TabNet: Attentive Interpretable Tabular Learning
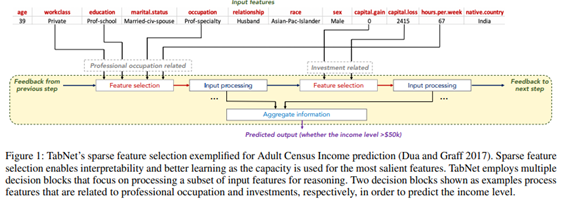
TabNet은 tabular 데이터의 훈련에 맞게 설계됐으며 Tree기반 모델의 변수선택 특징을 네트워크 구조에 반영한 모델이다. 이는 딥러닝 모델이 해석하기 어려운 문제를 sequential attention mechanism을 이용하여 해석을 용이하게 만들었다.
tabular 데이터란?
Row에 데이터, Col에 Feature로 되어있는 테이블 형태의 Dataset이다. (정형데이터이다.)
배경
기존에 딥러닝 모델들은 이미지. 텍스트, 오디오 데이터 등 비정형 데이터에서 notable success를 이루었다. 하지만 tabular data에는 잘 작동하지 못했다. XGBoost, LightGBM, Catboost 과 같은 Tree 기반의 앙상블 모델을 선호하는 경우가 많다.
tabular data에 Tree기반의 앙상블 모델들이 딥러닝 모델보다 우수한 이유
- Tree기반의 모델들이 학습이 빠르고 쉽게 개발할 수 있다.
- Tree기반의 모델들은 해석이 용이하다.
- 딥러닝 모델은 지나치게 Overparametrized된다는 문제가 있다.-귀납편향(inductive bias)으로 종종 tabular data의 최적의 솔루션을 찾는데 실패하는 원인이 된다.
귀납편향이란?
학습 시 만나보지 못한 상황에 정확한 예측을 하기 위해 사용하는 추가적인 가정을 뜻한다.
하지만, 딥러닝 모델의 장점도 있어 이를 결합해서 만든 딥러닝 모델이 tabnet인 것이다!
딥러닝의 장점
- multiple data type이 가능하다. 즉 Tabular data와 이미지(텍스트) 등 다른 데이터 타입을 학습에 함께 사용할 수 있다.
- 훈련 데이터가 매우 많아지면, 계산 비용은 많이 들지만 성능은 더 높일 수 있다.
- Tree 기반에서 필수적인 Feature Engineering과 같은 단계를 완화시킬 수 있다.
- Streaming 데이터로부터의 학습이 용이하다. Tree 기반의 모델들은 데이터의 분기를 통해 Global한 통계적 정보를 이용해야 하므로 스트리밍 학습은 어렵다는 큰 단점이 존재하는 반면 딥러닝 모델은 그러한 학습에 유연하다.
- 딥러닝 End-to-End모델은 Domain adaptation, Generative modeling, Semi-supervised learning과 같은 가치있는 Application이 가능하다는 장점이 있다.
그래서 논문에서는 DNN architecture을 재구성하였다.
tabnet의 메인을 요약하자면,
-
TabNet은 Feature의 전처리없이 raw한 데이터를 입력으로 사용할 수 있고, Gradient-descent 기반 최적화를 사용하여 End-to-End learning을 가능하게 하였다.
-
성능과 해석력을 향상시키기 위하여, Sequential attention을 사용하여 각 decision step으로부터 어떤 feature를 사용할지를 선택했다. 또한 변수선택에 있어 single 딥러닝 아키텍처를 사용했다. 이러한 변수선택 방법은 instance-wise하게 입력되고 각각마다 다르게 수행한다.
-
여러 데이터셋에서 기존의 분류, 회귀 모델들보다 성능의 우수성을 가진다. 그리고 해석력의 관점에서 두가지의 해석력을 가능하게 했다.
