이번 포스팅에선, Thread Programming 시 발생할 수 있는 Race, Deadlock 문제에 대해 자세히 다룰 것이다. 물론 이전에도 이들에 대해 다루었지만, 오늘 포스팅에선 좀 더 자세히 다루겠다.
Race
Simple Example Code
Race란, Program의 Correctness가 Thread의 경쟁 결과에 의존하는 현상을 의미한다.
/* Race Problem이 존재하는 Thread Program */
void *thread(void *vargp); // Thread Routine
/* Main Function */
int main(void) {
pthread_t tid[N];
int i; // N개의 Threads가 변수 i를 공유한다. 아래를 보자.
for (i = 0; i < N; i++) // Thread N개를 띄운다.
Pthread_create(&tid[i], NULL, thread, &i); // 변수 i를 공유한다.
for (i = 0; i < N; i++)
Pthread_join(tid[i], NULL); // Reaping Routine
exit(0);
}
/* Thread Routine */
void *thread(void *vargp) {
int myid = *((int *)vargp); // 변수 i가 넘어와 myid에 기록된다.
printf("안녕, 난 %d번 스레드야!\n", myid); // main Thread의 지역 변수 '자체'가
return NULL; // 넘어온 것이다. 주소값으로 받았으므로!
}- 위의 코드는 Race가 발생하는 코드이다.
- 만약, N이 2라 해보자. Main에선 Iteration을 2번 돈다.
- Peer Thread는 자신의 Iteration Index에 맞게 '자기 순서'를 출력해야한다.
- 그런데, 막상 프로그램을 돌려보면 0번 스레드보다 1번 스레드가 먼저 '안녕'을 하는 경우가 존재한다.
- Race가 발생한 것이다. (Incorrect Result) ★
- 그런데, 막상 프로그램을 돌려보면 0번 스레드보다 1번 스레드가 먼저 '안녕'을 하는 경우가 존재한다.
- Peer Thread는 자신의 Iteration Index에 맞게 '자기 순서'를 출력해야한다.
- 만약, N이 2라 해보자. Main에선 Iteration을 2번 돈다.
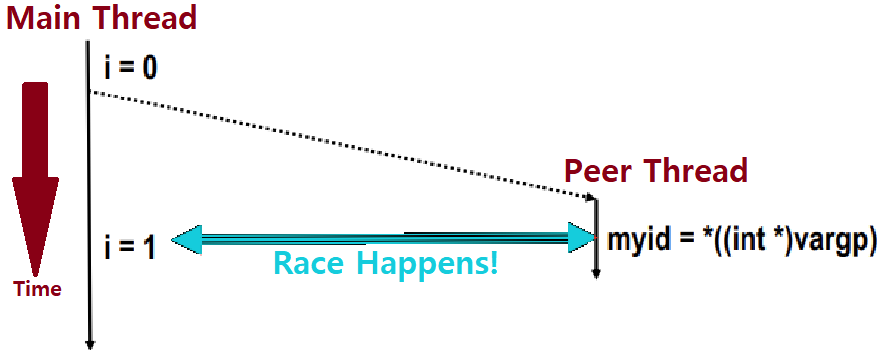
Thread Routine에서 vargp 파라미터의 Dereferencing이 Main Thread의 i변수 Increment보다 늦게 일어난 것이다!!!
i변수 값이 여전히 0일 때 Dereferencing이 일어나야만 정상인 것이다.
- 이러한 Race 현상(출력하는 순서가 중복되는 현상)을 실제로 실험해보면 신기하게도 Single Core CPU보다 오히려 Multicore Server에서 더 많이 발생한다. ★★★
- 왜냐? CPU 처리 속도가 더 빨라서 Race가 더 두드러지는 것이다.
Solution for Race
Race를 해결하기 위해선 '의도치 않은 State 공유'를 피해야한다.
