 Data D를 Cache에 담고 있는 모든 Core에게 "그 Data 구식이니까 Invalidate해라!"라고 알리는 방식
- Invalidate했으므로 Main Memory에서 Data를 다시 긁어와야 할 것이다. 이때, 그 Main Memory에는 Write-Through 또는 Write-Back으로 인해 Update된 데이터가 있을 것이다. ★★
여담) 같은 Data가 지속적으로 Update될 땐 Invalidate 방식이 Update 방식보다 훨씬 더 Overhead가 적다. 왜냐? Update 방식의 경우 매번 Update마다 다른 형제 Core(같은 데이터를 Cache에 둔 Core)에게 계속 알려주어야 하는데, Invalidate 방식의 경우 첫 번째 Update 시에만 다른 Core에게 Bus Snooping으로 'Invalidation 정보'를 알리고, 그 이후부터는 Invalidation으로 인해 해당 형제 Core들이 그 Data를 가지고 있지 않으므로 다시 알릴 필요가 없다.
~> 그래서, 주로 Write-Back + Write-Invalidate 조합이 많이 쓰인다. Overhead가 가장 적은 조합이기 때문이다.
Synchronization
Multicore Processor에서 Cache Coherence 다음으로 중요한 개념은 바로 Synchronization이다. Application Program이 Shared Data를 접근할 때 Lock & Unlock을 통한 동기화가 필요하다. 우리는 이를 'Mutual Exclusion'이라고도 했다.
~> SP에서 수차례 다루었던 그 개념이다!
pthread_mutex_t mutex;
typedef struct _node {
int value;
struct _node *next;
} NODE;
int enqueue(void) {
lock(&mutex);
NODE *temp = head; // Queue의 Header를 기억
int value = head->value; // Header의 Data를 추출
head = head->next; // Header를 그 다음으로 변경
free(temp); // 기존의 Header를 Free
unlock(&mutex);
return value; // Pop!
}~> 굳이 별다른 설명을 붙이지 않아도 쉽게 이해될 것이다.
Multiprocessing Scheduling
당연한 말이지만, Single CPU일 때보다 Multiple CPU에서의 Scheduling이 더 복잡하다. 따라서, 학습의 편의성을 위해 모든 CPU의 Functionality는 동일하다고 가정하자. CPU마다의 기능이 달라지는 상황은 학부 Level이 아니다.
-
Multiprocessing Scheduling은 크게 두 가지가 방법이 있다.
-
1) Asymmetric Multiprocessing : 하나의 CPU만이 Ready Queue와 같은 System Data Structure에 접근해 Process를 추출하고, 나머지 CPU들에게 그 Data 및 Process를 나눠주는 구조이다.
- This is not a mainstream!
-
2) Symmetric Multiprocessing (SMP) : 모든 CPU가 Global Shared Queue나 Multiple Private Queue 등에 접근하는 식으로 동일하게 Self-Scheduling을 하는 구조이다.
- 모든 Processor가 동일한 일을 한다. 각자 자신의 Ready Queue(또는 Global Shared Queue)에서 Thread를 끌어와 동작시킨다. ★
- 진정한 의미의 Multicore Machine이다. CPU들이 모두 동등하기 때문에 Symmetric하다고 부른다.
- 우리는 이 SMP Machine을 기준으로 학습한다.
- 진정한 의미의 Multicore Machine이다. CPU들이 모두 동등하기 때문에 Symmetric하다고 부른다.
- 모든 Processor가 동일한 일을 한다. 각자 자신의 Ready Queue(또는 Global Shared Queue)에서 Thread를 끌어와 동작시킨다. ★
-
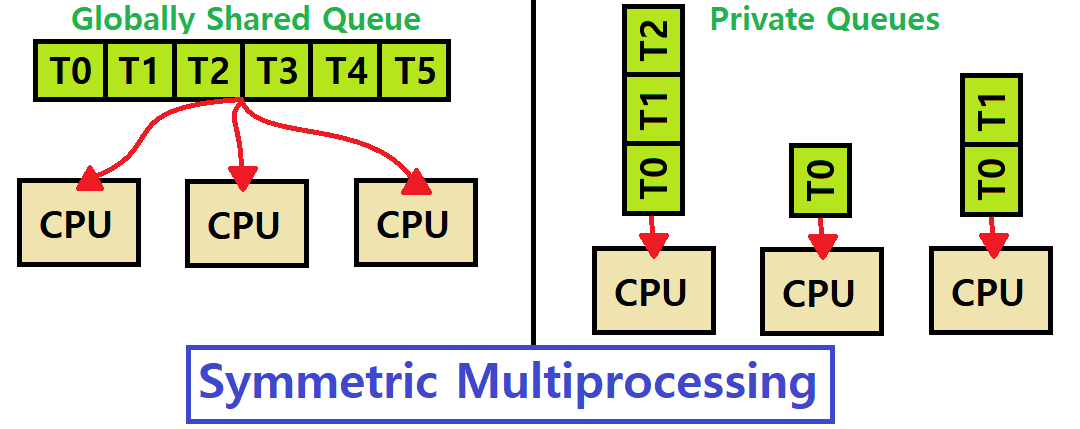
SQMS Algorithm
SMP는 Queue의 개수에 따라 그 종류가 달라진다. Queue가 하나인 방식을 'SQMS(Single Queue Multiprocessor Scheduling)'이라 한다.
