
NAND Flash 기반 SSD의 발전과 오늘날의 문제점
Flash Memory는 1984년 Toshiba Labs에서 처음 발명되었으며, 이후 바이트 단위로 접근하는 NOR 방식과 블록 단위로 접근하는 고밀도 NAND 방식으로 기술이 분화되었다 (주로 인텔이 전자인 NOR를, 도시바가 후자인 NAND를 서포트했다고 함). 이후 점차 더 많은 데이터를 가격효율적으로 저장할 수 있는 NAND가 Flash 제조 형태의 주류로 자리 잡았고, 이와 동시에 1990년대부터 이미 Flash Memory는 그 경량성과 집적도를 토대로 디지털 카메라, MP3 플레이어, PDA 등과 같은 휴대용 임베디드 기기에서 널리 사용되기 시작했다. 이러한 Flash Memory 태동기에는 주로 시스템에서 Raw Flash를 그대로 직접 사용하는 형태로 통합되었다. 재밌는건, 이 당시 Flash 가격은 지금과 달리 DRAM보다 오히려 더 높은 수준이었고, 따라서 이 당시 범용 PC에서 Flash Memory를 사용하는건 시기상조였다.
 Flash Memory의 선구자 중 하나인 후지오 마쓰오카 교수 [link]
Flash Memory의 선구자 중 하나인 후지오 마쓰오카 교수 [link]
그러던 중, 2000년대 중후반에 들어서며 스마트폰으로 대표되는, PC와 대등한 수준의 유저 경험을 제공하는 휴대용 전자기기가 대중화되기 시작했다. 이들은 필연적으로 기존 임베디드 기기와는 차원이 다른 수준의 스토리지 요구사항을 갖게 되었고, 업계와 학계에선 이 니즈를 맞추기 위해 NAND Flash 연구 개발에 더욱 몰두했다. 그 결과, Flash Memory 기술은 매우 빠르게 발달했고, 이는 곧 Mass Production, 즉, 양산으로 이어졌다. 대량 생산은 결국 Flash Memory 가격의 급격한 하락을 이끌었고, 이에 따라 본격적으로 Flash Memory는 PC와 데이터센터 시장으로 확산되었다. 이 시기, NAND Flash Memory 솔루션의 가장 대표적인 형태는 Solid-State Drive (SSD)였다.
 SK hynix의 PE9110/9010 NVMe E1.S/M.2 PCIe Gen4 SSD [link]
SK hynix의 PE9110/9010 NVMe E1.S/M.2 PCIe Gen4 SSD [link] NAND Flash Module과 DRAM, Controller SoC 등이 손가락만한 작은 크기의 PCB 기판에 오밀조밀 모여 있음을 확인할 수 있다.
단순히 더 빠른 HDD...?
초기 SSD 시대에는 기존 시스템과의 호환성을 보장하기 위해 Serial AT Attachment (SATA)나 Serial Attached SCSI (SAS) 인터페이스를 사용하여 Hard Disk Drive (HDD) 동작을 계승하는 방식으로 설계되었다. 여러 이유가 있었지만 가장 큰 이유는 결국 기존 운영체제와 파일시스템에 별다른 수정을 가하지 않고 NAND Flash 기반 SSD를 바로 사용할 수 있게 하는 것이었다. 이러한 접근은 HDD에서 SSD로의 전환과 SSD의 기존 인프라로의 통합을 용이하게 했고, 그 결과 2010년대부터는 대부분의 가정용 개인 PC에는 SSD를 꼽아 쓰는게 당연한 시대가 되었다.
사람들이 PC 부팅 속도가 엄청 빨라지고 게임이 버벅이지 않고 잘 돌아가는 것에 놀라고 있는 사이, 불과 몇년 사이에 NAND Flash Memory, SSD 기술은 그 엄청난 수익성에 힘입어 더욱 빠르게 발전했다. 그중 가장 괄목할만한 성과는 2013년 삼성의 최초 3D V (Vertical)-NAND Flash 모듈 '양산'이고, 2011년-2014년 NVM Express (NVMe) 인터페이스의 등장을 꼽을 수 있다. 3D NAND는 스토리지 용량을 기하급수적으로 스케일링할 수 있게 하였고, NVMe는 현대 멀티코어 CPU 아키텍쳐에 적합한 고성능 블록 인터페이스를 제공할 수 있게 하였다. 이들을 기점으로 SSD는 그전부터도 기존의 Spinning, 메커니컬 HDD 대비 더 좋은 성능과 에너지 효율 등이 장점이었지만, 이제는 사실상 가격 효율이라는 관점 외에는 모든 메트릭에서 더 이상 비교가 불가능할 정도로 우수한 저장장치가 되었다 (사실 QLC가 '양산'되기 시작한 요즘은 스토리지 용량 자체도 SSD가 더 높아지기 시작했다!).
