Cilium 스터디 - K8S/Cilium Performance
7주차 학습정리 - 대규모 클러스터 성능 최적화
🚀 K8S Performance 개요
1. 쿠버네티스 성능 테스트의 중요성
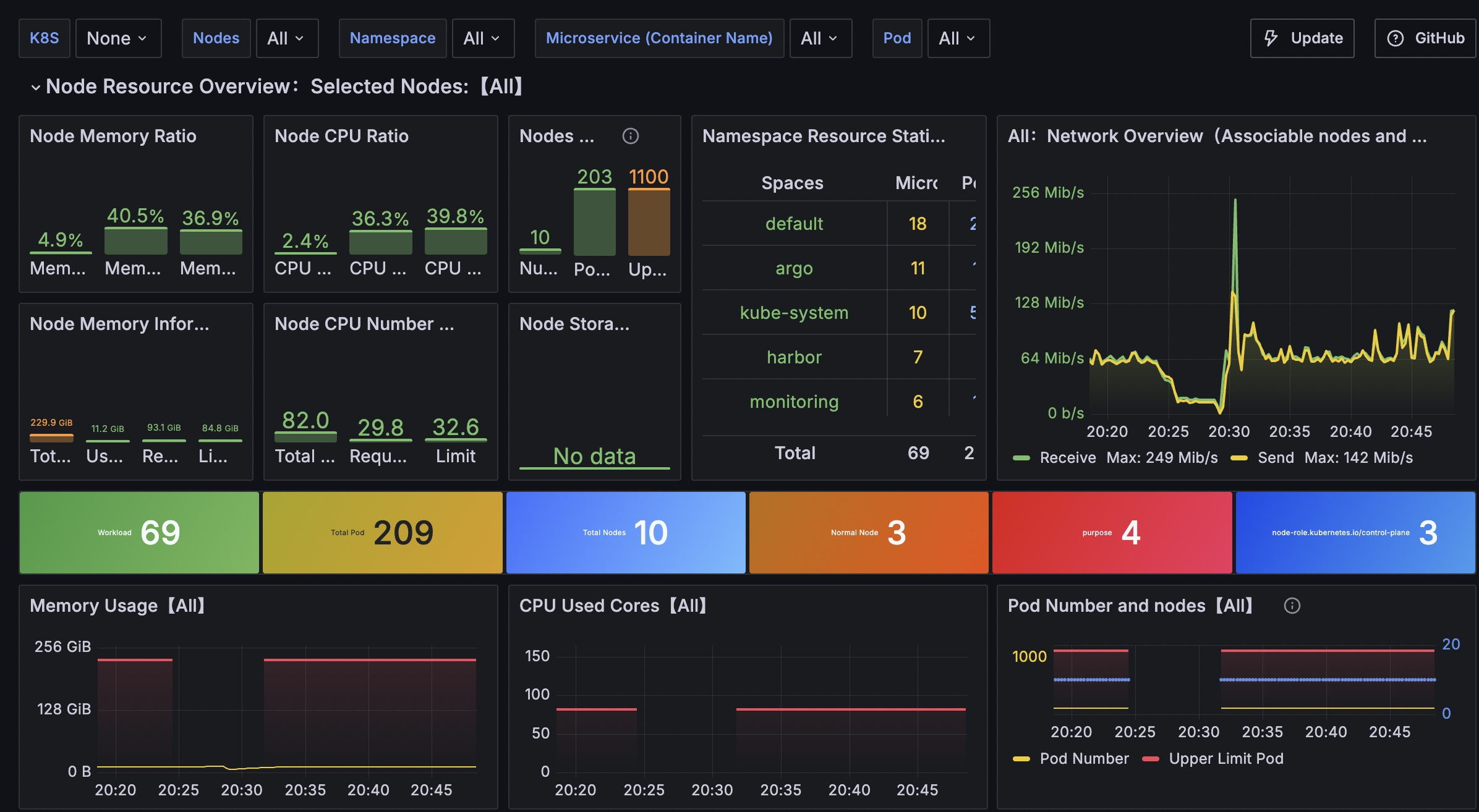
현대의 클라우드 네이티브 환경에서 쿠버네티스 클러스터의 성능은 전체 시스템의 안정성과 효율성을 좌우하는 핵심 요소입니다. 특히 대규모 클러스터 환경에서는 다음과 같은 성능 지표들이 중요합니다:
주요 성능 지표
- RPS (Requests Per Second): API 서버가 처리할 수 있는 초당 요청 수
- Latency: 요청부터 응답까지의 지연 시간
- 리소스 사용률: CPU, 메모리, 네트워크 대역폭 사용량
- 확장성: 노드와 파드 수가 증가할 때의 성능 변화
2. 실습 환경 구성
2.1 Kind K8S 클러스터 배포
실습을 위해 다음 구성요소들을 포함한 Kind 클러스터를 배포합니다:
# Kind 클러스터 생성 (HA Control Plane 3개 노드)
cat <<EOF > kind-config.yaml
kind: Cluster
apiVersion: kind.x-k8s.io/v1alpha4
nodes:
- role: control-plane
- role: control-plane
- role: control-plane
- role: worker
- role: worker
- role: worker
networking:
disableDefaultCNI: true
podSubnet: "10.244.0.0/16"
serviceSubnet: "10.96.0.0/16"
EOF
kind create cluster --config=kind-config.yaml --name=myk8s
# Cilium CNI 설치
cilium install --version v1.17.3
# 모니터링 스택 설치
# kube-ops-view
kubectl apply -f https://raw.githubusercontent.com/hjacobs/kube-ops-view/master/deploy/k8s/deployment.yaml
# metrics-server
kubectl apply -f https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yaml
# kube-prometheus-stack
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
helm repo update
helm install prometheus prometheus-community/kube-prometheus-stack \
--namespace monitoring --create-namespace🔨 Kube-burner: K8S 성능 테스트 도구
1. Kube-burner 소개
Kube-burner는 Golang으로 작성된 쿠버네티스 성능 및 확장성 테스트 오케스트레이션 프레임워크입니다. 주요 기능은 다음과 같습니다:
- 대규모 리소스 생성/삭제: 수천 개의 쿠버네티스 리소스를 빠르게 생성하고 삭제
