이 논문은 리뷰논문이기에 여러 자연어처리 기법을 알 수 있지만 어떠한 분석기법이 상세하게 나와있지 않아 필요한 부분을 따로 하나씩 공부해나감이 좋을 것이라고 생각한다.
3. 콘볼루션 신경망
워드 임베딩이 인기를 끌고 그 성능 또한 검증된 이후, 단어 결합이나 n-gram으로부터 높은 수준의 피처를 추출해내는 효율적인 함수의 필요성이 증대됐다.
CNN은 문장의 잠재적인 semantic represention을 만들어내기 위해 입력 문장으로부터 핵심적인 n-gram 피처를 추출하는 능력을 갖고 있다.
A. CNN 기본구조
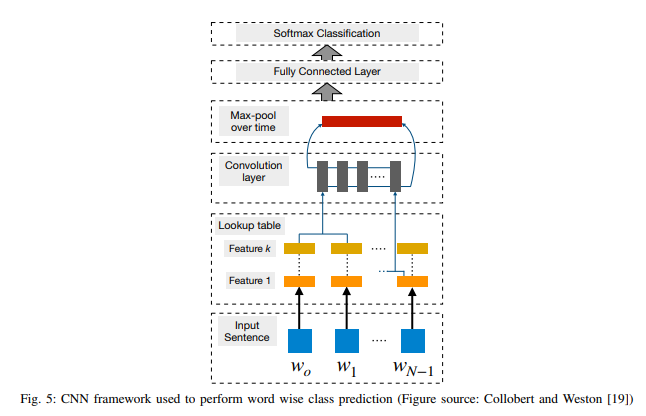
1) 문장 모델링
문장의 i번째 단어에 해당하는 임베딩 벡터를 wi, 임베딩 벡터의 차원수를 d라고 두자. n개 단어로 이뤄진 문장이 주어졌을 때, 문장은 n x d 크기의 임베딩 행렬로 표현할 수 있다.
콘볼루션 필터 k는 차원수가 hd인 벡터이다. 이 필터는 h개 단어벡터에 적용된다.
필터의 폭은 각기 다르며, 각 필터는 n-gram의 특정 패턴을 추출한다.
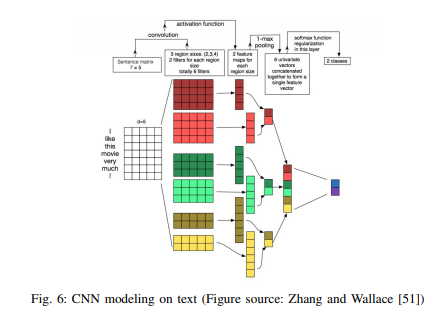
콘볼루션 레이어는 대개 맥스풀링 계층, 즉 c^=max(c)이 후행한다. 맥스풀링은 c에 대해 최대값을 취함으로써 입력값을 서브샘플링한다. 이 전략을 쓰는 데는 두 가지 이유가 있다.
첫째, 맥스풀링은 일반적으로 분류에 필요한 고정 길이의 출력을 제공한다. 따라서 필터의 크기가 각기 다름에도 맥스풀링은 입력값을 항상 고정된 차원의 출력으로 매핑한다.
둘째, 맥스풀링은 전체 문장에서 가장 핵심적인 n-gram 피처를 유지하면서 출력의 차원을 줄인다. 이는 개별 필터가 문장 내 어느 지점에 있든 특정 피처(예를 들어 ‘부정’)를 추출할 수 있고 이를 최종적인 문장 표현(representation)에 덧붙일 수 있기 때문에 변함없는 방식(invariant manner)으로 수행된다.
단어 임베딩은 랜덤 초기화하거나 레이블 없는 방대한 말뭉치에서 사전학습될 수 있다. 후자는 특히 정답 데이터의 양이 적을 때 성능 향상에 때로는 유용하다.
2) 윈도우 접근법
지금까지 기술한 CNN 아키텍처는 완전한 자연어 문장을 벡터로 표현한다. 그러나 개체명인식, 품사태깅, SRL 같은 많은 NLP 문제는 단어 단위의 예측이 필요하다. 이런 태스크에 CNN을 적용하기 위해, 윈도우(window) 접근법이 쓰인다. 이는 단어의 범주(tag)가 기본적으로 이웃 단어에 의존할 것이라고 가정한다.
문맥적 범위를 넓히기 위해, 전통적인 윈도우 접근법은 종종 time-dealy neural network(TDNN)와 결합된다. 여기에서 콘볼루션은 시퀀스 전체의 모든 윈도우에서 수행된다. 이런 콘볼루션들은 일반적으로 필터의 폭이 사전에 정의된다는 점에서 제약을 받는다. 따라서 전통적인 윈도우 접근법은 레이블이 달린 단어 주변의 윈도우에 있는 단어들만 고려하는 반면, TDNN은 문장 내 모든 윈도우들을 동시에 고려한다.
