Seq to Seq란?
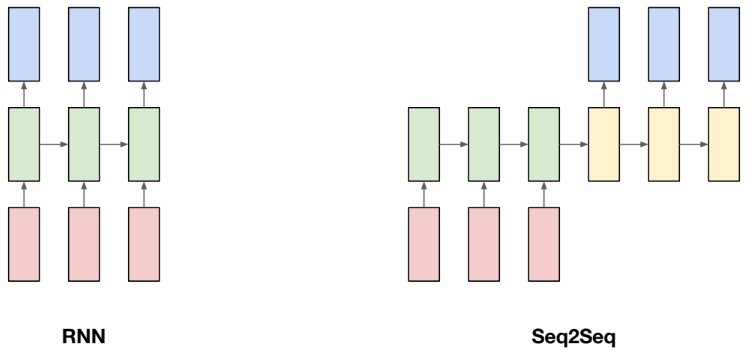
Seq to Seq는 시퀀스 입력을 받아서, 시퀀스 출력을 만들어내는 방식이다. 번역, 챗봇 같은 “문장을 문장으로 바꾸는 문제”에서 자주 사용된다.
인코더 — 디코더 구조
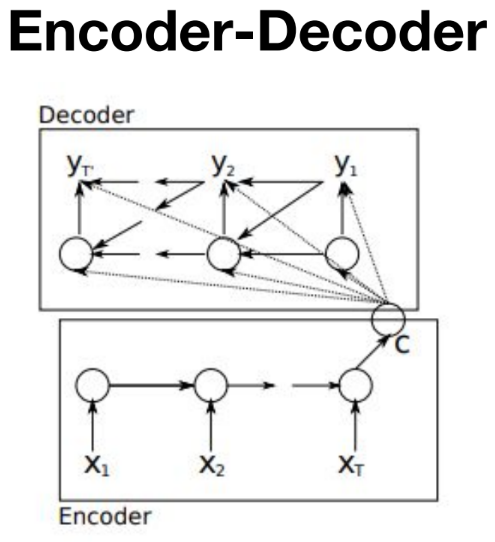
Seq to Seq의 대표 구조가 인코더 — 디코더다.
- 인코더는 입력 문장을 읽고, 입력 정보를 담은 벡터(상태)를 만든다.
- 디코더는 인코더가 만든 상태를 받아서, 출력 문장을 한 토큰씩 순서대로 만들어낸다.
인코더에서는 입력이 토큰(단어) 단위로 들어가고, 마지막 시점의 hidden(state)을 디코더의 초기 hidden으로 넘긴다. 디코더는 매 스텝마다 출력이 나오고, 그 출력이 다음 스텝의 입력으로 이어지면서 문장을 완성한다.
구현 예제
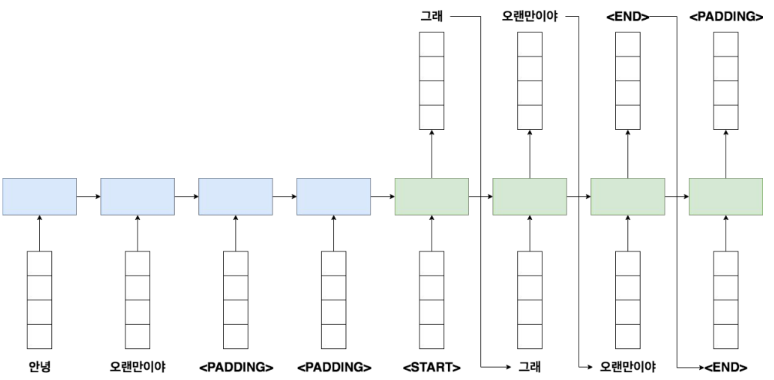
왼쪽 파란색이 인코더, 오른쪽 초록색이 디코더다.
인코더:
- 각 스텝마다 토큰이 들어오고, 임베딩을 거친 뒤 RNN(GRU)으로 처리된다.
- 배치 연산을 위해 문장 길이를 맞춰야 하므로 padding을 넣는다.
디코더:
- 첫 입력은 문장 시작을 의미하는 bos 토큰이다.
