지금까지 열심히 Implicit Free List에 대해 다루었다. 이제부턴 아직 소개하지 않은 Method들인 Explicit Free List와 Segregated Free List에 대해 알아보자.
Explicit Free List
Basic Concept
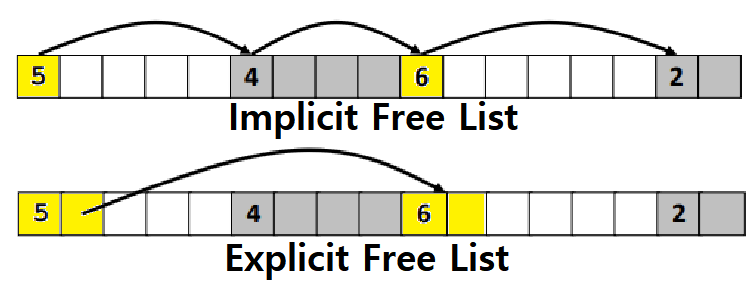
Explicit Free List는 '현재 Block의 Size' 뿐만 아니라 'Next Free Block의 주소값'도 저장하는 방식이다.
- 즉, 'Block Size'와 'Next Free Block Pointer'를 같이 저장하는 방식이다. (2Words)
-
당연히 공간적인 관점에서는 Implicit Free List가 더 유리하다.
-
Implicit Free List에선 Boundary Tags 방법을 사용하지 않는다고 보았을 때 Extra Space가 1Word면 충분하다.
-
반면, Explicit Free List에선 2Words가 필요한 것이다.
-
아래 그림을 보면, Implicit Free List에선 5Words Size의 Block에 4Words의 Payload가 저장될 수 있는 반면, Explicit Free List에선 똑같은 5Words Size Block에 3Words Size의 Payload를 저장할 수 있다.
- Implicit Free List는 4/5, 즉, Payload가 80%를 차지한다.
- Explicit Free List는 3/5, 즉, Payload가 60%만 차지한다.
-
-
- 두 방식 모두 Free Block Search 시에 Linear Traversal을 사용한다. 하지만 Implicit은 State와 상관없이 모든 Block을 순회하는 반면, Explicit은 Free Block만 순회한다.
- 따라서, Explicit이 순회 횟수가 훨씬 적으며, 나아가 수행 속도도 더 우수하다.
- Implicit Free List와 다르게 Explicit Free List는 오로지 Free Blocks에 대한 List만 운용한다.
- 그런데, 이전에 Implicit Free List free 상황에서 봤듯이, Explicit 방식 역시 마찬가지로 Previous Free Block을 탐색하기 위해선, Previous Free Block을 가리키는 Pointer도 필요하다.
- 즉, 외부 단편화를 줄이기 위해선 결국 Extra Space로 4Words가 필요한 것이다.
- Boundary Tags를 사용하는 Implicit Free List보다도 내부 단편화가 좋지 않다. ★
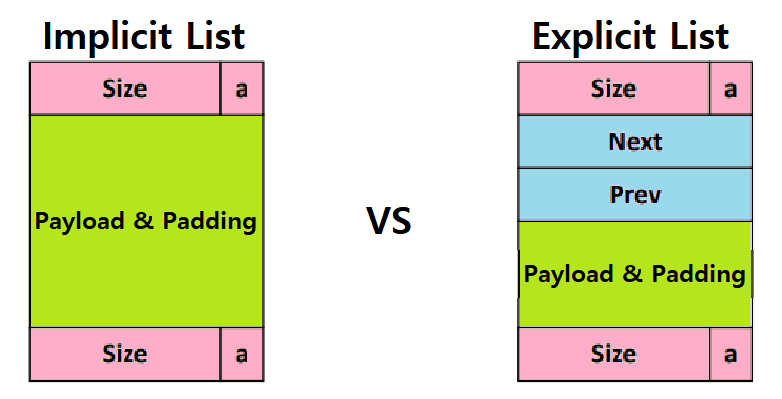
- Header, Next Ptr, Prev Ptr, Footer가 필요하다. 총 4Words!!!
- Boundary Tags를 사용하는 Implicit Free List보다도 내부 단편화가 좋지 않다. ★
- 즉, 외부 단편화를 줄이기 위해선 결국 Extra Space로 4Words가 필요한 것이다.
- 그런데, 이전에 Implicit Free List free 상황에서 봤듯이, Explicit 방식 역시 마찬가지로 Previous Free Block을 탐색하기 위해선, Previous Free Block을 가리키는 Pointer도 필요하다.
-
Explicit Free List는...
-
여전히 Size 정보가 필요하다. ★
- 얼마만큼 Free할지를 알아야할 것 아닌가. 그리고 Coalescing에도 필요하다.