SQMS(Single Queue Multiprocessor Scheduling)
Schedule의 대상이 되는 모든 Job을 하나의 Queue에 집어넣는다.
즉, Globally Shared Queue를 사용하며, 위의 좌측 그림이 바로 SQMS이다.
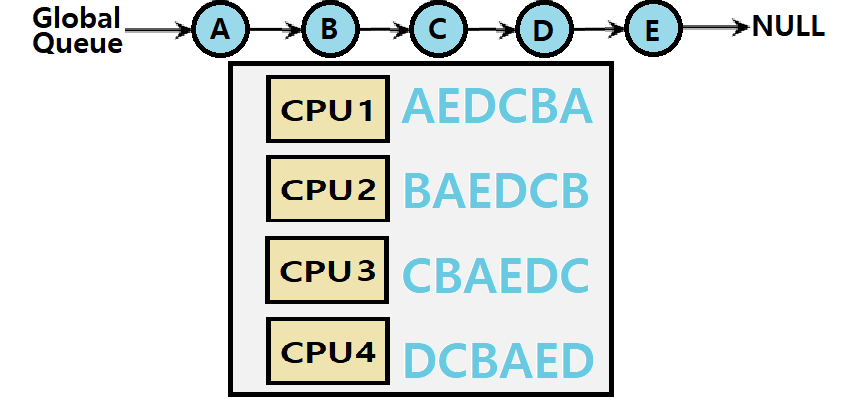
-
Globally Shared Queue는 말그대로 Shared Data Structure이므로 이에 대한 Locking이 필요하다. 계속 동기화 작업이 반복되어야 한다.
- Lack of scalability
- 동기화 작업의 필요성으로 인해 확장성에 한계가 있다. (SQMS의 큰 단점)
- Lack of scalability
-
Job이 여러 CPU에서 수행됐다 말았다 수행됐다 말았다 반복해서 Cache의 장점을 이용하기가 어렵다. Job이 다른 CPU로 갈 때마다 이전 CPU의 Cache에 있는 내용은 모두 무용지물이 되므로!!
Cache Affinity
-
어떤 Process가 특정 CPU에서 수행된다고 해보자. 그때, Cache Memory에는 어떠한 일이 일어나는가?
- CPU Cache에 해당 Process의 정보가 여럿 저장되어 있다.
- 따라서, Process가 다음에 다시 돌아갈 때, 몇 가지 정보를 Cache에서 바로 꺼내 쓸 수 있어서 수행 속도가 더 빨라진다.
- CPU Cache에 해당 Process의 정보가 여럿 저장되어 있다.
-
만약, 위의 SQMS 예시처럼, System이 Process Migration을 허용하면 Migration 관계에서 Source CPU의 Cache Memory에 있는 정보는 더 이상 무용지물이 된다.
- 또한, Destination CPU의 Cache Memory에선 해당 Process의 정보를 다시 끌어와야 한다.
이러한 현상을 방지하기 위해 한 Process를 계속해서 동일한 CPU에서 돌리는 행위를 Cache Affinity라고 한다. ★★★
또는 Processor Affinity라고도 부른다.
Affinity = 친화력
-
Cache Affinity는 그 정도에 따라 두 가지로 분류할 수 있다.
-
Soft Affinity : Migration 자체를 금지하진 않고, 대신 최대한 한 Process가 동일 CPU에서 돌아가도록 '시도'하는 방식
-
Hard Affinity : Migration 자체를 금지한다. 주로 이런 System은 항상 Hard Affinity인 것은 아니고, System Call 등으로 Hard Affinity Process를 명시할 수 있게 기능을 제공한다.
