지난 시간 우리는 Limited Direct Execution의 일환으로 도입된 Cooperative & Preemptive Approach에 대해 알아보았고, 그로 인해 가능해진 Process Context Switch에 대해 알아보았다. 그리고, Context Switch에 관한 몇 가지 Naive한 Scheduling Algorithm들도 확인했다. 안타깝게도 이들은 Convoy Effect나, 예측 필요성 등의 문제점이 있었다. 좀 더 좋은 방식을 개발해야한다.
이번 포스팅도 마찬가지로 Scheduling에 대해 알아볼 것인데, 바로 Advanced한 Scheduling Algorithm 개념이다. 많이들 들어봤을 Round Robin 기법부터 시작하자.
본격적인 설명에 앞서, 한 가지 Performance Metric을 더 도입하려고 한다. 이전 포스팅에서 간단히 언급했던 Response Time이다.
Response Time : Job이 System(Ready Queue)에 도착하고 나서부터 처음으로 Schedule될 때까지의 시간
𝑻_𝒓𝒆𝒔𝒑𝒐𝒏𝒔𝒆 = 𝑻_𝒇𝒊𝒓𝒔𝒕𝒓𝒖𝒏 − 𝑻_𝒂𝒓𝒓𝒊𝒗𝒂𝒍
- 앞서 살펴본 FIFO, SJF, STCF는 이 Response Time이 좋지 않다고 알려진다. ★★★
- 이들은 Turnaround Time 측면에선 우수하지만, 계속 기다려야한다는 근본적인 문제점이 있기 때문에 Response Time이 좋지 않다.
- 동시에 n개의 Process가 도달하면, 상기한 Naive Algorithm들은 마지막으로 Schedule된 Process 입장에서 매우 오랜 시간을 기다려야한다. ★
- 이들은 Turnaround Time 측면에선 우수하지만, 계속 기다려야한다는 근본적인 문제점이 있기 때문에 Response Time이 좋지 않다.
~> 이러한 Response Time 측면에서 우수한 스케쥴링 알고리즘이 존재한다. 그것이 바로 아래의, 많이들 들어봤을 Round Robin Algorithm이다. (사실 이미 다 아는 내용일 것)
Round Robin Scheduling Algorithm
줄여서 RR(Round Robin)이라 불리는 이 Scheduling 기법은 'Time-Slicing Scheduling'이다. RR은 다음과 같은 Idea에서 출발했다.
"모든 Process에게 동등한 양의 시간을 부여하자!"
Round Robin Scheduling Algorithm : 모든 Process에게 'Time Slice' 또는 'Time Quantam'이라 불리는 CPU Time의 작은 단위를 부여한다.
이 Time Slice가 다 지날 때마다(Elapsed), 현재의 Running Process는 OS로부터 Preempted되고, Ready Queue의 끝으로 들어간다.
즉, Running State에 있는 현재 CPU 점유 Process에 대해, OS가 CPU Control을 회수한 다음 Ready State로 변환시키는 것이다.
할당받은 시간만큼만 수행하라는 것이다!!!
"즉, RR 기법은 Preemptive Algorithm이다."
"그리고, 우리에게 익숙한 논리를 가지고 있다. 우리가 흔히 Context Switch라 인식하고 있는 개념이 드디어 제대로 보이기 시작하는 것이다."
-
알다시피, Ready State에서 Running State로 변하는 과정이 바로 Schedule이다.
- 반대로, Running State에서 Ready State로 변하는 것을 Preemption이라 부른다. ★
-
이때, Time Quantam의 길이는 반드시 Timer Interrupt 주기의 배수가 되어야 한다. ★★★
- Computer에선 Time을 어떻게 알까? OS에선 시간을 어떻게 알 수 있을까?
- 바로 CPU 외부의 Timer Hardware가 보내는 Timer Interrupt로 알 수 있다. ★★★
- 지난 시간 언급했듯, Timer Interrupt는 주기적으로 발생한다. OS에선 이 Interrupt가 도달하면 Interrupt Vector Table로 보내서 Timer Interrupt Handler를 발생시켜 Context Switch를 도모한다고 했다.
