우리는 현재 Linking에 대해 학습하고 있다. 우리가 Modular Programming을 할 때, 각 Subprogram별로 Program을 쪼개는 것이다. 한 소스 코드에 다 집어넣지 않는 것이다. 이때, 분리된 소스 코드들을 하나의 실행 파일로 묶는 것이 Linking이었다.
Linking은 두 단계를 거쳐서 이루어진다고 했다. 그 중 Step1인, 'Symbol Resolution'에 대해 알아보았다. 함수 이름, 변수 이름, Type 이름, Keyword 등을 모두 통틀어서 우리는 Symbol이라고 하는데, 이때, Symbol이 겹칠 경우, Linker가 이를 어떻게 Resolve하는지에 대해 알아본 것이다. Symbol이 겹치면, 어떤 Module의 Symbol을 사용할지 결정하는 것이다. 이 과정에서 Strong / Weak Symbol 개념이 등장했다. 초기화되어 있거나 함수명으로 쓰이면 해당 Symbol은 Strong이었다.
이러한 Strong, Weak 개념을 통해 Duplicate Symbol Definitions 상황을 해결했다. 다만, 이때 Subtle & Nasty Run-Time Bug가 발생할 수 있으니, 왠만하면 이를 태초에 방지해야한다는 것 역시 배운 바 있다. 애초에 Programmer가 '잘' 프로그래밍해야하는 것이다.
이전 포스팅 마무리 부분에서 언급한 '컴퓨터공학도가 분명 한 번쯤은 맞이해봤을 에러 상황'은 보통 언제 일어나는지 아는가? 보통, 코드에서 참조하고 있는 Library 내부에 정의된 전역 변수명과 동명의 전역 변수를 선언할 때이다. 우리는 우리가 사용하는 라이브러리 내부를 제대로 확인해본 적이 없지 않은가. 그래서 이런 일이 발생하는 것이다.
이를 방지하기 위해선, 가급적 전역변수를 사용하지 말고, 꼭 사용해야 한다면 초기화를 해 Strong Symbol로 만들어주자는 것이다. Strong이면, 변수명이 겹치는 경우, Link Time Error를 내 미리 에러를 발견할 수 있기 때문이다.
금일 포스팅에서는 아직 제대로 소개하지 않은 Linking Step2, 'Relocation'에 대해 알아보려고 한다. Executable Object Code를 만들 때, Virtual Memory Address Assign을 어떻게 할 것인가에 대한 이야기이다. 아래를 보자.
Relocation
Linker가 Symbol Resolution Step을 마치면, Code의 각 Symbol Reference는 정확히 하나의 Symbol Definition에 대응된다.
Symbol Resolution이 끝나면, Linker는 입력 Object Module들의 Code와 Data Section이 정확히 어떤 Size를 가지는지 알 수 있는 것이다. ★
이제 해야할 일은 Step2인 Relocation이다.
Relocation : 입력 Relocatable Object Module들을 하나의 Executable Object File로 Merge하고, 각 Symbol에 'Run-Time Address를 할당'한다.
