해당 포스팅은 공부한 내용을 바탕으로 작성한 것으로, 잘못된 내용이 있을 수 있습니다.
Webflux란?
Webflux는 비동기 웹 애플리케이션을 ‘반응형 프로그래밍(Reactive Programming)’을 구현하기 위해 Reactor라는 라이브러리를 이용한다.
Reactor는 Netty 서버를 통해 비동기식 이벤트 기반의 서버를 환경을 제공한다. 이를 이용하여 비동기, Non-blocking 요청을 통해 이벤트 기반의 반응형 스트림으로 데이터를 주고 받는다.
동기, 비동기, Blocking, Non-Blocking
앞 서 설명했듯이 Webflux는 비동기 Non-Blocking 을 전제로 한다. 이를 이해하기 위해 동기, 비동기 그리고 Blocking, Non-Blocking 에 대해 비교해보자.
동기, Blocking
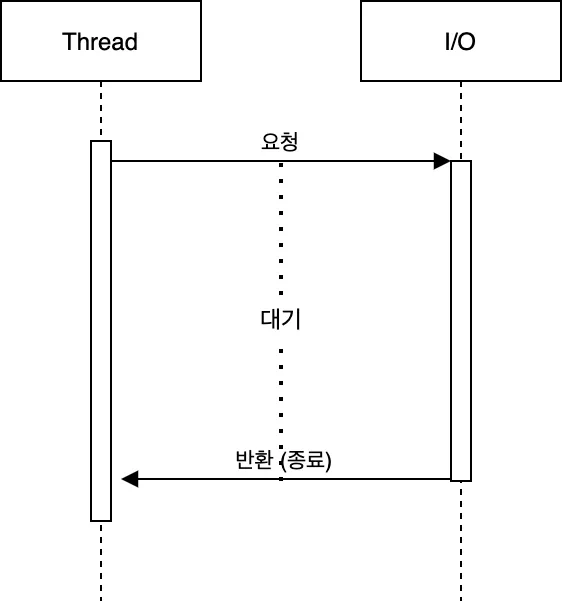
이미지 출처 : Medium - Choi Geonu, 백엔드 개발자들이 알아야할 동시성 2 — 블로킹과 논블로킹, 동기와 비동기
동기, Blocking 은 전통적인 Spring Web-MVC 의 동작 방식이다. 하나의 요청을 하나의 쓰레드에서 담당하고 Blocing I/O 작업이 있으면 함수 실행 제어권을 넘기고 쓰레드가 대기 상태가 되며 작업이 완료되었을 때 값을 반환받아 다시 이후 작업을 수행한다.
이 방식은 흐름을 따라가기 쉽고 익숙한 방식이라는 장점이 있다.
하지만 DB 혹은 외부 API 호출과 같이 외부에서 작업할 때, 스레드는 일을 하지 않음에도 대기하고 있어야하고 요청이 많아지면 자원이 남는데도 요청을 처리하지 못하는 상황이 발생할 수 있다.
동기, Non-Blocking
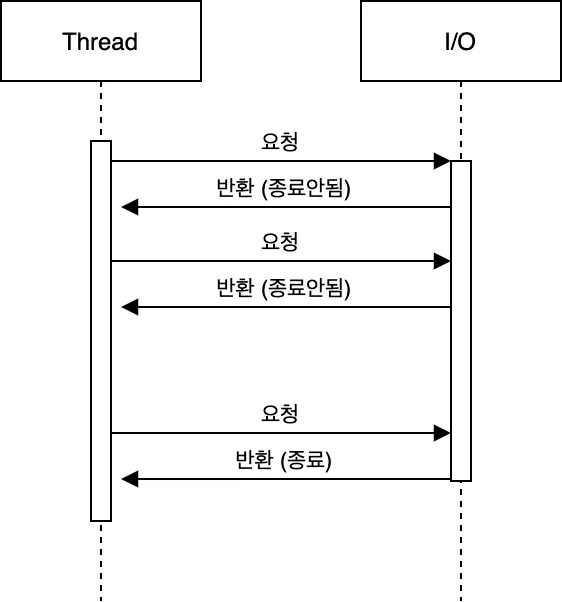
이미지 출처 : Medium - Choi Geonu, 백엔드 개발자들이 알아야할 동시성 2 — 블로킹과 논블로킹, 동기와 비동기
동기, Non-Blocking은 I/O 작업 발생 시 제어권을 넘기지 않고 작업을 수행한다. 그리고 작업이 끝났는지 수시로 확인하게 되는데, 이를 Polling 이라고 한다. I/O 작업이 발생해도 쓰레드가 작업을 수행할 수 있지만 수시로 발생하는 Polling 때문에 자원이 낭비된다는 문제점이 있다.
