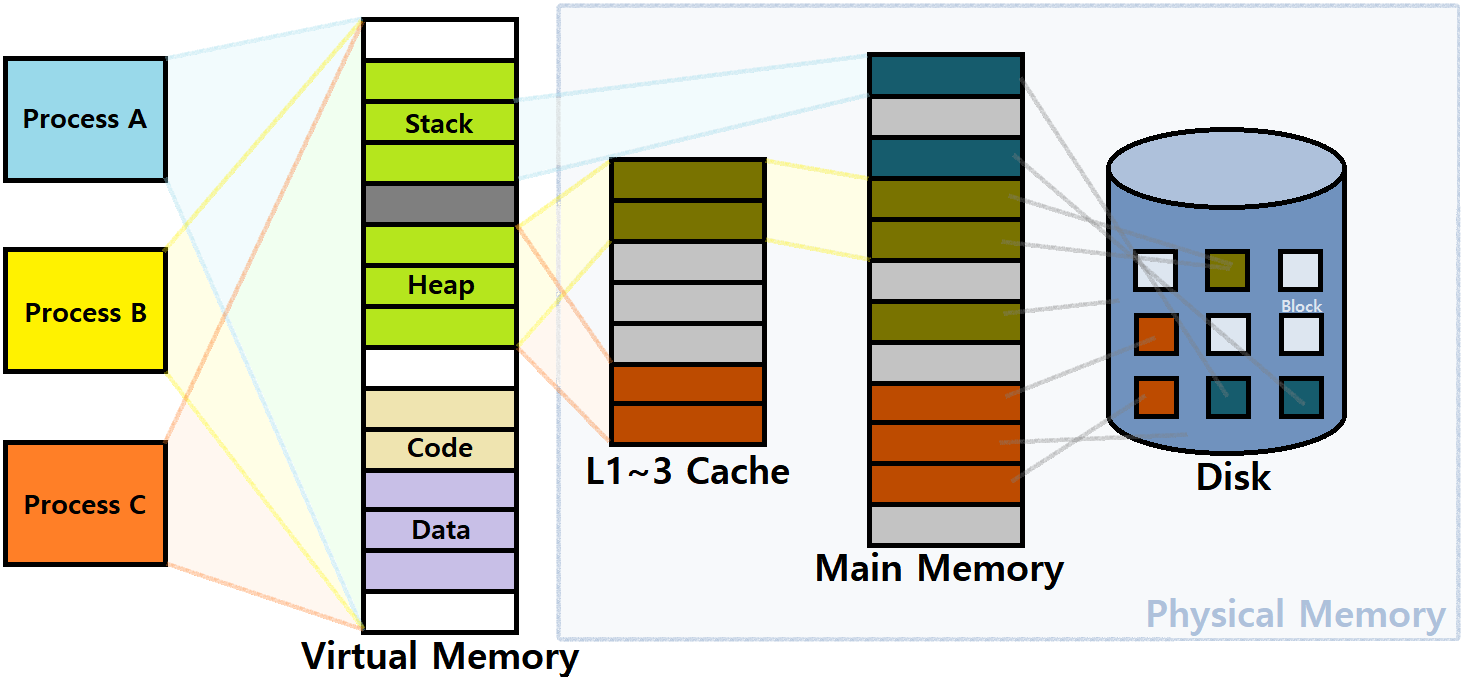
대망의 System Programming 연재 마지막 포스팅이다. 마지막 개념은 그동안 계속 언급만 해왔던 Virtual Memory이다. 이는 Computer Architecture를 공부했다면 어느정도 이미 알고 있을 수 있는 내용이지만, SP 연재가 끝나면 새롭게 진행할 예정인 'OS(운영체제)' 연재를 미리 간단히 준비하고자, 본 포스팅을 통해 간단히 다뤄보고자 한다. 너무 Deep하게 다루진 않을 것이다.
Address Space
"System에서 Process가 보는 Address Space는 무엇인가?"
이 질문에 대한 답에 따라 System을 크게 두 가지로 분류할 수 있다.
-
Process가 보는 Address Space가 Physical Address Space인 System
-
Embedded Microcontroller가 대표적이다. 자동차, 엘리베이터 등에 들어가는 소형 CPU를 생각하면 된다.
- CPU가 메인 메모리에 접근할 때, CPU가 Addressing하는 주소는 Physical Address이다.
-
즉, 가상 메모리를 지원하지 않는 시스템이 모두 여기에 들어간다.
-
- Process가 보는 Address Space가 Virtual Address Space인 System
-
일반적인 현대식 컴퓨터가 모두 해당한다.
-
CPU가 메인 메모리에 접근할 때, CPU가 Addressing하는 주소는 Virtual Address이다.
-
물론, 실제 메모리는 당연 Physical Address이다.
CPU에 들어있는 MMU(Memory Management Unit)가 Virtual Memory to Physical Memory 변환을 수행한다.
