Linking
이번엔 Linking에 대해 다뤄볼 것이다. 우리가 C Program을 작성하고, Program을 메모리에 올릴 때, Process에는 Code 및 Data가 자리잡는다(단순히 Segment를 말하는 것이 아니다).
이때, Process의 '다양한 Data와 Code 조각'을 Memory에 Load될 수 있는 'Single Executable File'로 만들고, 이를 Execute하는 일련의 과정을 Linking이라 한다.
-
Linking은 Compile Time, Load Time, Run Time에 수행될 수 있다.
- 구현에 따라 다르다.
-
현대 시스템에선 Linker가 Linking을 자동으로 수행한다.
Why Learning?
우리가 Linking의 원리, 그리고 Linker를 알아야하는 이유는 무엇일까?
-
큰 프로그램을 짤 때 도움이 된다.
- 일반적으로 큰 프로그램을 짤 땐 여러 개의 작은 파일로 프로그램을 나누는데, 이때, Linker가 Library를 이용해 Reference를 어떻게 Resolve하는지를 알면 조금 더 수월한 프로그래밍을 할 수 있다.
-
심각한 에러의 발생을 방지할 수 있다.
- 여러 파일에 걸쳐 복수의 전역 변수를 올바르지 않게 선언하여 프로그래밍 하는 경우, 일반적으로 Warning 없이 Compile이 그대로 이루어진다. 이러한 유형의 에러는 Run-Time 시에 뜬금없이 발견되며, 디버깅하기 매우 어렵다.
-
Language Scoping Rule에 대해서 더 잘 이해할 수 있게 된다.
-
Linker가 만들어내는 Executable Object File은 Program Loading, Program Running, Virtual Memory, Paging, Memory Mapping 등에 대한 폭넓은 정보를 담고 있다. 이들에 대한 System적 이해를 도모할 수 있다.
-
Shared Library를 '잘' 만들고, '잘' 이용하는 법을 알 수 있다.
즉, Linking 과정에 대한 이해는 SP 학습에 있어서 상당히 큰 도움이 된다.
Static Linking
-
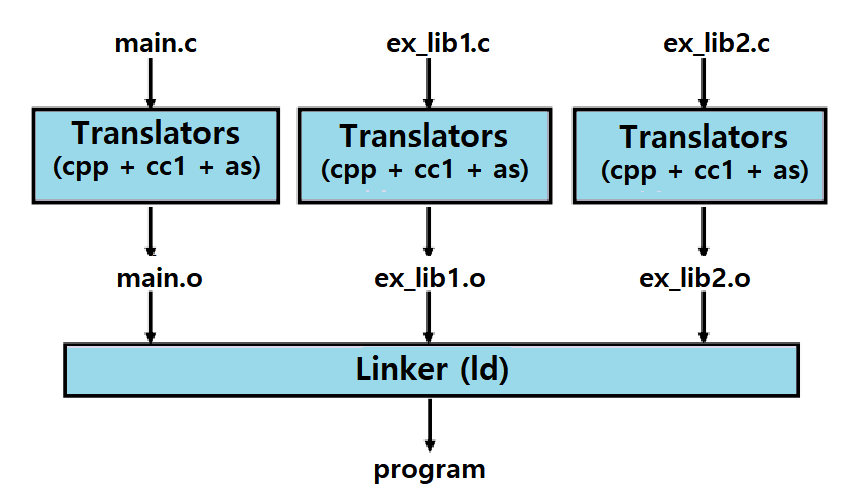
Compiler Driver가 Program을 Translate하고 Link한다.
- > gcc -Og -o program main.c ex_lib1.c ex_lib2.c
- > ./program
-
Compiler Driver (Compiler)의 구성
-
C Preprocessor (cpp) : 전처리를 수행한다.
- main.c와 같은 C 소스 코드를 main.i와 같은 ASCII Intermediate File로 변환한다.
-
C Compiler (cc1) : 컴파일을 수행한다. 결과로 Assembly Code File이 만들어진다.
- main.i를 ASCII Assembly-Language File인 main.s로 변환한다.
-
Assembler (as) : Assembler를 통해 Assembly File을 Relocatable Binary Object File로 만든다.
- main.s를 Binary Relocatable Object File인 main.o로 변환한다.
-
Linker (ld) : 위의 과정을 거친 '복수'의 .o File들을 하나로 합친다.