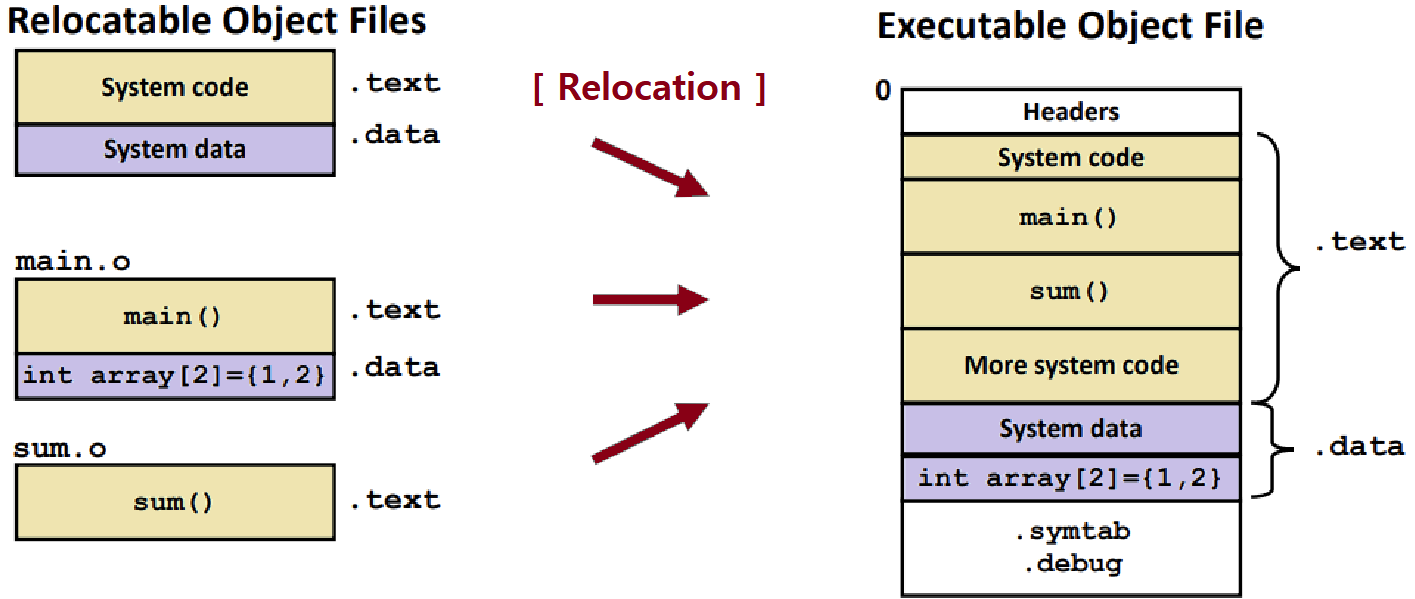
- 엄밀히 표현하면, '전처리-컴파일-어셈블'을 거쳐 생성된 Relocatable Object File들에 대해 Linker가 Symbol Resolution을 수행한 다음, 이어서 Relocation을 수행해 하나의 Executable Object File로 만드는 것이다. ★★★
Relocation Entry
-
Assembler가 Assemble을 통해 Relocatable Object Module을 만들었을 때의 시점을 보면, 이때는 아직 Code와 Data가 궁긍적으로 Memory의 어떤 위치에 저장되는지를 알지 못한다. ★
- 각 Module의 .text와 .data 정보가 메모리 어디에 올라갈지를 모른다는 것이다.
-
또한, 어떤 Module이 다른 '외부 정의 함수 및 전역 변수'를 사용할 때, 이들이 어디에 위치하는지도 알지 못한다.
- 위 그림을 예로 들면, main.o에서 sum.o의 sum 함수가 어디에 있는지를 모른다는 것이다.
따라서, 'Assembler'는 '궁극적 위치(Ultimate Location)가 알려지지 않은 Object'에 대한 Reference를 맞이하면, 이에 대해 'Relocation Entry'를 만들어, Linker에게 'Executable Object File 만들 때 어떻게 Modify해야하는지'를 알려준다. ★★★
즉, Relocation Entry는 Linker가 아니라 Assembler가 Assemble할 때 만든다. ★★
"Linker야, 내가 얘네들 주소 모르니까, 너가 Executable File 만들 때, 얘네 주소 좀 이런 식으로 명시해주라."라고 부탁하는 것이다.
- 앞선 포스팅에서, .rel.text.와 .rel.data. Section에 각각 Code와 Data에 대한 Relocation 정보가 들어있다고 했다.
- 여기서 말하는 'Relocation 정보'가 바로 'Relocation Entry'들이다. ★★
아래와 같은 간단한 C Source Code가 있다고 하자.
int arr[2] = {1, 2};
int main(void) {
int val = sum(arr, 2);
return val;
}이 .c File을 '전처리-컴파일-어셈블'하면, 다음과 같은 Linking 이전 코드가 생성된다(이 코드는 참조 교재에서 상정한 예시 코드이다).
0000000000000000 <main>:
0: 48 83 ec 08 sub $0x8,%rsp
4: be 02 00 00 00 mov $0x2,%esi
9: bf 00 00 00 00 mov $0x0,%edi # %edi = &arr (주소)
a: R_X86_64_32 arr # Relocation entry
e: e8 00 0 0 00 00 callq 13 <main+0x13> # sum() 함수 호출
f: R_X86_64_PC32 sum-0x4 # Relocation entry
13: 48 83 c4 08 add $0x8,%rsp
17: c3 retq- arr 주소값은 edi Register에 들어간다.