- 각 스텝의 출력이 다음 스텝 입력으로 이어지며 문장이 만들어진다.
- eos 토큰이 나오면 문장 생성(또는 학습 타깃)이 끝난 것으로 본다.
구현 코드
1. 데이터셋 준비
from pprint import pprint
import numpy as np
import tensorflow as tf
from tensorflow.keras.preprocessing.sequence import pad_sequences
sources = [
['I', 'feel', 'hungry'],
['tensorflow', 'is', 'very', 'difficult'],
['tensorflow', 'is', 'a', 'framework', 'for', 'deep', 'learning'],
['tensorflow', 'is', 'very', 'fast', 'changing'],
]
targets = [
['나는', '배가', '고프다'],
['텐서플로우는', '매우', '어렵다'],
['텐서플로우는', '딥러닝을', '위한', '프레임워크이다'],
['텐서플로우는', '매우', '빠르게', '변화한다'],
]
# vocabulary for sources
s_vocab = list(set(sum(sources, [])))
s_vocab.sort()
s_vocab = ['<pad>'] + s_vocab
source2idx = {word: idx for idx, word in enumerate(s_vocab)}
idx2source = {idx: word for idx, word in enumerate(s_vocab)}
pprint(source2idx)
# (출력 생략)
# vocabulary for targets
t_vocab = list(set(sum(targets, [])))
t_vocab.sort()
# pad, bos(beginning of sentence), eos(end of sentence)
t_vocab = ['<pad>', '<bos>', '<eos>'] + t_vocab
target2idx = {word: idx for idx, word in enumerate(t_vocab)}
idx2target = {idx: word for idx, word in enumerate(t_vocab)}
pprint(target2idx)
# (출력 생략)전처리 함수
def preprocess(sequences, max_len, dic, mode='source'):
assert mode in ['source', 'target'], 'source와 target 중에 선택해주세요.'
# source 전처리 (encoder 입력)
if mode == 'source':
s_input = list(map(lambda sentence: [dic.get(token) for token in sentence], sequences))
s_len = list(map(lambda sentence: len(sentence), s_input))
# padding 추가
s_input = pad_sequences(
sequences=s_input,
maxlen=max_len,
padding='post',
truncating='post',
)
return s_len, s_input
# target 전처리 (decoder 입력/정답)
elif mode == 'target':
# input: <bos> + sentence + <eos>
t_input = list(map(lambda sentence: ['<bos>'] + sentence + ['<eos>'], sequences))
t_input = list(map(lambda sentence: [dic.get(token) for token in sentence], t_input))
t_len = list(map(lambda sentence: len(sentence), t_input))
t_input = pad_sequences(
sequences=t_input,
maxlen=max_len,
padding='post',
truncating='post',
)
# output(label): sentence + <eos>
t_output = list(map(lambda sentence: sentence + ['<eos>'], sequences))
t_output = list(map(lambda sentence: [dic.get(token) for token in sentence], t_output))
t_output = pad_sequences(
sequences=t_output,
maxlen=max_len,
padding='post',
truncating='post',
)
return t_len, t_input, t_output
# preprocessing for source
s_max_len = 10
s_len, s_input = preprocess(sequences=sources, max_len=s_max_len, dic=source2idx, mode='source')
print(s_len, s_input)
# preprocessing for target
t_max_len = 12
t_len, t_input, t_output = preprocess(sequences=targets, max_len=t_max_len, dic=target2idx, mode='target')
print(t_len, t_input, t_output)tf.data를 활용한 파이프라인 구성
# hyper-parameters
epochs = 100
batch_size = 4
learning_rate = 0.005
buffer_size = 100
n_batch = buffer_size // batch_size
embedding_dim = 32
units = 32
# input pipeline
data = tf.data.Dataset.from_tensor_slices((s_len, s_input, t_len, t_input, t_output))
data = data.shuffle(buffer_size=buffer_size)
data = data.batch(batch_size=batch_size)2.Encoder — Decoder
1. GRU 레이어 헬퍼
def gru(units):
