
지난 시간 우리는 Dynamic Memory Allocation의 기초 이론을 가볍게 다루어보았다.
Heap은 결국 Word 단위 Memory Addressing이 이루어지는 '연속된' 가상 메모리 공간인 것이다. Heap의 시작 주소부터, brk Pointer가 가리키는 Top of Heap까지가 Heap의 Size이다.
~> 즉, Top of Heap에서 Heap의 시작 주소 값을 뺀 수치에 Word Size를 곱하면, 그것이 Heap Size가 된다. ★
~> 참고로, Block은 Word(Chunk)의 집합임을 잊지 말자. ★
Explicit Memory Allocator에는 malloc과 free가 있다고 했다. Java의 Garbage Collector와 같은 Implicit 개념은 지금은 다루지 않는다고 했다.
한편, Throughtput과 Peak Memory Utilization과 같은 성능 평가 지표에 대해서도 알아보았다. 이들이 Tradeoff 관계에 있음을 기억하자.
또한, malloc을 구현하기 위해 고민해봐야하는 다양한 Issue들에 대해서도 간단히 알아보았다. 이번 포스팅에선, 본격적으로 'Dynamic Memory Allocator를 어떻게 구현하는가'에 대해서 알아보겠다. Implementation Detail에 대해 말이다.
Implementation Issue
Dynamic Memory Allocator를 만들기 위한 '구현 측면의 Issue'들에 대해 알아보자.
-
free(ptr); 명령에서, 우리는 이 ptr이 가리키는 공간의 크기를 어떻게 알 수 있을까?
-
Heap은 Allocated와 Freed Block의 Sequence이다. 각 Block이 Random하게 배치되는데, 우리는 여기서 Free Block들을 어떻게 추적할 수 있을까?
-
새롭게 메모리 블록을 할당하고자 한다. Heap 전체로 보았을 땐 공간이 충분한데, 단일 Free Block들만 보았을 땐 Fit한 공간이 없을 때, 우리는 이를 어떻게 처리해야 할까?
-
새롭게 메모리 블록을 할당하고자 할 때, 여러 Fit한 Free State Block들 중 우리는 어떤 Block을 택해야할까?
-
메모리 블록을 Free할 때, Allocated Block을 Freed로 어떻게 바꿀 것인가?
이제부터 이들에 대한 해답을 찾아가자!
How much to Free?
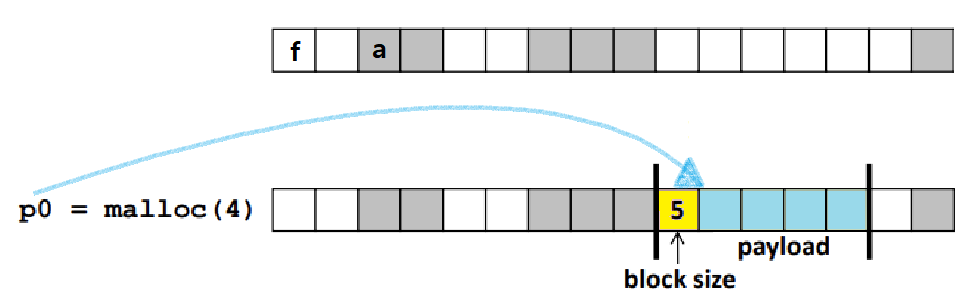
free 함수 호출 시, 얼마만큼의 사이즈를 Free해야할지를 알아내는 가장 Naive한 방법은 각 Block의 맨 앞에 Header Field를 두는 것이다.
- Header Field, 줄여서 Header라고 부르는 1Word를 각 Block 앞에 붙이고, 거기에 Block의 Length를 기록한다. ★
- 모든 Allocated Block에 대해 Extra Word를 필요로 한다. ★
- 그렇다, Internal Fragmentation이 늘어난다. ★
- 모든 Allocated Block에 대해 Extra Word를 필요로 한다. ★
-
위의 그림을 보자.
