1) Sequence data란?
- 우리가 사용하는 데이터 중에는 sequence data(순서가 있는 데이터)가 많다.
=> 음성 인식, 자연어, 시계열 데이터, 로그 데이터 등
=> 우리는 하나의 단어만 이해하는 것이 아닌, 문장/내용 전체를 듣고 이해하는 것이다. - 기존 NN/CNN은 하나의 입력이 있으면 바로 1개의 output으로 나오기 때문에, sequence data를 처리하기가 힘들었다.
=> 즉, 이전에 했던 연산이 다음 연산에 영향을 끼쳐야 한다.
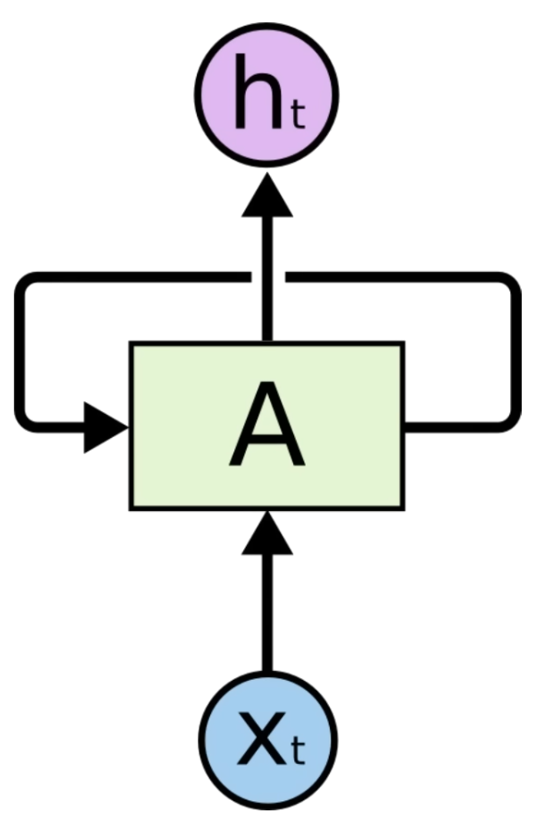
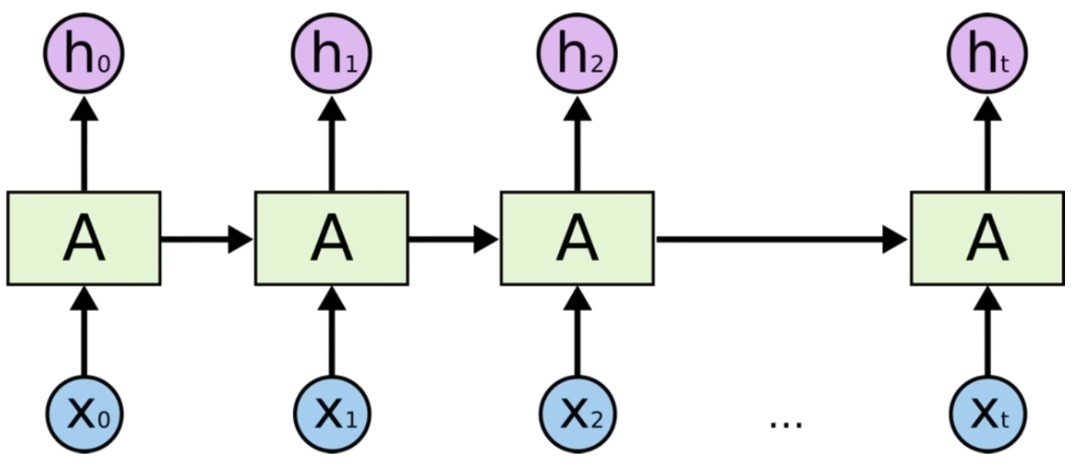
=> 즉, 이처럼 각 데이터가 연속적으로 다음 연산에 영향을 끼치게 된다.