/* Race Problem이 발생하지 않는 Thread Program */
void *thread(void *vargp); // Thread Routine
int main(void) {
pthread_t tid[N];
int i, *ptr;
for (i = 0; i < N; i++) {
ptr = Malloc(sizeof(int));
*ptr = i; // Heap 영역에 i값을 복사한다. ★★
Pthread_create(&tid[i], NULL, thread, ptr); // Heap 영역을 넘긴다. ★
}
for (i = 0; i < N; i++)
Pthread_join(tid[i], NULL);
exit(0);
}
/* Thread Routine */
void *thread(void *vargp) {
int myid = *((int *)vargp);
Free(vargp); // 넘겨받은 Heap 영역은 이제 해제!
printf("안녕, 난 %d번 스레드야!\n", myid);
return NULL;
}지속적으로 Increment하는 i값을 매 Iteration마다 특정 Heap 영역에 뿔뿔이 흩어지게 해서 기록해두고, 그 Heap 영역의 값(Copy본)을 Thread에게 넘기는 것이다.
즉, 각 Peer Thread는 모두 '이미 값이 확정된, 서로 다른 메모리 영역'을 이용하게 되는 것이다. ★★★
Deadlock
- 과거에 설명한 것처럼, Thread1과 Thread2가 있는데, Thread1은 A Resource를, Thread2는 B Resource를 가지고 있는 상황이다. 이때, Thread1은 B가 있어야 진행할 수 있고, Thread2는 A가 있어야 진행할 수 있는 상황이다. 서로가 서로를 기다리는 교착 상태, Hanging 상태가 발생하는 것이다.
- 이러한 현상을 Deadlock 현상이라 부른다.
- 과거에 예로 든 바 있는, Process에서 printf를 호출한 상태(Lock이 잡힘)에서 printf 수행 도중 printf를 사용하는 Signal Handler가 동작해, Signal Handler는 printf의 Lock 해제를 기다리고, Process에선 Signal Handler의 종료를 기다리는, 그러한 상황이 대표적인 Deadlock 예시이다.
- 이러한 현상을 Deadlock 현상이라 부른다.
Deadlock of Semaphore
Deadlock의 또 다른 예시 상황에는, Semaphore 상황이 있다.
"어라? Semaphore는 Synchronization을 목표로 하는데, 여기서도 Deadlock이 발생할 수 있나요?"
~> 당연하다. 당장 위에서 언급한 printf 예시도 Lock으로 인해 발생한다 하지 않았는가?
"Locking introduces the potential for Deadlock! How? Just waiting for a condition that will never be true!"
=> 이제, 아래 코드를 보자.
/* Deadlock이 발생하는 Thread Program */
void *count(void *vargp); // Thread Routine
int main(void) {
pthread_t tid[2];
Sem_init(&mutex[0], 0, 1); // mutex[0] = 1
Sem_init(&mutex[1], 0, 1); // mutex[1] = 1
// 둘 다 Binary Semaphore
Pthread_create(&tid[0], NULL, count, (void*) 0); // Thread 생성
Pthread_create(&tid[1], NULL, count, (void*) 1);
Pthread_join(tid[0], NULL);
Pthread_join(tid[1], NULL);
printf("Count is %d\n", cnt);
exit(0);
}
/* Thread Routine */
void *count(void *vargp) { // 0이 넘어왔다고 가정하자.
int id = (int) vargp;
int i;
for (i = 0; i < NITERS; i++) {
P(&mutex[id]); // mutex[0]에 대해 Lock을 잡음.
P(&mutex[1-id]); // mutex[1]에 대해 Lock을 잡음.
cnt++; // Critical Section
V(&mutex[id]); // mutex[0]의 Lock을 푼다.
V(&mutex[1-id]); // mutex[1]의 Lock을 푼다.
}
return NULL;
}
//----------------------------------------------------------------//
/* 이때, 1이 넘어온 Thread 내부에선 아래와 같이 수행된다. */
for (i = 0; i < NITERS; i++) {
P(&mutex[id]); // mutex[1]에 대해 Lock을 잡음.
P(&mutex[1-id]); // mutex[0]에 대해 Lock을 잡음.
cnt++; // Critical Section
V(&mutex[id]); // mutex[1]의 Lock을 푼다.
V(&mutex[1-id]); // mutex[0]의 Lock을 푼다.
}
//----------------------------------------------------------------//
// Thread1 Thread2
// mutex[0]에 대해 Lock을 잡음. mutex[1]에 대해 Lock을 잡음.
