[논문 리뷰]-Swin Transformer: Hierarchical Vision Transformer using Shifted Windows (2021)
Computer Vision
ViT 구현 해보느라 논문리뷰가 늦어졌네용
microsoft 논문
18000회 인용
0. Abstract
본 논문은 semantic segmentation, image classification, object detection 등 여러 비전 task에서 우수한 성능을 보이는 Swin Transformer를 컴퓨터 비전 분야의 back-bone으로 제시함
Swint Transformer는 shifed windows를 이용한 계층적 설계를 기반으로 하는 트랜스포머 모델이다.
1. Introduction
그동안은 CNN을 백본으로 해서 많은 아키텍쳐들이 발달해왔다. 더 크고, 더 정교한 형태의 CNN이 발전됨에 따라 performance 역시 계속 증가했음
반면 NLP는 살짝 다른 길을 걷고있다!
NLP 분야에서의 최고는 트랜스포머임.
트랜스포머가 워낙 잘나가다 보니까 vision 분야에서도 적용해보려고 여러 연구들이 진행되었고 , 아주 훌륭한 결과를 도출해냈다. ( ViT , CLIP )
저자는 CV에서 백본으로 쓰이는 genearl pupose Transformer의 적용에 대해서 연구를 했다.
language domain과 다른점은 기본처리 요소로 사용되는 것이 없다는 건데 (NLP는 단어 토큰이 있음) 시각적 요소들은 규모가 크게 다를 수 있다는 점을 지적하였다.
그리고 단어, 문장들과 다르게 하나의 고해상도 사진은 훨씬 더 많은 계산을 필요로 한다. => 비효율적임
Swin Transformer
이러한 문제들을 해결하기위해서 논문에선 Swin Transformer라는 백본 모델을 제시한다.
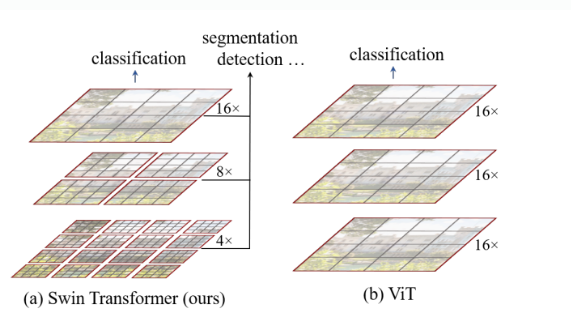
이는 계층적인 featur map과 qudratic이 아닌 linear computational complexity를 가진다!
이러한 계층적 구조를 지닌 덕분에 FPN ,U-Net 같은 기술들도 효과적으로 활용할 수 있다고한다 .( 뭔소리지? 일단 넘어가자 )
locally computed self attention인 non-overlapping window를 통해 linear한 computational complexity도 얻었다고 함
해상도가 224x224에서 448 x 448 이 되니까 그러면 32x32 => 64x64개의 패치니까 linear form이 나온다. 윈도우 사이즈는 7x7 고정
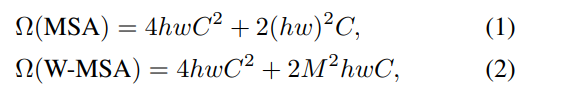
이러한 특징들 때문에 백본으로 쓰기 아주 좋다.
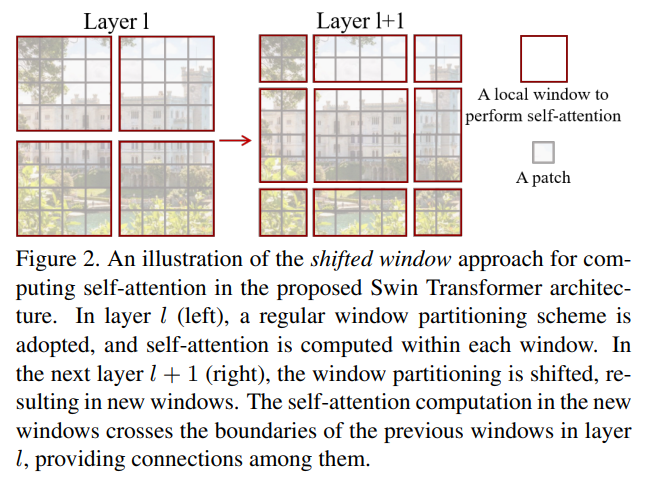
shifted windows
Swin Transformer는 "shifted windows"라는 기법을 사용한다. 이는 각 레이어마다 윈도우의 위치를 약간씩 이동시켜서 겹치게 한다.
