월 유지비 1$ 미만으로 마참내 안죽는 on-premise 인프라를 만들었다.

TL;DR
- https://yodangang.express
- k8s 클러스터: RPi * 3, x86 VM * 2
- 각각의 클러스터는 지리적으로 20km 이상 떨어져있음
- Tailscale VPN을 이용
- CNPG를 이용해 PostgreSQL의 HA를 구성
- Redis Sentinel을 이용해 Redis HA를 구성
- kube-system의 모든 deployment를 HA 구성
- 이론상 단 하나의 노드만 살아남아도 서비스는 건재함
- Google Cloud - Cloud Storage에 컨텐츠와 DB 백업
- 이렇게 되기까지 2년동안 많은 시행착오가 있었음
- 왠만한 사고에도 서비스에 장애가 생기지 않았으면 해서 여기까지 오게 됨
목차
어케핸ㄴ노
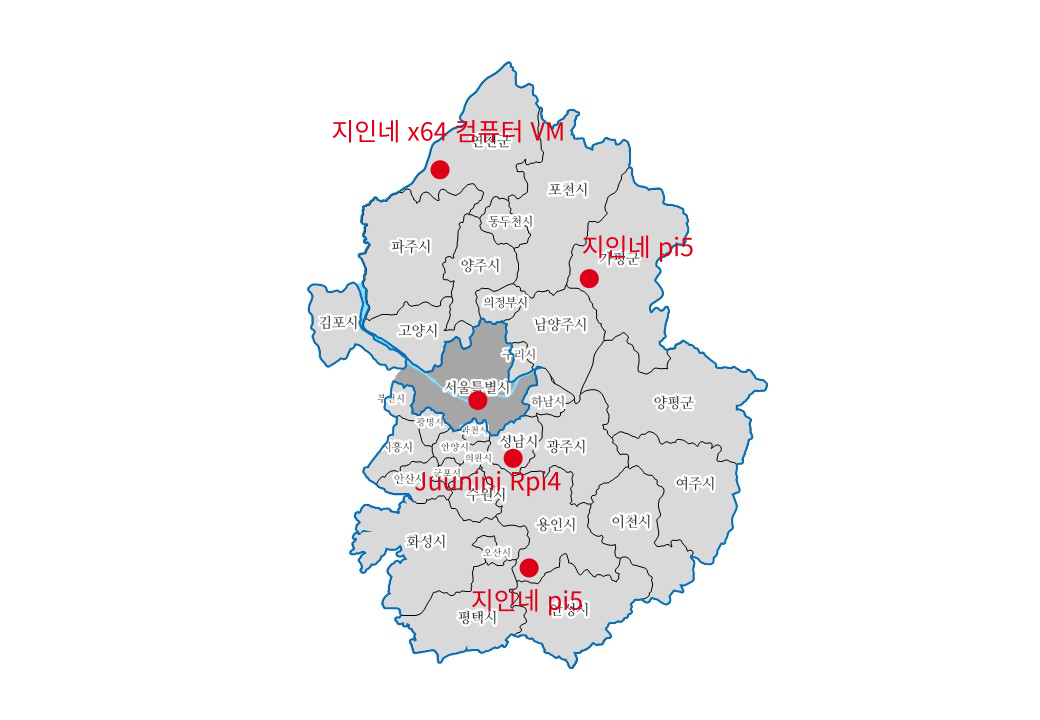
위의 지도에 표시한 위치는 실제 위치와는 무관합니다.
그냥 마음에 드는 아무 구석탱이에 하나씩 찍었어요.
(우리집 빼고)
하지만 이 정도로 멀리 떨어져 있다는건 사실입니다.
어떻게 구성했나?
Tailscale
Tailscale을 이용해
각각 다른 장소에 있는 노드들을 한 네트워크에 모았습니다.
❗맨 위에
azure-vm-1이 보여서 잠깐 딴소리를 하자면
CockroachDB 테스트를 위해 노드 수를 충당 하려고 잠시 붙여놓은거고
조만간 뗄 예정입니다.
Tailscale을 썼을 때의 장점이 몇 가지가 있는데
- 무료
- 보안
- 밖에서 각각의 노드로 SSH를 못함
- Tailscale VPN에 접속을 해야만 SSH 가능
- DB도 외부에서 접근 못함
- 같은 네트워크로 인식
- 쉬운 설치
이런 장점들이 있습니다.