- main.o와 ex_lib1.o, ex_lib2.o 등을 하나의 Binary Executable Object File인 program으로 변환한다.
- 즉, '전처리-컴파일-어셈블' 과정은 모든 대상 .c 파일에 대해 수행되고, Linking은 이들의 .o 파일에 대해 수행되어 단 하나의 결과물을 만드는 것이다. ★★★
- main.o와 ex_lib1.o, ex_lib2.o 등을 하나의 Binary Executable Object File인 program으로 변환한다.
-
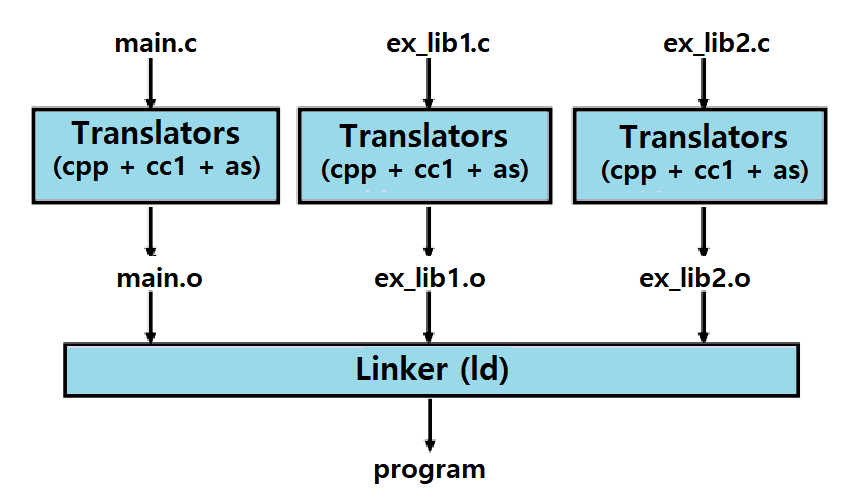
각각 만들어진 Relocatable Object File을 Linker가 하나의 Fully Linked Executable Object File로 합치는 것이다. ★★★
위와 같은 흐름으로 Linking이 수행되는 것을 Static Linking이라 한다. ★
Fully Linked가 Static Linking을 의미하는데, 자세한 이야기는 이후 포스팅에서 다룬다.
Linker
Advantages
Linker는 Linking을 수행하는 장치이다. Linker의 장점은 무엇일까?
-
Modularity : Program을 'Smaller Source File'들의 Collection으로 만들 수 있다. 즉, 모듈화할 수 있다.
- 프로그램이 하나의 Monolithic(큰 돌덩이같은) Mass가 되는 것을 방지한다.
- 자주 사용하는 함수들은 Library로 빌드해서 사용할 수 있다.
- math.h, stdio.h
-
Time Efficiency : Compiler Driver는 Separate Compilation을 수행하기 때문에 시간적인 효율이 좋다.
- Separate Compilation : 이전 Compile 후 수정이 일어나면, 수정이 일어난 Source File에 대해서만 Re-Compile하고, 그 외의 Source File은 그대로 유지한다.
- 수정이 일어난 Source에 대해서만 .o 생성 과정을 수행하고, 나머지 Source에 대해선 기존에 만들어놓은 .o를 그대로 사용해 Linking한다. ★
- Linker가 있기 때문에 Compiler Driver가 이렇게 Separate Compile을 할 수 있는 것이다. ★
- 수정이 일어난 Source에 대해서만 .o 생성 과정을 수행하고, 나머지 Source에 대해선 기존에 만들어놓은 .o를 그대로 사용해 Linking한다. ★
- Separate Compilation : 이전 Compile 후 수정이 일어나면, 수정이 일어난 Source File에 대해서만 Re-Compile하고, 그 외의 Source File은 그대로 유지한다.
-
Space Efficiency : 실행 파일을 만들 때 '실제 사용하는 함수'에 대해서만 코드를 가져오기 때문에 공간적인 효율도 높아진다.
- 메모리에 Library 코드를 다 올리지 않고, 부분적으로 필요한 것만 뽑아서 올리고, 구동시킨다는 것이다. ★
Symbol Resolution
Linker가 하는 일은 크게 'Symbol Resolution'과 'Relocation'으로 나눌 수 있다. 이들은 순차적으로 일어난다. 우선, Symbol Resolution에 대해 알아보자.
