Intro
머신러닝 엔지니어 인턴을 진행하며 새로운 프로젝트를 구상해나가는 과정에서 CVPR2024에서 발표된 S2M 논문이 흥미롭게 느껴져 리뷰 글을 작성하게 되었습니다.
논문의 본문은 아래 링크를 참고해주세요.
Segment Every Out-of-Distribution Object (CVPR2024)
Abstract
Semantic Segmentation 모델은 기존 데이터에서 학습된 클래스 즉, in-distribution 클래스 카테고리를 인식하는 것에는 매우 훌륭하지만 이는 실제 어플리케이션에 배포될 때에는 어려움이 존재합니다. 그 이유는 실제 서비스가 배포되고 유지됨에 있어 모델이 마주하는 데이터 중에는 기존에 알지 못하는 클래스, 다시 말해 Out-of-Distribution 클래스들이 있을 수 있는데 모델은 이를 검지하고 마스크를 추출하는 것에 대한 성능이 매우 떨어지기 때문입니다. 하지만 이러한 OoD 객체를 잘 검지해내는 것은 안전이 중요한 자율주행 자동차, 지능형교통시스템(ITS) 어플리케이션에서 매우 중요합니다.
이를 해결하기 위해 기존 방법들은 각 픽셀이 OoD 객체에 포함되는 정도를 anomaly score map을 제안하고 있는데 이를 기반으로 정확한 OoD 객체의 위치와 segmentation mask를 추출하는 것은 매우 어렵습니다. 왜냐하면 anomaly score map에서 OoD 인지 아닌지 결정할 threshold 값이 결정되야 하는데 이 값은 각 데이터마다 다를 수 있고 설령 최적의 값을 찾았다고 한들 최종 segmentation mask의 결과가 객체로부터 흩뿌려지는 fragmentation이나 부정확성을 야기하기 때문입니다.
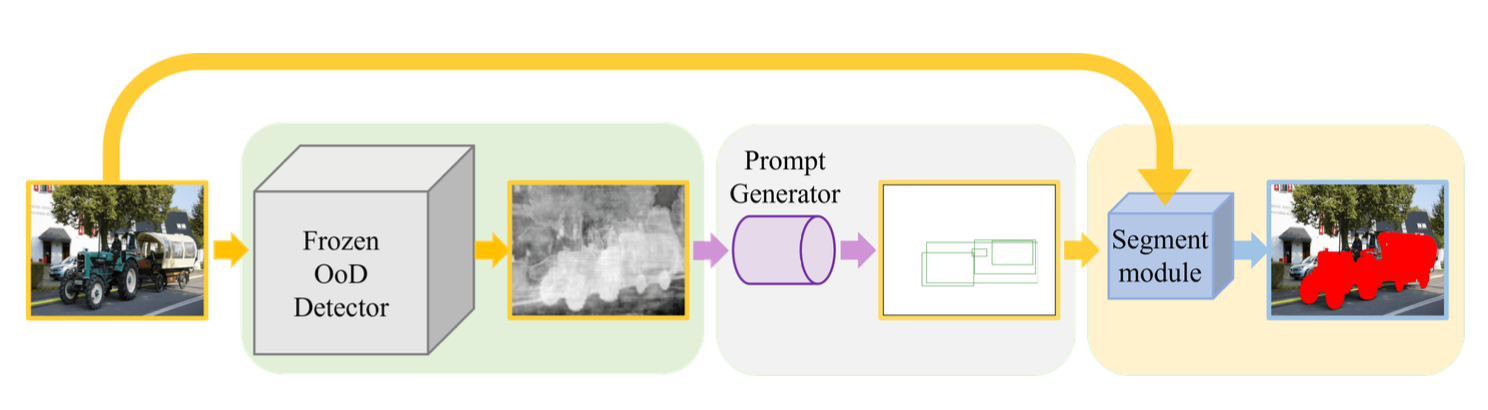
이에 따라 위 논문에서는 Anomaly Score를 OoD 객체의 segmentation mask로 변환하는 방법을 제안합니다. 이 S2M 모델은 anomaly score를 OoD 객체의 Bbox를 생성하는 bbox prompt generator 추가 모델에 넣어서 object detection처럼 OoD 객체의 바운딩 박스를 찾아내고 이 결과 값을 promptable segmentation 모델인 SAM에 넣어 최종적으로 OoD 객체의 정확한 segmentation mask를 얻을 수 있다고 합니다. 이로써 기존의 score에서 threshold를 정해야 하는 의존성을 없앴고 OoD 객체의 세그멘테이션 맵 성능에 있어 더 높은 정확도를 가질 수 있다고 합니다. S2M 모델은 다양한 벤치마킹 데이터셋으로 실험을 진행한 결과, SOTA 모델에 비해 약 20% IOU 스코어 상승, 40%의 mean F1 스코어의 성능 향상이 있었습니다.