- sum 함수 호출을 위해 sum 함수의 위치도 알아야 한다.
위 코드를 Linker가 Relocation하면, 다음과 같이 변화한다. 'Relocated .text Section'이다.
00000000004004d0 <main>:
4004d0: 48 83 ec 08 sub $0x8,%rsp
4004d4: be 02 00 00 00 mov $0x2,%esi
4004d9: bf 18 10 60 00 mov $0x601018,%edi # %edi = &array
4004de: e8 05 00 00 00 callq 4004e8 <sum> # sum()
4004e3: 48 83 c4 08 add $0x8,%rsp
4004e7: c3 retq
00000000004004e8 <sum>:
4004e8: b8 00 00 00 00 mov $0x0,%eax
4004ed: ba 00 00 00 00 mov $0x0,%edx
4004f2: eb 09 jmp 4004fd <sum+0x15>
4004f4: 48 63 ca movslq %edx,%rcx
4004f7: 03 04 8f add (%rdi,%rcx,4),%eax
4004fa: 83 c2 01 add $0x1,%edx
4004fd: 39 f2 cmp %esi,%edx
4004ff: 7c f3 jl 4004f4 <sum+0xc>
400501: f3 c3 repz retq-
이 코드에서 Relocation은 어떻게 수행할까?
- Computer Architecture에서 배운 PC-Relative Addressing을 적용한다.
ex) sum()의 Relocated Address
0x4004e8 = 0x4004e3 + 0x5 ★★★
-
sum은 0x4004e8 위치의 명령부터이다.
- 이 위치는 sum을 call한 명령 '다음 명령 위치(0x4004e3)'를 기준으로 5바이트 이후이다.
- 따라서, 0x4004e3에 0x5를 더하면 sum의 시작 위치가 나온다.
- 이 위치는 sum을 call한 명령 '다음 명령 위치(0x4004e3)'를 기준으로 5바이트 이후이다.
-
<main> 내부에서, 0x4004de 위치에, '05 00 00 00'이란 정보가 있다. 이것이 바로, call 다음 명령 위치인 0x4004e3부터 0x5만큼을 더하면 된다는 것을 의미한다. ★
- 더한 결과인 0x4004e8이 callq 명령 우측에 나타난다. ★
-
sum의 첫 번째 라인 수행해야 할 때, 기존 PC는 0x4004e3을 가리키는데, 여기서 5만큼을 더하면 sum 라인이 나온다는 의미이다. ★
Relocation은 이렇게 수행된다. Assembler가 알려주는 Relocation Entry를 토대로 Linker가 가상 메모리 주소를 할당해주는 것이다. ★
Loading
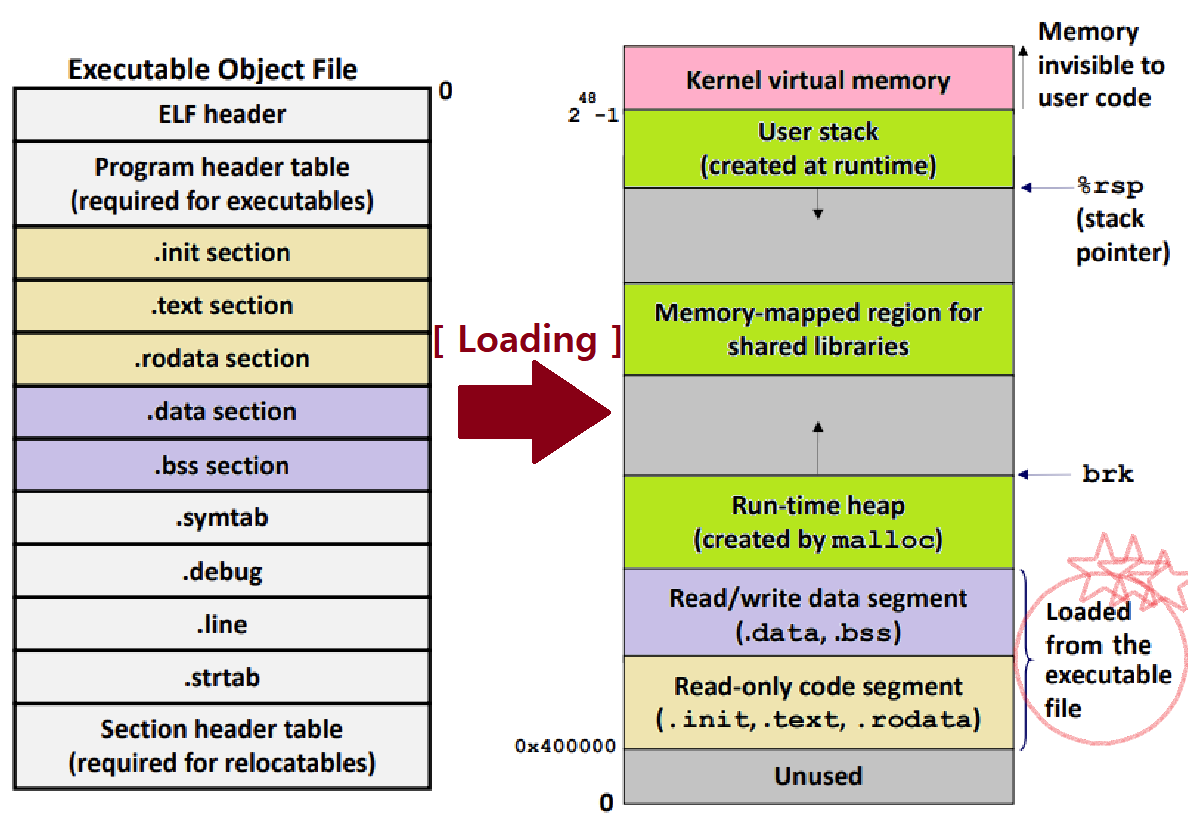