-
-
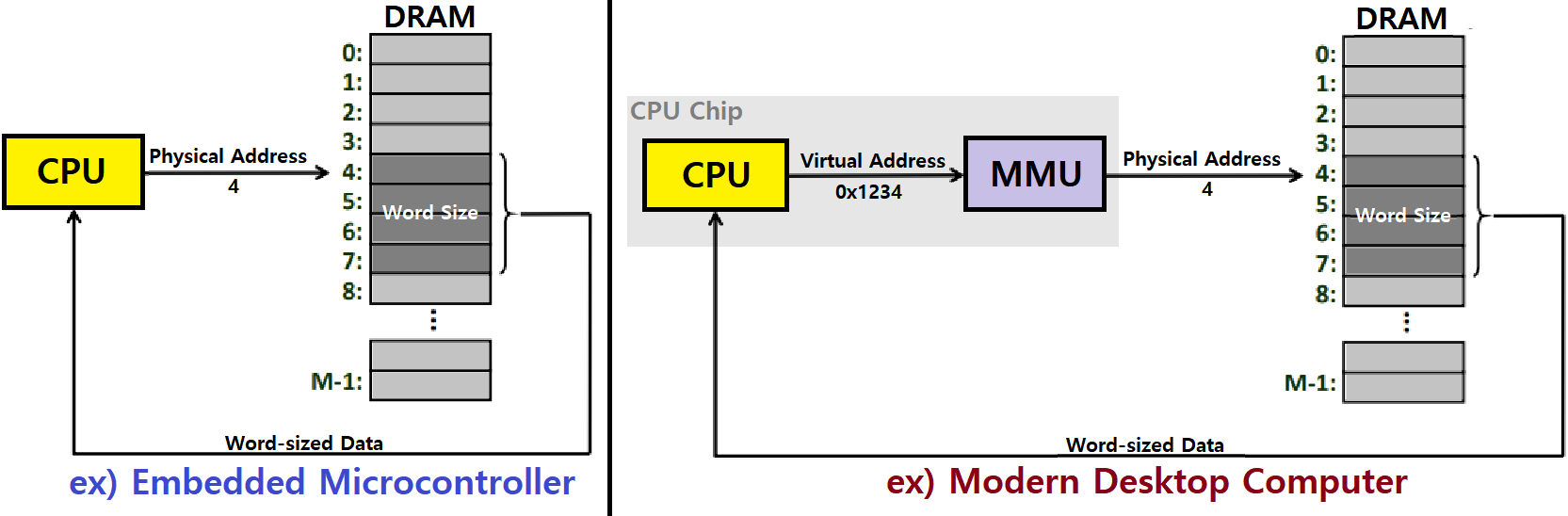
- 우측 Modern Desktop Computer를 보면, 1234번지라는 가상 메모리 주소가 4라는 물리 메모리 주소로 변환되고 있다.
- 누구에 의해서? 그렇다. MMU에 의해서!
Address Space는 아래와 같이 크게 세 가지 유형으로 분류할 수 있다.
-
Linear Address Space : 연속적인 Non-Negative Integer Address로 이루어진 'Ordered Set'이다.
- {0,1,2,3,4,...}
-
Virtual Address Space : 우리가 몇 비트로 가상 주소를 표현하느냐에 따라 범위가 달라진다. n-Bits라 하면, 2^n 크기의 가상 메모리 주소가 마련된다.
- {0,1,2,3,4,...,n-2,n-1}
- n-Bits!
- {0,1,2,3,4,...,n-2,n-1}
-
Physical Address Space : 우리가 몇 비트로 물리 주소를 설계하느냐에 따라 범위가 달라진다. m-Bits라 하면, 2^m 크기의 물리(실제) 메모리 주소가 마련된다.
- {0,1,2,3,4,...,m-2,m-1}
- m-Bits!
일반적으로 Virtual Memory가 Physical Memory보다 크기가 크게 설정된다.
n > m
- {0,1,2,3,4,...,m-2,m-1}
Virtual Memory
Why? (Advantages of VM)
그냥 Linear Address로 간편하게 사용하면 될 것을, 왜 굳이 Virtual과 Physical로 Memory를 구분하는 것일까? Virtual Memory를 도입함으로써 우리가 얻을 수 있는 이득이 무엇일까?
- Main Memory를 효율적으로 사용할 수 있다.
- DRAM을 효과적으로 사용할 수 있다. 무슨 말이냐면, 가상 주소의 일부만 DRAM에 올린다는 것이다. ★
- Process는 가상 메모리 영역으로 'Data-Code-Heap-Stack' Segments를 가진다고 했다. Program이 Memory에 Load되어 Process가 됐다고 해보자. 과연 이 Process는 얼마만큼의 메모리 공간을 접근할 것인가? 그렇다. 생각보다 그리 많은 공간을 점유하진 않을 것이다. Virtual Memory를 도입하면, Process에 대한 Memory 영역을 가상 메모리 영역으로 잡고, 그 중 실제로 사용할 (것 같은) 녀석들만, 즉, 일부만 Main Memory에 올리는 것이다.
Process에 대한 모든 메모리 영역을 Main Memory에 올리는 것은 공간 효율 관점에서 비효율적이다.
즉, DRAM을 낭비하지 말고, 필요한 것들만 올리자는 것이다.
DRAM(Main Memory)을 마치 Virtual Memory에 대한 Cache처럼 사용하는 것이다. 나머지 '덜 중요한' 부분은 Disk로 올리는 것이다. ★★★★★
- DRAM을 효과적으로 사용할 수 있다. 무슨 말이냐면, 가상 주소의 일부만 DRAM에 올린다는 것이다. ★
- Memory Management를 간소화할 수 있다.