B. CNN 어플리케이션
-
문장의 의미를 모델링하기 위한 dynamic convolutional neural network(DCNN)을 제안했다.
-
이들은 dynamic k max pooling 전략을 제안했다. 이는 시퀀스 p가 주어졌을 때 가장 활동적인(active) k개의 피처를 뽑는 방법이다. 선택은 피처의 순서를 보존하지만, 특정 위치에는 민감하지 않다. 둘의 조합은 작은 폭의 필터가 입력문장의 긴 범위를 커버할 수 있게 한다.
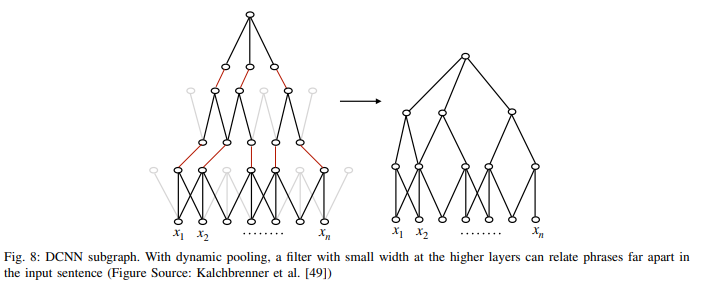
그림8에서 상위의 피처는 집중적이고 짧거나, 전역적이고 입력문장처럼 길 수도 있는 매우 가변적인 범위를 가진다. 이들은 감성 분류, 질의 유형 분류를 포함한 다양한 task에 이 네트워크를 적용했고, 의미있는 결과를 얻었다.
-
DMCNN 등장 배경
CNN은 텍스트 길이에 따라 성능이 달라진다. 장문의 텍스트에 대한 CNN 모델의 성능은 좋았던 반면 짧은 텍스트에선 반대였다.
CNN은 문장에서 가장 중요한 정보를 뽑기 위한 방법과 연결되어 있다. 그러나 기존의 맥스풀링 전략은 문장에서 가치 있는 정보를 종종 잃어버린다. 다중 이벤트 모델링(multiple-event modeling)에서 이러한 정보 손실 문제를 극복하기 위해, Chen et al. (2015b)는 수정된 풀링 전략, 즉 dynamic multi-pooling CNN(DMCNN)을 제안했다. -
Recursive NN이 적합한 상황
전반적으로, CNN은 contextual window 내에 있는 의미적 단서를 추출하는 데 고도로 효율적이다. 그러나 CNN은 매우 많은 데이터를 필요로 한다. CNN 모델은 방대한 양의 데이터를 요구하는 다수의 학습 파라미터를 포함한다. CNN은 데이터가 부족할 때는 문제가 된다.
CNN의 다른 이슈는 먼 거리의 문맥 정보를 모델링하기가 불가능하고 그들의 시퀀셜한 순서를 보존할 수 없다는 것이다. 따라서 Recursive NN과 같은 네트워크가 이런 학습에 적합하다.
4. Recurrent Neural Networks
RNN 개념
Recurrent Neural Network(Elman, 1990)는 순차적인 정보를 처리하는 네트워크다. 일반적으로 recurrent unit에 토큰을 하나씩 입력함으로써 고정 크기의 벡터가 시퀀스를 표현하기 위해 생성된다. 이런 방식으로 RNN은 이전 연산결과를 ‘기억’하고, 현재 연산 과정에서 이 정보를 활용한다.
A. RNN 필요성
- 단어는 이전 단어를 바탕으로 의미를 갖게 된다. 이와 관련한 간단한 예시는 ‘dog’와 ‘hot dog’ 간의 의미 차이일 것이다. RNN은 이러한 문맥 의존성을 모델링하기 위해 만들어졌으며 연구자들이 CNN보다 RNN을 사용하는 강한 동기가 되었다.
- RNN은 매우 긴 문장, 단락, 심지어 문서(Tang et al., 2015)를 포함해 다양한 텍스트 길이를 모델링할 수 있다.
B. RNN 모델
-
Simple RNN : 히든 스테이트는 다른 time step의 정보를 누적한 네트워크의 메모리 요소로 간주한다. 그러나 실제에선 배니싱 그래디언트 문제(Vanishing gradient problem)로 인해, 네트워크에서 이전 레이어의 파라미터를 학습하고 업데이트하는 걸 매우 어렵게 만든다. 이러한 제한은 LSTM, GRU 및 ResNet과 같은 다양한 네트워크에 의해 극복되었다.
