이것이 취업을 위한 코딩 테스트다 with 파이썬 (나동빈 저) 의 책과 강의를 보고 정리한 글입니다.
강의 출처 : https://www.youtube.com/channel/UChflhu32f5EUHlY7_SetNWw

알고리즘 성능 평가
복잡도
알고리즘의 성능을 나타내는 척도
- 시간 복잡도 : 특정한 크기의 입력에 대하여 알고리즘의 수행 시간 분석
- 공간 복잡도 : 특정한 크기의 입력에 대하여 알고리즘의 메모리 사용량 분석
시간 복잡도와 공간 복잡도가 더 낮을 수록 좋다.
빅오 표기법(Big-O Notation)
가장 빠르게 증하가는 항만을 고려하는 표기법으로 함수의 상한만을 나타내게 된다.
- 예를 들어 연산 횟수가 3N^3 + 5N^2 + 1,000,000인 알고리즘이라면 빅오 표기법에서는 차수가 가장 큰 항만 남기므로 O(N^3)으로 표현한다.
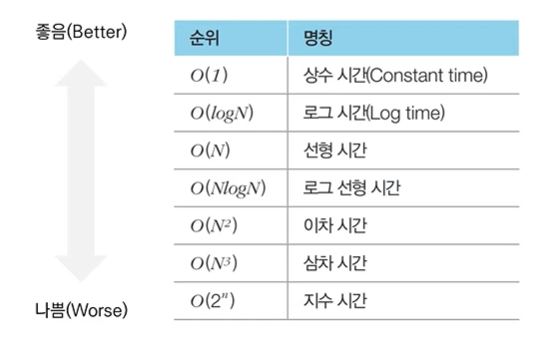
출처 : 이것이 취업을 위한 코딩 테스트다 with 파이썬 (나동빈 저)
시간 복잡도 계산해보기 1)
- N개의 데이터의 합을 계산하는 프로그램
array = [3, 5, 1, 2, 4] # 5개의 데이터 (N=5)
summary = 0 # 합계를 저장할 변수
# 모든 데이터를 하나씩 확인하며 합계를 계산
for x in array:
summary += x
# 결과를 출력
print(summary)
수행 시간은 데이터의 개수 N에 비례할 것임을 예측할 수 있다.
- 시간 복잡도 : O(N)
시간 복잡도 계산해보기 2)
- 2중 반복문을 이용하는 프로그램 예제
array = [3, 5, 1, 2, 4] # 5개의 데이터(N=5)
for i in array:
for j in array:
temp = i * j
print(temp)- 시간 복잡도 : O(N^2)
참고로 모든 2중 반복문의 시간 복잡도가 O(N^2)인 것은 아니다. 소스코드가 내부적으로 다른 함수를 호출한다면 그 함수의 시간 복잡도까지 고려해야 한다.
알고리즘 설계
일반적으로 CPU 기반의 개인 컴퓨터가 연산 횟수가 5억을 넘어가는 경우:
C 기준 통산 1~3초 Python 기준 5~15초 가량 소요
PyPy의 경우 때때로 C보다 빠를수도?
O(N^3)의 알고리즘의 경우 N의 값이 5000이 넘는다면 엄청난 시간이 걸린다. 코딩 테스트 문제는 대부분 1~5초 제한이 있으므로 유의하자
요구사항에 따른 적절한 알고리즘
문제에서 가장 먼저 확인해야 할 내용은 시간제한(수행시간 요구사항)이다.
시간제한이 1초인 문제를 만났을 때, 일반적인 기준
- N의 범위가 500인 경우 : O(N^3)
- N의 범위가 2000인 경우 : O(N^2)
- N의 범위가 100,000인 경우 : O(NlogN)
- N의 범위가 10,000,000인 경우 : O(N)
알고리즘 문제 해결 과정
- 지문 읽기 및 컴퓨터적 사고
- 요구사항(복잡도) 분석
- 아이디어 찾기
- 설계 및 코딩
수행 시간 측정 소스코드
import time
start_time = time.time() # 측정 시작
# 프로그램 소스코드
end_time = time.time() # 측정 종료
print("time:", end_time - start_time) # 수행 시간 출력파이썬 문법 보충
지수 표현 방식
파이썬에서는 e나 E를 이용한 지수 표현 방식을 이용할 수 있다.