-
4 Words Size 공간을 요청하는 malloc 순간이다. 앞의 두 Free Block은 둘 다 크기가 2이므로 이를 커버하지 못한다. 세 번째 Free Block이 커버할 수 있으므로 이를 택한다.
-
이 블록은 5 Words로 구성되어 있다.
-
이 중 맨 앞 Word에 '새로 할당할 공간의 크기에 Header를 더한 크기'인 5를 적어준다. ★
-
이 Block Size를 통해 우리는 Free시에 얼만큼을 Deallocate할지 알 수 있다.
-
How to keep track of Frees?
Free Block들을 추적하는 방법에 대해서도 알아보자. 위와 같이 Allocation을 수행하려면, Fit한 Free Block을 찾아야하고, 그러기 위해선 Free Block들을 추적해야한다.
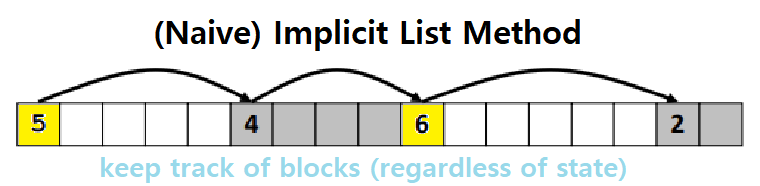
Implicit List Method
Block Size 정보를 가지고 Tracking하는 방법이다.
-
위 그림을 보자. 크기가 5 Words인 Free Block, 4 Words인 Allocated Block, 6 Words인 Free Block, 2 Words인 Allocated Block이 순차적으로 있는 상황이다.
-
그림에서처럼, 맨 처음 블록의 크기부터 읽어나가고, 그 읽은 값만큼 Pointer Arithmetic(Add)하면, 다음 Block을 알 수 있다. 이를 반복하면서 순차적으로 Block들을 조회하는 것이다.
- 실제 Block 내의 Data는 알 수 없지만, 각 Block들을 Traverse할 수 있다.
-
하지만, 이 Naive한 Implicit List는 Allocated Block도 함께 Tracking하기 때문에 Best한 방법은 아니다.
- 좀 더 개선의 여지가 있다... (후술)
Explicit List Method
이 친구는 'Block Size Word(Header)' 다음에 'Next Free Block의 Index'를 기록하는 Word를 추가하는 방식이다.

-
장점 : 모든 Block을 Traverse해야하는 Overhead가 없다.
-
단점 : Extra Word가 하나 더 필요하다. 즉, 공간 효율이 좋지 못하다.
- Internal Fragmentation이 굉장히 커진다.
-
이 역시 추후 자세히 설명한다.
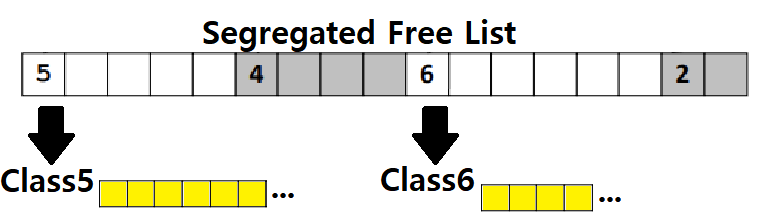
Segregated Free List Method
'Segregation'이란 단어의 뜻을 아는가? 과거 20세기에 시행됐던 인종차별 정책의 이름에 들어갔던 단어로, '분리'의 뉘앙스를 가지고 있다. 여기에서 착안해, 다음과 같은 Idea가 제기된 것이다.
"Free Block들마다 크기가 다 다른데, 이 'Different Size'를 Class화하여 'Different Free Lists'를 두는 것 어떤가?"
'Segregated Free List' 방법은 위와 같은 생각에서 시작한 방법으로, 사이즈가 다른 Free Block들을 Size별로 묶어서 Free Block을 추적하는 방법이다. 약간 Dynamic Scoping Rule Language에서 사용하는 Shallow Access 방법과 유사한 논리이다.