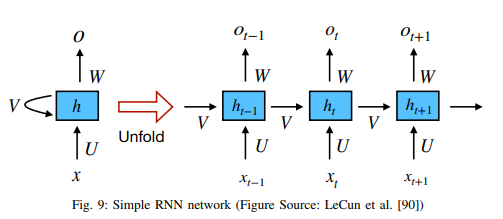
-
LSTM : 간단한 RNN에 forget gate를 추가했다. 이러한 독특한 매커니즘을 통해 배니싱 그래디언트 문제, 익스플로딩 그래디언트 문제(exploding gradient problem_를 모두 극복할 수 있다
-
GRU : reset gate와 update gate의 두 개 gate로 구성되며 LSTM처럼 메모리를 보호한다.
-구체적인 내용은 이전에 게시해둔 자료 참고!
어텐션 메커니즘
RNN 모델은 인코더에서 입력 시퀀스를 컨텍스트 벡터라는 하나의 고정된 크기의 벡터 표현으로 압축하고, 디코더는 이 컨텍스트 벡터를 통해서 출력 시퀀스를 만들어냈다.
하지만 이러한 RNN에 기반한 seq2seq 모델에는 크게 두 가지 문제가 있다.
- 하나의 고정된 크기의 벡터에 모든 정보를 압축하려고 하니까 정보 손실이 발생한다.
- RNN의 고질적인 문제인 기울기 소실(vanishing gradient) 문제가 존재한다.
결국 이는 기계 번역 분야에서 입력 문장이 길면 번역 품질이 떨어지는 현상으로 나타났다. 이를 위한 대안으로 입력 시퀀스가 길어지면 출력 시퀀스의 정확도가 떨어지는 것을 보정해주기 위한 기법인 어텐션이 등장했다.
어텐션의 기본 아이디어는 디코더에서 출력 단어를 예측하는 매 시점(time step)마다, 인코더에서의 전체 입력 문장을 다시 한 번 참고한다는 점이다. 단, 전체 입력 문장을 전부 다 동일한 비율로 참고하는 것이 아니라, 해당 시점에서 예측해야할 단어와 연관이 있는 입력 단어 부분을 좀 더 집중(attention)해서 보게 된다.
5. Recursive Neural Networks
Recursive Neural Networks 개념
Recurrent Neural Network는 시퀀스(순차적인 데이터) 모델링에 강점을 지닌 기법이다. 그러나 자연언어는 단어와 단어가 계층적인 방식으로 구(phrase)로 결합되는 재귀적인(recursive) 구조를 나타낸다. 이러한 구조는 문장 구성성분 분석 트리(constituency parsing tree)로 표현될 수 있다. 이 때문에 문장의 문법적 구조 해석을 보다 용이하게 하기 위해 트리 구조 모델이 사용되었다.
LSTM은 Tai et al. (2015)가 제안한 트리 구조에도 적용되었다. 그래디언트 배니싱 문제(Gradient Vanishing Problem)를 피하기 위해서다. 이 모델은 감성 분석(Sentiment analysis)과 문장 관련성 테스트(sentence relatedness test)에서 linear LSTM 모델보다 개선됐다.
6. 강화학습과 비지도학습
A. 문장 생성을 위한 강화학습
강화학습의 목표는 보상이 가장 큰 액션을 학습하는 것으로 행동에 대한 보상을 극대화하는 것이 중요하다. 최고의 결과를 내기 전까지 수많은 학습을 통해 알고리즘을 수정하고 변형하며 강화한다. 강화학습은 RNN의 문제점을 보완했다.
RNN의 문제점
-
‘노출 편향’이라고 불리는 학습과 추론 사이의 이러한 불일치는 생성된 시퀀스에 따라 빠르게 누적될 수 있는 오류를 야기할 수 있다.
현재 히든 스테이트와 이전 토큰(단어)이 주어졌을 때 정답 단어가 나타날 우도(likelihood)를 최대화함으로써 학습된다.
Teacher forcing이라 불리는 기법은 RNN 학습 과정에서 이전 스텝의 정답 단어들을 다음 스텝의 입력값으로 넣는다. 그러나 추론 과정에서는 이전 토큰은 모델 자체에서 생성된 토큰으로 대체된다. -
학습목표(training objective)가 테스트 측정지표(test metric)과 다르다.
단어 수준 최대 우도로 학습된 대화시스템은 둔하고 근시안적인 반응을 생성하는 경향이 있고, 단어 수준 최우도 기반의 텍스트 요약도 역시 비간섭적이거나 반복적인 요약을 생성하는 경향이 있다. 테스트 측정지표로는 BLUE, ROUGE 등이 있다.
- 강화학습 이외의 다른 접근법으로는 적대적인 학습 기술(GAN)이 있다. 생성기(generator)의 학습 목표는 생성된 시퀀스와 진짜 시퀀스를 구별하도록 학습된 판별자(discriminator)를 속이는 것이다.