- Linux가 이에 해당한다.
-
만약, SQMS에서 Cache Affinity를 제공하면 어떤 일이 일어날까?
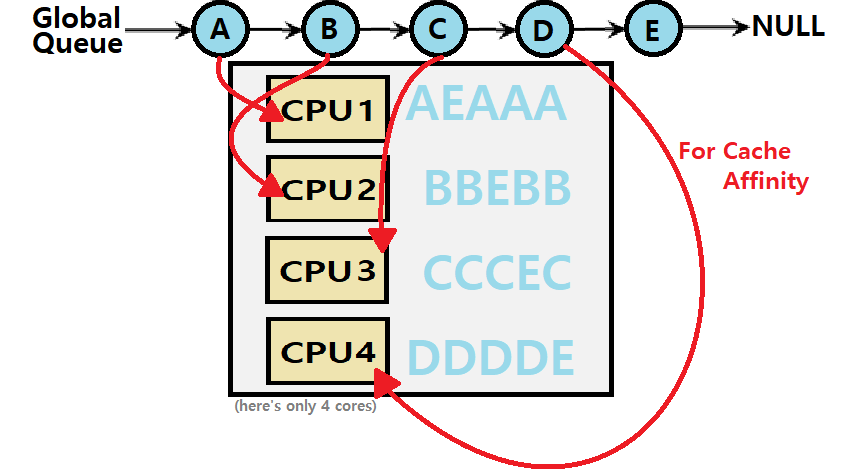
- 4-Core Processor라고 가정하자.
- ProcessA부터 ProcessD까지 Core1-4에 순서대로 매칭된다. (Cache Affinity)
- ProcessE만이 Migration하고 있다. (Soft Affinity)
~> 분명 이전의 SQMS 그림보다는 더 우수할 것이다. Cache의 이점을 활용하므로!
~~> 허나, 이러한 구조의 SQMS를 실제로 구현하는 것이 과연 쉬울까? 그렇지 않을 것이다. 각 Process한테 CPU를 어떻게 지정해줄 것인가.
===> 좀 더 개선된 Multiprocessor Scheduling Algorithm이 필요하다. ★
MQMS Algorithm
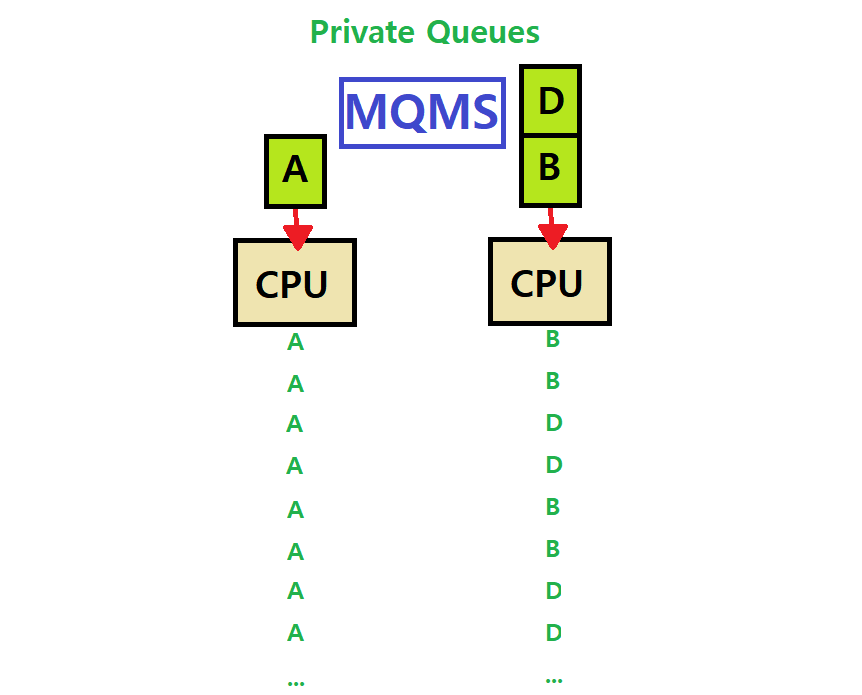
MQMS(Multi-Queue Multiprocessor Scheduling)
Multiple Scheduling Queue를 가지고 있다.
각 CPU는 자신만의 Private Queue를 운용한다. 따라서, Queue를 Share하지 않으므로 Lock & Unlock을 위시한 Synchronization이 필요치 않다.
