Abstract
- YOLO 모델의 속도와 정확성 사이의 trade-off 성능이 높음.
- 하지만, postprocess 중 NMS 이 성능에 부정적인 영향을 줌.
- 한 편, DETRs 모델은 end-to-end 방식으로 NMS 과정을 생략할 수 있음. (bipartite matching)
- 그럼에도 불구하고 DETR 모델은 매우 큰 연산량이 필요하기 때문에 NMS과정을 생략한 것에 의한 속도-정확도 trade-off에 대한 성능 향상이 크지 않음.
- 이 논문에선 위 딜레마를 극복하기 위해 최초로 트랜스포머 기반의 Real-time end-to-end object detector, RT-DETR을 제안함.
- 기존에 발전된 버전의 DETR모델에 2가지 단계로 RT-DETR을 만들어나감.
- 속도를 향상시키면서 정확도를 유지
- Efficient Hybrid Encoder를 디자인함.
- multi-scale feature들을 프로세싱함에 있어 intra-scale interation 과 cross-scale fusion을 decoupling하면서 속도를 향상시킴.
- Efficient Hybrid Encoder를 디자인함.
- 정확도를 향상시키면서 속도를 유지
- Uncertainty-minimal query selection을 제안함. 이 방법론은 decoder에 더 높은 퀄리티의 초기 쿼리들을 주어 정확도를 향상함.
- 속도를 향상시키면서 정확도를 유지
Introduction
-
기존 실시간 객체 검지모델 중 가장 유명한 것은 YOLO 계열이고 이는 speed와 accuracy trade-off 커브에서 좋은 성능을 보여주고 있음.
-
그러나 YOLO 계열 (YOLOv10 제외…) 모델은 전형적으로 NMS가 postprocessing에 들어가고 이는 추론 속도를 매우 떨어트릴 뿐만 아니라 hyperparameter에 의해 속도와 정확도에서 불안정함을 유발함. 게다가 어플리케이션에 따라 recall이 높아야 하는 경우도 있고 정확도 자체가 높아야 하는 경우가 있는데 이에 따라 NMS threshold를 잘 지정해줘야 함.
-
최근에는 end-to-end 트랜스포머 기반의 객체 검지 모델인 DETRs이 신식 아키텍쳐 구성과 threshold 와 같은 hand-crafted components를 제거함에 따라 학계로부터의 관심을 받아 왔음.
-
그러나 DETR은 연산량 자체가 매우 높음. 이에 따라 NMS-free 임에도 추론 속도의 발전을 보여주지 못함.
-
이 점에 저자들은 영감을 얻어 DETRs 모델이 실시간 시나리오로 확장될 수 있고 YOLO 계열의 모델의 성능을 뛰어넘을 수 있을지 탐구하고자 했음.
Related Work
Real-time Object Detectors
- 수년간의 끊임없는 발전으로 YOLO 계열 모델은 다른 one-stage object detectors를 능가해왔음.
- YOLO계열 모델은 두 가지로 분류할 수 있음.
- Anchor-based
- Anchor-free ⇒ speed-accuracy trade-off에서 좋은 성능을 보이고 다양한 실제 시나리오에서 많이 사용됨.
- 하지만 위 YOLO 계열의 모델들은 많은 양의 겹치는 bbox들을 만들며 NMS가 필요하기 때문에 속도 저하가 발생함.
End-to-end Object Detectors
- DETR은 Carion et al.에 의해 처음 제안됨.
- Anchor 설정이나 NMS에 필요한 hyperparameter들을 없앰.
- 대신, bipartite matching 알고리즘을 채택하여 1대1 객체 매칭을 직접적으로 예측함.
- 이러한 장점에도 불구하고, DETR은 여러 문제가 있음.
- 학습 수렴 속도가 느림.
- 계산량이 많음.
- Object queries를 학습하기 어려움.
- 위 문제를 극복하기 위해 여러 variants가 제안되어 왔음.
- Accelerating convergence
- Deformable DETR은 backbone에서의 multi-scale features를 활용해 attention 메커니즘의 효율성을 향상함.
- DAB-DETR과 DN-DETR은 iterative refinement scheme을 제안하고 학습 단계에서 발생하는 노이즈를 줄여 성능을 향상함.
