
지난 포스팅에서 설명했듯, 스마트폰의 대중화에 힘입어 NAND Flash Memory는 급격한 기술 발전과 대규모 생산이 이뤄지는 시대를 맞이했고, 이를 토대로 빠르고 자연스럽게 PC 및 데이터센터 환경에도 스며들기 시작했다. 가장 대표적인 솔루션은 Solid-State Drive (SSD)로, SSD는 3D Vertical (V)-NAND 기술과 Non-Volatile Memory Express (NVMe) 프로토콜 등을 통해 그 용량과 성능을 지속적으로 발전시키고 있다.
이렇게 SSD 기술이 비약적으로 발전하는 사이, 2010년대 중후반부터 본격적인 빅데이터 시대가 도래하면서 스토리지에 대한 응용의 요구는 과거와는 비교할 수 없을 정도로 폭증했다. 이에 따라 SSD 연구자와 엔지니어들은 기존과는 완전히 다른 양상의 새로운 문제를 마주하게 되었다. 그것은 바로, 현대 상용 SSD가 컴퓨팅 환경에 용이하게 통합되기 위해 채택 (계승)하였던 기존 HDD향 블록 인터페이스가 병목이 되기 시작한 것이다. 호스트는 SSD를 쉽게 사용하기 위해 기존의 단순한 블록 I/O를 고집하는 반면, SSD는 Backing NAND Flash 그 자체가 물리적으로 내제하고 있는 여러 제한 조건들을 가지고 있고, 그러한 상황에서 SSD는 결국 그 내부 펌웨어 로직에 복잡하고 다양한 작업을 만들어놔야 하는 것이다. 문제는 그러한 '복잡한 작업'들이 SSD 성능을 불안정하게 만들고, 동시에 용량이 커지면 커질수록 내부에 많은 리소스를 요구하게 되고, 이때 이러한 문제들이 Data-Intensive 시대에는 더더욱 부각되고 있는 것이다.
이러한 기존 SSD 설계의 한계를 극복하기 위해 지난 10여년 동안 다양한 신규 SSD 인터페이스 및 호스트 & 디바이스 설계 개념들이 등장했다. 이들은 전통적인 SSD 설계의 제약을 해결하고자 호스트와 디바이스 간 역할 분담을 재정의하거나, Flash Storage와 상호작용하는 전혀 새로운 방식을 도입하려는 시도로 요약할 수 있다. 지금부터 지난 10여년 간 이뤄진 이러한 연구들을 요약해보려고 한다.
SOTA Commercial Solution: NVMe SSD
하지만 설명에 앞서, '지피지기 백전불태'라고, 일단 현재 상용 솔루션의 최선봉인 NVMe SSD를 먼저 간단히 알아보고 넘어가자.
 PCI Express 기반 NVM Express 데이터 통신 프로토콜 [link]
PCI Express 기반 NVM Express 데이터 통신 프로토콜 [link]
멀티 큐 + PCIe 통신 = NVMe
NVMe는 SSD와 호스트 CPU를 PCI Express (PCIe) 인터커넥트 버스로 직접 연결하는 고속 인터페이스 프로토콜로, 기존 SATA (AHCI) 방식의 병목을 제거하도록 설계되었다. AHCI가 회전식 HDD에 맞춰 한 번에 최대 32개의 명령만 처리하는 단일 큐 구조였던 반면, NVMe는 수십~수백개 수준의 병렬 명령 큐를 운영하며 불필요한 레지스터 접근과 인터럽트 오버헤드를 최소화해 대역폭 활용을 극대화한다 (Spec상으로는 최대 64만개 정도이다). 그 결과, 동일한 Controller SoC + 펌웨어, DRAM, NAND 스펙을 가진 SSD에서 프로토콜만 NVMe로 교체해주어도 I/O Latency를 상당히 줄이고 초당 입출력 작업 수 (IOPS)를 높여줄 수 있다. NVMe의 도입을 통해 NAND Flash 본연의 속도에 근접한 I/O 서비스를 (이론적으로) 제공해줄 수 있게 된다. 이러한 효율성과 병렬처리 능력 덕분에 NVMe는 2010년대에 후반부터는 사실상 대부분의 상용 SSD의 데이터 통신 인터페이스로 채택되었고, 현재는 비단 시스템 분야 종사자가 아니더라도 일반 사용자들에게도 상당히 친숙한 개념이 되었다 (본 포스팅에선 NVMe over Fabrics (NVMe-oF)와 같은 NVMe의 네트워크 확장 개념은 다루지 않겠다).
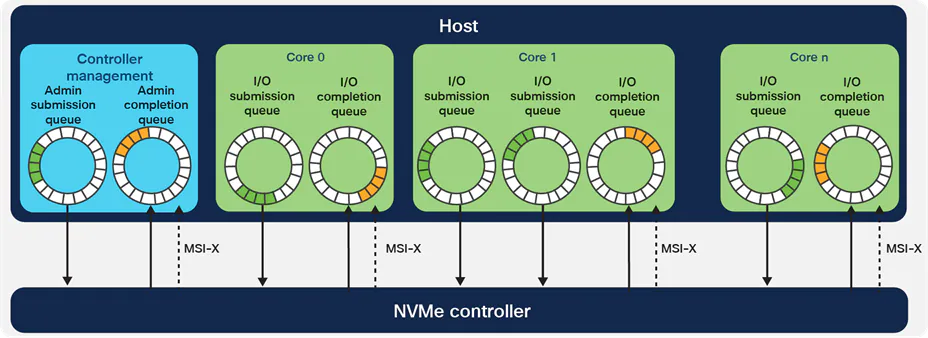 현대 멀티코어 CPU 아키텍쳐에 적합한 NVMe 멀티 큐 아키텍쳐 [link]
현대 멀티코어 CPU 아키텍쳐에 적합한 NVMe 멀티 큐 아키텍쳐 [link] 각 CPU 코어가 1개 이상의 Submission/Completion Queue를 관리하고 있음을 알 수 있다.
NVMe 기반의 데이터 Write Flow
이러한 NVMe SSD에 데이터를 쓰기 위한 하나의 요청이 실제로 NAND Flash에 기록되기까지, 다음과 같이 여러 계층의 소프트웨어 및 하드웨어 경로를 거치게 된다: [ 호스트 측 응용 계층 → 커널 I/O 스택 → NVMe 드라이버 및 DMA 전송 → SSD 컨트롤러 (HIL & FTL) → NAND I/O (FIL) ] (아래 그림 참고).
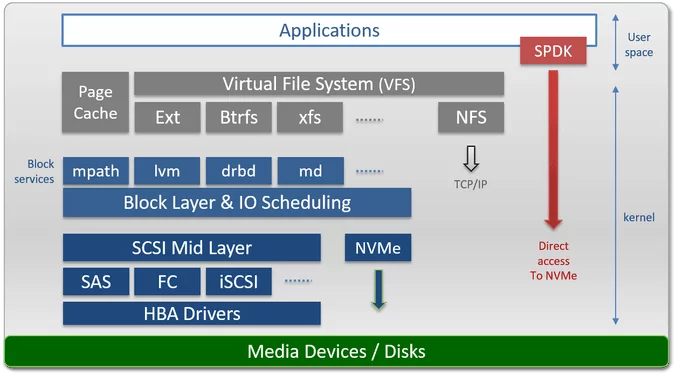 일반적인 호스트단 Storage (I/O) Stack, HDD부터 NVMe SSD까지 [link]
일반적인 호스트단 Storage (I/O) Stack, HDD부터 NVMe SSD까지 [link] App, VFS, FS, Block Layer를 거쳐 NVMe Driver까지 도달하는 Path에 주목하자. 참고로, 우측 상단의 SPDK는 Storage Performance Development Kit의 약자로 Intel에서 제안한 Kernel Bypassing향의 스토리지 인터페이스를 제공한다 (추후 다시 설명).