위와 같이 Relocation이 수행되면, ELF 형식의 Executable Object File이 만들어진다. 이 File이 Memory에 올라가게 되면, 아래 그림과 같이 Virtual Memory 형식을 갖추게 된다. Data, Code, Heap, Stack Segment가 마련되고, Heap은 brk까지, Stack은 맨 위에서부터 내려오는 방식으로 할당된다.
-
Executable Object File의 .init, .text, .rodata, .data, .bss Section만이 실제 Memory에 Loading된다는 점에 주목하자. ★
- 나머지는 Linking에서만 사용된다. ★★
-
ELF의 .init, .text, .rodata Section은 Program의 Code Segment를 이룬다. ★★★
-
ELF의 .data, .bss Section은 Program의 Data Segment를 이룬다. ★★★
-
나머지 Program Virtual Memory 영역의 Heap, Stack, MMAP Segment는 모두 Run-Time에 관리된다. ★★
- Stack은 Run-Time에 Dynamic하게 할당되고 해제된다.
- Heap 역시 Run-Time에 Dynamic하게 할당되고 해제된다.
- 다만, 얘는 Programmer가 Explicit하게 운영하는 것 (C 기준)
-
Memory-Mapped Segment : Run-Time에 Library Linking 시 사용하는 API들에 대해, 그들의 주소값을 맵핑하는 공간이다. (mmap)
Library(Packaging)
알다시피, Programmer는 자신이 자주 사용하는 함수들을 Library 형태로 묶을 수 있다. 이 역시 Linker 덕분에 할 수 있는 일이다.
"자주 사용하는 함수들을 프로그래머가 어떻게 묶을 수 있을까?"
-
방법1) 모든 '자주 사용하는 함수'들을 하나의 Source File로 묶는다.
- 가장 Naive한 옵션이다. 프로그램에 커다란 Object File을 Link하는 것이다.
- 당연히, 공간적으로나, 시간적으로나 Inefficient하다.
-
방법2) 각 함수를 기능/용도별로 Separate한 Source File로 묶는다.
-
Programmer가 프로그램에 적절한 함수들만 명시적으로 Link한다.
-
당연히, 방법1보다 효율적이다. 다만, 프로그래머가 할 일이 좀 더 많아진다.
-
Static Linking과 Dynamic Linking이 있다.
-
Static Library(Static Linking)
이후 소개할 'Shared Library' 방식에 비해 구식의 방식이다.
-
Static Libraries
-
관련된 Relocatable Object File들을 하나의 Single File로 모조리 Concatenate한다.
- 이 Single File을 Archive라고 부른다.
- .a archive File
- Index를 사용한다.
- 이 Single File을 Archive라고 부른다.