2) RNN (Recurrent Neural Network)
RNN에는 state라는 개념이 있다. 이 state를 먼저 계산하게 되는데, 이때 이전의 state가 입력으로 사용된다.
x라는 입력값과 이전 RNN에서 나온 state를 가지고 새로운 state를 계산한다.
=> 이때 모든 RNN의 함수가 동일하기 때문에 이미지 상 자기 자신에게서 다시 자기 자신으로 돌아오는 이미지로 그려진다.
3) Vanilla RNN 계산 방법
3-1) 기본 형태
RNN 계산 함수 :
=> 여기에 가중치(Weight) 행렬을 적용하여 각 입력에 W 값을 주게 된다.
=> 그리고 sigmoid와 같은 비선형성을 주기 위해 를 적용한다.
3-2) 대표 식
- state 계산
=> - 출력 계산
=> 이 는 다음으로 넘겨주기 위한 값이므로, 값을 출력하기 위한 식이 필요하다.
=>
이 가 몇 개의 벡터로 나올 것인가는 의 형태에 따라 달라진다.
그리고 각각의 는 모든 RNN에서 동일한 값을 가진다. (가중치 공유)
4) 예제: Character 레벨 언어 모델
- Character 레벨 언어 모델
마치 연관검색어처럼, hello를 입력하게 되면 각 rnn에 알파벳이 하나씩 들어가게 되고 각 rnn은 다음에 올 단어를 출력하게 된다.
즉, h를 입력했을 때 다음에 올 단어인 e를 맞추는 것이 language model이다.
5) 입력(one-hot encoding)
- 입력
우리가 [h, e, l, o]라는 단어를 가지고 있다고 할 때, 입력을 나타내는 가장 좋은 방법은 one-hot encoding을 사용하는 것이다.
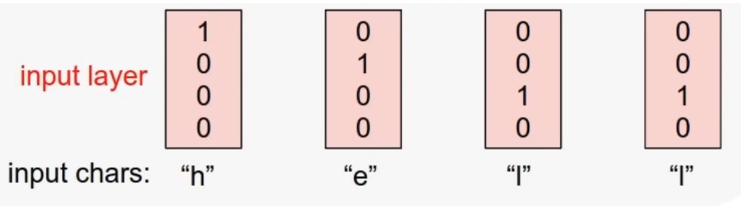
즉, 입력을 여러 개의 벡터로 표시하고 해당하는 위치에 1로 표시한다.
6) 계산(state 업데이트)
이제 각각의 rnn 셀에 값을 입력한다.
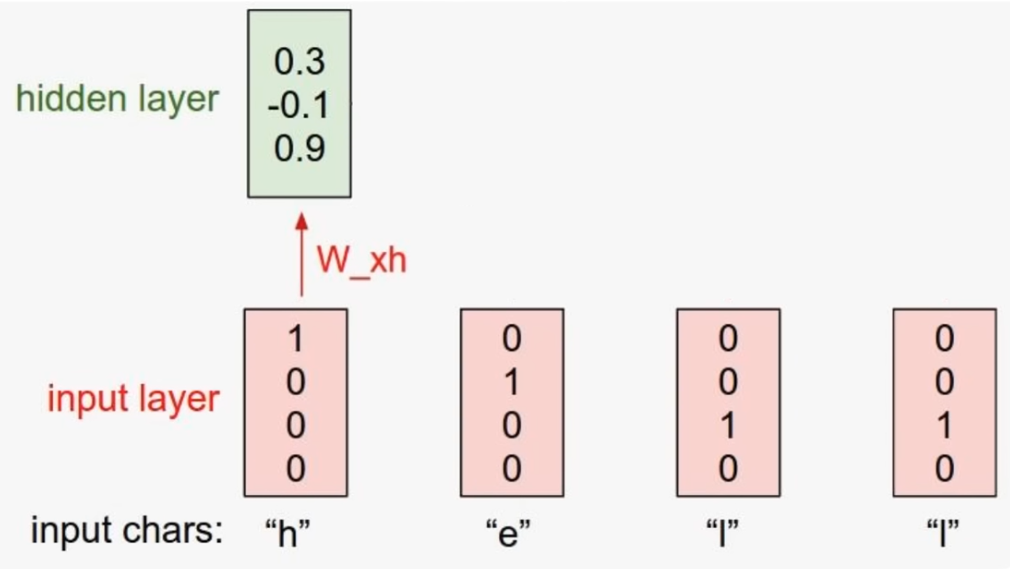
수식 을 사용하여 state 값을 구하게 된다.