-
여전히 Boundary Tags가 필요하다. ★
- Coalescing, 즉, '합체'를 하기 위해선 결국 Size 정보도 앞 뒤로 다 가지고 있어야 한다. Size를 모르면 단순 포인터(주소값)를 가지고는 합칠 수 없으므로!! ★★★
-
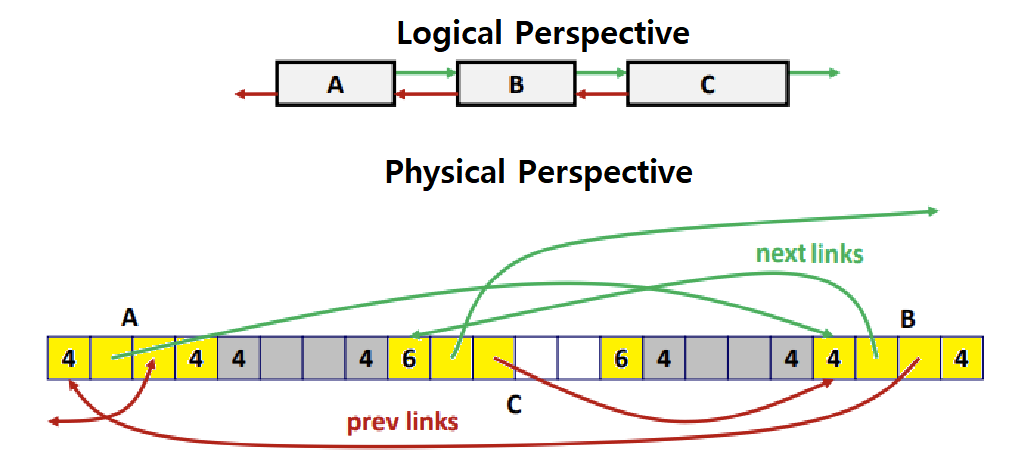
- 위의 그림을 보자. Explicit Free List의 경우, Logical한 관점에서는 일렬로 쭉 늘어진 Doubly Linked List이지만, Physical한 관점에서는 뒤죽박죽의 연결관계를 가질 확률이 높다.
- 왜냐? Free가 순서대로 이루어지지 않기 때문이다. 섞이기 마련이다.
How to allocate & free?
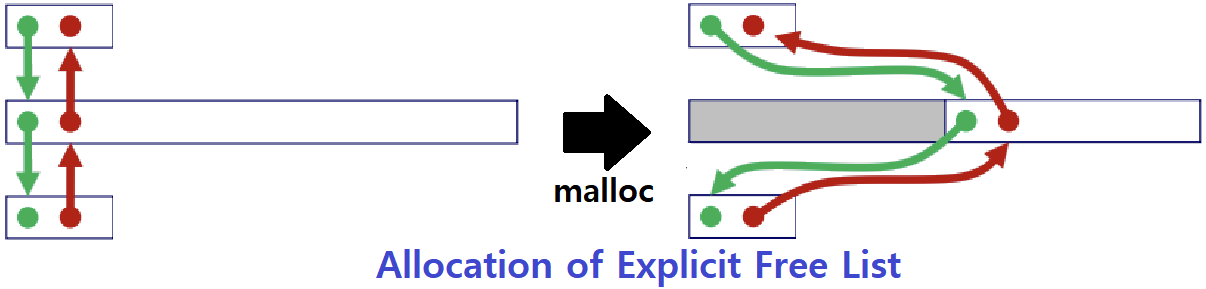
-
Explicit Free List의 Allocation도 당연히 Implicit Free List처럼 Splitting이 필요하다.
-
Free Block에 Allocation 후, 여유분이 없으면 마치 Doubly Linked List에서 중간 Node를 삭제하듯이 연결을 끊으면 그만이지만,
-
여유분이 남는 경우, Previous Free Block, Next Free Block과 여유분이 각각 서로 Doubly Linked 되도록 설정해주어야 한다.
-
-
Explicit Free List의 Free는 기본적으로 'Insertion'이다.
- Free List에 Newly Freed Block을 삽입해야하는 것이다.
- 여기엔 아래와 같이 크게 두 가지 유형의 방법이 존재한다.
- Free List에 Newly Freed Block을 삽입해야하는 것이다.
-
Method1) LIFO(Last-In-First-Out) Policy : Queue 논리를 따르는 것이다. 그냥 간단히 Free List의 맨 앞에 Newly Freed Block을 삽입하는 것이다.
- 굉장히 간단하고, 수행 속도가 빠르다. (Constant) ★★
- 연구 결과에 따르면 Fragmentation이 Method2에 비해 심하다고 한다. (단점) ★★
-
Method2) Address-Ordered Policy : Newly Freed Block을 Free List에 삽입할 때, 항상 Address Order에 맞게 Sorting해서 삽입하는 방식이다.
- 즉, 삽입할 때, Order대로 쭉 순회하다가, Proper 위치가 발견되면 해당 위치에 삽입하는 것이다.
