Abstract
text summarization 두가지 접근법
-
추출요약(extractive summarization): 주어진 문서 집합 "내"에서 중요한 단어나 문장을 선택하는 방법
-
생성요약(abstractive summarization): 앞모델을 보고 모든 생성 가능한 단어 중 새로운 문장을 생성하는 방법
pretrained bert를 기반으로 만든 텍스트 요약에 적용할 수 있는 모델을 소개한다.
1. Introduction
ELMo, GPT, BERT 등과 같은 pretrained language model은 감정분석, to question answering, natural language inference, named entity recognition, textual similarity에 이르는 많은 NLP task에서 SOTA를 달성했다. 대부분의 pretrained language model은 다양한 classification task를 관련된 문장 및 문단 수준의 자연어 이해를 위해 encoder를 사용했다.
본 논문에서는, language model이 text summarization에 미치는 영향을 검증한다. 이전의 task들과는 달리, Summarization은 개별 단어와 문장의 의미를 이해하는 것을 넘는 광범위한 자연어 이해 능력이 요구된다. 요약의 목표는 문서의 의미를 대부분 보존하면서 더 짧게 압축하는 것이다.
게다가 생성요약은 source text에 없는 새로운 단어나 구를 만들어 요약을 해야하기에 더욱 많은 능력을 필요로 한다.
-
Extractive Model : 문서 level의 특징을 포착하기 위해 encoder의 top에 몇 개의 inter-sentence transformer layers를 쌓아서 생성한다.
-
Abstractive Model : 사전 훈련된 BERT encoder를 랜덤하게 초기화된 transformer decoder와 결합하는 encoder-decoder architecture 적용한다.
Extractive, Abstractive setting 모두에서 'SOTA'를 달성했고 이 work는 세가지 기여를 했다.
- summarization task에 대한 document encoding의 중요성 강조했다.
- Extractive, Abstractive summarization 모두에서 pretrained language model을 효과적으로 사용하는 방법 제시했다.
- 추후 비슷한 앞으로의 연구들의 baesline으로 사용될 것이다.
2. Background
2.1 Pretrained Language Models
기존 BERT는 input에 총 세 개의 임베딩 층이 들어간다. token embeddings, segment embeddings, position embeddings
- token embeddings
- token embeddings은 해당 문서를 토큰화하고(문장이면 단어로 쪼갠다던지, 의미대로 나눈다던지), cls,sep 같은 special token을 사용하여 문장을 구분한다.
- 각 문장은 [sep]을 넣어 구분한다.
- 또한 input 시작에는 [cls]가 들어간다. 이 토큰은 Classification task에서는 사용되지만, 그렇지 않을 경우엔 무시, 무슨 의미냐면 데이터셋 모든 행의 첫번째 token은 언제나 [CLS](special classification token)으로 이 [CLS] token은 transformer 전체층을 다 거치고 나면 token sequence의 결합된 의미를 가지게 되는데, 분류를 하게 되면(classification task 수행하면) 단일 문장, 또는 연속된 문장의 classification을 쉽게 할 수 있게, cls로 각 문장을 확인할 수 있게 된다.
-
segment embeddings
segment embedding은 문장 간 비교를 하는 task에서만 사용한다. (두개의 문장에서만 사용가능 )
보통 [0 0 0 0 1 1 1]과 같이 표현하고 단어가 첫번째 문장에 속하는지 두번째 문장에 속하는지 알려준다. -
position embeddings
순서 정보를 구분하는 임베딩
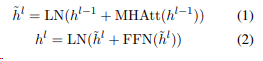
위의 식은 BERT의 세가지 임베딩을 single 벡터로 합쳐져서 input으로 들어가게 된다.
식의 표기
LN(layer nomalization): 정규화연산
MHAtt : multi head attention 연산
superscript l(h위에 있는) : stacked layer의 깊이를 의미
2.2 Extractive Summarization
이전 Extractive Summarization model 간략하게 설명~~
- neural model : extractive summarization을 classification 문제로 본다. neural encoder는 sentence representation을 만들고, classifier은 어떤 sentence을 요약으로 선택할지 예측한다.