- 첫 번째 layer(t=0)
가장 첫 번째 layer의 경우에는 이전 레이어에서 넘어온 이 없다.
따라서 초기값인 0으로 계산한다. - 다음 layer(t=1,2,...)
다음 layer에서는 이전 layer에서 계산된 를 같이 계산하게 된다.
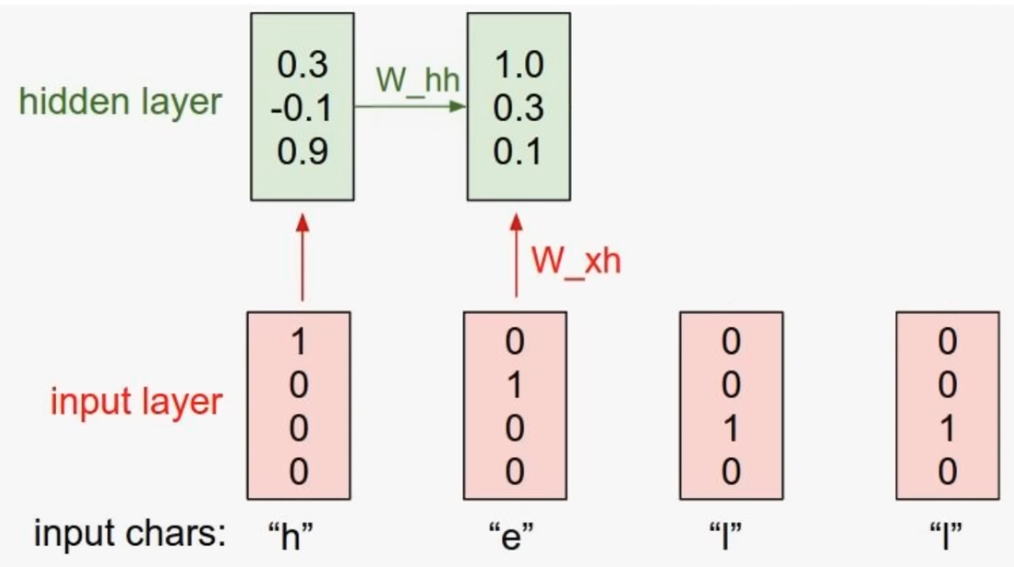
이전 레이어의 값에 를 곱한 값과, 입력에 를 곱한 값을 서로 더하여 다음 출력값(state)을 계산한다.
7) 최종 y 값 출력
최종적으로 다음에 올 값인 를 구하기 위해 다시 를 곱하게 된다.