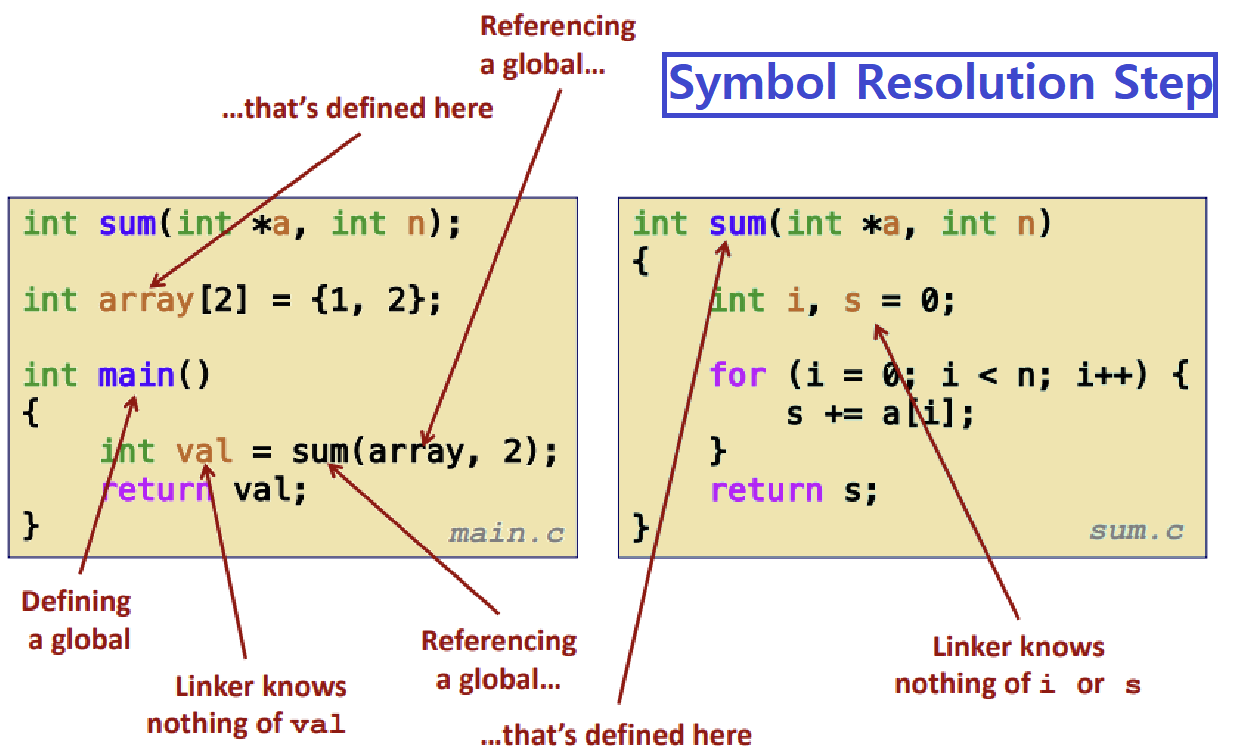
Linker는 Symbol Resolution을 통해 각 Symbol Reference가 정확히 하나의 Symbol Definition으로 대응되는지를 확인한다.
int sum(int *a, int n) {
int i, s = 0;
for (i = 0; i < n; i++) {
s += a[i];
}
return s;
}-
프로그램 안에는 여러 Symbol이 정의되어 있다. 위의 프로그램에서,...
- i, s, a, n, sum, int 등이 모두 Symbol이다.
-
프로그램 안에는 여러 Symbol이 정의되어 있고, 이들이 서로 참조하고, 참조된다. ★
-
Assembler가 만들어내는 Relocatable Object File 안에는 Symbol Table이라는 자료구조가 있고, 그 안에 각 Symbol에 대한 정보인 'Symbol Definition'들이 저장된다. ★★★
- Symbol Table은 Structures의 Array이다.
- 각 Entry는 name, size, location 등의 Symbol 정보를 포함한다. (그래서 '구조'인 것) ★
- 이러한 Object File이 Linker의 대상이 되는 것이다.