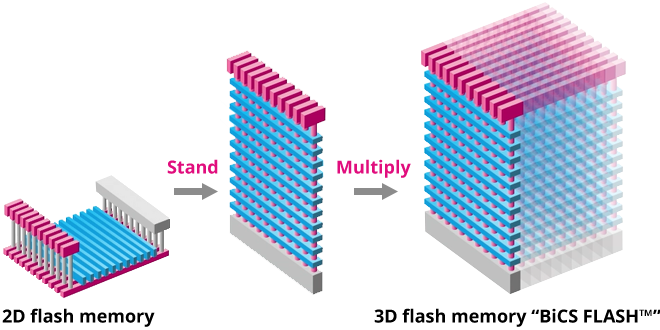 KIOXIA의 3D V-NAND Flash Memory 설명 그림 [link]
KIOXIA의 3D V-NAND Flash Memory 설명 그림 [link]
현대 엔지니어링의 정수로 손 꼽히는 3D NAND Flash Memory와 멀티 코어 최적화 프로토콜을 탑재한 하이엔드 SSD 제품의 등장으로, 이제는 사람들이 모두 행복하게 '빠르고 가볍고 작은 저장장치'를 그냥 쓰기만 하면 될거 같았다. 하지만 그러한 낙관은 그리 오래 가지 않았고, 2010년대 중후반을 넘어가면서, HDD로부터 비롯된 기존 블록 인터페이스를 활용해 SSD를 시스템에 붙이는 방식은 서서히 한계를 드러내기 시작했다. SSD를 단순히 "더 빠른 하드디스크"처럼 취급하는 것은 NAND Flash 고유의 특성과 장점을 충분히 활용하지 못하는 결과를 낳은 것이다.
 PCI Express 기반 NVM Express 데이터 통신 프로토콜 [link]
PCI Express 기반 NVM Express 데이터 통신 프로토콜 [link]
-
초기 NVMe만으로는 부족했다!: SATA (및 SAS)는 본래 단일 큐 기반의 고-Latency 디스크 접근을 위해 설계된 인터페이스이다. 고성능 SSD의 등장은 이 채널을 금세 포화시켰다. 2011년에서 2014년 사이에 등장한 NVMe는 처음으로 SSD 전용 Host Interface를 제공했으며, AHCI/SATA의 단일 명령 큐 구조에서 벗어나, 다중 큐 기반의 고성능 PCIe 인터페이스로 전환되었다. 이는 현대 SSD의 특징인 Parallelism과 낮은 Latency에 최적화된 구조였다. NVMe SSD는 이러한 구조 덕분에 훨씬 더 높은 IOPS와 낮은 Latency를 실현할 수 있었다. 그러나 초기 NVMe는 오로지 전통적 Block I/O Model을 유지했기 때문에 (왜? 당연히 시스템에 붙으려면 그럴 수밖에 없었다!), SSD는 여전히 고정 크기의 Sector를 갖는 Block Device로 host에 인식되었다.
-
Block Abstraction Limitation: SSD를 과거 HDD처럼 Black-box Block Device로 취급하게 되면, 호스트 단 응용이나 파일시스템은 SSD 내부 동작을 자세히 알 수 없다. Block I/O Model, 즉, 블록 인터페이스 하에선 호스트에서 할 수 있는 일을 오로지 "어떤 LBA에서 얼마만큼의 데이터를 쓸까/읽을까?"일 뿐이기 때문이다. 문제는, 후술하겠지만 SSD는 NAND Flash 자체에서 기인한 물리적 제약 때문에 내부에서 정말 다양한 일을 수행하는데, 그 '일'이라 하는 것은, 아무리 현대 SSD Controller SoC가 멀티 Arm Core를 탑재하고 그 내부 펌웨어에 스마트한 알고리즘을 사용한다하더라도, 결국 SSD I/O 성능의 갑작스런 하락과 불안정성을 만들어낸다. 호스트 단에서 이러한 SSD의 불안정한 성능을 고려해 특정한 예측 기법을 가미해 I/O 요청을 스마트하게 날리고자 하는 여러 연구들이 진행되었지만, 이 문제를 근본적으로 회피할 순 없었다.
문제를 더 심각하게 만든 것은, 소셜 미디어 서비스, 클라우드, 그리고 요즘엔 AI/ML을 필두로 흔히 말하는 '빅데이터' 시대가 오면서 애플리케이션은 SSD에 더 높은 성능과 용량을 요구하게 되었다는 것이다. 이때, 상기한 호스트-SSD 간의 비협조적인 구조는 SSD가 제공할 수 있는 잠재 성능과 실제 제공되는 성능 사이에 큰 격차를 발생시켰다. 호스트는 SSD의 특성과 현재 상황을 전혀 고려치 않은 채 굉장히 Intensive하게 계속해서 I/O를 발생시키고, SSD Controller는 이 모든 I/O 요청에 대해 앞선 '복잡한 일'을 지속적으로 처리해야 했다. 이로 인해 SSD는 (NAND Flash의 근본 특성에 의해) 바쁘게 일하고 있는데 그 와중에 동시에 호스트는 (블록 인터페이스에 의해) 아무것도 모른채 태평하게 계속해서 일을 요청하고, 하지만 SSD는 거기에 대응을 못하고 있으니 그냥 멀뚱멀뚱 기다려야만 하는, 그런 상황이 발생해버린 것이다.
