
Stack
기본 개념
stack(스택)은 LIFO(Last In First Out)를 따르는 자료구조이다. 바닥에 책을 쌓은 다음, 다시 한권 씩 들어올릴 때 가장 위의 책부터 들어올리게된다. 주로 사용하게 되는 메소드는 pop()과 push() 가 있고, 각각 스택에 자료를 빼고 넣는 역할을 한다. 그림을 통해 스택의 동작 과정을 보자.
push(1) - push(5) - push(7) - pop() - push(10) - push(3) - pop()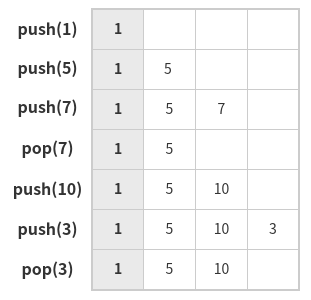
구성 요소
구성요소를 살펴보자. 모든 Object는 property(프로퍼티)와 method(메소드)로 구성되어있다. 스택의 핵심 기능은 넣고, 빼고, 읽는 것이다.
메소드
- 스택에 데이터를 넣는 push()
- 스택의 최상위 값을 가져오는 pop()
- 스택이 비었는지를 확인하는 isEmpty()
- 스택이 꽉차 있는지를 확인하는 isFull()
프로퍼티
- 저장 공간 역할을 하는 배열
Psuedo Code
Queue
기본 개념
스택이 LIFO 였다면, Queue(큐)는 FIFO(First In First Out)이다. 말그대로 가장 먼저 들어왔던 데이터가 가장 먼저 빠져나간다. 큐의 종류는 두가지로, 하나는 선형(linear) 큐이고 다른 하나는 환형(circular) 큐이다. 기본적인 동작 원리는 아래 그림과 같다(선형큐).
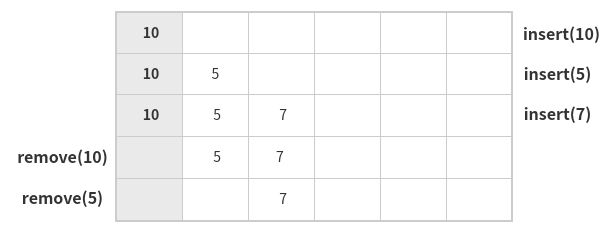
선형큐와 환형큐의 비교
선형큐는 앞서 설명한 대로, 먼저 들어온 데이터가 먼저 빠져나가는 자료구조이다. 이때 저장공간이 비어있을 때 데이터를 꺼내려고 하거나 저장공간이 꽉차 있을 때 데이터를 넣으려고 하면 각각 언더플로우(underflow)와 오버플로우(overflow)에러가 발생한다. 또한, 데이터의 양이 많아지면 단순히 맨 앞의 데이터를 꺼내는 동작 한번에 모든 데이터가 움직여야 하는 비효율이 생길 수 있다는 단점이 있다.
환형큐는 위에서 언급한 선형큐의 데이터 공간을 효율적으로 사용하지 못하는 문제점을 보완한 자료구조이다. 아래 두번째 그림에서 보면 3개의 데이터를 저장하기 위해 길이가 4개짜리 배열을 사용하고 있다. 이는 front 와 rear 의 위치를 계속 바꿔가며 주어진 배열이 마치 원을 이루고 있는 것처럼 구현하기 위함이다. 자세한 내용은 다른 포스트에서.
선형 큐에서의 오버플로우
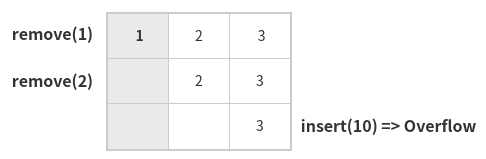
선형 큐의 오버플로우 문제를 보완한 환형 큐
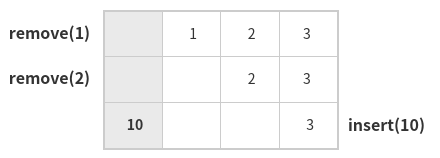
구성 요소
메소드
- 배열의 맨 뒷 부분에 데이터를 넣는 insert() 혹은 enqueue()
- 배열 맨 앞에 위치한 데이터를(front가 가리키는) 지우는 remove() 혹은 dequeue()
- 배열 맨 앞의 데이터를(front가 가리키는) 읽는 peek()
프로퍼티
- 가장 앞에 위치한 데이터를 가리키는 front
- 가장 뒤에 위치한 데이터를 가리키는 rear
Psuedo Code