- Fragmentation이 Method1보다 덜하다는 장점이 있다.
- 반면, Search를 필요로 하므로 수행 속도가 상대적으로 느리다.
- 즉, 삽입할 때, Order대로 쭉 순회하다가, Proper 위치가 발견되면 해당 위치에 삽입하는 것이다.

이전 포스팅에서 언급했던 'Free 상황 4가지 Case'에 대해 Method1(LIFO Policy)을 적용해보자.
- Case1 : Allocated Block을 Free하려고 하는데, Previous & Next Block이 모두 Allocated인 상황이다. 그냥 Root(Head)와 'Newly Freed Block', 'Newly Freed Block'과 'Previous First Free Block' 사이에 Doubly Link를 진행하면 된다.
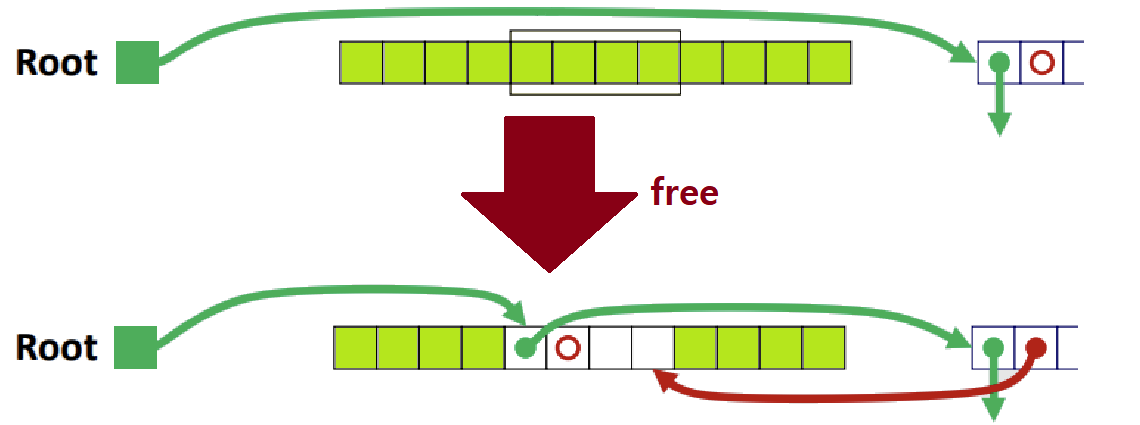
-
Case2 : Allocated Block을 Free하려고 하는데, Next Block이 Free인 상황이다.
-
일단 Coalescing부터 진행하자.
-
이를 위해, Next Block을 일단 Free List에서 Splice Out한다. 즉, 축출한다는 것이다.
-
이어서, 축출된 해당 블록과 Newly Freed Block을 하나로 합친다.
- Boundary Tags를 이용해 말이다.
-
-
Coalescing이 끝나면, 새롭게 만들어진 Coalesced Free Block을 Free List의 맨 앞에 삽입한다!
-
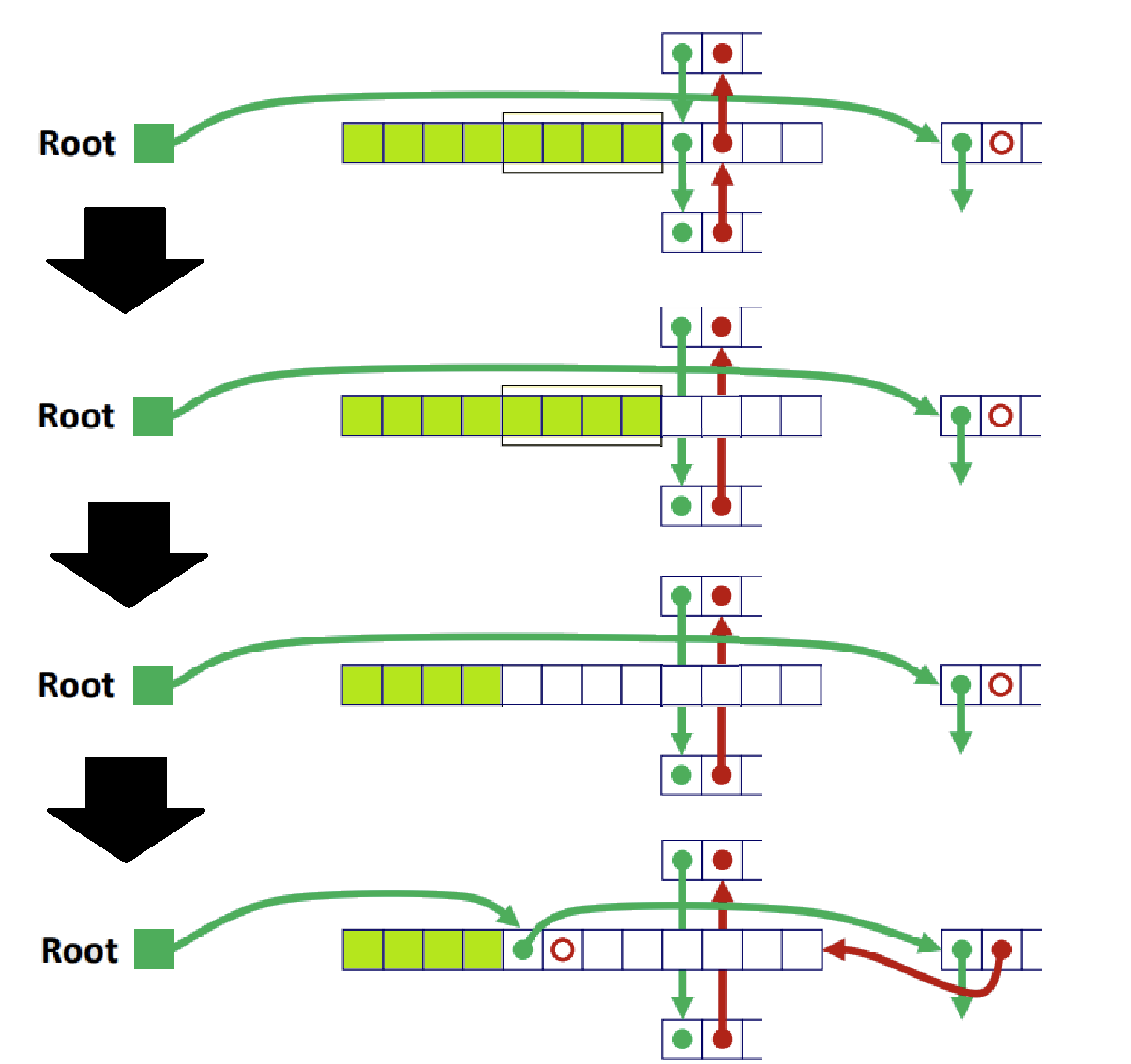
- 먼저 Next Free Block을 Free List에서 Delete한 후, 해당 Block과 새 Free Block을 하나로 합친 후, 다시 이들을 Free List에 삽입하는 것을 알 수 있다. 대신 맨 앞으로!