- 모든 Process가 동일한(Uniform) Linear Address Space를 가질 수 있게 만들어준다. 모두가 동일한 크기와 순서의 메모리 공간을 상상할 수 있게 하는 것이다. ★★★
- 만일, VM이 없다면, 각 프로세스가 서로 다른 시각을 가져야한다.
- 모든 Process가 동일한(Uniform) Linear Address Space를 가질 수 있게 만들어준다. 모두가 동일한 크기와 순서의 메모리 공간을 상상할 수 있게 하는 것이다. ★★★
- Address Space를 Isolate할 수 있다. 즉, 어떤 Process가 다른 Process의 메모리 영역을 침범할 수 없다. ★
- 마찬가지로, Application이 Kernel Information과 Kernel Code 부분을 접근할 수 없게 할 수 있다. ★
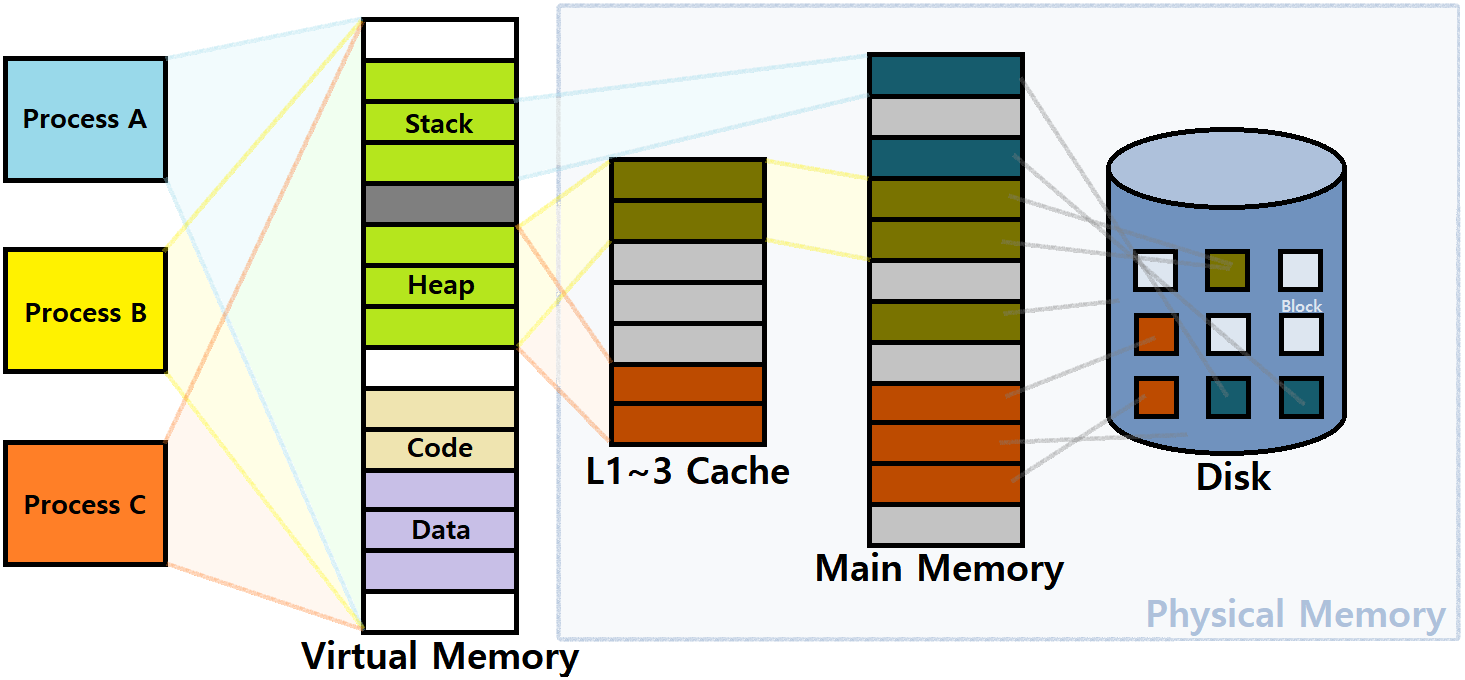
Caching Purpose
VM을 Caching을 위한 Tool로 바라볼 수 있다. Process가 실제 Memory에 올라가고 구동되면, 개념적인 관점에서 Virtual Memory는 N개의 연속된 Byte Array이다.
-
Process가 바라보는 '전체 Virtual Memory'는 Disk에 Load된다. (당연)
- 이러한 Virtual Memory는 모든 Process에 대해 일일이 존재한다고 했다.
-
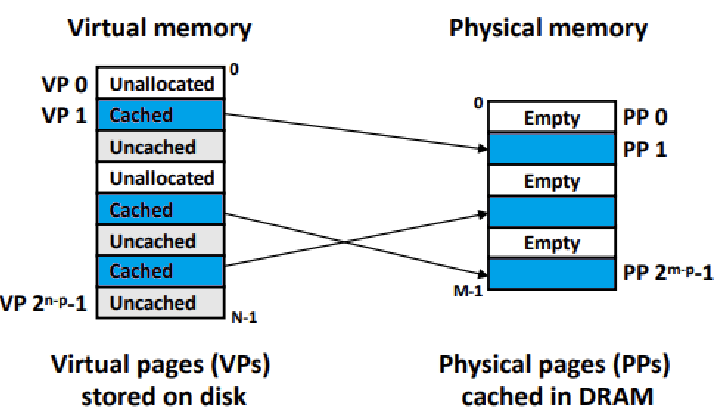
Disk에 있는 데이터 중 일부(Important Data)는 DRAM, Main Memory에 올라가는 것이다.