또한, Cache Affinity도 당연히 지켜질 것이다.
MQMS gives us more scalability and cache affinity !!!
-
각 Queue는 각자의 특정한 Scheduling Discipline을 따른다.
-
Job이 System에 도착하면, 임의의 한 Scheduling Queue에 들어간다.
-
각 Queue는 Round-Robin하게 Process를 Schedule한다.
- 아래의 그림을 보자.

~> 즉, 앞서 Symmetric Multiprocessing 첫 소개 시 첨부한 시각 자료의 우측 Private Queues 예시가 바로 이 MQMS이다.
Load Imbalance & Balancing
이러한 MQMS에는 Load Imbalance 문제가 존재한다.
Load Imbalance : CPU Job Load 상태가 불균형적인 문제
아래 그림을 보자. 바로 위의 예시 그림 상황에서, Left CPU에 할당되어 있던 Job C가 수행을 마치고 종료된 상황이다.
~> 그림과 같이 Job A가 Left CPU를 독점해서 사용할 것이다.
~~> 그말은 즉슨, Job A가 CPU를 소모하는 '양'이 B, D가 소모하는 양의 2배인 것이다.
===> Load Imbalance 문제이다. Load가 불균형적이기 때문이다. A가 더 많이 소모하고 있지 않은가.
-----> 그런데, 이것만이 문제가 아니다.
"위 상황에서 Left CPU의 Job A도 수행을 마치고 종료되었다고 해보자."
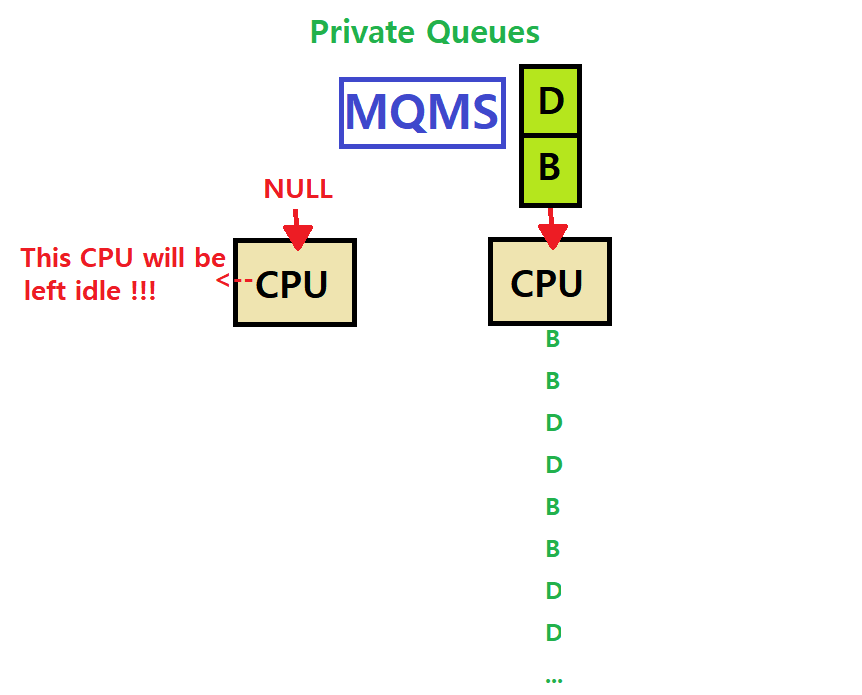
~> Left CPU의 Private Queue에 있던 Job A마저 수행을 마치니 Left CPU가 놀고 있게 된다. Right CPU엔 여전히 두 개의 Process가 돌고 있는데 말이다.
=> 당연하게도, Right CPU의 Job B나 D 중 하나가 Left CPU로 온다면 컴퓨터의 성능은 더 빨라질 것이다. (역시나 Load Imbalance) ★
"OS에서는 이러한 문제를 해결하기 위해 Load Balancing Algorithm을 MQMS에 적용해야한다"
Load Balancing : Workload가 모든 Processor 전반에 걸쳐서 고르게 분포되도록 하는 기능
MQMS와 같이, 각 Processor가 자신의 Private Queue를 가진 경우에 필요한 기법이다.
-
Load Balancing Approaches
-
1) Push Migration : 특정 Process를 두어, 해당 Process가 주기적으로 각 Processor의 Load 상태를 확인하고, 이를 고르게 뿌려주는 방식이다.
- 적은 쪽에 많은 쪽이 프로세스들을 옮긴다!