- (1) Application-Level: System Call을 통한 쓰기 요청
- 응용 프로그램은 일반적으로 POSIX 표준 System Call인 write() 또는 C 표준 라이브러리의 fwrite() 등을 통해 데이터 Write를 요청한다. 이때 호출된 쓰기 요청은 User Space의 Virtual Address에 위치한 버퍼 데이터와 함께, 대상 파일의 Offset과 Descriptor 등의 메타데이터를 포함하여 Kernel Space로 전달된다 (Context Switch).
- (2) Kernel I/O Stack: VFS, 파일시스템, 그리고 blk-mq
- 요청이 커널로 진입하면, 우선 Virtual File System (VFS) 및 파일시스템이 이를 처리하며, 필요 시 Page Cache를 통해 버퍼링된다. 이후 Evict될때가 되면 해당 Data에 대한 Write 요청은 Block Layer로 내려오는데, 이때부터는 실제 Logical Block Address (LBA) 기반의 요청으로 변환된다.
- 이때, Block Layer에선 NVMe의 등장에 맞춰 리눅스 커널에 패치된 blk-mq (Multi-Queue Block Layer)가 사용된다. blk-mq는 CPU 수에 비례하는 다수의 Software-Level Submission Queue를 지원하며, 멀티큐 기반의 병렬 I/O '요청 처리'를 수행한다. '요청 처리'라 함은, I/O 요청을 각 큐에 분배하고, 스케쥴링하는걸 뜻하는데, 이때 쓰이는 I/O 스케쥴러로는 보통 none, mq-deadline, bfq, kyber 등이 존재하며 (참고: none은 스케쥴링을 안쓰는 것을 의미함), NVMe 디바이스의 고성능 특성상 많은 시스템에서는 기본적으로 none 또는 mq-deadline을 사용한다. 이 스케줄러는 요청 간의 Sort, Merge 등을 통해 낭비되는 Random I/O를 줄이려는 목적을 가진다 (아래 그림 참고).
- none 정책이 default인 경우가 많은데, 이 이유가 재밌다. 궁금한 사람들은 이 논문에 언급된 부분을 확인해보자 (짧게 말하면, 그냥 Block Layer에서 별짓 안하고 NVMe로 바로 병렬로 때리는게 성능이 젤 좋단다).
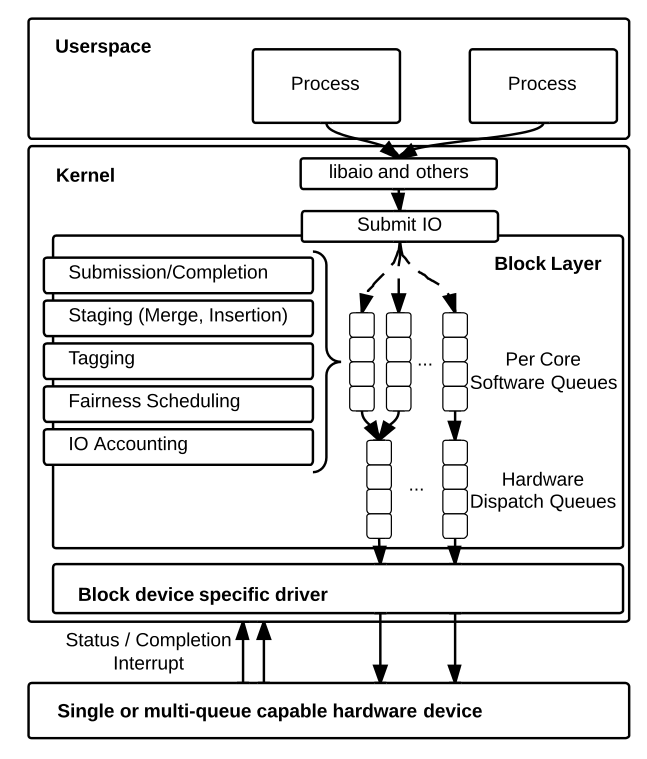 NVMe의 멀티 큐 구조와 긴밀하게 협력하는 Block Layer의 blk-mq 구조 [link]
NVMe의 멀티 큐 구조와 긴밀하게 협력하는 Block Layer의 blk-mq 구조 [link] Software-Level Queue와 Hardware-Level Queue로 구분되어 있음을 주목하자.
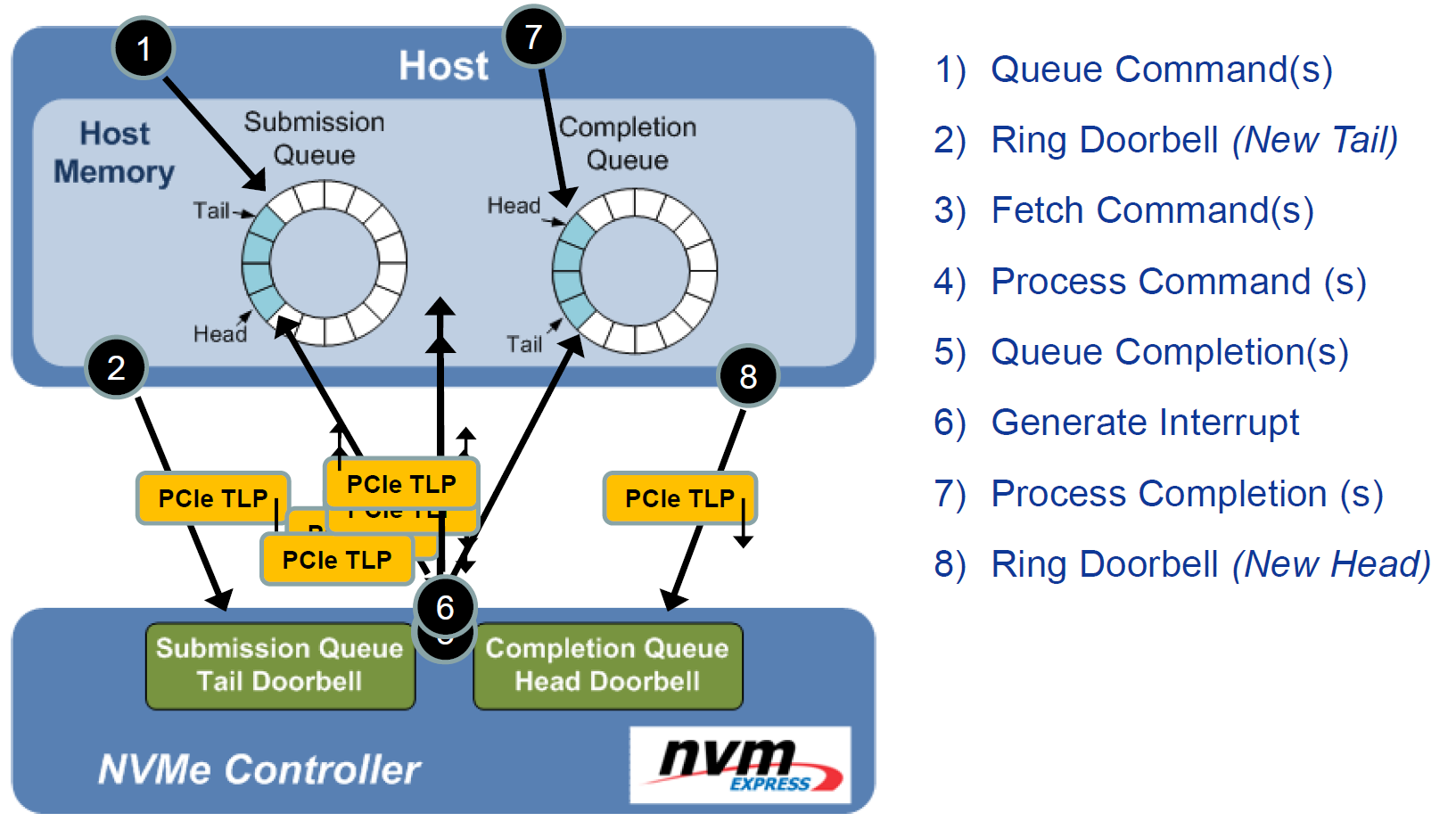 (그림상 Host라고 표시된) NVMe Driver와 Controller의 Command 기반 통신 매커니즘 [link]
(그림상 Host라고 표시된) NVMe Driver와 Controller의 Command 기반 통신 매커니즘 [link]
- (3) NVMe Driver: NVMe Command 변환 및 Submit
- Block Layer에서 Sort·Merge 등의 스케쥴링 처리를 마친 Write 요청은 blk-mq의 (역시나 여러개의) Hardware Dispatch Queue로 전달되며, 이 큐는 물리적으로 NVMe Submission Queue (SQ)와 1:1 또는 N:1로 매핑된다 (사실상 1:1임). blk-mq의 각 하드웨어 큐는 CPU별로 분산되어 있으며, 해당 큐의 요청들은 서로 lock-free로 직접 디바이스에 연결된다.