- 정확히는, Virtual Page 중 Active Page들만 Main Memory로 올라가는 것이다. ★
즉, Main Memory가 마치 Virtual Memory에 대한 Cache처럼 작용하는 것이다. ★
-
위 그림에서, 각 네모칸은 Page이다. 보통 이 Page는 4KB나 8KB 정도로 잡는다.
- 가상 메모리는 이러한 Page들의 연속된 배열이다.
-
Physical Memory 역시 마찬가지로 Page 단위로 구성된 배열이다.
- Virtual Page와 Physical Page가 Mapping된다. ★★★
Virtual Memory의 일부 Page들이 Cached로서, Main Memory에 올라가는 것이다.
이러한 관점에서, Main Memory, 즉, Physical Memory를 DRAM Cache라고 부른다. ★
Architectural View
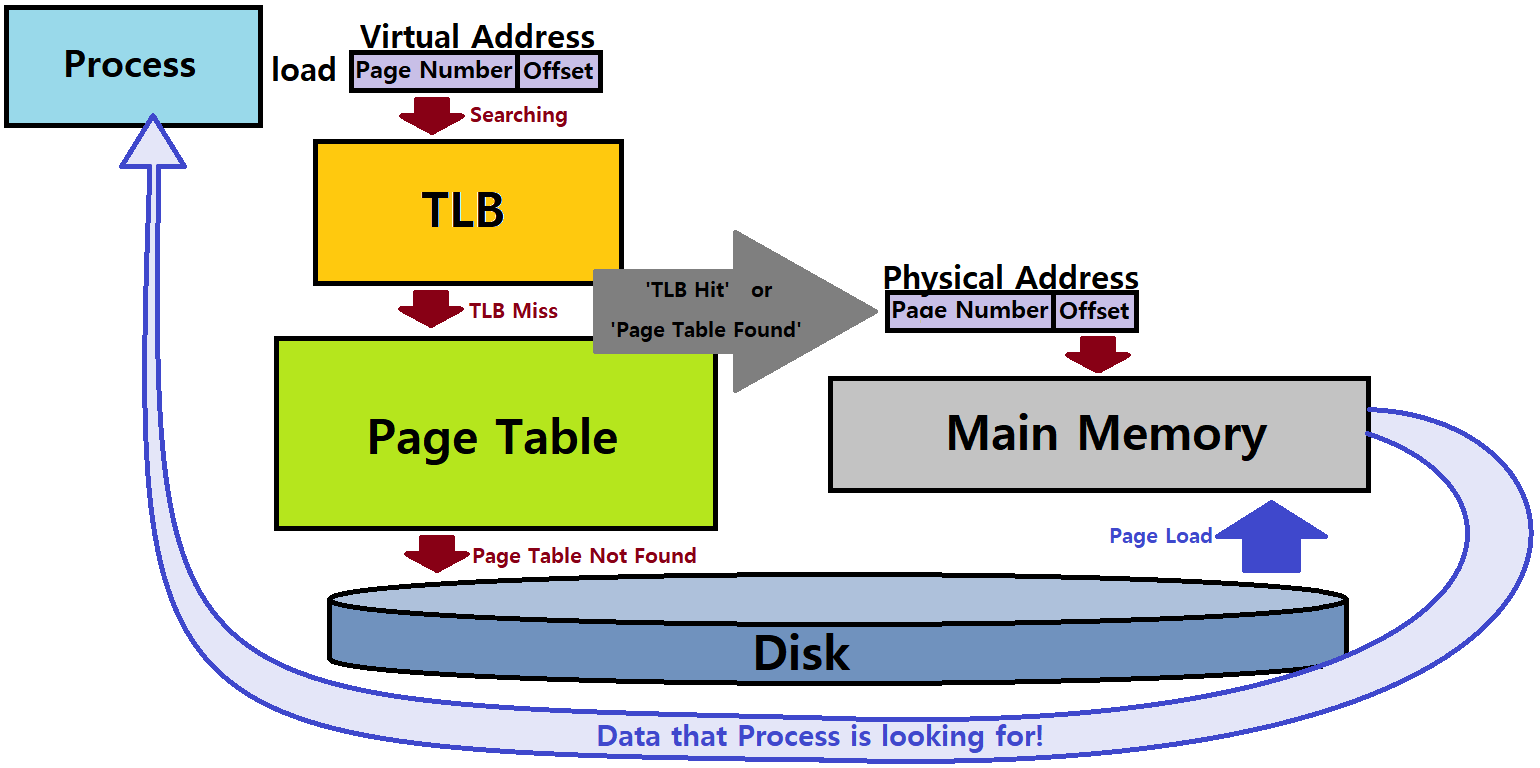
- 프로그램이 특정 데이터에 접근할 때, 가상 메모리 주소를 확인한다.
- 이 가상 메모리 주소를 'Page Number'와 'Offset'으로 쪼갤 수 있다.
-
Page Number를 기준으로, TLB(Translation Lookaside Buffer)를 확인한다. TLB는 Page Table에 대한 Cache이다.
