지난 포스팅에서 우리는 Memory Management와 관련한 API들에 대해 알아보았다. 이때, 이러한 API들의 실제 구현에 있어서, Free한 메모리 공간을 어떻게 처리할 것인가는 상당히 중요한 문제이다. 좀 더 구체적으로 말하면, Dynamic Memory Allocation 시, Free Space의 관리를 어떻게 할 것이냐가 핵심이란 것이다.
금일 포스팅에선 이 OS의 'Free Space Management'에 대해 알아볼 것이다. 그렇다. SP에서 다루었던 Dynamic Memory Allocation 개념의 복습 시간이라 보면 된다. SP에선 이 개념을 User System Program 입장에서 바라보았다면, 이번엔 OS 관점에서 이 개념을 학습할 것이다.
Split & Coalesce
Dynamic Memory Allocation에서 Free Space를 다루는 가장 기본적이고 핵심인 기능은 Splitting과 Coalescing이다. 아래를 보자.
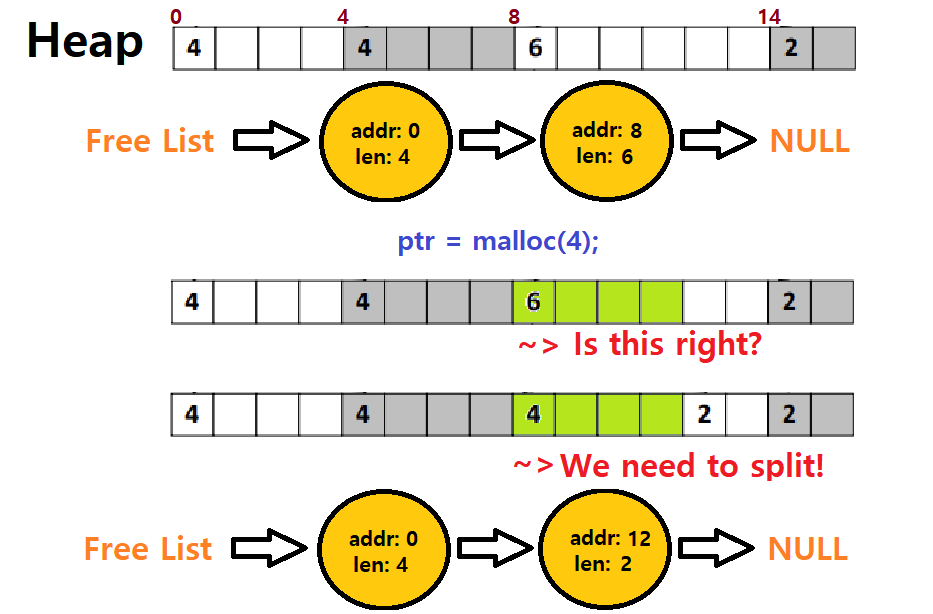
- malloc과 같은 Memory Allocation 시, Memory에서 Request를 Cover할 수 있는 Free Chunk를 찾은 후, Request Size에 맞게 할당 후, 나머지가 있는 경우, 해당 나머지 공간을 여전히 Free Space로 유지할 수 있도록 Split해야한다. ★★★
- malloc과 같은 Memory Allocation Request가 OS에 도달하면, OS는 특정 Fit Policy에 따라 Free List의 Block들 중 적절한 Block을 고르고, 해당 Block에서 Request Size만큼을 Allocate한 후, Split해선 나머지 공간을 Free로 유지한다는 것이다. ★
여담) Heap Management 시 위와 같이 Free List를 운용한다. 그 운용 방식이 무엇이든 간에!
(과거 SP 포스팅 참고)

- 반대로, 위와 같이 free 상황에서는 Newly Freed Block의 '앞 뒤(Logical 관점에서 Linear하게 붙어있는 관계)' Block 중 Freed Block이 있으면 Coalesce시키는 루틴도 필요하다.
- 그래야 추후 큰 Size의 Block을 요구하는 Memory Allocation Request가 왔을 때 그러한 요청을 Cover할 수 있다.
- "되도록이면 Free Block을 크게 만들자!"
- 그래야 추후 큰 Size의 Block을 요구하는 Memory Allocation Request가 왔을 때 그러한 요청을 Cover할 수 있다.
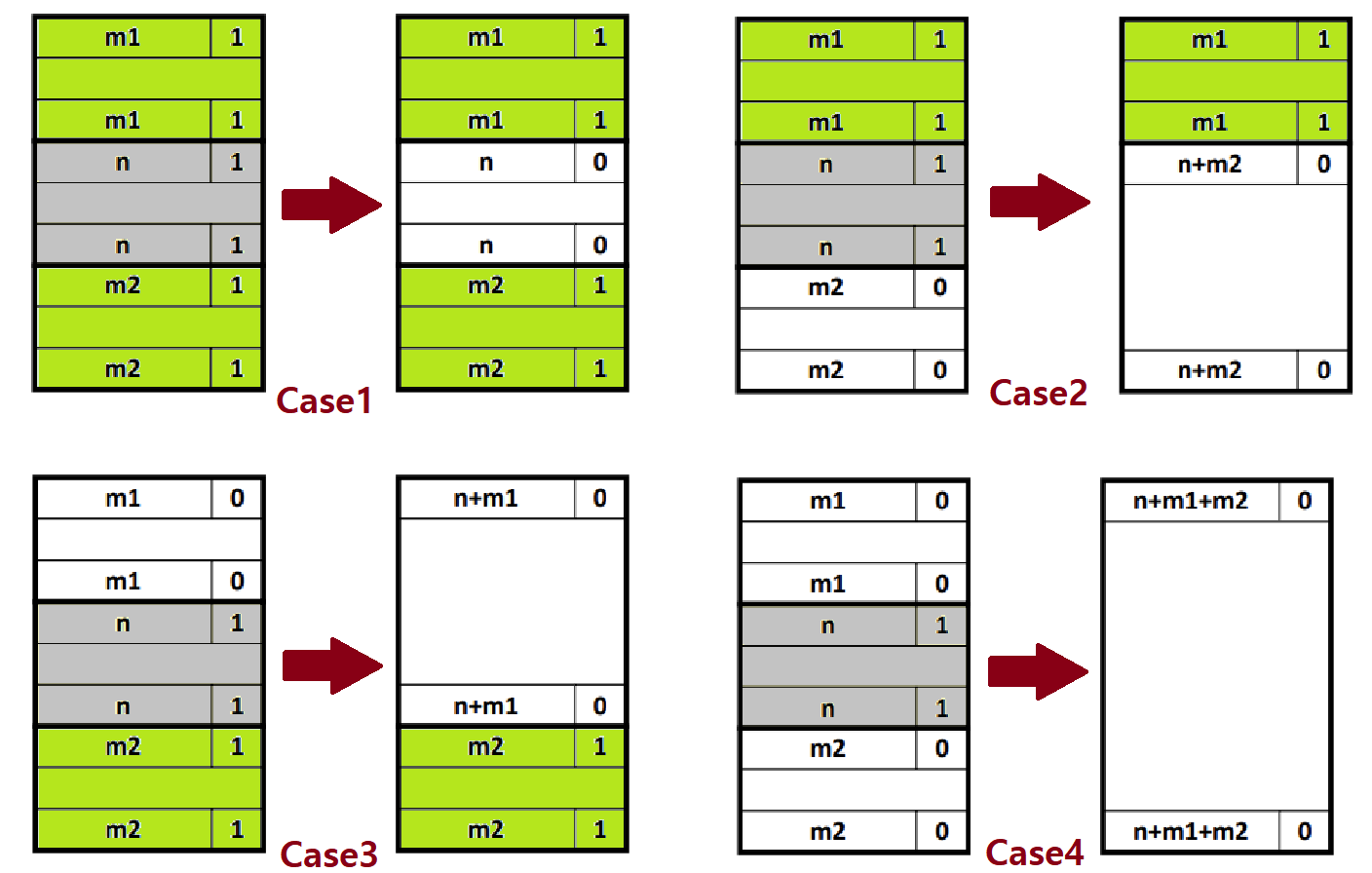
~> 과거 SP에선, Implicit(or Explicit or Segregated) Free List 구현 간에 위와 같이 Bidirectional Coalescing을 적용할 수 있음을 알아본 바 있다. (여기선, Header와 Footer는 신경쓰지 말도록!)
Tracking Regions
한편, Memory Management에서 Tracking도 상당히 중요하다. Allocated Region, Freed Region을 각각 Tracking해야한다. Tracking을 통해 현재 Memory 상태를 알아야, 이후의 Memory를 관리할 수 있기 때문이다.
그러한 Tracking을 위해선 아래 그림과 같이 Allocated Block에 특정 정보를 담는 Header를 마련해야한다.

-
Header Block을 추가로 두고, 해당 Block에 Extra Information을 저장한다.
- Size, magic Number 정보를 담는다.
(이는 구현에 따라 다름. 본 교재에선 이 형식을 채택한 것임!)- magic Number는 Region을 Free할 때 Integrity Checking 용도로 사용된다. ★★★
- 쉽게 말해 넘겨받은 Block이 Allocated인지, 그리고 Free 후 주변과 Coalescing할지 말지 결정할 때 사용하는 Flag라는 것!