- Prometheus 메트릭 수집: 테스트 중 시스템 메트릭 자동 수집
- 측정 및 분석: 성능 측정 및 병목 지점 분석
- 알림 시스템: 임계값 초과 시 자동 알림
2. Kube-burner 설치 및 기본 사용법
# Kube-burner 설치 (macOS M1)
curl -LO https://github.com/kube-burner/kube-burner/releases/download/v1.17.3/kube-burner-V1.17.3-darwin-arm64.tar.gz
tar -xvf kube-burner-V1.17.3-darwin-arm64.tar.gz
# Linux
curl -LO https://github.com/kube-burner/kube-burner/releases/download/v1.17.3/kube-burner-V1.17.3-linux-x86_64.tar.gz
tar -xvf kube-burner-V1.17.3-linux-x86_64.tar.gz
sudo cp kube-burner /usr/local/bin
# 버전 확인
kube-burner version
# Version: 1.17.33. 성능 테스트 시나리오
3.1 시나리오 1: 기본 Deployment 생성/삭제 테스트

설정 파일 생성
# s1-config.yaml - 기본 설정
cat << EOF > s1-config.yaml
global:
measurements:
- name: none
jobs:
- name: create-deployments
jobType: create
jobIterations: 1 # job 반복 횟수
qps: 1 # 초당 최대 요청 수 (평균 속도 제한)
burst: 1 # 순간적으로 처리 가능한 요청 최대치
namespace: kube-burner-test
namespaceLabels: {kube-burner-job: delete-me}
waitWhenFinished: true
verifyObjects: false
preLoadImages: true
preLoadPeriod: 30s
objects:
- objectTemplate: s1-deployment.yaml
replicas: 1
EOF
# s1-deployment.yaml - Deployment 템플릿
cat << EOF > s1-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: deployment-{{ .Iteration}}-{{.Replica}}
labels:
app: test-{{ .Iteration }}-{{.Replica}}
kube-burner-job: delete-me
spec:
replicas: 1
selector:
matchLabels:
app: test-{{ .Iteration}}-{{.Replica}}
template:
metadata:
labels:
app: test-{{ .Iteration}}-{{.Replica}}
spec:
containers:
- name: nginx
image: nginx:alpine
ports:
- containerPort: 80
EOF테스트 실행 및 모니터링
# 모니터링 (별도 터미널)
watch -d kubectl get ns,pod -A