- 입력 Feature의 중요도와 Feature들이 어떻게 결합되었는지를 시각화한 local한 해석력과,
- 학습된 모델에서 각 입력 Feature들이 얼마나 자주 결합되었는지의 Global한 해석력을 제시했다.
-
마지막으로, tabular data에 대해 처음으로 masked features를 예측하여 unsupervised pre-training을 이용해 상당한 성능 향상을 보여주었다.
TabNet의 feature selection 작동원리
TabNet의 Feature selection은 특정 feature들만 선택하는 것이 아니라, 마치 Linear Regression처럼 각 feature에 가중치를 부여하는 것이다. 즉, 설명 가능한(explainable) 모델이 되는 것이다. 훈련 가능한 마스크는 dense한 마스크가 아닌 sparse한 마스크가 되어야 한다. 따라서 input feature의 차원이 클수록 훈련이 어렵고 이런 경우에는 tabnet을 적용하는 것이 좋은 선택이 아니다.
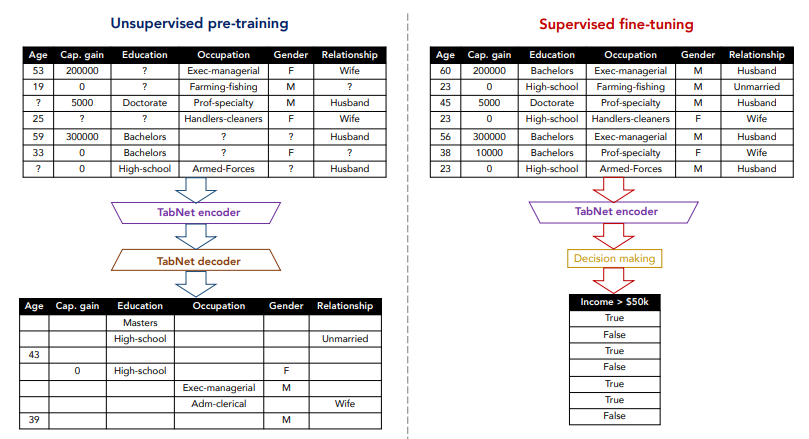
Semi-supervised Learning
인코더에 곧바로 디코더를 연결하면 Autoencoder 구조가 완성된다. Autoencoder는 별도의 정답 레이블 정보가 필요하지 않기 때문에 unsupervised learning이다. 이를 적용하면 tabular 데이터에서 종종 보이는 결측값들을 대체할 수 있다. 또한, 결측치를 채운 데이터셋에 레이블 정보를 포함하여 supervised learning으로 fine-tuning을 적용할 수 있다.
TabNet 구조
TabNet의 구조는 AutoEncoder 구조이다.
Encoder(인코더)-Decoder(디코더)를 거쳐, 결측값들을 예측할 수 있는 Autoencoder 구조이다. 따라서, 데이터셋에 결측값들이 포함되어도 별도의 전처리 없이 값들을 채울 수 있다.
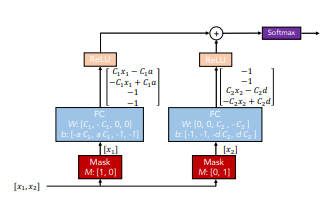
1. Encoder
인코더는 여러 Desicion Step으로 구성되며, Step 내의 두가지 블록이 존재한다.