- 이때, OS는 Timer Interrupt의 주기를 알고 있고, OS의 Timer Interrupt Handler에서 이 Timer가 오는 것을 Count한다면 OS는 시간을 알 수 있는 것이다. ★★★★
- 지난 시간 언급했듯, Timer Interrupt는 주기적으로 발생한다. OS에선 이 Interrupt가 도달하면 Interrupt Vector Table로 보내서 Timer Interrupt Handler를 발생시켜 Context Switch를 도모한다고 했다.
- 바로 CPU 외부의 Timer Hardware가 보내는 Timer Interrupt로 알 수 있다. ★★★
- Computer에선 Time을 어떻게 알까? OS에선 시간을 어떻게 알 수 있을까?
-
그래서 RR Scheduling에서 Time Slice는 Timer Interrupt Period의 n배가 되어야 한다.
- 왜? OS가 시간을 재기 위해서!!!
- OS 입장에선 Timer Interrupt를 통해서만 시간을 알 수 있고, 이를 체크할 수 있어야 Process의 수행 시간을 통제할 수 있기 때문!!! ★★★
- 왜? OS가 시간을 재기 위해서!!!
- 만약, Ready Queue에 n개의 Process가 있다고 하고, Time Quantam은 q라고 하자.
- 각 Process는 최대 q라는 Time Slice만큼만 CPU를 점유할 수 있다.
- 즉, 따라서 자신을 제외한 n-1개의 Process가 Time Quantam을 Full로 사용한다고 가정하면, Process가 기다릴 수 있는 최대 시간은 "(n-1) x q"이다. ★★★
- 내 Process가 수행되고 나서 나중에 다시 돌아와서 수행되기까지 최대 (n-1)xq만큼의 시간이 드는 것이다. (n x q)만큼의 단계를 거쳐서!
- 즉, 따라서 자신을 제외한 n-1개의 Process가 Time Quantam을 Full로 사용한다고 가정하면, Process가 기다릴 수 있는 최대 시간은 "(n-1) x q"이다. ★★★
- 각 Process는 최대 q라는 Time Slice만큼만 CPU를 점유할 수 있다.
- 이러한 Time Quantam이 너무 크면 사실상 FCFS Algorithm처럼 작동할 것이다. (FIFO)
- 반대로 Time Quantam이 너무 작으면 오히려 그만의 문제가 있다.
RR의 Time Quantam은 반드시 Context Switch의 Overhead보다는 커야한다.
Time Slice가 Overhead보다도 작으면 프로그램 자체를 제대로 수행하지 못할 것이다.
- RR Scheduling은 앞선 Algorithm들에 비해 Fair하고, Response Time이 우수하다.
- 하지만, Performance, 특히나 Turnaround Time과 Waiting Time 측면에서는 오히려 더 좋지 않은 성능을 보인다. (Trade-Off)
- 지난 시간 언급했듯, STCF는 성능 측면에서 Optimal하다. 현실성이 떨어질 뿐.
- 하지만, Performance, 특히나 Turnaround Time과 Waiting Time 측면에서는 오히려 더 좋지 않은 성능을 보인다. (Trade-Off)
-
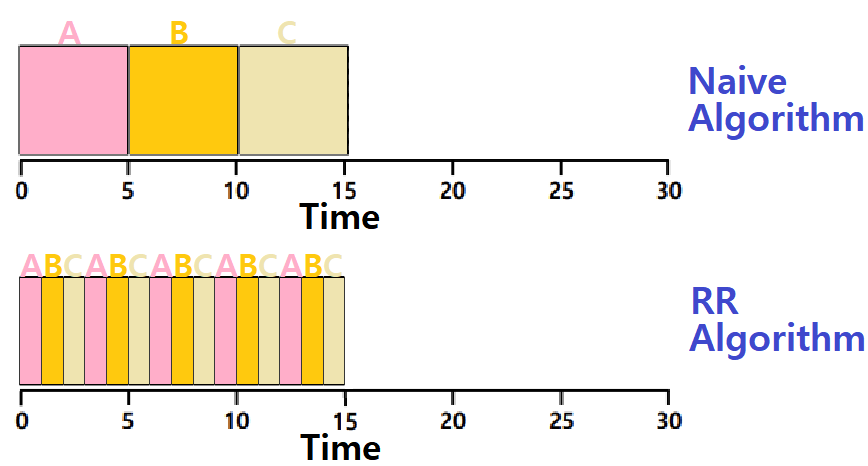
Average Response Time 입장에서 위의 그림을 바라보자.