이밖에도, 'Blocks sorted by Size Method'라고, Balanced Tree로 Free Block을 관리하는 방식이 존재한다. Block Size를 기준으로 Tree를 이용해 Block들을 정렬하고, Size(Length)를 Key로 사용하여 서칭하는 방식이다.
Implicit List Method
Incredible Discover
상기한 Implicit List를 구현하기 위해 우리는 각 Block에 대한 Size와 Allocation State 정보를 가지고 있어야 한다.
"이 두 정보를 각각 하나의 Word에 넣어, 총 두 개의 Word를 덧붙이는 것은 공간 효율 측면에서 너무 Wasteful하다!"
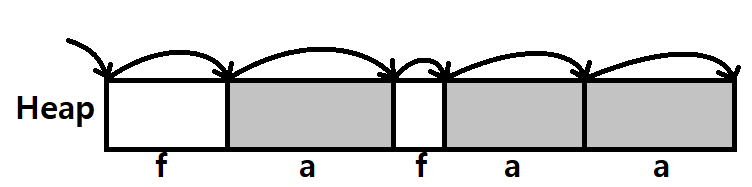
아래 그림과 같은 Heap이 있다고 해보자.
-
Traverse를 위해선, 각 Block들의 크기만큼 Pointer Arithmetic Addition이 수행되어야 한다.
- 각 Block의 맨 앞 Header에는 Block Size가 있다고 했다.
-
이때, 'Size Word(Header)' 우측에 'Status Word'도 둔다고 해보자. Status란, Allocation State를 나타내는 Word이다.
- 한 Word Size가 8Bytes라고 가정하면, 무려 16Bytes나 Extra Space로 필요한 것이다.
"두 Word말고, 한 Word 내에 두 정보를 모두 저장할 순 없을까?"
-
만약 64 Bit CPU System이라 하면, 8바이트 단위 Addressing을 해야한다.
- 0번지부터 시작한다고 하면, 0, 8, 16, 24, 32, ..., 이렇게 간다.
- 이를 Binary로 표현하면,
- 000...000000 (0)
- 000...001000 (8)
- 000...010000 (16)
- 000...011000 (24) ... 이다.
- 이를 Binary로 표현하면,
8Bytes Word Alignment에서, Block의 주소값의 LSB 방향 3개 비트는 반드시 0이다.
- 0번지부터 시작한다고 하면, 0, 8, 16, 24, 32, ..., 이렇게 간다.
"실로 대단한 발견이 아닐 수 없다! LSB 쪽 3개 비트가 반드시 0이면, 이 3개의 비트 중 하나의 비트를 'Allocated or Freed'를 나타내는 Flag로 사용할 수 있다!" ★★★

- 이 논리를 통해 다음과 같이 Block for 'Implicit List Method'를 구성할 수 있다.