2.3 Abstractive Summarization
이전 Abstractive Summarization model 간략하게 설명~~
- neural approaches는 Abstractive Summarization을 seq-to-seq 문제로 개념화한다. 인코더가 source document에 있는 연속적인 토큰 x를 z로 mapping하고 디코더는 모델링 조건부확률을 이용해서(auto-regressiove manner) 토큰별로 타겟요약 y를 자동으로 생성한다.
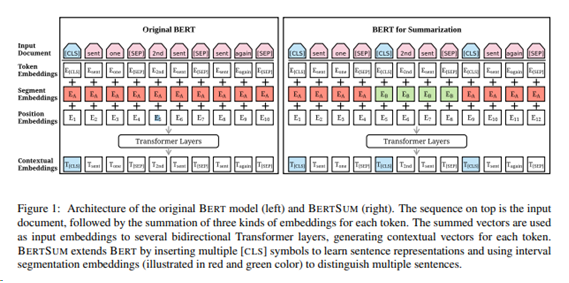
3. Fine-tuning BERT for Summarization
3.1 Summarization Encoder
기존의 bert를 summarization에 바로 사용하기에는 문제가 있다.
1. 버트는 masked-language model이기에 출력은 문장이 아닌 토큰 단위이다. extractive summarization의 경우는 대부분 모델은 문장 표현을 다룬다.
2. 버트는 segment embedding으로 sentence-pair를 입력으로 받는다. 하지만 요약 task에서는 여러 개의 문장(2문장 이상)들을 인코딩해야 한다.
따라서 입력 데이터 형태를 수정해서 사용할 수 있다.
1. [cls] token
기존 BERT에서는 첫번째 문장의 시작 부분에만 [CLS] 토큰을 추가했지만 요약 task에서는 BERT 모델에 여러 문장을 입력하고 입력한 모든 문장에 대한 표현이 필요합니다. 따라서 BERTSUM에서는 모든 문장의 시작 부분에 [CLS] 토큰을 추가하고 [CLS] 토큰 위치의 출력 벡터는 해당 문장의 feature를 함축하게 됩니다.
2. interval segment embedding
문장을 구별하는 segment embedding을 진행하는데 BERT에서는 주어진 두 문장을 E(A) 또는 E(B) 형태로 반환한다. 하지만 요약 task에서는 2개 이상의 문장을 입력하므로 interval segment embedding을 통해 여러 문장을 구별해야한다. 홀수 번째 문장에서 발생한 토큰은 E(A)에, 짝수 번째 문장에서 발생한 토큰은 E(B)에 매핑한다.
이렇게 새롭게 두가지를 바꿈으로써 하위 transformer layer가 인접한 문장을 표현하고, 상위 transformer layer가 self-attention과 combination으로 여러 문장의 결합된 형태를 표현하여 계층적으로 Document Representation을 학습할 수 있다.
또한 기존 BERT 모델의 positional embedding의 최대 길이는 512인데, BERTSUM에서는 무작위로 초기화되고, (encoder에서 다른 매개변수로 finetuned 되는)더 많은 positional embedding을 추가하여 이 한계를 극복했다.
3.2 Extractive Summarization
BERTSUMEXT
d : 문장들을 포함하는 document를 나타낸다. sent i : 문서에서 i번째 문장을 의미한다.
Extractive Summarization은 document의 각 i번째 문장(senti)을 요약문에 포함시킬지에 대한 여부를 yi∈{0,1}로 라벨링하는 것이라 정의한다.
BERTSUM에서 벡터 ti는 (top layer로부터 얻은 i번째 [cls] vector) sent i를 표현한다.
T를 transformer의 encoder layer에 공급한다.