- Group-DETR은 1대1 매칭이 아닌 1대 다수 매칭을 제안하여 학습 시 수렴을 가속화함.
- Reducing computational cost
- Efficient DETR 과 Sparse DETR은 인코더와 디코더의 숫자를 줄이거나 업데이트되는 queries의 갯수를 줄이면서 계산량을 줄임.
- Lite DETR은 low-level feature의 업데이트 주기를 줄이면서 인코더의 효율성을 높임.
- Optimizing query initialization
- Conditional DETR 과 Anchor DETR에선 object queries의 최적화의 어려움을 줄임.
- Deformable DETR논문에서 mixed query selection을 제안하면서 쿼리들을 더욱 잘 초기화했음.
- Accelerating convergence
Speed Analysis
NMS에 대한 분석
-
NMS는 2개의 threshold가 필요함.
- confidence_threshold
- 해당 임계값보다 작은 bbox들은 바로 필터링됨.
- IoU threshold
- 어떤 두 개의 bbox 사이의 IoU 값이 임계값보다 높다면 둘 중 confidence값이 더 낮은 박스는 필터링됨.
- 각 클래스의 모든 박스들에 대해서 위 조건을 가지고 만족될 때까지 반복함.
- 따라서 NMS 알고리즘의 latency는 총 예측 bbox 갯수와 위 2개의 임계값에 의해 좌우됨.
- confidence_threshold
-
위 두 개의 값에 의한 accuracy-speed trade-off를 검증하기 위해 YOLOv5 (anchor-based)와 YOLOv8 (anchor-free) 모델에 대해 위 임계값의 변화에 의한 mAP, latency를 측정함.
-
Confidence threshold 값에 따른 nms에 들어가는 bbox 갯수 변화 추이
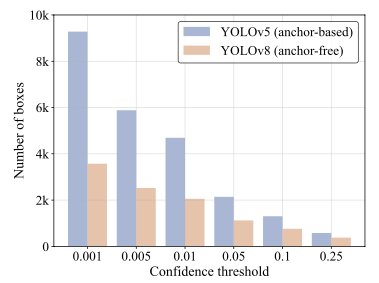
- confidence threshold 값이 높아질 수록 nms에 들어가는 box의 수가 감소하는 것을 확인할 수 있음. 이에 따라 IoU를 계산하는 박스 쌍이 작아지고 자연스럽게 latency의 감소로 이어짐.
-
YOLOv8 모델에 대해서 임계값들에 따른 AP 와 NMS를 보고함.
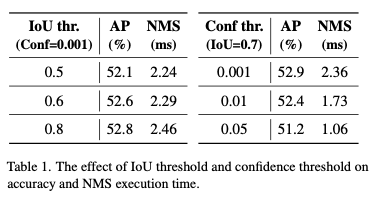
-
End-to-end Speed Benchmark
-
real-time detector 모델들의 성능을 벤치마킹하기 위해 COCO2017 데이터셋에 대해서 평균 추론속도와 정확도를 분석함. 이 때, 알고리즘 자체의 속도만을 측정하기 위해 IO, MemoryCopy 연산은 제외함.
- 측정 모델 리스트 with TensorRT FP16
- YOLOv5, YOLOv7 (Anchor based)
- PP-YOLOE, YOLOv6, YOLOv8 (Anchor free)
- 측정 하드웨어
- T4 GPU
- 측정 모델 리스트 with TensorRT FP16
-
결과
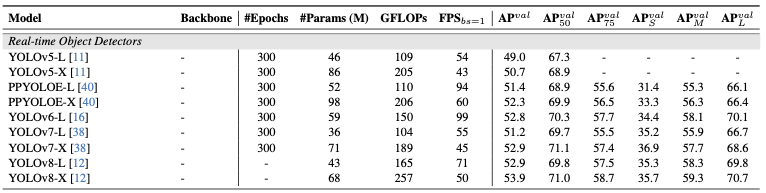
- Anchor free 모델이 anchor based모델에 비해 비슷한 accuracy에서 훨씬 빠른 속도를 보여줌.
- 그 이유는 생각보다 당연함.