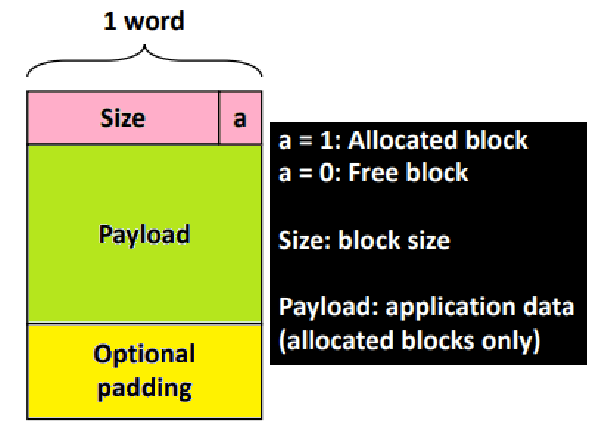
ex) malloc(5Bytes)라 하면, 1Byte는 Size&Status Info, 5Bytes는 Payload, 2Bytes는 Padding인 것이다. (8Bytes Word) ★★★
Simple Example
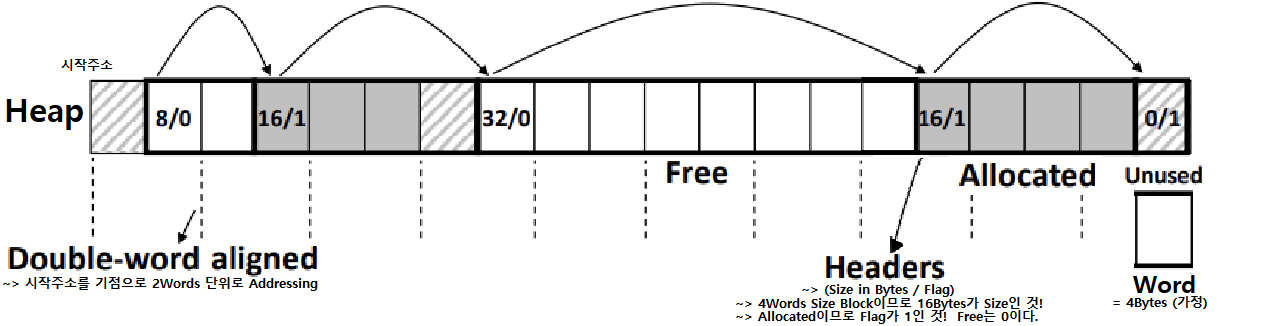
-
맨 앞 Header가 1Word를 점유하면서 BlockSize와 Flag 정보를 함께 담고 있음에 주목하라.
-
Padding을 위한 Words도 존재함에 주목하라.
-
Alignment가 '첫 번째 Block의 Payload'를 기준으로 시작하고 있음에 주목하라. 이를 위해 앞에 Unused Word가 하나 붙어있음에 주목하라. ★★
- 만약, 4 Words Alignment였으면 3개의 Unused Words가 Heap 맨 앞에 붙을 것! ★★★
How to find 'Fit' Free Block?
Allocation을 수행할 때, 여러 Free Block 중 어떤 친구를 선택할 것이냐의 문제이다.
- First Fit 방식 : Implicit List를 처음부터 쭉 순회하여 찾는 Naive한 방식이다.
- 첫 번째로 Fit한 Block을 택한다.
/* First Fit Method (When Word is 4Bytes) */
p = start;
while ((p < end) && // Implicit List의 각 블록을 순회
((*p & 1) || // LSB Check : Allocated Block은 Pass!
(*p <= len))) { // Block Header Value가 Fit하지 않으면 Pass!
p = p + (*p & -2); // Next Block으로 이동 (Alignment 지키면서)
}-
p = start의 이해 : First Fit이므로 항상 맨 처음 Block부터 확인한다!
-
(*p <= len)의 이해
- *p이 000...01000이라 해보자. Flag가 0이므로 Free Block이다.
- Size 정보가 8Bytes이므로, 길이가 2이다.
- len은 malloc(len)의 len이다. len Words만큼 할당하고자 하는 것이다. ★★
- 만약, 크기가 3Words인 블록을 요청했다면, 단순히 '2 <= 3' 비교를 하는 것!
- len은 malloc(len)의 len이다. len Words만큼 할당하고자 하는 것이다. ★★
-
p + (*p & -2)의 이해
- -2는 Binary로 000...00010의 2's Complement로, 111...11110이다.
- 즉, Flag를 제외하고 사이즈를 Get하는 과정인 것이다. ★★★
- 왜냐? Allocated Block의 경우, LSB를 0으로 만들어주지 않으면 Addressing이 잘 못 이뤄지기 때문!
-
Next Fit 방식 : Implicit List를 First Fit처럼 순회하되, '이전에 Searching이 완료되었던 블록'부터 Searching을 시작하는 방식이다.