- 이때 각 Write 요청은 NVMe 드라이버에 의해 64B NVMe I/O Command 형식으로 인코딩된 후, (호스트 메모리에 존재하는) SQ에 Insert (enqueue)된다 (NVMe CMB라는 특수 속성을 쓰는 경우엔 디바이스 메모리에 존재할수도 있긴 한데 이 구현체는 사실상 거의 없는거로 앎). SQ는 Ring Buffer 형태로 구동되며, 커널은 NVMe Command 삽입 직후 PCIe Base Address Register (BAR) 맵핑 영역에 존재하는 SQ Tail Pointer Register에 해당 Command의 Index를 4B 크기의 PCIe Memory-Mapped I/O (MMIO)를 수행해 기록하고, 이어 Doorbell Register에도 4B MMIO를 수행해 Flag를 올려 SSD Controller에게 새 명령이 도착했음을 알린다.
- 위 그림에 이 과정이 자세히 설명되어 있음.
- 또한, 이 과정은 리눅스 커널 NVMe Driver의 pci.c 코드에서도 잘 확인할 수 있음.
- (4) NVMe Controller: NVMe Command Fetch 및 DMA
- SSD의 Host Interface Layer (HIL), 즉, NVMe Controller는 호스트에 맵핑된 Doorbell Register를 항상 Polling하며 확인한다. 이때 Flag가 올라간 것을 확인하면, Controller는 Tail Pointer Register를 통해 현재 NVMe Command가 호스트 메모리 단 SQ 내부 위치한 주소를 확인하고, 해당 주소에서 64B 크기의 Direct Memory Access (DMA)를 수행해 NVMe Command를 실제로 디바이스로 가져온다.
- 이어, NVMe Command에 포함된 Physical Region Page (PRP) Entry (→ Command 생성 시 데이터 Payload가 위치한 User Space 버퍼 Address가 특정 (기록)되어 있음. 참고로, Logical Address가 아니라, IOMMU 변환을 통한 (Memory Page-Aligned) Physical Address가 기록되어 있음)를 통해 호스트 메모리 상 데이터 버퍼의 주소를 참조하고, 해당 주소로부터 4KB 메모리 페이지 단위의 DMA를 수행해 데이터를 디바이스로 가져온다.
- 하나의 PRP Entry는 4KB의 데이터를 가리킬 수 있으며, Payload 크기가 더 클 경우 PRP 리스트를 체인 형태로 연결하거나 Scatter-Gather List (SGL)를 사용하여 다중 메모리 블록 Fetch를 할수도 있다.
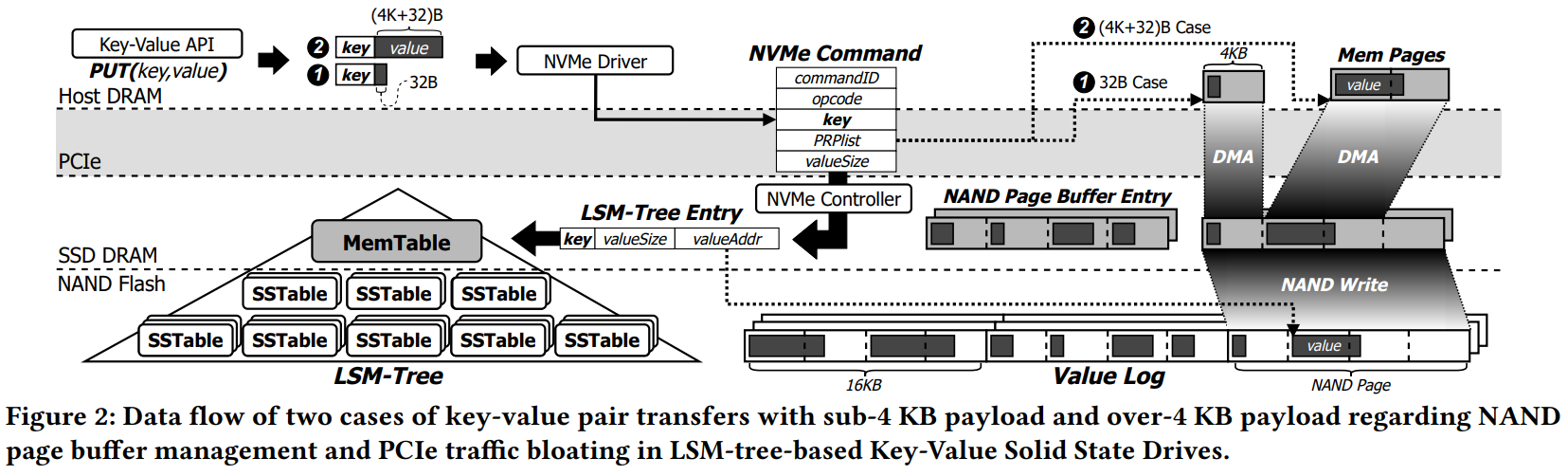 Figure from 'BandSlim: A Novel Bandwidth and Space-Efficient KV-SSD with an Escape-from-Block Approach [ICPP '24]' [link]
Figure from 'BandSlim: A Novel Bandwidth and Space-Efficient KV-SSD with an Escape-from-Block Approach [ICPP '24]' [link]이 그림은 향후 설명할 KV-SSD에 대한 그림이지만, NVMe PRP 기반의 Host-to-SSD 데이터 전송 매커니즘을 잘 묘사하고 있다: NVMe Command 내부에 명시된 PRP Entry를 통해 SSD Controller는 '디바이스로 가져올' 호스트단 메모리 페이지(들)를 인식하고 해당 페이지(들)에 대해 실제 DMA Copy를 수행하고 있음을 알 수 있다. 해당 페이지들 내부엔 실제 Payload가 담겨 있다.
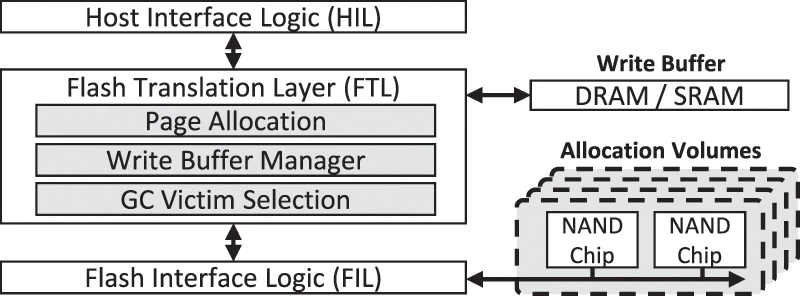 Figure from 'SSD Performance Modeling Using Bottleneck Analysis [IEEE Computer Architecture Letters '18]' [link]
Figure from 'SSD Performance Modeling Using Bottleneck Analysis [IEEE Computer Architecture Letters '18]' [link]SSD Controller SoC에서 구동하는 펌웨어 모듈이 HIL, FTL, FIL로 3단 구분된다.
- (5) Flash Translation Layer: NAND Address 특정과 내부 I/O 스케줄링
- SSD Controller는 호스트로부터 DMA Copy해온 Payload에 대해 내부에서 Write Buffering, Address Translation 등의 작업을 수행하며, 이 과정은 전적으로 Flash Translation Layer (FTL) 모듈이 책임진다 (HIL, FTL, FIL로 구분되는 아키텍쳐는 위 그림으로 확인 가능).