- Anchor based 모델은 하나의 그리드에 대해서 anchor 갯수만큼의 bbox를 생성하기 때문에 anchor-free에 비해 postprocessing에 들어가는 지연시간이 길 수 밖에 없음.
Methods (The Real-time DETR)
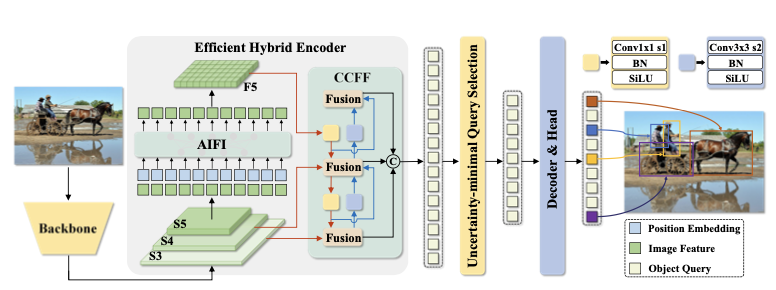
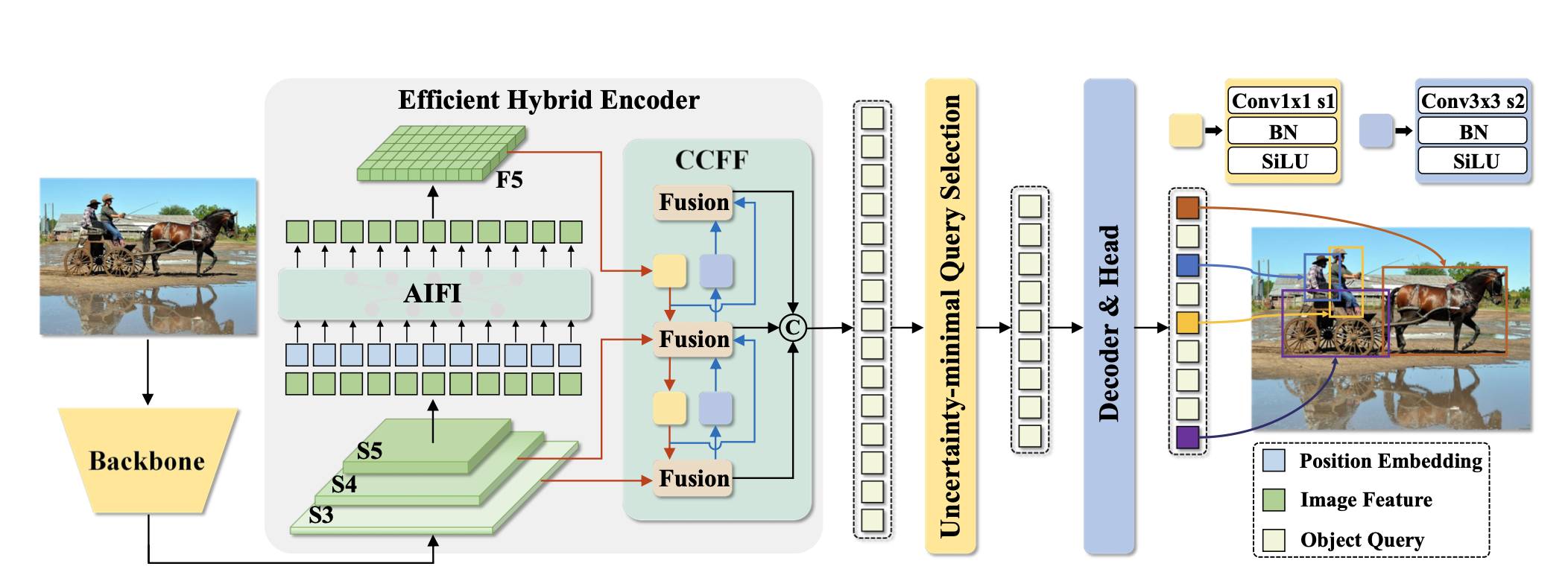
- RT-DETR은 backbone, efficient hybrid encoder, 그리고 transformer decoder에 auxiliary prediction head가 붙은 구조로 이뤄져있음.
