'대규모 트래픽 경험' 이라는 환상 - 1부

'아무도 나에게 대규모 트래픽을 경험시켜주지 않는다' 라는 말을 누군가 했다는걸 지나가다 어쩌다 주워들었다.
뭘 바라고 한 말일지는 모르겠다. 다만 도움이 될 것이라면 나의 이야기를 들려주고 싶다.
어떤 기대가 있었는지는 모르겠지만, 다 듣고나면 환상이 깨질지도 모르겠다.
목차
서문
주제가 '대규모 트래픽' 이다.
'트래픽' 이라는 말이 들어갔으니 이 글에서 어떤 키워드들이 나올지 먼저 살펴보자면
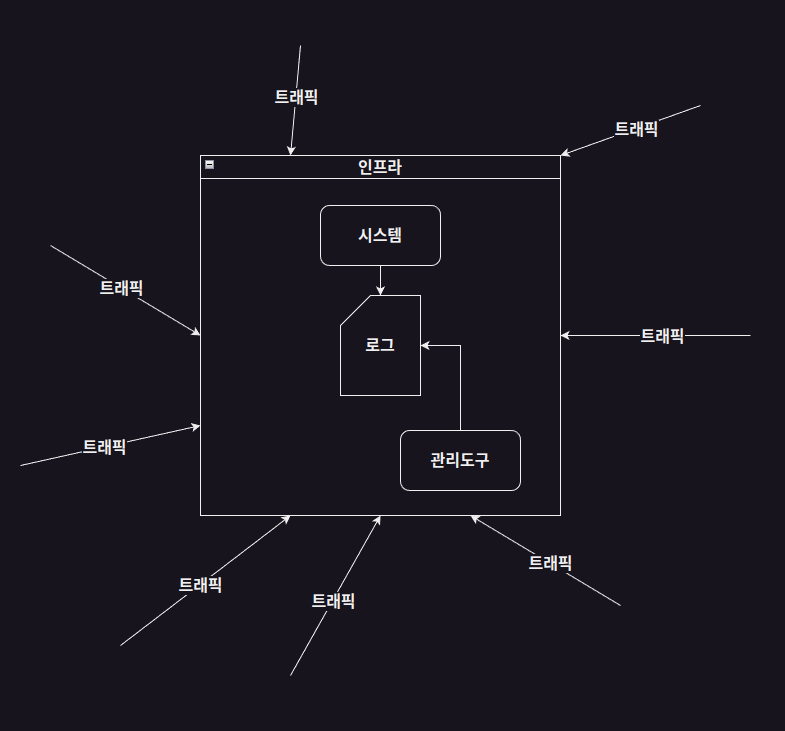
간단히 그림으로 설명하자면 이렇고
키워드를 나열하자면
- 말 그대로, 유저의 트래픽
- 트래픽이 1차적으로 접근하는 인프라
- 인프라가 트래픽을 전달해줄 시스템
- 시스템의 프로세싱으로 발생하는 로그
- 시스템을 수정하고 로그를 검색하는 관리도구
이런 것들이 있을 것이다.
배경
나는 개발자를 처음 하던 당시 이 모든걸 다 겪었다.
2018년 6월 28일 부터 2020년 3월 즈음 까지 였던 것 같다.
(나도 시작부터 지상 최강의 개발자였던 것은 아니었다.)
회사 이름은 따로 언급하지는 않겠다.
(이 글을 읽는 여러분도 알 것 같더라도 댓글에 언급하지 않길 바란다.)
나는 웹 퍼블리셔를 그만두고 개발자로 첫 커리어를 시작했고,
회사는 당시 상장폐지라는 사건이 터져서
300명이 넘던 직원들이 일제히 피난이라도 가듯 도망쳐버려서
제대로 된 인수인계 문서조차 남아있을 틈도 없었던 듯 하다.
나는 그런 일련의 사건 이후에 입사를 했고
제대로 인수인계를 받을 사람도, 문서도 없이
나보다 조금 먼저 정보를 습득한 동료들에게 정보를 공유받는 것이 고작이었다.
내가 맡은 일은 회사의 모든 인프라 관리 및 개발이었다.
하술 할 일들은 순차적으로 일어났다기보단
동시다발적으로, 혹은 연속으로 터져서 하나하나 준비 할 틈이 없었다.
(그리고 신입 개발자가 감당하기에도 꽤나 벅찬 일들이었다)
우리는 항상 야근에 시달렸고...