-
Naive Algorithm의 경우, (0 + 5 + 10) / 3으로 5초이다.
-
RR Algorithm의 경우, (0 + 1 + 2) / 3으로 1초이다.
-
~> RR Scheduling이 FIFO, SJF, PSJF보다 Response Time 측면에서 더 우수함을 가볍게 확인해볼 수 있다.
Time Slice
RR Scheduling에서 Time Slice, Time Quantam의 길이 q는 상당히 중요하다.
-
q가 길어지면 Context Switch 횟수가 줄어든다.
- Response Time은 안좋아지겠지만, Switch의 Cost가 줄어들 것이다.
-
q가 짧아지면 Context Switch 횟수가 늘어난다.
- Response Time은 좋아지겠지만, Switch의 Cost가 늘어날 것이다.
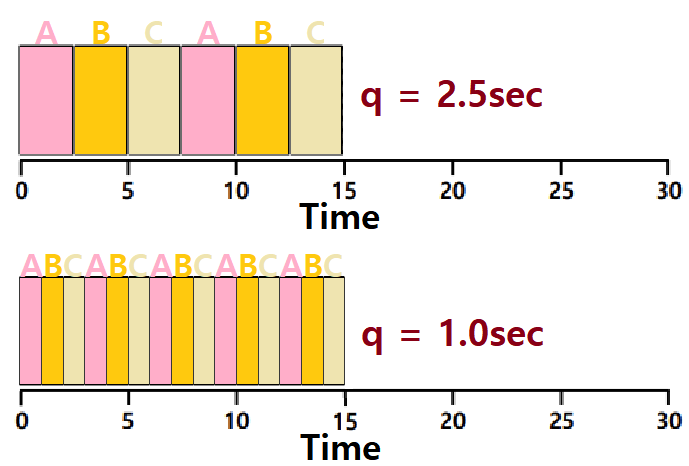
~> 위 그림을 보자. 상단은 Time Slice가 더 긴 RR이다. Context Switch가 5번 밖에 일어나지 않는다.
~~> 허나, Response Time은 (0 + 2.5 + 5)/3이다.
~> 하단은 Time Slice가 상단보다 짧은 RR이다. Context Switch가 14번이나 발생한다.
~~> 허나, Response Time은 (0 + 1 + 2)/3 밖에 되지 않는다.
Time Slice의 길이를 어떻게 정하느냐에는 Response Time과 Switch Cost 간의 Trade-Off 관계가 존재함을 알 수 있다. ★★★
System 설계자가 이를 결정하면 된다.
- 앞서, RR에서 Time Quantam의 크기가 커질수록 FIFO에 가까워진다고 했다. ★★★
- 그말은 즉슨, q가 커질수록 Turnaround Time이 좋아진다(줄어든다)고 볼 수 있다.
- 허나, 아래의 실험 결과를 보면 알 수 있듯, 꼭 그렇지만은 않다. RR에서 Turnaround Time을 줄이기 위해 q를 늘렸는데 오히려 Turnaround Time이 늘어나는 Case도 존재한다.
- 왜냐? 중간 중간 CPU Burst Time이 긴 Process들이 개입할 수 있기 때문! ★★★
- 허나, 아래의 실험 결과를 보면 알 수 있듯, 꼭 그렇지만은 않다. RR에서 Turnaround Time을 줄이기 위해 q를 늘렸는데 오히려 Turnaround Time이 늘어나는 Case도 존재한다.
- 그말은 즉슨, q가 커질수록 Turnaround Time이 좋아진다(줄어든다)고 볼 수 있다.