- Case3 : Allocated Block을 Free하려고 하는데, Previous Block이 Free인 상황이다.
- 이는 Case2와 동일하게 진행하면 된다. 단지 Previous Free Block을 Free Block에서 축출한다는 점만 빼고 말이다.
-
Case4 : Allocated Block을 Free하려고 하는데, Previous & Next Block이 모두 Free인 상황이다.
- 이 역시 Case2와 동일하다. Previous Free Block과 Next Free Block을 모두 Free List에서 뽑아낸 다음, 이들과 Newly Freed Block을 하나의 Free Block으로 합쳐준다.
- 즉, 총 3개의 Memory Block이 Coalescing의 대상이 되는 것이다.
- 그 다음, 이들을 Free List의 맨 앞으로 삽입한다.
- 즉, 총 3개의 Memory Block이 Coalescing의 대상이 되는 것이다.
- 이 역시 Case2와 동일하다. Previous Free Block과 Next Free Block을 모두 Free List에서 뽑아낸 다음, 이들과 Newly Freed Block을 하나의 Free Block으로 합쳐준다.
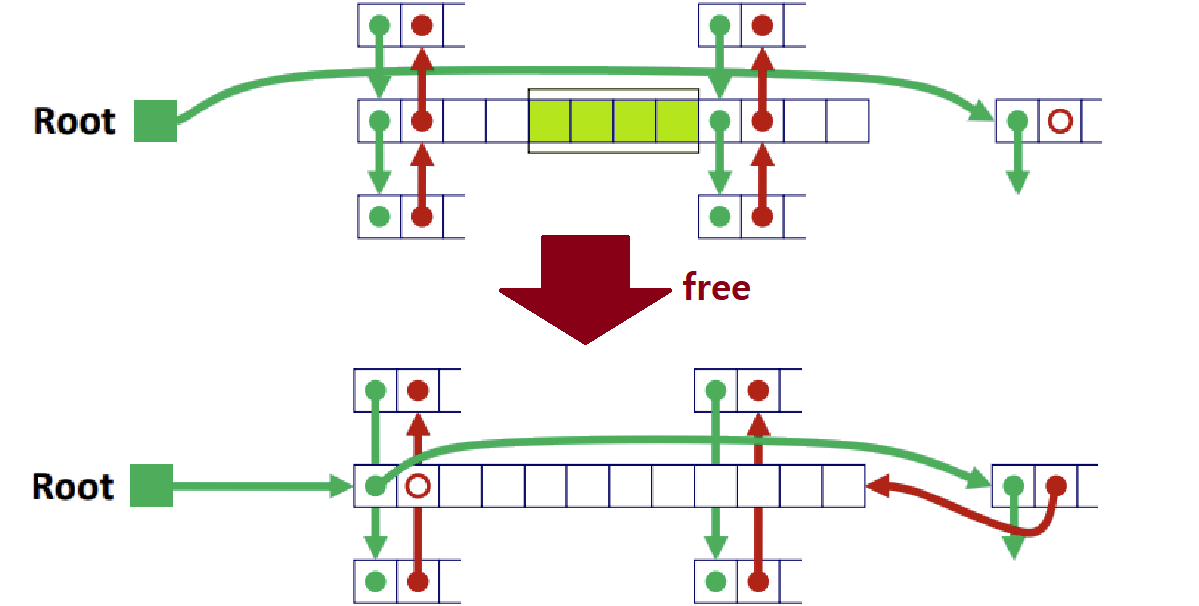
- 그냥 과거 Data Structure에서 배웠던 Doubly Linked List와 동일하다고 보면 된다. 단지, 삽입이 맨 앞에서만 이뤄지고, 삽입 이전에 Splitting이나 Coalescing이 일어날 수 있다는 점만 빼면 말이다. (Not Hard!)