- 구체적으로는, backbone에서 마지막 3개 레이어의 features 를 encoder에 전달해주고, encoder에서 intra-scale feature interaction과 corss-scale feature fusion을 수행한 다음, 고정된 갯수의 encoder feature가 decoder의 초기 객체 쿼리로 전달될 수 있도록 uncertainty-minimal Query Selection이 수행됨. 마지막으로 디코더와 헤드에서 bbox regression과 classification을 수행할 수 있도록 최적화함.
Efficient Hybrid Encoder
- Deformable-DETR 논문을 통해 backbone의 multi-scale feature를 도입하는 것이 학습의 수렴 속도와 성능 개선을 이끌 수 있다는 것이 보고된 바 있음.
- deformable attention이 계산량을 줄여주긴 함. 그러나, multi-scale feature를 사용함으로써 증가된 sequence의 길이는 Encoder가 연산에 있어 병목이 되게 할 수 있음.
- Deformable-DETR에서 Encoder는 GFLOPs에서 49%를 차지하는 데에 반해,, 11% 정도의 상승만을 기여함.
- deformable attention이 계산량을 줄여주긴 함. 그러나, multi-scale feature를 사용함으로써 증가된 sequence의 길이는 Encoder가 연산에 있어 병목이 되게 할 수 있음.
- 정보량 측면에서 생각해보면 더 높은 레벨의 feature는 낮은 레벨의 feature에 비해 더 풍부한 semantic information을 가지고 있을 것이기 때문에 각 feature들을 단순히 concat해서 feature interaction을 수행하는 것은 redundant함.
- 따라서, 저자들은 이와 같이 동시에 intra-scale 과 cross-scale feature interaction을 수행하는 것의 비효율성을 입증하기 위해 서로 다른 타입의 encoder를 디자인하였음.
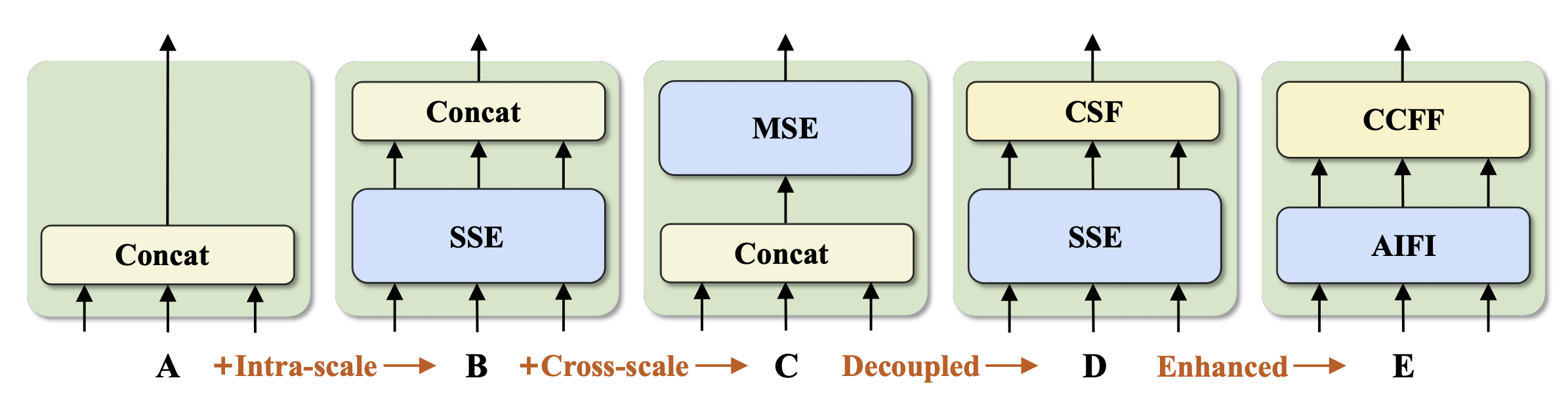
- 구체적으로는, DINO-Deformable-R50 모델에서 multi-scale Transformer Encoder를 제외한 것을 A라고 지정하고 이를 변형하며 설명함.
- A → B: Single-scale Transformer encoder를 추가하고 이 weights는 각 scale별로 공유함. 그리고 나온 output들을 concat함.