정시 퇴근을 언제 해봤는지는 기억도 안날 정도로 힘들었지만
그래도 우리들은 우리 회사를 사랑했고, 우리의 일을 사랑했고, 그렇게 고생하는 우리들을 사랑했기에
어떻게든 버텨냈던 것 같다.
회사 바깥의 모든 사람들은 곧 회사가 무너지리라 알고있었지만
의외로 회사는 지금까지도 건재하다.
비록 나는 후세(?)에 지독한 빌런이라고 전승되었다지만
뭐가 어찌되었건 우리들의 고생이 헛되지 않았고,
그 결과로 회사가 지금까지도 건재하다는 사실에 감개무량할 뿐이다.
트래픽
당시에 내가 다녔던 회사는 게임 퍼블리싱사 였다.
- 우리 회사가 개발한 게임을 직접 유통하거나
- 다른 회사가 개발한 게임을 유통해주거나
하는 일을 해서 돈을 버는 회사였다.
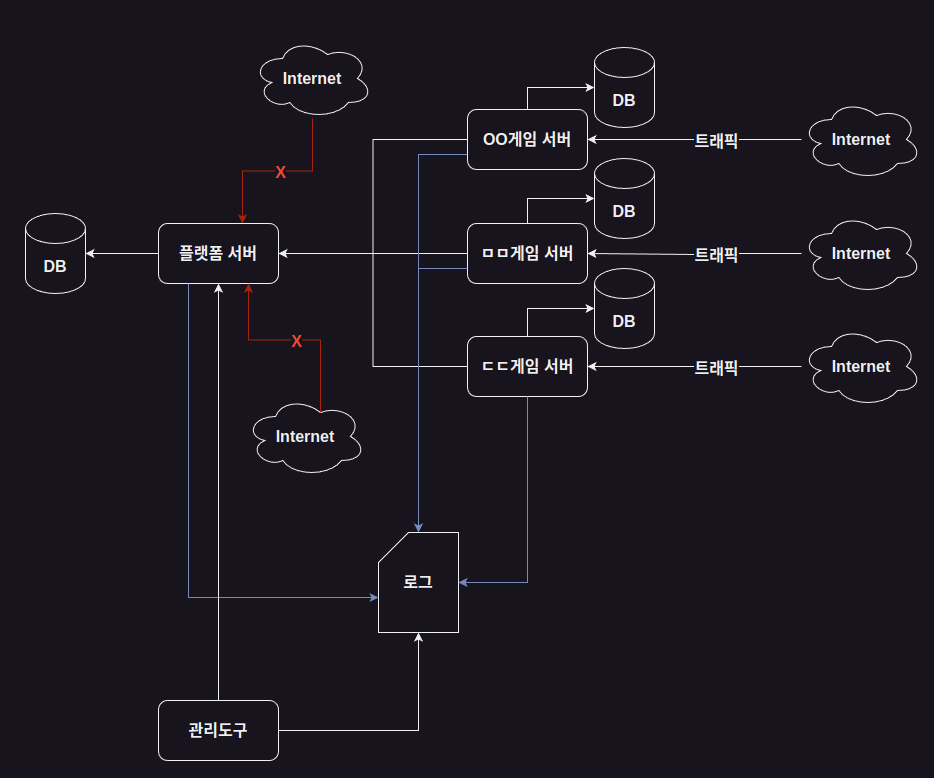
퍼블리싱사이기에 플랫폼 서버를 따로 운용했다.
(나는 플랫폼 개발팀이었다.)
그렇기에 모든 트래픽의 근원은 각각의 게임서버에서 오는 유저들의 트래픽이었고
게임서버가 유저의 트래픽을 견딜 수 있도록 관리해야했고,
게임서버들은 일제히 플랫폼 서버로 요청을 했기에
플랫폼 서버가 트래픽에 견딜 수 있게 관리도 해야했다.
일 접속자와 동접자 상황
당시에 운영하던 게임은 3개였다.
하나는 다른 개발사에서 만든 게임을 퍼블리싱 하는 것이었고,
구글/애플 게임 순위 100위 안에 드는 게임으로 일 접속자가 수만명 수준이었다.
동접은 수천명 정도였던가...
하나는 회사에서 직접 개발했던 게임으로,
구글/애플 게임 순위 150위 안에 드는 게임으로 일 접속자는 만명 전후였던 것으로 기억한다.
동접은 100~700 정도 왔다갔다 했던 것 같다.
나머지 하나는...
그만 알아보도록 하자
이벤트가 열리면...
다만, 내가 입사했던 시기는 기존에 관리하던 사람들도 없고
인수인계 문서도 없기에 어떻게 관리해야 할 지도 모르는 상황이었고,
각각의 게임이 이벤트라도 열리면
평소 수만명이 몰리던 서버에는 수십만명이 몰렸고,
백만명이 넘어갈 때도 종종 있었다.
동접자도 십만명을 넘기기 시작하면
그 트래픽은 약하디 약한 서버를 죽이는데는 부족함이 없었다.