비동기, Non-Blocking
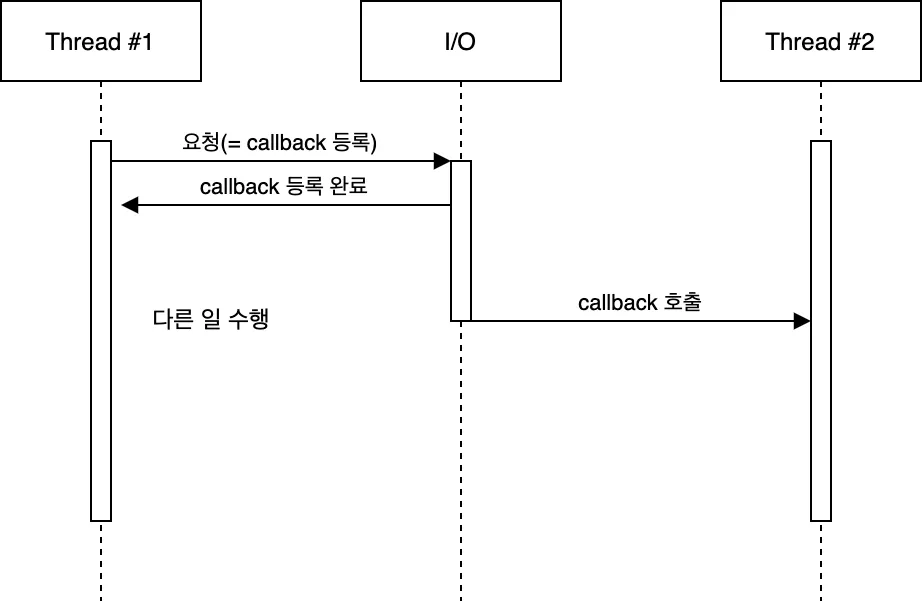
이미지 출처 : Medium - Choi Geonu, 백엔드 개발자들이 알아야할 동시성 2 — 블로킹과 논블로킹, 동기와 비동기
마지막으로 Webflux의 환경인 비동기, Non-Blocking 는 I/O 작업을 시작해도 제어권을 넘기지 않으며 지속적으로 I/O 작업이 끝났는지 확인하는게 아닌, callback을 등록하여 I/O 작업을 마치면 callback을 호출해 작업이 완료되었음을 알린다. Webflux는 이러한 환경에서 보다 적은 쓰레드로 더 효율적으로 작업을 처리할 수 있다.하지만, 이 방식은 흐름을 예측하기 어렵고 개발 비용이 올라갈 수 있다는 단점이 있다. 또한 중간에 Blocking 작업이 들어가면, 제 성능을 온전히 낼 수 없다는 점도 주의해야 한다.
일반적으로 Webflux 환경에서는 Web-Mvc 환경보다 사용하는 스레드가 적으므로 Blocking 작업에 의해 오히려 성능이 떨어질 수 있다.
Publisher-Subscriber 패턴
Webflux는 다음과 같은 Publisher-Subscriber 구조로 이루어져있다.
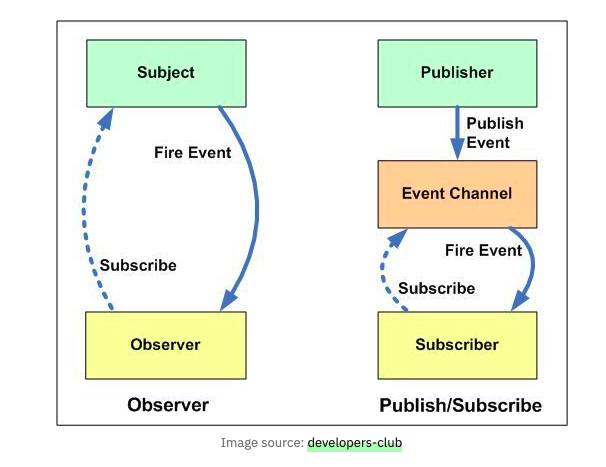
Publisher는 데이터를 생산하여 Event에 전달한다. Subscriber는
Obserber 패턴과 굉장히 유사하지만, 중간에 Event 채널을 둠으로써 결합도를 낮추었으며 비동기식 이벤트 기반 환경에 더 적합하도록 설계되었다.
Webflux에서는 Publisher 인터페이스를 구현한 Mono, Flux 등을 통해 고수준 API를 제공하고 보다 쉽게 프로그래밍할 수 있도록 돕는다.
