지난 시간까지는 Logical Space에 있는 Free Region을 어떻게 할당하고 관리할 것인가 대해 알아보았다. 이번엔 OS가 Process의 Memory Loading을 어떻게 하는지 알아보자. Process를 Memory에 Load할 때 어떠한 일들이 일어나는지를 알아볼 것이다.
Process Loading
-
Memory Virtualization
-
각 Process가 자신의 Memory Space를 각각 가지는 것과 같은 Illusion을 제공
- 마치 각 Process가 Memory 전체를 사용하는 것처럼 보임.
-
이러한 Memory Virtualization을 통해 우리는 다음과 같은 이득을 얻는다.
- Programming이 쉬워짐.
- 시공간적 측면에서 Memory Efficiency가 좋아짐.
- Process마다, 그리고 OS까지, 모두에게 Isolation을 제공해 안전성을 높임.
- 'Protection from errant accesses of other processes'
-
~> 이러한 가상화의 제공을 위해, Process Loading 과정에선 다음과 같은 고민이 필요하다.
"어디다 Load할 것인가?"
"어떻게 Mapping할 것인가?"
=> 이제 이들에 대해 알아보자. (사실 앞전에 이미 Paging 기법을 소개한 바 있지만, 우선 그에 앞서 개발되었던 Old-Fashioned Approaches에 대해 알아볼 것임. Paging은 추후 자세히 다룰 것!)
-
우리는 본 포스팅의 학습 간에 다음과 같은 가정을 적용한다. (학습 편의성 목적)
-
Virtual Address Space가 Physical Memory보다 사이즈가 작다.
- 실제는 Logical이 더 큰 경우가 대다수
- 즉, Disk Loading은 일단 고려 x
- 실제는 Logical이 더 큰 경우가 대다수
-
하나의 Virtual Address Space는 Physical Memory에 연속적인 형태로 Load된다.
- 실제로는 쪼개져서 올라가는 경우가 대다수
- 이 역시 현재는 고려 x (애초에 구식 방식이기 때문에 이 기능 자체가 x)
- 실제로는 쪼개져서 올라가는 경우가 대다수
-
각 Virtual Address Space의 크기는 동일하다.
- 실제로는 당연히 각기 다름!
-
위와 같은 가정을 고려한채, 아래의 간단한 예시 프로그램을 보자.
int main(int argc, char *argv[]) {
int a;
a = a + 4;
}~> 이 Program을 Linux에서 'objdump'라는 Command를 통해 Assembly Code로 변환하면 다음과 같은 명령부가 포함된다. ex) "objdump -d simple(process_binary)"
0x20: movl 0x8(%rbp), %edi # rbp에 8을 더해서 edi로
0x23: addl $0x4, %edi # edi에 4를 더하고
0x29: movl %edi, 0x8(%rbp) # edi 값을 rbp에 8을 더한 위치에!
# 이때, 0x20, 0x23 이런건 모두 Commands의 Logical 주소임.
# 참고로, 0x8(%rbp)인 이유는, argc, argv가 a보다 먼저 할당
# 되었음을 의미함. ASM의 논리!-
%rbp Register : 현재 Stack Frame의 Base를 가리키는 Base Pointer를 담는다.
-
%rip Register : Instruction Pointer Register이다.
-
%rip = 0x20, %rbp = 0x300이라고 가정하자. (Commands는 Code Segment이므로 낮은 주소 부근에 있고, Stack Frame은 Stack Segment이므로 높은 주소 부근에 있음)
-
1) 0x20 위치의 Instruction을 Fetch
- 수행 내용: 0x308 주소의 Value를 Load (0x308: 변수 a의 스택 내 위치임)
-
2) 0x23 위치의 Instruction을 Fetch
- 수행 내용: Memory Access 없이 단순 ALU 계산
-
3) 0x29 위치의 Instruction을 Fetch
- 수행 내용: 0x308 주소에 Value를 Store
-
~> Assembly Programming에 대해 배웠다면 매우 간단히 이해할 수 있을 것이다.
=> 여기서 우리의 의문은 다음과 같은 질문이다.
Assembly Level에서 Address는 Process Binary 내에서 Hardcoded되어 있다. 이게 무슨 말이냐면, 쉽게 말해 고정되어 있다는 것이다. 100개의 Process로 Simple Program을 각각 돌렸을 때, 매번 'objdump' 시 위와 같은 주소가 나온다는 것이다.
이때, Multiple Processes가 동시에 돌아가면, 모두 똑같은 주소를 참조하고 있는데 Collision이 어떻게 안일어날까?
도대체 Process Loading 시 어떠한 Memory Virtualization이 일어나는 것인가?
Time-Sharing, Static / Dynamic Relocation 등의 Mechanism을 통해 Collision을 회피하며 Process Loading을 수행한다. ★★★
~> 이제, 이들에 대해 하나 하나 알아보자.
Time-Sharing (Memory)
OS가 CPU Virtualization을 제공하는 것과 관점이 다른 이야기다. 허나, 관점은 다르지만, 결국 원리는 같다.
- OS는 Process Context Switch를 위시한, 'CPU Registers Set Saving/Restoring'을 통해 CPU Virtualization을 제공한다.