입사 초반에 어떻게 관리해야 하는지 파악하기 전까지는
서버 장애가 굉장히 잦았고, 모든 인프라와 시스템이 삐걱거렸기에
모든 상황은 우리에게 매 순간 포기하도록 종용하는 것 같았다.

하지만 나는 혼자가 아니었기에
동료들과 힘을 합쳐 어떻게든 수많은 역경을 해쳐나갔다.
우리들은 우리들의 회사를 사랑했고, 일을 사랑했고,
그렇게 고생하는 서로를 사랑했기에 말이다.
그것은 개발팀 말고도 운영팀, QA팀과 사업팀 등등의 회사 구성원 모두를 뜻한다.

그래서 당시의 우리는 서버가 터져서 서비스가 중단이 되면
하루, 이틀, 아니 일주일 내내도 퇴근을 못하면서도
겨울에 패딩을 뒤집어쓰고 의자에 웅크려 장애 복구 조치를
교대로 돌아가면서라도 최대한 빨리 서비스를 복구하기 위해 노력을 했었다.
인프라
회사에서는 AWS도 사용했었고,
배어메탈 장비를 IDC에 넣어놓고 운용도 했었다.
IDC에 들어있는 장비는 6년~7년 정도 연식이 있었다.
곧 초등학교에도 보내야 될 정도로
다수의 장비를 Docker Orchestration으로 운용하기 위해
선조(?)들은 IDC에 fleet(deprecated)을 구축도 해놨었다.
(후에 이것은 엄청난 재앙이 되었다)
서버의 증설과 네트워크 접근제어에서 생긴 문제
이벤트가 열렸을 때 터지는건 게임서버 였으므로
게임서버를 증설하려고 처음 시도했을 때 생긴 일이다.
서버를 증설하고나니 게임을 플레이하는 유저들이
랜덤하게 에러를 만나고 있다는 제보가 들어왔었다.
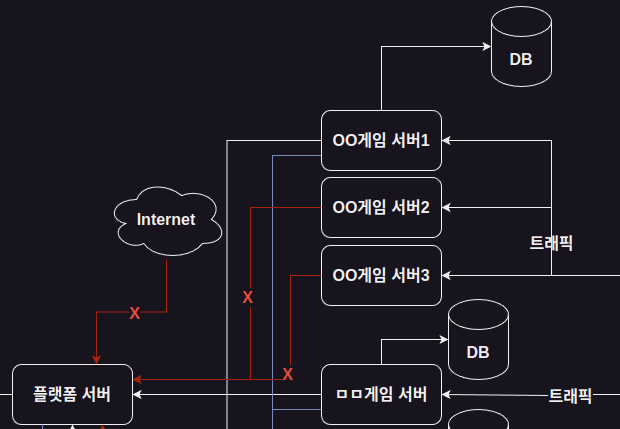
이해하기 쉽게 설명하자면 위와 같은 그림인 상황인데
이 상황까지 이해하는데도 꽤나 애를 먹었다.
우리는 제대로 인수인계 받은게 없었고
(계정과 pem키 말곤 받은게 없다고 할 정도)
플랫폼 서버가 접근제어를 deny all을 기반으로
allow list를 만들어서 운영한다는걸
뒤늦게 깨닫게 되었다.
그리고 지금이라면 게임서버쪽의 outbound 지점을 하나로 묶어서
static IP를 구매하여 public IP를 하나로 만들었을텐데,
당시 경험과 지식이 부족한 우리들은 그런걸 몰랐다.
그래서 이후에 게임서버에 장애가 나서 한동안 꺼져있다가 다시 켰을 때
public IP가 바뀌는 일이라도 생기면
매번 플랫폼 서버의 접근제어를 수정해줘야 했었다.
잘못된 오케스트레이션 구성이 부른 대참사
위에 언급했던 IDC에 배어메탈로 구성한 fleet(deprecated)에 문제가 생겼는데
여러개의 노드 중 하나가 장비 노후화로 죽었다.
보통 이런 경우엔 죽은 노드에서 실행되던 컨테이너가
여유가 있는 다른 노드에 뜨는게 정상적인 동작인데
fleet에 등록 된 모든 컨테이너가 꺼졌다 켜졌다 하는 파도타기를 하기 시작했다...