// mutex[1]에 대해 Lock을 잡음. mutex[0]에 대해 Lock을 잡음.
// cnt++; cnt++;
// mutex[0]에 대해 Lock을 푼다. mutex[1]에 대해 Lock을 푼다.
// mutex[1]에 대해 Lock을 푼다. mutex[0]에 대해 Lock을 푼다.
//----------------------------------------------------------------//
// ~> 위의 수행 흐름이 아래와 같이 수행되었다고 해보자. (Context Switch)
// mutex[0]에 대해 Lock을 잡음. by Thread1
// mutex[1]에 대해 Lock을 잡음. by Thread1
// mutex[1]에 대해 Lock을 잡음. by Thread2
// mutex[0]에 대해 Lock을 잡음. by Thread2
// ... (DEADLOCK!!)
// ... ~> mutex[0]과 mutex[1] 모두 Lock이 해제되질 못한다.- 위 프로그램은 Semaphore를 사용했는데, Deadlock이 발생한 프로그램이다. 아래의 Progress Graph를 보면 이해가 쉽다.
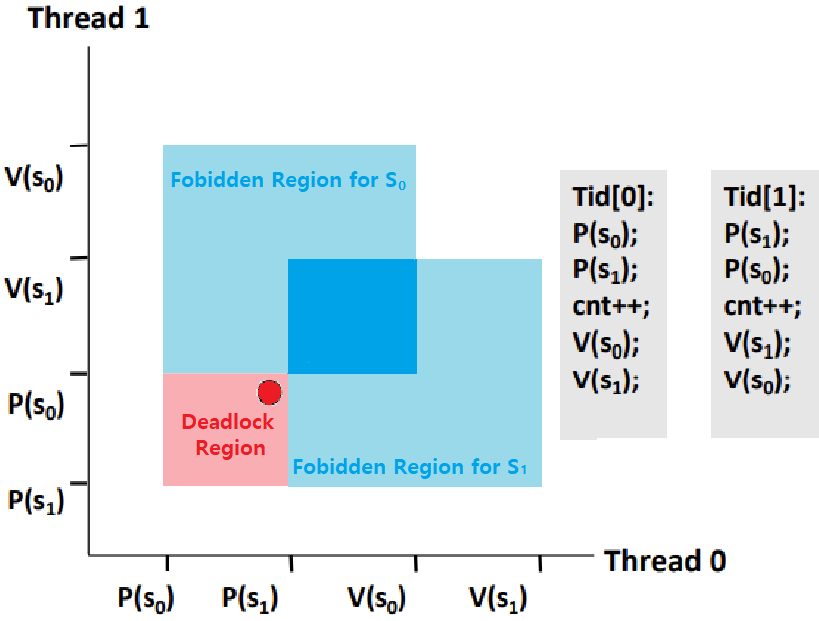
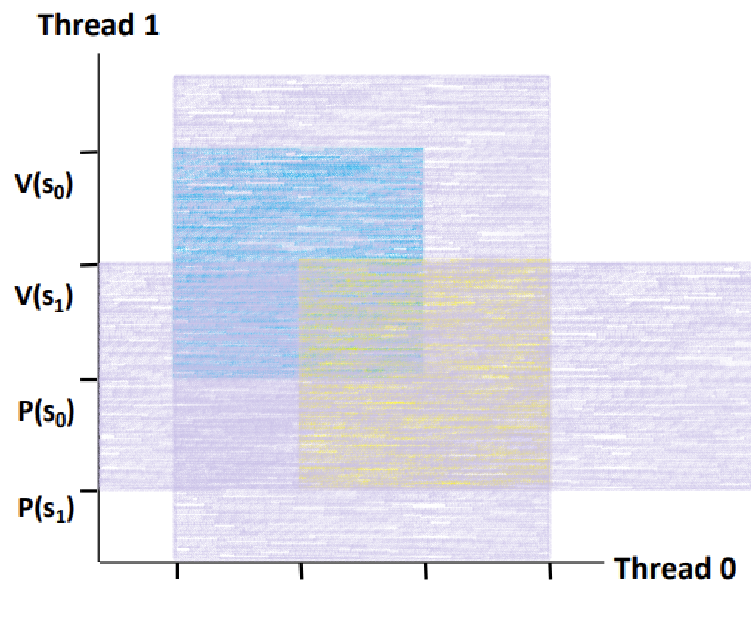
- Forbidden Region은 Binary Semaphore로 인해 Trajectory가 진입할 수 없는 구간이다.