-
Archive 내의 Symbol들을 이용해 Program의 Unresolved External Reference들을 모두 Resolve한다. ★★
- Archive를 통해 Resolution이 끝나면, Linker가 Executable File로 만든다. ★
-
-
쉽게 말해서, main.o에서 사용하는 sum.o, average.o와 같은 모듈들을 모조리 하나에 Concatenate해서 아카이브화하는 것이다. by Archiver Utility
- 필요한 라이브러리를 아카이브로 쫘악 모아놓고, 거기서 필요한 함수들을 링킹하는 것이다. ★

-
Archiver는 Incremental Update를 지원한다.
-
함수에 변화가 생겨 Recompile하고자 할 때는 Archive 내의 .o File을 교체한다. ★
-
위 그림에서 예시로 든 libc.a 아카이브는 실제 'C Standard Library'이다.
- 1496개의 Object File을 모아 만들어진 4.6MB 크기의 아카이브이다.
- I/O, 메모리 할당, 시그널 핸들링, 문자열 처리, Time, 난수, 수학 관련 기능들이 모두 포함되어 있다. ★
-
libc.a 외에도 libm.a 아카이브도 유명하다. C Math Library이다.
- 444개의 Object File을 모아 만들어진 2MB 크기의 아카이브이다.
- 실수 관련 함수들이 모여있다.
-
libc.a와 libm.a는 Shell에서 실제로 확인해볼 수 있다.
- 'ar -t libc.a | sort' Command를 입력해보자.
Simple Example
Static Linking을 이용해서 나만의 라이브러리를 만들어보자. Vector 연산을 수행하는 기능들을 묶어보는 것이다.
/* main.c */
#include <stdio.h>
#include "vector.h" // 이하의 .c 파일들에 대해 헤더파일을 만들었다고 가정
int x[2] = {1, 2};
int y[2] = {3, 4};
int z[2];
int main(void) {
addvec(x, y, z, 2);
printf("z = [%d %d]\n”, z[0], z[1]);
return 0;
}
/* addvec.c */
void addvec(int *x, int *y, int *z, int n) {
int i;
for (i = 0; i < n; i++)
z[i] = x[i] + y[i];
}
/* multvec.c */
void multvec(int *x, int *y, int *z, int n) {
int i;
for (i = 0; i < n; i++)
z[i] = x[i] * y[i];
}위의 C 코드 파일이 있다고 가정하자. 이제 Shell에서 'ar rs libvector.a addvec.o, multvec.o' Command를 입력해서 Static Linking을 수행한다.
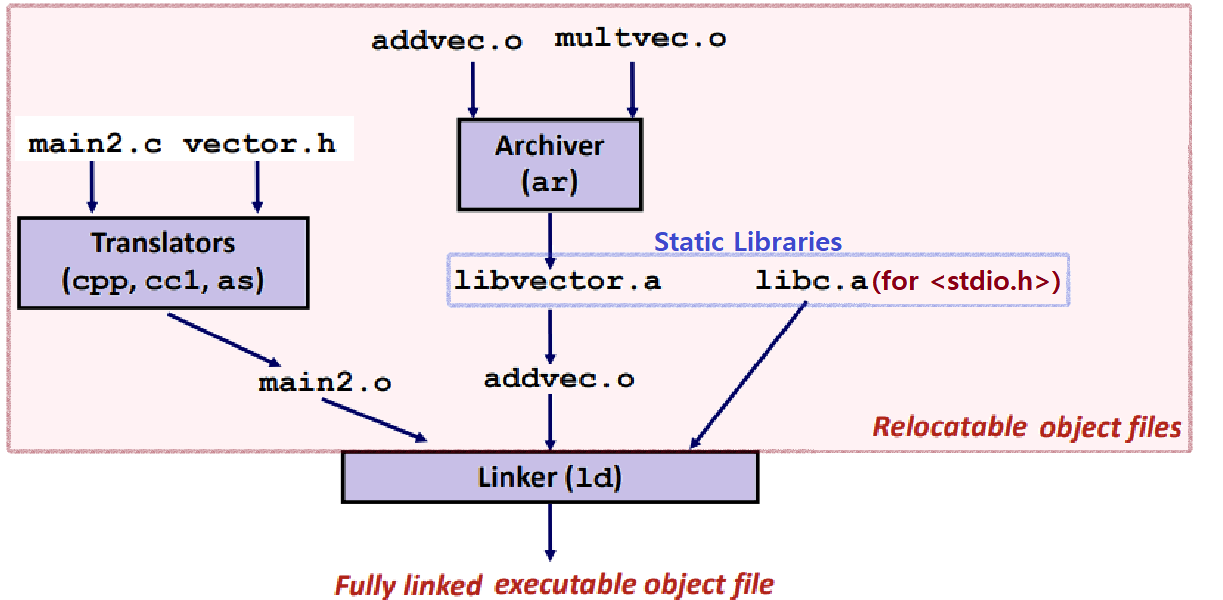
- 하나의 Executable Object File에 main2.o, libvector.a, libc.a가 모두 Fully Link되어 있는 것이다. ★
- 당연히 Compile Time에 이 일이 수행된다.