자세한건 아래에서 다루겠습니다.
본 논문의 저자들은 하나의 아키텍쳐가 Vision 과 NLP task의 경계를 허물어주고 둘 다 훌륭하게 처리할 수 있다는 믿음이 있다고 합니다. Swin Transformer의 뛰어난 성능이 이 믿음에 힘을 보태주었으면 한다고 하네요 🥹
3. Methods
늘 그렇듯 오버뷰를 보고 옵시다.
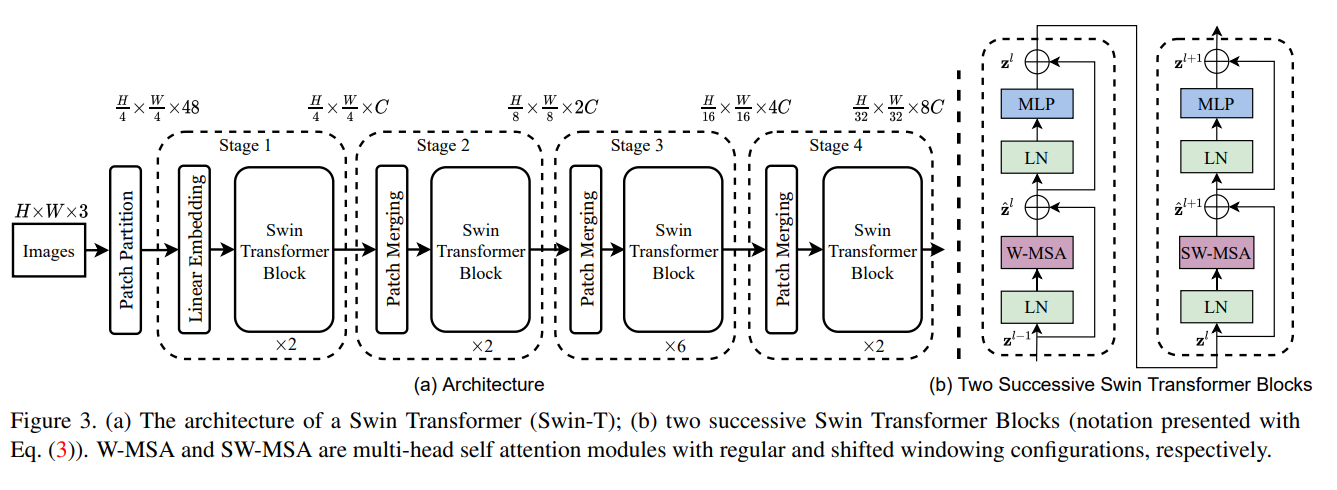
stage 1
먼저 4x4 patch size를 사용한뒤 48 ( 4 x 4 x 3 ) feature dimension을 C로 바꿔주는 linear embedding 을 통과합니다.
=>nn.Conv2d(3,C,4,strid=4) 와 같다
그러면 C x 56 x 56 이 ouput으로 나오겠죠? 여기서 윈도우 크기 내에서 (예를들면 7x7) self- attention을 수행합니다. attention weight가 빠져 나오면서 크기는 유지되겠죠.
여전히 Cx56x56 입니다.