- 코드로 구현하는 것 역시 Doubly Linked List와 거의 동일할 것이다.
Summary
-
Explicit Free List의 추가적인 특징
-
Heap Memory가 Full에 가까울수록 Explicit Free List의 Search Time이 빨라진다.
- 당연한 것이, Free Block 개수가 줄어들 것이기 때문이다.
-
Implicit Free List보다 Implementation 측면에서는 조금 더 난이도가 있다. 아무래도 Splicing 과정이 필요하기 때문이다. Linked List를 다룬다는 점도 그렇고.
-
Implicit Free List보다 공간 활용적 측면에선 훨씬 좋지 않다.
- 두 Method 모두 Boundary Tags를 채택한다고 했을 때, Explicit List가 Implicit List보다 2개의 Word를 더 필요로 한다. (Total 4Words)
- Internal Fragmentation이 더 심화될 것이다.
- 두 Method 모두 Boundary Tags를 채택한다고 했을 때, Explicit List가 Implicit List보다 2개의 Word를 더 필요로 한다. (Total 4Words)
-
Implicit과 Explicit 모두 Internal Fragmentation의 최소화를 위해 Best Fit Searching을 채택해야하는데, 이전에 설명한 것처럼, Best Fit은 Cost가 높다.
-
Q) Explicit의 경우, Block의 크기가 최소 몇 Words여야 하나요?
A) 생각해보자. Boundary Tags를 사용한다고 할 때, Header, Footer, Prev Ptr, Next Ptr까지 총 4Words의 Extra Space가 필요하다.
이때, Payload가 있어야 하는데, 과연 이 Payload가 단순히 1Word 이상이면 될까? 그렇지 않다. 2Words는 최소로 있어야 한다. Double-Word Alignment 기준으로 말이다. 즉, Alignment까지 고려하면, 최소 6Words가 필요할 것이다. (현재 예시에서) ★★★
Q) Implicit/Explicit, 그리고 Search Method(First Fit, Next Fit, Best Fit)에 상관 없이, Immediate Coalescing을 사용하면 바로 바로 Coalescing을 수행하므로 Previous Free Block은 있을 수 없지 않나요?
A) 정확하다. Immediate Coalescing의 경우, 그때 그때 바로 바로 Free Block들을 조정해주기 때문에 Allocated Block의 바로 앞에 Free Block이 있는 경우는 발생하지 않을 것이다. ★★★
Segregated Free List
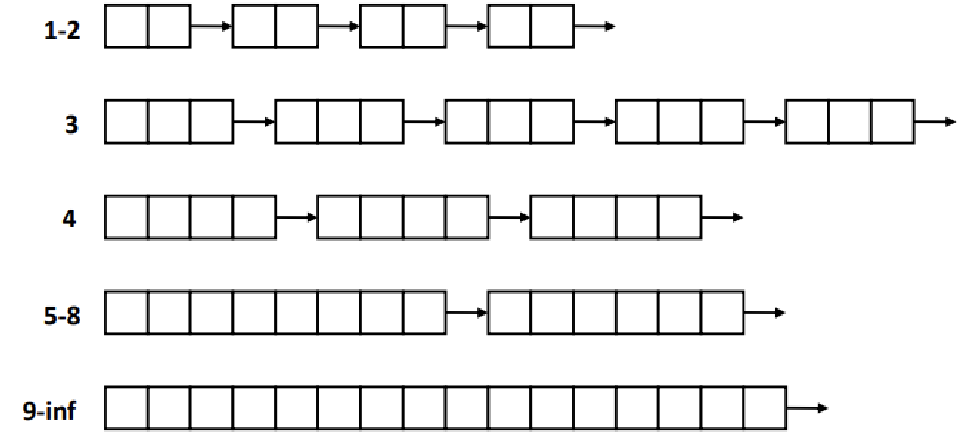
Segregated Free List Method는 'Free Block의 Size'에 대해 Free List를 각각 마련하는 방식이다. 서로 다른 Size 값이 N개라면, N개의 'Free List(Size Class)'를 두어 각 Free Block들을 분류해서 기억하는 것이다.