-
2) Pull Migration : Idle 상태에 놓인 Processor가 직접 Busy Processor로부터 'Queue에 대기하고 있는 Task'를 뺏어오는 방식이다.
-
즉, Push는 직접 분배하는 것이고, Pull은 부족한 녀석이 끌어오는 방식이다. ★
-
-
참고로 Linux System에선 두 방식을 모두 채택하였다. 200ms마다 Push Migration이 일어나고, 동시에 Queue가 Empty인 Processor가 스스로 Pull Migration을 수행하도록 설계되었다.
-
한편, SQMS와 같은 Single Queue Algorithm에선 Load Imbalance 문제가 발생하지 않는다.
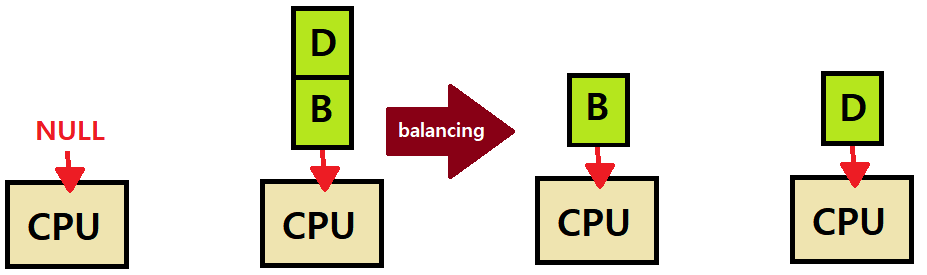
아래는 간단한 Load Balancing Case이다.
아래는 좀 더 복잡한 Case이다. Load Balancing의 목적은 모든 Job을 최대한 고르게 분포시키는 것인데, 이 분포에는 단순히 고정적인 전담 CPU를 두는 행위만을 의미하는 것이 아니라, Job 수행 중간 중간 계속해서 전담 CPU가 바뀔 수 있는 것도 의미한다.
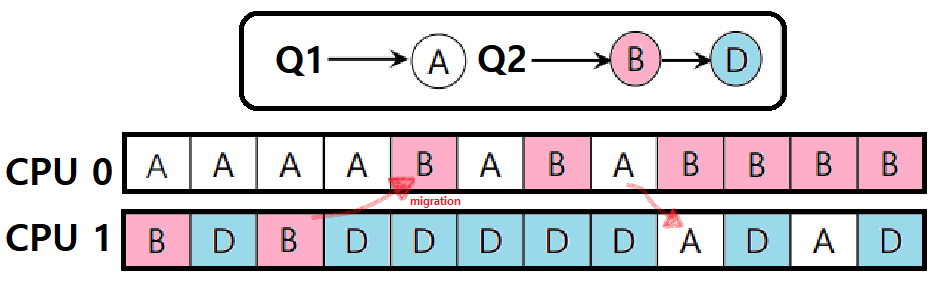
-
만약, 위와 같이 홀수개(3개)의 Job이 있다고 해보자. Double Core 상황이다.
-
Load Balancing이라 함은, Job A, B, C가 모두 균형있게 CPU를 소모해야한다는 것이다.
- 따라서, 3개의 Job에선 위와 같이 2번의 서로 다른 Job의 Migration이 있어야 한다.
- 두 번의 Migration을 통해 세 Job이 모두 균등하게 8번의 CPU Time을 가져가고 있음을 알 수 있다.
- 따라서, 3개의 Job에선 위와 같이 2번의 서로 다른 Job의 Migration이 있어야 한다.
-
Job B를 CPU1에서 CPU0으로 Migrate하면, A와 B가 서로 RR을 지키고, 다시 CPU0에서 Job A를 CPU1으로 보내면 A와 D가 RR을 지키고 있음에 주목하자. ★★★
-
여담) Migration을 Stealing으로 표현하는 경우도 있다. (특히 Pull Migration)
이렇게 해서 Process Virtualization 개념 설명을 마친다. Process를 가상화하기 위해 어떤 매커니즘이 사용되는지를 포괄적으로 깊이 있게 알아보았다. 이 방대한 개념들을 pintOS 실습을 통해 조각 조각 모아가며 진정한 이해를 도모할 수 있을 것이다. 참고로, 추후 pintOS와 관련된 포스팅도 연재할 계획이다. 기대해도 좋다.
이제 다음 포스팅부터는 또 다른 Virtualization인 Memory Virtualization이다. 이 역시 재밌게 학습해보도록 하자.
금일 포스팅은 여기까지이다.