-
TLB Hit를 하면, 즉, TLB에서 찾고자 하는 Page Number를 찾으면, 이를 토대로 변환하여 Physical Memory Address를 얻는다.
- Data가 Load된다!
-
TLB Miss를 하면, 즉, TLB에 찾고자 하는 Page Number가 없으면, Page Table을 훑는다. 여기서 Target Page Number가 발견되면, 이를 토대로 변환하여 Physical Memory Address를 얻는다.
- Data가 Load된다!
-
Page Table에도 Target이 없으면, 이는 초반 포스팅에서 언급했던 'Page Fault'이다.
- Secondary Memory인 Disk에서 찾고자 하는 Data를 추출해 Main Memory, DRAM으로 Load한다.
- 이 New Physical Address를 기반으로 Page Table, TLB를 LRU 등의 Replacement 기법을 적용해 업데이트한다.
- Fault를 야기한 Instruction을 다시 수행해 Data를 Fetch한다.
- Data가 Load된다!
- Fault를 야기한 Instruction을 다시 수행해 Data를 Fetch한다.
- 이 New Physical Address를 기반으로 Page Table, TLB를 LRU 등의 Replacement 기법을 적용해 업데이트한다.
- Secondary Memory인 Disk에서 찾고자 하는 Data를 추출해 Main Memory, DRAM으로 Load한다.
-
-
- 이 가상 메모리 주소를 'Page Number'와 'Offset'으로 쪼갤 수 있다.
(여기서, TLB고, Page Table이고, 이런 개념이 중요한 것이 아니다. 이는 Computer Architecture에서 배우는 내용이다. 중요한 것은, DRAM이 Virtual Memory의 Cache처럼 작용하고 있는 점이 중요하다. aka 'DRAM Cache' ★★★)
DRAM Cache
DRAM Cache, 줄여서 DRAM은 SRAM(for 'Real(General)' Cache)보다 10배 느리다. 그리고 Disk는 이러한 DRAM보다 10,000배 느리다.
-
DRAM의 각 Page(Block)는 일반적으로 4KB 크기를 가진다.
- Virtual Page 역시 마찬가지로, 같은 크기를 가진다.
-
Fully Associative : Virtual Page를 Physical Page로 Mapping할 때, Fully Associative 방식으로 맵핑된다.
- Virtual Page가 어떤 Physical Page에도 맵핑될 수 있다. (Fully Associative) ★
- Large Mapping Function이 필요하다.
- VP가 어떤 PP에 맵핑되는지를 관장함.
- Large Mapping Function이 필요하다.
- Virtual Page가 어떤 Physical Page에도 맵핑될 수 있다. (Fully Associative) ★
-
Cost가 높은, 정교한(Sophisticated) Replacement Algorithm이 필요하다.
- Disk에서 새로운 데이터를 Fetch하고자 하는데, DRAM이 꽉차 있으면, 어떤 Page를 Evict할 지 특정 알고리즘을 토대로 결정한다. ex) LRU(Least Recently Used), MRU, etc.
- Expensive! ~> 그래서 HW적으로 구현함. Overhead를 최대한 낮추고자!
- Disk에서 새로운 데이터를 Fetch하고자 하는데, DRAM이 꽉차 있으면, 어떤 Page를 Evict할 지 특정 알고리즘을 토대로 결정한다. ex) LRU(Least Recently Used), MRU, etc.
-
Write-Through 방식 대신 Write-Back 방식이 사용된다. (Synchronization)
- Write 시 Cache만 Update하고, 나중에 Cache의 Page를 Evict할 때, Dirty Bit를 확인해 수정 유무를 판단 후, 수정이 있는 Page만 Disk에 Update한다.
DRAM과 Disk(or Virtual Memory) 관계, L3 Cache와 DRAM 관계, Li-1 Cache와 Li Cache 사이에서 위의 개념이 모두 공통적으로 적용된다(Associativity 제외). 자세한 Detail은 SP에서는 다룰 이유가 없다. 가볍게 읽어가라. ★★★
Page Table
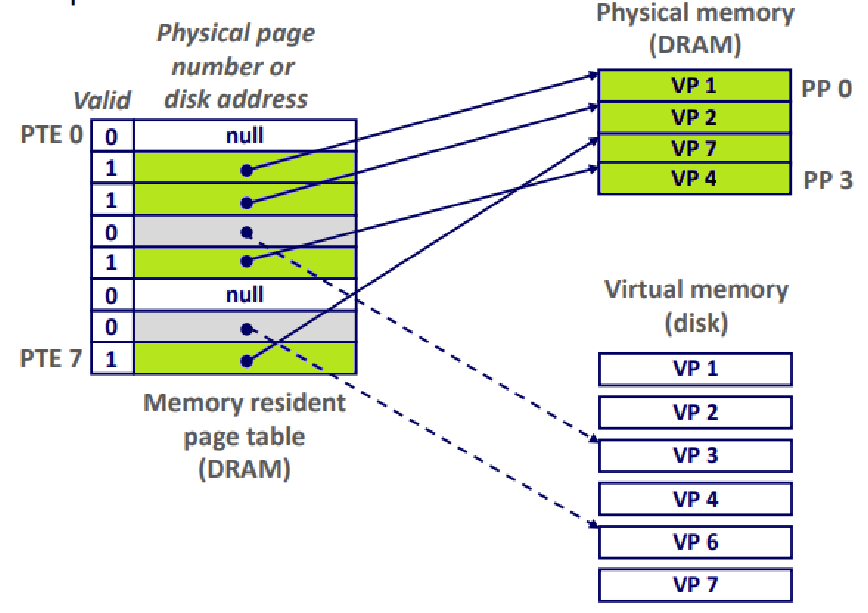
Page Table은 'PTE(Page Table Entry)'로 구성된 배열로, Virtual Page를 Physical Page에 맵핑하는 역할을 수행한다.
