Ensemble : 모델 서브클래싱 방식으로 모델 클래스를 만들고, 그 인스턴스를 여러 개를 각각 학습시켜 좋은 성능을 낼 수 있게 한다.
변경점
- 신경망 모델 구축 — tf.keras 사용 (실제 모델 클래스는 동일하지만, 인스턴스를 여러 개 생성)
- 모델 성능 지표 정의 — 정확도 (여러 모델의 output을 종합해서 계산)
- 신경망 모델 학습 및 검증 (여러 개 모델을 동시에 학습)
모델 구조 개념
모델 이미지 참조
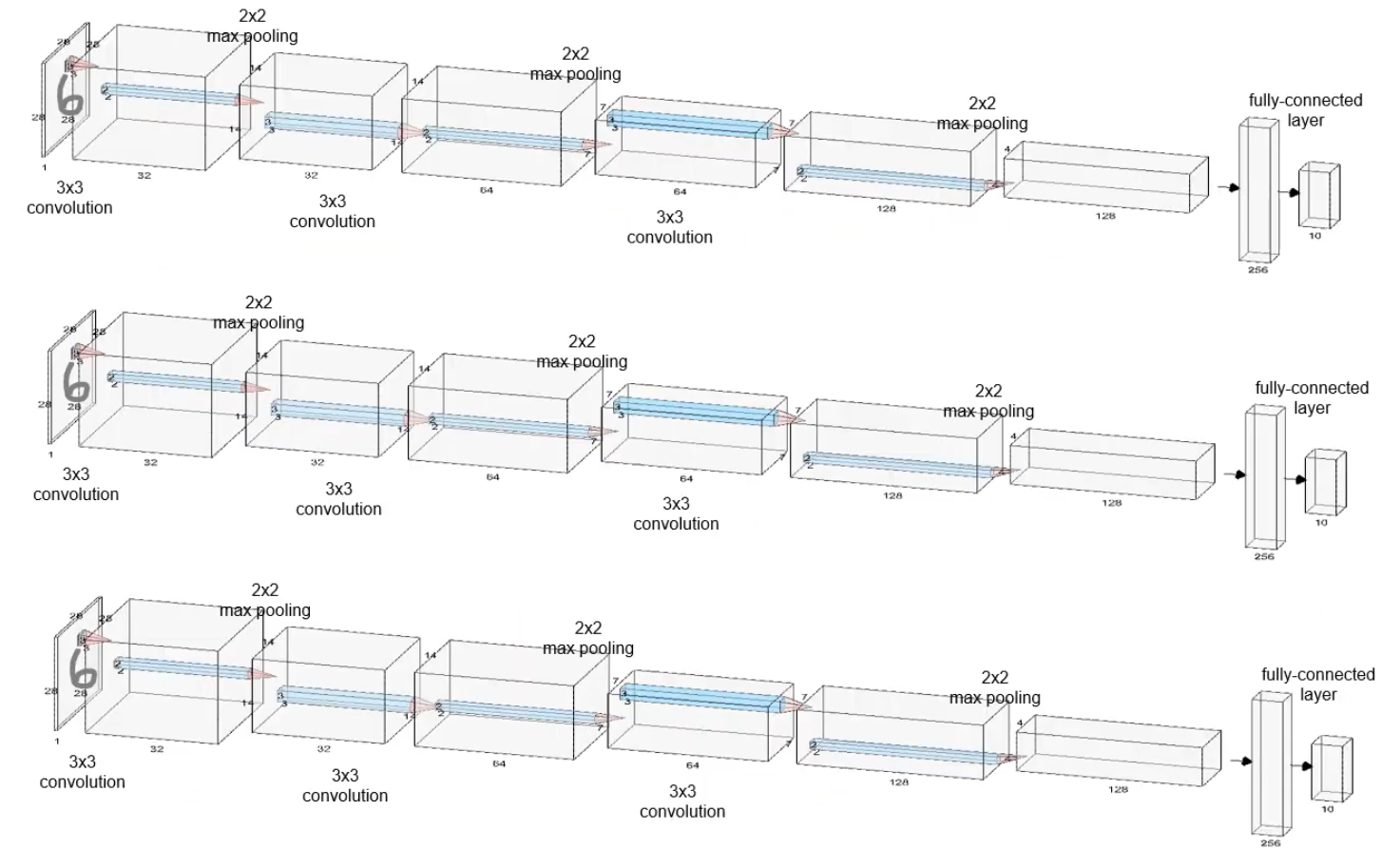
각 CNN에 각각의 Input을 넣고, 각 output을 더해서 하나의 최종 logits로 만든 뒤, 그 결과를 이용해 분류를 수행하는 구조이다.