- Feature transformer 블록 : 임베딩을 수행(=인코딩 수행)
- Attentive transformer 블록 : trainable Mask를 생성
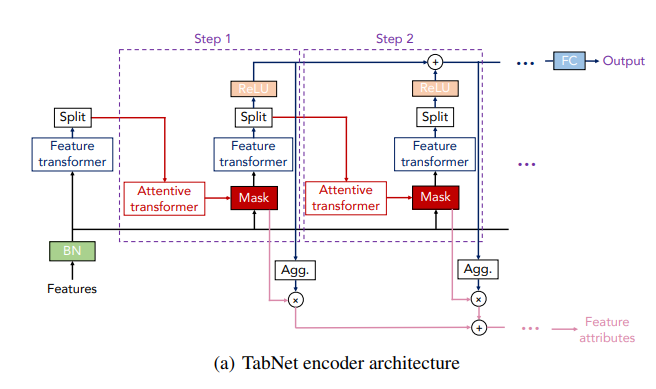
-
Mask의 3가지 용도
1) Feature Importance를 계산한다,
2) 이전 Step의 Feature에 곱하여 Masked Feature(다음 step에서 input feature) 생성한다,
3) 다음 Step의 Mask에서 적용할 Prior scale term 계산한다. -
Masked Feature는 다음 Step의 Input feature가 되며, 이전 step에서 사용되었던 Mask의 정보를 피드백하기에 Feature의 재사용 빈도를 제어할 수 있다.
2. Decoder
각 step은 feature transformer 블록에서 FC layer로 이루어지고 각 step 합산해서 reconstructed feature 결과를 산출한다. 디코더 구조를 통해 결측치 보간 효과가 가능하다.
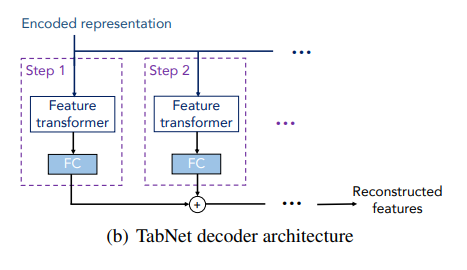
진행 순서
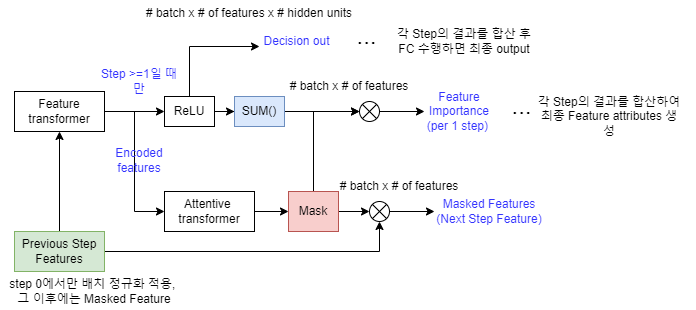
-
Input Feature의 차원은 batch x of features이다. 매 Step 마다 반복하기 전 Initial Step (Step 0)에서는 별도의 Mask Feature 없이 Ghost Batch Normalization을 수행한다.
Ghost BN은 전체가 아닌 샘플링 데이터에 대해서만 BN을 수행한다. -
Feature Transformer 블록에서 인코딩을 수행할 때,
Step ≥ 1인 경우, 인코딩된 결과에서 ReLU layer를 거쳐 해당 step의 Decision output을 생성한다. 각 step의 Decision output의 결과를 합산하여 overall decision 임베딩을 생성하여 이 임베딩이 FC layer를 거치면 최종 output (classification/regression 예측 결과)이 산출된다. -
인코딩된 결과는 Attentive transformer 블록을 거쳐 Mask를 생성한다. Mask에 Feature를 곱하여 Feature selection이 수행되기 때문에 Mask의 차원은 batch x of feature 이다.
Attentive transformer 블록 내에서 FC → BN → Sparsemax를 순차적으로 수행하면서 Mask를 생성한다. -
Mask는 이전 Step의 Feature와 곱하여 Masked Feature를 생성합니다. Sparsemax 함수를 거쳤기 때문에 일반적인 tabular 데이터에서 수행하는 Hard Feature Selection이 아닌 Soft Feature Selection이다. Masked Feature는 다시 Feature transformer로 연결되면서 Step이 반복된다.