Introduction
- Semantic Segmentation은 자율주행이나 위성영상분석 등 여러 어플리케이션에 매우 중요한 태스크입니다.
- 하지만 현재의 semantic segmentation 모델에는 치명적인 단점이 존재하는데, 이는 기존에 보지 못한 클래스 객체를 segmentation하지 못한다는 것입니다. 구체적으로는, OoD 객체가 속한 픽셀을 기존에 알고 있는 클래스로 매핑해버리는 일이 종종 있다고 합니다.
⇒ 이러한 단점은 자율주행과 같은 안전이 중요하게 여겨지는 어플리케이션에서 잘못된 결과를 초래할 수 있습니다.
-
기존에 존재하던 semantic segmentation을 활용한 OoD 검지 방법론은 각각의 픽셀에 anomaly score를 할당하는 방법을 사용합니다.
-
이 때, 높은 anomaly score로 할당된 픽셀은 OoD 객체의 일부로 여겨짐.
-
PEBAL, RPL 등이 위 방법론의 예시입니다.
- PEBAL은 anomaly score를 계산하기 위해 픽셀 별로 energy-based segmentation을 사용합니다.
- RPL도 동일하게 energy-based 방법론을 사용하는데 이를 통해 in-distribution 객체의 segmentation 성능은 유지한 채로 OoD 픽셀에 대한 민감도를 증진시킬 수 있다고 합니다.
-
하지만, 이러한 score 기반 OoD detection 방법론들은 OoD 객체 전체를 세그멘테이션하는 것에는 효과적이지 않습니다.
- 이 스코어에서 anomalous 와 normal 픽셀을 구분하는 threshold를 결정하는 것이 매우 중요한데, 최적의 값을 찾는 것은 매우 어렵습니다.
- 아래의 그림을 보면 미세한 threshold 조정에 따라 부정확한 결과가 나온다는 것을 볼 수 있는데, 최적의 threshold 값은 또 각 이미지마다 달라질 수 있기 때문에 이 값을 찾기란 매우 어렵다는 것에 납득이 가실 겁니다.

- 또한, 이러한 값을 지정했다고 한들, 이는 사람의 손을 탄 값이기에 편향될 수 있다는 단점이 존재합니다.
-
이 논문에서는 위에서 언급한 score-based OoD Detection 방법론의 단점을 극복하기 위해 Anomaly Score Map을 segmentation mask로 변환하는 간단하지만 매우 효과적인 방법론으로 S2M을 제안합니다.
- S2M은 기존 OoD detection 방법론으로부터 생성된 anomaly score가 주어지면, 이를 활용하여 OoD 객체의 bounding box를 생성하고, 이 bounding box를 기반으로 crop한 이미지를 Segment Anything모델과 같은 Promptable segmentation model에 넣어주면 OoD 객체의 Segmentation Mask를 얻을 수 있는 원리입니다.
-
아래의 그림을 보면 S2M 방법론의 OoD 객체 segmentation mask의 퀄리티가 다른 알고리즘에 비해 매우 높은 것을 알 수 있습니다.

-
정리하자면, S2M 모델은 다음 세 가지 장점이 있다고 저자들은 소개합니다.
- Simple: S2M 방법론은 추가적인 hyperparameter tuning이 필요하지 않아, 학습과 배포가 매우 간편합니다.
- General: 기존 anomaly score기반의 어떤 방법론과 호환이 가능하고 높은 퀄리티의 객체 mask를 생성할 수 있습니다.
- Effective: 부정확하거나 객체의 모양을 제대로 잡지 못하고 흩뿌려진 마스크를 생성하지 않고, 정확한 OoD 객체의 마스크를 생성할 수 있습니다.