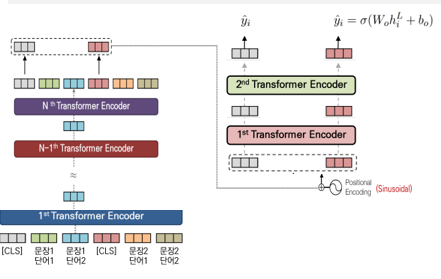
순서
1. BERT를 거쳐 나온 결과 중 [CLS] 토큰에 해당하는 벡터만 선택한다.
-
선택한 [CLS] 토큰들을 두개의 Layer로 이루어진 Transformer Encoder의 input으로 사용한다.
-
마지막 output을 이용해 binary classification 수행한다.
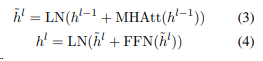
l = encoder
h = encoder로부터 표현된 은닉 상태 (encoder는 hidden state를 출력)
T : BERTSUM에 의해 출력된 문장 벡터
PosEMB : 벡터 T에 각 문장의 위치를 나타내는 positional embedding을 더해주는 함수
h0=PosEMB(T) 입력값 T에 위치 임베딩을 추가한 값
L = 최상위 encoder
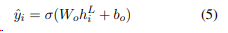
마지막 output layer는 sigmoid classifier로 각 문장을 요약에 포함시킬지 여부의 확률을 얻는다.
h(i)^L은 transformer의 top layer (L번째 layer)의 sent i (i번째 문장)에 대한 벡터이다. L = 2인 transformer가 가장 성능이 우수하다. 이 모델을 BERTSumExt라고 한다. BERTSUM과 함께 동시에 fine-tuning 되었고 옵티마이저는 Adam을, learning rate는 아래 식을 따른다.
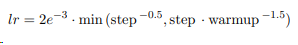
- 정리하면, BERT로부터 나온 문장의 표현인 ti를 입력받아서 위치 인코딩을 해준 후, 트랜스포머의 인코더에 입력으로 넣어주고, 인코더를 거쳐 최상위 인코더의 은닉 상태인 h(I)^L값을 얻습니다. 그 이후 h(I)^L을 시그모이드 분류기에 입력해 요약에 문장의 포함 여부를 반환하는 프로세스를 거치게 됩니다.