"Each size class of blocks has its own free list!"
-
위와 같이, Unique한 Size가 아니라, Size의 Range를 하나의 Class로 두기도 한다. 너무 많은 Class가 있으면 그것 나름대로의 Overhead가 있을 수 있으므로.
- 주로, Small Size들에 대해선 각각 유니크하게 Class를 두고, 큰 Size들에 대해선 2^n 단위로 끝어서 Class화한다.
-
이러한 Segregated Free List의 가장 큰 장점은 무엇일까?
- 기존의 Implicit, Explicit Free List 방식에서 Best Fit을 찾기 위해 전체 Traversal이 필요했던 것과 다르게, '요청한 Size'에 대응하는 Size Class만 Searching하면 된다는 것이다.
- 즉, Free Block Searching의 Cost가 상대적으로 훨씬 적다. ★
- 기존의 Implicit, Explicit Free List 방식에서 Best Fit을 찾기 위해 전체 Traversal이 필요했던 것과 다르게, '요청한 Size'에 대응하는 Size Class만 Searching하면 된다는 것이다.
-
이 방식을 적용한 Dynamic Memory Allocator를 'Seglist Allocator'라고도 부른다. ★
How to allocate?
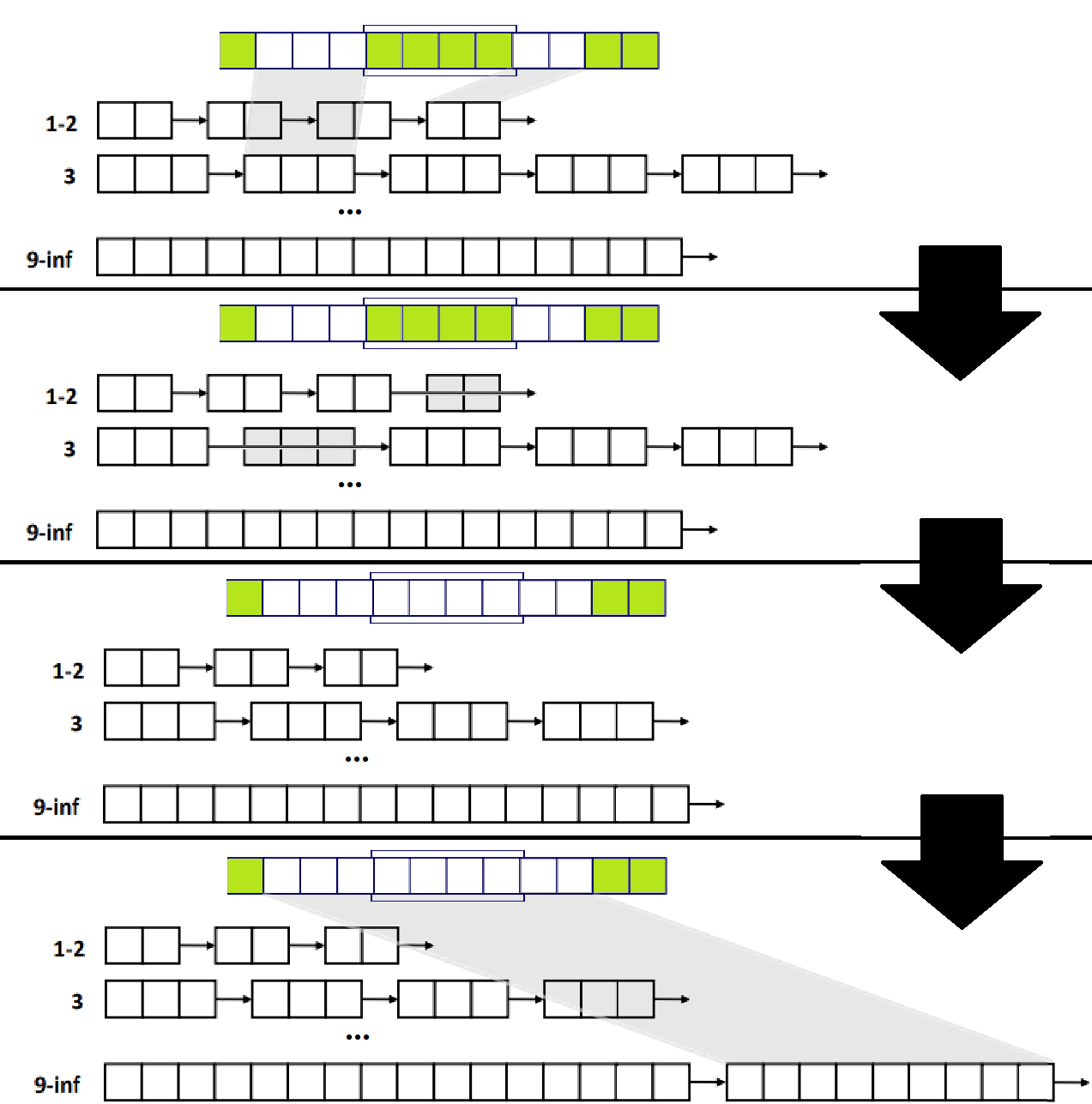
malloc(n Words)으로, 크기가 n Words인 Block의 Allocation을 요청했다고 해보자. n보다 크기가 큰 Size Class들 중 Size가 가장 작은 Class부터 찾아간다. ★★★
-
즉, malloc(4 Words)인 경우, 위의 그림에서 1-2, 3 Class는 Skip한다.