대체 선조(?)들이 어떻게 설정해서 이리 된건지는 알 수 없으나
아무튼 상황은 그러했다.
IDC로 달려가 배어메탈 장비에 직접 접근해
fleet 연동을 끊고 컨테이너를 수동으로 올려서 조치하려고 했는데
거기서 엄청난 변수를 만나게 됐다.
우리에겐 이 fleet node에 접근할 수 있는 pem키도 없었고
배어메탈 장비에 직접 로그인할 수 있는 계정도, 패스워드도 없었다.
결국 디스크를 뽑아서 다른 서버에 집어넣고 마운트 시켜
필요한 데이터를 복사해서 끄집어낸 뒤에
컨테이너를 수동으로 올리는 것으로 해결했었다.
그 뒤, fleet으로 등록된 모든 배어메탈 장비를 뽑아서 회사에 가져왔는데
쏘카를 빌려서 가져왔는데 트렁크에 실으니 차가 약간 뒤로 눕던...
회사에 가져와서 하나씩 켜보니 참 가관이었다.
켜려고 하니 어딘가 고장이 나서 안켜지는거부터
싹 밀고 클린설치 하려고 하니 디스크에 손상이 가있어서 못쓰는것도 있었고
그런 것들을 전부 뜯고 재조립해서 쓸 수 있는 상태로 만들어서
클린설치 한 뒤에 다시 IDC에 갖다 넣었던 일도 있었다.
시스템
MongoDB 배어메탈 서버에 용량이 가득 찼던 일
MongoDB를 쓰던 게임이 있었는데
1TB SSD가 꼽혀있는 배어메탈 서버 하나를 통으로 쓰고있었다.
이 사건이 터질 때 까지 MongoDB를 쓰는지 모르고 있었다
정확히는 앞의 수많은 사건들에 의해 알 여력이 없었지
처음엔 replication을 만들어 그걸로 어떻게든 해볼 생각이었는데
master node에 전체 용량의 40% 이상의 여유가 있어야 한다는걸 알고 좌절했다.
앞에 언급한 fleet 사건이 터진 직후 생긴 일이라
디스크를 뽑아서 다른데 꼽고 할 용기가 나지 않았었다.
부팅 잘 되던걸 뽑아서 다른데 꼽자마자 손상되서 못읽는 상태가 되는걸 눈으로 봤던 직후이니...
그래서 우리는 rsync로 로컬에 data폴더 전체를 복사해왔다.
아마도 약 6시간쯤 걸렸는데 겨울에 패딩을 뒤집어쓰고 의자에 웅크려
새벽에 교대로 지켜보며 복사하는데 이상이 생기는지 보고있었다.