- Page Table은 Process마다 DRAM에 자료구조로서 존재한다. ★
- OS가 이를 관리한다. (in Kernel Context)
- 프로그램이 10개가 돌아가고 있으면, 그들에 대응하는 10개의 Page Table을 가지고 있는 것이다. ★
- OS가 이를 관리한다. (in Kernel Context)
-
가상 메모리를 물리 메모리로 맵핑하는 Mapping Function이 있다고 위에서 언급했다. 그 역할을 수행하는 것이 바로 Page Table인 것이다.
-
"Page Table is a Translator!"
-
어떤 Virtual Page가 어떤 Physical Page와 Mapping되어 있는지 정보를 관리한다. ★
-
맵핑 정보를 각 PTE에 저장한다.
-
Virtual Memory의 Index가 곧 PTE Index라고 볼 수 있다. ★
-
앞서, VP는 Cached, Uncached, Unallocated 등으로 구분됐는데, Cached인 VP들이 다 DRAM에 맵핑되어 있는 것을 의미한다. ★★★
- TLB는 여기선 고려 x
-
-
-
Page Hit : Reference to VM word that is in physical memory
- is equal to 'DRAM Cache Hit'
- Valid Bit of PTE is 1 ★
- Cached인 VM!
- is equal to 'DRAM Cache Hit'
-
Page Fault : Reference to VM word that is not in physical memory
- is equal to 'DRAM Cache Miss'
- Valid Bit of PTE is 0 ★
- Uncached인 VM!
- is equal to 'DRAM Cache Miss'
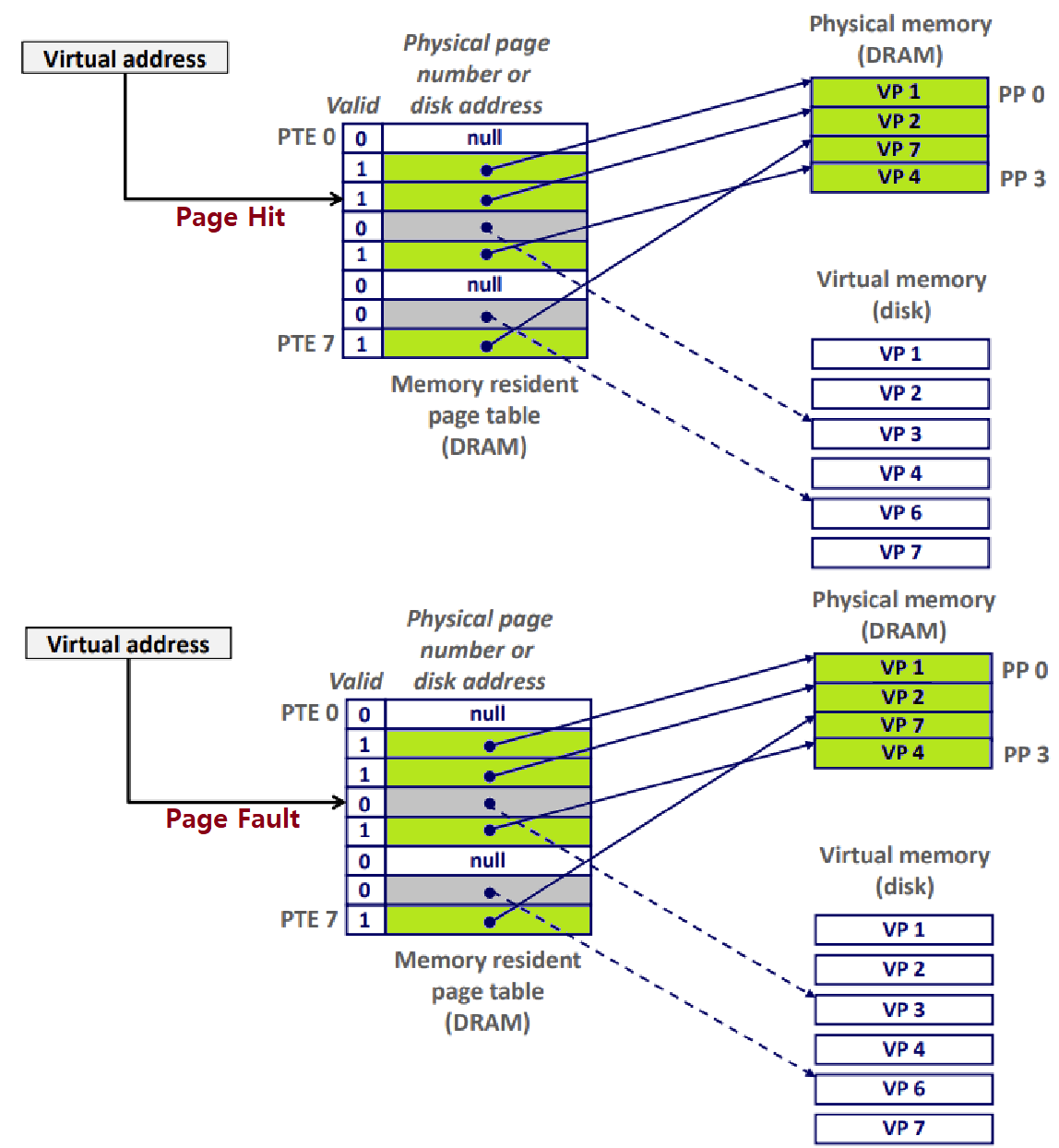
- Page Fault가 발생하면, 아래와 같은 처리 과정을 거친다.
