XLNet 요약
XLNet AR의 장점 + AE의 장점을 combine하기 위해 permutation objective 사용한 AR 기반의 모델이다. 또한 XLNet이 원활하게 work하기 위해 Transfromer-XL의 기술이 합쳐지고, two-stream attention mechanism으로 디자인 됐다.
- transformer-XL에서 사용되는 두가지 중요한 기술 relative positional encoding scheme과 segment recurrence mechasnism을 pre-training framework에 포함시켰다.
- permutation 개념
토큰을 랜덤으로 셔플한 뒤, 그 뒤바뀐 순서가 마치 원래 그랬던 것 처럼 언어모델을 학습하는 기법이다. 퍼뮤테이션 방식으로 예측을 수행하면, 문장 전체 문맥을 살필 수 있게 된다. 예측해야할 단어를 제외하고 모든 문장의 부분집합 전부를 학습한다. 즉 permutation 집합을 통해 다양한 시퀀스를 고려할 수 있고 이를 AR objective function에 대입해서 특정 토큰에 양방향 context를 고려할 수 있다.
BERT pretraining 과정에서 사용하는 MASK 토큰이 finetuning 할 때에는 쓰이지 않는 문제를 해결했다.
Abstract
XLNet은 문장의 전체 위치정보를 활용하지 않기 때문에 사전학습과 파인튜닝 간의 위치 불일치가 발생한다. MPnet은 토큰 간 종속성을 활용하고 보조 위치 정보(모든 토큰 위치 정보를 입력으로 받아)를 입력으로 사용해 모델이 전체 문장을 볼 수 있도록 하여 pretrain-fine tuning 간 위치 불일치를 줄인다.
1. Introduction
Masked Language Modeling + permuted Language Modeling => MPnet
1. 예측된 토큰 간의 종속성을 PLM을 통해 고려하므로 BERT의 문제점을 해결한다.
2. 모든 토큰의 포지션 정보를 입력으로 받아 모델이 모든 토큰의 포지션 정보를 볼 수 있도록 하여 XLNet의 포지션 불일치를 완화한다.
실험 결과 MPNet이 MLM과 PLM을 크게 능가했다.
2. MPnet
2.1 Background

x : token p : position embeddings 의미. (a)-MLM, (b)-PLM 둘다 왼쪽은 원래 순서이고 오른쪽은 permuted 순서
출력 종속성 관점
MLM은 마스킹된 토큰이 서로 독립적이라고 가정하고 개별적으로 예측하므로 자연어의 복잡한 컨텍스트 종속성을 모델링하기에는 충분하지 않다. 반면 PLM은 MLM의 독립성 가정을 피하고 예측된 토큰 간의 종속성을 더 잘 모델링할 수 있게 순열된(permuted) 순서를 사용하여 예측된 토큰을 분해한다.
입력 일관성 관점
다운스트림 작업의 파인튜닝에서 모델은 전체 입력 문장을 볼 수 있으므로 사전 훈련과 파인튜닝 간의 일관성을 보장하기 위해 모델은 사전 훈련 중에전체 문장에 대해 가능한 한 많은 정보를 볼 수 있어야 한다.
MLM에서 일부 토큰은 마스킹되지만 해당 위치 정보(즉, 위치 임베딩)는 전체 문장의 정보(문장에 있는 토큰 수, 즉 문장 길이)를 (부분적으로) 나타내는 모델에서 사용할 수 있다. 그러나 PLM의 각 예측한 토큰은 앞선토큰만 볼 수 있고 AR 사전 훈련 중에 전체 문장의 위치 정보를 알지 못하므로 사전 훈련과 파인튜닝 간에 불일치가 발생한다.
2.2 A Unified View of MLM and PLM
BERT와 XLNet 모두 Transformer 를 백본으로 사용한다 . Transformer는 토큰과 해당 위치를 입력으로 사용하며 각 토큰이 문장의 올바른 위치와 연결된 경우에만 해당 토큰의 입력 순서에 민감하지 않다. 이는 그림 1에서와 같이 토큰을 예측되지 않은 부분과 예측된 부분으로 재정렬하고 분할하는 MLM 및 PLM에 대해 통합된 관점에서 볼 수 있도록 영감
을 줬다. 그림 1(a)는 왼쪽에 있는 인풋은 먼저 시퀀스를 순열한(permuted) 다음 가장 오른쪽에 있는 토큰을 마스킹하는 것과 같다. 그림 1(b)의 PLM 의 경우 시퀀스 (x1, x2, x3, x4, x5) 가 먼저 (x1, x3, x5, x2, x4)로 치환된 다음 가장 오른쪽 토큰 x2 및 x4 가 예측된 토큰으로 선택된다. 즉, MLM 및 PLM 모두에서 마스킹되지 않은 토큰은 왼쪽에 배치되고 마스킹되고 예측될 토큰은 순열 시퀀스의 오른쪽에 있다.
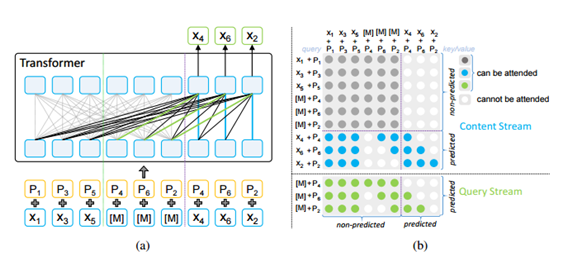
(a) MPNet의 구조. (b) MPNet의 어텐션 마스크.
-
(a)의 밝은 회색 선은 예측되지 않는 부분에서 양방향 self-attention을 나타낸다. 이는 (b)의 밝은 회색 어텐션 마스크에 해당한다.
-
(b)의 파란색 및 녹색 마스크는 2개 스트림 셀프 어텐션에서 어텐션 마스크와 쿼리 스크림을 나타낸다. 이는 (a)의 파란색, 녹색 및 검은색 선에 해당된다. 콘텐츠와 쿼리 스트림의 일부 어텐션 마스크가 겹치기 때문에 (a)에서 검정색 선을 사용하여 표시한다.
-
(b)의 각 행은 쿼리 위치에 대한 어텐션 마스크를 나타내고 각 열은 키/값 위치를 나타낸다. 예측 부분(s4, x6, x2)은 쿼리 스크림에 의해 예측된다.
training objective 제시

