NLP
1.Transformer, BERT
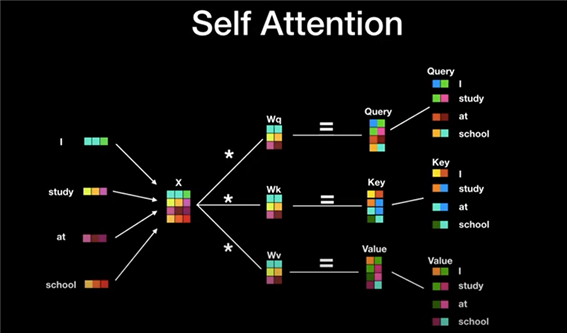
BERT에 대해 알기 위해서는 Transformer의 구조부터 알아야합니다! 인코더, 디코더 구조를 지닌 딥러닝 모델.전통적인 RNN based인 encoder, decoder는 순차적으로 계산한다. 문맥벡터가 고정된 크기여서 책과 같은 긴 입력값은 처리가 어렵다. 하
2.[논문리뷰] XLNet : Generalized Autoregressive Pretraining for Language Understanding
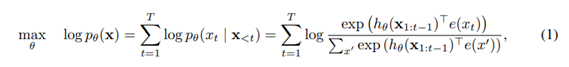
NLP domain에서 unsupervised representation learning이 매우 성공적인 결과를 보여주고 있다. 많은 양의 unlabeled corpus를 이용해 Pre-training을 하고, 얻어진 representation을 직접적으로 활용하거나
3.[논문리뷰]Recent Trends in Deep Learning Based Natural Language Processing(1)

NLP 공부를 하고 있는데 기본을 알아야하지 않나 싶고 요즘 트렌드도 알아야한다 생각해서 기사읽고 블로그 찾아보고 리뷰논문 읽다가 논문 'Recent Trends in Deep Learning BasedNatural Language Processing'에 대해서 중요하
4.[논문리뷰]Recent Trends in Deep Learning Based Natural Language Processing(2)
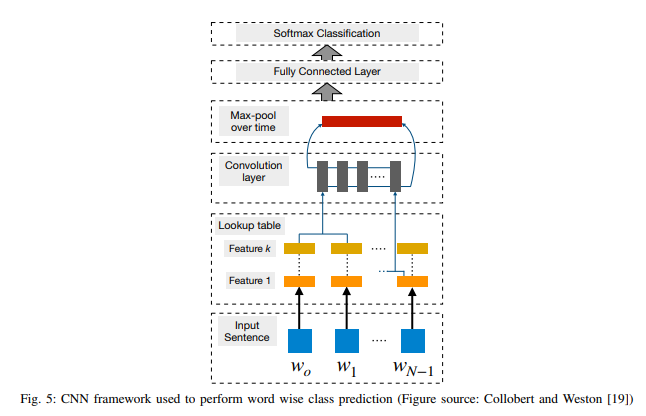
이 논문은 리뷰논문이기에 여러 자연어처리 기법을 알 수 있지만 어떠한 분석기법이 상세하게 나와있지 않아 필요한 부분을 따로 하나씩 공부해나감이 좋을 것이라고 생각한다. 3. 콘볼루션 신경망 워드 임베딩이 인기를 끌고 그 성능 또한 검증된 이후, 단어 결합이나 n-gr
5.[논문 리뷰] ELECTRA: PRE-TRAINING TEXT ENCODERS AS DISCRIMINATORS RATHER THAN GENERATORS
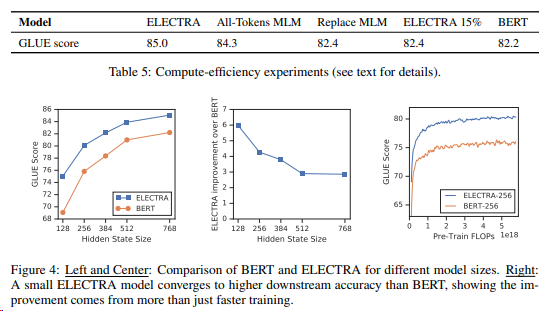
논문 리뷰에 앞서, 이해를 돕기 위해 ELECTRA를 짧게 정리해놓는다."통계적 언어 모델"고정된 확률을 할당하고, 각 단어를 모두 독립된 단어로 취급, 따로 훈련 필요없이 데이터셋이 주어지면 확률 확인한다. "신경망기반 언어모델"단어를 분산표현으로 전환–고차원벡터 :
6.[논문리뷰] RoBERTa : A Robustly Optimized BERT Pretraining Approach

Abstract BERT는 상당히 undertrained 됐다. RoBERTa로 GLUE, RACE, SQuAD nlp task에서 SOTA를 달성하였다. 이 결과는 설계에 중요성을 강조했다. Introduction 기존의 버트에서 수정한 사항 training th
7.[논문리뷰] Text summarization with pretrained encoder
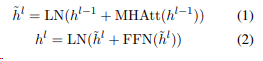
추출요약(extractive summarization): 주어진 문서 집합 "내"에서 중요한 단어나 문장을 선택하는 방법생성요약(abstractive summarization): 앞모델을 보고 모든 생성 가능한 단어 중 새로운 문장을 생성하는 방법pretrained b
8.[논문리뷰] ALBERT: A LITE BERT FOR SELF-SUPERVISED LEARNING OF LANGUAGE REPRESENTATIONS
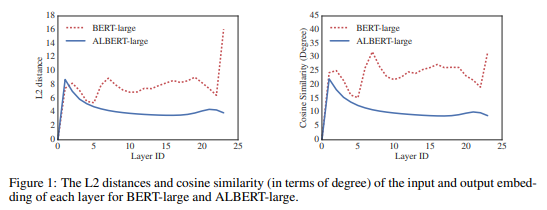
pretrained model은 downstream tasks에서 우수한 성능 향상을 보였지만 모델의 커진 사이즈로 GPU,TPU 메모리가 제한적이고 training 시간이 길어졌다.이 문제를 해결하기 위해 파라미터를 줄이는 두 개의 기술을 제시한다. 또한 SOP도 제
9.[논문 리뷰] Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context
transformers는 잠재적인 장기의존성을 가지고 있다. 하지만 모델링에서 고정 길이 세팅으로 제한이 있었다. transformer-xl은 이전 segment를 처리할 때 계산된 hidden state들을 사용하는 recurrence mechanism을 적용하고 이
10.[논문리뷰]SimCSE: Simple Contrastive Learning of Sentence Embeddings
contrastive learning이란? 동일한거 가까이, 다른거 멀리 두고 pair비교하는 것--> positive pair인지 아닌지 NLP에서는 두 문장의 의미가 같은지를 확인한다. 가까운 이웃을 더 가깝게하고, 먼 이웃들은 더 pushing 하는 방법이다.