Scanning Algorithm
Static Linking 시 Linker가 수행하는 Algorithm은 다음과 같다.
1) 입력으로 들어오는 .o, .a 파일을 모두 Scan한다.
2) Scan할 때, 현재 Unresolved Reference를 모두 찾아내어 List화한다.
3) List의 각 Unresolved Reference들을 모두 Resolve한다. Object File 내의 Symbol Definition에 의거해 말이다.
4) 하나라도 Unresolved Reference가 남아있게 되면, 그것은 에러이다.
Disadvatages
Static Linking 시에는 Command Line의 Order가 중요하다.
Static Linking 시, 라이브러리 파일을 반드시 라인 끝에 기입해야한다. ★
unix> gcc -L. main2.o -libvector # 에러 x, 정상 수행
unix> gcc -L. -libvector main2.o # 에러 o
main2.o: In function `main':
main2.o(.text+0x4): undefined reference to `addvec'- Program인 main2.o를 쭉 훑다가, addvec 함수 호출이 있으면, 대응 코드를 libvector에서 찾으면 된다.
- 이때, gcc -L에 입력하는 순서가 뒤집히면, 즉, 라이브러리를 먼저 기입하면, 라이브러리를 먼저 뒤지게 된다.
- 두 번째 Command를 보면, libvector를 먼저 뒤지고, 그 다음 main2.o를 훑게 된다. main2.o에서 addvec이 없으니 찾아야하는데, 찾을 대상인 libvector를 이미 먼저 훑었기 때문에 더 이상 찾을 대상이 없어서 에러가 난다. ★★★
- 이때, gcc -L에 입력하는 순서가 뒤집히면, 즉, 라이브러리를 먼저 기입하면, 라이브러리를 먼저 뒤지게 된다.
-
Static Linking에선 이처럼, 링킹 순서에 따라 에러가 발생할 수 있는 위험성이 존재한다.★
-
또한, Static Linking은 Duplication을 반드시 Stored Executable Object File에 삽입해야하기 때문에 공간적인 비용도 높다. ★★
- 또한, Duplication을 반드시 Running Executable Object File에 삽입해야하는 문제도 존재한다. (Object File에 삽입해야한다는 것이 핵심)
- ex) 만약, 위의 그림 예시에서, main3.o라는 오브젝트 파일이 하나 더 있고, 여기도 addvec을 사용한다고 하면, main2.o와 main3.o가 같은 addvec에 대해 각각 복사/저장하고 있어야하는 것이다. (Static Linking의 가장 큰 단점) ★★★
- 또한, Duplication을 반드시 Running Executable Object File에 삽입해야하는 문제도 존재한다. (Object File에 삽입해야한다는 것이 핵심)
-
또한, 일부 라이브러리에 변형이 생기면, 관련된 Application들을 모두 다 명시적으로 Relink해야한다. 아주 소모적인 것이다. ★★
고전적인 Static Linking은 상기한 문제점들이 있기 때문에 아래의 Dynamic Linking 방식이 도입되었다.
Shared Library(Dynamic Linking)
Dynamic Linking : Code와 Data를 포함하고 있는 Object File이 Application에 Load Time 또는 Run Time에 Dynamic하게 Link된다. ★
- Dynamic Linking에서 사용하는 라이브러리를 'Shared Library' 또는 'Dynamic Link Library, DLL'이라고 부른다.
- 앞전 포스팅에서 소개한 .so File이 바로 여기에 해당한다. ★
- Load Time : Dynamic Linking은 Executable Object File이 처음 Load될 때 수행될 수 있다.