- magic Number는 Region을 Free할 때 Integrity Checking 용도로 사용된다. ★★★
- Size, magic Number 정보를 담는다.
-
malloc이 반환한 위치는 ptr이 가리키는 위치(Block의 실제 데이터가 시작하는 위치)이고, 이 Allocated Block의 Header는 ptr이 가리키는 위치에서 8Bytes 위쪽에 마련된다.
- Header에는 Size와 magic Number 정보가 있으며, Size는 말그대로 '요청'된 크기이다.
Actual Chunk Size of malloc(N) = N + Header Size 8
이러한 Header의 용도는 다음과 같은 예시 상황에서 명확히 나타난다.
"free Function은 Size Parameter가 없는데 free할 Size를 어떻게 알까?"
~> Target Block의 Header에서 Size 정보를 추출해서 알 수 있다.
"free Function에선 넘겨받은 Block이 Allocated인지 어떻게 알까?"
~> Target Block의 Header에서 magic Number를 추출해 알 수 있다. 일종의 Is_Allocated_Flag인 것이다.
void free(void *ptr) {
header_t *header = (void*)ptr – sizeof(header_t); // Header 추출
// malloc의 반환 포인터를 받은 ptr은 Allocated Block의 Payload 시작 위치
// 를 가리키므로, 그 위치에서 8Bytes 위쪽으로 Pointer Arithmetic을 해야함!
…
assert(header->magic==1234567); // 정상적인 Free인지를 확인할 수 있음.
…
}~> Block Header의 magic Number가 1234567이면 Allocated Block이다!!! ★
(본 시리즈 참조 교재 상에서)
한편, Free Region에 대한 Tracking도 중요하다. 초기 Heap은 하나의 커다란 Free Region이고, 당연히 Free List엔 단 하나의 Entry만 있을 것이다.
Free Region이 Memory Allocation 요청으로 인해 여러 개의 작은 Free Region으로 분리되고, 이들은 당연히 서로 인접하지 않을 수 있다.
Free List를 구축하여 Free Region들을 Tracking한다! (ex. Linked List)
typedef struct _node_t {
int size;
struct _node_t *next; // 다음의 '인접하지 않은' Free Block을 가리킨다.
} node_t; // Coalescing 때문에 항상 'Not Adjacent'임. ★★즉, Allocated Block의 Header엔 Size, magic Number가, Free Block엔 Size, Next Pointer가 있는 것이다. ★★★
Examples
예를 들어보자. 초기 Heap이 mmap( ) System Call을 통해 커다란 공간으로 구축되었다고 하자.
/* OS initializes the heap with mmap() */
// mmap()은 Free Space의 Chunk에 대한 Pointer를 반환한다.
node_t *head = mmap(NULL, 4096, PROT_READ|PROT_WRITE, MAP_ANON|MAP_PRIVATE, -1, 0);
head->size = 4096 - sizeof(node_t); // Header Size를 제외한다!
head->next = NULL; // 초기 Next Pointer 설정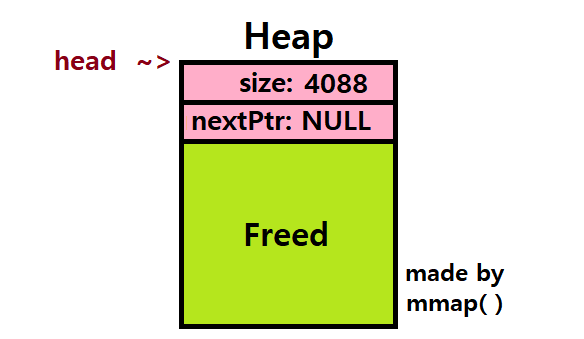
- 위 그림은 최초의 Heap 상태를 보여준다. 이 예시의 OS는 4K = 4096Bytes의 Free Space를 mmap( ) System Call을 통해 마련한다.