이는 과거 HDD 시절엔 스토리지 자체가 호스트의 컴퓨팅에 비하면 뭐 비교가 불가능할 정도로 느리다보니 전혀 고려되지 않던 문제 사항이었으나, 이제는 고성능 SSD가 등장하면서, 하지만 고성능 SSD가 고성능을 제때제때 내지 못하면서, 문제가 되기 시작한 것이다. 이로 인해 빅데이터 환경에서 SSD의 성능 비효율과 불안정성은 더욱 극대화되었고 (아래 Figure1을 보자. 데이터 쓰기가 누적될수록 SSD 성능이 급격히 하락하는 모습을 확인할 수 있다), 이는 가격적 측면을 고려 시 고객들이 프로덕션 시에 그냥 느리더라도 (상대적으로) 안정적이고 값 싼 HDD를 계속 선택하도록 만들었다.
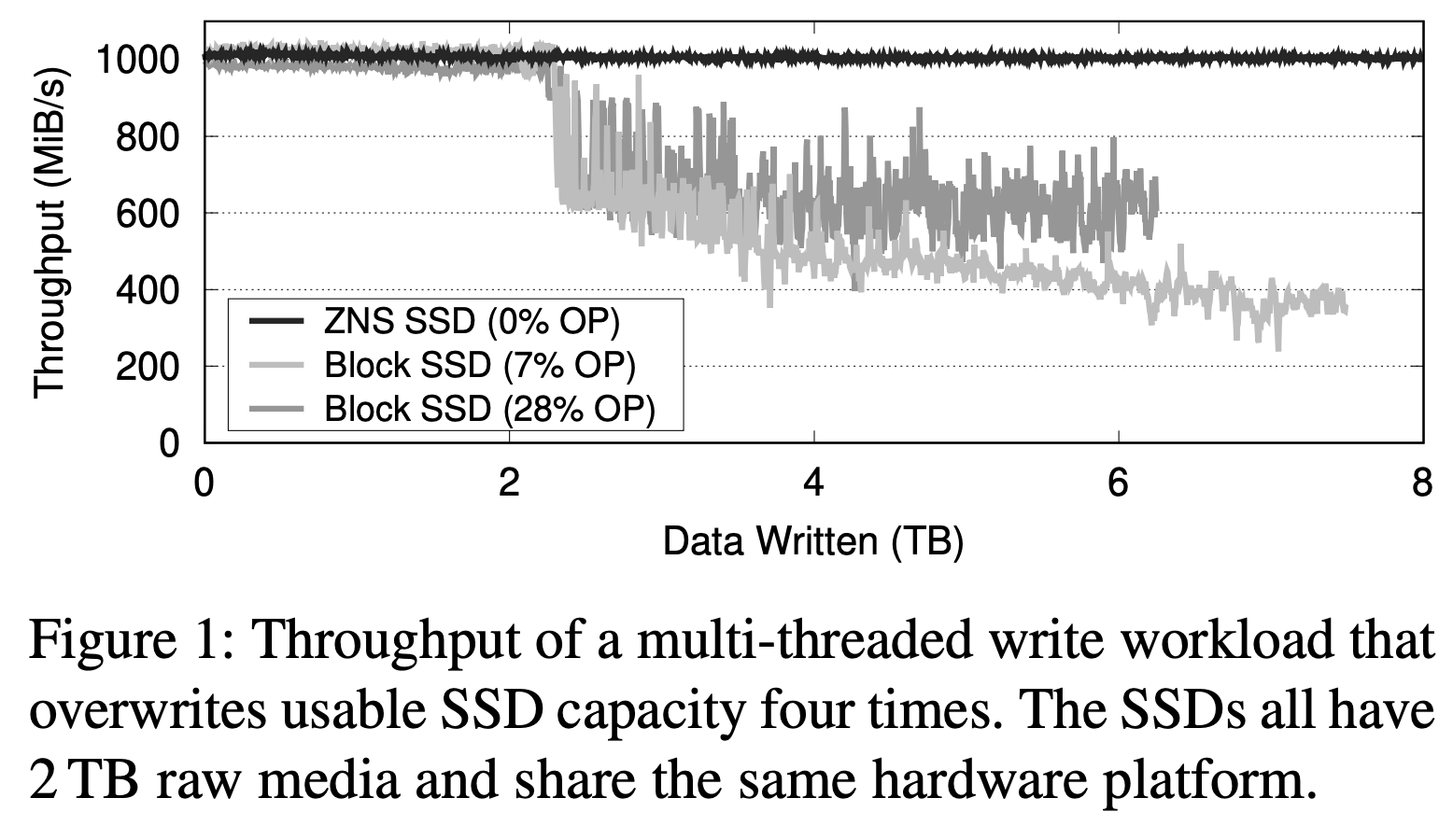 Figure from 'ZNS: Avoiding the Block Interface Tax for Flash-based SSDs [USENIX ATC '21]' (상기 캡션 참고) [link]
Figure from 'ZNS: Avoiding the Block Interface Tax for Flash-based SSDs [USENIX ATC '21]' (상기 캡션 참고) [link]
요약하자면, HDD 설계의 유산은 SSD의 초기 호환성과 빠른 채택에는 기여했지만, 동시에 SSD의 성능을 제한하는 병목으로 작용했다. HDD → SATA SSD의 상용화 → 3D NAND의 등장 → NVMe의 등장은 저장장치 그 자체의 최대 성능과 용량이 더 이상 주요 제약 요소가 아니게 만들었고, 이제는 저장장치 추상화 방식, 즉, Logical Interface에 대한 재고가 필요해지게 된 것이다. 이에 따라 Host의 저장장치 인식 방식과 SSD의 실제 동작을 보다 정합성 있게 맞추기 위한, SSD 특화된 새로운 추상화 모델과 표준들이 2010년대 후반부터 대거 등장하게 되었다.