무료로 쓰고있는데도 속도도 빠르고 좋구요.
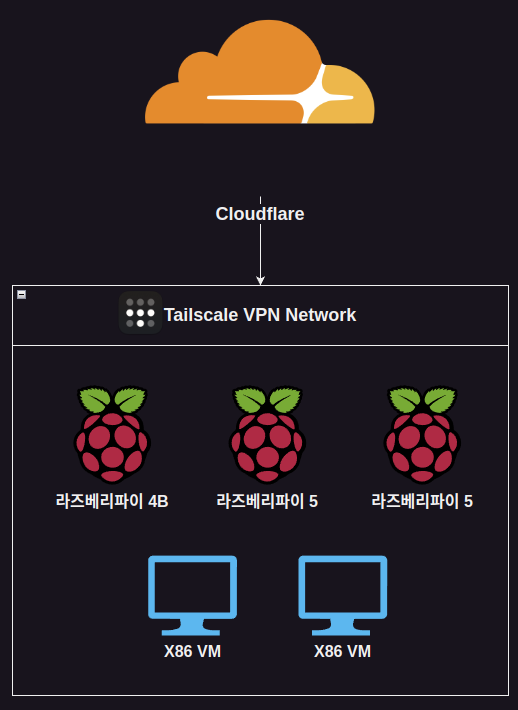
대충 그림으로 쉽게 풀면 이렇지요.
Kubernetes 노드 구성

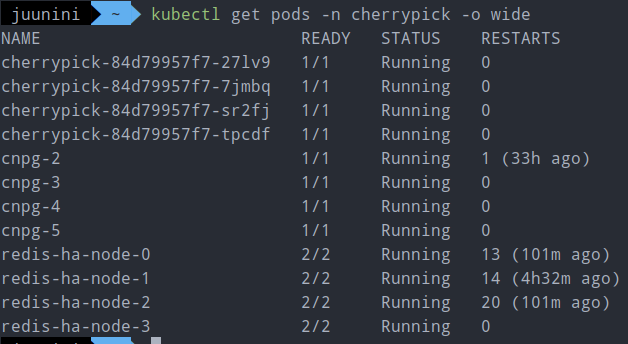
kubectl get nodes -o wide 해서 나오는거 보면
3개는 라즈베리파이고(arm64)
2개는 x86 입니다(amd64).
모든 노드가 같은 아키텍쳐도 아니고
같은 장소에 있지도 않죠.
지리적으로 20km 이상 떨어져 있기도 하구요.
서비스 구성
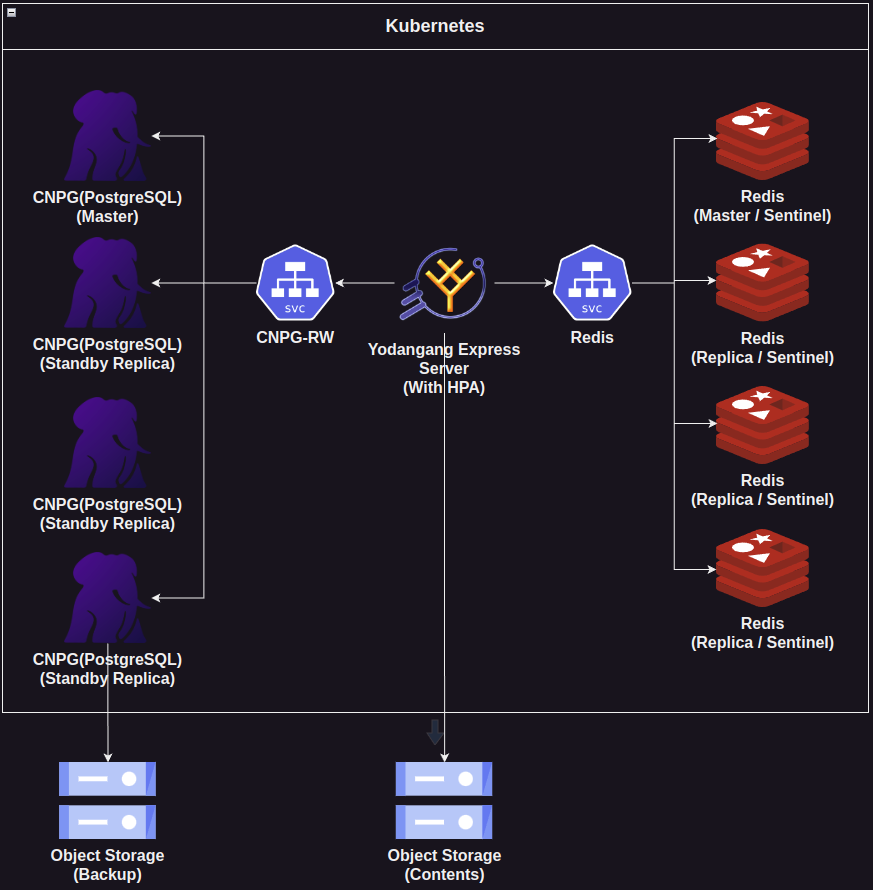
- CNPG
- Redis
- Cherrypick (Misskey의 포크)
이론상 단 하나의 노드만 살아남는다면
서비스는 장애 없이 잘 유지됩니다.