-
이때, Tracking을 위해 상기한 Freed Region Format에 맞게 Header를 구축한다.
-
Header는 8Bytes이므로, Size 정보엔 4096-8 = 4088Bytes가 들어간다. ★
-
Next Pointer는 일단 없으므로 NULL로 초기화한다.
-
-
이때, 위의 상황에서 User Program은 OS에게 100Bytes 공간을 Heap에 할당해달라고 Request하는데, 이를 총 3번 요청하였다. 아래 그림과 같이 말이다.
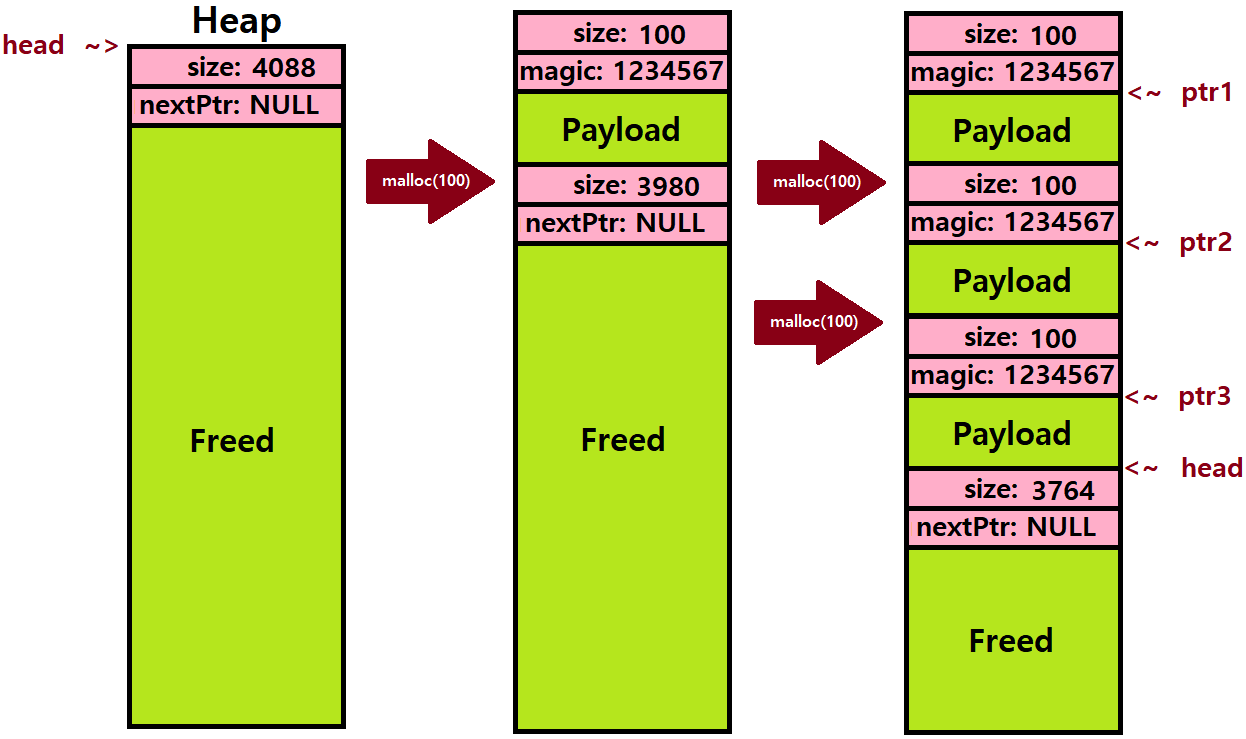
-
User Program이 100Bytes를 달라고 요구하면, 실제 Heap에는 Header를 포함해 108Bytes가 할당된다.
- 따라서, 최초의 Heap 크기 4096에서 108이 할당되어 빠지는 것이다.
- 4096-108 = 3988Bytes가 남는다. 이때, 마찬가지로 Freed Region의 Header를 고려해, 실제 Free Space의 Size는 3980이 된다.
- 따라서, 최초의 Heap 크기 4096에서 108이 할당되어 빠지는 것이다.
-
이 상태에서 두 번의 같은 Request를 반복하면, 3988 - 108x2 = 3772Bytes가 남고, 역시나 Header를 고려하면, 최종적으로 (only one) Free Space의 Size는 3764가 된다.
자, 이제 Free를 해보자. Allocation을 받아들인 Pointer Variable을 순서대로 ptr1, ptr2, ptr3라 하고,
ptr2->ptr1->ptr3의 순서대로 free( ) Function을 호출해보자.