- 마찬가지로, OS는 Memory를 Disk에 'Saving/Restoring'하면서 Memory Virtualization을 제공할 수 있다. (Time-Sharing(Memory) 기법)
-
Time-Sharing (Memory)
-
현재 돌고 있지 않은 Process의 Memory를 Disk에 저장하고, 다시 돌아갈 때 Main Memory로 Restore한다.
-
허나, Poor Performance가 자명하다.
- 매번 상당히 큰 크기의 Memory를 넣었다 뺐다 해야하기 때문!
-
개선책으로, Memory Space를 동시간대에 Process별로 분리해서 할당하는 방법도 존재한다.
- 바로 아래의 Static Relocation Method! (후술)
-
Time-Sharing Method : Memory를 Time-Sharing마다 Swap하는 것 ★
Obviously, this method will have great overheads.
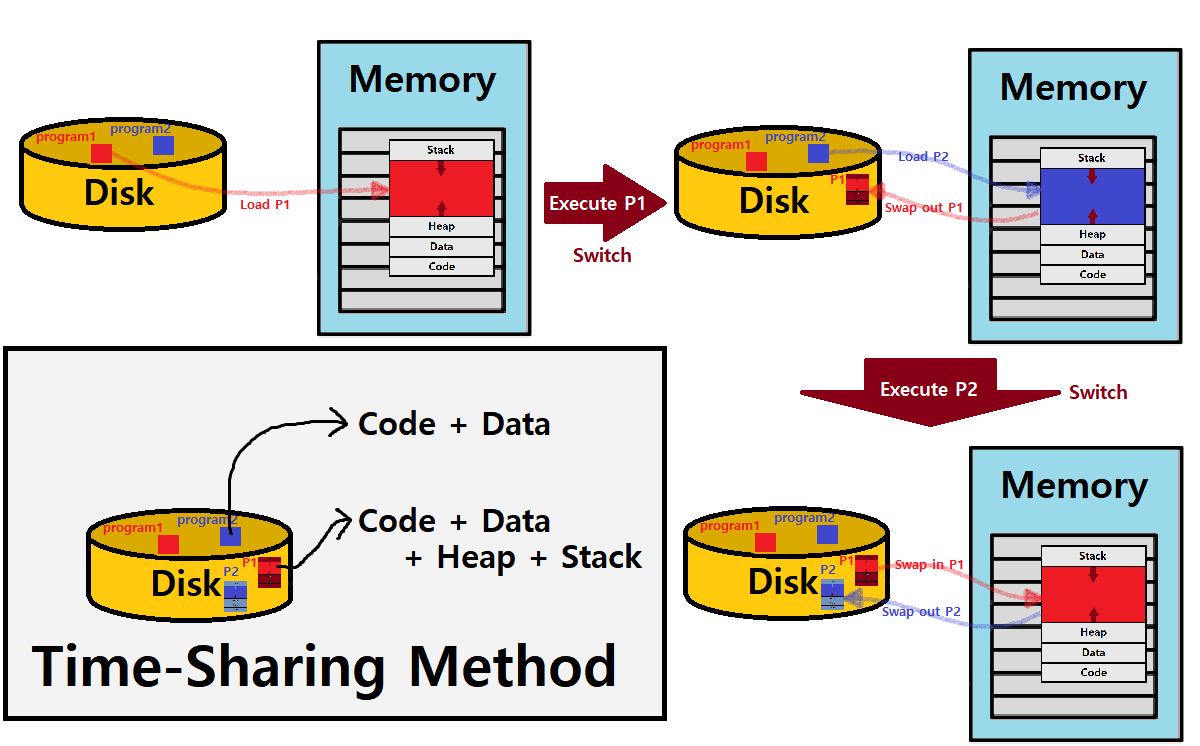
- 이 방식에선 Disk 내에 Program의 Executable File ELF와 Process의 Virtual Address Space 정보가 서로 별개로 존재함을 기억하자. Running Program을 위해선 Heap과 Stack 데이터도 필요하기 때문이다. ★
Static Relocation
Static Relocation : Process가 올라갈 Physical Memory를 Static하게 지정하는 방식이다.