Method
- S2M 방법론은 anomaly score maps을 box prompt를 생성하는데 활용하고, 이를 통해 생성된 box prompt를 SAM과 같은 promptable segmentation model에 넣어서 OoD 객체의 segmentation mask를 생성합니다.
- 더 자세하게는 다음과 같은 과정으로 이뤄져 있습니다.
- Image to Anomaly Score
- Anomaly Score to Box prompt
- Outlier Exposure
- Prompt Generator Training
다음 챕터에서 위 과정을 자세하게 알아보도록 하겠습니다.
Image to Anomaly Score
OoD 객체의 마스크를 생성함에 있어서 사전에 필요한 것이 anomaly score인데, 이를 생성하기 위해선 우선적으로 inlier 클래스에 대한 segmentation 모델이 필요합니다. 이번 챕터에선 이 segmentation 모델을 활용해서 anomaly score를 계산하는 방법론들에 대해서 소개하겠습니다.
세그멘테이션 모델 과 인풋 이미지 가 있다고 했을 때, 각 픽셀 에 대해서 segmentation 모델로부터 나온 각 클래스 별 logit은 다음과 같이 표현할 수 있습니다.
이 logit 값에 softmax함수를 적용하게 되면 해당 픽셀이 각 클래스에 속할 확률 를 계산할 수 있습니다.
이제 이 확률들을 기반으로 각 픽셀이 OoD 클래스에 속할 것이라는 스코어를 계산하는 방법을 소개하도록 하겠습니다.
첫번째로는 다음과 같이 샤논 엔트로피를 통해 계산할 수 있습니다.
엔트로피 값이 높다는 것은 해당 픽셀 가 inlier 클래스에 속하는지에 대한 불확실도가 높다는 것을 의미하고, 이는 즉슨 해당 픽셀이 OoD 객체에 속할 확률이 높다는 것을 의미하게 됩니다.
Anomaly Score to Box Prompt
anomaly score로 직접적으로 마스크를 생성하는 것은 상당히 어렵지만, 이 스코어 자체는 OoD 객체의 위치에 대해 강한 지표를 제공합니다. 따라서, 저자들은 이 스코어를 Segment Anything 모델에 프롬프트로 활용할 수 있도록 변환하는 아이디어를 착안했다고 합니다.
한 가지 방법으로는 높은 이상치 스코어를 가지는 픽셀들을 point prompts로 사용하는 방법이 있을텐데, 저자들은 이 방법을 사용할 때 OoD 객체의 segmentation mask를 정확하게 얻을 수 없었다고 합니다.
따라서, 저자들은 Object Detection 모델을 활용해서 bbox를 생성하는 아이디어를 착안했다고 합니다. 그 결과 아래의 그림처럼 box 프롬프트를 사용하여 OoD 객체의 segmentation map이 훨씬 정확한 것을 확인할 수 있습니다.

이러한 방법론을 활용하기 위해선, OoD 객체의 bbox 라벨링이 된 데이터가 필요한데, 이러한 실제 OoD 데이터셋이 없는 관계로, 다음 챕터의 Outlier exposure 라는 OoD 객체를 training 데이터에 합성하는 방법을 활용해서 훈련을 진행했다고 합니다.
Outlier Exposure
Outlier exposure 방법론은 기존에 가지고 있는 데이터셋을 활용해서 바운딩 박스 프롬프트 생성기를 학습하기 위해 OoD 데이터셋을 기존 데이터셋에 합성하는 방법을 말합니다.
inlier 데이터셋은 으로 정의할 수 있고 여기서 각 데이터는 은 인풋 이미지와 는 개의 in-distribution 카테고리에 대한 segmentation맵의 쌍으로 구성되어 있습니다.
이와 동일하게, Outlier 데이터셋 또한 인풋 이미지와 segmentation 맵 쌍으로 구성되어 있는데 여기서 은 각 픽셀이 OOD 객체에 속하는 지 아닌지에 따라 0, 1로 구성된 맵이 됩니다.
이를 기반으로 Outlier Exposure를 수학적으로 표현하면 다음과 같습니다.
- where P is an outlier class. 여기서 는 indicator 함수로서, 괄호 안 내용이 참이면 1, 거짓이면 0의 결과를 주는 함수입니다.
