https://wikibook.co.kr/mymlrev/ 을 읽고 정리한 내용입니다.
4.1 머신러닝 알고리즘 실습 개요
4.1.1 알고리즘 선정
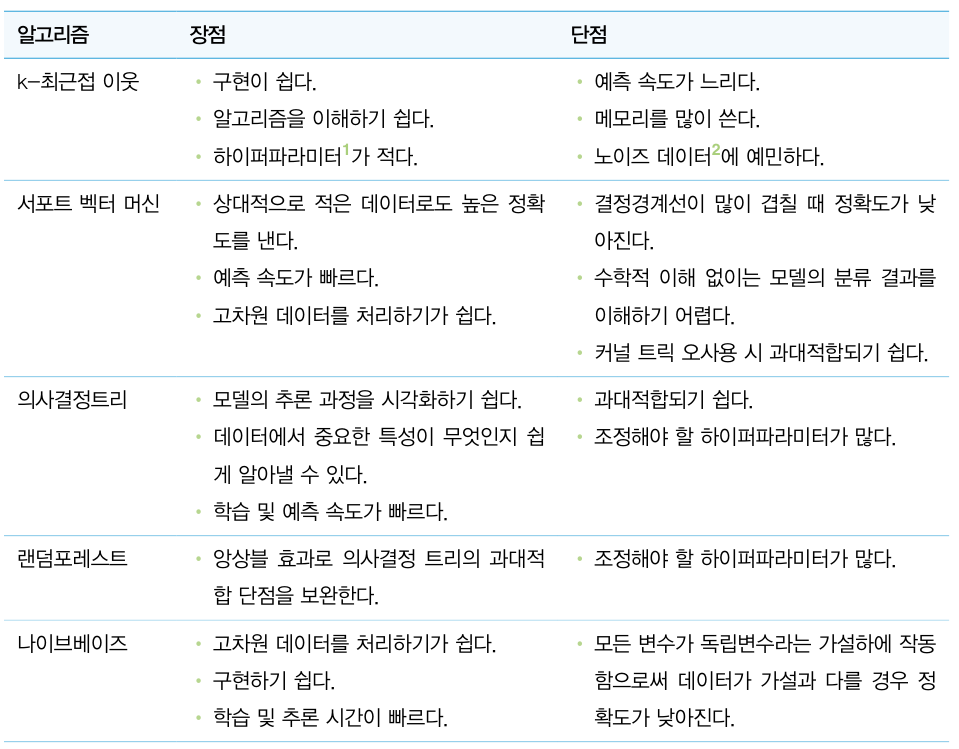
4.2 k-최근접 이웃 (k-Nearest Neighbor, kNN)
데이터 분류에 사용되는 지도학습 알고리즘
1. 정의
-
kNN의 정의
현재 데이터를 특정값으로 분류하기 위해 기존의 데이터 안에서 현재 데이터로부터 가까운 k개의 데이터를 찾아 k개의 레이블 중 가장 많이 분류된 값으로 현재의 데이터를 분류하는 알고리즘k : k 개의 이웃(가까이 존재하는 데이터), 예측을 위해 참조할 데이터 개수 NN : 현재 알고자 하는 데이터로부터 근접한 데이터
-
머신러닝 알고리즘에서의 공간의 개념
- 현실 공간 : 평면 이동 및 수직 이동이 가능한 3차원 공간
- 벡터 공간 : 벡터 연산이 가능한 N차원 공간 => 머신러닝 알고리즘에서 사용
-
'k'의 결정
- kNN 알고리즘은 k에 따라 데이터를 다르게 예측할 수 있음.
- k는 1이 아닌 홀수로 정하는 경우가 많음
- 최적의 k를 찾기 위해서는 검증 데이터를 통해 가장 정확도가 높은 k 를 선정
2. 종류
2.1 이진 분류(binary classification)
두 개의 레이블 중 하나로 분류하는 경우
ex. 악성 코드 분류(일반 파일 vs 악성 코드 파일)
2.2 다중 분류(multiclass classification)
여러 개의 가능한 레이블 중 하나로 분류하는 경우
ex. 임의의 손글씨 숫자를 1~9 중 하나로 분류
3. kNN 알고리즘의 수학적 이해
n차원 벡터 공간에서의 거리계산에 유클리드 거리를 이용

4. kNN 알고리즘의 장단점
4.1 장점
- 이해하기 쉬움
- 수치화된 데이터에 대해서 거리기반 알고리즘인 kNN의 성능이 높음
- 별도의 모델 학습이 필요 없음, 게으른 학습(lazy learning)
4.2 단점
- 예측 속도가 느림
- 예측값이 지역 정보에 편향될 수 있음. k의 개수가 이상치가 이웃으로 존재할 경우 예측값이 틀릴 가능성이 높아짐
5. 실습

데이터 개발자를 꿈꾸는 대학생입니다