- B → C: multi-scale features를 concat한 다음 intra-scale과 cross-scale interaction을 동시에 수행하는 Multi-scale Transformer Encoder에 통과시킴.
- C → D: Intra-scale interaction과 cross-scale fusion을 분리함. 이 때, single-scale transformer encoder와 PAN 스타일의 CSF 레이어를 사용함.
- D → E: 위 D에서 각각의 레이어를 향상시킨 버전임. (제안한 버전)
- 구체적으로는, DINO-Deformable-R50 모델에서 multi-scale Transformer Encoder를 제외한 것을 A라고 지정하고 이를 변형하며 설명함.
Hybrid design
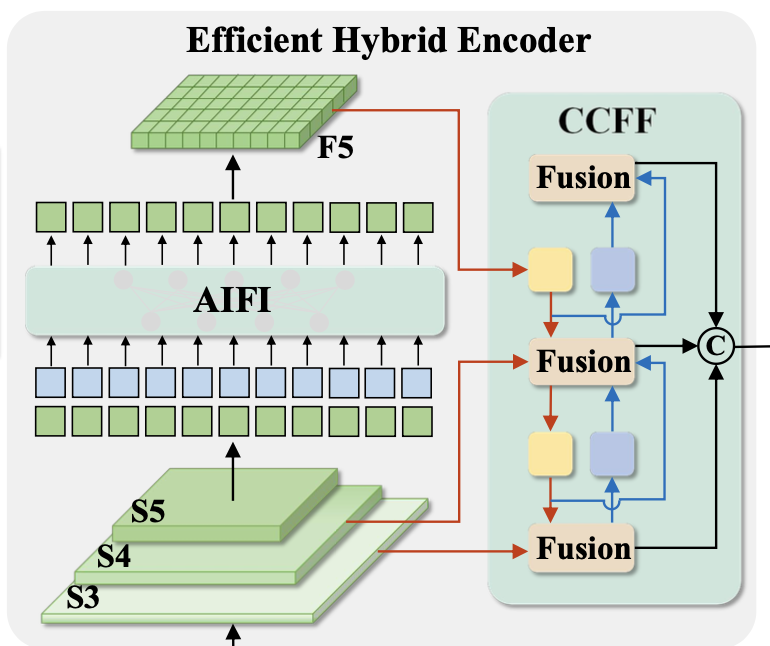
위 분석을 통해, 저자들은 efficient hybrid encoder를 제안하였으며 다음과 같이 구성함.
- AIFI (Attention-based Intra-scale Feature Interaction)
- CCFF (CNN-based Cross-scale Feature Fusion)
AIFI
-
AIFI는 위 encoder 디자인 D에 기반하여 계산량을 더욱 줄였음.
-
Single-scale Transformer encoder를 사용하여 intra-scale interaction을 에 대해서만 진행함.
-
그 이유는 더 풍부한 의미론적인 컨셉을 담고 있는 high-level features에 self-attention 연산을 적용하는 것이 뒤에 이어지는 decoder나 head 모듈이 객체 인식과 localization을 더욱 수월하게 할 수 있다고 함.
-
게다가 낮은 레벨의 feature들은 이런 의미론적인 컨셉이 부족하고 낮은 레벨에도 self-attention을 적용하게 되면 위 의 intra-scale interaction과 중복이 되거나 혼란을 일으킬 수 있어 저자들은 마지막 feature에 대해서만 AIFI를 적용했다고 함.
-
Table 3의 보면 이 내용이 옳다는 것이 실험적으로 증명됨.