3. 신경망 모델 구축 (Model Subclassing + Ensemble)
class MNISTModel(tf.keras.Model):
def __init__(self):
super(MNISTModel, self).__init__()
self.conv1 = keras.layers.Conv2D(
filters=32,
kernel_size=3,
padding='SAME',
activation=tf.nn.relu,
)
self.pool1 = keras.layers.MaxPool2D(padding='SAME')
self.conv2 = keras.layers.Conv2D(
filters=64,
kernel_size=3,
padding='SAME',
activation=tf.nn.relu,
)
self.pool2 = keras.layers.MaxPool2D(padding='SAME')
self.conv3 = keras.layers.Conv2D(
filters=128,
kernel_size=3,
padding='SAME',
activation=tf.nn.relu,
)
self.pool3 = keras.layers.MaxPool2D(padding='SAME')
self.pool3_flat = keras.layers.Flatten()
self.dense4 = keras.layers.Dense(units=256, activation=tf.nn.relu)
self.drop4 = keras.layers.Dropout(rate=0.4)
self.dense5 = keras.layers.Dense(units=10)
def call(self, inputs, training=False):
net = self.conv1(inputs)
net = self.pool1(net)
net = self.conv2(net)
net = self.pool2(net)
net = self.conv3(net)
net = self.pool3(net)
net = self.pool3_flat(net)
net = self.dense4(net)
net = self.drop4(net)
net = self.dense5(net)
return net
# 모델의 인스턴스를 3개 생성
models = []
num_models = 3
for m in range(num_models):
models.append(MNISTModel())7. 모델 성능 지표 정의 (Ensemble 평가)
여러 개의 모델에서 나온 logits를 모두 더한 뒤, 그 합에 대해 softmax / argmax를 사용해 최종 예측을 만든다.
# 여러 개의 모델에서 나온 정확도를 계산함
def evaluate(models, images, labels):
# 모델 3개에서 나온 output을 종합한 결과 (초기값 0)
predictions = tf.zeros_like(labels)
for model in models:
logits = model(images, training=False)
predictions += logits
correct_prediction = tf.equal(
tf.argmax(predictions, 1),
tf.argmax(labels, 1),
)
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
return accuracy9. 신경망 모델 학습 및 검증 (Ensemble 학습 루프)
기본 CNN 학습 루프와 구조는 같지만,
각 배치마다 models 리스트에 있는 모델들을 모두 한 번씩 학습시키고,
정확도 계산은 항상 ensemble 결과(evaluate(models, ...))를 사용한다.
# 예시: 각 모델별 체크포인트 리스트 (이미 정의된 checkpoint_prefix 사용)
checkpoints = [
tf.train.Checkpoint(cnn=model)
for model in models
]