- n을 Payload만을 가리킬 지, Payload를 포함한 전체 Block Size로 볼지에 따라 구현이 약간 달라질 수 있다. ★★★
- 설명은 후자 방식을 토대로 진행한다. 즉, Payload를 포함한 Size로 본다.
- n을 Payload만을 가리킬 지, Payload를 포함한 전체 Block Size로 볼지에 따라 구현이 약간 달라질 수 있다. ★★★
-
따라서, n Size의 Block을 할당하고자 하면,
- n보다 큰 임의의 정수 m에 대해, m Size Class들부터 쭉 훑는 것이다.
- 적절한 Free Block이 발견되면,
- Splitting과 함께, 여유분 Free Block을 해당 Size에 알맞는 Size Class로 귀속시킨다(이는 구현 방법에 따라 다를 수 있다). ★★
- 적절한 Free Block이 발견되면,
- n보다 큰 임의의 정수 m에 대해, m Size Class들부터 쭉 훑는 것이다.
-
예를 들어, malloc(6)시, 위의 그림 기준으로, 5-8 Class를 훑기 시작하고, 해당 Class의 첫 번째 Free Block에 대해, 6 Words 만큼을 Allocation하고, 나머지 2Words는 여유분 Free Block이 되므로 이 부분을 Split해서 1-2 Class에 귀속시킨다.
- 삽입하는 방법 역시 구현하기 나름이다. 맨 앞에 하거나, 적절한 위치를 찾아서 삽입하거나.
-
만약, 한 Class에서 Proper Block을 찾지 못하면, 그 다음 크기가 큰 Size Class로 가서 Keep Searching한다. 찾을 때까지!
- 만약, 다 훑고 나서도 Proper Block을 찾지 못하면,
- sbrk System Call을 통해 OS에게 Heap Memory 확장을 요구한다.
- 여기서 바로, n Bytes의 Allocation을 수행한다.
- Allocation하고 남은 여유분 Memory를 '통째로' Largest Size Class에 귀속시킨다. ★★★
- 위 그림에선 9-Inf Size Class가 될 것이다. 물론, 9보다 작게 남는다면, 그 이하 Class에 삽입하면 될 것!
- Allocation하고 남은 여유분 Memory를 '통째로' Largest Size Class에 귀속시킨다. ★★★
- 여기서 바로, n Bytes의 Allocation을 수행한다.
- sbrk System Call을 통해 OS에게 Heap Memory 확장을 요구한다.
How to free?