OS는 특정 Program을 Memory로 올려 Process를 만들 때, 해당 Program에 대해 Rewrite한다. (ELF를 VAS꼴로 Main Memory에 올리되, Address를 다 바꾼다는 것임)
Rewrite는 각각의 Process에 대해 서로 다른 Address와 Pointer를 부여한다. ★★★
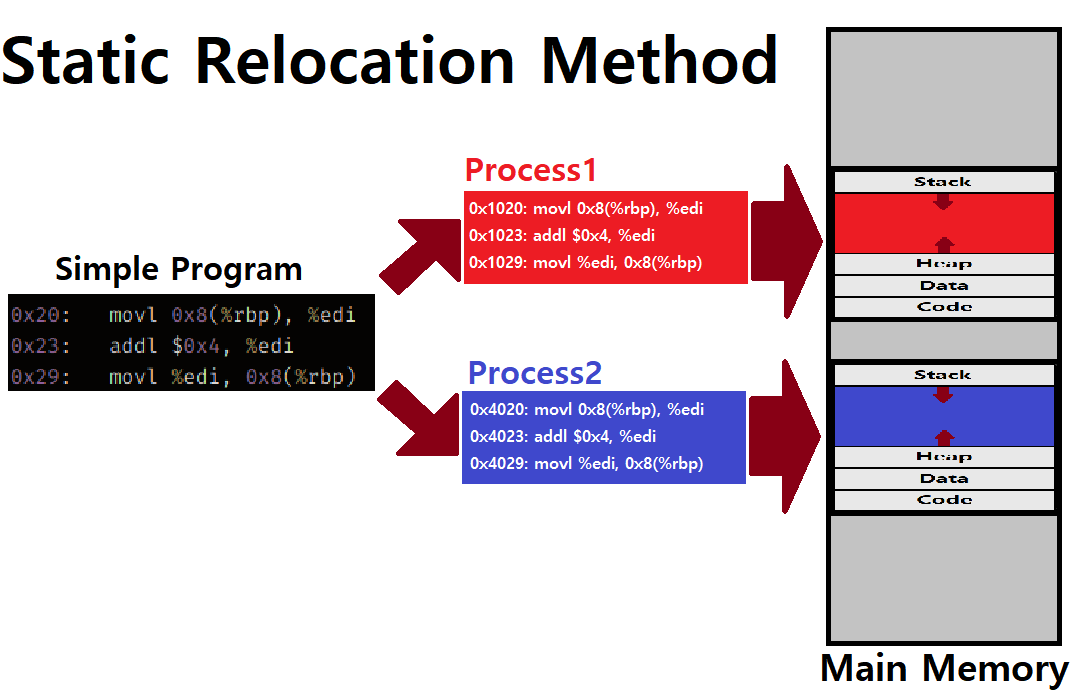
-
당연히, 명확한 단점이 있다.
-
Process Virtual Address Space 간에 Protection이 존재하지 않는다.
- Process가 다른 Process, 또는 OS로 침범하는 행위가 방지되지 못한다.
-
또한, Process의 VAS가 Main Memory에 지정되고 나서는, 다른 위치로 이동할 수 없다.
- 그래서 'Static'이라 부르는 것!
-
Dynamic Relocation
Dynamic Relocation : Virtual Address를 항상 '특정 번지로부터 얼마만큼'으로 보자!
MMU's aid
-
Dynamic Relocation
- MMU(Memory Management Unit) HW의 도움이 필요한 방식이다.
-
MMU는 BASE Register와 BOUNDS Register를 통해 Process 간의 Protection을 제공한다.
- BASE Register : Starting Location in Physical Memory ★★
- BOUNDS Register : Process Virtual Address Space의 Size ★★
- 주소 초과 에러를 감지하는데 쓰인다. (Segfault Detection)
~> MMU는 Logical Address를 Physical Address로 변환하는데, MMU에 Logical Address가 들어오면, MMU는 그것을 BASE Register Value, BOUNDS Register Value를 이용해 Physical Address로 바꾸는 것이다. ★
-
이러한 MMU에는 Mode Bit도 존재한다. Mode Bit는 알다시피 Dual Mode Operations 개념에서의 두 Mode 지정을 가능케하는 Bit이다.
-
Privileged(Protected/Kernel) Mode : OS가 수행될 때의 Mode
- System Call과 같은 Trap이나 여타 다른 Exception들로 인해 CPU Control이 Process에서 OS로 넘어가면, User Mode에서 Kernel Mode로 전환되고, OS가 일을 수행한다. ★
- MMU 입장에선, 이러한 Kernel Mode일 때, OS가 모든 Physical Memory를 접근할 수 있게 해준다. ★
-
User Mode : User Process가 수행될 때의 Mode
- MMU 입장에선, 이러한 User Mode일 때, User Process가 전달하는 Logical Address를 Physical Address로 변환한다.
- with BASE & BOUNDS Registers
- MMU 입장에선, 이러한 User Mode일 때, User Process가 전달하는 Logical Address를 Physical Address로 변환한다.
-
Address Translation
이제부터 Dynamic Relocation 상황에서 MMU가 어떻게 Logical Address를 Physical Address로 변환하는지 그 원리에 대해 알아보자. 이를 통칭 'Address Translation'이라 한다.
-
User Process의 '모든 Memory Access'에 대해 Address Translation이 수행된다.
- User Process가 보는 Address는 모두 Logical Address이므로.
-
Address Translation
-
1) MMU는 넘겨받은 Logical Address를 BOUNDS Register Value와 비교한다. ★
- 범위를 넘어서는 접근인지부터 체크하는 것!
- 따라서, Logical Address가 BOUNDS보다 '이상'이면 Error를 발생시켜 OS가 Process를 죽이도록 만든다. (Fault Error occurs!)
- 범위를 넘어서는 접근인지부터 체크하는 것!