- FTL (또는 그와 동급의 레이어에서는) 그밖에도 Write Buffering (→ Write Request에 대해 바로 NAND Program을 수행하는게 아니라 SSD 내부 DRAM에 마치 파일시스템 페이지 캐시마냥 임시 보관함), Write Coalescing, Garbage Collection (GC), Wear Leveling 등을 수행한다. 이 과정에서 Over-Provisioning 영역을 활용해 Write Amplification을 줄이는 전략을 활용한다.
- FTL 아래에서는 NAND I/O Scheduler가 동작한다. 이는 SSD 내부의 Channel, Plane, Die 구조를 활용해 가능한 많은 Parallel I/O를 실행하고 컨텐션을 최소화하려는 방향으로 알고리즘이 돌아간다 (이 '속성'을 많이들 NAND Parallelism이라고들 부름).
- 상기 컴포넌트들에 대한 자세한 설명은 한양대학교에서 만든 훌륭한 NVMe SSD 개발 플랫폼인 Cosmos+ OpenSSD에 대한 논문으로 대체한다. OpenSSD가 NVMe SSD 펌웨어 로직의 모든 것을 커버하는 것은 아니지만 (특히나 최신의 Vendor-Specific한 최적화 기법들과는 무관), 상기 Operation들을 Basic한 관점에서 모두 커버하고, 실제 코드와 디바이스 레벨로 실습해볼 수 있기에 개념 학습 관점에선 이만한게 없다.
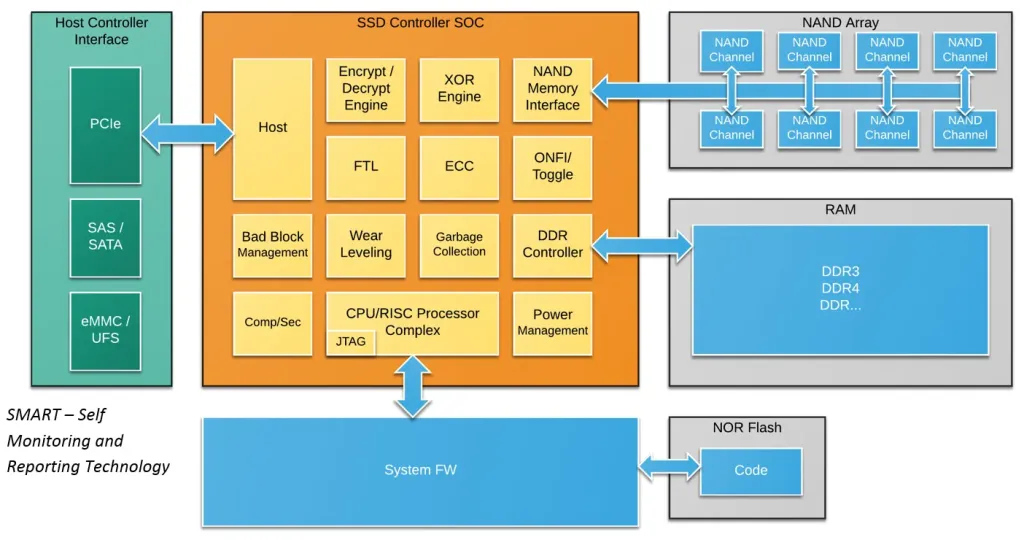 이전 회차에서 다룬 SSD의 SW/HW 아키텍쳐 그림 [link]
이전 회차에서 다룬 SSD의 SW/HW 아키텍쳐 그림 [link]SSD Controller SoC에서 정말 다양한 작업이 이뤄지고 있음을 주목하자.
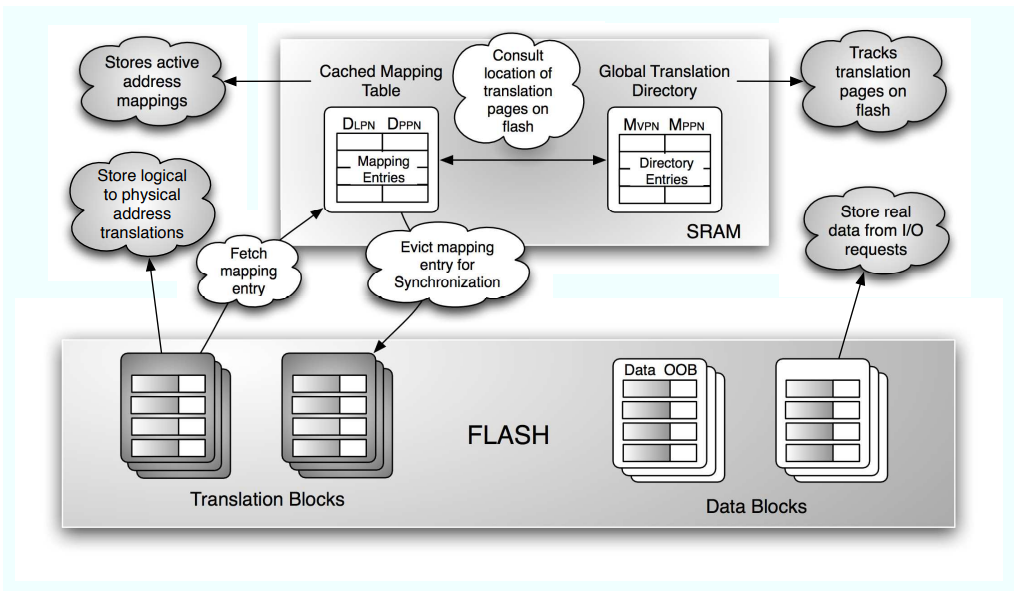 Figure from 'DFTL: A Flash Translation Layer Employing Demand-Based Selective Caching of Page-Level Address Mappings [ASPLOS '09]' [link]
Figure from 'DFTL: A Flash Translation Layer Employing Demand-Based Selective Caching of Page-Level Address Mappings [ASPLOS '09]' [link]대표적인 Hybrid FTL인 DFTL의 데이터 배치 형상 → 자주 쓰이는 맵핑 정보만 SRAM에 두고 나머지 맵핑 정보는 Flash에 둔다는, 굉장히 간단하면서도 강력한 Locality 기반의 정책이다.
- (6) Flash Interface Layer: 특정된 NAND Address에 대해 실제 NAND I/O를 수행
- FTL이 최종적으로 Physical NAND Address를 결정하면, Controller는 NAND Flash Interface Layer (FIL)를 통해 실제 NAND I/O를 수행한다. 이때 쓰이는 인터페이스로는 Open NAND Flash Interface (ONFI)가 있으며, 여기도 NVMe처럼 Command 기반의 인터페이스가 돌아간다 (진짜 NVMe랑 비슷함).
- 이때의 Command라 함은 Program (Write) / Read / Erase가 대표적이고, NAND Flash Chip과 SSD Controller SoC 간의 공유 메모리 공간 상에 위치한 몇 가지 ONFI-Compatible Register들을 통해 I/O를 Trigger하고, DMA를 통해 Payload를 주고 받고, 하는 식으로 돌아간다.
- 여기서부턴 Error Correction Code (ECC) 관련 루틴이 개입하기 시작하고, 이를 위해 NAND Page의 Out-of-Bound (OOB) 영역에 대한 I/O도 내부적으로 이뤄진다. 이에 대한 설명도 생략하겠음.
- FTL이 최종적으로 Physical NAND Address를 결정하면, Controller는 NAND Flash Interface Layer (FIL)를 통해 실제 NAND I/O를 수행한다. 이때 쓰이는 인터페이스로는 Open NAND Flash Interface (ONFI)가 있으며, 여기도 NVMe처럼 Command 기반의 인터페이스가 돌아간다 (진짜 NVMe랑 비슷함).