# (정정 - TF2) TF2에서는 CuDNNGRU를 직접 쓰기보다 GRU를 쓰고,
# GPU 환경에서는 조건이 맞으면 내부적으로 CuDNN 커널을 사용한다.
return tf.keras.layers.GRU(
units,
return_sequences=True,
return_state=True,
recurrent_initializer='glorot_uniform',
)2. Encoder
class Encoder(tf.keras.Model):
# vocab_size: 단어 사전 크기
# embedding_dim: 임베딩 차원
# enc_units: 인코더 hidden 크기
# batch_sz: 배치 크기
def __init__(self, vocab_size, embedding_dim, enc_units, batch_sz):
super(Encoder, self).__init__()
self.batch_sz = batch_sz
self.enc_units = enc_units
self.embedding = tf.keras.layers.Embedding(vocab_size, embedding_dim)
self.gru = gru(self.enc_units)
# 소스 입력을 임베딩 — GRU에 통과시켜 output과 state를 반환
def call(self, x, hidden):
x = self.embedding(x)
output, state = self.gru(x, initial_state=hidden)
return output, state
# 초기 hidden state(더미) 생성
def initialize_hidden_state(self):
return tf.zeros((self.batch_sz, self.enc_units))3. Decoder
class Decoder(tf.keras.Model):
# vocab_size: 단어 사전 크기
# embedding_dim: 임베딩 차원
# dec_units: 디코더 hidden 크기
# batch_sz: 배치 크기
def __init__(self, vocab_size, embedding_dim, dec_units, batch_sz):
super(Decoder, self).__init__()
self.batch_sz = batch_sz
self.dec_units = dec_units
self.embedding = tf.keras.layers.Embedding(vocab_size, embedding_dim)
self.gru = gru(self.dec_units)
self.fc = tf.keras.layers.Dense(vocab_size)
# (참고) enc_output은 여기서는 사용하지 않지만, 이후 attention 버전으로 확장할 때 인터페이스를 유지할 수 있다.
def call(self, x, hidden, enc_output):
x = self.embedding(x)
output, state = self.gru(x, initial_state=hidden)
# output shape == (batch_size * 1, hidden_size)
output = tf.reshape(output, (-1, output.shape[2]))
# output shape == (batch_size * 1, vocab)
x = self.fc(output)
return x, state
def initialize_hidden_state(self):
return tf.zeros((self.batch_sz, self.dec_units))
encoder = Encoder(len(source2idx), embedding_dim, units, batch_size)
decoder = Decoder(len(target2idx), embedding_dim, units, batch_size)3. loss — Optimizer
def loss_function(real, pred):
# padding(<pad>=0)이 loss에 영향을 주지 않도록 mask를 적용한다.
mask = tf.cast(tf.not_equal(real, 0), tf.float32)
# (정정 - TF2) TF2 권장 방식: SparseCategoricalCrossentropy(from_logits=True, reduction=NONE)
loss_obj = tf.keras.losses.SparseCategoricalCrossentropy(
from_logits=True,
reduction=tf.keras.losses.Reduction.NONE,
)
loss_ = loss_obj(real, pred) # (batch,)
loss_ = loss_ * mask
return tf.reduce_mean(loss_)
# (정정 - TF2) optimizer를 tf.train.AdamOptimizer 대신 keras optimizer로 변경
optimizer = tf.keras.optimizers.Adam(learning_rate=learning_rate)
# checkpoint (Object-based saving)
import os
checkpoint_dir = './data_out/training_checkpoints'
checkpoint_prefix = os.path.join(checkpoint_dir, 'ckpt')
checkpoint = tf.train.Checkpoint(optimizer=optimizer, encoder=encoder, decoder=decoder)