그래서 Subscriber는 누구야?
Webflux를 통해서 구현한 엔드포인트는 Mono, Flux 인스턴스를 반환하도록 구현한다.
Nothing Happens Until You
subscribe()
하지만 ProjectReactor 공식 문서를 보면 subscribe() 하기 전까지는 아무런 일도 일어나지 않는다고 설명되어 있다. Publisher는 구독이 등록될 때 까지 아무런 행동을 하지 않는다.
그렇다면 subscribe() 는 어디서 호출하고, Subscriber는 누구일까?
이에 대한 답변은 이 질문 (stackoverflow - who calls subscribe) 에서 찾아볼 수 있다.
Mono와 Flux는 Webflux 애플리케이션 내부에만 존재하므로, 프레임워크 내부에서 subscribe() 를 호출한 뒤 HTTP 요청에 매핑하여 반환한다는 것이다.
Subscriber 는 애플리케이션 내부에서 생성되지만 이는 요청하는 클라이언트에 의한 것이다. 즉, 서버의 엔드포인트를 요청하는 클라이언트가 Subscriber 라고 이해하면 될 것이다.
참고로 Webflux의 default 서버인 netty에서는 HttpServer 클래스의 onStatechange() 를 통해 subscribe() 를 호출하는 것을 확인할 수 있다.
public void onStateChange(Connection connection, ConnectionObserver.State newState) {
if (newState == HttpServerState.REQUEST_RECEIVED) {
...
HttpServerOperations ops = (HttpServerOperations)connection;
Publisher<Void> publisher = (Publisher)this.handler.apply(ops, ops);
Mono<Void> mono = Mono.deferContextual((ctx) -> {
ops.currentContext = Context.of(ctx);
return Mono.fromDirect(publisher);
});
if (ops.mapHandle != null) {
mono = (Mono)ops.mapHandle.apply(mono, connection);
}
mono.subscribe(ops.disposeSubscriber());
...
}
}Mono와 Flux
Webflux 환경에서 개발을 하려면 Mono와 Flux를 통해서 모든 데이터 처리를 해야하기 때문에, 이들이 제공하는 Operator 를 알아야 한다. 다만, 제공하는 Operator의 갯수가 굉장히 많기 때문에 공식 문서에서도 모든 Operator를 숙지하는 것을 권장하지 않으며 원하는 Operator를 쉽게 찾을 수 있도록 돕는 문서를 제공한다.
이 중 많이 사용되는 Operator 몇 가지를 살펴보자.
map
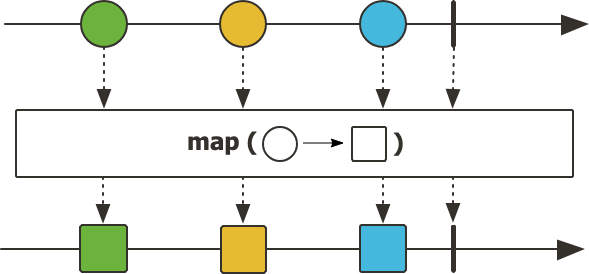
map() 연산은 동기적으로 작동하며 element를 다른 값 혹은 타입으로 변경하기 위해 사용한다.
동기식으로 작동하기 때문에, 비동기 환경에서 작동해야 하는 api를 map() 으로 호출하게 되면 비동기의 이점을 활용하지 못하게 될 수 있다.
또한, map()은 연산마다 객체를 생성하기 때문에 chain 하여 너무 많이 사용하게 되면 GC의 대상이 늘어나 성능이 저하할 수 있으니 이러한 점들을 주의해서 사용해야한다.
flatMap
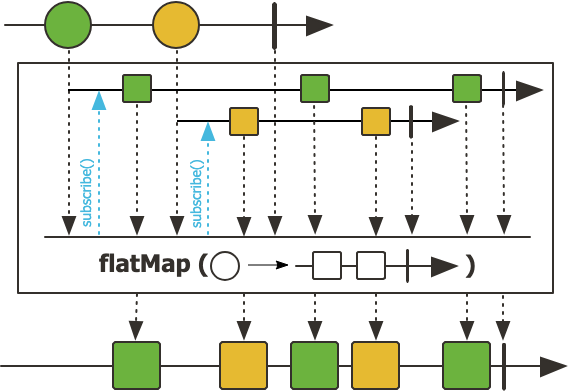
flatmap() 은 비동기적으로 동작하며, element를 활용해 새로운 Publisher를 만들고 inner Publisher를 구독한다.
새로운 Publisher를 만들기 때문에, 다양한 상황에서 유연하게 적용할 수 있다는 장점이 있다.