stage 2
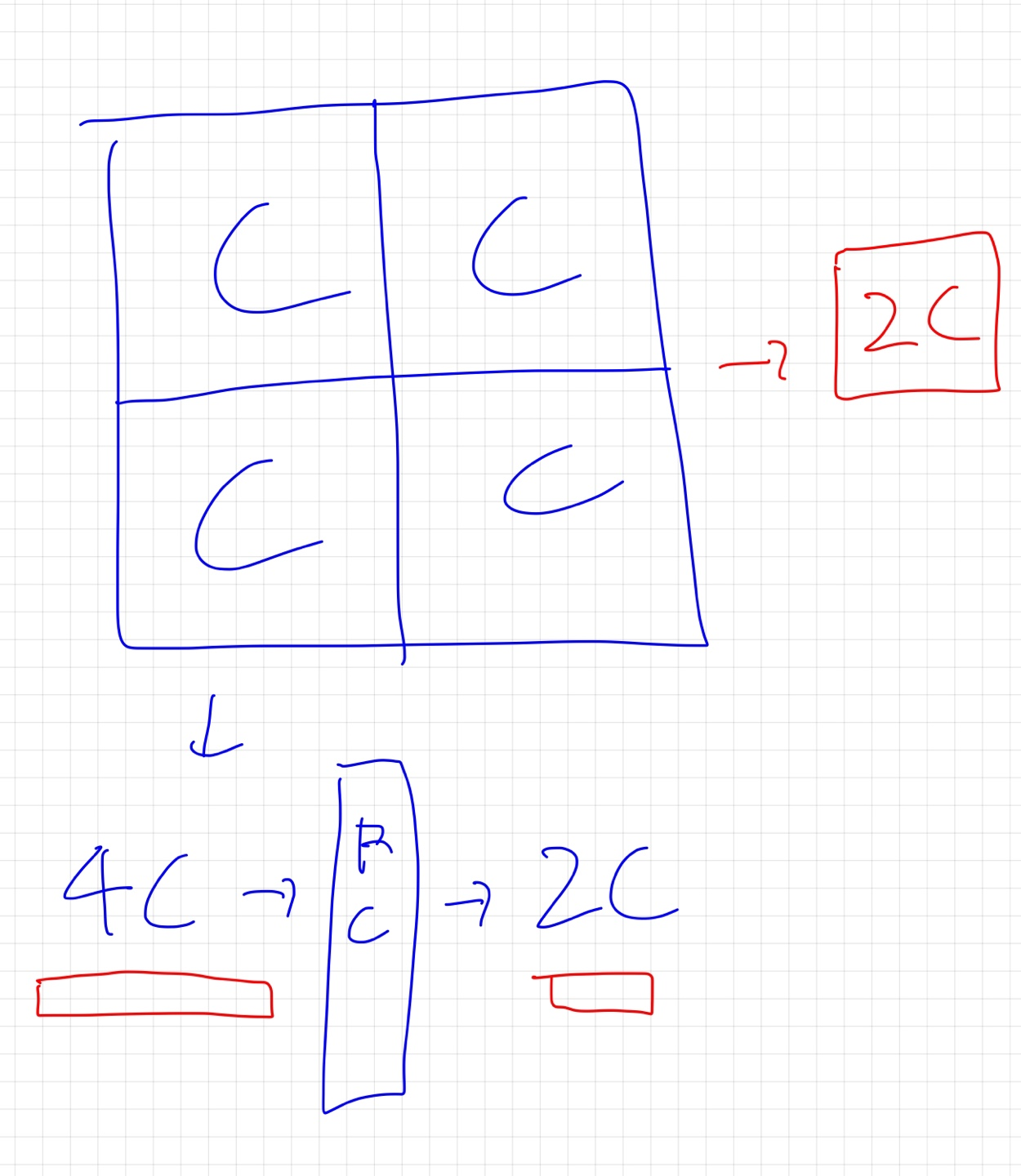
2x2 기준으로 Merge합니다. Merge한 4C가 Linear layer 를 거쳐서 4C=>2C가 되게 해줍니다. 28x28x2C가 되겠죠?
28x28에 대해서 또 윈도우 크기 내에서 self-attention 수행합니다.
stage 3
2x2 기준으로 Merge합니다. 근데 Linear layer 를 거쳐서 8C=>4C가 되게 해줍니다. 14x14x4C가 되겠죠?
14x14에 대해서 또 윈도우 크기 내에서 self-attention 수행합니다.
stage 4
2x2 기준으로 Merge합니다. 근데 Linear layer 를 거쳐서 16C=>8C가 되게 해줍니다. 7x7x8C가 되겠죠?
7x7에 대해서 또 윈도우 크기 내에서 self-attention 수행합니다
왜 back bone으로 사용가능하지?
이것은 마치 전통적인 CNN layer처럼 계층적으로 feature map을 뽑아 낸 것이라고 할 수 있습니다.
( self-attention으로 학습하고 줄이고 self-attention 학습하고의 반복이니 receptive field를 늘려가는 과정이라 할 수 있겠네요 )
그래서 기존 CNN 기반 아키텍쳐들을 대체할 수 있다고 말하죠
3.1 Details
Shifted window partitioning in successive block
우리가 그동안 언급했던 self-attention은 그냥 이루어지지 않는다. 엄격하게 구분된 상태에서 self-attention을 수행하는 방식은 gloabl한 정보교환이 이루어지지 않기 때문에 우리는 shifted window partitioning을 도입할 것이다.