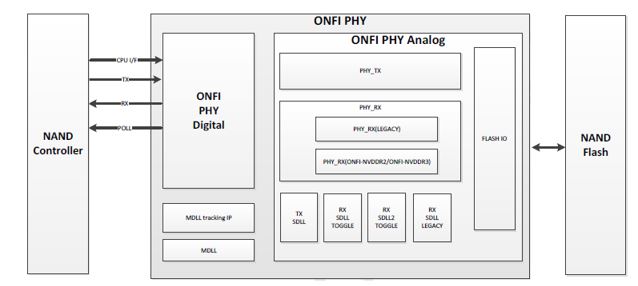 SSD Controller와 NAND Flash 사이에 존재하는 ONFI Physical Layer [link]
SSD Controller와 NAND Flash 사이에 존재하는 ONFI Physical Layer [link](일반 학생들에겐) 크게 주목받지는 않지만, 사실 SSD Controller와 NAND Flash 간 통신에도 위와 같은 복잡한 커뮤니케이션 매커니즘이 존재한다.
암튼, 결론적으로 NVMe SSD는 호스트와 위와 같은 Flow를 거치며 Data I/O 서비스를 제공한다. PCIe 기반의 고속 DMA 통신, PRP를 활용한 4KB 단위의 데이터 참조, 멀티큐 아키텍처를 통한 병렬성 극대화 등을 통해 NVMe의 고성능 인터페이스가 작동하고, 그것을 기반한 NVMe SSD는 내부의 Multiple Arm Core와 DRAM/SRAM 등을 통해 (점차 계속해서 스케일링해서) 고성능을 제공한다. 또한, 3D NAND와 QLC와 같은 고집적도 기술들을 통해 고용량의 NVMe SSD도 등장하고 있다.
위 Flow를 쭉 읽어보면 다음과 같은 생각이 들면 딱 좋다.
1. "NVMe가 어떤 식으로 고성능 블록 인터페이스를 제공하는지 알겠네!"
2. "근데 뭐이리 호스트 디바이스 양쪽 다 스택이 깊고 복잡해?"
1번을 통해 현대 고성능 NVMe SSD의 동작 원리를 이해할 수 있고, 2번을 통해 그러한 블록 인터페이스가 내제한 (다음과 같은) 두 가지 큰 문제를 '느낄 수' 있다.Problem#1: SSD 내부에서 하는 일이 너무 많은 반면 호스트는 이를 알 수 없다.
Problem#2: 한편, 호스트 단에서 I/O를 요청하는 과정도 상당히 (그리고 어쩌면 불필요하게) 헤비하다.
대표적인 NVMe SSD 스펙과 QLC 통합
일단, NVMe SSD의 문제는 차치하고, 현존 NVMe SSD의 대표 상품들을 통해 스펙을 알아보자.
 SK hynix 일반 소비자용 주력 NVMe SSD인 Platinum P41 SSD [link]
SK hynix 일반 소비자용 주력 NVMe SSD인 Platinum P41 SSD [link]
- 최신 NVMe SSD의 성능 지표는 다음과 같다.
- 일반 소비자용 Performance향 고속 NVMe SSD (PCIe 4.0/5.0 기반)는 Sequential Read 속도 약 7~14GB/s 및 Write 속도 7~14GB/s 내외에, Random 4K IOPS는 약 100만 이상에 달하는 수준이다 [link].
- SK hynix Platinum P41 SSD, Samsung 990 Pro SSD 등이 대표적
- 엔터프라이즈 데이터센터용 NVMe SSD의 경우 Read Latency가 100μs 이하, Write Latency가 10μs대까지 보고되고 있다 [link].
- Solidigm D5-P5336, Micron 9400 NVMe SSD 등이 대표적
- 일반 소비자용 Performance향 고속 NVMe SSD (PCIe 4.0/5.0 기반)는 Sequential Read 속도 약 7~14GB/s 및 Write 속도 7~14GB/s 내외에, Random 4K IOPS는 약 100만 이상에 달하는 수준이다 [link].
- 현대 NVMe SSD는 다양한 폼팩터를 제공해 일반 소비자 니즈 (소형)부터 데이터센터 니즈 (대형)까지 폭넓게 활커버한다.
- 일반적인 PC, 노트북용으로는 중지(..) 손가락 크기의 M.2 모듈이 보편적이며, 서버용으로는 2.5인치 드라이브 형태의 U.2 (U.3) SSD가 핫스왑을 지원하는 엔터프라이즈 스토리지로 쓰인다.
- 최근에는 Enterprise & Data Center SSD Form Factor (EDSFF) 규격인 E1.S, E1.L, E3.S, E3.L 폼팩터 등이 도입되어 표준화되고 있다. 기존 M.2나 2.5인치보다 공간 활용과 발열 관리에 최적화된 높은 집적도의 NVMe 스토리지 구현이 가능해졌다.
 QLC NAND Flash 기반의 Solidigm 데이터센터용 NVMe SSD인 D5-P5336 SSD [link]
QLC NAND Flash 기반의 Solidigm 데이터센터용 NVMe SSD인 D5-P5336 SSD [link] 122TB급의 대용량 저장장치로, 2025년 현재 상용 SSD 중 용량이 가장 큰 것으로 유명하다.
- Quad-Level Cell (QLC) NAND Flash는 엔터프라이즈용 SSD 고용량화 트렌드를 주도하고 있다. QLC는 메모리 셀 하나에 4비트를 저장하여 전 세대인 Triple-Level Cell (TLC, 3비트) 대비 약 33% 높은 밀도를 제공해 동일한 실리콘 면적에서 더 많은 데이터를 저장할 수 있다. 이를 바탕으로 최근 출시된 엔터프라이즈용 NVMe SSD에서는 단일 드라이브로 수십에서 심지어 100을 넘어가는 수준의 TB 용량을 제공하는 초대용량 제품들이 등장했다.
- 예를 들어, 위에도 언급된 Solidigm의 D5 시리즈는 한 개의 NVMe SSD에 30~60 TB에 달하는 용량 (최대 약 61.44TB)을 구현하였고, 2024년 작년엔 122TB급 제품도 등장했다.
- 다만 QLC는 용량 향상의 대가로 성능과 내구성 측면에서 제약이 있다. 셀당 저장 상태가 늘어난 만큼 데이터 처리 속도가 TLC 대비 느리고 Read Latency도 증가하며, Program/Erase (P/E) Cycle Limit이 낮아 Cell Endurance가 떨어진다 (즉, Bad Block 문제가 심각함).
- 이러한 특성 때문에 QLC SSD는 잦은 쓰기보다는 읽기 위주의 워크로드에 적합한 것으로 평가되며, 실제로도 워크로드의 일일 쓰기량이 낮아지는 최근 추세와 맞물려 고용량 QLC 기반 NVMe SSD의 활용도가 높아지고 있다.
SSD 최적화 추상화를 향해!
앞서 언급한 기존 블록 인터페이스 기반 SSD의 문제점을 해결하고, 보다 'SSD 친화적인 인터페이스 & 아키텍쳐'를 고안하기 위해 연구자들은 최근 10년간 정말 많은 노력을 기했다. 일부는 전통적 호스트의 역할을 더 확장하고자 하였고, 일부는 오히려 반대로 디바이스의 역할을 더욱 늘려보고자 하였다. 전자의 경우, 전통적 호스트의 역할을 더 확장하며, SSD 내부의 '복잡한 일'에 대해 호스트가 더 많은 정보를 제공하고 간접적으로 제어할 수 있도록 하는 방향을 모색했다. 이 흐름은 디바이스를 단순한 저장소로 보지 않고, 호스트가 I/O 특성이나 데이터 수명 정보를 명시적으로 전달하여 디바이스 내부 동작의 최적화를 유도하는, 일종의 '호스트 중심 제어 패러다임'으로 요약될 수 있다. 이와 같은 시도는 결국 블록 추상화 뒤에 가려졌던 SSD의 실제 동작과 제약을 호스트가 인지하고 협력적으로 대응하려는 노력의 일환이라 할 수 있으며, Multi-Stream, Open-Channel, Zoned Namespace, Flexible Data Placement 등의 기술들은 이러한 철학을 공유하며 진화해왔다.