다 복사가 끝나고나서 안전을 위해 로컬 to 로컬로 하나 더 복사하는데도
한 시간 정도 걸렸던걸로 기억한다.
(짜잘한 용량의 파일이 너무 많아서)
게임이 8주년이던가 되던 게임이다보니
MongoDB도 2.6버전을 쓰고있었는데
2019년인가 당시에도 굉장히 구버전이었던걸로 기억한다.
너무 구버전이라서 더 높은 버전으로 올려보고자 했는데
더 높은 버전에서는 해당 data 폴더를 읽어들이질 못했고
어쩔 수 없이 2.6버전 그대로
10TB짜리 SSD로 데이터를 이전시켜 IDC에 갖다넣는걸로 해결했다.
Redis를 DB처럼 쓰던 시스템에 생긴 참사
Redis Cluster가 나오기 전에 나온 설계라서
codis라는걸 사용한 서버가 있었다.
64GB의 클러스터의 메모리가 꽉차서 게임이 터진 일이 있었는데,
우리는 codis 구성에 대해 전혀 인수인계 받은 바가 없었기에
이 사태가 터질 때 까지 전혀 알 길이 없었다.
그래서 터진 덕에 구조를 다 뜯어보게 됐고
sentinel, proxy, 그리고 나머지 노드의 분배를 위해
3개의 그룹과 여러개의 데이터 노드로 나눈 뒤
128GB로 늘려서 서비스를 다시 복구했다.
글만 보면 간단해보이겠지만
우리는 이 복구를 위해 3일 밤낮을 매달렸다.
하지만 복구를 해냈다고 다 된게 아니었다.
서비스가 죽기 전에 BGSAVE가 끝나지 못한 부분부터 유실이 일어났고
유실이 일어난 부분 외에 손실되고 깨진 데이터들도 존재해서인지

특정 유저들은 길드 정보가 날아갔다던가
인벤토리 정보가 꼬였다던가
이상 현상들이 발생했고
이 부분도 복구하기 위해 굉장히 애썼다.
근본적인 복구는 사실 불가능했고
복구 요청이 오는 유저들을 대상으로
장애 이 전의 상태를 참고해서 되돌려준다던가
아무튼 2달 가까이 굉장히 고생을 했던 기억이다.
이 장애 이후에는
게임의 업데이트를 위해 서버를 잠시 중지시킬 때
Codis 노드 전체의 foreground SAVE 이후
dump.rdb 파일의 백업과
현재 메모리 상태를 체크하는 과정이 추가되었다.
로그
시스템을 운용하면 로그는 필연적으로 쏟아진다.
말 그대로 쏟아진다고 할 수 있다.
엄청난 양의 로그를 보관하고
그 로그를 검색해서 유저의 문의를 처리하거나
오류가 있었는지 판별하기 위해 로그를 확인해야 했으므로
로그는 보관도 중요하고
검색할 수 있는 시스템을 만드는것도 중요했다.
연 3억을 쓰던 Redshift를 없애고 ElasticSearch를 도입한 일
월 3000만원 가까이 지출되던 시스템이었는데 앞에 수 많은 사건사고들이 있었기에
여기까지 눈을 둘 틈이 없었다.
다만 무언가가 터질 때 마다 고치면서 조금씩이나마 보완되었기에
나중에는 꽤나 안정된 운영을 할 수 있었던 순간도 찾아왔다.
그리고 그 쯔음에 경영진들의 요청이 있었다.
지출 비용을 좀 줄일 수 없겠느냐는 그런.