# 부하 발생 실행
kube-burner init -c s1-config.yaml --log-level debug
# 생성된 리소스 확인
kubectl get deploy -A -l kube-burner-job=delete-me
kubectl get pod -A -l kube-burner-job=delete-me
kubectl get ns -l kube-burner-job=delete-me
# 로그 확인
ls kube-burner-*.log
cat kube-burner-*.logQPS와 Burst 이해하기
- QPS (Queries Per Second): 평균 속도 제한. 초당 처리할 수 있는 최대 요청 수
- Burst: 순간적으로 처리 가능한 최대 요청 수 (버퍼 역할)
다양한 설정값으로 테스트:
# 실험 1: preLoadImages 비활성화
# preLoadImages: false로 변경 후 실행
# → 이미지 다운로드 시간이 추가되어 전체 실행 시간 증가
# 실험 2: jobIterations 증가
# jobIterations: 5로 변경
# → 5개의 deployment가 순차적으로 생성됨
# 실험 3: replicas 증가
# objects.replicas: 2로 변경
# → 각 iteration마다 2개의 deployment 생성
# 실험 4: QPS/Burst 조정
# qps: 10, burst: 10으로 변경
# → 더 빠른 속도로 리소스 생성
# 실험 5: 대규모 생성
# jobIterations: 100, qps: 300, burst: 300
# → 100개의 deployment를 고속으로 생성리소스 삭제
# 삭제 설정 파일
cat << EOF > s1-config-delete.yaml
jobs:
- name: delete-deployments-namespace
qps: 500
burst: 500
namespace: kube-burner-test
jobType: delete
waitWhenFinished: true
objects:
- kind: Deployment
labelSelector: {kube-burner-job: delete-me}
apiVersion: apps/v1
- kind: Namespace
labelSelector: {kube-burner-job: delete-me}
EOF
# 삭제 실행
kube-burner init -c s1-config-delete.yaml --log-level debug3.2 시나리오 2: 노드당 최대 파드 한계 테스트 (150개)
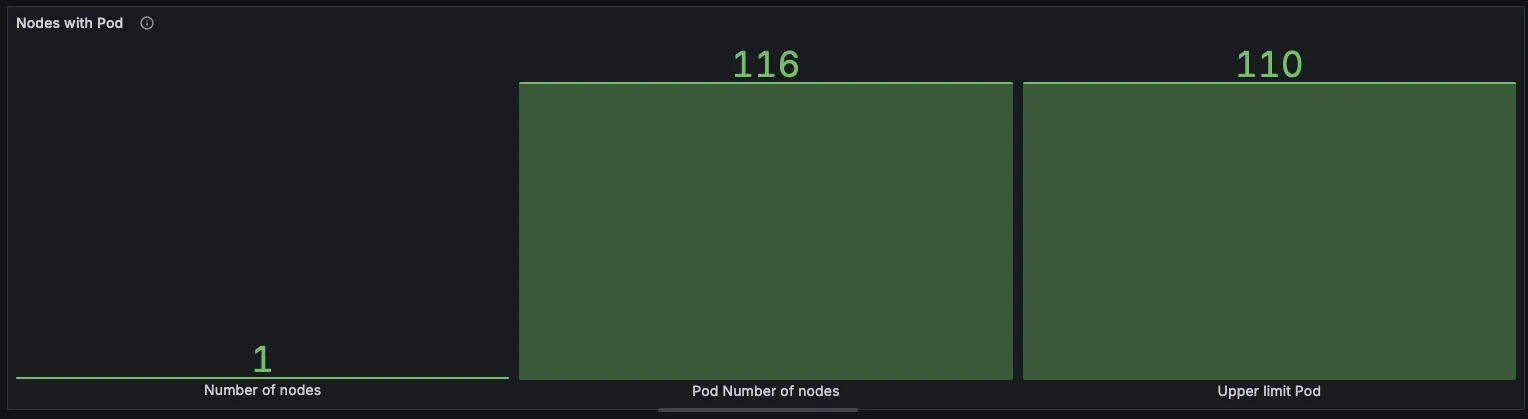
# 100개 파드 생성 시도
jobIterations: 100, qps: 300, burst: 300, objects.replicas: 1
# 실행
kube-burner init -c s1-config.yaml --log-level debug
# 문제 확인
kubectl get pod -A | grep -v '1/1 Running'
kubectl describe pod -n kube-burner-test-99 | grep Events: -A5
