
현재 우리는 Process에서 Heap Segment를 어떻게 할당하고 관리하는지 알아보고 있다. Heap은 Top of Heap, 즉, brk Pointer가 가리키는 위치에 따라 크기가 좌우된다. brk Pointer는 sbrk 호출을 통해 조절되며, sbrk 호출은 malloc 내에서 자동으로 수행된다.
brk Pointer는 처음에 Static하게 설정된다. malloc이 처음 정해진 공간 내에서 더 이상 할당이 불가능할 경우, 그때 sbrk라는 System Call을 통해 brk Pointer의 위치를 조정해서 공간을 늘린다고 했다.
Q) 처음부터 Heap 크기를 매우 크게 잡으면 되지 않을까요?
A) 그렇지 않다. 대부분의 Application은 Heap 공간을 극도로 많이 사용하진 않을 확률이 높다. 굳이 불필요하게 처음부터 큰 공간을 부여하면 좋을 것이 없다. 최초엔 적당한 크기를 부여하고, 그 공간 내에서 빈 공간을 최대한 효율적으로 관리하고, 그렇게 했는대도 초과할 경우, 그러한 경우에만 크기를 늘리는 것이 더 합리적이다.
Dynamic Memory Allocation을 배우는 가장 큰 이유가 무엇이라 했는가? 그렇다. "어떻게 하면 빈 공간을 효율적으로 관리할 것인가"에 대한 통찰을 얻을 수 있기 때문이라 했다. 정해진 크기 내에서 빈 공간을 최대한 효율적으로 관리해야 하는 것이다. 우리가 애용하는 malloc은 오랜 시간 수많은 고급 개발자가 다양한 시행착오를 겪으면서 개발한, 아주 효율적인 Allocator이다. 우리는 그들의 '고민 과정'을 배우는 것이다.
우리는 그러한 학습의 일환으로, Implicit Free List 개념에 대해 배우고 있다. 알다시피 Heap은 가변적인 크기의 Block들로 이루어진다. 크기는 가변적이지만, 그 블록들은 모두 일정한 Chunk로 구성되며, 그들의 주소는 Chunk에 대해 Alignment되어 있다. 우리가 5바이트를 malloc하더라도 8바이트 시스템에선 2바이트의 패딩을 꼭 더하는 것이다. 1바이트는 Header(Payload Size + Allocate_or_Freed_Flag)이다.
System이 Double-Word Alignment를 채택하고 있고, Word Size는 4Bytes라 하자. 1Word는 4Bytes=32Bits이기 때문에 LSB 방향 3개 비트는 반드시 0이라 했다(주소값이 8단위로 끊길 것이므로). 상위 29개의 Bits만으로 충분히 Size 표기가 가능한 것이다. 따라서, 3개의 Unused Bits 중, 최하위 LSB Bit를 Flag로 사용하는 것이다.
우리는 지난 포스팅에서, 이러한 문제 상황에서 Implicit Free List를 어떻게 구현할지 알아보았다. Free Block을 Tracing하는 방법부터, 고르는 방법, 그리고 Allocate하는 방법 등, 각 Routine이 어떠한 Policy를 기반으로 설계되었는지를 알아보았다.
가장 마지막으로 다루었던 개념은 'How to free'였다. Allocate에 비해 Free는 더 Tricky하다. 왜? 'False Fragmentation' 문제 때문이다.
~> 우리가 어떤 Pre-Allocated Block을 Free를 했을 때, 만약, 그 공간 앞 뒤로 Free Block이 붙어있다고 해보자.
=> 간단하게 Flag만 바꾼다고 해서 해결될 일인가? 아니었다.
--> 앞 뒤의 Free Block과 새롭게 Free가 된 공간을 하나로 합쳐(Coalesce)주어야 한다. 이들을 합치지 않으면, 이들을 합쳤을 때 충분히 할당할 수 있는 '요청'을 제대로 처리하지 못하게 되는 것이다. 이는 곧 불필요한 sbrk 호출로 이어질 것이다.
"합칠 수 있는 것들은 모두 합쳐주어야 한다!"
Bidirectional Coalescing
지난 포스팅의 마지막에서, 기-할당된 Block을 Free할 때, 해당 공간 바로 뒤에 Free Block이 있으면, 이를 합쳐주는 Code를 본 기억이 날 것이다. 당연, 그 코드에선 다음과 같은 문제가 발생한다.
"좋아, 그런데 Previous Free Block은 어떻게 처리할거야?"