# (정정 - TF2) tf.contrib.summary 대신 tf.summary 사용
summary_writer = tf.summary.create_file_writer(logdir=checkpoint_dir)4. 모델 학습
EPOCHS = 100
for epoch in range(EPOCHS):
hidden = encoder.initialize_hidden_state()
total_loss = 0
for i, (s_len, s_input, t_len, t_input, t_output) in enumerate(data):
loss = 0
with tf.GradientTape() as tape:
enc_output, enc_hidden = encoder(s_input, hidden)
# 인코더 마지막 hidden을 디코더 초기 hidden으로 사용
dec_hidden = enc_hidden
# 디코더 첫 입력은 <bos>
dec_input = tf.expand_dims([target2idx['<bos>']] * batch_size, 1)
# Teacher Forcing: 다음 입력으로 “예측값”이 아니라 “정답 토큰”을 넣는다
for t in range(1, t_input.shape[1]):
predictions, dec_hidden = decoder(dec_input, dec_hidden, enc_output)
loss += loss_function(t_input[:, t], predictions)
# 다음 스텝 입력을 정답 토큰으로 설정(teacher forcing)
dec_input = tf.expand_dims(t_input[:, t], 1)
batch_loss = (loss / int(t_input.shape[1]))
total_loss += batch_loss
# (정정 - TF2) variables 대신 trainable_variables 사용 권장
variables = encoder.trainable_variables + decoder.trainable_variables
gradient = tape.gradient(loss, variables)
optimizer.apply_gradients(zip(gradient, variables))
if epoch % 10 == 0:
print('Epoch {} Loss {:.4f} Batch Loss {:.4f}'.format(epoch, total_loss / n_batch, batch_loss.numpy()))
checkpoint.save(file_prefix=checkpoint_prefix)
# restore checkpoint
checkpoint.restore(tf.train.latest_checkpoint(checkpoint_dir))5. 예측
def prediction(sentence, encoder, decoder, inp_lang, targ_lang, max_length_inp, max_length_targ):
inputs = [inp_lang[i] for i in sentence.split(' ')]
inputs = tf.keras.preprocessing.sequence.pad_sequences([inputs], maxlen=max_length_inp, padding='post')
inputs = tf.convert_to_tensor(inputs)
result = ''
hidden = [tf.zeros((1, units))]
enc_out, enc_hidden = encoder(inputs, hidden)
dec_hidden = enc_hidden
dec_input = tf.expand_dims([targ_lang['<bos>']], 0)
for t in range(max_length_targ):
predictions, dec_hidden = decoder(dec_input, dec_hidden, enc_out)
predicted_id = tf.argmax(predictions[0]).numpy()
result += idx2target[predicted_id] + ' '
if idx2target.get(predicted_id) == '<eos>':
return result, sentence
dec_input = tf.expand_dims([predicted_id], 0)
return result, sentence
sentence = 'tensorflow is a framework for deep learning'
# sentence = 'I feel hungry'
result, output_sentence = prediction(sentence, encoder, decoder, source2idx, target2idx, s_max_len, t_max_len)
print(sentence)
print(result)Seq to Seq의 문제점
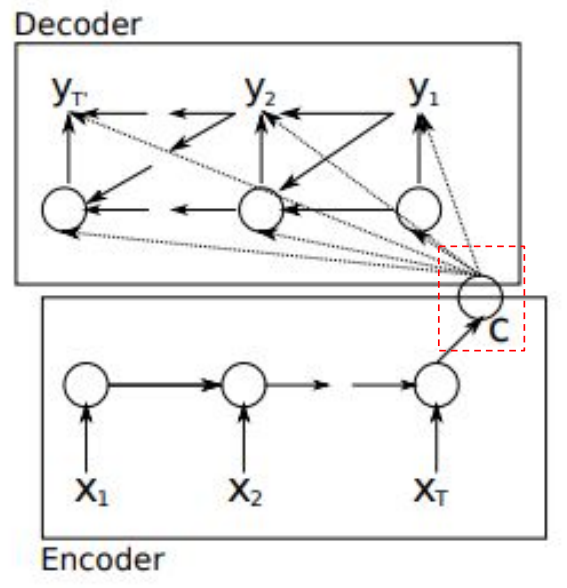
- 기존에는 Seq to Seq로 RNN 인코더 — 디코더 구조의 간단한 번역 모델을 만들 수 있었다.
=> 그런데 “중간에 한 개의 벡터(인코더 마지막 hidden)”만으로는 입력 문장의 정보를 전부 담기 어렵다.
=> 입력 문장과 타겟 문장이 길어질수록(길이가 늘어날수록) 성능이 떨어지는 문제가 생긴다.
Attention이란?
- 가령 영어 지문을 읽을 때, 모든 정보를 똑같이 기억하지는 않는다.