-
2) MMU는 1)에서 Validation한 Logical Address에 대해, BASE Register Value를 더해 Physical Address를 뽑아낸다. ★
-
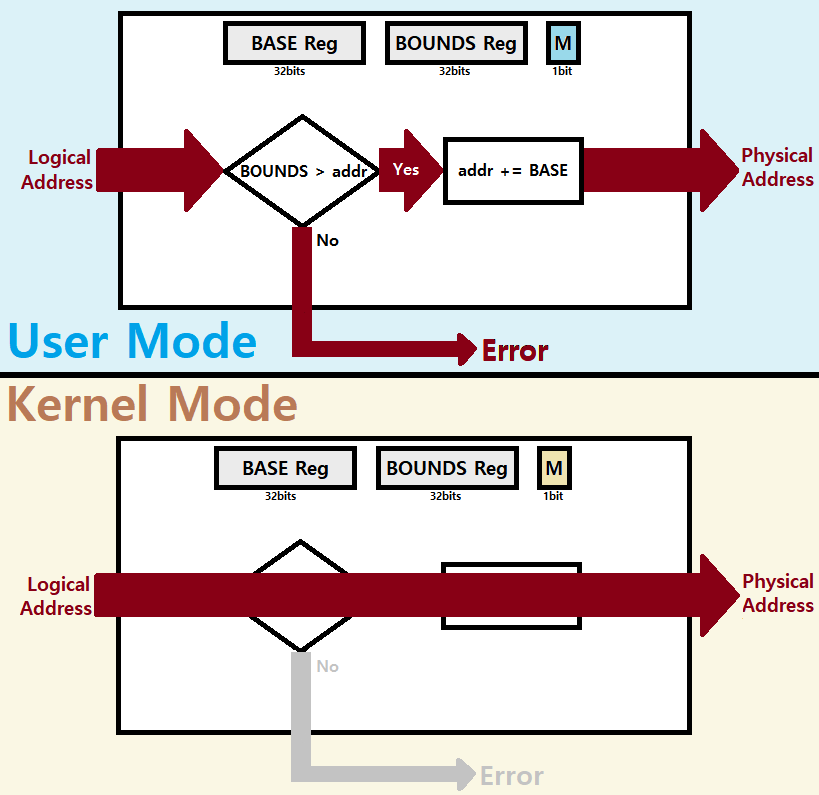
-
Kernel Mode에선 사실상 MMU가 아무런 역할을 하지 않는다는 것을 알 수 있다. (오로지 Mode Bit Check만 수행한다. ★)
-
BASE와 BOUNDS Register는 모두 32Bits = 1Byte 크기이고, Mode Bit는 1Bit이다.
-
이러한 Dynamic Relocation을 실제로 구현하기 위해선 BASE Register Value와 BOUNDS Register Value를 각 Process마다 기억하는 루틴이 필요하다. ★
-
Process의 PCB에 넣어서 기억할 수 있다. ★★★
-
Process Context Switch가 일어나면,
- Context Switch를 위해 Mode가 Privileged Mode로 바뀌고, OS의 Handler가 동작한다.
- Old Process의 BASE와 BOUNDS 값을 기억한다.
- New Process의 BASE와 BOUNDS 값을 로드한다.
- Switch를 마친 후 Mode가 User Mode로 바뀌고, New Process가 수행된다.
-
이때, User Process는 자신의 BASE와 BOUNDS Register Value를 바꿀 수 없어야한다. ★
-
ex) 만약, ProcessP1이 있고, P1의 BASE와 BOUNDS 값이 1024라 하자. Sequence of Instructions가 아래와 같다면, 무슨 일이 일어날까?
P1: load 123, R1
P1: load 124, R1
P1: load 1023, R1
P1: load 512, R1
P1: load 2000, R1 -> Segmentation Fault!!!
~> 2000이라는 Address는 BOUNDS 값 이상이기 때문에 Error를 맞이하고 있음을 알 수 있다.
~~> 따라서, ProcessP1은 OS에 의해 Kill될 것이다.
Q) Dynamic Relocation에서 특정 Process가 다른 Process를 침범할 수 있을까요?
A) 없다. 왜냐? MMU 선에서 이를 처리해주기 때문!
Dynamic Relocation provides 'Protection among processes(includes OS)!'
Free Holes
자, 이제 우리가 포스팅 초반에 했던 가정을 하나 풀어보자. 각 Process의 Address Space Size가 서로 다를 수 있다고 하자.
-
Dynamic Relocation에선 'Hole'이라는 개념이 존재한다.
-
Hole : Available(Free) Memory의 Block
-
서로 다른 Size의 여러 프로세스가 할당되고 해제되고를 반복하면, Main Memory 전반에 걸쳐서 Hole이 여러군데 존재하게 된다.
- 특정 Process를 Memory에 Load할 때, Dynamic Relocation에선 Process의 Virtual Address Space Size를 Cover할 수 있는 Hole에다가 Process를 Load한다. ★
- 이를 위해 OS에선 'Allocated Partition'과 'Freed Partition (Hole)'에 대한 정보를 유지해야한다. (Tracking needed)
- 특정 Process를 Memory에 Load할 때, Dynamic Relocation에선 Process의 Virtual Address Space Size를 Cover할 수 있는 Hole에다가 Process를 Load한다. ★
-
~> 그리고, 당연히 특정 Process를 Hole에 넣지 못하는 상황도 발생할 수 있다. (External Fragmentation)
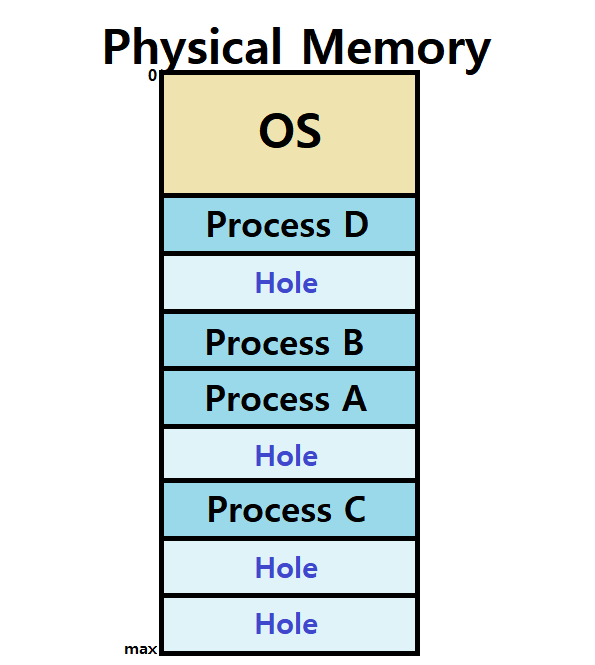
-
즉, OS에선 이러한 Free Hole들의 정보를 담고 있는 List를 운용해야한다.