2.3 Our Proposed Method

MPNet은 셀프어텐션 사용하는 두 개의 stream을 이용했다.
각 단계에서 항상 n개의 토큰 을 볼 수 있도록 쿼리 및 콘텐츠 스트림에 대해 어텐션 마스크를 설계했다. 쿼리 스트림은 콘텐츠 스트림에서 숨은 항목을 재사용하여 키와 값을 계산한다.
2.4 Discussions
MLM, PLM 및 MPNet의 조건부 정보를 설명하기 위한 ‘the task is sentence classification’라는 예문.
마스킹된 단어를 예측하는 동안 MPNet은 문장의 전체 보기를 캡처하기 위해 모든 위치 정보에 대한 조건을 지정한다. MLM은 독립적으로 mask token 맞추고 PLM은 위치정보를 반영못함.

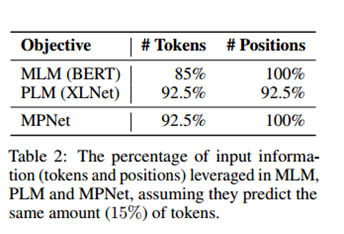
- 결과 : 동일한 15%의 토큰을 예측한다고 가정할 때 세 모델에서 활용된 입력 정보(토큰 및 위치)의 백분율.
3 Experiments and Results
3.1 Experimental Setup
- BERTBASE, (12 transformer layers, with 768 hidden size, 12 attention heads, and 110M model parameters in total.) 모델 사용
MPNet의 pretraining을 위해 PLM로 다음 문장을 무작위로 치환하여 가장 오른쪽 15% 토큰을 예측 토큰으로 선택하고 BERT와 동일한 8:1:1 변환 전략에 따라 마스크 토큰을 준비한다.
배치의 문장 길이를 최대 512개의 토큰으로 제한하고 배치 크기를 8192문장으로 사용하고 adam씀.
Fine‑tuning 동안, 우리는 two‑stream self‑attention에서 쿼리 스트림을 사용하지 않고 컨텍스트 표현을 추출하기 위해 원래 숨겨진 상태를 사용한다 . 각 후속 작업에 대한 미세 조정 실험을 5회 수행하고 중간 값을 최종 결과로 선택한다.
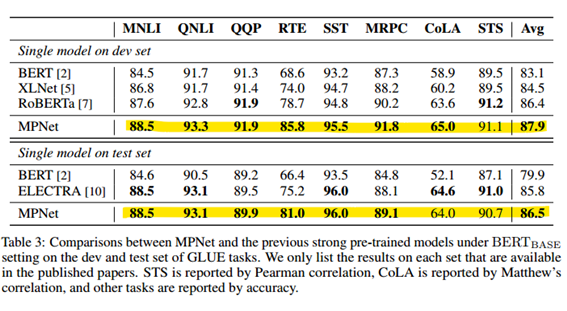
3.2 Results on GLUE Benchmark
9개의 자연어 이해 작업 모음으로 정확도 비교.
3.3 Results on Question Answering (SQuAD)

3.4 Results on RACE
중고등학생의 영어 시험에서 수집한 대규모 데이터 세트로 주어진 옵션에 따라 올바른 선택하는 것.

3.5 Results on IMDB
이진 감정 분류를 위한 50,000개 이상의 영화 리뷰가 포함된 IMDB 텍스트 분류 작업

4 Conclusion
본 논문에서는 BERT의 MLM과 XLNet의 PLM의 문제점을 해결하기 위한 새로운 사전 훈련 방법인 MPNet을 제안하였다. MPNet은 순열 언어 모델링을 통해 예측된 토큰 간의 종속성을 활용 하고 모델이 보조 위치 정보를 볼 수 있도록 하여 사전 학습과 파인튜닝 간의불일치를 줄인다. 다양한 작업에 대한 실험은 MPNet이 MLM 및 PLM뿐만 아니라BERT, XLNet, RoBERTa와 같은 이전의 강력한 사전 훈련된 모델보다 훨씬 뛰어난 성능을보인다는 것을 보여준다.