=> 지금 목적에 중요한 문장이나 단어에 더 집중한다.
=> 핵심은 보통 일부에 몰려 있고, 그 부분만 잘 잡아도 전체 의미를 이해할 수 있기 때문이다.
=> 즉, 특정 목적에 맞는 정보에 “집중”해서 활용하는 방식이 어텐션이다.
구현 코드
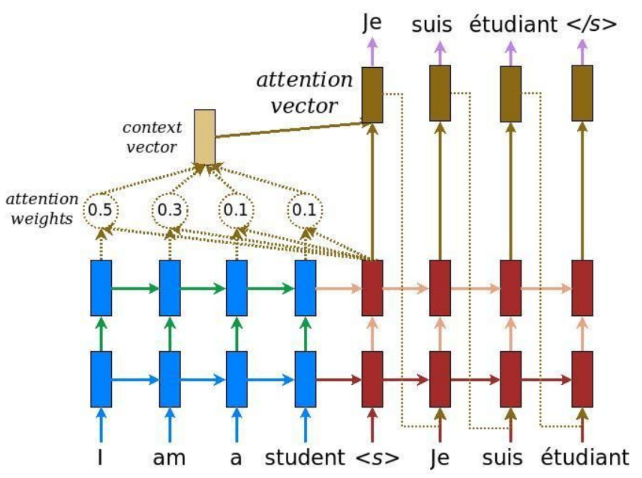
이전 Seq to Seq에서는 인코더가 마지막 시점에 만든 hidden state(마지막 hidden) 하나로 컨텍스트 벡터를 만들고, 디코더는 그 컨텍스트 벡터에 크게 의존해서 출력을 만들었다.
어텐션에서는 인코더의 모든 시점 hidden state를 후보로 두고, 디코더가 “현재 시점에서 어떤 인코더 시점이 더 중요한지”를 가중치(attention weights)로 계산한다.
예를 들어 디코더가 첫 번째 토큰을 예측하는 시점이라면, 입력의 앞부분 정보가 더 필요할 가능성이 크다. 그래서 가중치가 입력의 앞쪽 시점에 더 크게 몰리는 형태가 나올 수 있다.
즉, 어텐션은 “지금 이 출력을 만들 때 입력의 어느 부분을 더 봐야 하는지”를 가중치로 알려주는 메커니즘이다.
이 가중치는 softmax로 정규화되기 때문에 총합은 1이 된다. 그리고 이 가중치로 인코더 hidden들을 가중합해서 컨텍스트 벡터를 만든 뒤, 그 컨텍스트 벡터를 사용해 디코더가 현재 출력을 예측한다.
구현 코드
1. 데이터셋
sources = [
['I', 'feel', 'hungry'],
['tensorflow', 'is', 'very', 'difficult'],
['tensorflow', 'is', 'a', 'framework', 'for', 'deep', 'learning'],
['tensorflow', 'is', 'very', 'fast', 'changing'],
]
targets = [
['나는', '배가', '고프다'],
['텐서플로우는', '매우', '어렵다'],
['텐서플로우는', '딥러닝을', '위한', '프레임워크이다'],
['텐서플로우는', '매우', '빠르게', '변화한다'],
]2. Encoder
- 기존 Seq to Seq Encoder와 동일하다.
# 기존 Seq to Seq Encoder와 동일함
class Encoder(tf.keras.Model):
def __init__(self, vocab_size, embedding_dim, enc_units, batch_sz):
super(Encoder, self).__init__()
self.batch_sz = batch_sz
self.enc_units = enc_units
self.embedding = tf.keras.layers.Embedding(vocab_size, embedding_dim)
self.gru = gru(self.enc_units)
def call(self, x, hidden):
x = self.embedding(x)
output, state = self.gru(x, initial_state=hidden)
return output, state
def initialize_hidden_state(self):
return tf.zeros((self.batch_sz, self.enc_units))3. Decoder
-
Attention weights
: score를 softmax로 정규화한 값이다. -
Context vector
: 인코더 hidden에 가중치를 곱해서 가중합한다. -
Attention vector
: 디코더 hidden과 context vector를 결합해서 반영한다. -
Score
: 현재 디코더 시점에서 “어떤 인코더 시점이 중요한지”를 점수로 만든다. 대표적으로 2가지 스타일이 있다.- Luong multiplicative style :
- Bahdanau additive style :
3. Decoder
class Decoder(tf.keras.Model):
def __init__(self, vocab_size, embedding_dim, dec_units, batch_sz):
super(Decoder, self).__init__()
self.batch_sz = batch_sz
self.dec_units = dec_units
self.embedding = tf.keras.layers.Embedding(vocab_size, embedding_dim)
self.gru = gru(self.dec_units)