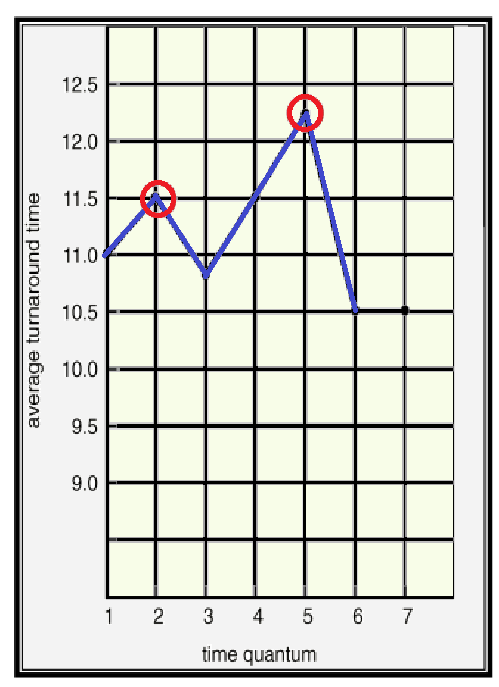
Average Turnaround Time과 Time Quantam의 길이 간에는 별다른 상관 관계가 없다.
Time Quantam이 Too Large여야만 FCFS와 같아진다. ★
여담) 여러 연구 결과, CPU Burst의 80% 정도가 Time Quantam보다 작을 때 성능이 가장 좋다는 것이 알려져 있다. 이를 '80% Rule'이라 한다.
Considering I/O
지금까지의 Assumption엔 I/O가 없었다. 모든 Process가 CPU만 사용한다고 가정했었다. 허나, 대부분의 Process는 오히려 I/O Bound인 경우가 많다. 따라서, 우린 I/O도 고려해야한다.
-
만약, ProcessA와 ProcessB가 있는데, 두 Process가 모두 CPU를 50ms정도 소모한다고 하자. A가 먼저 수행된다.
-
ProcessA가 10ms 수행된다음 I/O Request를 요청한다.
- I/O는 10ms 소요된다고 하자.
-
ProcessB는 I/O없이 CPU만 50ms 소모하는 Process이다.
-
ProcessA가 I/O를 할 때, 만약 ProcessB가 마냥 기다리게 하면 성능이 안좋을 것이다. CPU Utilization이 떨어질 것이다.
- 그래서, 우리가 이미 알다시피 특정 Process가 I/O를 수행할 때, 다른 Process가 CPU를 점유할 수 있도록 Modern Computer는 설계되어 있다. CPU Utilization을 높이기 위해 말이다.
-
-
특정 Process가 I/O Request를 요청하면,
- 그 Job는 I/O Operation이 끝날 때까지 Block되고,
- OS Scheduler는 다른 Process를 Schedule하여 CPU가 놀지 않게 한다.
-
I/O Operation이 끝나면,
- Interrupt Exception이 발생하고,
- OS는 그 Process를 Blocked State에서 Ready State로 바꿔준다. 즉, Ready Queue에 삽입한다. ★★★
평소 우리의 Computer System에서 돌아가는 Process들을 생각해보자. CPU Bound Process가 많을까, I/O Bound Process가 많을까. 그렇다. I/O Bound Process가 더 많을 것이다.
~> 따라서, 실제 Scheduling Algorithm을 설계할 때, I/O Bound Process에 Favor를 주는 것이 좋을 수 있다.
~~> 어떻게? CPU Burst 길이가 짧은 Process들이 먼저 돌아갈 수 있도록 말이다. ★
===> 허나, SJF나 STCF에서 말했듯이, Estimation의 문제가 있다. Exponential Averaging같은 예측 기법은 구현이 복잡할 것이다.
----> 그렇다고 RR 기법을 사용할까? RR은 Turnaround가 좋지 않다는 문제가 있다. 그리고 애초에 시간 예측도 못하고.
"좀 더 현실에 적용할만한 Scheduling Algorithm이 없을까?"