(Heap의 시작 주소가 16KB = 16384번지라고 가정한다 ★)
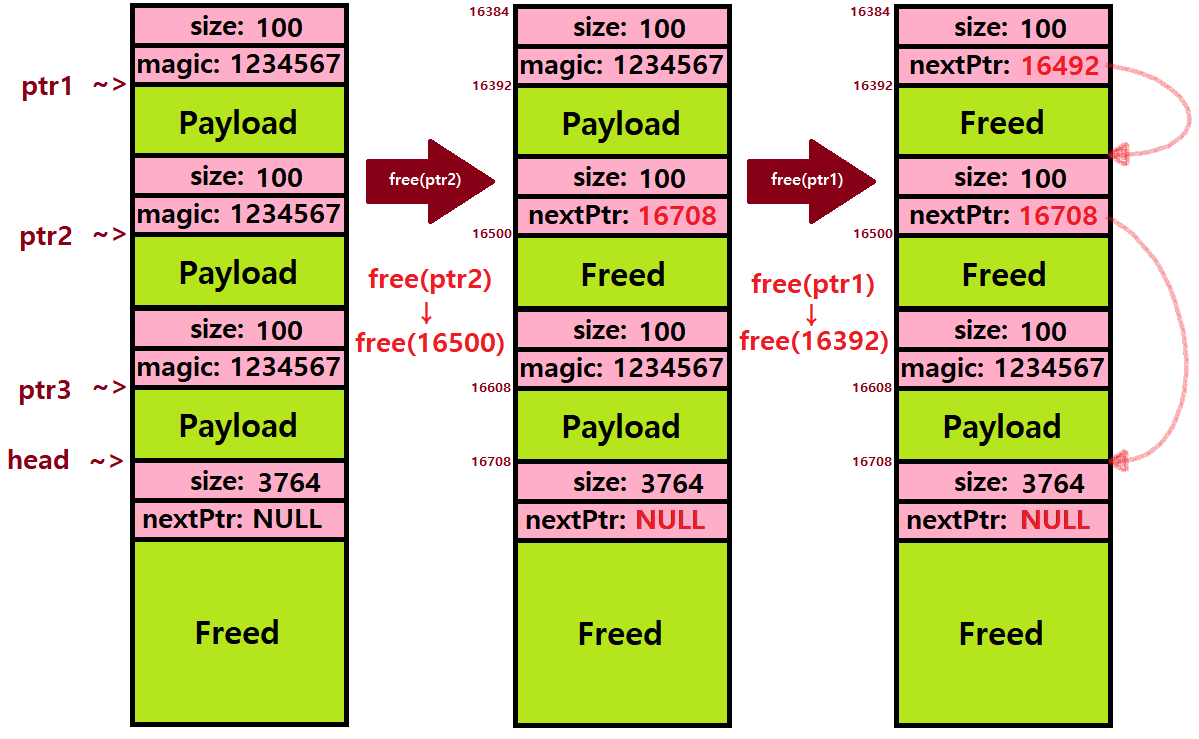
~> Newly Freed Block의 앞 뒤는 모두 Allocated Block으로, Coalescing이 필요 없다(일단, 잠시 Coalescing은 고려하지 말자). 이 Block의 Next Pointer는 기존 Free List의 Head에 위치했던 '큰 블록'을 가리키도록 만들어주자.
~> 이어서 ptr1이 가리키는 Allocated Block이 Free된다. ptr1이 가리키는 위치는 16392번지이다. malloc의 반환 주소는 Payload의 시작 위치이기 때문이다. ★★
~~> 허나 Free를 위해선 Payload가 아니라, Header를 알아야 한다. 따라서, ptr1이 가리키는 위치에서 8Bytes 앞으로 이동한 후, 그곳에서 작업을 해준다. ★★
===> Freed Block에선 Payload의 위치가 아니라 해당 Block의 시작 위치가 중요하기 때문에, Next Pointer는 '기존의 큰 블록'의 Payload 위치가 아니라, 'Block의 시작 위치'를 가리키도록 만들어준다. 여기선, 16708번지가 되겠다. ★
-> 이러한 Free Mechanism을 고려해봤을 때, 우리는 다음과 같이 free( ) Function을 설계할 수 있을 것이다.
/* 현재 예시의 OS는 Free List의 Freed Block 삽입 간에
'맨 앞에 삽입' Policy를 따른다고 가정! */
void free(*ptr) {
void* temp = head; // '기존의 head가 가리키는 Block의 시작주소'를 임시 보관
head = ptr - 8; // head는 이제 '넘겨 받은 Block의 Header 주소'를 가리킴!
head->next = temp; // 새 head는 '기존의 head'를 Next Block으로 취급한다!
}
// Heap은 위로 확장하기 때문에 ptr - 8인 것이다. ★★★동일한 원리를 토대로 free(ptr3)까지 수행하면 Heap의 상태는 아래와 같아진다. Next Pointer는 Next Freed Block의 시작 주소를 가리키고, free의 Parameter인 ptr은 Allocated Block의 Payload 시작 위치를 가리키고 있음을 반드시 기억하자. ★
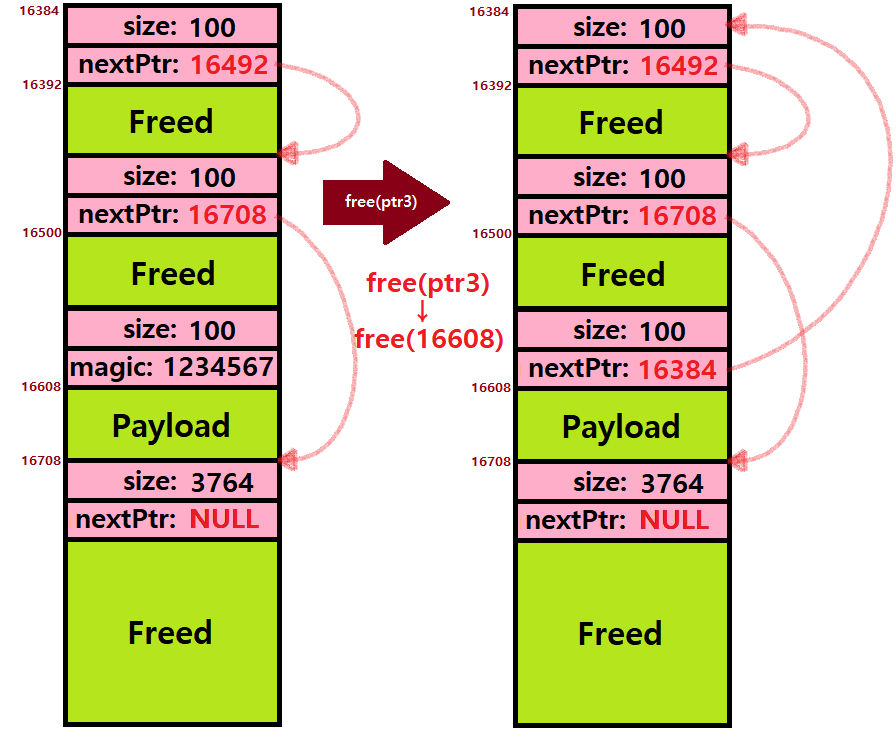
~> 하지만, 이게 끝은 아니다. Coalescing이 필요하다. Coalescing은 여러 가지 방식으로 할 수 있는데, 하나는 Free할 때마다 당장 Coalescing하지 않고, 특정 시간이 지날 때만 한 번에 Coalescing하는 방식이 있을 수 있고, 다른 하나는 매번 Free할 때마다 Coalescing하는 방식이 있을 수 있다.
=> 우리는 전자를 채택했다고 가정하면, 특정 시간 소요 후 다음과 같이 Coalescing이 일어나 최초의 Heap 상태로 돌아가게 될 것이다.