3.3 Abstractive Summarization
BERTSUMABS
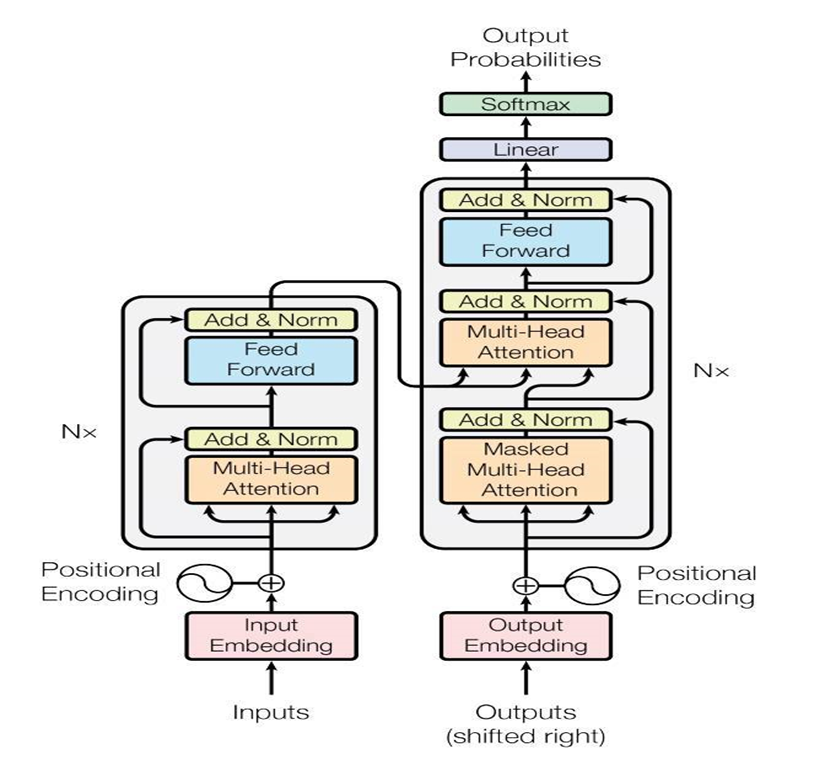
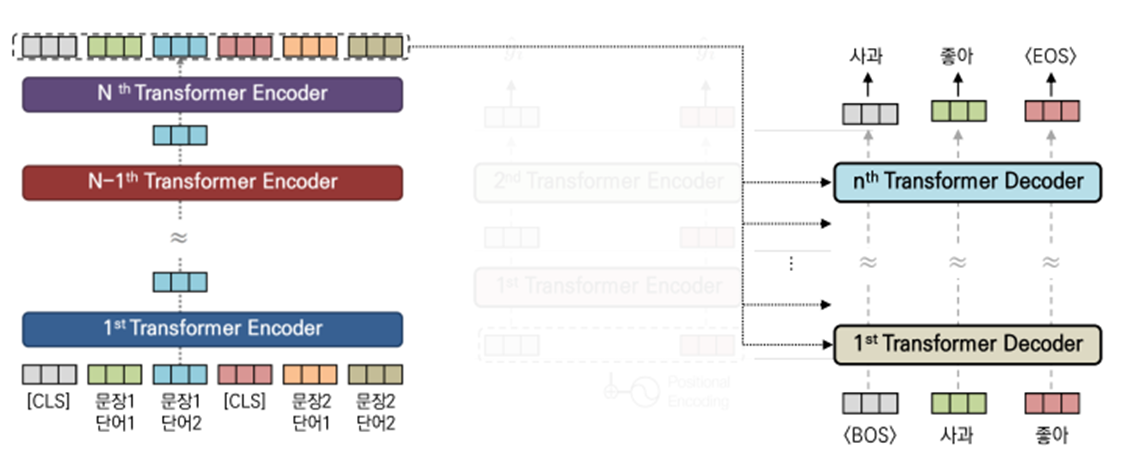
Abstractive Summarization을 수행하기 위해 stardard encoder-decoder framework를 사용한다. 인코더는 pretrained된 BERTSUM을 의미하고 디코더는 랜덤하게 초기화된 6-layered transformer를 의미한다.
- 인코더(왼) 디코더(오)
문장 생성 순서
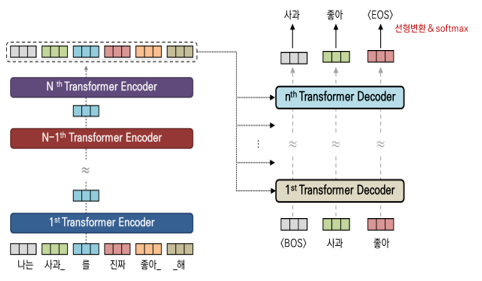
문장생성에는 sampling, bimsearch등 다양한 기법이 있지만 greedy 방식으로 설명한다.
-
문장을 시작하는 BOS(begining of sentence)를 받아 요약문의 첫 단어를 예측한다.
-
앞서 예측한 단어를 받아서 다른 단어를 생성한다.
-
모델이 EOS(end of sentence)를 예측하면 문장생성이 종료된다.
encoder는 의미있는 표현을 생성하고, decoder는 이 표현을 사용해 요약을 생성하는 방법을 학습한다. 하지만 여기에는 fine-tuning 중에 encoder와 decoder 사이에 불일치가 발생한다는 문제점이 존재한다.
encoder는 pretrained 되어있기 때문에 과적합될 수 있고, decoder는 무작위로 초기화되어있기 때문에 과소적합이 발생할 수 있다. 이를 해결하기 위해 adam optimizer 2개를 사용한다. (beta1=0.9, beta2=0.999)
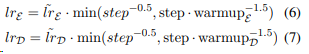
encoder와 decoder에 서로 다른 학습률을 적용한다. (6)이 인코더 학습률, (7)이 디코더 학습률.