-
Free Holes List에서 특정 Process Loading에 대해 적절한 Hole을 찾기 위한 방법은 무엇이 있을까?
-
Dynamic Memory Allocation 시 Free Space Search 논리와 유사하다.
-
First-Fit Approach : 처음으로 발견되는 'Cover할 수 있는 Hole'을 선택한다.
-
Best-Fit Approach : Cover할 수 있는 Hole 중 Size가 가장 작은 Hole을 선택한다.
- 당연히 List에 대한 Full Search가 필요하다. (Size별로 정렬되어 있지 않다면)
- 그리고, Load하고 남은 공간은 여타 다른 Approach들보다 더 작을 것이다.
-
Worst-Fit Approach : Largest Hole을 선택한다.
- 역시나 당연히 Full Iteration이 필요하다.
- Load하고 남은 공간은 여타 다른 Approach들보다 클 것이다.
-
~> First-Fit과 Best-Fit이 성능, 공간 효율 측면에서 가장 우수하다고 알려진다.
※ 50% Rule : 일반적으로 N개의 Allocated Block이 있으면, 그 중 절반의 Block이 Fragmentation에 의해 Lost된다. (1/3은 Unusable)
Fragmentation
Free Space Management에서도 언급했던 Fragmentation이다. 다시 한 번 짚고 넘어가보자. Dynamic Relocation에서도 중요하기 때문이다.
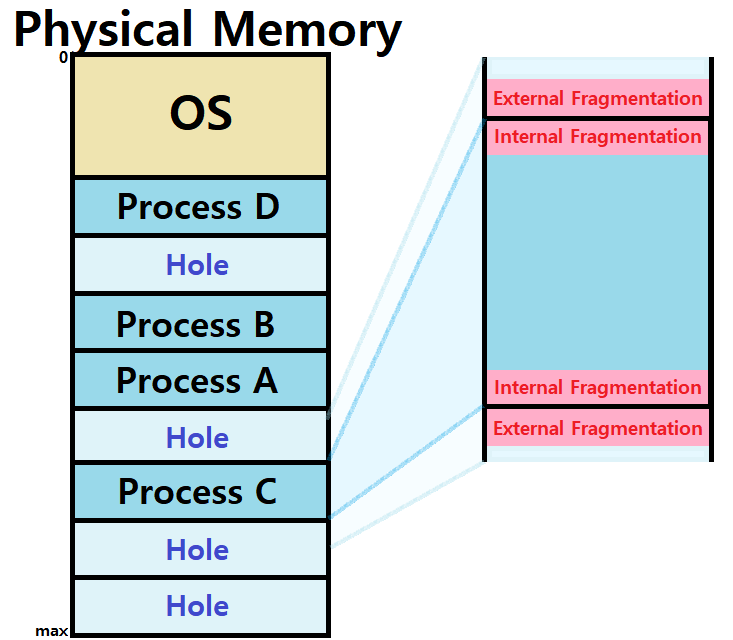
-
External Fragmentation : 전체 Memory Space는 Request를 충족할 수 있지만, 개별 Space들은 그렇지 못한 상황
- 특정 연속적인 Request를 받아들이지 못하는 문제로, Block 외부에 쓸모없는 공간이 많아지는 문제이다. ★
-
Internal Fragmentation : Request에 대해 Allocate한 Memory Space의 Size가 실제 Requested Size보다 큰 문제이다. 즉, Memory Internal이 필요한 문제이다.
- 내부에 Data 저장 외 목적의 공간이 많아지는 문제이다. ★
Dynamic Relocation에서 Hole의 존재는 곧 Great External Fragmentation을 의미한다.
-
Dynamic Relocation 시 External Fragmentation을 줄이는 방법
-
Compaction이 대표적이다.
- 마치 우리에게 친숙한 Window의 '디스크 조각 모음'처럼, 모든 Free Memory들을 한 곳으로 모아 큰 Block으로 만드는 작업이다. ★
-
Compaction을 위해선 Allocated Memory가 왔다갔다 할 수 있어야하고, 따라서 Dynamic Relocation 같은 방법론이 전제되어야 한다. (Process Loading에 적용한다고 했을 때)
- 또한, Compaction은 Execution Time에만 수행할 수 있다. 누군가 이 작업을 해야할 것 아닌가.
