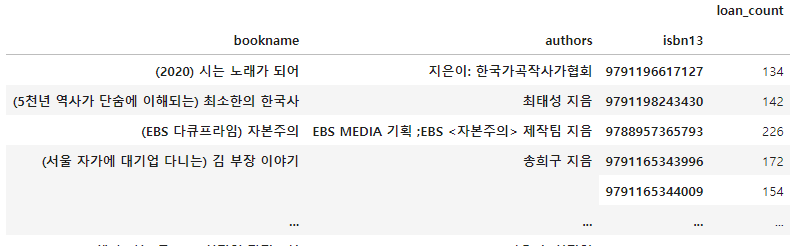
API 사용하여 DataFrame 에 저장
import requests
import pandas as pd
import json
# 인증 키 및 url
authkey= '626aa71863ae6a014b9fb05f6979f61014cd3e4eab866284d958151e9390b694'
url = 'http://data4library.kr/api/loanItemSrch?authKey={}&startDt=2024-01-01&endDt=2024-02-02&age=20&format=json'.format(authkey)
# json 객체를 파이썬 객체로 변환
r =json.loads(requests.get(url).text)
# 변환된 파이썬 객체를 pandas.DataFrame으로 저장
books = []
for book in r['response']['docs']:
books.append(book['doc'])
books_df = pd.DataFrame(books)books_df
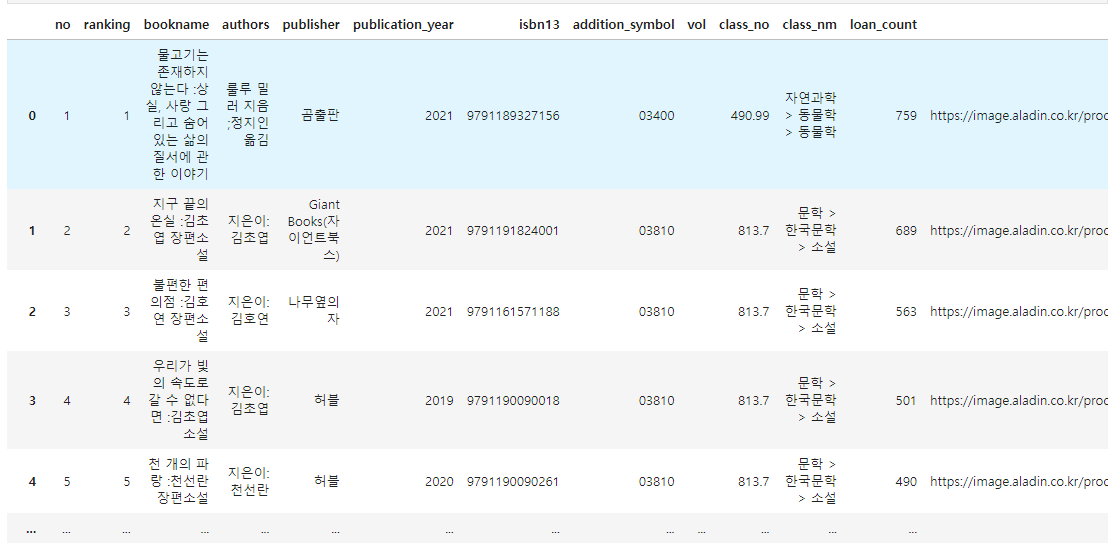
DataFrame.loc() / DataFrame.drop() / DataFrame.duplicated()
# bookname ~ class_nm 열에 해당하는 모든 행 출력
ns_books_df = books_df.loc[:,'bookname':'class_nm']
# drop() : 열 삭제
# 'addition_symbol' 열 삭제
removed_books_df = modified_books_df.drop('addition_symbol', axis='columns')
# 10~14 행의 bookname~publication_year 열 출력
ns_books_2 = books_df.loc[10:15, 'bookname':'publication_year']
# 10~14 행 출력(모든 열)
ns_books_2 = books_df[10:15]
# 대출 횟수(lean_count) 1000 회 이상인 책 목록
ns_book_2 = books_df[books_df['loan_count'] >= 500]
# dup_rows: authors, publisher, isbn13을 기준으로, 중복된 행을 모두 True로 표시한 배열
dup_rows = books_df.duplicated(subset = ['authors','publisher','isbn13'], keep=False)
dup_books = books_df.loc[dup_rows]Boolean 사용
# publisher = 문학동네 인 행 만 출력
selected_publisher = books_df['publisher'] == '문학동네'
ns_book_2 = books_df[selected_publisher]```
# 'class_no' 열 만 제외하는 Boolean 배열
selected_columns = ns_books_df.columns != 'class_no'
modified_books_df = ns_books_df.loc[:,selected_columns]DataFrame.groupby()
count_df = books_df[['bookname', 'authors', 'isbn13', 'loan_count']]
loan_count = count_df.groupby(by = ['bookname','authors','isbn13'], dropna = False).sum()