아니, 그냥 I/O만 하면 되는거 아니야...? 왜 바쁜거야...?
초기 SSD는 (NAND Flash의 물리적 특성에서 기인한) 내부 펌웨어 로직의 복잡성을 단순한 < 블록 인터페이스 > 뒤에 숨겨, 디바이스가 알아서 할 일을 잘하고 호스트는 뭐 특별히 신경쓰지 않고 원래 I/O 하듯이 살면 되도록 만들어졌다. 이 덕분에 SSD는 Plug-and-Play 방식으로 쉽게 사용할 수 있게 되었지만, NAND Flash 고유의 제약과 Legacy Storage Stack의 비효율성으로 인해 빅데이터 워크로드에 대해 여러 문제를 맞닥들이게 됐다.
(1) SSD는 I/O만 하는게 아니야!
앞서 언급했듯, SSD가 '복잡한 일'을 수행하는 이유는 근본적으로 NAND Flash가 아래와 같은 특성 (제약 사항)을 가지기 때문이다.
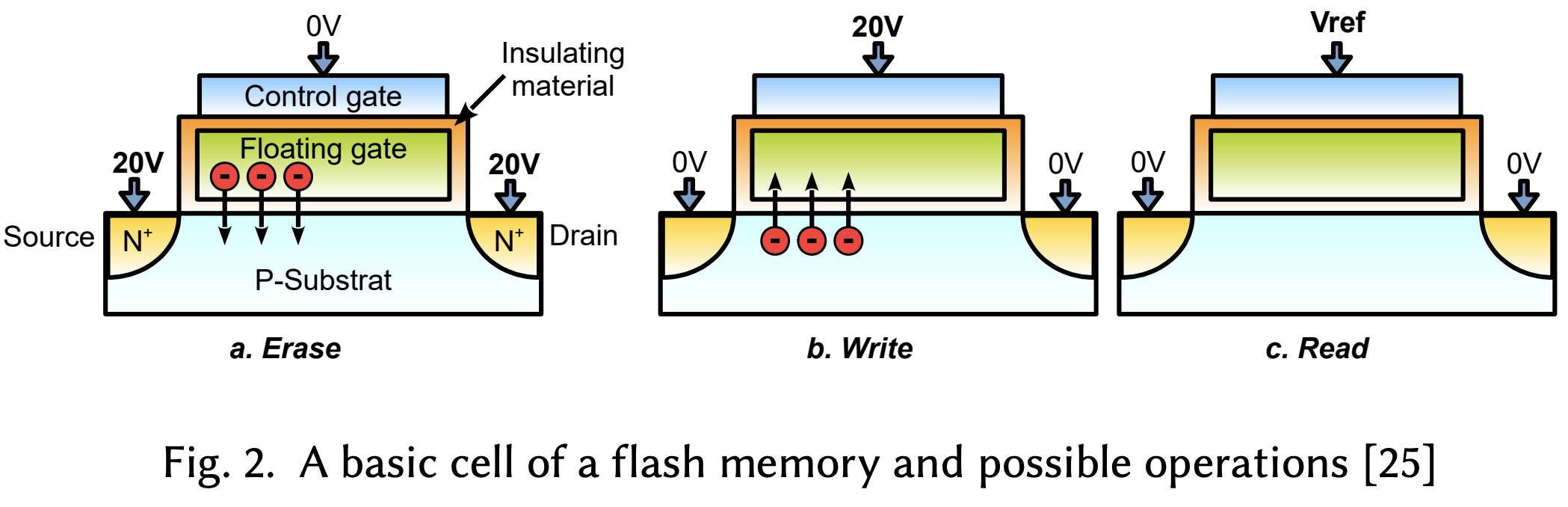 Figure from 'A Survey on Flash-Memory Storage Systems: A Host-Side Perspective [ACM Transactions on Storage '25]' (상기 캡션 참고) [link]
Figure from 'A Survey on Flash-Memory Storage Systems: A Host-Side Perspective [ACM Transactions on Storage '25]' (상기 캡션 참고) [link]
NAND Flash 제약 사항#1 - Page-Unit I/O & Block-Unit Erase: NAND Flash는 태생적으로 그 물리적 속성이 전기적 특성상 전하 삭제 (Erase Operation)에 높은 전압이 필요하고, 이 전압을 개별 Page (I/O 단위)에 정밀하게 걸 수 없기 때문에 Block 단위로만 Erase가 가능하며, 반면 Read/Write는 상대적으로 낮은 전압으로 Page 단위 접근이 가능하다.