정은이가 맨날 외치는 남조선 불바다가 현실이 되더라도
일본 리전에도 백업이 되고있기에
다시 살려낼 수 있습니다.
근데 내가 죽으면 누가 다시 살려내주지?
CNPG
CockroachDB, postgresql-ha, CNPG
셋 중에 뭘 쓸지 고민을 많이 했었습니다.
처음 테스트 한건 CockroachDB였는데,
써본적도 없고 설정도 어찌 하는지 몰라서 그런지
Slow Query가 많이 뜨고 속도 개선도 어찌 해야할지 몰라서 포기했습니다.
다음 테스트 한건 postgresql-ha인데,
Master 파드와 Replica 파드의 커넥션을 분리시켜주지 않았습니다.
그래서 CNPG까지 테스트 해보고 결정하기로 했죠
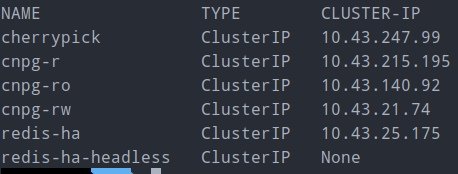
CNPG는 rw(Master), ro(Read-Only), r(준비된거 아무거나)
이렇게 k8s의 service가 따로 떠서 좋았습니다.
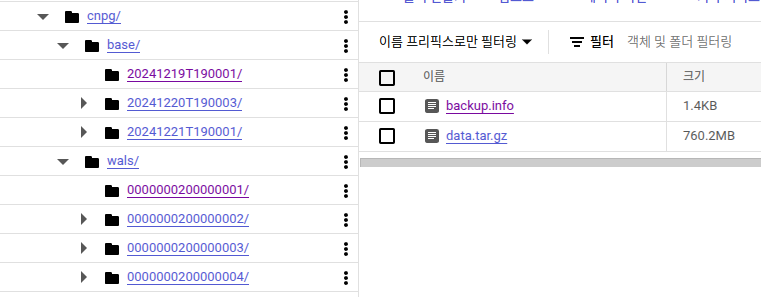
추가적으로 클라우드에 백업을 해주는 설정도 있었기에
CNPG를 골랐습니다.
dump도 되고, wal 백업도 되고 암튼 좋음
Redis
원래는 Redis Cluster를 고려했었습니다.
다만, Redis랑 Redis Cluster는
ioredis 에서 코드를 다르게 쓰도록 하기에
수정하기 귀찮아서 결국 도입을 안했습니다.
Redis 쪽에 sentinel 구성으로 replication 할 수 있는 옵션이 있었습니다.
원래 이거 직접 구성하려면 엄청 힘든데(해본적 있음)
이걸 자동으로 해준다니 안할 이유가 없었죠.
sentienl로 replication을 한 redis에 접속하려면
- Sentinel한테 Master가 누군지 물어본다
- Master가 어딘지 확인 후 연결
(이렇게 안하고 그냥 연결하면 replica에 접속될 가능성이 있음)
이런 과정이 필요합니다.
간단하게 아래의 설정을 추가하는걸로 마무리 되었습니다.
근데 진짜 안죽나?
테스트 했을 때 괜찮기에 괜찮겠지 하고 생각했었습니다.
그런데, 어쩌다보니 구성 하자마자 문제가 생겨서
적용한지 1시간만에 실전에서 당해봤습니다.