여담) Response Time은 어떤 Process에게 중요할까? 바로 Foreground Process이다. 왜냐? 그래야 사용자에게 Illusion을 효과적으로 제공할 수 있을 것이기 때문이다.
여담) 그렇다면, Turnaround Time은 어떤 Process에게 중요할까? 그렇다. Background Process이다. 왜냐? 사용자 눈에 보이지 않으므로 그냥 최대한 빨리 수행하면 되기 때문이다.
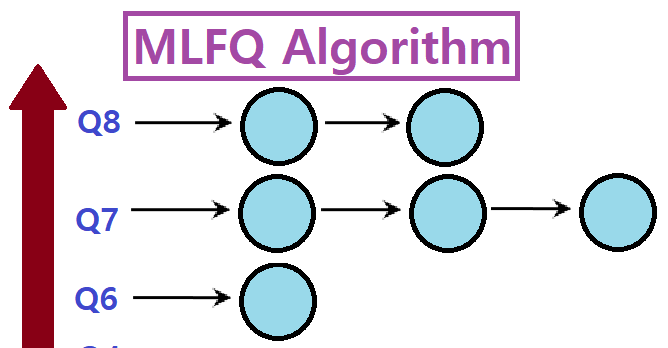
MLFQ Algorithm
지금까지 다룬 Scheduling Algorithm들의 모든 단점을 해결하는 Algorithm이 바로 MLFQ(Multi-Level Feedback Queue) Scheduling Algorithm이다.
-
FIFO Algorithm : 간단하지만 Convoy Effect라는 큰 단점이 존재. CPU와 Device Utilization이 급격히 안좋아질 수 있음.
-
SJF & STCF Algorithm : Average Turnaround / Waiting Time이 좋다. 하지만 Job Length를 어떻게 알 수 있냐는 문제점이 있다.
-
RR Algorithm : Response Time 측면에선 우수하지만 Turnaround Time이 좋지 않음.
상기한 Algorithm들의 단점들에서 해결책을 각각 뽑아내면 다음과 같다.
1) Turnaround Time : Shorter Job을 먼저 수행하면 된다.
2) Response Time : Round Robin 기법을 사용해 Process들을 최대한 동시에 수행하면 된다.
"그렇다면, 이 두 가지 방법을 합칠 수 있지 않을까?"
~> 그렇게 해서 등장한 Algorithm이 바로 Multi-Level Feedback Queue Algorithm이다.
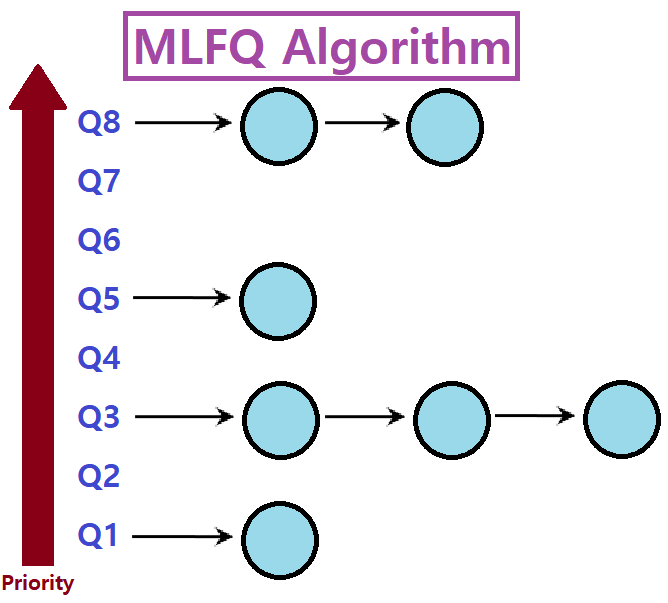
MLFQ(Multi-Level Feedback Queue) Scheduling Algorithm
쉽게 말해, Priority를 기준으로 여러 Level의 Queue를 두고, 각 Queue에서 RR을 적용하는 것이다.
"Shorter Job에 우선순위를 주고, 동등한 Job끼리는 Fair하게 RR을 돌린다."