NAND Flash 제약 사항#2 - Erase-Before-Write: NAND Flash는 그 근간의 Floating Gate Array 특성상 데이터를 제자리에서 덮어쓸 수 없으며, 다시 쓰기 전에 해당 Block을 지워야한다.
이로 인해 SSD Controller는 Log-Structured 방식으로 발전했다. 데이터가 업데이트될 경우, 새 Page에 기록하고 이전 Page는 무효화한다. 시간이 지나면 무효 Page가 누적되므로, Controller는 Garbage Collection (GC)을 실행해 공간을 회수한다. GC는 하나 이상의 Block을 Victim Block으로 선택하고, 여전히 유효한 데이터를 복사한 뒤 해당 Block을 지운다. 이 과정은 Host가 요청하지 않은 (Aware하고 있지 않은) 추가적인 NAND I/O를 발생시키며, Write Amplification Factor (WAF)로 나타난다. WAF는 (SSD가 실제로 수행한 쓰기량 / Host가 요청한 쓰기량)의 비율로, 특히 랜덤 업데이트 패턴에서 매우 높아질 수 있다. 이는 Host가 인식하는 것보다 SSD가 훨씬 많은 작업을 수행하고 더 빨리 마모됨을 의미한다.
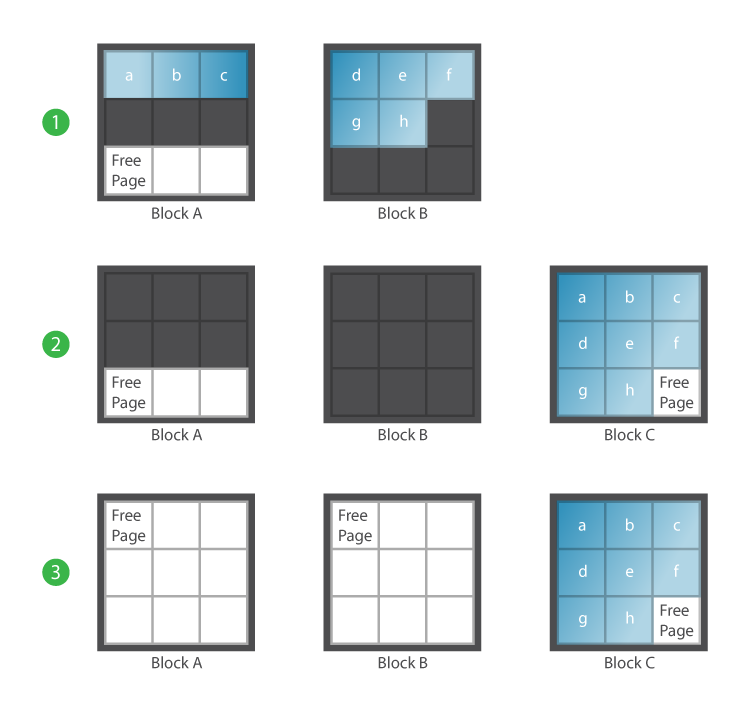 Garbage Collection을 통한 Free NAND Page 확보 [link]
Garbage Collection을 통한 Free NAND Page 확보 [link]
NAND Flash 제약 사항#3 - Limited Program/Erase Cycle: NAND Flash는 Erase 시 높은 전압으로 Flash Cell (e.g., Charge Flash Trap)에 물리적 스트레스가 누적되기 때문에, Program/Erase (P/E) Cycle 횟수에 한계가 있어 수명이 제한된다.