-
Page Fault Exception이 발생한다.
-
Page Fault Handler가 Victim(Evict할 대상)을 일련의 Sophisticated Algorithm을 통해 선정한 후, Evict한다.
- 이때, Write-Back이 일어날 수 있다.
-
Page Fault를 일으켰던 'Offending Instruction'을 Restart한다.
- 이번엔 Page Hit이 될 것!
-
-
- 이러한 과정을 'Demand Paging'이라고 부르기도 한다. ★
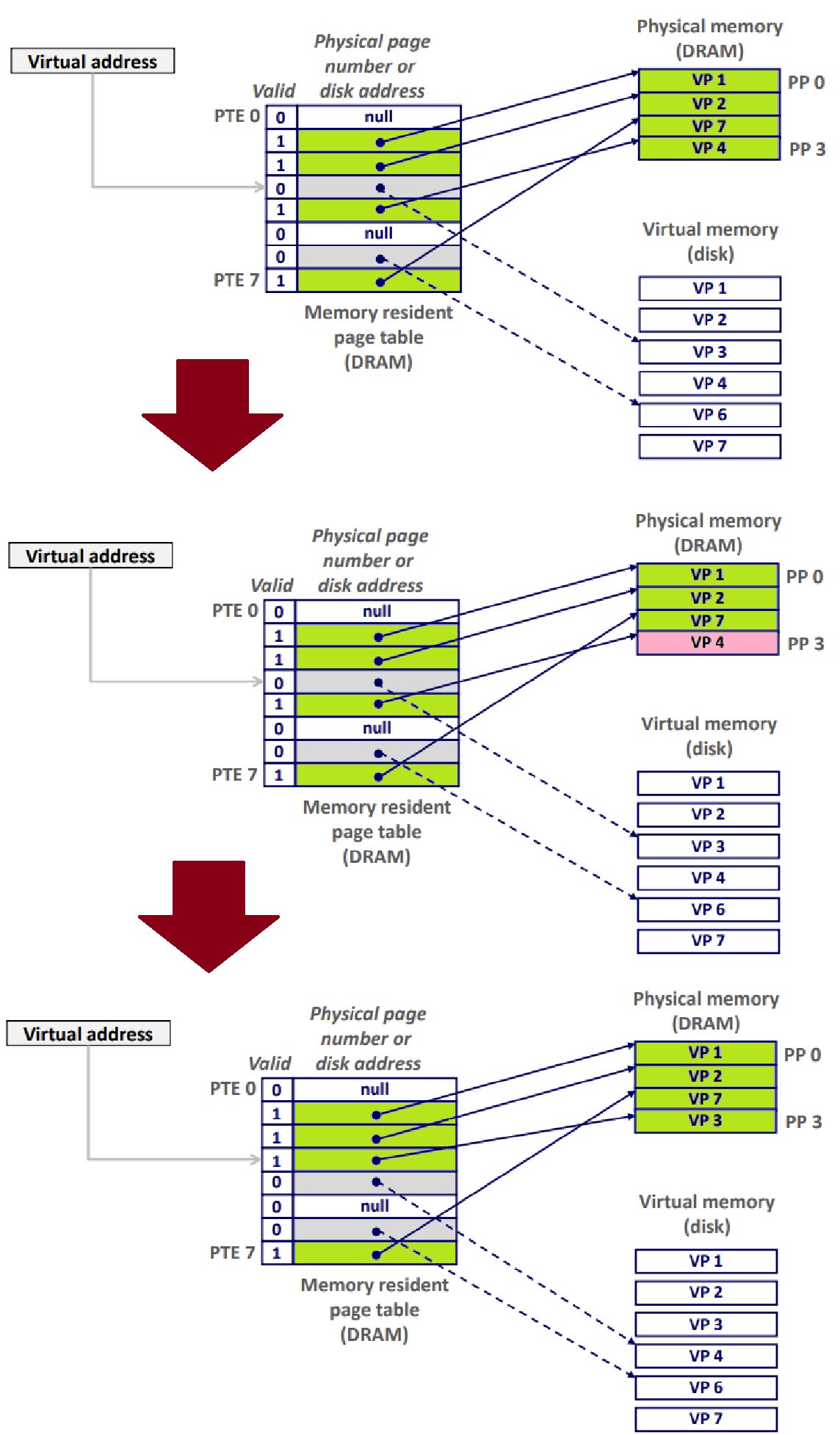
- Uncached였던 PTE3(VP3)이 Cached가 되고, Cached였던 PTE4(VP4)가 Uncached가 된 것을 주목하자.