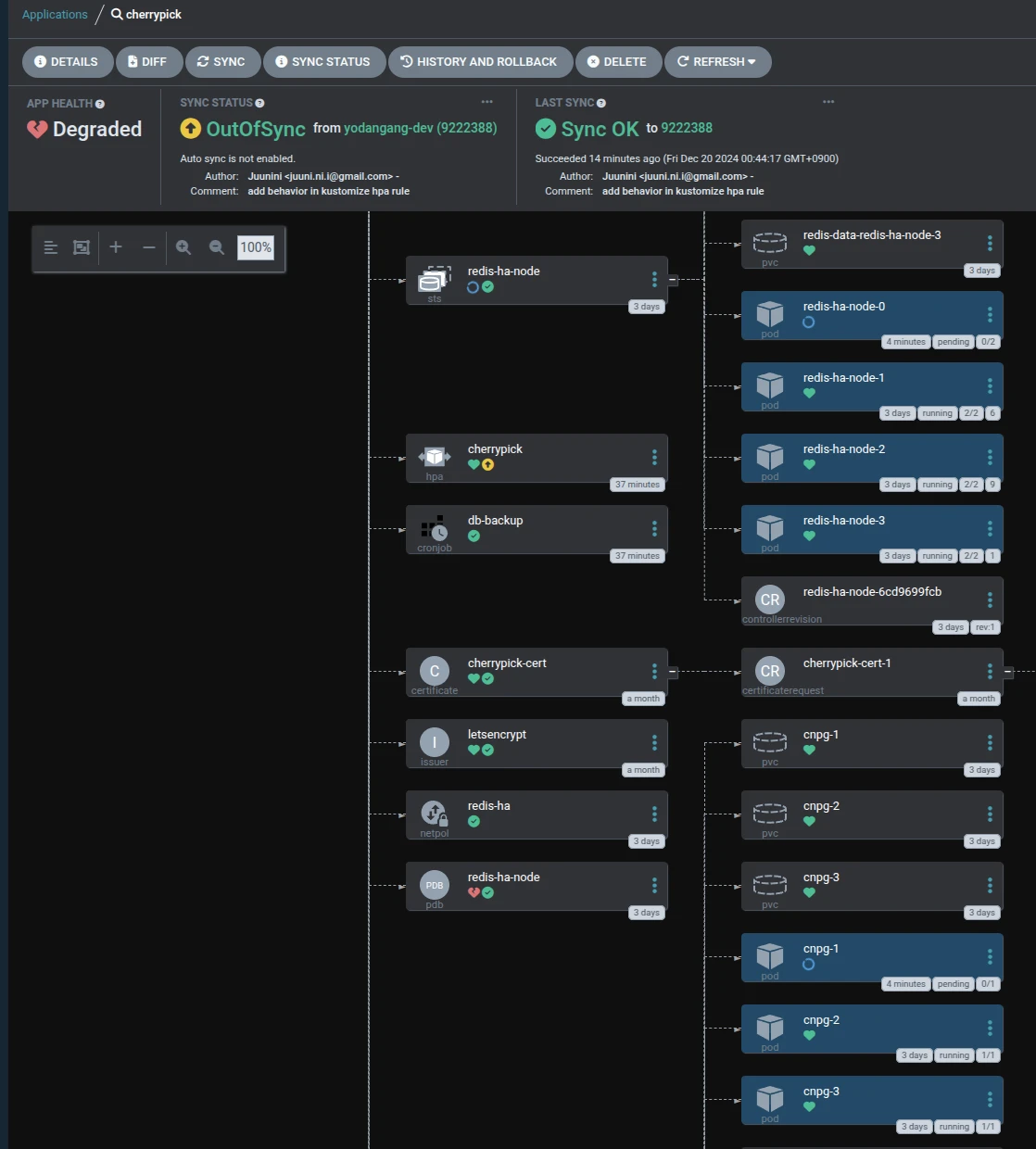
노드 하나가 메트릭 서버 이상으로 모니터링이 안되서
HPA랑 PDB에서 Warning을 내고 있기에
어쩔 수 없이 해당 노드를 delete 시킨 후
iptables -F 해서 깔끔하게 만들고 다시 붙였는데
위의 이미지는 그 시간동안 redis 0번과 cnpg 1번...
그러니까, 공교롭게도 각각 Master Pod가 올라간 노드를 떼는 바람에
그것들이 pending 되어있는 상태를 찍은건데
이런 상태인데도 서비스에는 전혀 장애가 발생하지 않았습니다.
