딥러닝
1.Fast R-CNN
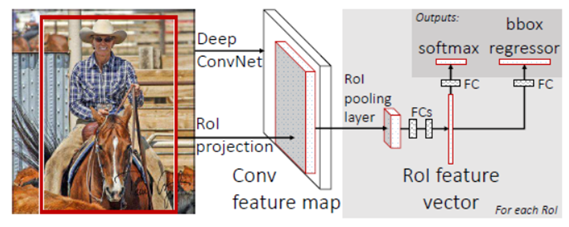
Fast R-CNN, Mask R-CNN 개념 설명
2.R-CNN
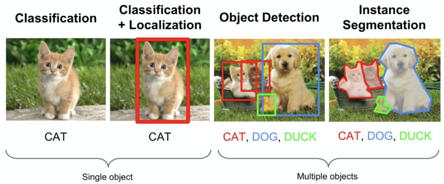
object detection, R-CNN 개념 설명
3.Catboost
공모전 데이터를 보고 공부를 하던 중, gradient boosting library에 새로 나온 'Catboost'를 알게 되었다. 기존의 부스팅 기법의 문제를 해결하고, 범주형 변수들이 많을 때 이용하기 좋으며 비슷한 데이터 사이즈에서 다른 gradient boos
4.논문 읽는 법

무작정 논문을 읽었던 나는,,,, 유투브와 블로그를 찾아보고 앞으로 어떻게 효율적으로 논문을 읽고 정리할지 정리를 하게 된다....!리뷰논문 -어떤 주제에 대한 연구들모아 정리해둔 논문리서치논문 읽기 전에, 논문 제목 , 저자이름 , 발행된날짜 확인하기.논문에 중심내용
5.TabNet
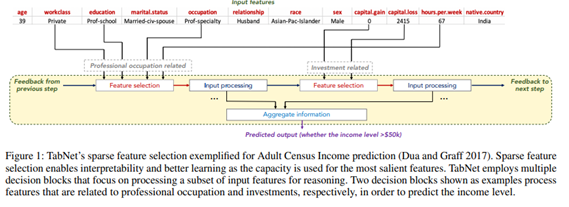
TabNet은 tabular 데이터의 훈련에 맞게 설계됐으며 Tree기반 모델의 변수선택 특징을 네트워크 구조에 반영한 모델이다. 이는 딥러닝 모델이 해석하기 어려운 문제를 sequential attention mechanism을 이용하여 해석을 용이하게 만들었다. t
6.RNN(순환신경망)
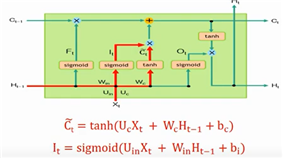
RNN 입력데이터가 시간적 순서를 지닌 시계열 데이터, 은닉층 내부구조는 순환구조이다. ##SimpleRNN ##LSTM ##GRU
7.RNN(2)

RNN의 구체적인 개념 정의!
8.딥러닝 기본 개념 정의

딥러닝의 기본 개요
9.ANN
ANN은 사람의 신경망 원리와 구조를 모방하여 만든 기계학습 알고리즘이다.
10.[논문리뷰] GANILLA: Generative Adversarial Networks for Image to Illustration Translation