-
Priority Level에 따라 여러 개의 Queue를 마련한다.
-
높은 우선순위의 Queue에 있는 Job이 먼저 Schedule되어 수행된다.
-
같은 우선순위의 Queue 내에선 Round Robin Scheduling Algorithm을 적용한다.
-
이때, MLFQ에서 우선순위는 'Observed Behavior'를 토대로 결정된다.
- 많은 I/O Operation을 위해 I/O를 자주 기다리고, CPU를 적게 사용하는 Job들을 높은 우선순위에 둔다. ★★★
- CPU를 많이 사용하는 Job들은 낮은 우선순위에 둔다. ★★★
-
만약, ProcessA가 5ms만 사용하고 I/O를 한다고 해보자. q가 10ms인 상황이다.
- q를 다 소모하지 않은 상태에서 CPU Control을 Relinquish(=Yield, 포기)한다.
- ProcessA는 높은 우선순위의 Queue에 두거나, 또는 현재 Queue에 그대로 유지한다.
- q를 다 소모하지 않은 상태에서 CPU Control을 Relinquish(=Yield, 포기)한다.
-
만약, ProcessB는 20ms를 순전히 CPU 위에서 돈다. 이땐 q가 10ms이니 10ms를 돌린 다음 Switch할 때, Priority를 낮춰준다. 왜냐? 오랫동안 도는 녀석이므로!
MLFQ의 Rule을 정리하면 아래와 같다.
Job이 처음에 System이 Arrive하면, 가장 높은 Priority의 Queue에 위치시킨다.
만약 Job이 Time Quantam을 모두 소모한다면, 낮은 Priority의 Queue로 위치시킨다.
만약 Job이 Time Quantam을 모두 소모하기 전에 CPU Control을 놓는다면, 동일한 Priority Queue에 유지한다.
여담) MLFQ를 실제 OS에 적용할 때는, Queue를 60개 이상 놓기도 한다.
Problems of Basic MLFQ
그러나, 위에서 설명한대로만 MLFQ를 구성하면 Low Priority Queue의 Process들이 굶어죽을 수 있는 문제가 발생한다.
~> Low Priority Queue의 Process, 정확히는 CPU Burst Time이 긴 Process가 Starve하는 문제가 발생할 수 있다. 사실상 SJF와 다를바가 없다.
몇 가지 예시를 통해 이 문제를 확인해보자. 아래를 보자.
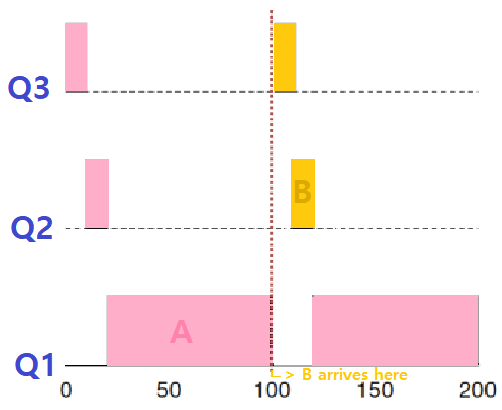
-
ProcessA는 Long-Running CPU-Intensive Job이다.
- 총 200ms를 돈다.
-
ProcessB는 Short-Running Interactive Job이다. (No I/O)
- 총 20ms를 돈다.
- 100ms 지점에 도착했다.
- 총 20ms를 돈다.
~> ProcessB가 나중에 도달했음에도 먼저 수행된다. 물론, 이는 당연하다. 허나, ProcessB와 같은 Short Job들이 10개가 있다고 해보자. ProcessA는 수 ms가 지나고 나서야 제대로 돌 수 있을 것이다. (Starvation)
~~> 한편, ProcessA와 ProcessB 모두 MLFQ에 도착한 후, Time Slice가 지날 때마다 Time Slice를 모조리 소모해서 한 단계씩 아래 Queue로 내려가고 있음을 주목하자. ★

-
ProcessA는 Long-Running CPU-Intensive Job이다.
- 총 200ms를 돈다.