- Symbol Resolution에서는, 이러한 Symbol Definition을 이용해 각 Symbol이 오로지 하나의 Definition에 1대1로 대응하는지를 체크하는 것이다. ★
- 예를 들어, a.c, b.c라는 두 Source File에 각각 전역 변수 int cnt;가 있으면, 이 둘을 Linking 시 Linker는 Error를 알리는 것이다. ★★
Relocation
Linker는 Relocation을 통해, Linker의 대상이 되는 여러 Separate한 Code & Data Section들을 하나의 Section으로 만들고, 각각의 Relocatable Symbol들을 실제 Memory Location에 맵핑시킨다.
추후 이 두 Step을 더 자세히 설명할 것이다.
Object File
Kinds of Object Files
Object File은 아래와 같이 세 가지 종류로 분류할 수 있다. 각 유형을 Module이라고도 부른다.
-
Relocatable Object File (.o)
- 다른 Relocatable Object File들과 함께 묶여서 Executable Object File이 될 수 있도록 만들어진 Format에 의거한 Code, Data 정보들이 들어있다.
- 하나의 .c Source File로부터 하나의 .o File이 만들어진다.
- '전처리-컴파일-어셈블'의 과정을 거쳐서 말이다.
- 하나의 .c Source File로부터 하나의 .o File이 만들어진다.
- 다른 Relocatable Object File들과 함께 묶여서 Executable Object File이 될 수 있도록 만들어진 Format에 의거한 Code, Data 정보들이 들어있다.
-
Executable Object File (filename)
- Memory에 바로 Copy되고 Execute될 수 있는 Format에 의거한 Code, Data 정보들이 들어있다.
- 이름을 따로 지정해주지 않으면 Default File Name으로 'a.out'이 지정된다.
- Memory에 바로 Copy되고 Execute될 수 있는 Format에 의거한 Code, Data 정보들이 들어있다.
-
Shared Object File (.so)
- Relocatable Object File의 특별한 유형으로, Load Time에 Memory에 Load될 수 있으며, Run Time에 Dynamic하게 Link될 수 있다.
- Windows의 DLL(Dynamic Link Library)s가 바로 여기에 해당한다.
- Relocatable Object File의 특별한 유형으로, Load Time에 Memory에 Load될 수 있으며, Run Time에 Dynamic하게 Link될 수 있다.
ELF(Executable and Linkable Format)
ELF(Executable and Linkable Format)는 Object File을 위한 표준 Binary Format이다. 'ELF Binaries'라고도 부른다.
- Relocatable Object File, Executable Object File, Shared Object File 모두에 대한 Unified Format이다. ★
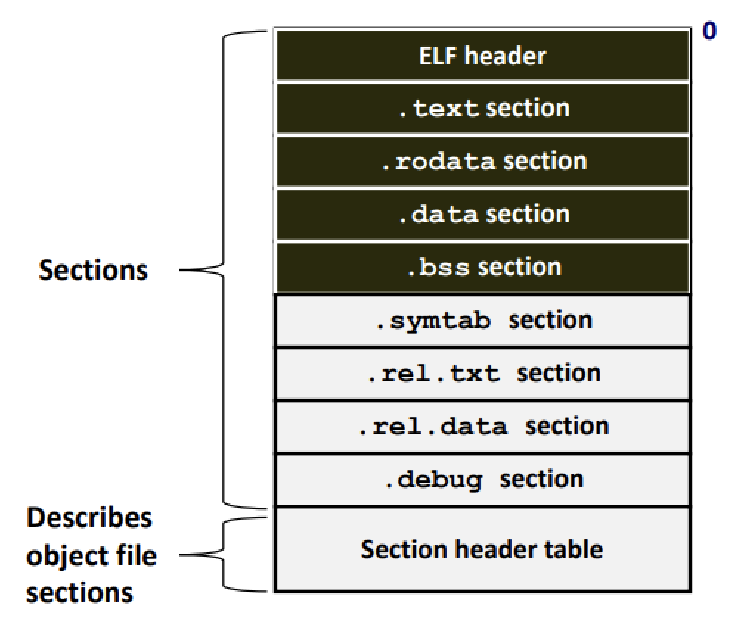
-
각 Section들과, 각 Section에 대한 정보를 담고 있는 Section Header Table 부분으로 나뉜다. ★
-
Sections
-
ELF Header : Word Size, Byte Ordering, File Type(.o, exec, .so 등), Machine Type, Section Header Table의 Offset 위치 등의 정보를 담고 있다. ★
-
.text : Compiled Program의 Machine Code가 담겨 있다.