-
Unhelpful Block을 Re-Scanning하는 과정이 생략되므로 일반적으로는 First Fit보다 수행 속도가 빠르다고 알려진다. ★
-
하지만, Fragmentation 측면에서 좋지 않다는 연구 결과가 있다.
-
그리고, 당연히 Fit Free Block이 중간 중간 발견되는 형태로 Request Sequence가 구성되면 이 Next Fit 방식은 좋을리가 없다.
-

-
Best Fit 방식 : Implicit List를 처음부터 끝까지 순회하여 가장 'Best Fit'한 Free Block을 찾는다.
-
할당하고자 하는 크기를 가장 Fewest Bytes로 커버하는 Free Block을 찾는다!
-
Fragmentation을 줄이는 효과가 있다(꾸깃 꾸깃 공간을 아껴가며 할당할 수 있으므로). ★
- Peak Memory Utilization을 향상시키는 효과가 있다. ★★★
-
하지만, 매번 Allocation할 때마다 List 전체를 순회해야하므로 속도가 First Fit보다도 느리다.
- Tradeoff between Thoughput and Peak Memory Utilization의 대표 예시! ★
-
How to allocate in Free Block?
Free Block을 찾고 나면 Allocation을 수행해야한다. 그런데, Allocation이 단순히 Flag 바꾼다고 될 일일까? 조금만 생각해보면 그렇지 않다는 것을 알 수 있다. 아래의 그림을 보자.
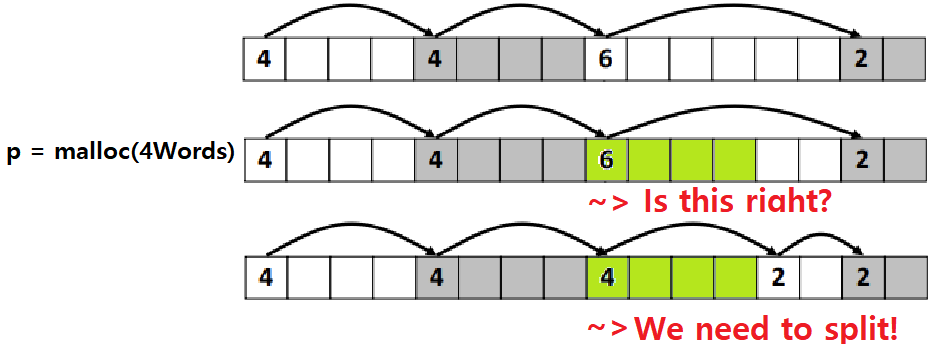
"그렇다. Free Block이 Allocation Size에 완벽하게 Fit한게 아닌 이상, 여유분이 남을 것이고, 그 여유분은 Free Block으로서 존재하고, 취급되어야하기 때문에 Splitting이 필요하다"
이를 수행하기 위해 다음과 같은 코드를 작성할 수 있다.
/* Implicit List Method - How to allocate in Free Block? */
/* We need to split!! (if needed) */
void addblock(ptr p, int len) { // p라는 블록에 len만큼을 새로 할당
int newsize = ((len + 1) >> 1) << 1; // 할당하고자 하는 크기를 짝수로 만든다
int oldsize = *p & -2; // 선택된 Free Block의 LSB를 0으로!
*p = newsize | 1; // Header의 Size&Status 정보를 수정!
// newsize와 Allocated State로!!!
if (newsize < oldsize) // 만약 여유분이 있다면?
*(p+newsize) = oldsize - newsize; // 여유분의 첫 Word를 New Header로!
} // Size만 명시하면 된다. Alignment에 의해 LSB가 자동 0이 되므로-
((len + 1) >> 1) << 1의 이해
- len이 5라고 해보자(5Words를 할당하고자 하는 상황)
- len + 1은 6이다.
- 6 >> 1은 3이다.
- 3 << 1은 6이다.
이 행위를 왜 하는거지?
앞서, Implicit List를 구현하기 위해선, 첫 번째 Block의 Payload 시작 주소부터 다루기 위해 첫 번째 Block 앞에 Unused Words를 넣어주어야 한다고 했다.