encoder가 pretrained 되어 있기 때문에 학습률을 줄이고 좀 더 부드럽게 감쇠하도록 설정한다. (decoder가 안정화되고 있을 때 encoder가 더 정확한 gradient로 학습될 수 있도록)
BERTSUMEXTABS
이 모델은 Two-stage fine-tuning approach를 제안하는데, 먼저 Extractive Summarization task에서 encoder를 먼저 fine-tuning하고, 이후 Abstractive Summarization task에서 fine-tuning을 진행한다. architecture의 변화없이 두 task간의 공유되는 정보를 활용할 수 있다는 장점이 있고 성능이 BERTSUMABS보다 성능이 더 뛰어났다.
4. Experimental Setup
4.1 Summarization Datasets & Results
ROUGE 평가지표 사용
-
ROUGE는 텍스트 자동 요약, 기계 번역 등 자연어 생성 모델의 성능을 평가하기 위한 지표이며, 모델이 생성한 요약본 혹은 번역본을 사람이 미리 만들어 놓은 참조본과 대조해 성능 점수를 계산합니다.
-
ROUGE-1 : unigram(n=1, n개의 단어뭉치 단위로 끊어서 하나의 토큰으로 간주)
-
ROUGE-2 : bigram overlap(n=2)
-
ROUGE-L : fluent(유창함) 평가
BERT-based model은 다른 abstractive model, extractive model보다 뛰어남 -
ORACLE : r2를 maximize하는 문장을 구성하는 알고리즘을 생성하는 방법
-
LEAD3 : base-line (document의 앞의 3문장 이용)
모델 평가를 위해 3가지 benchmark dataset을 이용함.
1. the CNN/DailyMail(somewhat Extractive)
기사에 대한 간략한 개요 포함, 512 tokens로 제한
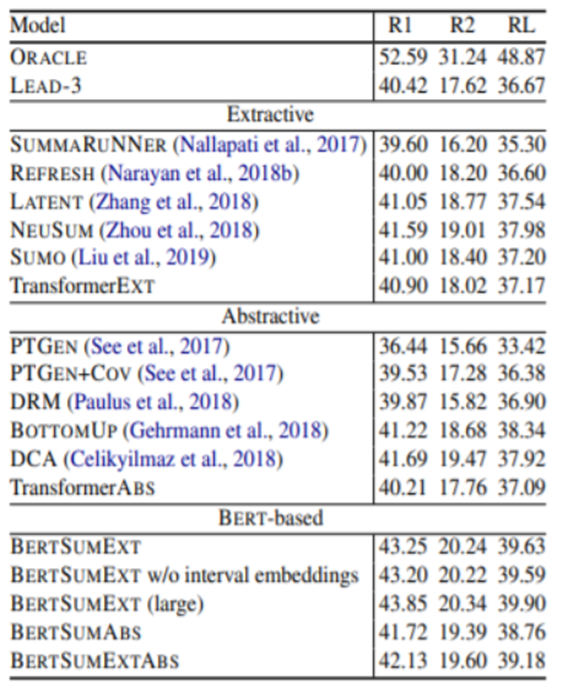
→ BERTSUMEXT(large)가 가장 좋은 성능.