Prompt Generator Training
이제 위 과정을 통해 얻은 합성된 데이터에서 outlier 객체의 부분을 bounding box로 변환하여 박스 프롬프트의 ground truth 라벨을 만들 수 있게 됩니다.
다음으로 합성된 데이터로부터 anomaly score 맵을 얻기 위해, 기존에 주로 사용되어 오는 OoD detection 레이어 에 OoD 객체가 합성된 이미지 를 넣어주면 다음과 같이 anomaly score map을 구할 수 있습니다.
드디어 박스 프롬프트와 합성된 이미지의 anomaly score를 통해 box prompt generator 모듈 을 학습할 수 있게 됩니다. 이 때 손실 함수는 box prompt generator 에서 생성된 bbox와 기존에 작업해둔 gt 박스 프롬프트 사이의 오차로 정의할 수 있습니다. 논문에서는 구체적으로 어떤 손실 함수를 사용하였는지 기술되어 있지는 않지만, 첨부한 공식 레포의 코드를 살펴보면 IOU loss (GIoU, DIoU, CIoU)를 사용하거나 l1 loss를 사용하는 것을 확인할 수 있습니다.
(+ 다음 블로그 포스트에서 여러 IoU의 정의에 대해서 다루도록 하겠습니다 :) )
Experiments
Datasets
- Fishyscapes
- static
- lost & found
- SMIYC(Segment-Me-If-You-Can)
- RoadAnomaly (RA): 110장의 다양한 크기의 anomaly 객체들이 존재합니다.
- RoadObstacle (RO): 442장의 이미지로 구성되어 있으며, 주로 도로 위에 작은 객체 위주로 구성되어 있습니다.
- Road Anomaly: real-world 이상치 탐지 데이터셋이며 60장의 이미지로 구성되어 있습니다.
Outlier Exposure
- Cityscapes 이미지에 COCO 객체를 붙혀서 합성 훈련 데이터를 생성했습니다.
- Cityscapes 는 2975장의 훈련 이미지로 구성되어 있고, 총 19개의 inlier 클래스로 구성되어 있는데, 이 훈련 데이터에 COCO 데이터셋에서 Cityscapes의 19개 클래스에 속하지 않는 객체를 위 OE방법론을 통해 합성했다고 합니다.
Optimal Threshold for existing method
- 기존 방법론의 segmentation map과의 비교를 위해 validation set을 통해 score map에서 최적의 OoD 객체를 구분하는 threshold를 스코어 맵의 가장 작은 값부터 큰 값까지 0.01 단위로 탐색하며 가장 좋은 결과를 리포트했다고 합니다.
Results
- 실험 결과의 경우 본 논문에 자세한 내용이 기술되어 있으니 참고하시면 좋을 것 같습니다!
논문 링크
Summary
- 제안된 S2M 방법론은 기존의 score-based 방법론으로 얻은 anomaly score map을 기반으로 OoD 객체의 위치를 검지할 수 있는 box prompt generator를 학습하고 inference 시에 생성된 bbox를 promptable segmentation model에 넣어 OoD 객체의 segmentation mask를 생성합니다.
- 이 논문을 리뷰하면서 든 생각은 다음과 같습니다.
- S2M 모델이 잘 동작하기 위해선 높은 퀄리티의 anomaly score map이 전제되야 한다는 생각이 들었습니다.
- 결국 OoD Segmentation mask를 얻기 위해선 SAM모델에 통과시켜야 하는데 이 과정이 무겁다는 느낌이 듭니다.
- 혹은 OoD Detection만 필요한 경우라면, 이 과정을 생략해도 될 것 같다는 생각이 드네요..
- 결국 OoD detection이라는 어플리케이션에 배포되기 위해선 모델 자체가 가벼워져야 하고 이와 동시에 성능 하락이 최소화되는 방법이 필요할 것이라는 생각이 들었습니다.
S2M 논문을 리뷰하면서 기반이 되는 기술들을 리뷰해나가는 시리즈 느낌이 아닌 갑작스레 최신 논문 리뷰를 작성했다는 생각이 들었습니다. 이에 따라 앞으로 작성할 게시물들에서는 이 논문을 이해하기에 좋은 배경 기술들을 차근차근 리뷰해보도록 하겠습니다. 긴 글 읽어주셔서 감사합니다~