본 논문에서는 짝을 이루지 않은 이미지 대 이미지 전환(image-to-image translation)의 새로운 도메인으로 아동 도서의 삽화를 탐구한다. 현재의 sota 모델이 스타일이나 콘텐츠 중 하나를 성공적으로 전환하지만 동시에 둘 다를 전환하지 못한다. 본 논
11.[논문 리뷰]Layer-Wise Relevance Propagation: An Overview
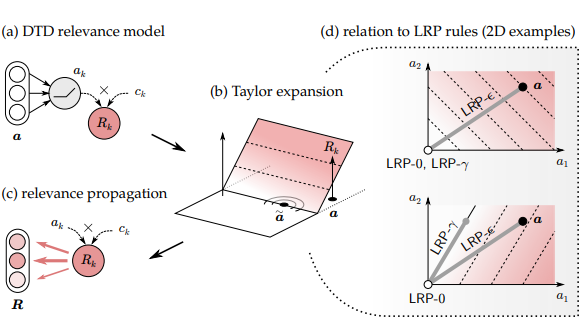
<사전 이해>LIME, Filter Visualization와 같은 피처맵 시각화 방식은 모델이 입력 이미지에 어떻게 반응하는 지 각 은닉층을 조사하는 방법이다. 하지만 이는 깊은 은닉 계층일수록 해석력이 떨어지고, 해석자마자 모델을 다양하게 받아들일 소지가 여전
12.[논문 리뷰] EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks
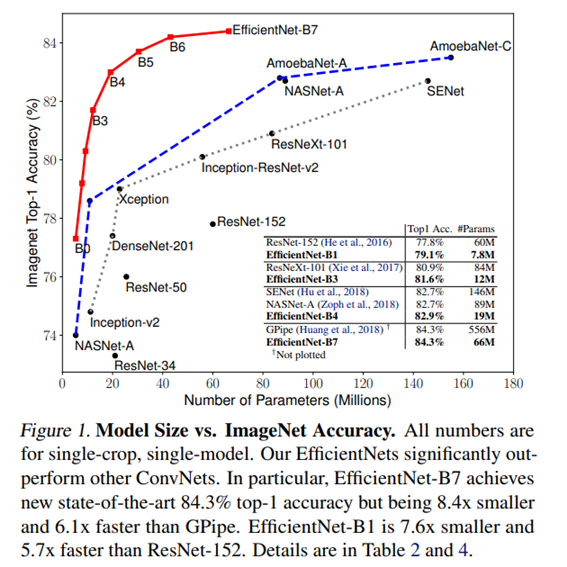
CNN은 모델의 정확도를 높이기 위해 스케일을 키워가며 발전했다. 본 논문에서는 모델의 깊이, 너비, 입력 이미지 해상도(resolution)의 균형을 맞출 수 있는 새로운 스케일링 방법으로 compound coefficient를 제안한다. compound coeffi
13.[논문리뷰] Vision transformer
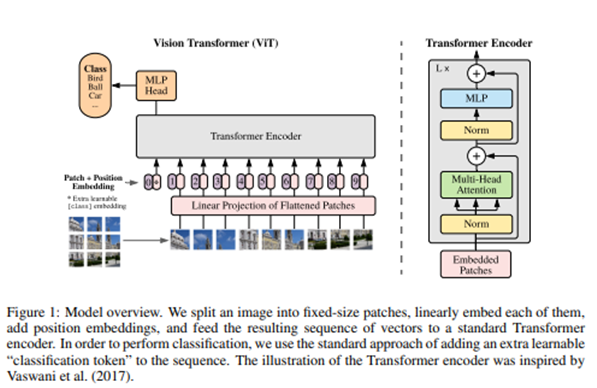
transformer는 자연어처리에서 많이 사용되고 있었는데 비전에서는 제한적으로 적용되어왔다. 비전 분야에서 어텐션은 Convolutional network과 함께 적용되거나, Convolutional network의 특정 요소를 대체하기 위해 사용되었기 때문이다.
14.[논문리뷰] Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
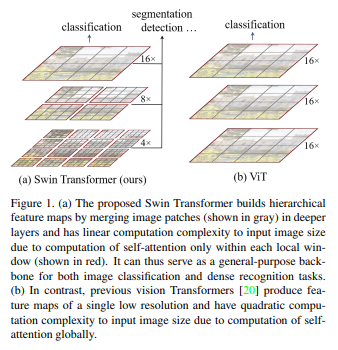
ViT는 현재까지도 Classification 분야에서 SOTA 성능을 기록하고 있다. 반면에 Swin Transformer는 Classification에서 성능은 뒤쳐지면서 Object detection과 Segmentation 분야에서 SOTA 성능을 기록한다.
15.[논문리뷰] InfoGAN

disentangle representation원하는 특징을 가진 랜덤한 이미지를 만드는 것은 쉽지않다.한 특징은 다른 특징과 연관이 있기 때문이다. 이것이 ‘entangle’, 얽히다. 꼬여있음을 의미한다. 내가 원하는 피처 외에 나머지를 고정한 채로 이미지를 생성하