Computer Vision
1.ILSVRC 논문 정리
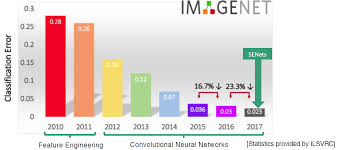
CNN 리뷰 먼저 CNN에 대해 가볍게 리뷰를 해보자. 어떻게 CNN이 MLP보다 우월한 성능을 보일 수 있었을까? 👩💼인간의 사고방식 흉내 신경다발을 잘 끊어 냄 실제 사람이 이미지를 인식할 때 뇌의 일부분만 활성화 된다는 것을 알게 되었다. 따라서
2.ILSVRC 논문 정리 (2)
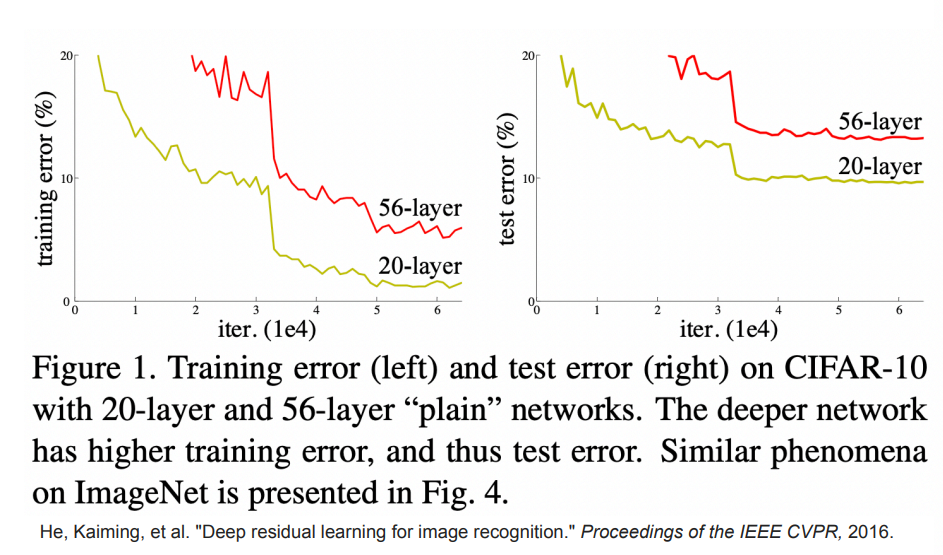
신경망을 학습하는데 이상한점이 발견되었다.layer의 개수가 늘수록 training error가 늘어나는 현상이 관찰 됨.보통 신경망을 깊게만들면 오버피팅이 나더라도 training은 잘 되어야 하는데 매우 수상함.왜 이런일이 생겼을까?이는 layer수가 많아짐에 따라
3.ILSVRC 논문 정리 (3)
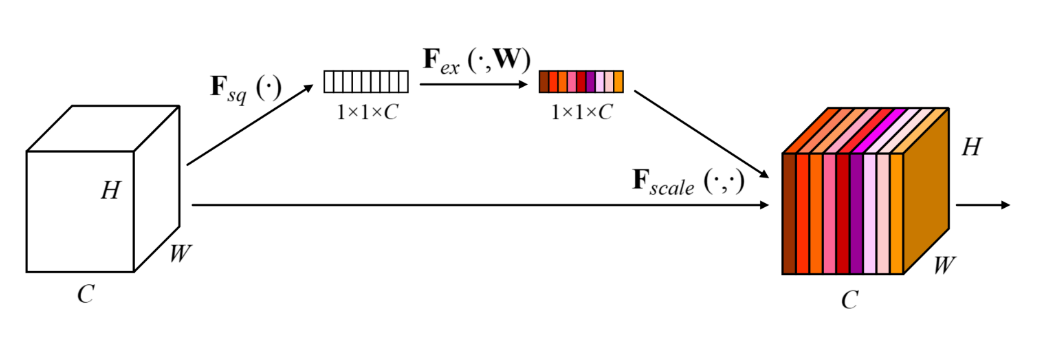
2017년 1등한 친구. (파라미터수 6600만)SE block은 아래와 같다.HxWxC 의 feature map을 GAP 한후 FC Layer 두층을 통과시킨 다음 그 값을 각 특징 맵 채널 에다가 곱해준다.FC Layer는 C -> C/16->C 형태의 네트워크다.