- 기계어 코드가 담겨있다.
-
.rodata : Read Only Data를 담고 있다.
- switch 문에서 사용하는 Jump Table, printf문의 Format String 등이 이러한 Read Only Data에 해당한다.
-
.data : 초기화가 이루어진 Global Variable들의 정보가 담겨있다. Static Local Variable 정보도 여기에 들어간다.
-
.bss : 초기화되지 않은 Global Variable(Static Local도 포함)들이 여기에 들어간다.
- "Block Started by Symbol" or "Better Save Space"라고 해석할 수 있다. ★
- 아직 초기화되어 있지 않은 데이터들을 담기 때문에, 실제 Type만큼 공간을 차지하지는 않고, 그냥 '위치' 정보만 가지고 있다. 공간 효율을 높이기 위해 이런 것이다. ★★★
- "Has section header, but occupies no space."
- 추후 메모리 Load가 이뤄질 때, 0으로 초기화되고, 동시에 메모리를 차지하게 된다. ★★★
-
.symtab : Symbol Table이다.
- Program에서 정의되고 참조되는 Function과 Global Variable, Procedure, Static Variable Name 등의 정보가 Symbol Table에 들어있다. ★★
- 참고로, Local Variable은 C 기준 Stack-Dynamic하기 때문에 Linker와는 관계가 없다. 무조건 Run Time에 처리된다. ★★★
- Program에서 정의되고 참조되는 Function과 Global Variable, Procedure, Static Variable Name 등의 정보가 Symbol Table에 들어있다. ★★
-
.rel.text : .text Section에 대한 Relocation 정보를 담는다.
- 각 Instruction들의 Address를 다룬다. ★
- 이들은 Modification의 대상이다.
- 각 Instruction들의 Address를 다룬다. ★
-
.rel.data : .data Section에 대한 Relocation 정보를 담는다.
- Pointer Data들의 Address를 다룬다. ★
- 이들은 Modification의 대상이다.
- Pointer Data들의 Address를 다룬다. ★
-
.debug : 'gcc -g'를 통한 Symbolic Debugging 시에 사용되는 정보들이 담겨있다.
-
-
Section Header Table : 위의 각 Section에 대한 Offset과 Size 정보가 담겨있다. ★
-
Symbols
.symtab의 Symbol Table에는 각 Relocatable Object Module에서 Define되고 Reference되는 Symbol들에 대한 정보가 담겨있다. ★
Linker Symbols
한편, Linker 입장에선 Symbol을 아래와 같이 분류한다.
-
Global Symbols : 현재 Module에서 정의되어 있으면서, 동시에 다른 Module에서 참조할 수 있는 Symbol들을 가리킨다.
- Non-Static C Function과 Non-Static Global Variable들이 여기에 해당한다. (진짜 '찐' Global들)
-
External Symbols : Global Symbol이긴 한데, 현재 Module에서 정의되지 않고 다른 Module에서 정의된 Symbol을 의미한다.
- 즉, Global Symbol과 External Symbol은 같은 Symbol을 바라보는 서로 다른 관점인 것이다. ★★★
-
Local Symbols : 현재 Module에서 정의되어 있으면서, 동시에 오로지 현재 Module에서만 참조할 수 있는 Symbol들을 가리킨다.
- static Keyword와 함께 정의된 C Function과 Variable들을 의미한다. ★
- Program의 Local Variable들은 이와 관계가 없다.
- 위에서 언급한 것처럼, 애초에 지역 변수는 Linker와 관계가 없다. ★★★
- Program의 Local Variable들은 이와 관계가 없다.
- static Keyword와 함께 정의된 C Function과 Variable들을 의미한다. ★
※ Local Linker Symbol vs Local Program Variable
~> 'static Keyword를 붙이지 않고 선언한 모든 Local Variable(Non-Static Program Variable)'들은 .symtab의 Symbol Table에 담기지 않는다.
~> 앞서 말한 것처럼, Local Non-Static Program Variable들은 Run Time 시에 Stack에 의해 Dynamic하게 관리된다. Linker와는 하등 관계가 없다.
Local Symbols
앞서 말했듯이, Local Non-Static C Variable은 우리가 아는 일반적인 '지역변수'를 의미하며, Stack Segment에서 Dynamic하게 관리된다.