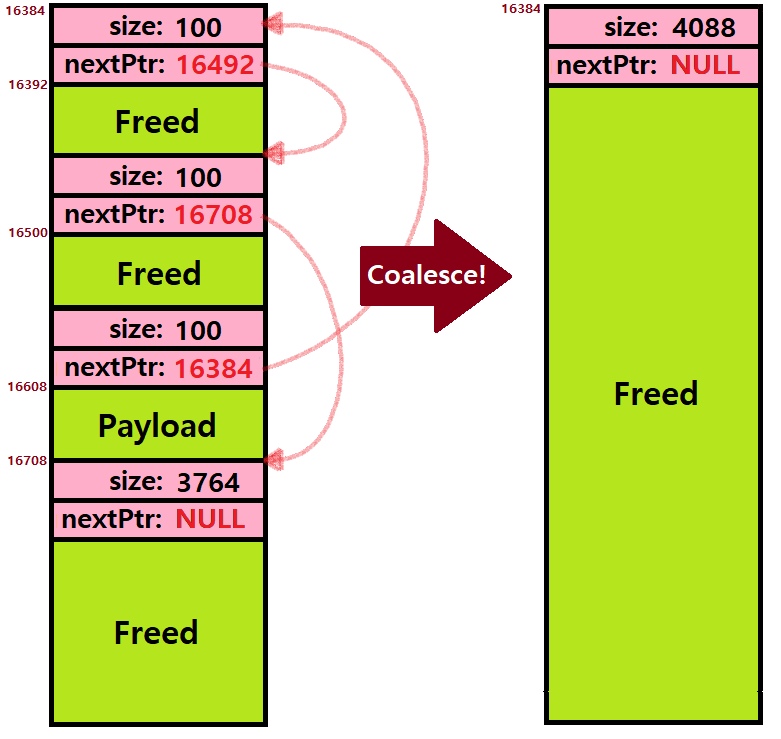
여담) Coalescing은 External Fragmentation을 해결하기 위한 Method 중 하나이다. External Fragmentation은 추후 다시 설명할 것이지만, 간단히 말하면, 합쳤을 땐 Request를 Cover할 수 있는데, 안 합치면 Cover하지 못하는 그런 상황을 의미한다.
여담) 반대 개념인 Internal Fragmentation은 Block 내부에서의 희생 공간을 의미한다. Header나 Footer같은 것 말이다.
여담) 이러한 내/외부 단편화 문제를 해결하기 위한 다양한 Heap 관리 방법론이 존재한다. SP에서 다루었던 그것들을 포함해서 말이다! 하지만, 기억나는가? 내/외부 단편화는 서로 Trade-Off 관계에 있기 때문에, 둘 모두를 만족시키는 방법론을 찾기란 쉬운 일이 아니다. 내부 단편화를 줄이면 공간 효율은 높아지지만 Searching이 오래 걸리는,, 그런 느낌이다. (과거에 다 설명했다)
How to find FREEs
한편, Memory Allocation 시 Free List에서 적절한 Free Region을 어떻게 찾을 것이냐라는 Issue도 존재한다. 이 역시 마찬가지로 SP에서 자세히 다루었던 바 있다. 다시 한 번 복습해보자. 아래와 같이 크게 4개의 Approach가 있다.
- (1) Best Fit
- Request의 Size 이상인 Free Chunk들을 찾는다.
- 그 중 가장 작은 Chunk를 선택한다.
- 즉, '딱 알맞는 Freed Block'을 찾아 Allocation한다는 것이다!
- 이를 위해선 Free List를 Full Iteration해야한다. ★
- (2) Worst Fit
- Free List에서 가장 Size가 큰 Free Chunk를 찾는다.
- 즉, 할당하고 나서 남는 공간이 가장 큰 Block을 찾는 것이다.
- 이게 꼭 나쁜게 아니다. Best Fit을 생각해보자. 딱 알맞는 Block만 찾는다면, Allocation을 하고 나서 남는 Free 공간이 다시 Allocation의 Selection 대상이 될 확률이 얼마나 높을까? 그렇다. 별로 안 높다. ★
- 즉, Best Fit은 External Fragmentation 측면에서 우수하지 않다. 반면, Worst Fit의 경우 Allocation하고 남은 공간이 다시 Allocation의 대상이 될 가능성이 높아 External Fragmentation 측면에서 좋다. ★★★
- 하지만, Internal Fragmentation 측면에선 Best Fit이 더 좋다고 알려져 있다.
- 즉, Best Fit은 External Fragmentation 측면에서 우수하지 않다. 반면, Worst Fit의 경우 Allocation하고 남은 공간이 다시 Allocation의 대상이 될 가능성이 높아 External Fragmentation 측면에서 좋다. ★★★
- 이게 꼭 나쁜게 아니다. Best Fit을 생각해보자. 딱 알맞는 Block만 찾는다면, Allocation을 하고 나서 남는 Free 공간이 다시 Allocation의 Selection 대상이 될 확률이 얼마나 높을까? 그렇다. 별로 안 높다. ★
- 즉, 할당하고 나서 남는 공간이 가장 큰 Block을 찾는 것이다.
- Request에 대해 Allocation을 수행하고 나머지는 Free List에 다시 넣는다.
- 당연히 Full Iteration이 필요하다. ★
- Free List에서 가장 Size가 큰 Free Chunk를 찾는다.
- (3) First Fit
- Request를 Cover할 수 있는 Chunk가 처음으로 발견되면, 그 Chunk를 그대로 선택하는 방식이다.
- 즉, 처음으로 가능해지면 바로 선택한다! (Not Full Iteration)
- (4) Next Fit
- 기본 Principle은 First Fit의 그것과 동일하다.
- 하지만, Free List에서 '가장 최근 Search에서 Selection됐던 Block 위치'에서 그 다음 Block부터 찾는다.
- First Fit에선 Free List의 앞 쪽 Block들이 계속해서 선택된다는 단점이 있는데, 이를 개선한 것이다. ★

~> Workload에 따라 달라지겠지만, 일반적으로 Best Fit과 First Fit이 가장 우수하다고 알려진다.
Segregated List
지금까지 우리는 Linked List 기반의 Heap Management에 대해 알아보고 있다. 구체적 명칭은 언급하진 않았지만 SP에서 소개했던 Implicit List, Explicit List 방식을 배운 것이라 보면 된다. 허나, 이러한 (Single) Linked List 기반의 Approach들은 다음과 같은 문제점들이 존재한다.