- 두 Semaphore의 Fobidden Region이 겹치는 구간이 있다. 즉, Trajectory가 진행할 수 없는 구간이다.
-
여기가 Deadlock 구간인가? 아니다.
-
'이후에' 이 Overlapped 구간을 향해 나아갈 수 밖에 없는 'Possible' Region이 바로 Deadlock 영역인 것이다. ★★★★★
-
Overlapped Region의 최좌측 Point인 'Deadlock State'로 갈 수 밖에 없는 Region을 Deadlock Region이라 한다.
-
이 영역에 진입하면, s0과 s1이 0이 되길 무한하게 기다리는 것이다.
-
-
- 두 Semaphore의 Fobidden Region이 겹치는 구간이 있다. 즉, Trajectory가 진행할 수 없는 구간이다.
Synchronization을 위해 일부러 Lock을 적용했는데, 오히려, Lock으로 인한 Forbidden Region이 Deadlock Region을 만들어버린 것!
- 이러한 Deadlock Problem은 Nondeterministic한 Context Switch에 의해 발생하기 때문에 예측하기 어렵다.
Solution for Deadlock
이를 해결할 수 있는 방법은 무엇일까?
우선, Lock과 Unlock 순서를 기준으로 Progress Graph에서 Fobidden Region부터 알아내자.
아래 그림을 쭉 따라가보자.
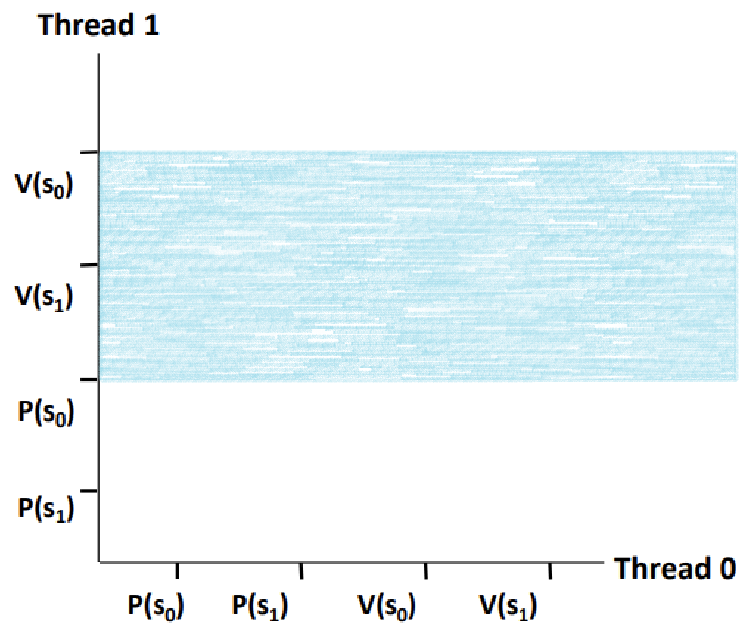
~> 한 쪽 축에서 P(s0)과 V(s0)이 둘러싸는 영역을 구한다.