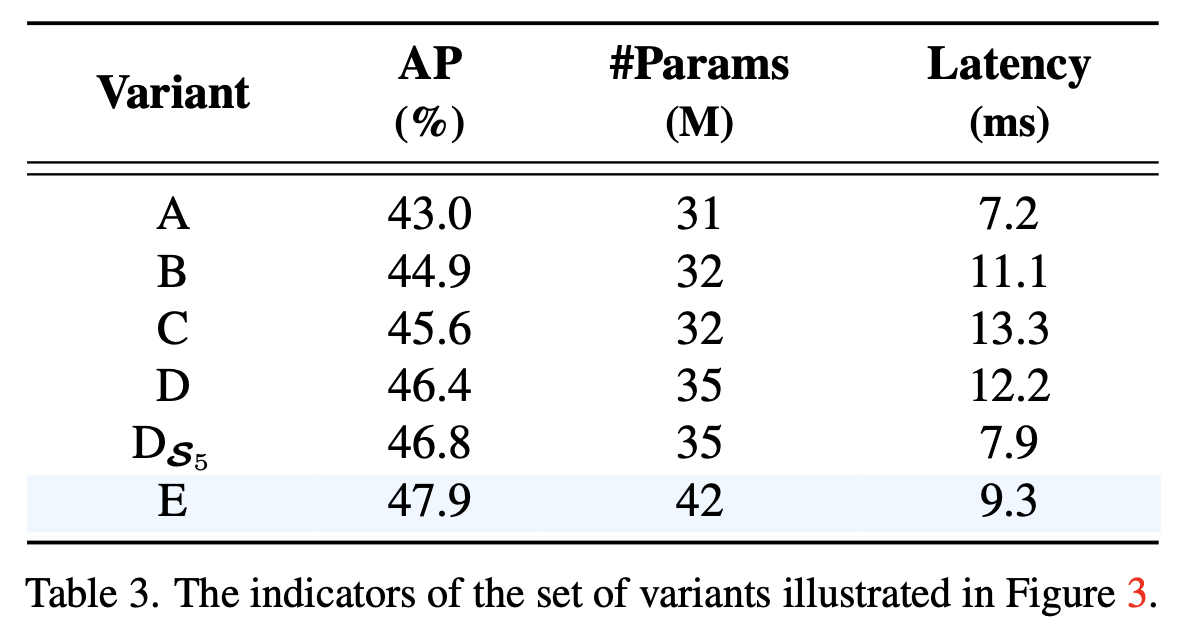
-
와 비교했을 때, 가 latency를 35% 더 줄였을 뿐만 아니라, AP를 0.4% 향상시킴.
CCFF
-
CCFF 모듈은 cross-scale fusion 모듈을 최적화한 것임.
- fusion 블록의 역할은 서로 인접한 scale의 feature들을 새로운 feature로 만드는 것임.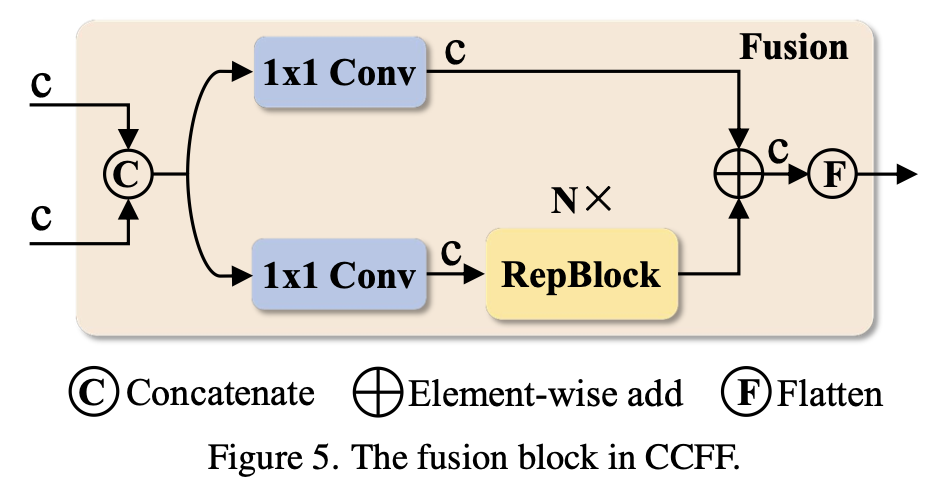
-
2개의 1x1 Conv와 N개(=3개)의 RepBlock으로 구성되며, RepBlock에서는 RepConv가 feature fusion에 사용되고, 마지막으로 Fusion 블록의 2개의 path의 결과는 element-wise 덧셈으로 융합됨
-
-
정리하자면 Efficient Hybrid Encoder는 다음과 같이 수식으로 표현할 수 있음.