-
External Fragmentation이 높아질 가능성이 있다. ★
-
Same Size의 Request, Popular Size의 Request의 처리에 그닥 효율적이지 않다. ★
- 계속 List에 넣었다 뺐다 해야하기 때문!
이러한 단점을 극복하기 위해 고안된 방법이 바로 Segregated List 방식이다.
Segregated List : 특정 Size(주로 Popular Size)의 Request들에 대해 미리 Allocated된 Memory Chunk들을 특정 자료구조 형태로 준비해놓는 방식 ★
굳이 '자주 Request되는 Size'들에 대해 매번 할당하고 해제하는 일을 반복하지 말고, 미리 그에 대한 공간을 마련해두자는 것이다. ★★
다른 Size의 Request에 대해선 기존의 방식을 사용한다.
- Linux의 Slab Allocator가 이에 해당한다.
Slab Allocator

-
Slab Allocator
-
Segregated List 기반 Approach이다.
-
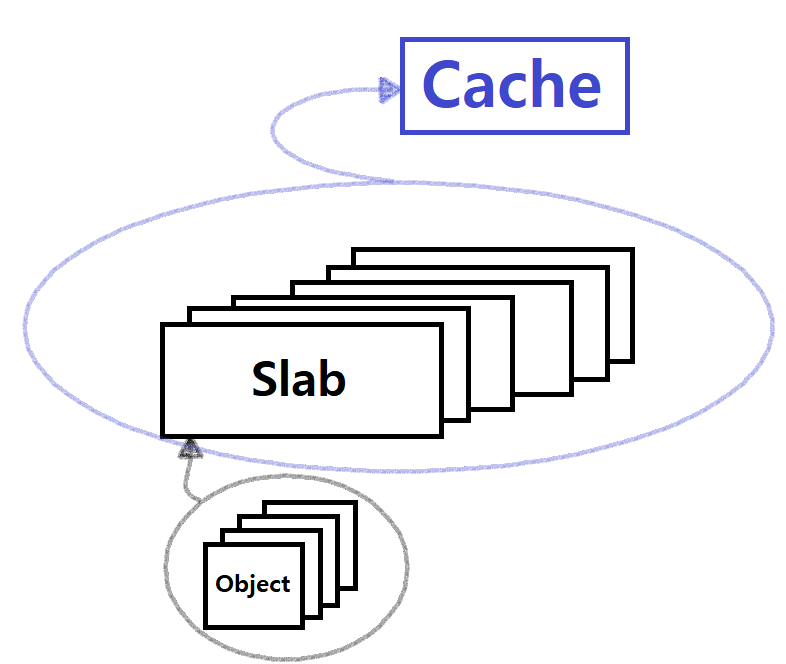
Slab : Kernel Page의 집합 ★
-
각 Kernel Page들은 똑같은 크기의 Object들로 구성된다. ★
-
이러한 Slab들이 모여 Cache를 이룬다. ★
-
-
즉, 'Objects -> KernelPages -> Slabs -> Caches -> SlabAllocator'
-
Allocate memory & Construct the object!
- Use the object!
- Reuse possible data structures rather than release! ★★★
- Use the object!
-

-
큰 판대기인 Slab에 Kernel Page들을 모아놓는다.
- 각 Page엔 같은 크기의 Object들을 넣어놓는다.
-
그러한 Slab들을 모여서 Cache를 이룬다.
-
정해진(대중적인) 크기의 자료구조를 Allocation할 때는, 굳이 새로 생성/해제하지 말고, 그냥 이렇게 미리 Kernel에 마련된 공간을 사용한다는 것이다. ★
- Flag를 바꾸는 식으로 할당/해제를 취급하는 것이다.
- 주로 Kernel Memory Allocation에 사용된다.
- Flag를 바꾸는 식으로 할당/해제를 취급하는 것이다.
~> 이러한 Segregated List는 실제 구현 시에는 Multiple Linked Lists가 있는 형태로 구현될 수 있겠다. SP에서 수행했던 malloc-lab Project를 참고하도록 하자.
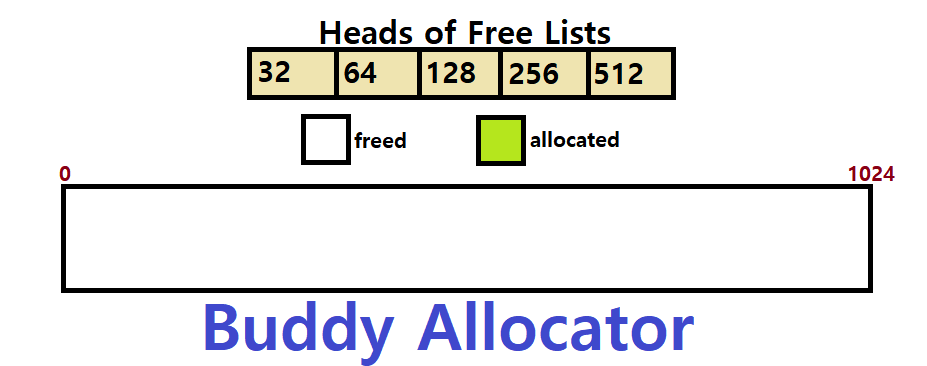
Buddy Allocator
본 포스팅의 마지막 개념은 Buddy Allocator로, 최근에 가장 많이 쓰이는 Memory Allocation 방식이다.
-
Buddy Allocator
-
Free Memory를 2^n 사이즈의 Big Space로 설정한다.
- 2^n 꼴이 가장 효율이 좋다고 알려져 있다.
- 다만, 이로 인해 Internal Fragmentation을 어느 정도 감수해야하는 문제가 있다. ★
- 2^n 꼴이 가장 효율이 좋다고 알려져 있다.
-
Memory Allocation Request가 오면 2^n 크기의 Free Memory를 Recursive하게 계속해서 반으로 나눈다.
- Request를 Cover할 수 있으면서 가장 작은 사이즈가 될 때까지 나눈다.