Feature Transformer 블록
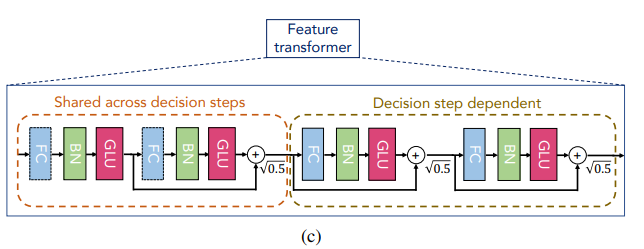
4개의 GLU(Gated Linear Unit) 블록으로 구성되어 있으며, 첫 2개의 GLU 블록들을 묶어서 shared 블록이라 하고 마지막 2개의 GLU 블록들을 묶어서 decision block이라고도 한다. 각 GLU 블록 간에는 Skip Connection을 적용하여 vanishing gradient 현상을 개선한다.
GLU(x)=
GLU 함수는 수식에서 알 수 있듯이, 이전 레이어에서 나온 정보들을 제어하는 역할을 하기 때문에 LSTM의 gate와 유사하다.
Attentive transformer 블록
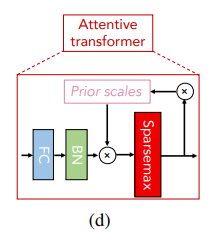
Mask는 어떤 feature를 주로 사용할 것인지에 대한 정보가 내포되어 있고, 그 정보는 다음 Step에서 유용하게 쓰이기에 다음 Step에서도 Mask 정보가 재활용된다. 이전 Step에서 사용한 Mask를 얼마나 재사용할지를 relaxation factor인 로 조절할 수 있고, 이를 반영한 term이 바로 prior scale term이다. 이 Prior scale term이 다음 Step에서의 Mask와 내적함으로써, Step-wise Sparse Feature selection이 가능하게 된다.
Sparsemax activation 함수
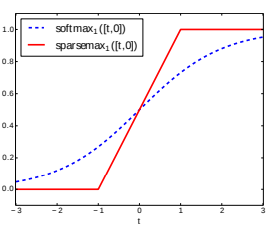
Softmax에 sparsity를 강화한 활성화 함수로 미분이 가능하며, Sparse Feature Selection의 핵심적인 역할을 하게 된다.
해당 논문의 key point
- 트리기반의 모델의 변수선택 특징을 활용해 정형데이터에도 모델 해석이 용이한 딥러닝 모델이 사용 가능하다는 것.
- Conventional DNN 블록을 사용하여 masking되지 않은 한 변수만 학습되도록 하고, 이는 트리 기반 알고리즘의 결정 경계와 유사한 역할을 가능하게 한다는 것.
- feature transformer는 Ghost Batch Norm, Gated Linear Unit(GLU) 등을 활용하여 선택된 변수로 정확히 예측할 수 있다는 것.
- feature transformer와 attentive transformer의 블록을 반복적으로 연결하여 이전 결과가 다음 학습에 영향을 주도록 해서 이전 모델 학습 결과의 잔차를 다음 단계에서 보완하는 gradient boosting와 유사한 결과를 낼 수 있다는 것.
- 정형 데이터에서도 Unsupervised pre-training 을 추구하고 fine-tuning이 가능하는 것.
-> 직접 사용할 때는 feature engineering에 시간을 많이 할애하는데 전처리가 필요없으니 사용하기 좋은 모델인 것 같다. 또한 결측치를 어떻게 대체할까 고민이 많은데 해결해주니 편리할 것 같다.
code
구글의 공식 코드와 공식 코드를 좀 더 개선한 PyTorch-TabNet이 있으니 링크에 들어가 참고하면 좋겠다!
[구글공식링크]https://github.com/google-research/google-research/blob/master/tabnet/tabnet_model.py
[pytorch링크]https://github.com/dreamquark-ai/tabnet
참고
https://arxiv.org/pdf/1908.07442.pdf
https://housekdk.gitbook.io/ml/ml/tabular/tabnet-overview#4.-semi-supervised-learning