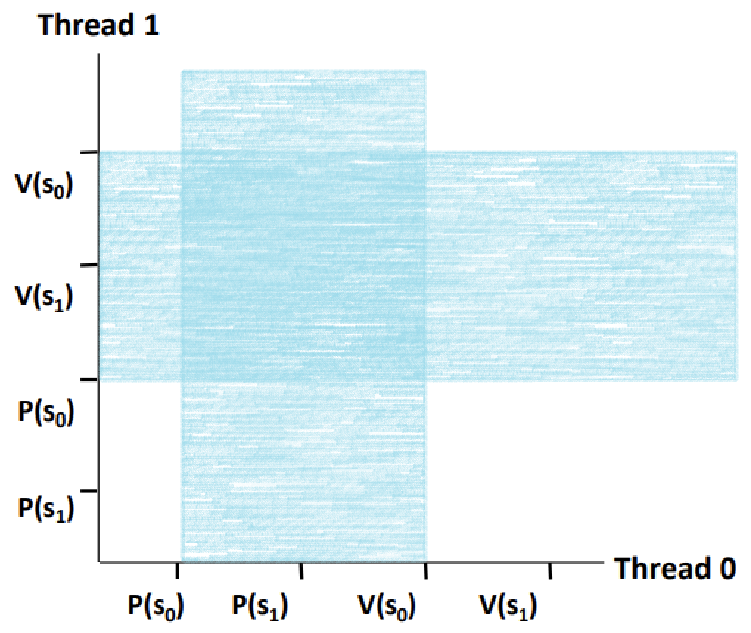
~> 반대 쪽 축에서 P(s0)과 V(s0)이 둘러싸는 영역을 구한다.
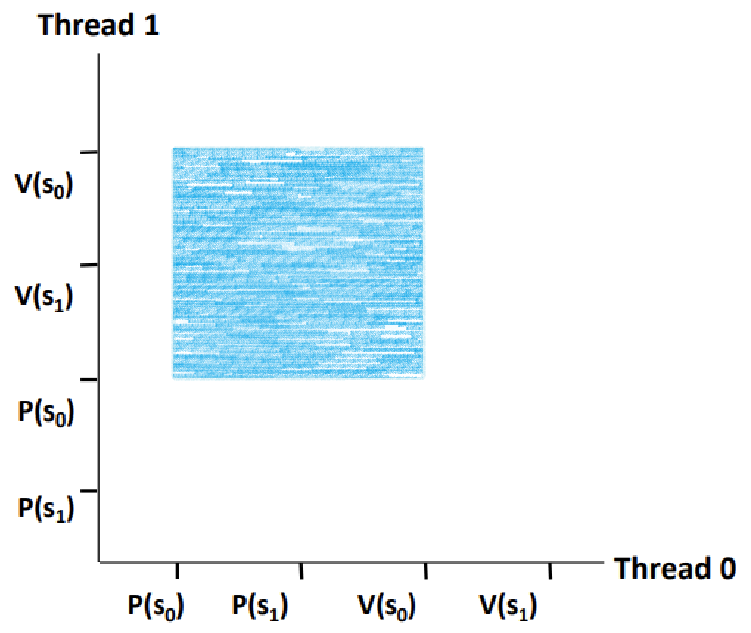
~> 그 두 영역의 교차 영역이 바로 s0의 Forbidden Region이다.
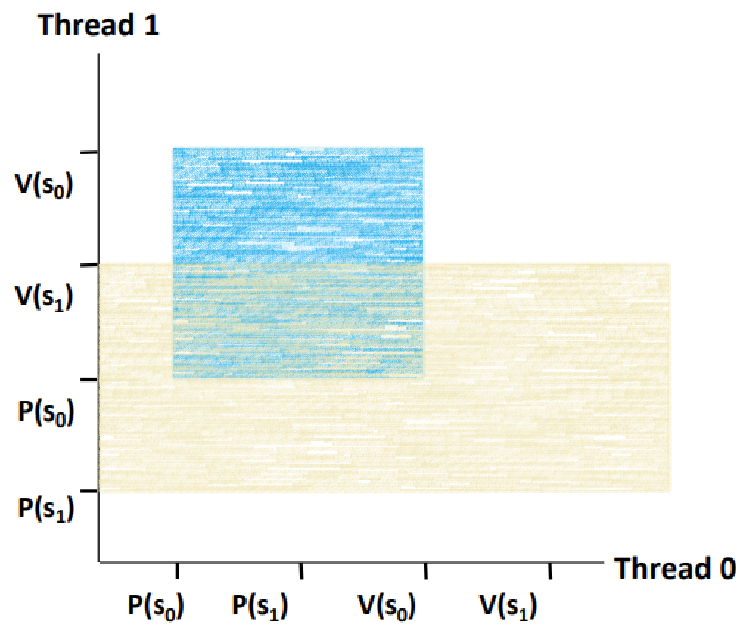
~> 한 쪽 축에서 P(s1)과 V(s1)이 둘러싸는 영역을 구한다.