-
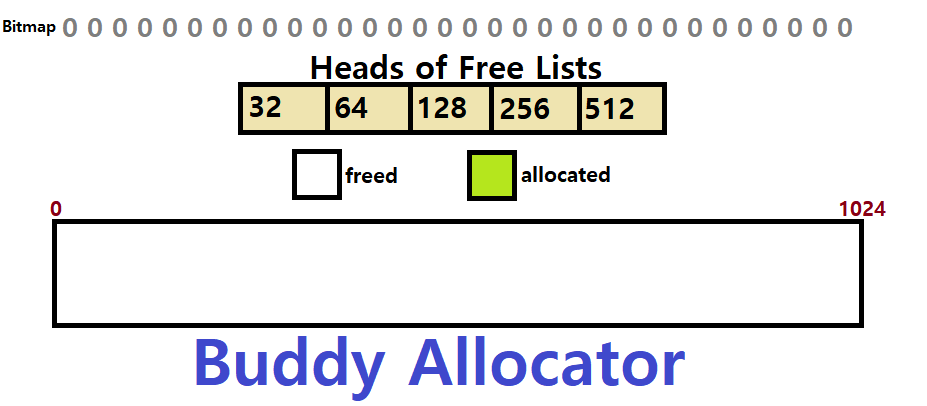
ex) 예를 들어보자. 전체 Free Space의 크기가 K, 즉, 1024라 하자. 이때, 10Bytes에 대한 Memory Allocation Request가 왔다.
1024
512 / 512
256 / 256 / 512
128 / 128 / 256 / 512
64 / 64 / 128 / 256 / 512
32 / 32 / 64 / 128 / 256 / 512
~> 이렇게 Division이 이뤄진다. 왜 32까지만 나누었냐면, 보통 이러한 Buddy Allocator는 Minimum Threshold를 두기 때문이다. 너무 많이 나뉘는 것을 방지하기 위해 말이다.
~~> 따라서, 10Bytes Request에 대해 32Bytes의 Block이 할당된다!
===> 이러한 '하한'이 있기에, 1Byte만 요청하더라도 32Bytes의 Block이 할당될 것이다.
-
왜 'Buddy' Allocator라 불리는가?
-
Buffer(Free Space)를 반으로 쪼갤 때 생기는 같은 크기의 Block들을 'Buddy(친구)'라고 부르기 때문이다. 사이즈가 같으니 친구인 것이다!
-
이러한 Buddy의 상태를 계속해서 체크해가며 할당할지 말지를 결정한다.
-
-
Allocated Block이 Free되면, 해당 Block의 Buddy가 Freed인지 확인하고, Freed일 경우 하나의 Block으로 Coalesce한다. 그리고, 이를 Recursive하게 반복한다! 멈출때까지! ★
- 2^k + 2^k = 2 x 2^k = 2^(k+1)
- 여전히 2^n꼴을 유지한다.
- 2^k + 2^k = 2 x 2^k = 2^(k+1)
-
주로 이러한 Buddy Allocator의 구현에는 Bitmap이 사용된다.
- Bitmap을 이용해 각 Block의 상태를 체크할 수 있다.
- 자세한 원리는 아래 예제에서 확인하자!
- Bitmap을 이용해 각 Block의 상태를 체크할 수 있다.
-
또한, 각 Size의 Buffer(Free Space)에 대해 각각 Free List를 운용한다.
- ex) 32Bytes에 대한 Free List, 64Bytes에 대한 Free List, ...
- Segregated적 요소!
- ex) 32Bytes에 대한 Free List, 64Bytes에 대한 Free List, ...
Buddy Allocator Implementation : Bitmap + Multiple Free Lists
Examples
이제 예제를 통해 Buddy Allocator를 이해해보자. 위의 상황과 똑같은 상황을 상정한다. 초기 Buffer Size는 1024이고, 하한은 32이다.
-
1024 / 32 = 2^10 / 2^5 = 2^5
- 총 32비트(1B)로 이루어진 Bitmap만 있으면 각 Block의 Status를 모두 체크할 수 있다.
- How?
- 1024가 끝까지 Recursive하게 반으로 쪼개지면 32Bytes의 Block이 32개가 되기 때문이다. 1비트가 32Bytes Block 한 개의 Status(Is_Allocated?)를 나타내고, 예를 들어 256Bytes의 Block은 8-Bit로 상태를 파악할 수 있는 것이다. ★★★
- How?
- 총 32비트(1B)로 이루어진 Bitmap만 있으면 각 Block의 Status를 모두 체크할 수 있다.
-
Free List는 32부터 512까지의 Size에 대해 각각 존재한다. (1024는 초기값이고, 아무 할당이 없는 상태를 의미하므로 굳이 Free List를 만들 필요가 없음)
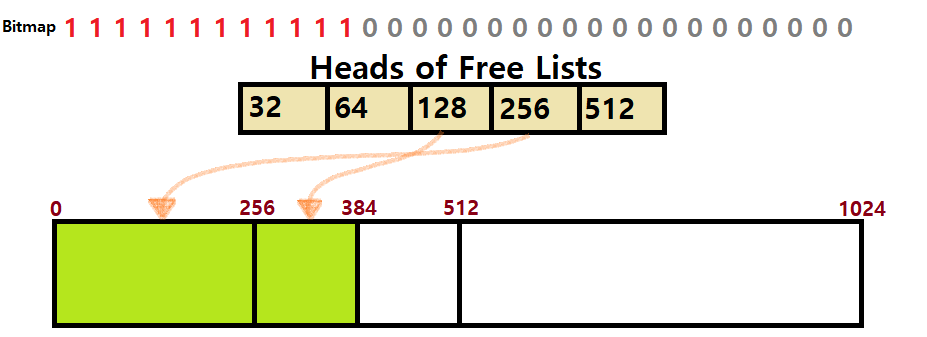
- 자, 먼저 256Bytes에 대한 Allocation Request가 왔다고 하자. 그럼, "1024 -> 512 / 512 -> 256 / 256 / 512"의 흐름으로 분리될 것이다.
- 첫 번째 256Bytes Block을 할당하자.

- 자, 이번엔 128Bytes를 달라고 하자. 현재 ㅁ / 256 / 512인데, 이 중 256만 나누면 될 듯하다. 실제 Buddy Allocator의 논리도 이러하다.
- ㅁ / 128 / 128 / 512가 된다. 이 중 첫 번째 128을 할당하자.
- "Free Block만 반으로 쪼갠다. 당연히."
- ㅁ / 128 / 128 / 512가 된다. 이 중 첫 번째 128을 할당하자.