- 1e9 = 10의 9제곱
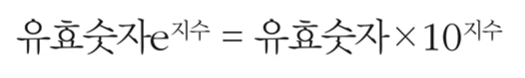
최단 경로 알고리즘에서는 도달할 수 없는 노드에 대하여 최단 거리를 무한(INF)로 설정하곤 한다. 이때 가능한 최댓값이 10억 미만이라면 무한(INF)의 값으로 1e9를 이용할 수 있다.
지수 표현 방식은 기본적으로 실수 데이터로 들어가기 때문에 출력을 해보면 실수형 데이터로 출력된다.
실수의 한계
컴퓨터 시스템은 실수 정보를 표현하는 정확도에 한계를 가진다. 10진수에서는 0.9를 표현할 수 있지만 컴퓨터에서는 0.9와 가까운 수로 미세한 오차를 낸다.
따라서 round()함수를 이용하여 반올림해주는 것이 좋다.
- 123.456을 소수 셋째 자리에서 반올림하려면 round(123.456, 2)
나누기 연산자(/) 주의
파이썬에서 나누기 연산자(/)는 나눠진 결과를 실수형으로 반환하는 것에 주의하자.
리스트 초기화
- 리스트는 대괄호 안에 원소를 넣어 초기화하며, 쉼표(,)로 원소를 구분한다.
- 리스트의 원소에 접근할 때에는 인덱스(index)값을 괄호에 넣는다.
# 직접 데이터를 넣어 초기화
a = [1, 2, 3, 4, 5, 6, 7, 8, 9]
print(a)
# 크기가 N이고, 모든 값이 0인 1차원 리스트 초기화
n = 10
a = [0] * n
print(a)
리스트 컴프리헨션
- 대괄호 안에 조건문과 반복문을 적용하여 리스트를 초기화할 수 있다.
# 0부터 9까지의 수를 포함하는 리스트
array = [i for i in range(10) if i % 2 == 1]
print(array)- 2차원 리스트를 초기화할 때 효과적으로 사용할 수 있다. 특히 N X M 크기의 2차원 리스트를 한 번에 초기화 해야할 때 매우 유용하다.
좋은 예)
# N번 반복할 때마다 길이가 m인 리스트를 새롭게 초기화하는 리스트
array = [[0] * m for _ in range(n)]
- 만약 2차원 리스트를 초기화할 때 다음과 작성하면 예기치 않은 결과가 나올 수 있다.
잘못된 예)
array = [[0] * m] * n
위 코드는 전체 리스트 안에 포함된 각 리스트가 모두 같은 객체로 인식된다.
코딩 테스트에 많이 쓰이는 리스트 관련 메서드

리스트에서 특정 값을 가지는 원소를 모두 제거하기
a = [1, 2, 3, 4, 5, 5, 5]
remove_set = {3, 5} # 집합 자료형
# remove_list에 포함되지 않은 값만을 저장
result = [i for i in a if i not in remove_set]
print(result)문자열은 변경 불가능하다!
- 문자열은 리스트와 마찬가지로 인덱싱, 슬라이싱이 가능하지만 특정한 인덱스의 값을 변경하는 것이 불가능하다 !
튜플을 사용하면 좋은 경우
-
서로 다른 성질의 데이터를 묶어서 관리해야 할 때 - 최단 경로 알고리즘에서는 (비용, 노드 번호)의 형태로 튜플 자료형을 자주 사용한다.
-
데이터의 나열을 해싱(Hashing)의 키 값으로 사용해야 할 때 (사전 자료형, 집합 자료형 등에서 해싱의 키 값으로 데이터의 묶음, 나열을 사용해야 할 때) - 튜플은 변경이 불가능하므로 리스트와 다르게 키 값으로 사용될 수 있다.