-
허나, Overhead가 극심할 것은 자명하다.
-
또한, I/O Operation 수행 시 사용되는 Buffer도 Compaction할 때마다 매번 옮겨야한다는 문제가 존재한다. ★
-
Latch Process : 고정된 메모리 공간에서 일을 해야하는 프로세스 (주로 I/O 때문)
- Compaction의 적용 시, 이러한 Latch Process를 어떻게 처리할 것인가? (의문)
-
물론, '고정 Buffer(OS 내부에 두는 식의)'를 사용할 수도 있겠지만, 고정 Buffer를 쓰면 Concurrency와 같은 다른 문제를 신경써야한다.
-
-
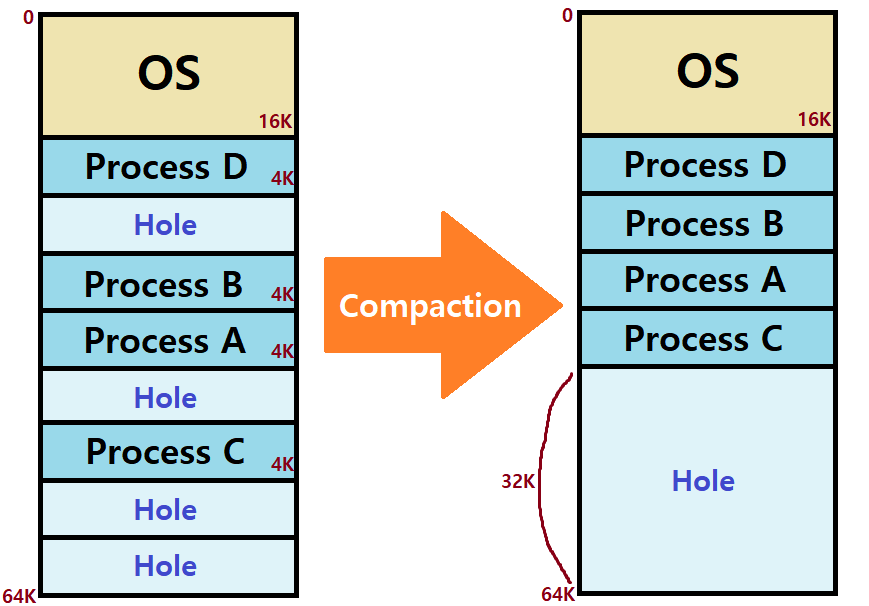
Pros and Cons
이처럼 Dynamic Relocation의 여러 성질을 알아보았다. 마지막으로 Dynamic Relocation의 장단점을 확인하자.
-
장점
-
Process Virtual Address Space 간에 Protection을 제공한다. by MMU ★
- Read/Write Operation 모두!
-
Process를 여러 위치에 둘 수 있고, 동시에 VAS를 옮길수도 있다. (Dynamic의 의미)
-
Simple하다. 구현이 어렵지 않다. MMU와 약간의 알고리즘만 있으면 된다
-
(Compaction을 하지 않을 때) 성능이 좋다. 빠르다.
-
-
단점
-
Process가 Heap이나 Stack을 활용하지 않을 수도 있는데, Dynamic Relocation에선 이와 상관없이 반드시 다 할당해야한다. ★★★
- 필요할때만 할당하는 루틴이 없으므로!
-
Virtual Address Space의 일부분을 공유하는 행위도 불가능하다. ★★
-
External Fragmentation이 극심해질 수 있다. by Holes
-
"무언가 좀 더 우수한 Method가 필요하다...!"
Segmentation
지금까지의 학습에 우리는 다음과 같은 가정을 전제한 바 있다.
"Process Virtual Address Space가 Physical Memory에 Contiguous한 형태로 올라간다. 복수의 VAS끼리를 의미하는 것이 아니라, VAS 하나 그 자체가 말이다."
~> 이러한 가정을 토대로 설계한 상기한 Methods들엔 무슨 문제가 있었나?
=> 그것은 바로 External Fragmentation이 커진다는 것이었다. Dynamic Relocation의 경우 Hole의 존재가 바로 그 이유였다.
--> Segmentation은 이에 대한 해법을 제시한다. (Segmentation 자체가 Method 이름)
Segmentation : Process Virtual Address Space는 Code, Data, Heap, Stack 등의 Segment로 나뉘는데, 이때, VAS 단위로 Contiguous하게 올리지 말고, Logical Segment 단위로 Contiguous하게 올려보자! ★
즉, MMU에 Segment마다 BASE, BOUNDS를 두는 것이다! ★
-
(한 Process의) 각 Segment는,
- Physical Memory에 각각 분리되어 올라간다. Segment마다 따로따로 존재한다.
- 각 Segment의 Size가 가변적일 수 있다.
- 나아가 Relocation도 가능!
- 각각 서로 다른 (독립적인) Protection을 가진다.
- 가령, Code Segment는 Read에 대해서 Protection하고,.. 이런식!
-
이러한 Segmentation Method는 기존에 OS가 Process Virtual Address Space를 통째로 연속 형태로 올려서 생겨나던 Hole 문제, Unused Space 문제 등을 해결할 수 있다. ★
- Unused Space란, VAS 내의 Stack과 Heap 사이에 있는 Free Space 같은 것을 의미한다.