2. the New York Times Annotated Corpus(NYT) (somewhat Extractive)
abstractive summaries 있는 110,540개의 기사를 포함, 800 tokens로 제한
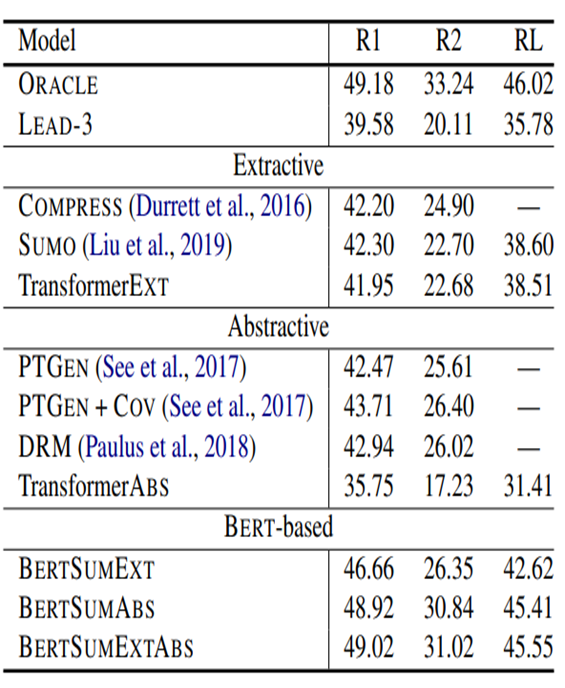
→ ORACLE의 성능에 매우 가까움
3. XSum (somewhat abstractive)
‘What is this articles about?’의 질문에 답하는 226,711개의 뉴스 기사 + 한 문장 요약본 포함, 512 tokens로 제한
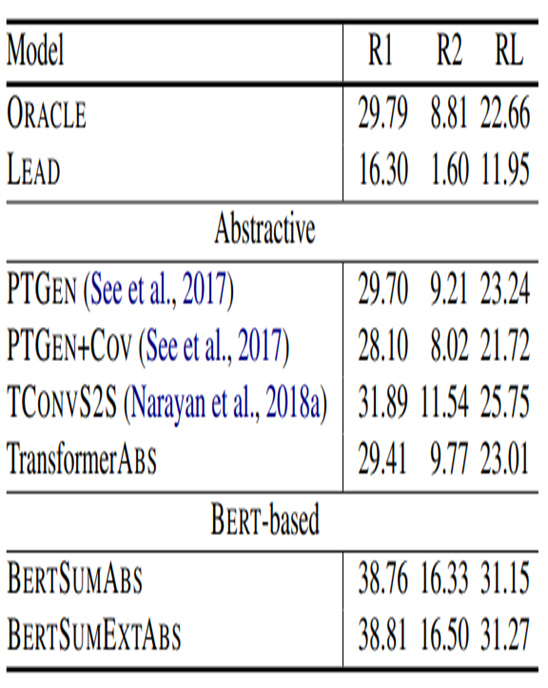
->BERT-based model의 매우 우수한 성능
Extractive model은 Extractive summary를 가진 dataset에서 더 나은 성능을 발휘하고, Abstractive model은 Abstractive summary를 가진 dataset에서 더 나은 성능을 발휘할 것이라 기대한다.
4.2 Implemetation Details
Extractive and Abstractive setting으로 파이토치를 사용했으며 BERTSUM을 구현하기 위해 ‘bert-base-uncased’ 버전의 BERT를 사용했다.
Extractive Summarization
모든 모델은 50,000 steps on 3 GPUs를 사용하여 train했고 1000step마다 model checkpoint 저장
중복 문장을 줄이기 위해서 요약문 내의 후보 문장끼리 겹치는 trigram이 존재하면 해당 후보를 스킵하는 방식인 Trigram Blocking 방식을 사용했다. 이미 요약의 일부분으로 선택된 문장과 숙고 중인 문장 사이의 유사성을 최소화하기 위해서이다.
Abstractive Summarization
200,000 steps on 5 GPUs를 사용하여 학습이 되었고, 5 step마다 gradient accumulation을 적용, 2500 step 마다 model checkpoint 저장
모든 abstractive model에서 모든 linear layer 앞에 dropout(0.1)을 적용하고 label smoothing(factor 0.1) 적용
transformer decoder hidden units : 768
hidden size for feed-forward layers : 2048
End-of-sequence token이 나올 때까지 decoding & Trigram Blocking
Conclusion
pretrained BERT는 텍스트 요약에 유용하게 활용될 수 있음을 보여줌.
Abstractive & Extractive summarization을 위한 프레임워크를 제안함.
세가지 데이터셋에 대한 실험결과는 BERTSUM 모델이 automatic & human-based 평가 지표에 sota를 달성한다는 것을 보여준다.