-
리스트보다 메모리를 효율적으로 사용해야 할 때
참고) 튜플 자료형은 리스트와 유사하지만 한 번 선언된 값을 변경할 수 없고, 리스트에 비해 상대적으로 공간 효율적이다.
사전 자료형
-
키와 값의 쌍으로 데이터를 가진다. - 리스트나 튜플이 순차적으로 저장하는 것과 대비
-
자료의 순서가 없기 때문에 인덱싱으로 값을 얻을 수 없다.
-
원하는 '변경 불가능한(immutable) 자료형'을 키로 사용할 수 있다.
-
파이썬의 사전 자료형은 해시 테이블(Hash Table)을 이용하므로 데이터의 조회 및 수정에 있어서 O(1)의 시간에 처리할 수 있다.
집합 자료형
-
중복을 허용하지 않고, 순서가 없기 때문에 데이터의 존재 여부를 확인할 때 유용하다.
-
자료의 순서가 없기 때문에 인덱싱으로 값을 얻을 수 없다.
-
리스트 혹은 문자열을 이용하여 초기화할 수 있다. - set() 함수 이용
-
데이터의 조회 및 수정에 있어서 O(1)의 시간에 처리할 수 있다.
자주 사용되는 표준 입력 방법
-
input() : 한줄의 문자열을 입력
-
map() : 리스트의 모든 원소에 각각 특정한 함수를 적용할 때 사용
예시) 공백을 기준으로 구분된 데이터를 입력 받을 경우
list(map(int, input().split()))예시) 공백을 기준으로 구분된 데이터가 무조건 3개 입력된다고 한다면 다음과 같이 할 수 있다.
a, b, c = map(int, input().split()))학생의 성적 데이터가 주어지고, 이를 내림차순으로 정렬한 결과를 출력하는 프로그램
# 데이터의 개수 입력
n = int(input())
# 각 데이터를 공백을 기준으로 구분하여 입력
data = list(map(int, input().split()))
data.sort(reverse=True)
print(data)빠르게 입력 받기
-
사용자로부터 입력을 최대한 빠르게 받아야 하는 경우가 있다.
-
파이썬의 경우 sys 라이브러리에 정의되어 있는 sys.stdin.readline() 메서드를 이용한다. 단, 입력 후 엔터가 줄 바꿈 기호로 입력되므로 rstrip() 메서드를 함께 사용한다.
-
입력의 개수가 매우 많은 문제는 입력을 받는 것만으로 많은 시간이 소요되어 문제가 생길 수 있는데 readline()으로 해결한다.
-
실제로 이진탐색, 정렬, 그래프 관련 문제에서 자주 사용되는 테크닉이다.
import sys
# 문자열 입력 받기
data = sys.stdin.readline().rstrip()
print(data)자주 사용되는 표준 출력 방법
-
파이썬에서 기본 출력은 print() 함수를 이용한다. 각 변수를 ,를 이용하여 띄어쓰기로 구분하여 출력할 수 있다.
-
print()는 기본적으로 출력 이후에 줄 바꿈을 수행한다. 줄 바꿈을 원치 않는 경우 'end' 속성을 이용할 수 있다.
코딩 테스트 무한 루프
-
코딩 테스트에서 무한 루프를 구현할 일은 거의 없으니 유의
-
반복문을 작성한 뒤에는 항상 반복문을 탈출할 수 있는지 확인
여러 개의 반환 값
def operator(a, b):
add = a+b
sub = a-b
mul = a*b
div = a/b
return add, sub, mul, div
data = list(operator(7, 3))
print(data)
람다 표현식
- 특정한 기능을 수행하는 함수를 한 줄에 작성할 수 있다.
print((lambda a, b: a+b)(3, 7))-
함수 자체를 입력으로 받는 또 다른 함수가 존재할 때 유용하게 사용할 수 있다.