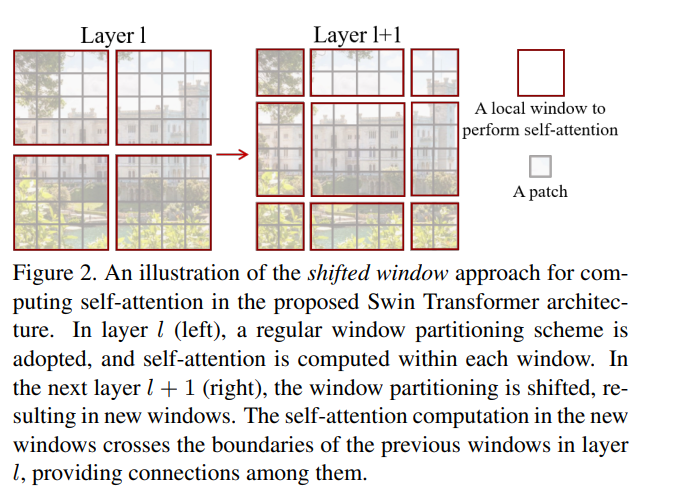 위와 같이 window를 움직인다. 윈도우 사이즈가 M이라면 (⌊ M/2 ⌋, ⌊ M/2 ⌋) 만큼 이동시킴! (위에선 (2,2) )
위와 같이 window를 움직인다. 윈도우 사이즈가 M이라면 (⌊ M/2 ⌋, ⌊ M/2 ⌋) 만큼 이동시킴! (위에선 (2,2) )
이렇게 밀리고밀리다 보면 각 픽셀이 전체에 대한 정보를 갖고있게 된다.
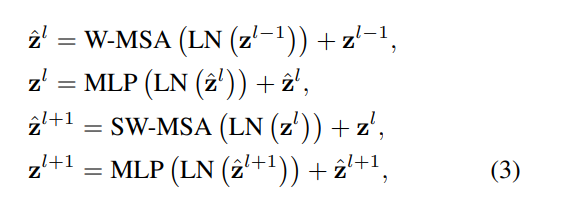
정리하면 block 하나가 위와같은 식을 거친다.
근데 기준 윈도우 사이즈로 명확히 안나뉘어 떨어지면?
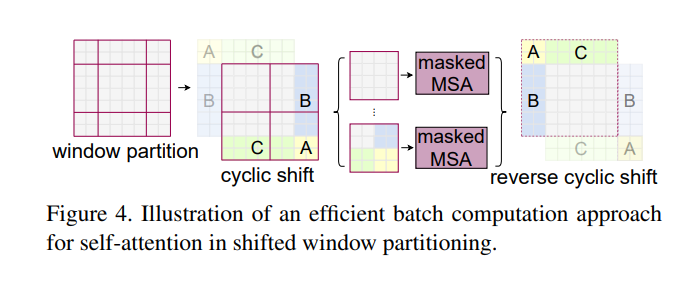
저렇게 왼쪽처럼 따로따로 attention 하면 GPU의 오버헤드가 커지게 된다.
(4번에 끝날거 9번이나 함수 호출하게 됨 => 메모리에 가서 가져왔다가 다른거 가져왔다가 )
패딩을 0 으로해서 계산할수도 있지만 이러면 불필요한 computation량이 많아짐 ( 위에만해도 7x7x8)
그래서 그림처럼 cyclic shift를 한뒤에 경계로 구분되어 있는 네모에 대해서는 masking을 하는 전략을 취한다. GPU효율도 최대한으로 낼 수 있고 (적은 오버헤드로 병렬처리 가능) , (7x7x4)로 줄일 수 있음
Relative position bias
지역성 정보를 추가하기위한 단계입니다.