- Linux에서 보통 이 방식을 채택한다. by 'Dynamic Linker'
- Standard C Library 'libc.so'가 보통 이렇게 Dynamic Linking된다.
- Run Time : Dynamic Linking은 Program이 아예 시작하고 나서 수행될 수도 있다.
- Linux에선, dlopen()이란 인터페이스를 이용해 이 기능을 사용할 수 있다. ★
- 이 방식은 웹 서버에서 좋은 성능을 보인다.
- 추후 소개할 Interpositioning과도 연관된다. ★
- Linux에선, dlopen()이란 인터페이스를 이용해 이 기능을 사용할 수 있다. ★
- Shared Library는 복수의 프로세스들이 공유할 수 있다.
- 굳이 각 프로그램 코드에 복사해놓지 않아도 말이다.
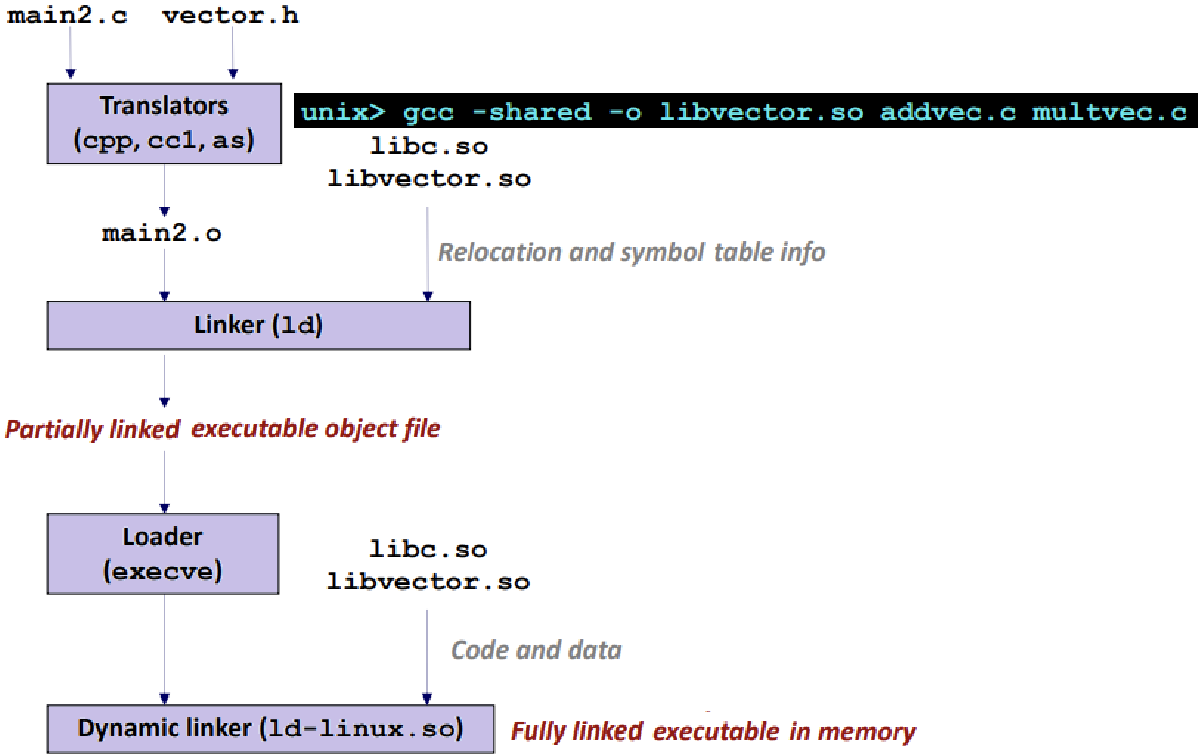
-
Static Linking 시에는 모든 라이브러리(아카이브, libvector, addvec,...)를 그대로 다 Linker에 입력해 한 번에 Fully Link를 수행했다.