GC 외에도 NAND Flash는 그 태생적으로 SSD 내부에서 Wear Leveling, Bad Block Management, Error Correction 등을 필요로 한다. NAND Flash의 최소 Unit인 Cell은 데이터 저장/읽기 과정에서 전자를 계속 충전하고 빼고 반복해야 하는데, 그 작업이 물리적인 한계로 인해 최대 가능한 횟수가 생산 시점부터 정해진다 (이 횟수는 참고로 SLC에서 QLC로 갈수록 더 줄어든다. QLC의 경우 1만회 정도로 알려져 있다). 이로 인해 같은 Cell에 데이터를 계속 반복해서 쓰기보다는 여러 Cell에 분산해서 쓰는게 필연적으로 마모를 줄일 수 있는 길이고, 그에 따라 Wear Leveling이라는 작업을 수행한다.
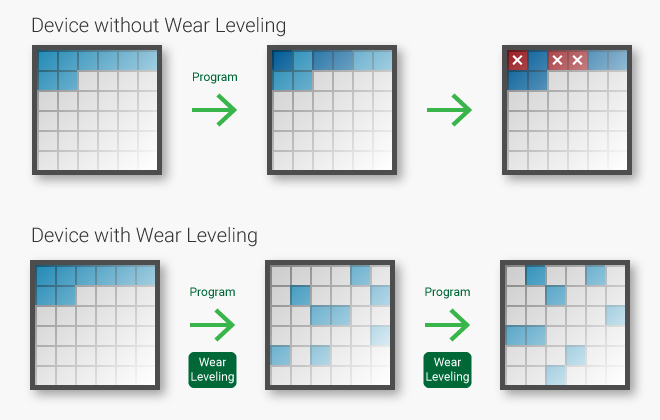 Wear Leveling을 통한 NAND Flash 수명 연장 [link]
Wear Leveling을 통한 NAND Flash 수명 연장 [link]
또한, 3D NAND와 같이 집적도가 매우 높은 마이크로한 월드에선 한 Cell에 I/O, Erase를 수행하는게 (물론 실제론 Page 단위로 쓰고 Block 단위로 지우지만 설명의 편의를 위해 생략) 간헐적으로 다른 Cell의 전자 상태에 영향을 줄 수 있고, 이게 Bit-Flip과 같은 저장 정보의 왜곡 문제로 이어질 수 있어, 이에 대한 Error Correction Code (ECC)와 같은 작업도 필수적이다.
 SSD Controller System-on-Chip (SoC, 빨간색)과 DRAM/SRAM (노란색), NAND Flash Chips (파란색)로 이뤄진 SSD의 모습 [link]
SSD Controller System-on-Chip (SoC, 빨간색)과 DRAM/SRAM (노란색), NAND Flash Chips (파란색)로 이뤄진 SSD의 모습 [link]
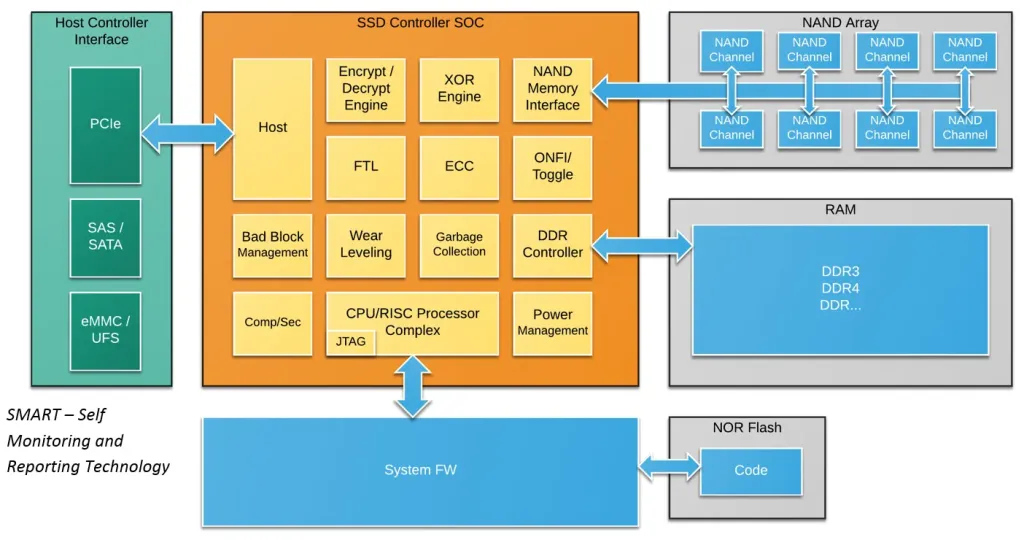 기본적인 Address Translation (호스트의 LBA로부터 NAND Page/Block을 결정)부터 Garbage Collection, ECC, Wear Leveling, 그리고 거기에 더해 Host Interface (e.g., NVMe)와 Flash Interface (e.g., ONFI) 등, 너무나 많은 작업을 수행하는 SSD Controller [link]
기본적인 Address Translation (호스트의 LBA로부터 NAND Page/Block을 결정)부터 Garbage Collection, ECC, Wear Leveling, 그리고 거기에 더해 Host Interface (e.g., NVMe)와 Flash Interface (e.g., ONFI) 등, 너무나 많은 작업을 수행하는 SSD Controller [link]