현재, Double-Word Alignment를 가정하고 있고, 여기 코드에서 len과 size는 모두 Words의 개수를 의미한다.
즉, len이 홀수일 때 짝수로 변형하는 이유는, 2Words Alignment에 맞추기 위함이다. ★★★★★
-
따라서, 새로운 사이즈를 2의 배수로 맞춰주는 것이다. 홀수이면 1을 더해주는 것이라 보면 된다. ★★★
-
그렇다. 따라서, 만약 4Words Alignment이면 ((len + 3) >> 2) << 2여야 할 것이다.
-
*p & -2의 이해 : 선택된 Free Block의 Pure한 Size 정보를 얻기 위해서이다.
-
*p = newsize | 1의 이해 : 새로운 Size(Even화된)에 Flag를 Set해주기 위함이다.
-
*(p + newsize) = oldsize - newsize의 이해 : p가 가리키는 주소값에 newsize만큼을 Pointer Arithmetic하면, 여유분 Free Block의 시작 위치를 알 수 있다. 그곳에 oldsize-newsize를 넣어주는 것이다. newsize가 2배로 맞춰져있으므로 Padding은 알아서 빼놓고 계산할 것이다. ★★
How to free Allocated Block?
이 역시 처음엔 의문이 들 것이다. Flag만 0으로 바꿔주면 되는 것 아닌가요? 하지만, 아래 그림을 보면 그리 단순한 문제가 아님을 금새 알 수 있을 것이다.
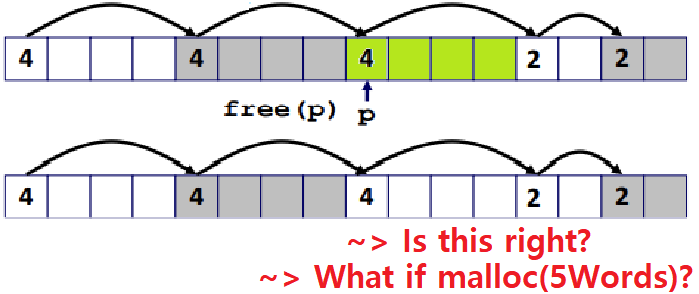
- 단순히 Flag만 바꾸면, 새롭게 Free된 공간 앞 뒤로 붙어있을 수 있는 Another Free Block과 합쳐지지 않게 된다.
- 이를 그냥 냅두면, 위의 예시 상황처럼, 공간은 충분한데 할당은 하지 못하는 웃기는 상황이 발생할 수 있다. (External Fragmentation이 올라간다)
- 이를 'False Fragmentation'이라 한다. ★★★
- 이를 그냥 냅두면, 위의 예시 상황처럼, 공간은 충분한데 할당은 하지 못하는 웃기는 상황이 발생할 수 있다. (External Fragmentation이 올라간다)
이를 해결하기 위해 아래와 같은 기법이 도입된다.
- Coalescing(합체) : 새롭게 Free된 Block의 Previous와 Next Block을 확인해, 이들이 Free Block일 경우, 하나의 Free Block을 합체해주어야 한다.
아래의 코드는 뒤의 Block만 처리하는 Coalescing Free 함수이다.
/* Implicit List - How to free Allocated Block? */
void free_block(ptr p) { // 해제하고자 하는 Block을 가리키는 Pointer
*p = *p & -2; // 우선 Flag부터 Unset한다. (Free로)
next = p + *p; // 다음 Block의 위치를 계산해놓는다.
// p에다 *p를 Pointer Arithmetic Addition!
if ((*next & 1) == 0) // 만약 다음 Block이 Free Block이면?
*p = *p + *next; // p 주소의 Value에 다음 블록 크기까지 합쳐준다.
}금일 포스팅은 여기까지이다. 다음 포스팅에선 Coalescing부터 이어서 진행한다.