- 이런 Unused Space를 따로 사용하지 않는 Process의 경우, 굉장히 불필요한 메모리 낭비를 하는 셈과 같다. ★★
- Unused Space란, VAS 내의 Stack과 Heap 사이에 있는 Free Space 같은 것을 의미한다.
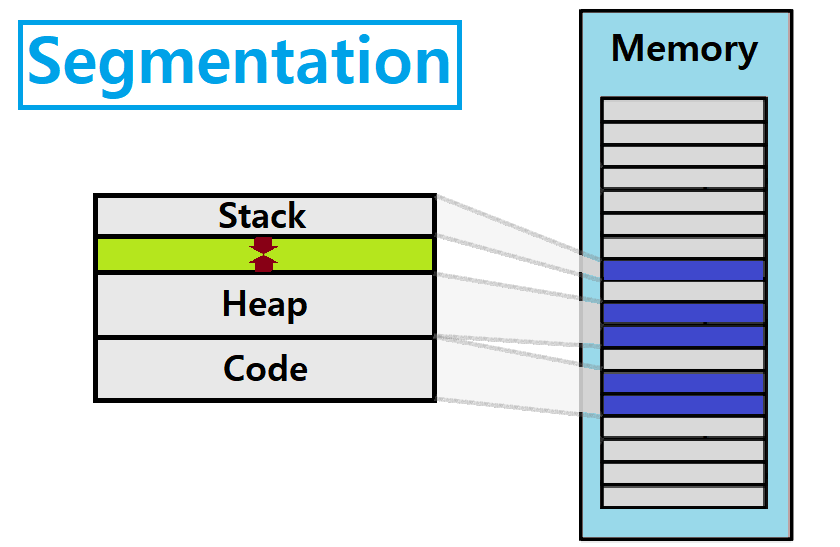
Segmented Addressing
그렇다면, 이 Segmentation 방식에선 어떻게 Address Translation을 할까. 여기서 쓰이는 방식을 Segmented Addressing이라 부르는데, 아래와 같다.
-
Logical Address가 기존에는 말 그대로 단순 Address (with No Format)였던 것에서, 특정 Format을 가지도록 한다.
-
Logical Address (in Segmentation) : Segment Number + Offset (in Segment)
-
상위의 몇 비트는 Segment Number를 가리킨다.
-
하위의 몇 비트는 Offset in Segment를 가리킨다.
-
-
그리고, MMU에 각 Process마다 Segment Table을 둔다. ★
- 각 Segment에 대해 BASE, BOUNDS Register Value, Protection Bits를 따로 둔다. ★
-
ex) 예를 들어, Logical Address가 표현할 수 있는 범위가 16K라 하자.
-
16K = 2^14
- Logical Address는 14Bits로 구성된다.
-
이때, 이 OS에선 VAS를 4 Segments로 나눈다. (Code-Data-Heap-Stack)
-
Segment Number = 4 = 2^2
- Segment Number는 2Bits로 표현한다.
-
그렇다면, 자연스럽게, 나머지 14-2 = 12Bits는 Offset을 나타낼 것이다.
- Offset = 2^12 = 4K
- 각 Segment의 Size는 4K이다.
- BOUNDS 값은 최대 0xfff일 것이다. Offset을 12비트로만 표현할 수 있으므로!
- 각 Segment의 Size는 4K이다.
- Offset = 2^12 = 4K
-
-
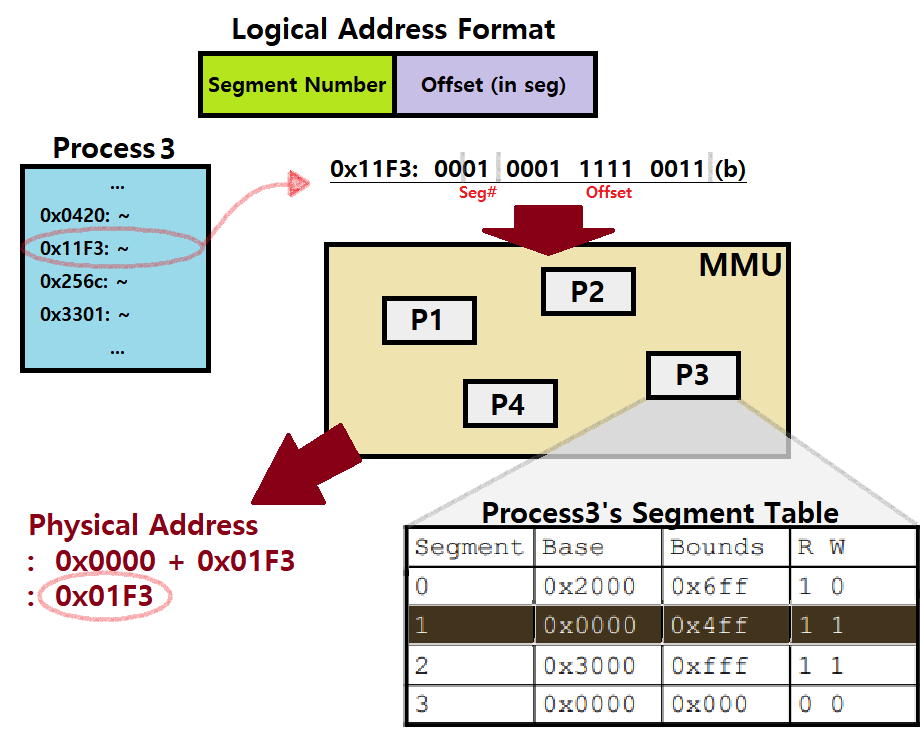
-
위 그림을 보면 Segmentation Method의 원리를 잘 이해할 수 있을 것이다.