그래서 고민끝에 가장 지출이 컸던 Redshift를 어떻게 해보기로 했다.
게임서버에서 나오는 로그를 전부 저 안에다 집어넣고
쿼리를 이용해 검색하는 시스템이 있었는데
선조(?)들이 처음 구축했던 시기에는 괜찮았을지 모르겠으나
이미 시간이 많이 지난 시점에서는 한 번 검색하는데 6분 ~ 30분 정도 걸리는
고객센터 업무를 하는 동료분들에겐 애물단지였으니 말이다.
돈도 월 3000만원씩 나갔고
결론만 말하자면 데스크탑 한대에 RAM을 꽉 채워넣고
거기에 ElasticSearch를 구축해서 2년치 로그만 검색이 가능한 시스템을
장장 3개월에 걸쳐 구축했다.
비록 검색하는데 7초 ~ 2분 정도 걸렸으나,
기존에 비하면 훨씬 빨랐기에, 조악한 시스템이었지만
고객센터 업무를 하는 분들은 다들 고맙게도 만족해주셨다.
연 지출 3억을 아낀 시점에서만 해도 얼티메이트 위업이긴 한데
한 번 지출을 줄이는데 성공하니, 경영진 입장에서는 "하면 되는구만" 으로 인식했는지
더 줄일 수 있냐고 꾸준히 압박이 들어왔었다.
관리도구
모니터링 도구를 만들 여력이 없어 메신저 알림이라도 만들었던 이야기
그 때의 우리라고 프로메테우스나 그라파나를 몰랐던건 아니다.
그러나 직접 구성하기 위해서는 많은 노력이 들어가야 했고
당장에도 게임 서버는 종종 터졌기에 실시간으로 파악하고 조치가 필요해서
서버가 살아있는지 죽었는지 확인하여 메신저로 발송하는 알림을 만들어서 알림을 받았었다.
전문적으로 인프라만 담당해서 관리 할 사람이 없었기에 어쩔 수 없었다.
그런데 이상하지 않은가? 맨 처음에 내가 이런 언급을 했으니 말이다.

내가 맡은 일은 회사의 모든 인프라 관리 및 개발이었다는데
그런 일을 할 사람이 없었다니?
좀 더 자세히 말하자면
회사에서 근무하던 기간 내내 사건사고를 수습하느라 휩쓸려다녔기 때문에
모니터링 도구라던가, 알림 시스템이라던가 하는 것들을
체계적으로 구축할 수 있는 여유가 없었다고 말하는게 정확할 것 같다.
마치며
대규모 트래픽 경험이라는건 이런 험난한 경험을 뜻하는거라 생각한다.
당시 우리는 경험이 많지 않고 미숙했기에 이런저런 실수를 하며 더 많이 고생하긴 했지만
경험이 많은 지금의 나 라도 대규모 트래픽을 받는 서비스를 담당하면
조금 더 능숙하게 이런저런 일을 당하고 있겠지 하는 생각을 한다.

쉽게 경험할 수 없는 일이기도 하고
그 경험이 쉬운 일이 아닐거라고도 장담할 수 있다.
이력서에 가볍게 한 줄 가볍게 쓸 수 있는 그런 것이 아니라
줄줄이 쓰면서 눈물이 떨어지는 수준의 고생이 뒤따를거라고 말이다.
그리고 눈물을 닦고 한 두줄로 줄여야겠지

그럼에도 그 대규모 트래픽이라는거 경험해보고 싶다면
왠지 퇴근도 못하고 개고생 해야될 것 같은 자리가 생기면
뛰어들어보길 바란다.
그게 회사 내에서의 일이든
그런 이직 자리가 생기든 뭐든 말이다.
P.S
"우리 회사는 체계가 없어" 라고 불평을 하는 사람들을 종종 보는데,
나의 경험에 따르면
체계적이어야 할 곳에 들어가는 전문가들에겐 적응기간따위 따로 없어도
다들 알아서 몇 시간 만에 적응을 마쳐서 몇 개월 있었던 사람처럼 익숙하게 행동을 하고
체계같은건 정해진게 없더라도 알아서들 무언의 약속이 있는듯이 행동한다.
체계가 없다는 말로 내가 무엇을 얻고싶었던건지
다시 생각해보길 바란다.

20개의 댓글





아 재밌다.. 디비에 한글문서 잔뜩 쳐박아놓고 말 안해서 매 요청마다 데이터 잔뜩 넘어오는 바람에 시간은 시간대로 비용은 비용대로 나가던 거 잡아서 aws 운영비 절반으로 줄였더니 두 눈 벌게져서 더 안 되냐고 닥달하던 누군가가 생각나는 군요



The only thing that stands between you and your dream is the will to try and the belief that it is actually possible.


이런 경험하고 면접때 "대규모 트래픽 다뤄보신 적 있으신가요?" 질문 들으면 눈물부터 흐를듯 ㅋㅋㅋㅋ