- PTE를 처음 할당할 때에는, Disk의 Virtual Memory와 연결된다. 즉, Uncached가 Default State인 것! ★★★
Locality (Working Set)
이렇게 VM에 대해 간단히 알아보았는데, 얼핏 보았을 땐 상당히 비효율적인 과정처럼 보인다. 하지만, 실제로는 꽤나 준수한 성능을 보인다(그렇기에 현대에서도 적용되는 것). 이는 바로 'Locality(근접성)' 때문이다.
-
Working Set : 어떤 시점에 Process가 접근하고자 하는 'Active Virtual Page들의 Set을 의미한다.
-
만약, Working Set Size가 Main Memory Size보다 작으면, 'Compulsory Miss(초기 상태에서 메모리 Fetching 시 필연적으로 일어나는 Miss들)'를 제외하고는 Miss가 잘 일어나지 않아 프로그램 성능이 굉장히 우수하다. ★
- 프로그램이 'Temporal Locality(이전에 접근했던 메모리 영역을 재접근하는 근접성)'를 높이기 위해선 작은 사이즈의 Working Set을 가져야 한다. ★
-
만약, Working Set Size가 커져서, 그 합이 Main Memory Size보다 커지면, Page들이 계속해서 In & Out으로 Swap하기 때문에 성능이 굉장히 떨어지게 된다. ★
- Page Fault가 굉장히 자주 발생하게 되는 것! (Disk I/O가 너무 많아지는 것)
- 이를 Thrashing 현상이라고 부른다. ★
- Page Fault가 굉장히 자주 발생하게 되는 것! (Disk I/O가 너무 많아지는 것)
-
~> CPU 성능도 중요하지만, 메모리 성능도 매우 중요하다. 메모리가 작으면, 많은 프로그램을 돌릴 경우, Thrashing이 발생해 속도가 저하되는 상황이 발생한다.
이외에도 VM에 관해선 상당히 깊고 다양한 개념이 존재한다. 그러나, 본 SP 연재에서는 여기까지만 다루도록 한다. 이보다 더 Low-Level한 Concepts는 Application 측면에서의 시스템 개념을 다루는 SP에서 소개하기엔 무리가 있기 때문이다. 자세한 내용은 추후 진행될 OS 연재에서 이어가도록 하겠다.
마무리
이렇게, System Programming 연재 대장정을 마친다. 첫 포스팅에서 언급했듯, 본인의 SP 개념 복습 목적으로 글을 쓰겠다 했는데, 이는 실제로도 학기 중에 꽤나 많은 도움이 되었다. 허나, 중요한 것은 이렇게 기록물을 남겨놓았기 때문에 앞으로도 계속해서 생각날 때마다 이 SP 연재를 다시 보며 기억을 떠올릴 수 있다는 것이다. 현재 System 쪽 진로를 희망하는 입장에서, 이는 굉장히 큰 무기가 될 것이라 생각한다. '어려운 SP 개념을 나만의 언어로 풀어가는 연습'을 많이 하게 되었고, 이는 추후 System을 더 깊게 공부하고, 연구하는 과정에서 분명 크나큰 도움이 되리라 믿는다.
한편, 분명 이 연재를 읽는 이가 언젠가라도 생길 것이라 믿는다. 포스팅 과정에서 정확치 않은 내용이 담겼을 수 있는데, 이를 너그러이 양해해주길 바란다. 또한, 본인의 평소 글쓰기 스타일이 워낙 주절주절하는 스타일이라 가독성이 조금 떨어졌을 수 있음도 인정한다. 이 역시 양해해주길 바란다. 그러나, 연재 과정에서 본인은 최대한 '타인에게 설명하는 기분으로', 그리고 '내가 교수가 된다면, 이렇게 설명하는게 좋겠다'는 마인드를 가지고 임했기 때문에, 분명 어느 정도 독자의 이해에 큰 도움이 되리라 자부한다. SP에 대한 개념 보충이 필요한 사람, 컴퓨터공학을 전공하지 않아 SP에 대한 개념 학습이 필요한 사람들이 읽으면 좋을 것이다. 본인이 SP를 공부하며 느꼈던 재미를, 다른이들도 느꼈으면 좋겠다.
현재 글을 작성하고 있는 시점이 2022년 6월 19일인데, 앞으로도 이 SP 연재 시리즈를 지속적으로 관리하며, 시각 자료를 보충 및 변경(참조 교재 자료를 최대한 배제하고, 최대한 내 스스로 표현한 그림 자료들로 대체할 것)하고, 개념을 보충하고 할 것이기 때문에, 앞으로도 이 SP 연재는 살아있을 것이다.
연재 중간에 언급한 것처럼, 사실 SP 연재는 여기서 끝은 아니다. 여기서 다룬 개념들을 토대로 실제 본인이 학부 SP 수업에서 수행했던 프로젝트들이 있는데, 이들을 적절히 변형(같은 강의 수강생의 Copy 방지)하고, Customizing해서 순차적으로 소개할 계획이다. 세 프로젝트는 각각 Linux Shell 제작, Concurrent Server 구축, Dynamic Memory Allcator 구현이다. 추후 이들에 대한 포스팅이 올라올 것이다.
아무튼, 2022년 상반기 System Programming 개념 설명은 공식적으로 여기까지로 한다. 하반기에 OS(Operating System) 연재로 다시 찾아올 것이다. System을 완벽히 이해하는 그 날까지!
Stay Hungry, Stay Foolish!