-
ProcessB는 계속 반복적으로 '1ms CPU 점유 + I/O Operation'을 수행하는 Interactive Job이다.
~> ProcessB는 계속 Time Slice를 다 소모하지 않기에 최상단 Priority Queue에서 Run하고, ProcessA는 계속 최하단 Priority Queue에서 돌다 말다 돌다 말다 하고 있다.
=> ProcessA가 굶고 있고, ProcessB는 폭식(또는 기만)하고 있는 것이다. ★
위의 예시들에서 Basic MLFQ의 문제점들을 발견할 수 있다. 크게 3가지 정도 있는데,
1) Starvation : 만약 Short-Running하는 Interactive Job들이 System에 많으면 Long-Running Job은 CPU Time을 제대로 점유하지 못할 수 있다.
2) Gaming Scheduler Problem : 만일, Time Slice의 99%만 사용하고 나머지 1% 상황에서 I/O Operation을 요청하는 행위를 계속 반복하는 Process가 있으면 어떨까? 기존의 Rule 하에서는 계속해서 최우선순위 Queue에서 이를 반복할 것이고, 궁극적으로 CPU Time의 대부분을 그 Process가 차지할 것이다. 즉, 스케쥴러를 속이는 Process가 있을 수 있는 것이다.
3) CPU Bound Process와 I/O Bound Process의 성질을 모두 가지는 Process가 있을 수 있다. 이럴 땐 어떻게 처리해줄 것인가? 애매하다. 만약, 처음엔 CPU를 오래 소모하다가, 후반에 I/O를 많이 사용해야하는 Process가 있다면, 이 친구는 기존의 MLFQ 하에선 CPU Control을 잡기가 어려울 것이다.
즉, Priority Boosting Mechanism이 필요하다!!! ★★★
Priority Boosting
Basic MLFQ에 다음과 같은 Rule을 추가하자.
특정 Period가 지나면, System의 모든 Job을 최우선순위(Topmost) Queue에 옮긴다.
아래의 예시를 보자. Long-Running Job A와 Short-Running Interactive Job B, C가 있다. 이전과 다르게, Priority Boosting을 적용했다. 좌측은 Boosting이 없는 Case, 우측은 Boosting이 있는 Case이다.
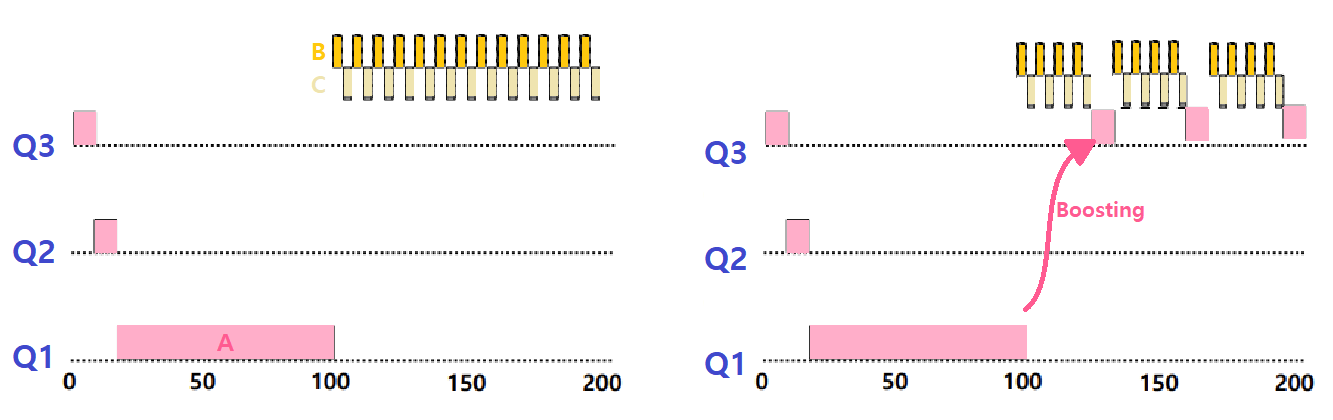
~> ProcessA가 최하단 Priority Queue로 이동한 후, 일정 시간 수행되다가 어느 정도 특정 시간이 지나면 다시 Topmost Priority Queue로 Boosting되는 모습을 볼 수 있다.