Uncertainty-minimal Query Selection
-
DETR 이후에 나온 논문들에서 Object queries를 학습하는 것의 어려움을 극복하기 위해, confidence score를 사용하여 encoder로부터 top K features 골라서 object queries를 초기화했음.
-
Confidence score는 해당 feature가 foreground objects 에 포함될 가능도를 나타냄. 쉽게 말하면 단순히 객체가 있는지 없는지 확신하는 정도라고 할 수 있음.
-
그럼에도 불구하고, 검지 모델은 해당 객체의 위치와 카테고리를 동시에 모델링할 수 있어야함. 따라서 object queries의 features는 localization과 classification에 모두 correlated 된 latent variable 이어야할 것임.
-
이에 따라 현재 confidence score만으로 object queries를 초기화하는 것은 불확실성을 야기하고 디코더의 sub-optimal한 초기화를 초래함.
-
The Uncetainty query selection scheme을 제안하여 위 문제를 해결하고자 함.
-
Encoder에서 나온 feature의 Localization에 대한 분포와 Classification의 분포의 차이가 줄어드는 방향으로 loss를 두고 이를 최소화하는 방향으로 학습을 한다면 localization과 classification 사이의 correlation이 높아진다는 것을 의미하는 것 같음.

-
COCO val2017 데이터셋에 대해서 classification score가 0.5 이상인 객체들에 대해서 IoU score를 시각화함.
-