4.Auto Encoder에 대하여

Autoencoder는 무엇을 위해 쓰일까? 여러가지 쓰임새들이 있겠지만 Autoencoder의 가장 중요한 기능중 하나는 Manifold를 학습하는 것이다.Manifold는 복잡한 다차원 구조의 데이터 샘플들을 에러 없이 잘 다루는 subspace 이다.이런 sub
5.GAN 간단 정리
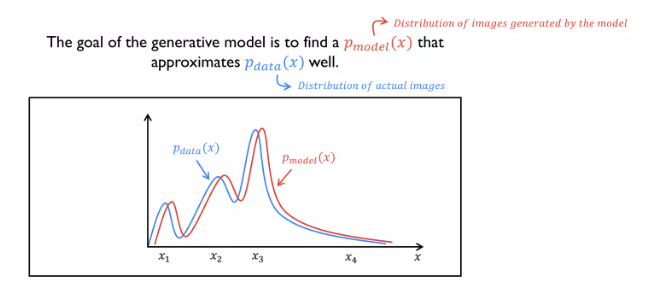
생성 모델은 데이터의 확률 분포에 근사하는 분포를 학습하여, 실제 데이터와 유사한 새로운 데이터를 생성하는 것을 목표로 합니다. 이를 통해, 생성 모델은 다음과 같은 작업을 수행할 수 있습니다GAN은 두가지 모델로 이루어져있다.input의 진위를 판단하는 Discrim
6.[VAE] Variational auto-encoder

VAE는 처음부터 auto encoder구조를 염두해두고 만들어 진게 아니다. 뒷단, 즉 generator부분을 학습시키려다 보니까 앞단이 붙은거고 공교롭게 그 구조를 보니까 auto encoder와 똑같아진 경우임우린 Generative model을 control
7.[논문 리뷰] An Image is worth 16x16 words: Transformers for Image recognition (2020)
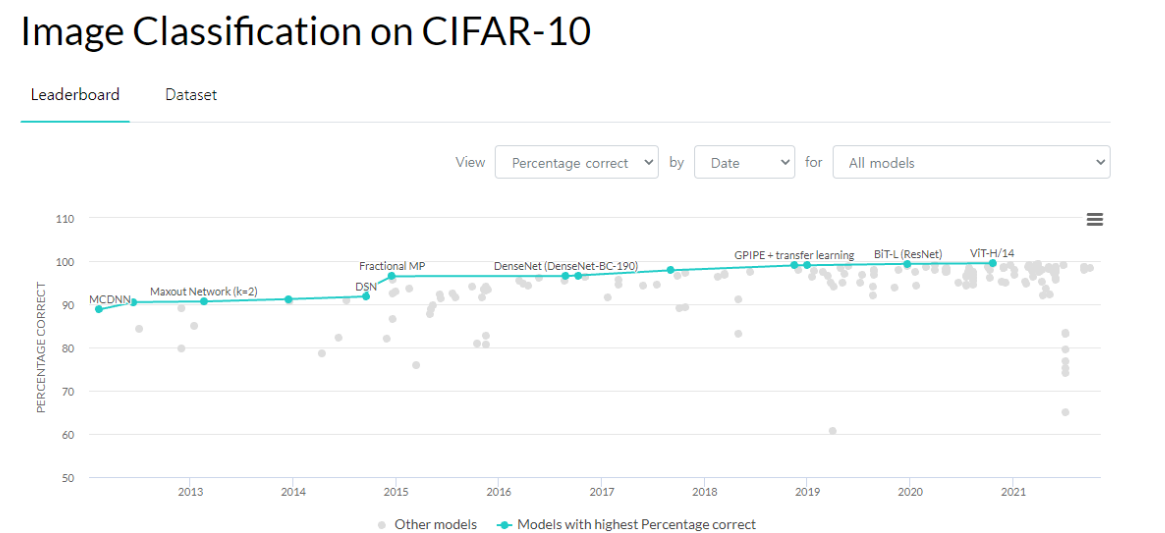
안녕하세요 오늘 그 유명한 ViT 논문을 가져왔습니다. 트랜스포머가 비전분야에서까지 쓰이네요. 너무 기대가 되는 논문입니다. 36000회 인용된 논문이구요 , 구글 리서치 팀에서 낸 논문입니다. 트랜스포머 아키텍쳐는 NLP 태스크를 수행함에 있어서 de-facto 스탠
8.[논문 리뷰]-Swin Transformer: Hierarchical Vision Transformer using Shifted Windows (2021)
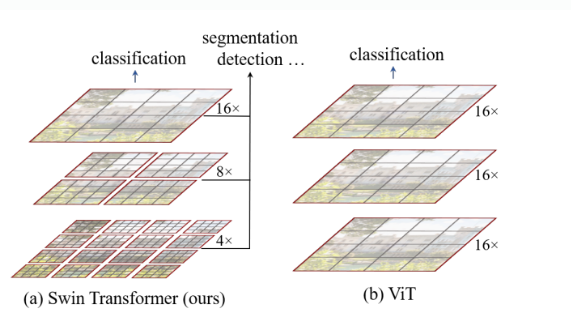
microsoft 논문18000회 인용 본 논문은 semantic segmentation, image classification, object detection 등 여러 비전 task에서 우수한 성능을 보이는 Swin Transformer를 컴퓨터 비전 분야의 back