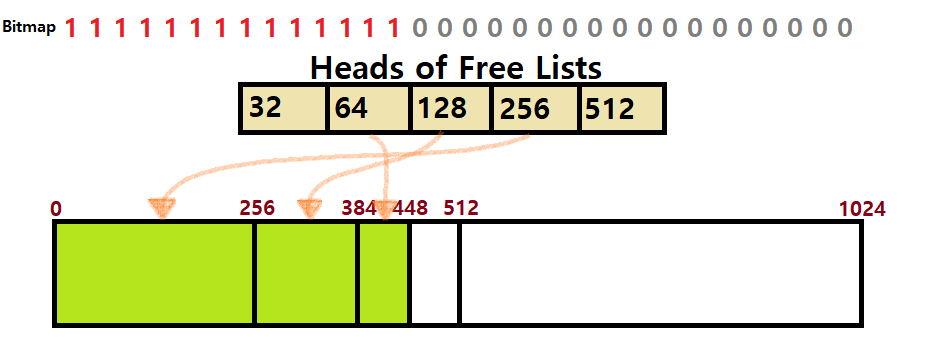
- 다음 요청은 64바이트이다. 앞선 예시들과 동일한 논리로 처리한다.
- ㅁ / ㅁ / ㅁ / 64 / 512가 될 것이다.
- 이번엔 128바이트를 할당해보자. ㅁ / ㅁ / ㅁ / 64 / 512에서 512 블록을 128 / 128 / 256으로 분리한 후, 맨 앞 128에 할당하면 될 것이다.
- ㅁ / ㅁ / ㅁ / 64 / ㅁ / 128 / 256이 되는 것이다.
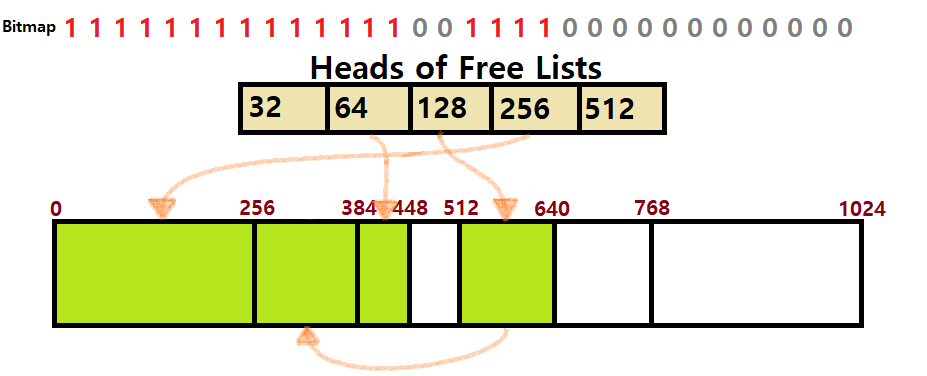
- 이제는 Free를 해보자. 첫 번째 128Bytes 할당 공간을 Release하자. 해당 Block의 양 옆에는 Freed Buddy가 존재하지 않는다. 따라서 해제하기만 하면 된다.
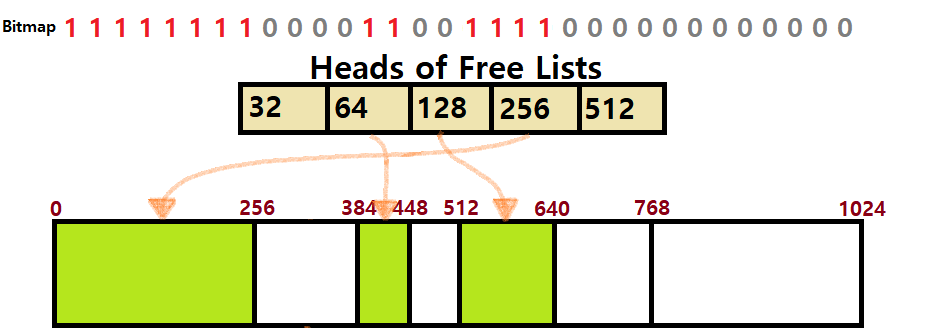
-
그렇다. 이번엔 그 우측의 64Bytes 할당 공간을 Release하자. 해당 Block의 우측에는 똑같은 64Bytes 크기의 Freed Buddy가 존재한다.
-
Coalesce한다.
- 128Bytes의 Freed Block이 되었다. 그런데, 이 Block의 좌측엔 똑같은 128Bytes의 Freed Buddy가 또 존재한다!
- 역시나 Coalesce한다.
- 최종적으로 256Bytes의 Freed Region이 생겨났다!!
- 'Recursively Free with Buddies!'
- 최종적으로 256Bytes의 Freed Region이 생겨났다!!
- 역시나 Coalesce한다.
- 128Bytes의 Freed Block이 되었다. 그런데, 이 Block의 좌측엔 똑같은 128Bytes의 Freed Buddy가 또 존재한다!
-
이러한 'Buddy Checking'에 Bitmap이 사용되는 것이다. 현재 Freed Block의 Size만큼만 Bitmap을 양 옆으로 탐색해, Bit Value가 0이면 Coalesce하는 것이다. ★
-

~> Buddy Allocator는 이런 논리로 진행된다. ★
Pros and Cons
이러한 Buddy Allocator는 Linux Kernel에서 사용하는 Memory Allocating 방식이다. Heap 할당에서도 사용되고, 굳이 Heap 뿐만이 아니라 '연속적인 메모리에 대한 할당/해제'가 필요한 부분에선 어디든지 적용되는 개념이다. ★★★
-
Buddy Allocator의 특징
-
2^n꼴의 Block만 취급하므로 Internal Fragmentation이 높다.
- 만약, 작은 크기의 Object들만 계속 할당한다면 공간 효율이 좋지 않을 것이다.
-
Bitmap을 사용하기 때문에 Buddy를 찾기가 쉽다. (효율적이다)
- Coalescing에도 용이하다. Bit 반전만 하면 되기 때문!
-
-
Buddy Allocator의 장점
- Adjacent Free Buffer에 대한 Coalescing이 용이하다.
- External Fragmentation이 매우 좋아진다. (Trade-Off with Internal Fragmentation) ★★★
-
Buddy Allocator의 단점
- Buffer를 Free할 때마다 매번 Recursive하게 Coalescing이 이뤄지기 때문에 성능적인 단점이 있다. Overhead가 높다. ★★
- 또한, Release할 때 Buffer의 Address와 Size 정보가 모두 필요하다. ★
금일 포스팅은 여기까지이다. 다음 포스팅에선 Address Translation을 다룰 것이다!