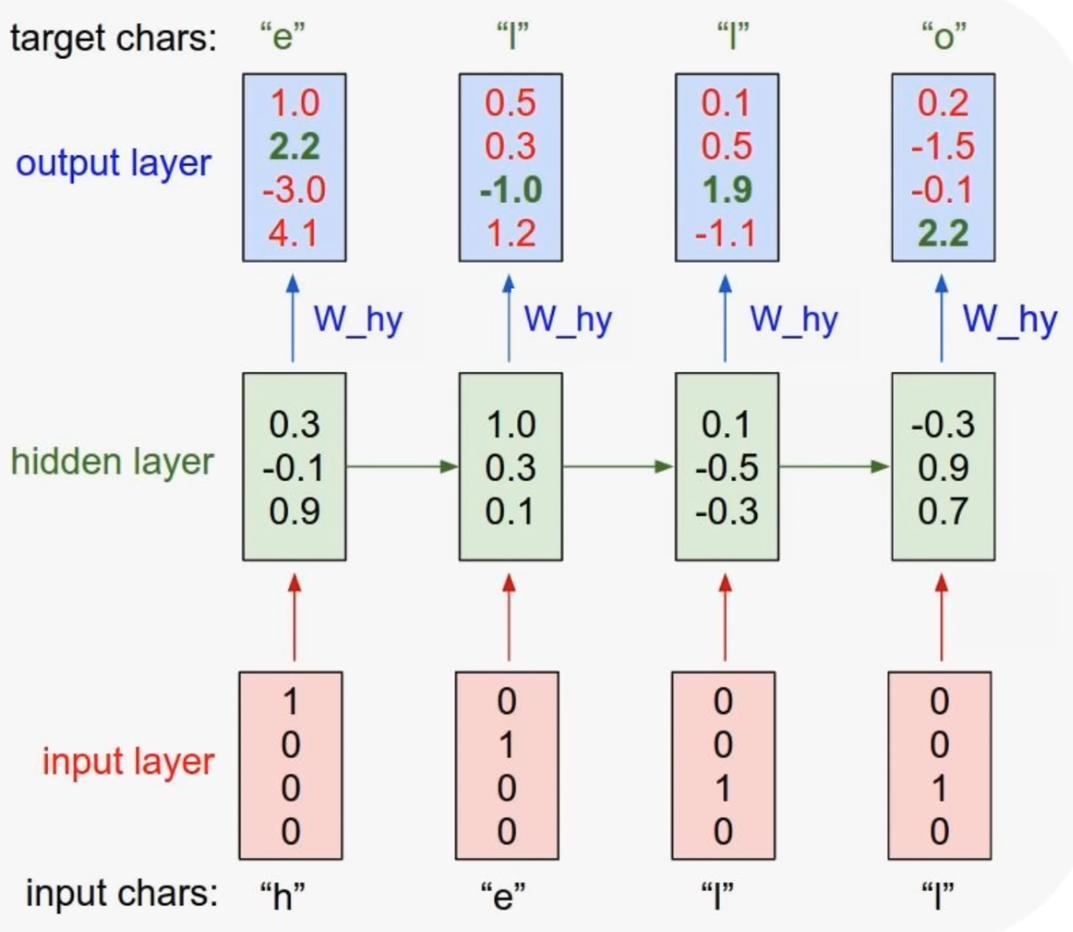
이런 방식으로 다음에 올 단어(또는 글자)를 예측하게 된다.
8) RNN 활용법
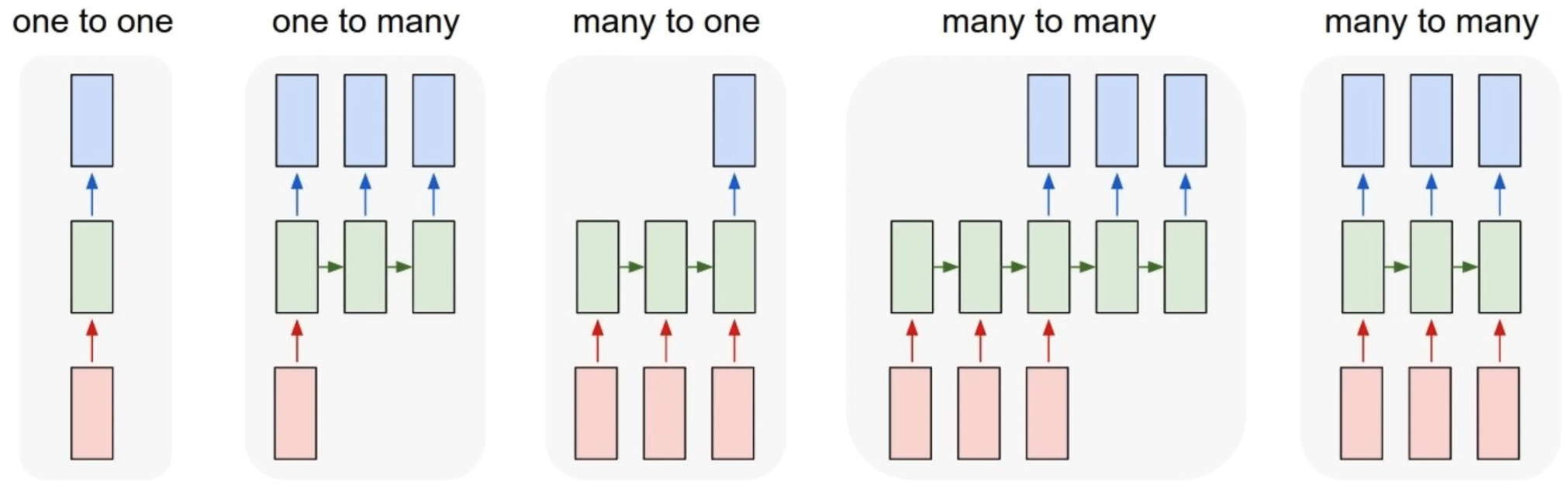
이처럼 RNN은 다양한 형태로 활용될 수 있다.