-
반면, Dynamic Linking 시에는, Linker에게 각 공유 라이브러리의 "얘들을 사용할거다."라는 정보만 Executable Object File에 기록한다. ★★★
- 그래서 Partially Linked라고 하는 것이다. ★
-
이후, 실제 Load Time에 Dynamic Linker와 Shared Library를 이용해 Real Linking이 수행되는 것이다. ★
-
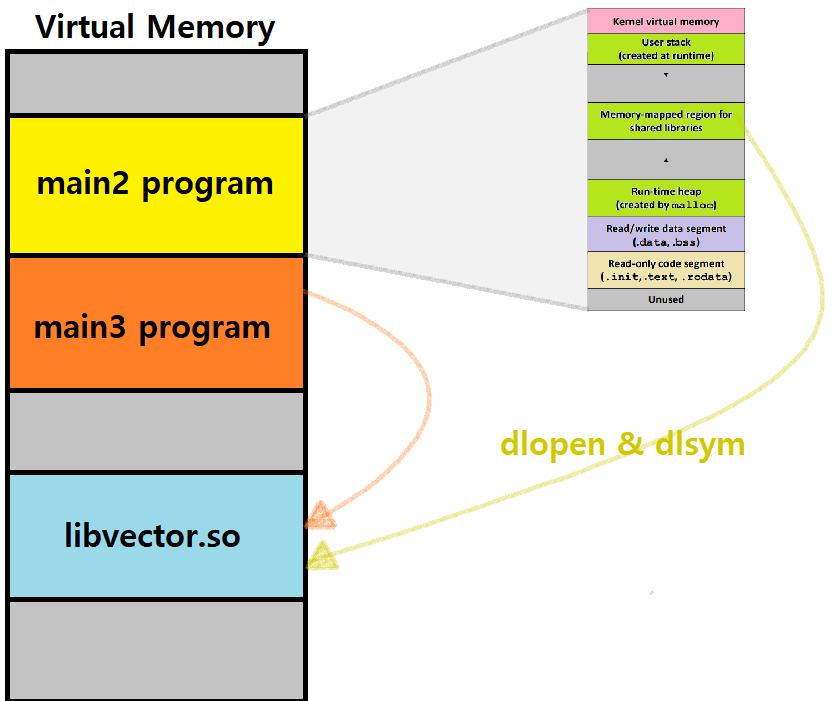
main3.o가 있다고 하면, Static Linking 시에는 main2.o와 main3.o 모두에 사용하는 함수 코드를 똑같이 복제해야하는데, Dynamic Linking 시에는 '사용할 것이란 정보'만 기록하면 되는 것이다. 이후 실제 Load / Run 시에 링킹하는 것이다. ★
Static Linking은 Copy, Dynamic Linking은 Reference이다. ★★★
Run-Time Dynamic Linking
앞서, Run Time Dynamic Linking에는 dlopen이란 인터페이스가 사용된다고 했다. 이를 'On-Demand' 방식이라 하는데, '그때 그때 필요에 따라서 프로그램 실행 중간에 링킹함'을 의미한다. (Load Time 방식은 Code Reference를 Loading 시에 수행하는 것) ★★★

- 프로그램의 가상 메모리 영역에서 Memory-Mapped Segment가 Dynamic Linking에 관여한다고 했는데, 이것이 그림에 표현되어 있음을 주목하자. ★
Simple Example (Run-Time)
간단한 Run-Time Dynamic Linking 수행 프로그램을 확인해보자.
#include <stdio.h>
#include <stdlib.h>
#include <dlfcn.h>
int x[2] = {1, 2};
int y[2] = {3, 4};
int z[2];
int main(void) {
void *handle;
void (*addvec)(int *, int *, int *, int); // 포인터를 받을 것 ★
char *error;
/* addvec()을 포함하고 있는 libvector Shared Library를 동적으로 Load */
handle = dlopen("./libvector.so", RTLD_LAZY);
if (!handle)
unix_error(dlerror()); // Wrapper
/* ... */
/* 해당 라이브러리 내의 addvec 함수에 대한 포인터를 받는다. */
addvec = dlsym(handle, "addvec");
if ((error = dlerror()) != NULL)
unix_error(error);
/* 이제 자유롭게 addvec 함수를 사용할 수 있다! */
addvec(x, y, z, 2);
printf("z = [%d %d]\n", z[0], z[1]);
/* Shared Library를 Unload하는 Routine */
if (dlclose(handle) < 0)
unix_error(dlerror());
return 0;
}~> 위와 같이 코드를 작성해서 사용할 수 있다. dlopen으로 Shared Library를 Load하고, dlsym으로 Target Function을 포인팅하는 방식을 잘 기억해두자. ★
금일 포스팅은 여기까지이다.
