Introduction
ViT는 현재까지도 Classification 분야에서 SOTA 성능을 기록하고 있다. 반면에 Swin Transformer는 Classification에서 성능은 뒤쳐지면서 Object detection과 Segmentation 분야에서 SOTA 성능을 기록한다.
이유는 Swin Transformer는 계층적인 구조를 활용하기 때문이다. CNN에서 layer가 깊어지면서 입력 이미지의 resolution을 축소하는 것처럼 Swin Transformer도 layer가 깊어지면서 이미지의 resolution을 변경한다. 서로 다른 scale information을 갖고 있으므로 Object detection의 FPN 구조를 사용할 수 있다. FPN 구조를 사용하여 multi-scale information 정보를 활용하기 때문에 Object detection과 Segmentation task에서의 성능이 ViT보다 우수할 수밖에 없다.
transformer 구조를 object detection에 적용한 모델로 text에 비해서 image는 어떻게 patch로 분할하느냐에 따라서 엄청나게 다양한 변동성(차이)이 존재한다. 따라서 Shifted Windows를 사용하여 hierarchical transformer로 representation을 학습한다.
-> 패치 사이즈를 다양하게해서 유동적으로 사용가능해진다.
hierarchical transformer
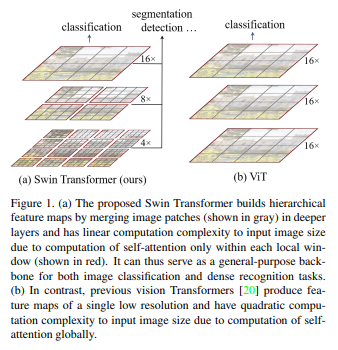
작은 단위의 패치에서 점점 merge하는 방식이고 계층마다 다른 representation을 가진다.
다양한 크기의 엔터티를 다루는 비전 분야에서 좋은 성능을 낸다.
Shifted Windows
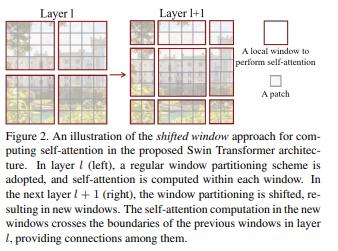
이전 레이어의 window와 현재 window 사이를 이어주는 방식으로 단순 window 기준이 아닌 분할이 발생한 패치에서 [M/2,M/2]칸 떨어진 패치에서 layer l+1 window분할한다. -> 통해 연결성을 더 강화시킬 수 있다.
Method
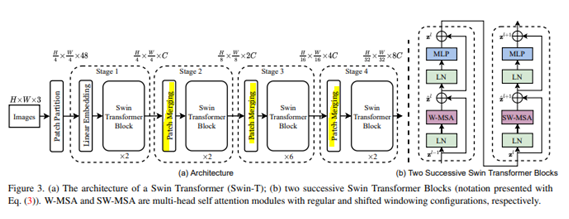
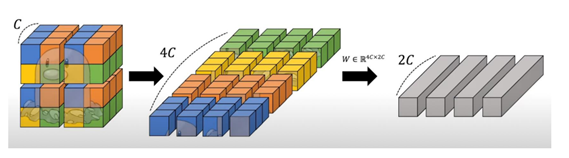
- patch merging : 각 stage(4개)가 진행됨에 따라 해상도를 줄여준다.
실제 patch merging되는 과정
예시) 캐릭터가 아래와 같이 있으면 차윈을 나누어서 쪼갬
- Swin transformer block : 연속적으로 이어져 있는 구성이고 (b)는 block의 내부 모습이다.
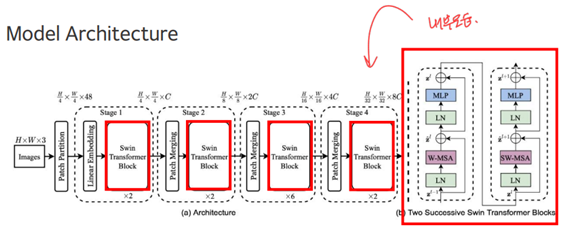
W-MSA: local window 안에서 self-attention
SW-MSA: local window 간의(사이에서) self-attention
local window
vision transformer 는 classification이 목표였지만 swin transformer는 detection, segmentation이 가능하게 하기 위해 local window가 도입되었다.
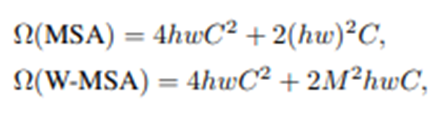
▶ h : 세로 패치 수
▶ w : 가로 패치 수
▶ m : local window size -> 선형적으로 수를 증가시켜 효율적으로 만듬.