11.[논문리뷰] GPT1, GPT2, GPT3 차이와 한계
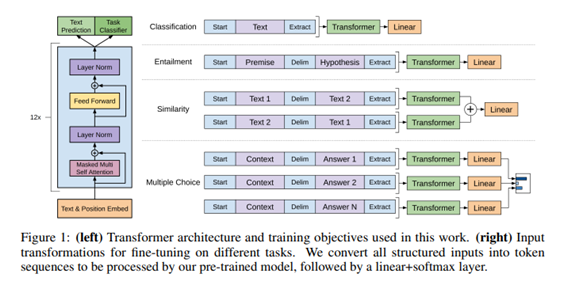
이전부터 BERT관련된 모델들을 리뷰하며,,, GPT와 비교하는 결과가 많았고 이전에 논문을 읽었지만 다시읽으며 GPT 모델 발전과정과 차이점을 서술해본다\~~!대부분의 딥러닝 task는 label을 만들기위해 비용이 많이 든 data가 필요하다. 하지만 실제 가지고
12.[kaggle] 텍스트전처리부터 모델링까지
1월부터 캐글 스터디를 진행했다.매주 캐글에서 데이터를 찾아 성능이 높거나, 알아보고 싶은 코드를 분석해서 발표하는 형식이다. nlp에 관심이 있어 스팸 메일 관련 데이터를 골라 이번주에 발표를 준비했고, 준비하면서 알게 된 개념들을 간략히 정리한다.
13.[논문리뷰] FastText
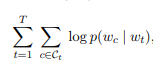
기존의 인기있는 모델들은 단어마다 다른 벡터를 할당하여 단어의 형태를 무시한다. 큰 어휘들과 드물게 사용되는 단어에 한계가 있다. 이 한계를 극복하기 위해 본 논문에서는 skipgram 기반 모델로, 각각의 단어를 character n-gram 벡터의 조합으로 표현했다
14.[논문리뷰] Convolutional Neural Networks for Sentence Classification
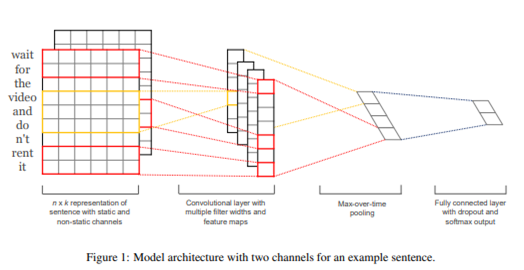
본 논문에서는 사전 학습된 word vector에 CNN을 사용한 sentence classification 모델을 제안한다. 특히 간단한 CNN 모델 + 약간의 하이퍼파라미터 튜닝과 static vector를 통해 여러 벤치마크에서 훌륭한 성과를 거두었다. word
15.[논문 리뷰] Seq2Seq
실제 구현 코드를 참고하며..! 동빈나님의 seq2seq code기존 DNN은 sequence와 sequence를 매핑하는데 사용할 수 없다는 한계점이 있다. 본 논문에서는 문장 구조에 대한 최소한의 가정만 하는 sequence learning에 관한 end-to-en
16.N-gram
N-gram은 카운트에 기반한 통계적 접근을 사용하고 있으므로 SLM의 일종이다. 일부 단어를 몇 개 보느냐를 결정하는데 이것이 n-gram에서의 n이 가지는 의미이다.
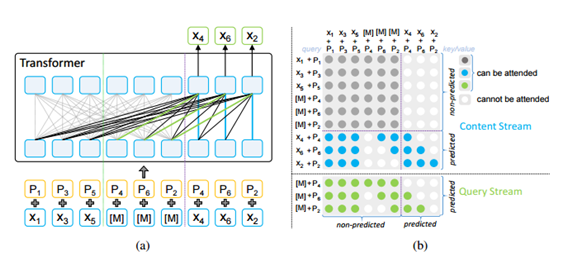
17.[논문리뷰]MPNet
XLNet AR의 장점 + AE의 장점을 combine하기 위해 permutation objective 사용한 AR 기반의 모델이다.