잘 생각해보자. 현재의 Block Format을 떠올려보자. 과연, 이 Format에서 Previous Block의 State를 알 수 있는 방법이 있을까?
"그렇다. 현재 우리가 고려하는 Format 상에선 '이전 Block'을 Reference할 방법이 없다."
Boundary Tags
그래서 도입된 개념이 'Boundary Tags'이다. 굉장히 간단하면서도 획기적인 방법이다. 우리는 여태 '현재 Block의 Size'를 통해서 Next Block을 조회했다. Size에 Double-Word Alignment를 맞춰주고, 그 Size를 이용해 Pointer Arithmetic Addition을 수행해 다음 Block의 위치를 찾았었다.
"무엇을 통해서? Size를 통해서!"
이 말은 즉슨, 우리가 'Previous Block의 Size'를 알 수 있다면, 이전 Block을 Reference할 수 있다는 것이다. 이 Idea에서 비롯된 개념이 바로 이 'Boundary Tags'이다. 문자열 매칭 알고리즘을 만든 CS의 대가 중 하나인 'Donald Knuth' 교수가 정립한 개념이다.

-
Header와 유사한 개념인 Footer를 도입한다.
-
각 Block의 맨 우측 끝에다가 Footer를 삽입한다.
- 각 Block이 Header와 Footer를 모두 가지는 것이다.
- 따라서, 안타깝지만 Internal Fragmentation은 늘어날 것이다.
- 각 Block이 Header와 Footer를 모두 가지는 것이다.
-
각각의 Block Bottom에 있는 Header에는 무엇이 있는가? 그렇다 Size&Status가 있다.
- 그 값을 그대로 Footer에 복제한다. ★★★
Previous Block으로 이동하고 싶으면, 현재 조회 중인 Block의 Header Word의 바로 앞 Word를 확인하면 Previous Block의 Size를 알 수 있다.
- 물론, Extra Space를 필요로 한다는 큰 단점이 존재한다. Backward로 가기 위한 노력이 희생을 낳는 것이다.
-
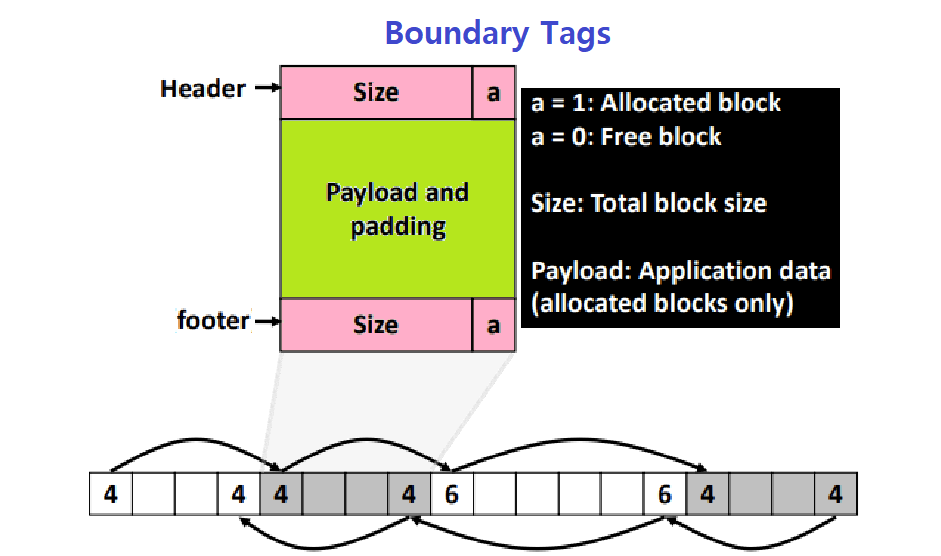
- Footer와 Header는 정확히 동일하다.
- Footer를 Boundary Tag라고 부른다.
Case Analysis
이러한 Bidirectional Coalescing을 이해하기 위해 다음과 같은 4가지 Case를 상정한다.

-
Case1 : 그냥 간단하게 Newly Freed Block만 해제하면 된다.
-
Case2 : Newly Freed Block과 Next Block을 합체한다.
- 'Newly Freed Block'의 Header에 '기존 Size + Next Block Size' 값을 기록해주고(Flag는 0으로), 그것을 그대로 'Next Block'의 Footer에 똑같이 기록해주면 된다.
-
Case3 : Newly Freed Block과 Previous Block을 합체한다.
- 'Previous Block'의 Header에 'Previous Block Size + Newly Freed Block Size' 값을 기록해주고(Flag는 0으로), 그것을 그대로 'Newly Freed Block'의 Footer에 똑같이 기록해주면 된다.