- layer가 진행될수록 윈도우 위치가 바뀌는데, 단 W-MSA에서는 바뀌지 않는다.
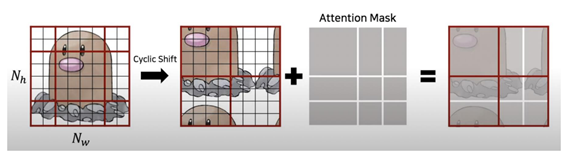
Cyclic Shift & Attention Mask
window는 window size // 2 만큼 바뀌는데 하는데, 이미지 범위를 벗어나면 padding을 하는 것이 아니라 다음의 trick을 사용한다.
A ,B, C를 이동시켜서 A ,B, C 사이즈 맞춤. window안에서 mask 시켜서 self attention.
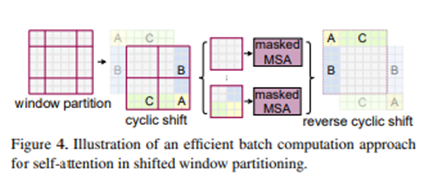
Cyclic Shift & Attention Mask 예시)
relative position bias
또 다른 방법으로는 self-attention을 계산할 때 relative position bias를 더한다. 이 덕분에 positional embedding을 사용하지 않아도 되고, 이 relative position bias는 윈도우 내에서 patch의 상대적인 위치를 나타낸다.
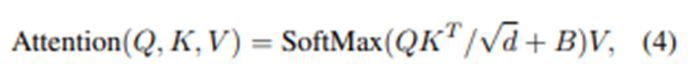
Experiments
데이터 키우면서 성능 비교
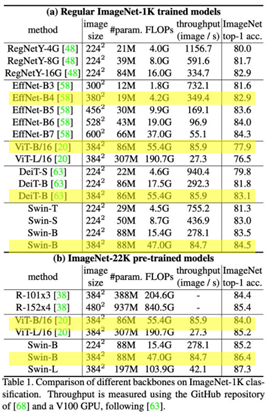
Object Detection
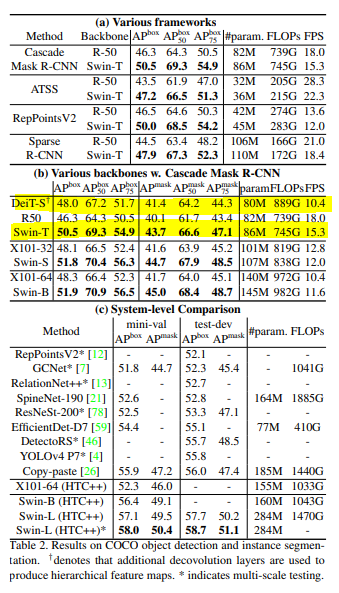
Semantic segmentation
더 적은 파라미터로 좋은 성능을 냄
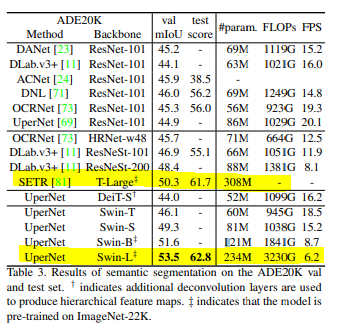
ablation study : 각 여부에 따른 실험결과
Shifted windows, Relative position bias
빨강 : Shifted windows 파랑 : Relative position bias
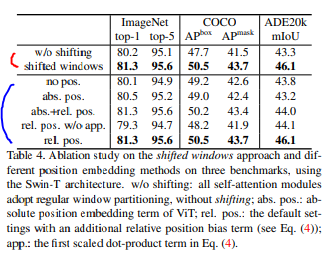
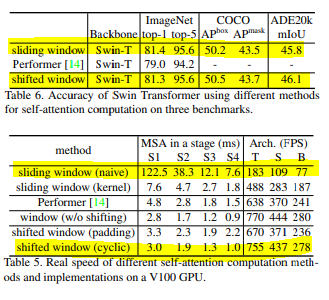
성능차이는 크게 없지만 속도 차이가 크다.
Conclustion
COCO 2017, ADE20K에서 이전 최상의 방법을 훨씬 능가하는 최첨단 성능을 보여줬다.
핵심요소인 shifted windows 기반 self-attention은 Visual 문제에서 효율적 성능을 보였고 추후 자연어 처리 상황에서도 뛰어난 성능이 기대된다.