-
이때, Segment Table에서 각 Segment의 BOUNDS가 최대 0xfff임을 주목하자.
- Offset이 12Bits로 표현되고, 이때의 최대 표현 범위는 0 ~ (4K-1)이기 때문에 위와 같이 BOUNDS가 설정되는 것이다!
-
Protection Bits도 주목하자. 각 Segment마다 Protection이 다 다르다. 즉, 독립적이다. 이것 역시 Segmentation의 큰 특징이다.
-
한편, 이러한 Setting이 MMU에서 각 Process마다 되어야 한다.
- "MMU가 상당히 복잡하겠는데..?"
-
ex) 만약, Segment가 8개이고, Segment 크기가 2K라면, Logical Address는 어떻게 표현될까?
~> ㅁㅁ ㅁ/ㅁㅁㅁ ㅁㅁㅁㅁ ㅁㅁㅁㅁ로, 위 예시처럼 14Bits로 구성될 것이다. 따라서, Process Virtual Address Space의 크기는 2^14 = 16K가 되겠다. ★
위와 같은 Segmented Addressing을 C Code로 표현하면 아래와 같다.
// SEG_MASK : 0011 0000 0000 0000 (b) = 0x3000
// SEG_SHIFT : 12
// OFFSET_MASK : 0000 1111 1111 1111 (b) = 0x0FFF
/* 14Bits Logical Address에서 상위 2Bits만을 AND로
살리고, Right Shift해서 Segment Number를 추출하자! */
seg_num = (vaddr & SEG_MASK) >> SEG_SHIFT;
/* 14Bits Logical Address에서 하위 12Bits를 추출! */
offset = vaddr & OFFSET_MASK; // Offset 추출
/* BOUNDS Error Checking */
if (offset >= BOUNDS[seg_num]) Exception(PROTECTION_FAULT);
else {
paddr = BASE[seg_num] + offset; // Physical Address 추출
register = AccessMemory(pddr); // Execution!
}~> 이런 코드를 MMU에 설치하면 되겠다!
BOUNDS's Meaning
이때, (MMU 내의) 각 Process의 Segment Table에서 BOUNDS 값은 무엇을 의미할까?
BOUNDS Value in Segment Table : The Size of each Segment
ex) 예를 들어, 특정 Segment Table에서 2번 Index Slot이 Stack Segment를 나타내고, 해당 Slot의 BOUNDS가 0x7ff라 하자.
~> Offset이 0x7ff 이상이면 Fault Error가 날 것이다.
=> 그.리.고! 0x7ff는 곧 Stack Segment의 크기를 나타낸다.
--> 0x7ff = 0111 1111 1111 (b)로, 0x0 ~ 0x7ff는 총 11Bits로 표현할 수 있다.
--> 11Bits = 2^11 = 2K
===> 즉, 이 Process에서 Stack Segment는 2K 크기를 가지는 것이다. ★★★
Pros and Cons
-
장점
-
Process Virtual Address Space에 대한 Sparse Allocation이 가능하다. ★★
- 나아가, Stack과 Heap 사이의 빈 공간을 Allocation할 필요가 없다.
-
각 Segment마다 Independent Protection을 할 수 있다. ★★
-
Segment끼리의 Sharing이 가능하다. ★★
- 기존의 방식들은 VAS가 모두 동떨어져 있어 Sharing이 불가능했다.
- 참고로, Sharing이 필요한 이유는, 추후 설명하겠지만, 가령 동일한 Library를 사용하는 Process가 1000개 있다고 하면, 이들이 각각 따로따로 해당 Library를 올리는 것은 불필요하다. 이때, 특정 Segment끼리 Sharing을 하면 공간을 아낄 수 있다. ★
- 기존의 방식들은 VAS가 모두 동떨어져 있어 Sharing이 불가능했다.
-
각 Segment의 Dynamic Relocation도 당연히 가능하다. ★★
-
-
단점
-
각 Segment는 반드시 Contiguous Form을 가져야 한다.
- 결국, Segment의 크기가 커지게 되면 기존의 External Fragmentation 문제가 다시 생길 것이다. ★★★
- 당연, I/O 시의 Buffer 문제 등으로 Compaction을 적용하기도 어려울 것이다.
- 결국, Segment의 크기가 커지게 되면 기존의 External Fragmentation 문제가 다시 생길 것이다. ★★★
-
그리고, 또 하나 꼽자면, MMU가 복잡해질 것이다.
-
"무언가.. 좀 더 좋은 방법이 필요하다..."
"이제 진짜.. Paging을 공부할 때가 다가온다..."
금일 포스팅은 여기까지이다. 다음 포스팅부터 Paging을 제대로 알아보자.