B. 비지도학습 기반 문장 표현
문장에 대한 분산표현도 단어 임베딩처럼 비지도(unsupervised) 방식으로 학습할 수 있다. 이러한 비지도학습의 결과는 임의의 문장을, 의미와 문법적 속성이 내재한 고정 크기의 벡터에 매핑하는 ‘문장 인코더’이다.
단어 임베딩을 위한 skip-gram 모델과 유사하게, 문장 임베딩을 위한 skip-thought 모델이 제안됐다. skip-thought 모델에서 보조적인 과제는 주어진 문장 앞뒤에 있는 두 개의 인접 문장을 예측하는 것이다. 여기에는 seq2seq 모델이 사용됐다.
7. 메모리 네트워크
빠른 이해를 위해 예시를 통해 알아본다.
- Mary moved to the bathroom.
- John went to the hallway.
- Where is Mary? -> bathroom
메모리 네트워크 구조
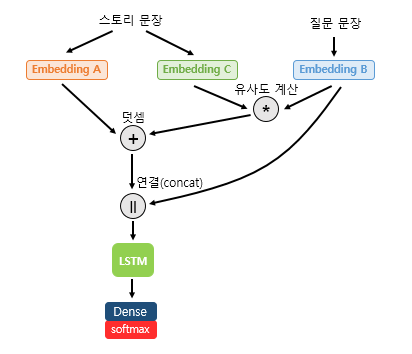
스토리 문장은 Embedding C를 통해서 임베딩이 되고, 질문 문장은 Embedding B를 통해서 임베딩이 된다.
임베딩이 된 두 개의 문장은 내적(dot product)을 통해 각 단어 간 유사도를 구하고, 이렇게 구해진 유사도는 소프트맥스 함수를 지나서 Embedding A로 임베딩이 된 스토리 문장에 더해진다. 현재 위 그림에서 '덧셈'이라고 적혀있는 부분까지 연산이 진행된 상태이다. (Embedding A, B, C는 각각 별 개의 임베딩 층(Embedding layer)이다.)
그런데 지금까지 설명한 연산을 표현을 조금 바꿔서 다시 설명해보자면, 스토리 문장을 Value와 Key라고 하고, 질문 문장을 Query라고 정한다. Query는 Key와 유사도를 구하고, 소프트맥스 함수를 통해 값을 정규화하여 Value에 더해서 이 유사도값을 반영한다. 결국 지금까지의 연산 과정은 어텐션 메커니즘의 의도를 갖고 있다.
지금까지 설명한 위 그림에서 '덧셈'이라고 적혀있는 부분까지의 연산은 어텐션 메커니즘을 통해서 질문 문장과의 유사도를 반영한 스토리 문장 표현을 얻기 위한 여정이었다. 스토리 문장 표현을 질문 문장을 임베딩한 질문 표현과 연결(concatenate)한다. 그리고 이 표현을 LSTM과 밀집층(dense layer)의 입력으로 사용하여 정답을 예측한다.
9. 결론
딥러닝은 많은 양의 계산과 데이터를 활용하는 기법으로, 수작업으로 피처 엔지니어링을 거의 하지 않아도 된다. 분산표상을 활용한 다양한 딥러닝 모델들이 NLP 문제를 위한 새로운 최첨단 방법이 되었다. 이러한 추세가 계속될 것이라 기대한다.
강화학습과 비지도 학습을 활용한 NLP 어플리케이션이 더 많이 나올 것으로 예상된다. 강화학습은 특정 목표를 최적화하기 위해 NLP 시스템을 학습하는 자연스러운 방법을 제시하고, 비지도 학습은 큰 데이터에서 풍부한 언어 구조를 학습할 수 있다. 또한 현실세계에서 언어가 종종 다른 신호(signal)에 근거하거나 상호관련되어 있기 때문에 멀티모델(multimodal)학습에 대해 더 많은 연구가 이뤄지기를 기대한다.
마지막으로 우리는 내부 메모리(데이터에서 배운 상향적 지식)가 외부 메모리(지식베이스로부터 상속된 지식)로 풍부해진 보다 깊은 학습모델이 나오기를 기대한다. Noam Chomsky는 이렇게 말했다. “엄청난 양의 데이터를 컴퓨터에 던지고 통계분석을 통해 과학적 발견을 얻지 말라. 이해하는 방식이 아니라 이론적인 통찰력을 가져야 한다.” 데이터 분석을 통해 통찰력을 기르는 연습이 필요하다는 것을 느낀다.
참고
https://arxiv.org/pdf/1708.02709.pdf
https://wikidocs.net/82475
https://wikidocs.net/22893