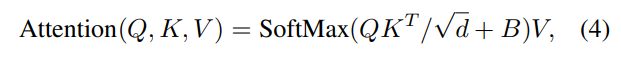
이건 예시로 설명하는게 쉬울 것 같네요
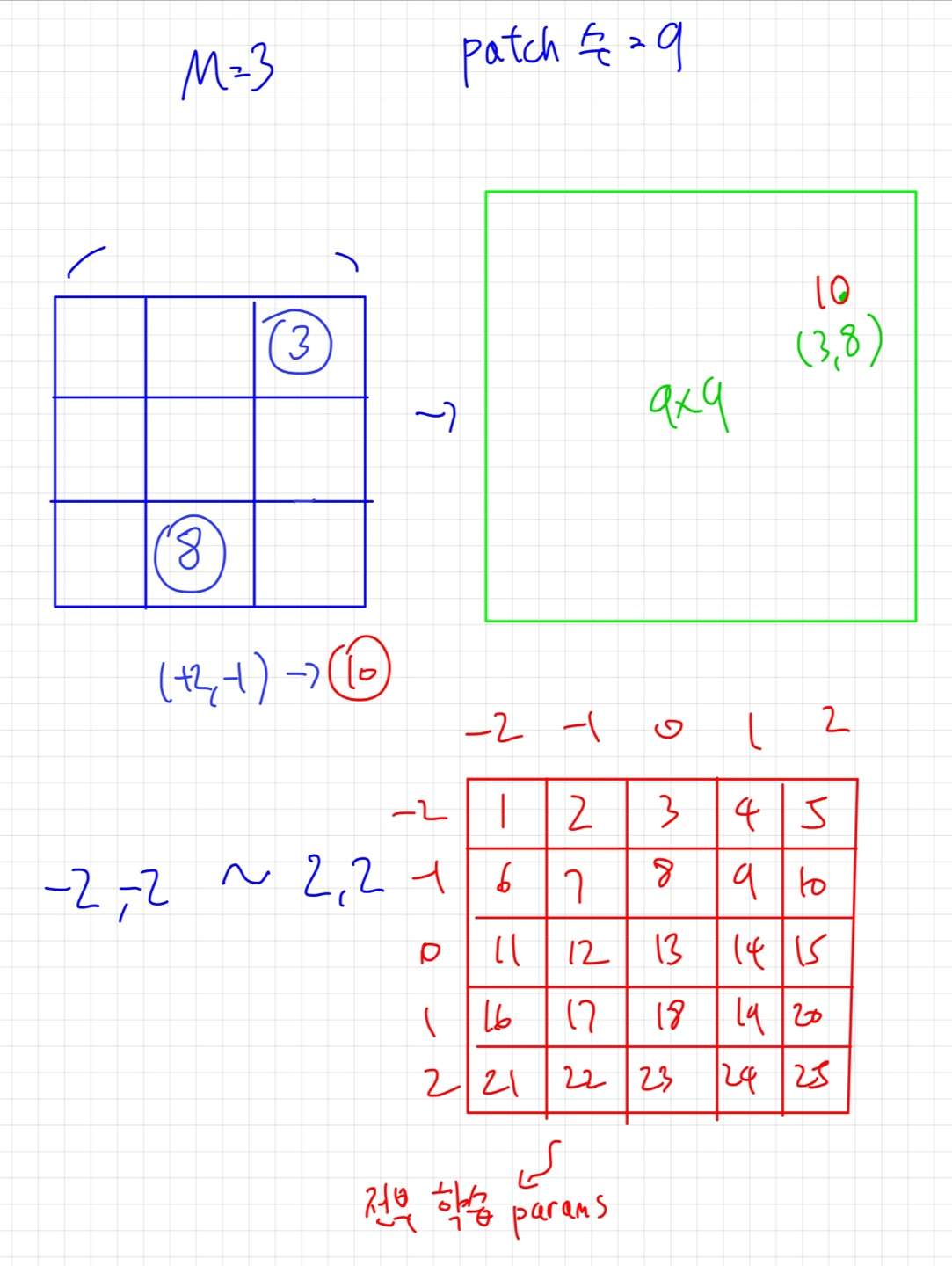
self attention을 적용하는 패치수가 9개라 할때
초록색이 B입니다 M4 에 해당하는 파라미터를 각각 따로 설정하지 않고 [2M-1] x [2M-1] 의 작은 행렬 B^ 로 부터 가져옵니다.
그리고 학습을 진행시킵니다!
이렇게 B를 추가해주면 locality 정보를 추가해줄 수 있겠죠
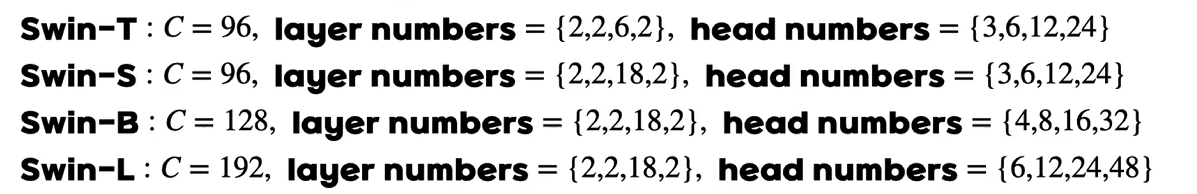
모델별 block , 차원의 수, head의 수는 위와 같다네요.