~> 반대 쪽 축에서 P(s1)과 V(s1)이 둘러싸는 영역을 구한다.
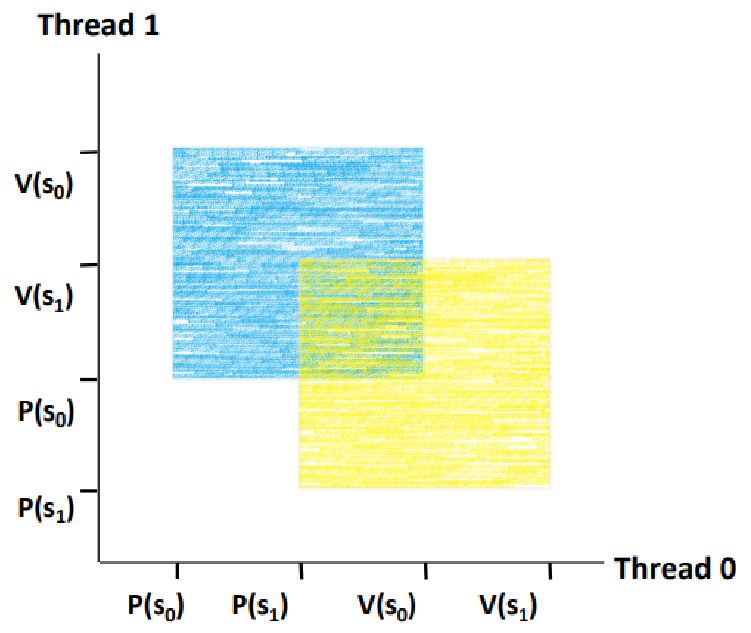
~> 그 두 영역의 교차 영역이 바로 s1의 Forbidden Region이다.
이제, 여기서, Deadlock Region을 없앨 방법을 생각해보자. Semaphore가 필요하기 때문에 Forbidden Region을 없앨 수는 없다.
그렇다면, s0과 s1의 Forbidden Region이 만드는 '전체 Forbidden Region'에, 좌측 하단 방향에서 '음푹 파인 부분'이 존재하지 않도록 해주어야 한다.