- Case4 : Newly Freed Block과 Previous & Next Block을 합체한다.
- 'Previous Block'의 Header에 'Previous Block Size + Newly Freed Block Size + Next Block Size' 값을 기록해주고(Flag는 0으로), 그것을 토대로 'Next Block'의 Footer에 똑같이 기록해주면 된다.
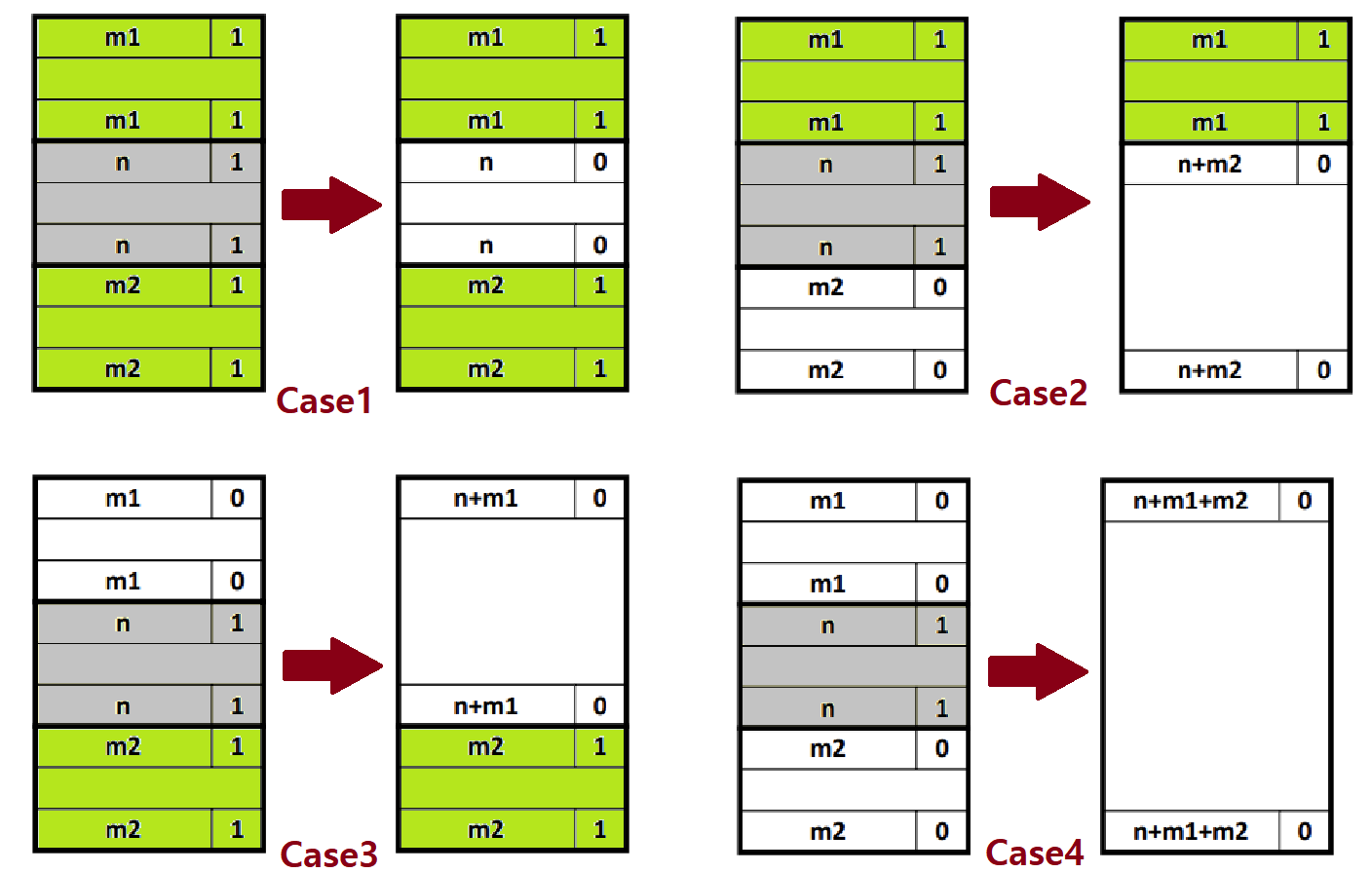
- 앞선 포스팅에서 소개한 코드를 기반으로 위의 내용을 코드화하는 것은 일도 아닐 것이다.