| 형태 | 입력 -> 출력 | 예시 |
|---|---|---|
| one to one | 단일 입력 -> 단일 출력 | Vanilla NN |
| one to many | 1개 입력 -> 시퀀스 출력 | Image Captioning (image -> sequence of words) |
| many to one | 시퀀스 입력 -> 1개 출력 | Sentiment Classification (sequence of words -> sentiment) |
| many to many | 시퀀스 입력 -> 시퀀스 출력 | Machine Translation (seq of words -> seq of words) |
| many to many | 프레임 시퀀스 -> 프레임별 출력 | Video classification on frame level |
9) 여러 레이어 RNN (Stacked RNN)
또 여러 개의 레이어를 가진 RNN을 만들 수도 있다.
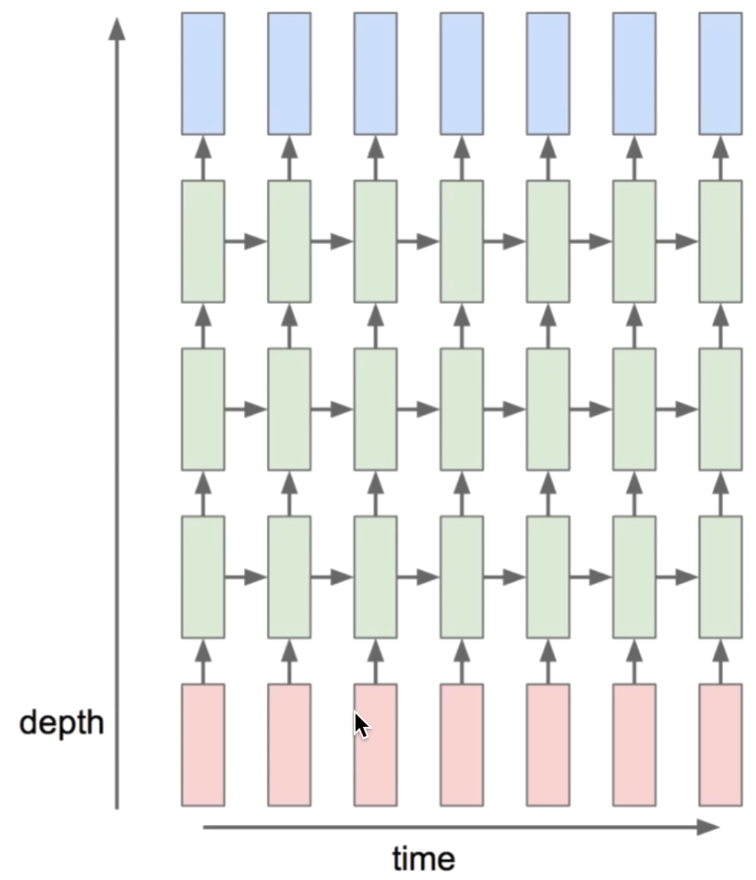
모두를 위한 딥러닝 강좌 2
https://www.youtube.com/watch?v=7eldOrjQVi0&list=PLQ28Nx3M4Jrguyuwg4xe9d9t2XE639e5C