그렇다면, s0과 s1의 Forbidden Region 중 한 Region을 더 늘려서 '음푹 파인 곳'을 메워주자.
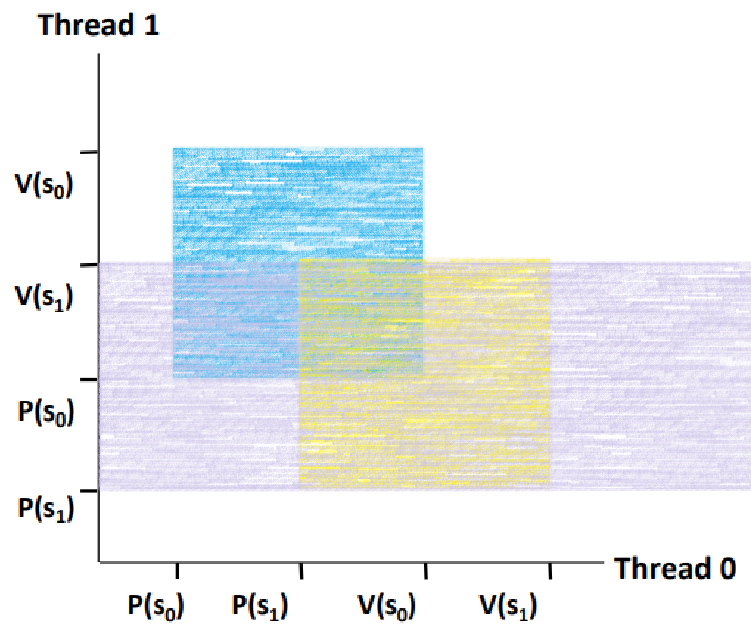
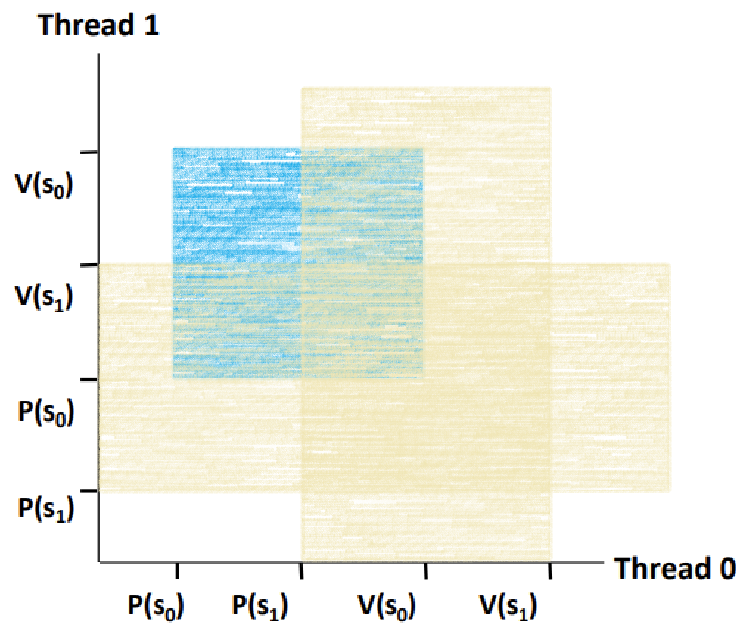
~> s1의 금지 영역을 늘려보자.
~~> 한 쪽 축에서 P(s1)과 V(s1)이 둘러싸는 영역을 구해서 기준점을 잡아주자.
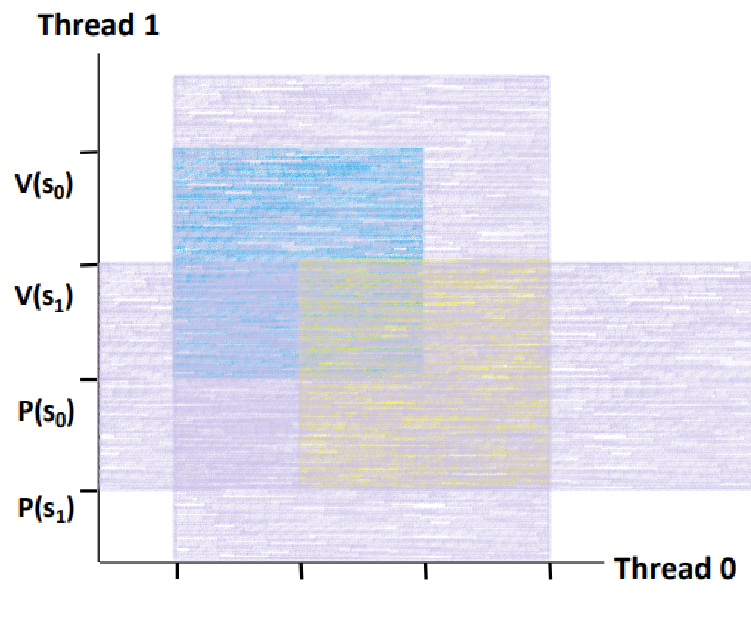
~> 반대 쪽 축에선, 기존의 명령 배치를 무시하고, 어떻게 P(s1), V(s1)의 영역을 만들어주면 음푹 패인 곳이 메워질지를 고려해 영역을 잡아준다.