이를 통해 제안된 Uncertainty query selection scheme의 효과성을 입증하고자 함.
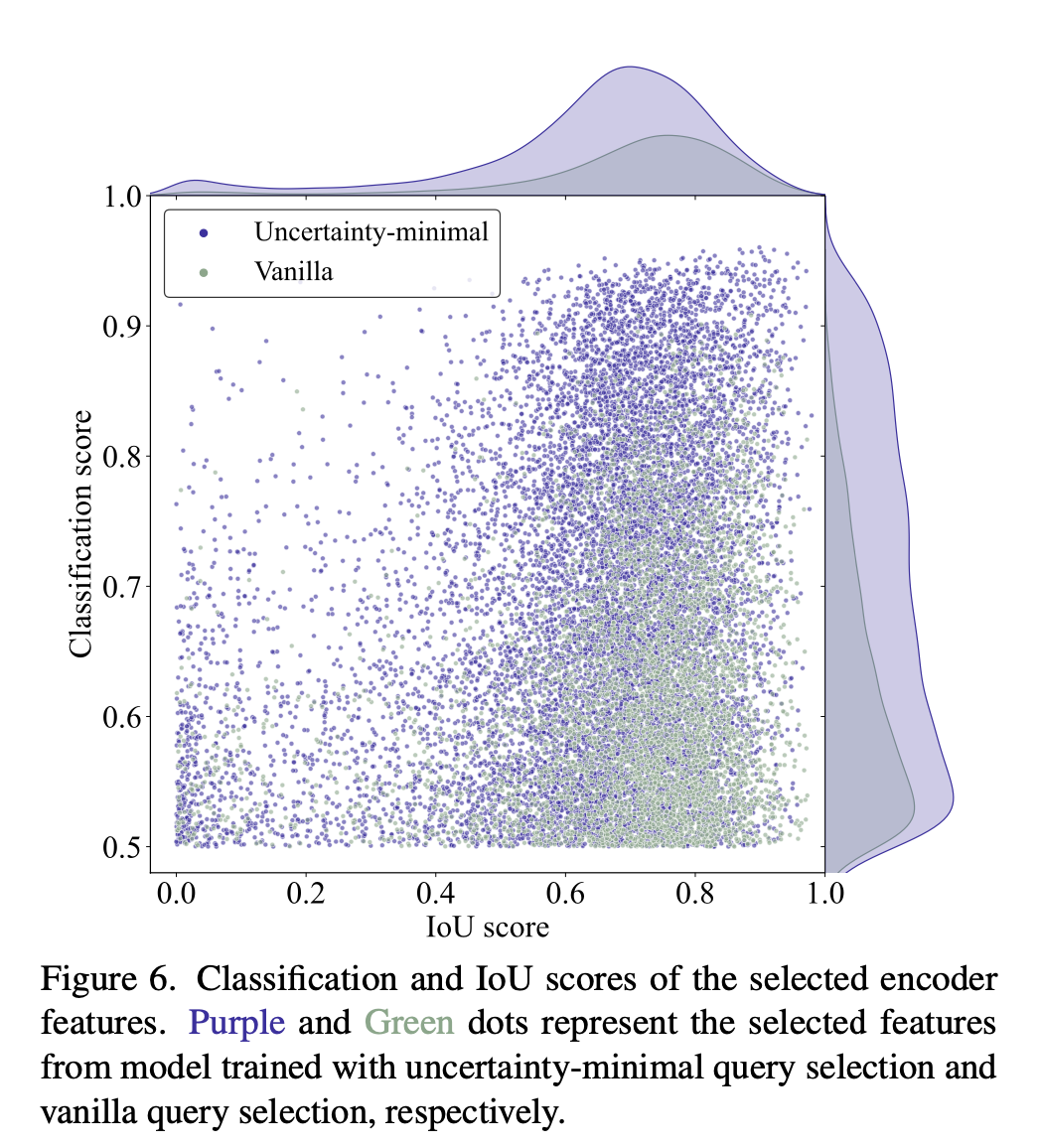
-
보라색 점들이 우측 상단에 더 많이 분포하는 것을 볼 수 있음. 이는 uncertainty-minimal query selection이 더 높은 퀄리티의 encoder features를 선택한다는 것을 의미함.
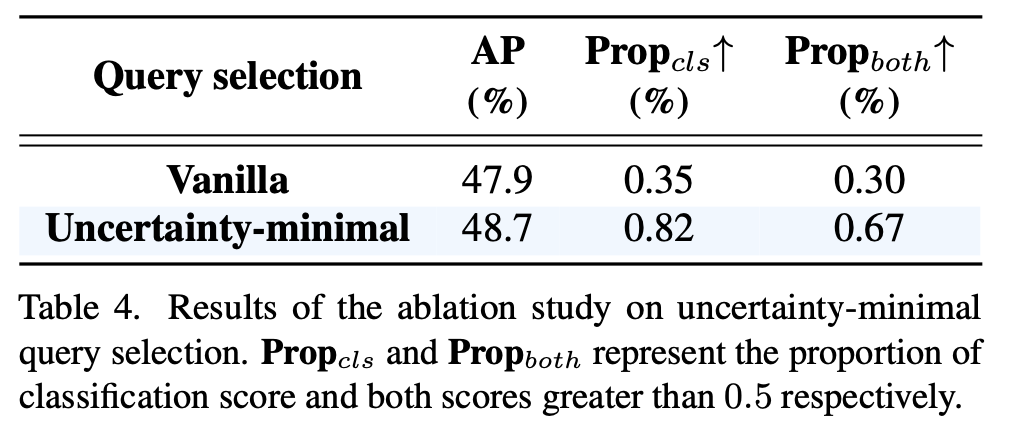
-
성능 또한 향상됨.
-
-
Scaled RT-DETR
- hybrid encoder에서 임베딩 차원수와 채널 수를 조절하거나 RepBlock의 갯수를 조절함으로써 모델의 크기를 유연하게 조절할 수 있고, 디코더에서는 object queries의 갯수와 디코더 레이어의 갯수를 통해 조절할 수 있음.
Experiments

Limitation and Discussion
- 다른 DETR 계열의 모델들과 같은 한계를 가지고 있음.
- 작은 객체 검지 성능이 다른 실시간 검지 모델에 비해 떨어짐.
- 기존의 큰 DETR모델이 COCO test-dev 데이터에 대한 리더보드에서 높은 성능을 보여주고 있음.
- 그리고 RT-DETR의 디코더 부분은 다른 DETR모델과 동질적임. 이는 가벼운 RT-DETR모델이 다른 큰 DETR 계열 모델로부터 distillation을 받을 수 있다는 것을 시사함. 추후 흥미로운 탐구가 될 것이라는 것이 저자들의 주장임.
Summary
Key Enhancements
- Efficient hybrid encoder
- Uncertainty-minimal query selection
- Flexible speed tuning