후자의 경우, 오히려 디바이스의 역할을 더욱 확장하는 방식으로 접근하였다. 이는 SSD를 단순한 저장 매체가 아닌 데이터 처리의 일부를 담당할 수 있는 독립적인 연산 자원으로 재정의하려는 시도이며, 흔히 '디바이스 중심 확장 패러다임'으로 설명된다. 이 흐름은 주로 호스트와 디바이스 간의 I/O 병목 문제를 완화하거나, 불필요한 데이터 이동을 줄여 전체 시스템 효율을 높이려는 목적에서 출발하였다. 대표적인 예로는 (Computational SSD 또는 SmartSSD라고도 좀 더 세부화해서 명명할 수 있는) Computational Storage Drive (CSD)가 있으며, 이는 디바이스 내에 연산 자원을 적극 활용하여 데이터 필터링, 압축, 분석 등의 작업을 디바이스 내부에서 선제적으로 수행함으로써, 데이터 이동 비용을 절감하고 처리 지연을 줄이려는 구조이다. 또 다른 예시로는 (CSD의 일종으로도 볼 수 있는) Key-Value SSD가 있으며, 이는 기존의 LBA 기반 블록 인터페이스를 벗어나, 디바이스가 현대 빅데이터 처리 환경의 비정형 데이터 형식 표준인 'Key-Value' 형태의 데이터 구조를 디바이스에서 직접 처리함으로써, 호스트단 소프트웨어 스택을 단순화하고 이기종 컴퓨팅향의 성능 최적화를 추구한다.
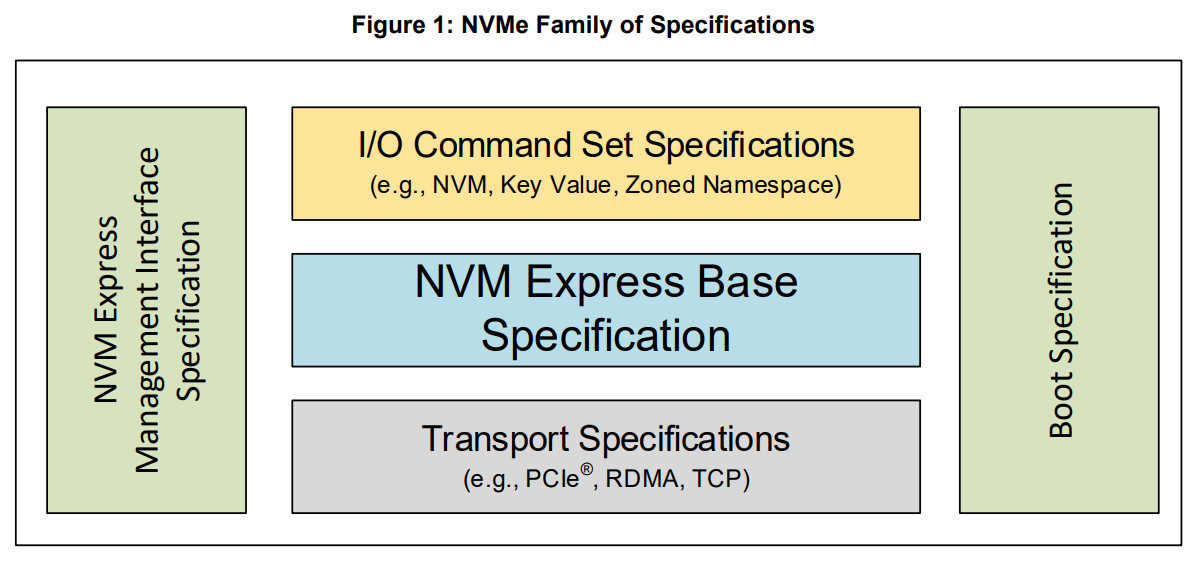 2024년 8월 5일자 NVMe Base Specification Revision 2.1에 나와 있는 현재 NVMe가 규정/관리하는 다양한 국제 표준들 [link]
2024년 8월 5일자 NVMe Base Specification Revision 2.1에 나와 있는 현재 NVMe가 규정/관리하는 다양한 국제 표준들 [link] 재밌는 점은, 2024년 8월 5일에서 10년전인 2014년 7월 2일자 Spec에는 위와 같은 Family 그림 자체가 애초에 없고 그냥 바로 Admin Queue 설명부터 시작한다. 지난 10년간 정말 많은 내용들이 새롭게 추가되었음을 알 수 있고, 그중에는 본 연재에서 다룰 CSD, FDP, KV-SSD, ZNS 등에 대한 인터페이스 규정 뿐만 아니라 전술한 NVMe-oF와 같은 네트워크 상의 표준들, 그리고 Booting, Power Management 등에 대한 규정들도 포함되어 있다. 근래에는 CXL Interconnect와의 통합도 진행되고 있는 것으로 보인다 (작년 FMS 발표에 있음).
이처럼 지난 10여년간의 SSD 인터페이스 발전은, (1) 한쪽에서는 호스트가 디바이스를 더 잘 활용할 수 있도록 도와 디바이스를 경량화하는 방향, (2) 다른 한쪽에서는 디바이스가 스스로 더 많은 일을 할 수 있도록 설계해 호스트단 스택을 경량화하려는 방향, 이 두 가지 축이 상호 보완적 혹은 대립적으로 발전해온 양상으로 정리할 수 있다. 본 연재에서는 지금부터 그 역사를 항목별로 간략히 소개하고자 한다. 먼저, Multi-Stream이다.
동향#1: Multi-Stream - 데이터 수명 기반 Stream 분리
Multi-stream은 호스트가 데이터의 예상 수명 또는 특성에 따라 여러 개의 'Stream ID'를 지정해 SSD에게 전달하면, SSD가 각 Stream별로 물리적인 쓰기 공간을 분리하여 관리하는 디렉티브 방식 기술이다 (디렉티브, 말 그대로 호스트가 디바이스에 '지시'하는 느낌으로 받아들이면 된다).
등장 배경
현대의 스토리지 워크로드는 운영체제, 여러 Application, Virtual Machine 등 다양한 출처의 데이터가 무작위로 섞여서 SSD에 기록된다. 이때, 서로 수명이 다른 데이터가 한 Physical Block (= Erase Block)에 섞이면, '단명'한 데이터가 삭제되더라도 그 Block에 같이 들어간 '장수' 데이터가 남아있는 한 블록을 해제할 수 없다는 것이다. 이 경우, 결국 일부 Valid 데이터를 옮겨야 해당 Block을 지울 수 있게 되고, 이 과정이 WAF를 키우는 주원인이 된다. 예를 들어 RocksDB의 WAL처럼 금방 Invalid되는 데이터와 사용자의 ToDoList를 정리한 텍스트 파일과 같은 오래 지속되는 데이터가 같은 Physical Block에 쓰여지면 GC 시 오래 남는 데이터를 반복해서 옮겨야 하는 것이다.
Multi-stream 개념은 이러한 문제를 해결하고자, 호스트가 미리 데이터의 특성을 알려주면 SSD가 처음부터 분리해서 써주겠다는 발상에서 출발했다. 2014년경 삼성전자 Memory Solutions Lab에서 제안하였으며 (아래 그림이 해당 논문에서 발췌한 그림으로, Multi-stream의 철학이 정확히 드러난다), 이후 표준화 논의가 이루어져 NVMe 1.3에서 'Streams' 디렉티브로 채택된 바 있다.