그 외에도 몇번 더 노드가 죽은적이 있었는데
그 때에도 서비스엔 아무런 장애가 없었습니다.
라즈베리파이는 종종 번갈아가며 죽음
왜 죽었냐면
라즈베리파이5는 4보다 발열량이 높아서
자체 발열로 죽어버리는데
쿨러 설정을 따로 해주지 않으면
쿨러가 작동을 안합니다...
그런 이유로 라즈베리파이가 몇 번 죽은 적이 있었습니다.
아래 설정을 추가해서 더 이상은 라즈베리파이5가 죽지 않게 되었지만
그래도 라즈베리파이가 둘 쯤 죽는다고 아무런 장애는 없었습니다.
https://gist.github.com/juunini/b52a9c3c77bfb84e343ffb51cb73fb88

라즈베리파이는 사실 별 이유 없이도 자주는 아니지만, 개복치마냥 가끔 죽습니다.
서버용 컴퓨팅 자원이 아니기에 어쩔 수 없지요.
죽으면 그냥 재부팅 시켜주면 다시 잘 붙습니다.
다만 어제 한 번 장애가 있었음
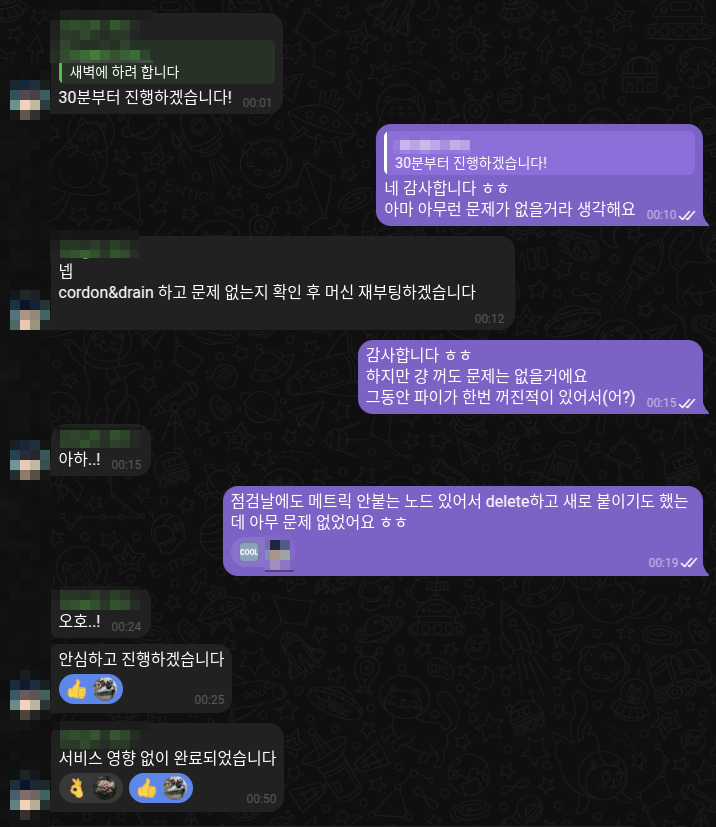
x86 VM을 제공해주시는 지인분께서 컴퓨터 재부팅을 하셨는데
서비스에는 아무런 영향이 없었습니다.
그래서 괜찮은 줄 알았는데...
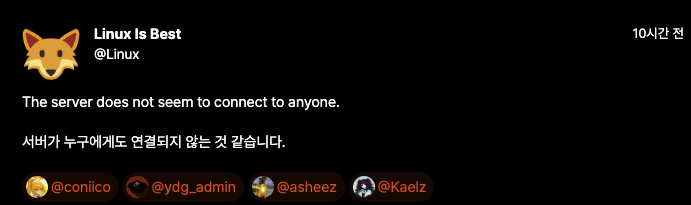
이 분은 미국 사람이고 우리는 한국 사람이기에
새벽 2시쯔음에 이런 제보가 올라왔었고
아침 7시에 일어나서 뒤늦게 조치를 하게 되었습니다.
rollout restart 하니 괜찮아지긴 했는데,
원인을 찾아보니 공교롭게도 CoreDNS Pod가 올라간 노드가 재부팅이 됐었고
그 이후로 모든 Pod가 인터넷 통신이 안됐었던 겁니다.