또한 비동기적으로 동작하기 때문에, 데이터를 통해 비동기를 지원하는 api를 호출하는 등의 작업을 하기에 적합하다.
주의점은 마블 다이어그램에서 볼 수 있듯이, 인터리빙이 발생해 원래 요소의 순서와 일치하지 않을 수 있다.
참고
공식문서에서는 flatMap과 유사한 flatMapSequential, concatMap을 비교 설명하고 있다.
flatMapSequential: flatMap과 유사하게 동작하며 순서를 보장한다. 순서를 보장하기 위해 뒤쪽의 element에 대한 작업이 먼저 끝났을 경우 이전 element의 작업이 끝날 때까지 대기 Queue에서 대기한다.
concatMap: flatMapSequential와 마찬가지로 순서를 보장하지만 작업 처리 방법이 다르다. concatMap은 순차적으로 element를 읽어 이전 element의 작업이 끝나야 다음 element의 작업을 수행한다. 순차적으로 작업을 수행하는 것이 중요한 상황이거나, 작업에 수행하는 동작이 무거워 동시 수행할 시 서버 리소스 과부화가 우려되는 경우 사용할 수 있을 것으로 추측된다.
doOnNext
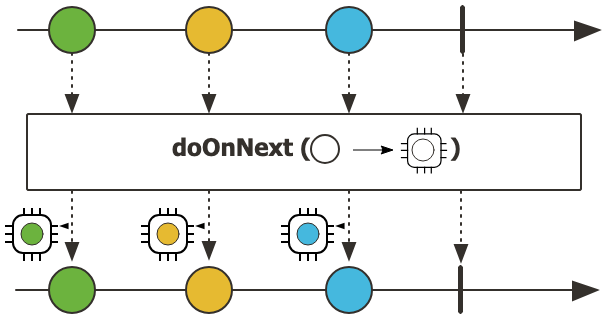
doOnNext() 는 onNext() 가 수행되기 전에 side-effect를 준다. 데이터 자체에는 아무런 영향을 주지 않는다.
flatMap 대신 doOnNext를 통해 log와 같이 비즈니스 로직과 관계 없는 작업을 처리하여 가독성을 높일 수 있다.
앞서 말했듯이 그 외에도 굉장히 많은 Opertator가 제공되며 그 중 극히 일부분만 정리해보았다.
flatMap과 그 외 유용한 Operator에 대해 이 글 (Naver D2 - flatMap만 사용하기는 그만! Reactor 오퍼레이터 파헤치기) 에 잘 정리 되어있다.
기능을 구현하기 위해 Operator를 적절히 사용하는 것도 중요하지만, 해당 Operator의 동기, 비동기 혹은 Blocking 특성을 가지고 있는지도 주의해서 사용해야 할 것이다.
Backpressure
Reactive Program에서는 Backpressure라는 기능을 지원한다. Backpressure란 클라이언트의 서버의 데이터 처리 속도가 다를 때, 이를 제어하기 위한 flow control이다.
Application-level 에서 Backpressure를 제어할 수 있을까?
내가 생각한 Backpressure의 기능은 서버의 전송 속도보다 클라이언트의 처리 속도가 느릴 때, 클라이언트가 서버의 응답 속도를 조절하는 것이었다.
Backpressure 관련 Operation의 설명과 다이어그램을 보면 Publisher의 송신을 관리하는 것이 아닌 Subscriber가 처리 못한 데이터를 어떻게 할 지에 대한 전략을 제시하고 있다.
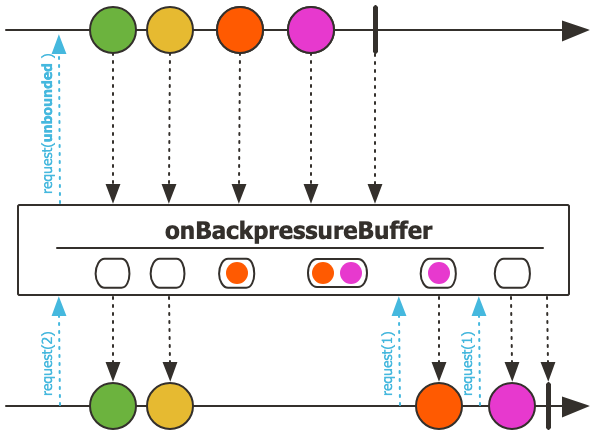
위와 같이 Buffer에 데이터를 저장하고, 버퍼의 크기를 제한할 수 있다. 만약 데이터 처리속도가 느려서 버퍼의 크기보다 데이터가 많이 쌓이게 된다면 오래되거나 마지막의 element를 Drop하는 방식으로 Backpressure를 관리한다.