=> Starvation 문제를 이렇게 해결할 수 있다.
--> 허나, 아직 Gaming the Scheduler 문제는 해결되지 않았음도 알 수 있다. B와 C가 Time Quantam을 다 쓰지 않고 중간에 I/O를 반복적으로 요청하면서 Scheduler를 독점하고 있기 때문이다.
여담) Priority Boosting을 실제 OS Scheduler에 적용할 때, 그 Period는 일반적으로 1초 가량으로 설정한다. (생각보다 더 짧다. 하지만, 이는 CPU 입장에선 매우 긴 시간)
Time Allotment
Gaming the Scheduler 문제를 해결하기 위해 다음과 같은 Rule을 추가하자.
어떠한 Job이 CPU Control을 놓는 횟수와는 관계없이 특정 Level의 Queue에서 '일정 시간(Time Allotment)' 이상 머무르면 Priority를 낮춰주자.
특정 Level에서 머무를 수 있는 시간의 Maximum을 정해두어 Gaming을 해결하는 것이다.
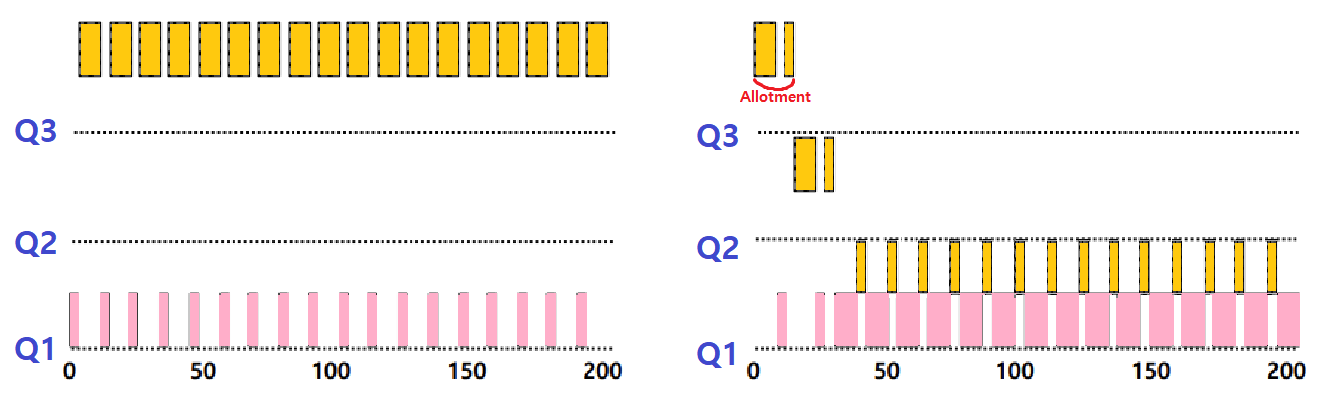
~> 좌측은 Time Allotment가 적용이 되지 않은 Case, 우측은 적용된 Case이다. 확실히 우측에서는 ProcessB의 Gaming 시도가 방지되고 있음을 알 수 있다.
-
이러한 Time Allotment 방식이 실제로 적용될 때에는 Queue에 따라 Time Slice 크기를 달리하는 Variation도 가능하다. (Lower Priority, Longer Quantam)
- 위로 올라갈수록 Time Slice가 짧아져 최상단 Queue에서의 Gaming이 원천에 방지된다.
-
또한, Time Allotment는 Starvation을 낮추는 효과도 있다.
이렇게 해서 MLFQ에 대한 개념 설명을 마무리한다. MLFQ의 가장 큰 의의는 무엇일까. 그것은 바로...
MLFQ는 Process의 CPU 사용 정도를 알 필요가 없다. 즉, 예측이 필요가 없다. ★★★
금일 포스팅은 여기까지이다.