이러한 SSD의 백그라운드 작업들 (e.g., Wear Leveling, ECC)은 Host I/O와 충돌할 수 있다. 예를 들어, SSD에 사전 Erase된 Block이 없을 때 Host가 Write를 요청하면, SSD는 데이터를 이동하거나 Block 지우느라 작업을 멈춰야 하며, 이로 인해 Latency Spike가 발생한다. 평소 수십 μs에 처리되던 write가 GC 중에는 수 밀리초로 지연될 수 있다. 이러한 지터 (jitter)는 안정적 성능이 중요한 시스템에서 큰 문제다. 이를 해결하기 위해 SSD 내부에 Over-Provisioning (OP)이나 병렬 GC가 가능한 고성능 알고리즘를 탑재하곤 하지만, 이는 비용 증가로 이어지고, 아무리 OP를 많이 할당하더라도 데이터 쏟아지는 시나리오에선 결국 그 끝에 다다르면 Spike가 비일비재해질 수 밖에 없다.
(2) 이와중에 Host도 너무 바빠!
호스트 단 스토리지 스택 (파일시스템, 커널 I/O 스케줄러, 디바이스 드라이버 등)은 과거 HDD와 같은 Spinning 저장장치 시절부터 차근차근 구축되어 올려진, 오랜 시간에 걸친 유산이다. 현대 상용 NVMe SSD도 마찬가지로 이러한 스토리지 스택을 토대로 호스트와 커넥션을 이뤄 I/O를 수행한다 (Intel SPDK와 같은 툴은 논외로 한다). 이러한 스토리지 스택에서 발생시키는 OS/파일시스템의 소프트웨어 오버헤드는 과거 밀리초 단위의 I/O 서비스를 제공하는 저장장치들에 대해선 전체 성능에서 큰 비중을 차지하지 않았고, 따라서 특별히 '문제의 대상'이 되지 않았다.
하지만, NVMe SSD는 기본적으로 수십 마이크로초 단위의 레이턴시와 수십만 IOPS 이상의 성능을 제공하고, 이에 따라 시각이 달리지기 시작했다. 이제는 디바이스 자체의 처리속도보다, 그에 명령을 전달하는 소프트웨어 스택의 처리속도가 상대적으로 더 느려지는 상황이 발생하게 된 것이다. NVMe 등장에 맞춰 개발된, 현재 리눅스 커널의 기본으로 자리 잡은 blk-mq와 같은 멀티큐 서포트가 이뤄지더라도 소프트웨어 스택 오버헤드는 상당했다. 응용이 Write System Call을 요청한다고 하면, 그에 대한 I/O 요청이 디바이스에 도달하기까지 해당 요청은 파일시스템, I/O 스케줄러, Block Layer, NVMe 드라이버 등 여러 커널 계층을 거치는데, 이 오버헤드가 상당하다는 것이다. 경우에 따라선 전체 I/O Latency의 70% 이상이 소프트웨어에서 발생한다고 알려진다 (아래 그림 참고). 결론적으로, SSD가 빠르기 때문에 전체 I/O 성능은 더 빨라졌지만, 그만큼 기존 블록 인터페이스 기반의 소프트웨어 스택이 상대적으로 병목으로 작용하게 되기 시작했다.