-
내장함수 특히 sorted와 같은 정렬 함수를 사용할 때 람다 함수를 사용한다.
array = [('홍길동', 50), ('이순신', 32), ('아무개', 74)]
def my_key(x):
return x[1]
print(sorted(array, key=my_key))
print(sorted(array, key=lambda x: x[1]))- 여러 개의 리스트에 동일한 규칙을 가지는 함수를 적용하고자 할 때
list1 = [1, 2, 3, 4, 5]
list2 = [6, 7, 8, 9, 10]
result = map(lambda a, b: a+b, list1, list2)
print(list(result))
실전에서 유용한 표준 라이브러리
-
itertools : 파이썬에서 반복되는 형태의 데이터를 처리하기 위한 유용한 기능 제공 - 특히 순열과 조합 라이브러리는 코딩 테스트에서 자주 사용
-
heapq: 힙(Heap) 자료구조를 제공 - 우선순위 큐 기능을 구현하기 위해 사용
-
bisect: 이진 탐색(Binary Search) 기능을 제공합니다.
-
collections: 덱(deque), 카운터(Counter) 등의 유용한 자료구조 포함
-
math: 필수적인 수학적 기능 제공 - 펙토리얼, 제곱근, 최대공약수, 삼각함수, 파이(pi) 등
자주 사용되는 내장 함수
-
sum(), min(), max()
-
eval() : 사람의 입장에서 작성된 식을 실제 수 형태로 계산
# eval()
result = eval("(+5)*7")
print(result)- sorted(), sorted() with key
순열과 조합
모든 경우의 수를 고려해야 할 때 어떤 라이브러리를 효과적으로 사용할 수 있을까?
-
순열 : 서로 다른 n개에서 서로 다른 r개를 선택하여 일렬로 나열하는 것
{a,b,c} 에서 3개를 선택하여 나열하는 경우 : abc, acb, bac, bca, cab, cba -
조합 : 서로 다른 n개에서 순서에 상관 없이 서로 다른 r개를 선택하는 것
{a,b,c} 에서 순서를 고려하지 않고 두 개를 뽑는 경우 : ab, ac, bc
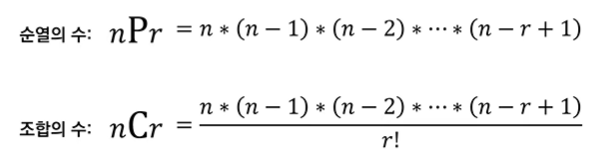
- 모든 순열 구하기
from itertools import permutations
data = ['a', 'b', 'c']
# 모든 순열 구하기
result = list(permutations(data, 3))
print(result)- 중복 순열
from itertools import product
data = ['a', 'b', 'c']
# 2개를 뽑는 모든 순열 구하기 (중복 허용)
result = list(product(data, repeat=2))
print(result)- 중복 조합
from itertools import combinations_with_replacement
data = ['a', 'b', 'c']
# 2개를 뽑는 모든 조합 구하기 (중복 허용)
result = list(combinations_with_replacement(data, 2))
print(result)Counter
- 파이썬 collections 라이브러리의 Counter는 등장 횟수를 세는 기능을 제공
- 리스트와 같은 반복 가능한 객체가 주어졌을 때 내부의 원소가 몇 번씩 등장했는지를 알려준다.
from collections import Counter
counter = Counter(['red', 'blue', 'red', 'green', 'blue', 'blue'])
print(counter['blue'])
print(counter['red'])
print(dict(counter)) # 사전 자료형으로 반환최대 공약수와 최소 공배수
- math 라이브러리의 gcd() 함수 이용
import math
# 최소 공배수(LCM)를 구하는 ㅎ마수
def lcm(a, b):
return a * b // math.gcd(a, b)
a = 21
b = 14
print(math.gcd(a, b)) # 최대 공약수(GCD) 계산
print(lcm(a, b)) # 최소 공배수(LCM) 계산