Window size=7로 고정입니다.
각 헤드의 dimension =>32가 되도록 했다네요
(초반 부분의 차원이 생각보다 적네..)
4. Experiments
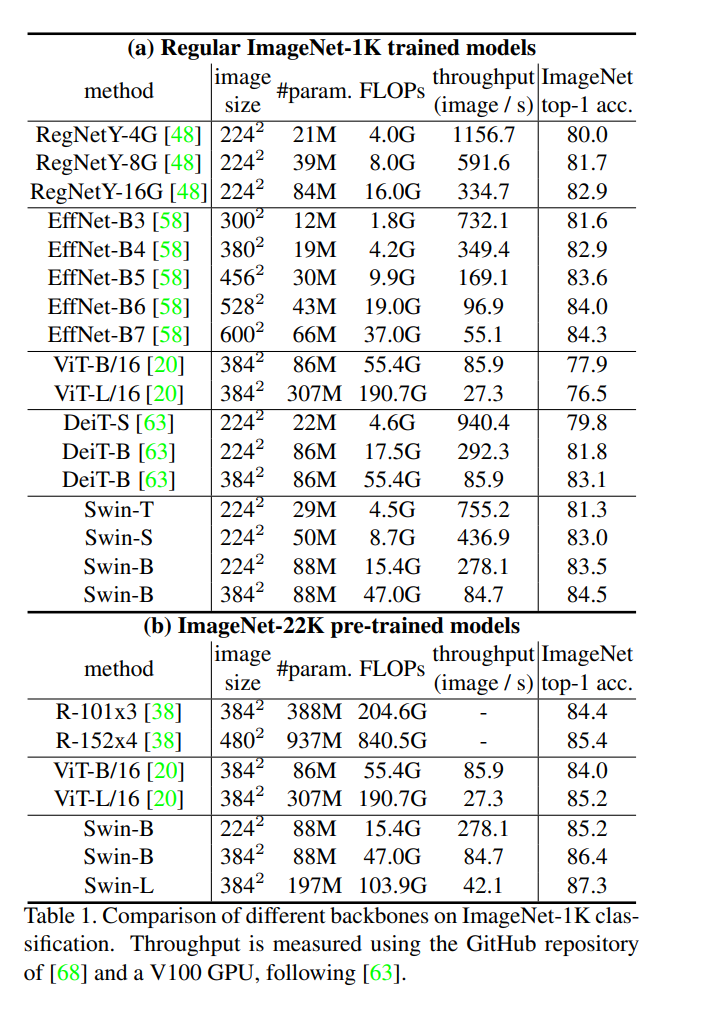
(a) 부터 보자면 (1k pre-train)
ViT는 압도했지만 Efficent Net과는 비슷한성능을 보인다. 하지만 throughput을 보면 Swin이 훨씬 빠른걸 확인 할 수 있다.
(b)를 봐도 ViT를 압도한걸 볼 수 있다.
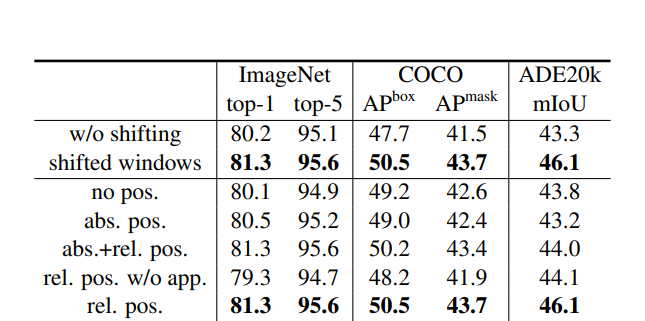
shifted window , relative positional bias의 성능도 보여주었다.
후기
간만에 CV논문들을 읽어서 그런지 읽고 정리하는데 되게 오래걸렸네요 😅.
window를 shift해서 global한 정보교환을 하는 것 , Relative position bias의 도입, patch merging 등등 처음보는 다양한 기법들이 나와서 꽤 난이도가 있었던 논문입니다.
시간 나는대로 experiments 부분 추가로 정리하도록 하겠습니다.
감사합니다