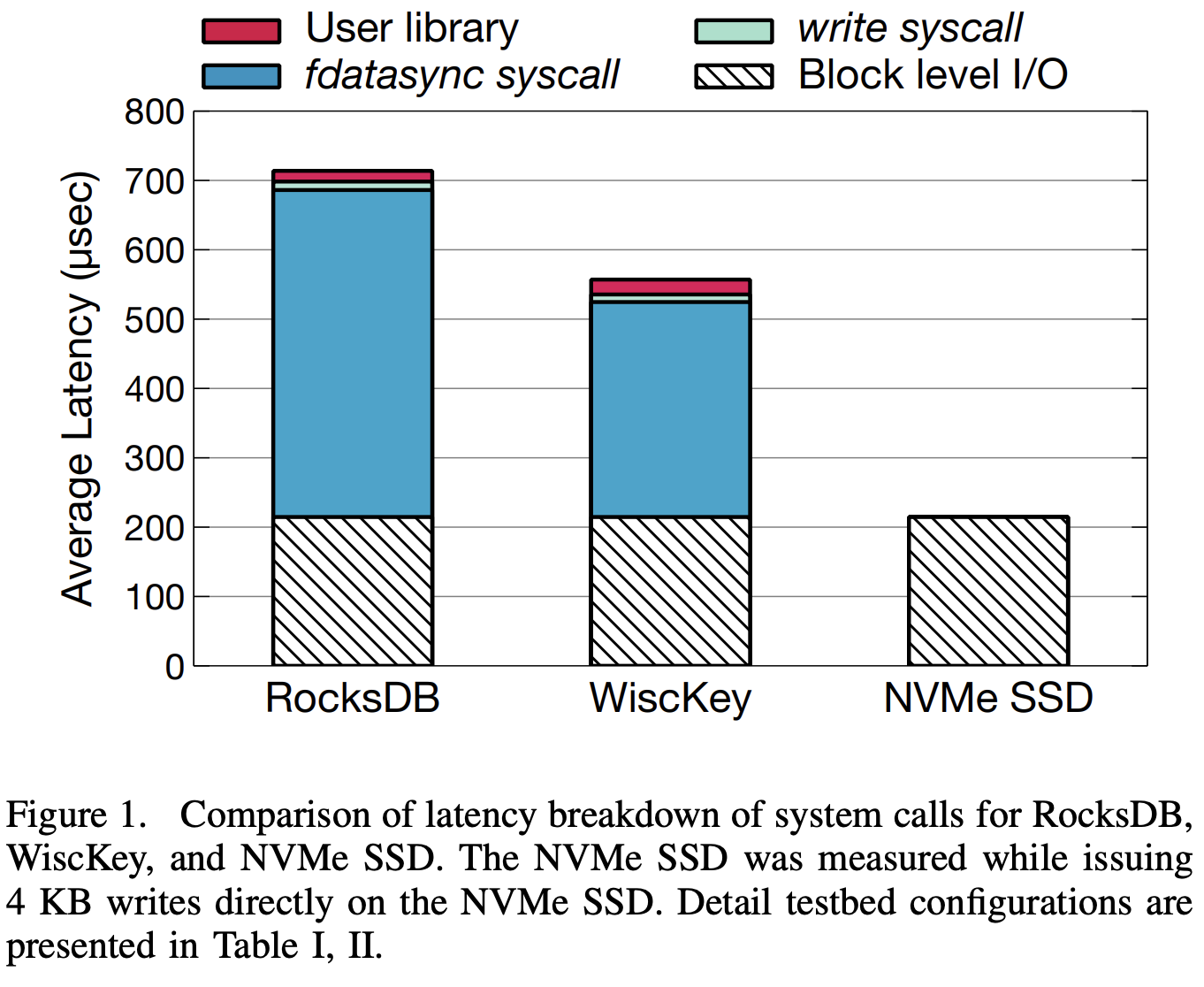 Figure from 'iLSM-SSD: An Intelligent LSM-tree based Key-Value SSD for Data Analytics [MASCOTS '19]' (캡션 참고) [link]
Figure from 'iLSM-SSD: An Intelligent LSM-tree based Key-Value SSD for Data Analytics [MASCOTS '19]' (캡션 참고) [link]
전반적으로, 전통적인 SSD 설계는 Host와 Device 간의 협업 부족에서 비롯된 어려움을 겪는다. SSD Controller SoC가 구동하는 펌웨어의 일부인 Flash Translation Layer (FTL)은 Wear Leveling과 GC를 위해 데이터를 끊임없이 이동시키고, Host OS는 이 동작을 전혀 인지하지 못한 채 스스로 '바쁘게' I/O를 발생시켜 SSD 내부와 호스트 자신에게 과도한 부하를 유발시키고 있는 것이다. 즉, Block 추상화는 마치 벽처럼 동작하여 협업적인 최적의 Flash 관리를 방해하고, 결과적으로 성능 저하와 불안정, 수명 단축이라는 문제로 이어지는 것이다. 이러한 문제들이 연구자들과 업계로 하여금 Host-Device 간 정보 격차와 양단의 소프트웨어 스택 오버헤드를 줄일 수 있는 새로운 인터페이스 방식을 고민하게 만들었고, 이는 다음 회차에서 소개할 기술들의 출발점이 되었다.
본 포스팅은 올해 초 ACM Transactions on Storage에 연달아 올라온, 현대 SSD 추상화에 관한 두 편의 훌륭한 서베이 논문 (paper1, paper2)을 기반으로 하며, SSD 연구 흐름을 내 스스로 정리해보고 외부에도 가볍게 소개해보는 목적으로 작성하였다. 이 글을 읽고 흥미가 생긴다면 이 두 논문을 실제로 읽어보길 권한다!
본 글에 담긴 Claim격의 서술은 모두 제 개인의 의견일 뿐이며 아무런 대표성을 가지지 않습니다.