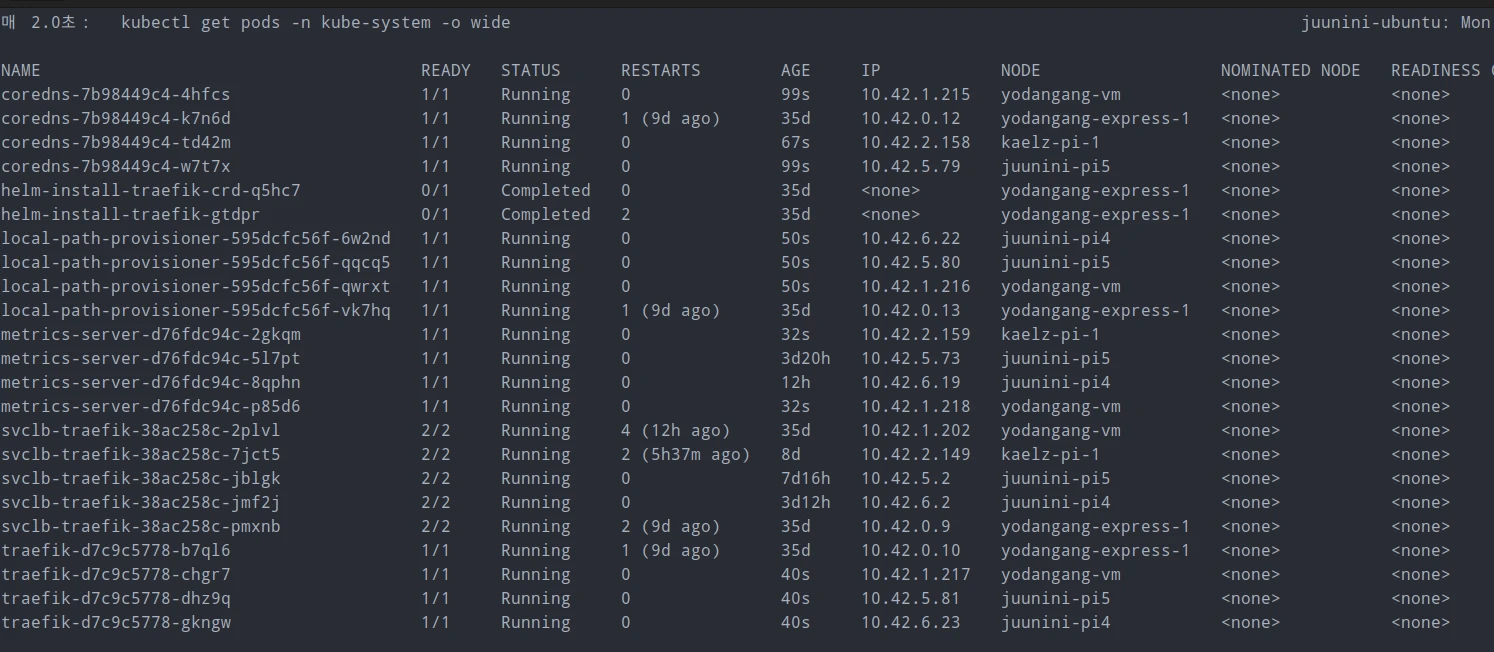
kube-system에 있는 모든 deployment를 scale out 했는데,
찾아보니 클라우드에서 제공하는 k8s는
대부분 이런식으로 kube-system의 HA를 설정해두더군요.
여담
라즈베리파이 구매한건 돈 아니냐?
맞습니다. 근데 하드웨어 구매 비용이랑 유지비는 다르다고 생각합니다.
4vCPU / 8GB Mem (arm64) 스펙을 클라우드에서 쓰려면 월 유지비가 적어도 10만원은 나올겁니다.
그동안 강조하던 서버리스는 어디다 팔아먹었냐 하는 사람도 있겠지만
PostgreSQL과 Redis는 조상님이 내려주지 않기에
SaaS를 쓰던가 VM을 올리던가 해야합니다.
클라우드 쓰면 월 유지비 10만이라 쳤을 때
2년이면 240만원인데
라즈베리파이 3개 사는데 30만원이면 됩니다.
아, 요즘 환율땜에 비싼가?
다만, 물리장비를 관리함으로 인한 고통도 감내해야 합니다.
물리장비는 언제 어떤 이유로 죽을지 모르고,
수명이 다 해서 죽는것도 생각해야 합니다.
특히나 라즈베리파이는 SD카드의 짧은 수명도 신경써야 합니다.