반면, Local Static C Variable은 .bss(초기화x)나 .data(초기화o)에 저장된다. Global Variable과 동일하게 취급되는 것이다. Lifetime은 다르지만.
int foo(void) {
static int x = 0; // foo 안에서만 접근 가능한 Variable
return x;
}
int bar(void) {
static int x = 1; // bar 안에서만 접근 가능한 Variable
return x;
}~> 위 코드에서, Compiler는 각각의 x라는 변수를 .data 영역에 할당한다(초기화되어 있으므로).
=> 이때, 이름이 같은 서로 다른 두 Local Static Variable을 Symbol Table 상에는 x.1, x.2와 같이 Linker(Compiler) 자체적으로 구분을 해서 넣어준다. ★★★
Strong & Weak Symbols
Symbol이 중복될 때, 바로 위의 문장에서는 Linker가 각각 구분을 해서 저장한다고 언급했다. 그러나, 포스팅 초반에는 분명 각 모듈에서 전역변수 명이 겹치면 오류가 난다고 했다. 무엇이 맞는 것일까?
"Linker는 Duplicate Symbol Definition 상황을 어떻게 Valid, Invalid 판정할까?"
- Program의 모든 Symbol은 Strong 또는 Weak로 구분할 수 있다.
- Strong : 모든 Procedure와 초기화된 Global Variable들
- Weak : 초기화되지 않은 Global Variable들
int foo = 5; // Strong Symbol
int bar; // Weak Symbol
void ex_procedure { // Strong Symbol
/* ... */
}Symbol Rule of Linker
Linker는 상기한 Duplicate Symbol Definitions 상황을 아래와 같은 3가지 Rule을 통해 처리한다.
-
Rule1
- 복수의 Duplicate Strong Symbol은 허용되지 않는다.
- (같은 Name에 대해) Strong Symbol은 오직 한 번만 Define될 수 있다.
- Violate하는 경우, Linker가 Error를 내보낸다.
- (같은 Name에 대해) Strong Symbol은 오직 한 번만 Define될 수 있다.
- 복수의 Duplicate Strong Symbol은 허용되지 않는다.
-
Rule2
- 하나의 Strong Symbol과 복수의 Weak Symbol이 있는 경우, 이때는 Strong Symbol을 선택해 Reference한다.
- "References to the weak symbol resolve to the strong symbol!"
- 하나의 Strong Symbol과 복수의 Weak Symbol이 있는 경우, 이때는 Strong Symbol을 선택해 Reference한다.
-
Rule3
- 복수의 Weak Symbol이 있는 경우, 이때는 아무 Symbol이나 임의로 선택해 Reference한다.

- Strong Symbol이 겹칠 때를 빼고는 Link Time Error는 발생하지 않는다.
- 허나, 위의 그림에서 3, 4번째 예시를 보면 알 수 있듯이, 두 모듈에서 Symbol이 Duplicate 상황이고, 둘 중 한 쪽이 택해졌을 때, 양측 모듈의 메모리 구성 상태가 다르면, 선택되지 않은 곳이 선택된 곳의 메모리 영역을 Run Time에 오류없이 오염시키는 심각한 일이 발생할 수 있다. ★★★
- 이때, 3번 예시는 '발생할 수도 있음'인데, 이는, 둘 중 우측 코드의 x가 택해질 경우엔 타 메모리 공간 Overwrite 상황은 발생하지 않기 때문이다. (Weak끼리는 임의 선택이므로)
- 허나, 위의 그림에서 3, 4번째 예시를 보면 알 수 있듯이, 두 모듈에서 Symbol이 Duplicate 상황이고, 둘 중 한 쪽이 택해졌을 때, 양측 모듈의 메모리 구성 상태가 다르면, 선택되지 않은 곳이 선택된 곳의 메모리 영역을 Run Time에 오류없이 오염시키는 심각한 일이 발생할 수 있다. ★★★
위의 그림에서 3, 4번째 예시와 관련하여, 한 가지 코드를 더 보면서 다시 한 번 확인해보자. 아래의 코드는 심각한 Run-Time Bug가 발생할 수 있는 코드이다. Link Time Error는 발생하지 않고 말이다. ★
/* test1.c 파일 내부 */
#include <stdio.h>
void foo(void);
int x; // Weak Symbol
int main(void) {
x = 12345;
foo();
printf("x = %d\n", x);
return 0;
}
/* test2.c 파일 내부 */
int x; // Weak Symbol
void foo(void) {
x = 12344;
}~> Comipler가 두 모듈 내 Symbol들의 메모리 영역을 어떻게 구성하느냐, Duplicate Symbol 중 어느 모듈이 Symbol이 택해지느냐에 따라, 의도치 않은 메모리 영역 침범 및 런타임 강제 종료를 야기할 수 있는 코드이다. 그냥 얼핏 봤을 때는 문제가 없어보이지 않는가? 그래서 더욱이 심각한 에러인 것이다.