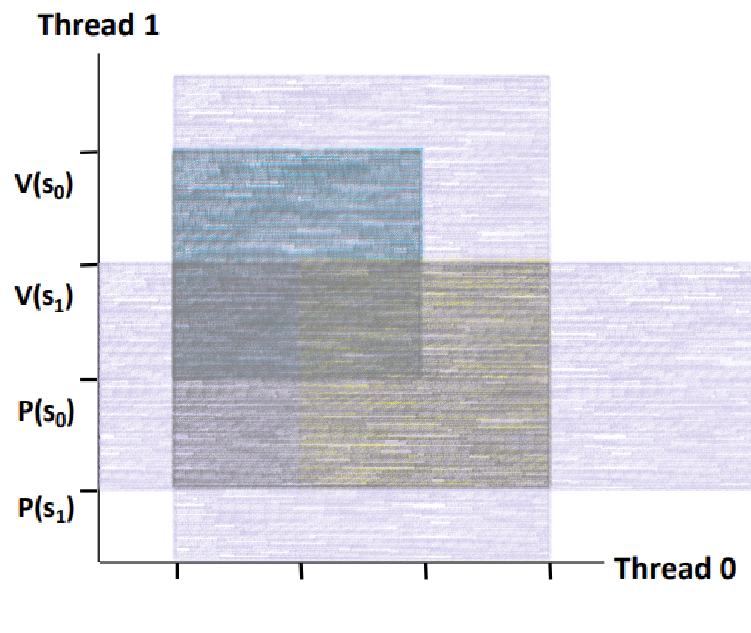
~> 그림처럼 영역을 잡아주면, 교차 영역이 위와 같이 그려진다.
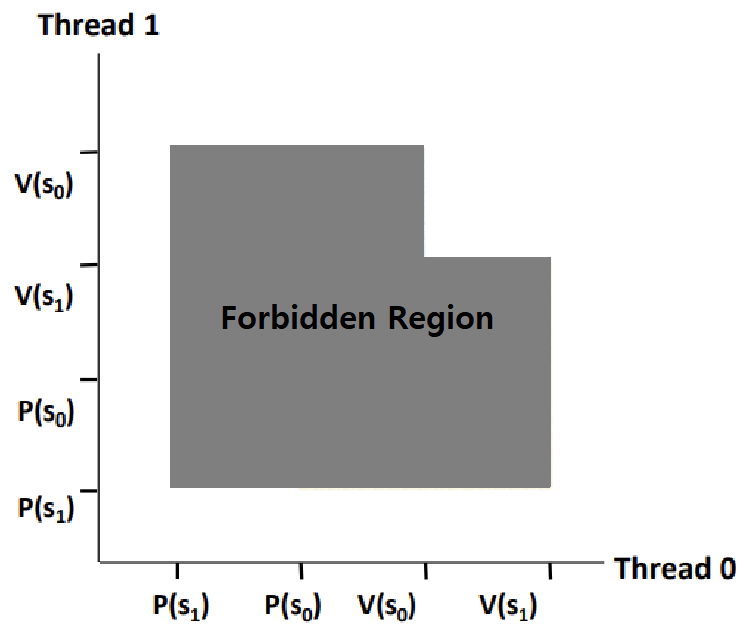
~> '전체 Forbidden Region'이 위와 같아진다. 이제 음푹 패인 곳이 없고, 그에 따라 Deadlock State가 사라지게 된다. ★★★
위와 같은 흐름으로, 명령의 가능 배치 순서를 고려해서, Progress Graph 좌표평면을 그리고, 거기서 영역 그리기 및 겹치기를 수행해 Deadlock이 발생하지 않는 명령 배치를 찾아낼 수 있다.
이를 고려하여 코드를 변형하면 아래와 같다.
/* Deadlock이 발생하지 않는 Thread Program */
void *count(void *vargp); // Thread Routine
int main(void) {
pthread_t tid[2];
Sem_init(&mutex[0], 0, 1); // mutex[0] = 1
Sem_init(&mutex[1], 0, 1); // mutex[1] = 1
// 둘 다 Binary Semaphore
Pthread_create(&tid[0], NULL, count, (void*) 0); // Thread 생성
Pthread_create(&tid[1], NULL, count, (void*) 1);
Pthread_join(tid[0], NULL);
Pthread_join(tid[1], NULL);
printf("Count is %d\n", cnt);
exit(0);
}
/* Thread Routine */
void *count(void *vargp) {
int id = (int) vargp;
int i;
for (i = 0; i < NITERS; i++) {
P(&mutex[1]); // 이곳의 Locking 순서를
P(&mutex[0]); // 고정해버린다!!! ★★★
cnt++; // Critical Section
V(&mutex[id]);
V(&mutex[1-id]);
}
return NULL;
}금일 포스팅은 여기까지이다.