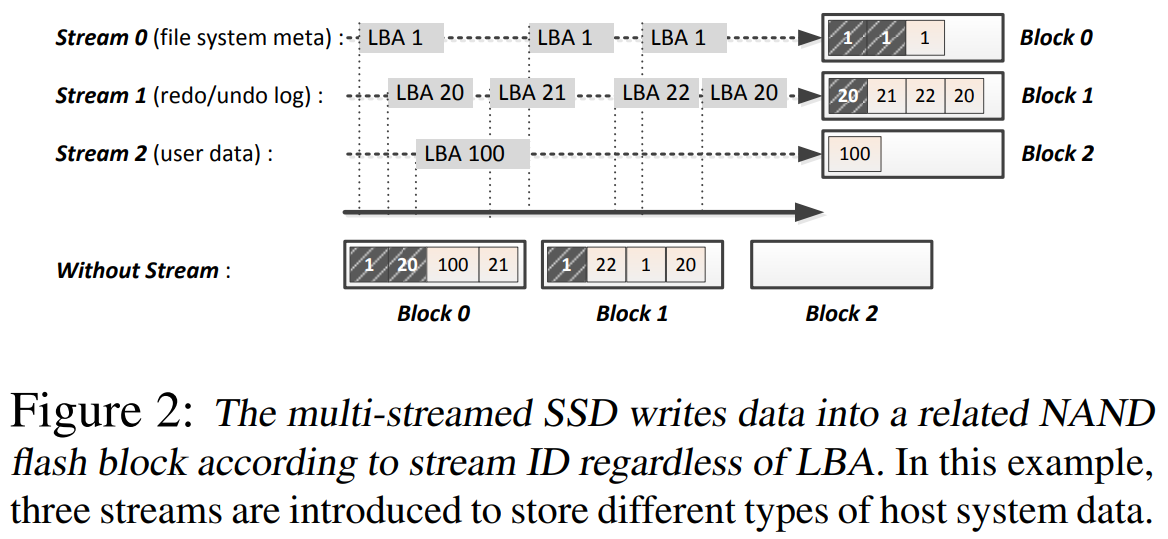 Figure from 'The Multi-streamed Solid-State Drive [USENIX HotStorage'14]' [link]
Figure from 'The Multi-streamed Solid-State Drive [USENIX HotStorage'14]' [link]
기술적 원리
Multi-stream SSD의 내부 동작을 자세히 보면, SSD는 Stream ID마다 별도의 할당 영역 (which is called 'Super Block')과 Write Pointer를 가진다. 예를 들어 Stream ID 1번에는 Super Block A, B, C가 차례로 할당되고, Stream ID 2번에는 Super Block D, E, F가 할당되는 식이다 (Super Block이란 SSD 내부에서 병렬로 묶여 지워지는 최소 단위로, 주로 각 채널당 한 블록씩을 묶는다. 일반적인 SSD의 GC 기본 단위임). Multi-stream SSD는 Stream별로 이러한 Super Block을 통째로 예약하여, 서로 다른 Stream 데이터가 한 Super Block에 섞이지 않게 한다.
호스트가 Write Hint로 지정한 Stream ID는 곧바로 SSD 펌웨어의 디렉티브로 작용하여, 해당 ID 전용으로 할당된 Super Block의 현재 Write Pointer 위치에 데이터가 기록된다. 하나의 Super Block이 꽉 차면 SSD는 새로운 빈 Super Block을 같은 Stream ID에 할당하고 연속해서 그 Stream의 데이터를 기록한다. 이러한 방식으로 Stream 간 Write 영역이 논리적으로 분리되며, Controller가 의도적으로 다른 Stream의 빈 공간을 채우기 위해 섞어쓰는 일이 없도록 한다. 이는 """같은 스트림 = 동일한 수명 특성"""이라는 가정하에, 각 스트림별로 데이터가 밀집 배치되는 형태라고 이해할 수 있다.
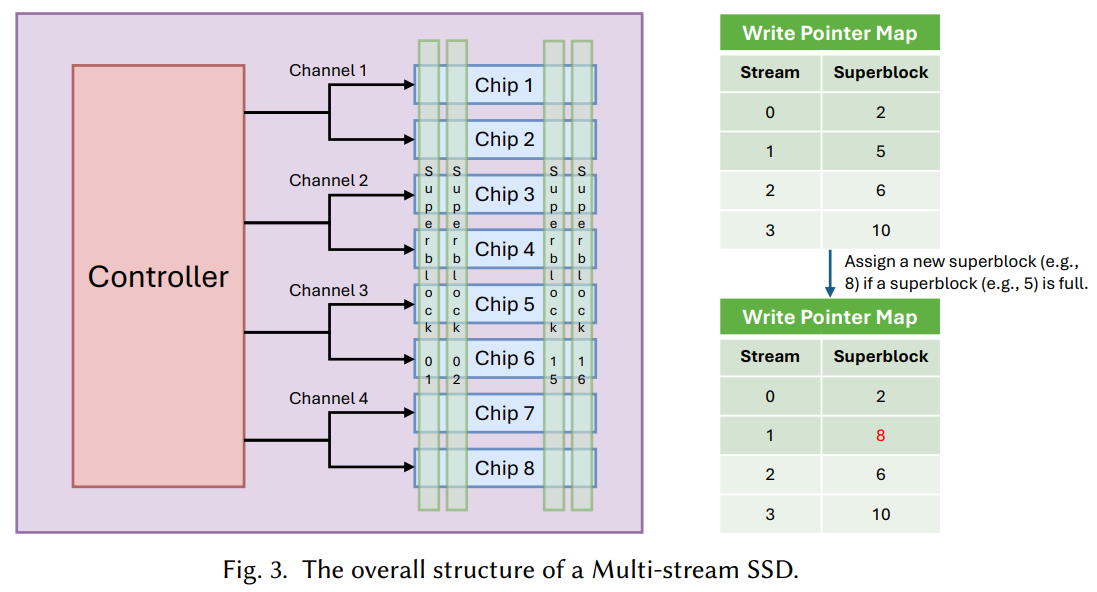 Figure from 'Storage Abstractions for SSDs: The Past, Present, and Future [ACM Transactions on Storage '25]' [link]
Figure from 'Storage Abstractions for SSDs: The Past, Present, and Future [ACM Transactions on Storage '25]' [link]Super Block과 Write Pointer Map 기반의 Multi-Stream SSD 아키텍쳐가 상세히 드러난다.
NVMe Streams 디렉티브 표준에서는 호스트가 NVMe Controller에 Stream 설정을 할당하고, NVMe I/O (Write) Command의 특정 Field로 Stream ID를 함께 전달하는 식으로 인터페이스가 정의되었다. Linux 커널에서도 이를 지원하기 위해 fcntl(F_SET_RW_HINT)라는 파일 단위 힌트 설정 API와 Block Layer의 Stream Mapping 코드가 도입되었다. 예를 들어 응용이 특정 파일에 대해 '이 파일의 데이터 수명 힌트=HINT_X'를 설정하면, 파일시스템과 블록 디바이스 계층을 거쳐 해당 파일의 Write 요청마다 SSD로 스트림 ID X가 전달되는(될 수 있는) 식이다. 이를 토대로 여러 응용과 파일시스템을 타겟삼아 각 데이터 종류에 따라 (파일시스템의 경우 저널, 메타데이터, 일반 파일 등으로 구분 가능할 것임) 다른 Stream으로 구분해 그 유불리를 따지는 식으로 많은 연구들이 진행되었다.
주요 장점
Multi-stream의 주요 장점은 결국 WAF 감소와 SSD 수명 향상으로 요약할 수 있다 (위에 언급된 HotStorage 논문에서 'Aging'을 막는다는 표현을 썼는데, 굉장히 적절한 것 같다). 호스트가 데이터 특성을 알려준 덕분에 SSD는 유사한 수명의 데이터만 한데 모아 저장할 수 있고, 그 결과 GC 시 이동해야 할 유효 데이터 양이 크게 줄어든다. 초기 연구와 실험 결과에 따르면, 워크로드에 따라 WAF를 두 자릿수 % 이상 감소시켜 성능과 내구성을 향상시킬 수 있었다고 한다. 또한, (부가적인 효과로서) Stream 분리를 통해 서로 다른 작업의 Interference를 줄이고 성능 안정성을 높이는 효과도 있다. 예를 들어, 대용량 Sequential Write 작업과 소량 Random Write가 동시에 진행될 때, Stream을 구분해두면 Random Write의 GC로 Sequential Write 영역이 방해받는 일이 기존 일반 블록 SSD 대비 적어져 QoS가 향상될 수 있다. 인터페이스 개발 측면에서도 Multi-stream은 기존 블록 인터페이스에 소폭의 확장만으로 구현 가능하여, (Low-Level Kernel과 SSD Firmware 정도 Level에서 보았을 때) 호환성을 유지하기가 쉽다는 이점이 있다.