Free시엔, Explicit Free List에서 그랬던 것처럼, 'Coalescing'과 'Placing on an appropriate list'가 연달아 수행되어야 한다. 아래 그림처럼 말이다. ★★
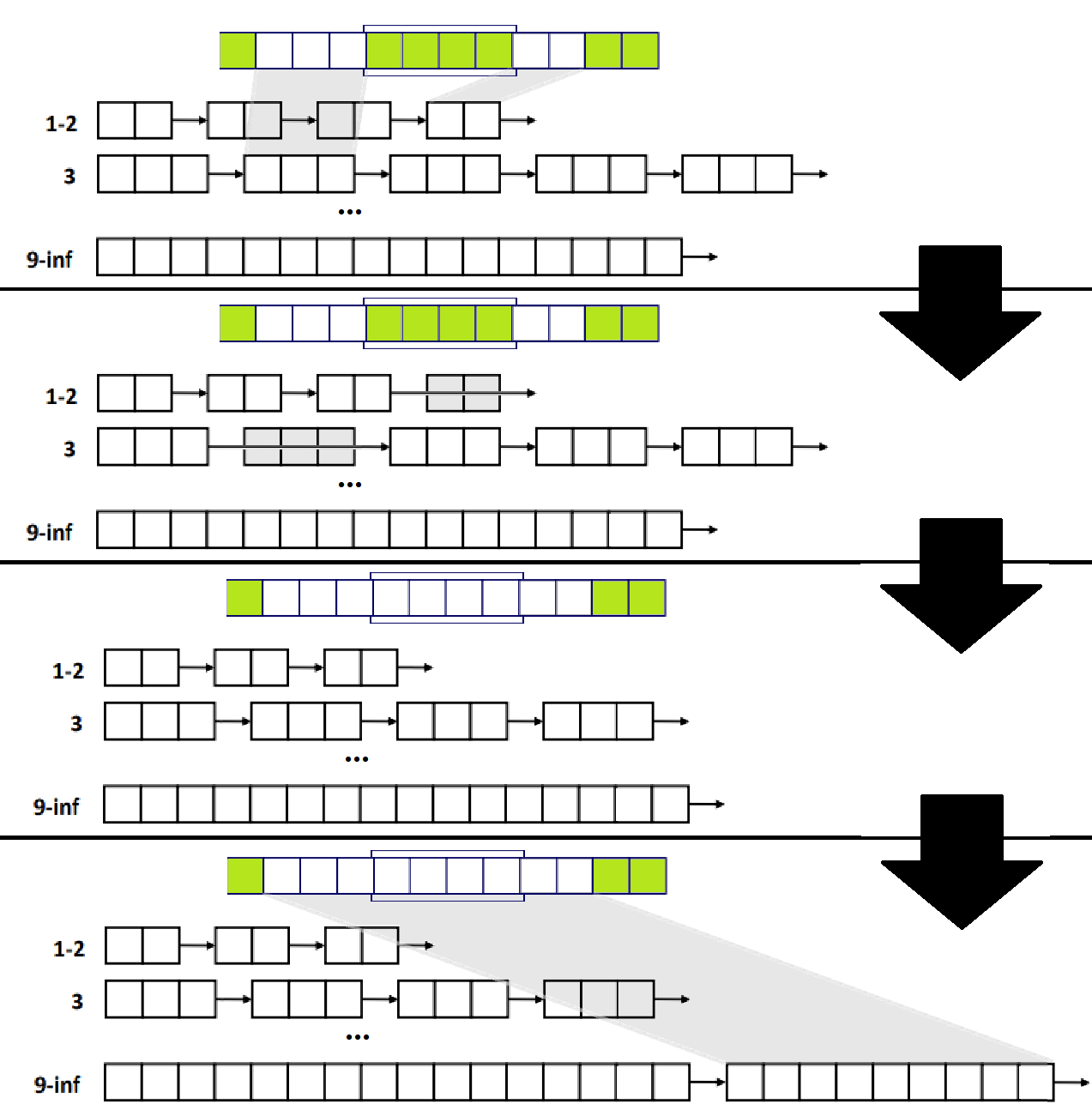
- Newly Freed Block의 앞 뒤에 Free Block이 있으면, 해당 Block들을 자신들이 속해있는 Size Class Free List에서 축출해주고, 그 다음, 이들을 하나의 Free Block으로 Coalescing한다. 이어서, 새롭게 만들어진 Free Block을 Size에 알맞게 Size Class로 귀속시킨다.
Advantages
-
Seglist Allocator의 장점은 다음과 같다.
-
Throughput이 좋다.
- Size Class가 아무리 많아도 Class 선정에 최소로 log time밖에 걸리지 않기 때문에 상당히 Searching이 우수하다. (Class Picking에 Binary Search 등을 적용한다고 가정)
-
Peak Memory Utilization이 우수하다.
-
Segregated Free List에서 First Fit 방식을 채택하더라도, 그 메모리 활용도는 Heap에 대한 Best Fit Search의 메모리 활용도에 준한다.
-
만약, 극단적으로, 모든 Size에 대해 일일이 Size Class를 마련할 경우, Memory 활용도가 매우 높아질 것이다.
-
즉, Fragmentation을 최소화할 수 있다.
-
-
즉, Segregated Free List 방식은 Throughput이나 Peak Memory Utilization이나, 모든 면에서 Implicit or Explicit Free List보다 우수하다.
- 물론, Seglist Allocator는 구현이 다소 복잡하다는 점 등 일부 단점도 존재한다.
이 밖에 Dynamic Memory Allocator 구현 방법 Method4인 'Blocks Sorted by Size'라는 방법도 존재한다. Red-Black Tree를 사용하는데, 이 개념은 본 SP 연재에선 생략하겠다. Dynamic Memory Allocator 구현 방법에 대한 학습은 여기까지이다. 다음 포스팅에선 아직 소개하지 않은 Implicit Memory Management에 대해서 다뤄보겠다.
금일 포스팅은 여기까지이다.