# 인코더와 유사하지만, 디코더에는 마지막에 fc가 추가된다.
self.fc = tf.keras.layers.Dense(vocab_size)
# attention에 필요한 Dense 레이어(Score 계산용)
self.W1 = tf.keras.layers.Dense(self.dec_units)
self.W2 = tf.keras.layers.Dense(self.dec_units)
self.V = tf.keras.layers.Dense(1)
def call(self, x, hidden, enc_output):
# enc_output: (batch_size, max_length, hidden_size)
# hidden에 time 축(길이 1)을 추가: (batch_size, 1, hidden_size)
hidden_with_time_axis = tf.expand_dims(hidden, 1)
# score: (batch_size, max_length, 1)
score = self.V(tf.nn.tanh(self.W1(enc_output) + self.W2(hidden_with_time_axis)))
# attention_weights: (batch_size, max_length, 1)
# 입력 길이(max_length) 축에 대해 softmax를 적용해야 각 입력 토큰별 가중치가 된다.
attention_weights = tf.nn.softmax(score, axis=1)
# context_vector: (batch_size, hidden_size)
context_vector = attention_weights * enc_output
context_vector = tf.reduce_sum(context_vector, axis=1)
# 디코더 입력 토큰 임베딩: (batch_size, 1, embedding_dim)
x = self.embedding(x)
# context + embedding concat: (batch_size, 1, hidden_size + embedding_dim)
x = tf.concat([tf.expand_dims(context_vector, 1), x], axis=-1)
# 디코더는 이전 hidden을 이어받아야 하므로 initial_state=hidden을 넣는다.
output, state = self.gru(x, initial_state=hidden)
# output: (batch_size * 1, hidden_size)
output = tf.reshape(output, (-1, output.shape[2]))
# logits: (batch_size * 1, vocab_size)
x = self.fc(output)
return x, state, attention_weights
def initialize_hidden_state(self):
return tf.zeros((self.batch_sz, self.dec_units))4. 학습
# 학습 과정은 이전과 동일함
EPOCHS = 100
for epoch in range(EPOCHS):
hidden = encoder.initialize_hidden_state()
total_loss = 0
for i, (s_len, s_input, t_len, t_input, t_output) in enumerate(data):
loss = 0
with tf.GradientTape() as tape:
enc_output, enc_hidden = encoder(s_input, hidden)
dec_hidden = enc_hidden
dec_input = tf.expand_dims([target2idx['<bos>']] * batch_size, 1)
# Teacher Forcing: 다음 입력으로 예측값이 아니라 정답 토큰을 넣는다
for t in range(1, t_input.shape[1]):
predictions, dec_hidden, _ = decoder(dec_input, dec_hidden, enc_output)
loss += loss_function(t_input[:, t], predictions)
dec_input = tf.expand_dims(t_input[:, t], 1)
batch_loss = (loss / int(t_input.shape[1]))
total_loss += batch_loss
# TF2에서는 trainable_variables를 쓰는 편이 안전하다.
variables = encoder.trainable_variables + decoder.trainable_variables
gradient = tape.gradient(loss, variables)
optimizer.apply_gradients(zip(gradient, variables))
if epoch % 10 == 0:
# 10 epoch마다 저장
print('Epoch {} Loss {:.4f} Batch Loss {:.4f}'.format(epoch, total_loss / n_batch, batch_loss.numpy()))
checkpoint.save(file_prefix=checkpoint_prefix)모두를 위한 딥러닝 강좌 2
https://www.youtube.com/watch?v=7eldOrjQVi0&list=PLQ28Nx3M4Jrguyuwg4xe9d9t2XE639e5C