Pros and Cons
-
Pros : False Fragmentation 문제를 방지한다.
- 연속된 Free Block이 있는 문제를 방지한다는 것이다.
-
Cons : Internal Fragmentation이 더 심화된다.
- 이전의 Format에는 Footer가 없었다. 우리가 Boundary Tags 개념을 적용하기 위해선 반드시 Footer가 필요하다.
- 내부 단편화가 무엇이라 했는가? Block 내부에 Extra Space가 있는 문제라 했다. 이 방식은 당연히 내부 단편화 문제를 심화시킨다.
- 오해하지 말자. 이전 Format도 내부 단편화 문제가 있는 것이다. 왜? Header가 있으니까!
-
더 Optimize할 수 있을까?
-
개선의 여지는 분명히 있다. 우리는 Footer를 오로지 'Previous Block이 Free인지 확인할 때'만 사용한다.
-
내가 p라는 포인터를 가지고 Free를 하려는데, p가 가리키는 공간 바로 이전의 Block이 Free인지 아닌지를 확인하고자 할 때 필요하다.
- Previous Block이 Allocated이면, Coalescing할 일도 없고, 나아가 Footer도 필요가 없다.
- 여기서 Idea를 얻을 수 있다.
- Previous Block이 Allocated이면, Coalescing할 일도 없고, 나아가 Footer도 필요가 없다.
-
"이전 블록이 Free가 아니라면, 굳이 Footer를 둘 필요가 없다."
"이전의 Format을 생각해보자. 여기에 우리가 Extra Space를 더 두지 않으면서 동시에 추가적으로 활용해볼만한 공간이 더 없을까?"
"Double-Word Alignment 기준으로 LSB 방향 3개 비트는 Unused라 했다. 그 중 LSB는 우리가 Flag로 활용하고 있다."
"그렇다면, LSB 다음의 두 개 비트로 무언가 해볼만한 일이 있지 않을까?"
바로 이 부분이 '개선의 여지'이며, malloc을 개발한 개발자들이 떠올렸던 'Critical Idea' 중 하나였으며, 이번 Dynamic Memory Allocator 학습의 가장 중요한 부분 중 하나이다.
그런데, 본인은 이 부분에 대한 설명을 여기서 하지 않을 것이다.
여태 SP 연재를 해가며, Process 개념에서 Shell 만들기를 할 것이며, Network & Thread 개념에서 Server 만들기를 해볼 것이라 했다. 마찬가지로, Memory 개념에서 Allocator 만들기를 해볼 것이다. 따라서, 위 질문에 대한 해답은 Allocator 만들기 프로젝트에서 소개하도록 한다. (참고로, 이 세 프로젝트는 본인이 수강한 SP 과목의 세 프로젝트이기도 하다)
사실, 그렇게 대단한 이야기는 아니다. 몇 가지 방법이 존재하는데, 그 중 하나의 Hint를 주자면, 우리가 Allocate할 때, 조금만 생각해보면, Preivous Block은 반드시 Allocated라는 것을 알 수 있다. 왜냐? 가상의 '이미 완성된 최적의 free 함수'가 있다고 하면, Free Block이 연속될 순 없기 때문이다. 그렇다면, Unused Bits로 무언가 앞의 Allocated Block이 얼마만큼 떨어져 있는지 Offset을 기록해볼 수 있지 않을까? (다른 방법도 있다)
더 이상의 언급은 생략한다. 이어서 나머지 개념을 간단히 보자.
Coalescing Policies
Coalescing을 수행하는 시점은 아래와 같이 두 가지로 나눠볼 수 있다.
-
Immediate Coalescing : free 함수가 호출될 때 즉시 합체를 수행한다.
- 여태 본 상황이 여기에 해당한다.
-
Deferred Coalescing : free 함수의 성능을 높이기 위해 '특정 조건'을 두고 '필요할 때'만 합체를 수행한다.
- 즉, free 시에 합체를 수행하는 것이 아니라, malloc 시에 Free Block 찾을 때 Coalescing을 수행하는 것이다.
- 근데 이것도 항상 하는 것이 아니라, External Fragmentation이 어느 일정 Threshold를 넘어갈 때 말이다!
- 즉, free 시에 합체를 수행하는 것이 아니라, malloc 시에 Free Block 찾을 때 Coalescing을 수행하는 것이다.
~> 여기서도 Implicit Free List 개선의 여지를 떠올려볼 수 있을 것이다. (Insight for Project!)
금일 포스팅은 여기까지이다. 다음은 Explicit Free List에 대한 설명이다.