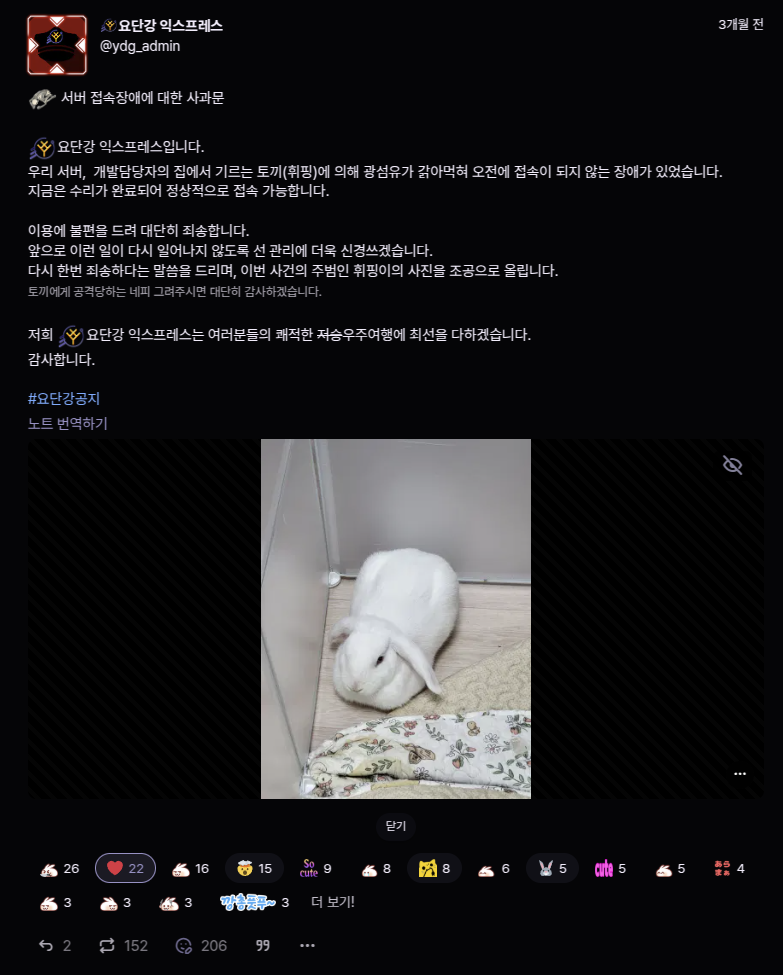
https://yodangang.express/notes/9yrwhfa6ta9o0190
이런 말도 안되는 이유로도 물리장비는 타격을 입을 수 있습니다.
근데 이게 한 번도 아니고 두 번이나 있었다는...
인터넷 비용이랑 전기세 무시하냐?
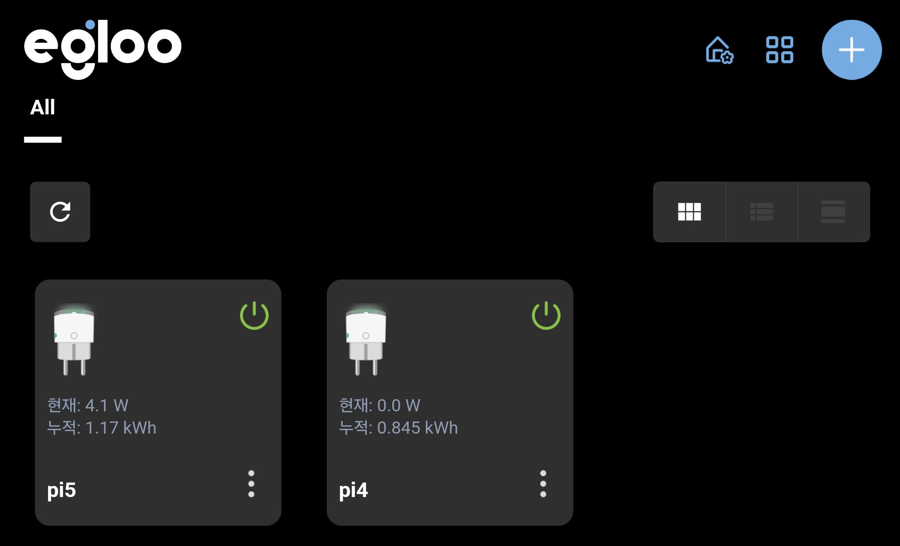
뭐... 인터넷이랑 전기세 안나오냐 하는 사람도 있을텐데
인터넷 안쓰는 사람이 어딨고
라즈베리파이 전기세라 해봤자 한 달에 1kW쯤 쓰는데...
