개념
해시테이블(Hash Table)은 키(Key)를 값(Value)에 매핑하여 저장하는 자료구조이다. 두가지 데이터를 연결하여 저장하는 자료구조라고도 할 수 있다. 배열에서는 인덱스를 가지고 값을 찾지만(array[index]), 해시테이블을 이용하면 인덱스가 아닌 키로 매칭되는 값을 찾을 수 있다. 전화번호부에서 이름-전화번호 를 키-값이라고 생각하면 되겠다.
컴퓨터는 모든 것을 숫자로 표현하기 때문에 주어진 '키' 를 숫자로 바꿔주는 과정이 필요하다. 그리고 되도록이면 이 숫자가 중복되지 않으면 좋겠다. 이 역할을 하는 것이 해시(Hash)함수이다. 해시 함수는 주어진 키를 적절히 계산하여 숫자로 변환하여 배열의 인덱스를 반환하고, 반환된 값을 해시 코드(Hash code)라고 한다.
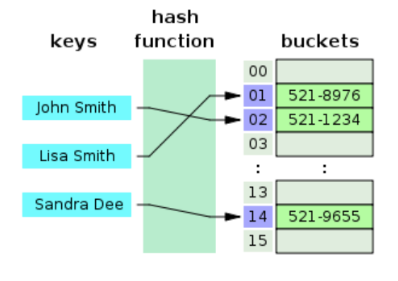
다음은 구글에 해시테이블을 검색하면 빠지지 않고 등장하는 그림이다. 이 그림을 이용하여 해시테이블에 데이터를 저장하는 과정과 데이터를 읽어오는 과정을 생각해보겠다.
데이터 입력
해시 테이블에 John Smith - 521-1234의 데이터를 저장하라는 명령어가 들어왔다. 먼저 John Smith라는 문자열은 hash function을 지나 해시코드로 바뀐다. 이 해시코드는 배열 buckets의 인덱스로 사용되고, 521-1234가 buckets에 저장된다.
데이터 호출
John Smith의 전화번호를 알고 싶다. 데이터를 저장할 때와 마찬가지로, John Smith라는 문자열은 hash function을 지나 해시코드로 바뀐다. 이 해시코드를 인덱스로 하여 배열 buckets에서 값을 불러온다.
해시 충돌(Hash collision)
주어진 키를 해시함수를 통해 특정 숫자(해시 코드)로 바꿔주는 과정이 해시테이블의 핵심이다. 위에서 되도록이면 이 숫자가 중복되지 않아야 한다 라고 언급했지만, 사실 중복되지 않는 것은 불가능하다. 최대한 중복되지 않도록 해시 함수를 작성하는 것이 최선일 뿐이다.
주어진 키를 해시 코드로 바꾸는 방법 중 하나는 아스키코드를 이용하는 것이다. 주어진 키를 이루는 문자의 아스키코드를 더하고 빼고 곱하고 나누면 키마다 다른 값을 얻을 수 있다. 하지만 이마저도 충돌을 피할 수는 없다. jordan 과 dorjan의 해시 코드는 같을테니까. 충돌을 해결하는 방법으로는 체이닝 기법(Chaining)과 개방주소법(Open Addressing)이 있다.