# 기존에는 에폭 1번, dataset 1번 이렇게 2중 for문이었지만,
# 지금은 모델별 for문이 하나 더 추가되었다.
for epoch in range(training_epochs):
avg_loss = 0.0
avg_train_acc = 0.0
avg_test_acc = 0.0
train_step = 0
test_step = 0
# 학습 루프
for images, labels in train_dataset:
for model in models:
grads = grad(model, images, labels)
optimizer.apply_gradients(zip(grads, model.variables))
loss = loss_fn(model, images, labels)
avg_loss += loss / num_models
acc = evaluate(models, images, labels)
avg_train_acc = avg_train_acc + acc
train_step += 1
avg_loss = avg_loss / float(train_step)
avg_train_acc = avg_train_acc / float(train_step)
# 평가 루프
for images, labels in test_dataset:
acc = evaluate(models, images, labels)
avg_test_acc = avg_test_acc + acc
test_step += 1
avg_test_acc = avg_test_acc / float(test_step)
print(
"Epoch: ",
"{}".format(epoch + 1),
"loss = ",
"{:.8f}".format(avg_loss),
"train accuracy = ",
"{:.4f}".format(avg_train_acc),
"test accuracy = ",
"{:.4f}".format(avg_test_acc),
)
# 각 모델별 체크포인트 저장
for idx, checkpoint in enumerate(checkpoints):
checkpoint.save(file_prefix=checkpoint_prefix)최고 성능을 얻는 방법
- 데이터 증강
- 배치 정규화
- 모델 앙상블
- 학습률 감소
| 방법 | 목적 | 구현 포인트 | 주의점 |
|---|---|---|---|
| 데이터 증강 | 데이터 다양성 증가로 과적합 완화 | 회전, 이동(shift) | 증강 후 데이터 크기 급증 |
| 배치 정규화 | 학습 안정화, 수렴 개선 | BN 레이어, training 플래그 전달 | training 전달 안 하면 효과 저하 |
| 모델 앙상블 | 여러 모델의 예측을 합쳐 성능 개선 | logits 합산 후 argmax | 학습 비용 증가 |
| 학습률 감소 | 후반 학습 안정화 | ExponentialDecay 스케줄 | decay_steps 계산이 중요 |
변경점
- 데이터 증강 — 회전 및 이동 (추가됨)
- 신경망 모델 구축 — tf.keras 사용 (모델 클래스는 동일, 인스턴스를 여러 개 생성)
- 모델 성능 지표 정의 — 정확도 (모델 output이 여러 개이므로 합산 후 정확도 계산)
- 신경망 모델 학습 및 검증 — 여러 개의 트레이닝 데이터(모델별) 발생
0. Import Libraries
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras.utils import to_categorical
import numpy as np
import matplotlib.pyplot as plt
import os
from scipy import ndimage # 이미지 rotation 및 shift를 쉽게 해 주는 ndimage 라이브러리2. 데이터 증강 (rotation + shift)
- 이미지 회전/이동 시 빈 공간이 생기므로, 해당 공간을 bg_value(중간값)로 채웁니다.
- for문 4번 반복: 원본 1장 + 증강 4장 = 총 5배 데이터가 됩니다.
def data_augmentation(images, labels):
# 증강된 이미지와 라벨을 담을 리스트
aug_images = []
aug_labels = []
for x, y in zip(images, labels):
# 원본도 포함
aug_images.append(x)
aug_labels.append(y)
# 이미지 회전/이동 시 생기는 빈 공간을 채울 값(배경값)
bg_value = np.median(x)
# 원본 1장 + 4장 증강 = 총 5배
for _ in range(4):
# -15 ~ 15 도 회전 (정수 각도)
angle = int(np.random.randint(-15, 16))
rot_img = ndimage.rotate(x, angle, reshape=False, cval=bg_value)
# -2 ~ 2 픽셀 이동 (x축, y축)
shift = np.random.randint(-2, 3, size=2)
shift_img = ndimage.shift(rot_img, shift, cval=bg_value)
aug_images.append(shift_img)
aug_labels.append(y)
aug_images = np.array(aug_images)
aug_labels = np.array(aug_labels)
return aug_images, aug_labels3. 데이터 파이프라인 구성
mnist = keras.datasets.mnist
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
# 데이터 증강
train_images, train_labels = data_augmentation(train_images, train_labels)
train_images = train_images.astype(np.float32) / 255.0
test_images = test_images.astype(np.float32) / 255.0
# (N, 28, 28) -> (N, 28, 28, 1)
train_images = np.expand_dims(train_images, axis=-1)
test_images = np.expand_dims(test_images, axis=-1)
# one-hot encoding
train_labels = to_categorical(train_labels, 10)
test_labels = to_categorical(test_labels, 10)
# batch_size 는 하이퍼파라미터로 미리 정의되어 있어야 함
train_dataset = (
tf.data.Dataset.from_tensor_slices((train_images, train_labels))
.shuffle(buffer_size=500000) # buffer 사이즈 증가
.batch(batch_size)
)
test_dataset = (
tf.data.Dataset.from_tensor_slices((test_images, test_labels))
.batch(batch_size)