참고로 라즈베리파이는 전부 와이파이 쓰도록 구성되있습니다.
랜선을 CAT.5 사냐 뭐 사냐 고민 할 필요도 없음
ISP는 각각 다른걸 쓰나?
친구들이 집에 무슨 인터넷을 쓰는지는 모릅니다.
(같아도 달라도 상관은 없을 것 같습니다.)
돈을 쓰면 제가 했던 고생을 안해도 됩니다.
앞에 언급한 CoreDNS 이슈같은 일은
클라우드에서 돈을 주고 사용하면 이런 일을 겪지 않아도 됩니다.

제가 굳이 이런 사족을 붙이는 이유는
저는 회사에서 일을 하면서 k8s를 많이 접하는데도
개인 서버를 운영하면서 겪은 이런 부분들을
클라우드에서는 단 한번도 겪어본 적이 없기 때문입니다.
그러니 클라우드의 지출을 감내하실 수 있다면
돈을 주고 클라우드를 쓰는게 훨씬 수월할겁니다.
여러가지 의미에서요.
여기까지 오는데 정말 고생을 많이 했습니다.
위에 언급했던 토끼로 인한 인터넷 단절로 서버 장애도 두 차례나 있었고
정전으로 인해 서비스에 장애가 생겼던 적도 있습니다.
그 외 온갖 사건사고들로 서비스의 장애는 여러차례 있었구요.
2년간 여러가지 시도를 했고
많은 시행착오를 겪었으며
많은 사건사고도 있었죠.
이제는 토끼가 인터넷을 갉아먹어도, 정전이 나도 문제가 없습니다.
전쟁만 안난다면 말이죠.
2년이나 지났지만 서버의 사용자가 많은 편은 아닙니다.
하지만, 2년간의 고생 덕분에 탄탄한 인프라가 구축이 되었고
유저가 늘어난다고 해도 이미 대비가 다 되어있어서
더 뭔가 특별히 해야 할 것도 없습니다.
누군가는 k3s로 클러스터 구성하는걸 보고 낭만 넘친다고 했고
누군가는 허세 아니냐고, 오버테크놀로지라고 비아냥 대기도 했습니다.
하지만 이런 결정들은 낭만도 허세도 아니고,
제가 보유하고 있는 물리장비 중 무엇이 죽더라도
단 하나만 살아남아 있다면
서비스엔 영향이 없이 잘 유지되었으면 해서 내린 결정입니다.
결국은 왠만한 일에는 버틸 수 있는 인프라를 구축하는데 성공했습니다.
아무리 작아도 '서비스' 니까요.

14개의 댓글

좋은 글 감사합니다 ~!! 궁금한 게 있는데 , 혹시 DNS 쪽에서는 livenessProbe 를 해놓은 것인지 알 수 있을까요? 도메인에 대해서 하나의 IP 해놓으면 지정된 IP 에 해당되는 노드가 끊어지면 문제가 발생할 것 같은데 어떤 식으로 구현하셨는 지 궁금하네요.

잘봤습니다~ 구성 재밌네요.
라즈베리 여러개로 구축하는것 까지는 생각해봤는데... 멀리 떨어진 노드끼리 묶는 생각은 안해봤네요.
k8s 버전 업그레이드도 잘되나요?


와 개쩐다....
안그래도 고가용성 아키텍처 인프라를 AWS로 만들다가 한달에 유지비가 150달러로 나오는 대참사가 일어나서 요금 절감 인프라를 만들려고 하는데 참고해도 괜찮을까요?

라즈베리파이를 sd 카드 대신에 usb플래시메모리에 os 설치해서 쓰니 수명이 늘어나고.
라즈에 방열판 달아주니 발열문제는 없어지긴했었던 것 같습니다.
가끔 아파트가 정전되는 것도 패스스루 보조배터리에 전원 연결해서 쓰니까 바꿔서 큰 문제가 없었네요.
근데 😾고양이가 와서 플러그 😽냥냥냠! 하는 건 어케 못막음.<--이게 제일 문제 😭

개인 서버 구축 따로해 봐야겠네요 :) 감사합니다