=> 궁금하면 직접 Linux에서 돌려보자!
또 다른 코드를 보자. 이 역시 마찬가지의 문제 상황을 야기할 수 있는 코드이다.
/* test1.c */
#include <stdio.h>
void foo(void);
int y = 12344;
int x = 12345; // Strong Symbol
int main(void) {
foo();
printf("x = 0x%x y = 0x%x\n",
x, y);
return 0;
}
/* test2.c */
double x; // Weak Symbol
void foo(void) {
x = -0.0;
}~> 이 코드는 반드시 에러가 발생하는 코드이다. x라는 Symbol이 겹치는데, test1.c에선 Strong, test2.c에선 Weak이다. 따라서, test1.c의 x가 선택된다. 허나, 두 소스 파일에서 x의 Type 및 Size가 다르다. 만일, foo 함수 호출로 인해 x에 0.0이란 값이 입력되면, test1.c의 int x에 0.0이란 Floating Point Value가 들어가게 되고, 이는 x의 4바이트 공간을 초과해 미지의 영역에 Write하는 일을 만든다.
=> 이는 Subtle(미묘)하고 Nasty(심각)한 Run-Time Bug를 만들어내는 것이다. ★
- 만일, x의 메모리 주소가 0x1000이고, y의 메모리 주소가 0x1004라고 해보자. 알다시피, 전역 변수는 쭉 나열해서 저장하기 때문에 실제로도 이렇게 할당될 것이다.
- 이때, foo 함수에서 'x = -0.0;'을 수행하면, Linker에 의해 선택된 0x1000번지에 0.0이라는 8Bytes 크기의 Value가 입력되게 된다. 즉, 1000번지부터 1007번지까지의 영역이 Overwrite되는 것이다.
- 따라서, 의도치 않게 y 변수의 값이 바뀌어버릴 수 있다.
- 이때, foo 함수에서 'x = -0.0;'을 수행하면, Linker에 의해 선택된 0x1000번지에 0.0이라는 8Bytes 크기의 Value가 입력되게 된다. 즉, 1000번지부터 1007번지까지의 영역이 Overwrite되는 것이다.
이러한 예시들에서 우리가 얻을 수 있는 교훈은 무엇이 있을까? 이번 Linking 포스팅에서 배울 수 있는 Skill 말이다.
사실, 일단 기본적으로 Duplicate Symbol 상황 자체를 만들지 않아야 한다. ★
그리고, 왠만하면, 프로그래밍 시, Global Variable은 피한다. ★
만약 사용해야한다면, Static Local Variable이나, Initialized Global Variable을 사용하고, 외부 전역 변수 사용 시엔 extern으로 명시해준다. ★
커다란 프로그램을 작성해본 컴퓨터공학도라면 분명 한 번 쯤은 '도무지 에러가 날 상황이 아닌데, 또는 아무리 봐도 모든 코드 부분을 정확히 작성했고 잘 검증했는대도, 이상한 에러가 발생했던 경험'이 있을 것이다. 정말 다 확인했는대도 에러가 발생하는 것이다. 기억나는가? 그리고 매우 높은 확률로, 전역 변수를 지역 변수로 바꿨더니 뜬금없이 해결된 적이 있을 것이다. 기억이 나지 않거나, 눈치채지 못했더라도, 아마 그랬던 순간이 분명 있을 것이다. 그러한 상황이 바로 오늘 배운 Linking 원리에서 비롯된 것이다. 이제는 Linking에 대해 어느 정도 이해가 잡혔으니, 더 이상 그런 실수에 애먹을 일이 없을 것이다. 이것이 바로 우리가 Linking을 배우는 이유인 것이다.
금일 포스팅은 여기까지이다.

와.....linking에 대해서 자세한 내용을 찾고 있었는데, 이것만큼 자세하고 잘 설명되어 있는 블로그가 없네요..! 감사합니다.