)4. 신경망 모델 구축
- 작은 블록: Input -> Conv -> BN -> ReLU
- Dense도 동일하게 Dense -> BN -> ReLU
- 모델 인스턴스를 여러 개 만들어 앙상블 준비
# tf.keras.Model의 subclass를 만들어서 Model Subclassing 하던 방식대로 작은 cnn을 만든다.
# Input -> Conv -> BN -> ReLu 순서의 작은 네트워크가 있다고 생각하면 된다.
class ConvBNRelu(tf.keras.Model):
def __init__(self, filters, kernel_size=3, strides=1, padding='same'):
super(ConvBNRelu, self).__init__()
self.conv = keras.layers.Conv2D(
filters=filters,
kernel_size=kernel_size,
strides=strides,
padding=padding,
kernel_initializer='glorot_normal' # default glorot_uniform -> glorot_normal
)
self.batchnorm = tf.keras.layers.BatchNormalization()
def call(self, inputs, training=False):
layer = self.conv(inputs)
layer = self.batchnorm(layer, training=training)
layer = tf.nn.relu(layer)
return layer
# Dense -> BN -> ReLU 블록
class DenseBNRelu(tf.keras.Model):
def __init__(self, units):
super(DenseBNRelu, self).__init__()
self.dense = keras.layers.Dense(
units=units,
kernel_initializer='glorot_normal'
)
self.batchnorm = tf.keras.layers.BatchNormalization()
def call(self, inputs, training=False):
layer = self.dense(inputs)
layer = self.batchnorm(layer, training=training)
layer = tf.nn.relu(layer)
return layer
class MNISTModel(tf.keras.Model):
def __init__(self):
super(MNISTModel, self).__init__()
self.conv1 = ConvBNRelu(filters=32, kernel_size=3, padding='same')
self.pool1 = keras.layers.MaxPool2D(padding='same')
self.conv2 = ConvBNRelu(filters=64, kernel_size=3, padding='same')
self.pool2 = keras.layers.MaxPool2D(padding='same')
self.conv3 = ConvBNRelu(filters=128, kernel_size=3, padding='same')
self.pool3 = keras.layers.MaxPool2D(padding='same')
self.pool3_flat = keras.layers.Flatten()
self.dense4 = DenseBNRelu(units=256)
self.drop4 = keras.layers.Dropout(rate=0.4)
self.dense5 = keras.layers.Dense(units=10, kernel_initializer='glorot_normal')
def call(self, inputs, training=False):
net = self.conv1(inputs, training=training)
net = self.pool1(net)
net = self.conv2(net, training=training)
net = self.pool2(net)
net = self.conv3(net, training=training)
net = self.pool3(net)
net = self.pool3_flat(net)
net = self.dense4(net, training=training)
net = self.drop4(net, training=training)
net = self.dense5(net)
return net
models = []
num_models = 5
for m in range(num_models):
models.append(MNISTModel())7. 최적화 알고리즘 선택
- steps_per_epoch : 5 epoch 마다 학습률을 0.5배로 계단식(staircase) 감소하도록 설정함.
# learning_rate, batch_size 는 하이퍼파라미터로 미리 정의되어 있어야 함
# decay_steps: (한 epoch당 step 수) * num_models * 5 epoch
steps_per_epoch = int(train_images.shape[0] / batch_size)
decay_steps = steps_per_epoch * num_models * 5
lr_decay = tf.keras.optimizers.schedules.ExponentialDecay(
initial_learning_rate=learning_rate,
decay_steps=decay_steps,
decay_rate=0.5,
staircase=True
)
optimizer = tf.keras.optimizers.Adam(learning_rate=lr_decay)
global_step = optimizer.iterations모두를 위한 딥러닝 강좌 2
https://www.youtube.com/watch?v=7eldOrjQVi0&list=PLQ28Nx3M4Jrguyuwg4xe9d9t2XE639e5C