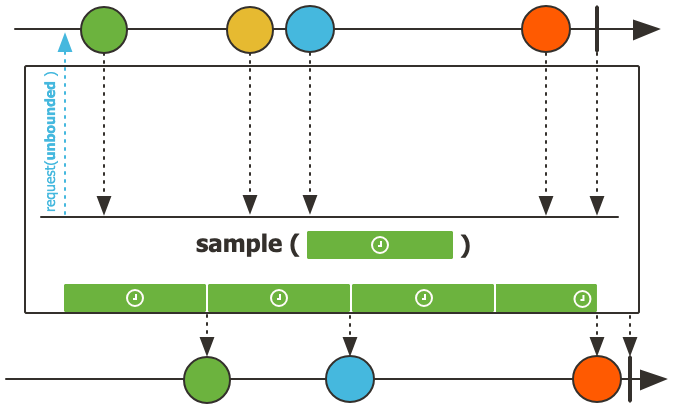
혹은 데이터를 샘플링하여 최신의 element만 가져오는 등의 작업도 할 수 있다.
그 외에도 다양한 처리 방법이 있지만, 해당 방법들로는 원하는 솔루션을 찾을 수 없었다. 송신 서버에 직접 Delay를 걸지 않으면 데이터는 계속해서 전송될 것이고 처리하지 못한 데이터를 버리거나, 에러를 발생시켜야 할 것이다.
결론적으로, Reactor 에서 제공하는 api로는 원하는 불가능하다. Reactor 공식 문서는 아니지만 RxJava wiki 에도 다음과 같은 문구가 있다.
Reactive pull backpressure isn’t magic
Backpressure doesn’t make the problem of an overproducing Observable or an underconsuming Subscriber go away. It just moves the problem up the chain of operators to a point where it can be handled better.
Backpressure는 overproducing, underconsuming 문제를 해결해 줄 수 없다.
만약 근본적으로 문제를 해결하고 싶다면 RSocket 을 활용하면 양방향 통신을 하여 송수신을 조절할 수 있다. RSocket에 대한 내용은 이 글 (Webflux의 Backpressure와 RSocket) 에 설명되어 있다.
실제 동작
그렇다면 Backpressure를 적용하지 않고 수신측의 데이터 처리가 지연되면 통신은 어떻게 될까? 실제 Publisher 서버와 Subscriber 서버를 간단하게 구현해 보았다.
Publisher Server
@GetMapping("/publish", produces = [MediaType.TEXT_EVENT_STREAM_VALUE])
fun publish(): Flux<Music> {
val musicList = ArrayList<Music>()
for (i in 1 .. 5000)
musicList.add(Music (id = i.toString(), releaseDate = ZonedDateTime.now(), lyrics = "hi"))
return Flux.fromIterable(musicList).log()
}Publisher Server에서는 5000개의 element를 생성하고 MediaType.TEXT_EVENT_STREAM_VALUE 방식으로 전송한다.
Subscriber Server
val webClient = WebClient.create("http://localhost:8080")
webClient.get()
.uri("/publish")
.retrieve()
.bodyToFlux(String::class.java)
.delayElements(Duration.ofMillis(1000))
.log()
.subscribe()WebClient를 사용해서 Publisher Server의 API를 호출하고 구독했다.
각각의 element에 1초 delay를 줘서 처리 속도에 차이를 두었다.

위 예시 코드를 실행하여 통신을 어떻게 하는지 패킷을 살펴보았다. 클라이언트가 데이터를 처리하지 못하면, 위 사진 처럼 Reciever 측 TCP 통신 버퍼가 가득차고 서버는 Retransmisson을 시도하면서 통신 리소스가 낭비될 수 있다.
단순하게 생각해도 HTTP가 Backpressure를 지원하지 않기 때문에 이 방법으로는 내가 원했던 결과를 만들어 낼 수 없다.
마무리하며
Webflux는 공식문서에서도 러닝커브가 높은 기술이라고 언급하고 있다. 이 문구를 처음 봤을 때에는 별 생각이 없었다. 비동기적 Non-blocking 방식으로 인해 코드 흐름을 이해하는 것도 어렵고, Web-MVC 에 비해 레퍼런스가 압도적으로 적어 굉장히 힘들었다.
또, 공부하면서 들었던 의문을 해결하고 정리하고나니 너무 당연한 내용도 있어 민망한 부분도 있다. 그럼에도 Webflux 뿐만 아니라 비동기, Reactive Programming 에 대한 전반적인 지식을 학습할 수 있어 좋은 경험이었다.
참고 자료