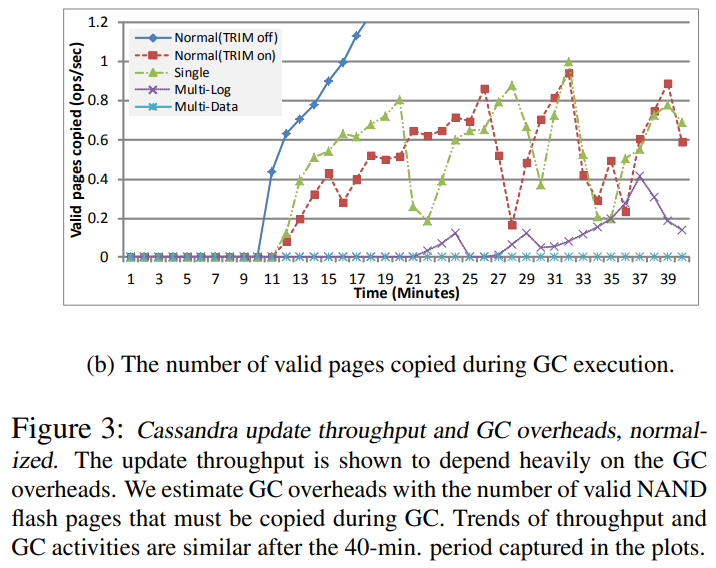 Figure from 'The Multi-streamed Solid-State Drive [USENIX HotStorage'14]' [link]
Figure from 'The Multi-streamed Solid-State Drive [USENIX HotStorage'14]' [link]TRIM을 Enable한 Normal SSD 대비 Multi-Stream SSD가 GC 시의 Valid Page Copy를 훨씬 덜 수행함을 알 수 있다 (참고: TRIM은 본 연재에선 다루지 않음, 이를 새로운 SSD 추상화라고 보긴 어렵다고 생각함).
주요 챌린지
(참고: Multi-stream의 경우 어느 정도 '학계 및 업계에서의 평가'가 마무리된 컨셉이라고 Consensus가 되어 있어 업황을 아래에 서술해놓는다)
가장 대표적인 챌린지로는 Multi-stream의 도입은 결국 호스트의 부담이 늘어난다는 점이다. Multi-stream을 제대로 활용하려면 파일시스템이나 응용프로그램이 데이터의 수명 또는 특성을 분류해야 하는데, 이는 (당연하게도) 개발자나 시스템에 추가적인 (그리고 여러 방면의) Effort를 요구한다. 잘못된 Stream 분류는 오히려 이득을 못 보거나, 최악의 경우 특정 Stream 블록이 반쯤만 채워지고 데이터가 다 무효화되어 공간 활용도가 되려 떨어지는 문제가 생길 수도 있다. 즉, App, OS, Driver, Controller 등 다양한 계층에서 이 기능을 모두 지원해야 하고, 반대로 말하면 그러한 'Consistent한 협업' 없이는 실제 Production에 적용되기가 어렵다는 것이다 (파편화의 문제라고 볼 수 있겠다). 실제로 안타깝게도 이러한 Streams 표준화에도 불구하고 산업계 채택이 저조해 결국 NVMe에선 현재는 이를 Deprecate하였다. 따라서, Multi-stream에선 결국 이러한 Stream 분류를 자동으로 수행하는 Layer가 (App, OS는 최대한 그대로 유지하면서) 도입되어야 바람직하다고 볼 수 있고, 실제로 2010년대 후반 이러한 컨셉을 제안하는 연구들이 많이 등장한 바 있다 (대표적인 연구가 아래의 AutoStream이다).
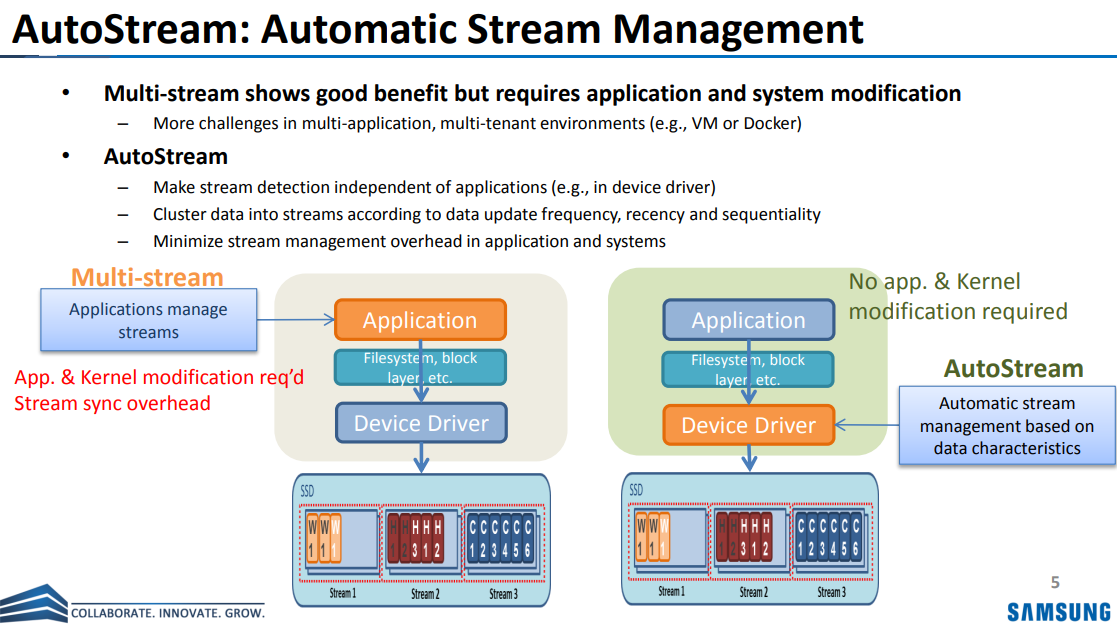 Figure from Talk Slides of 'AutoStream: Automatic Stream Management for Multi-Streamed SSDs [ACM Systor '17]' [link]
Figure from Talk Slides of 'AutoStream: Automatic Stream Management for Multi-Streamed SSDs [ACM Systor '17]' [link]"Make stream detection independent of applications!"
마지막으로, 일부 커뮤니티에선 Multi-stream의 피드백 메커니즘 부재를 큰 한계점으로 지목한 바 있다. 호스트가 Stream ID를 스마트하게 붙여주어도, SSD 내부에서 과연 이것이 효과적으로 작동했는를 호스트에게 사후 보고를 할 방법이 없는 것이다. SSD가 내부적으로 WAF를 계산해도 호스트와 이를 공유하지 않으므로 튜닝이나 동적 조정이 어렵다는 문제가 존재한다 (이러한 피드백 부족 문제를 포함해 Stream 컨셉을 개선하고자 등장한 것이 향후 서술할 Flexible Data Placement (FDP)이다).
(다음 회차에선 Open-Channel과 Zoned Namespace 컨셉을 다룰 예정이다)
본 포스팅은 올해 초 ACM Transactions on Storage에 연달아 올라온, 현대 SSD 추상화에 관한 두 편의 훌륭한 서베이 논문 (paper1, paper2)을 기반으로 하며, SSD 연구 흐름을 내 스스로 정리해보고 외부에도 가볍게 소개해보는 목적으로 작성하였다. 이 글을 읽고 흥미가 생긴다면 이 두 논문을 실제로 읽어보길 권한다!
본 글에 담긴 Claim격의 서술은 모두 제 개인의 의견일 뿐이며 아무런 대표성을 가지지 않습니다.