# 노드 정보 확인
kubectl describe node
# Capacity와 Allocatable의 pods 항목 확인
# 기본값: 110개문제 해결: maxPods 증가
# Kind 노드에 접속
docker exec -it myk8s-control-plane bash
# kubelet 설정 수정
cat /var/lib/kubelet/config.yaml
vim /var/lib/kubelet/config.yaml
# maxPods: 150 추가
# kubelet 재시작
systemctl restart kubelet
systemctl status kubelet
exit
# 변경 확인
kubectl describe node
# Capacity:
# pods: 150
# Allocatable:
# pods: 1503.3 시나리오 3: Pod CIDR 한계 테스트 (300개)
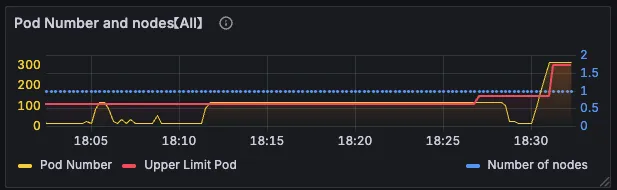
# 300개 파드 생성 시도
jobIterations: 300, qps: 300, burst: 300, objects.replicas: 1
# maxPods를 400으로 증가
docker exec -it myk8s-control-plane bash
vim /var/lib/kubelet/config.yaml
# maxPods: 400
systemctl restart kubelet
exit
# 실행
kube-burner init -c s1-config.yaml --log-level debug
# 문제 발생
kubectl describe pod -n kube-burner-test-250 | grep Events: -A5
# Warning FailedCreatePodSandBox: failed to allocate for range 0:
# no IP addresses available in range set: 10.244.0.1-10.244.0.254
# Pod CIDR 확인
kubectl describe node myk8s-control-plane | grep -i podcidr
# PodCIDR: 10.244.0.0/24문제 원인
/24서브넷은 최대 254개의 IP 주소만 제공- 노드당 할당된 Pod CIDR 범위 초과
📊 K8S Performance & Tuning
1. 대규모 클러스터 고려사항
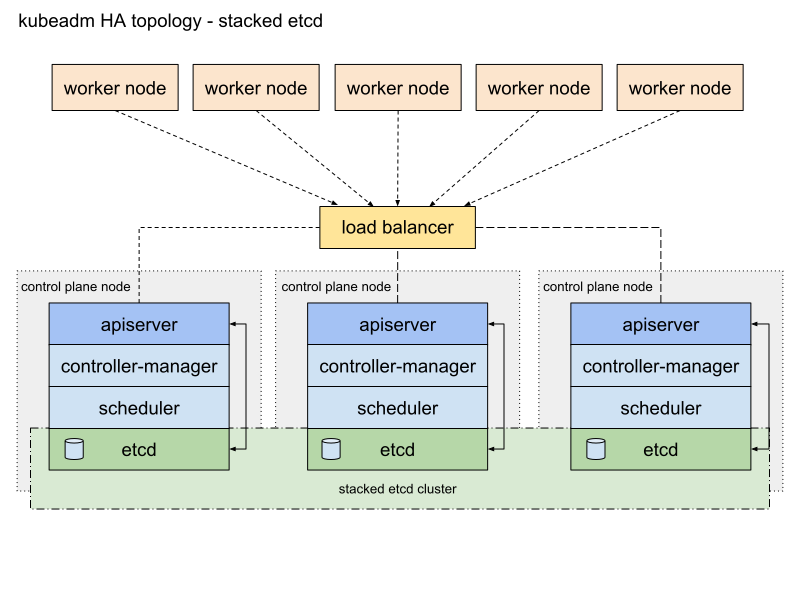
1.1 K8S v1.33 최대 수용 규모
공식 지원 한계
- 5,000개 이하의 노드: 단일 클러스터 최대 노드 수
- 노드당 110개 이하의 파드: 기본 maxPods 설정
- 총 150,000개 이하의 파드: 클러스터 전체 파드 수
- 총 300,000개 이하의 컨테이너: 모든 컨테이너 합계
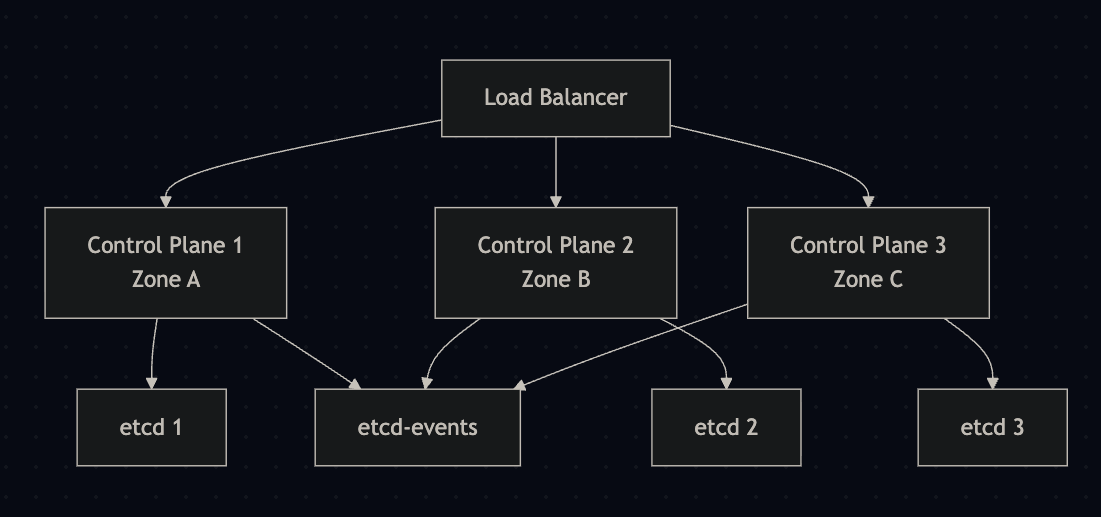
1.2 Control Plane 고려사항
권장 구성
- Failure Zone별 배치: 각 Rack에 1-2개의 Control Plane 노드 배치
- 로드밸런서 구성: Control Plane 앞단에 하드웨어 로드밸런서 배치
- etcd 분리: 이벤트 객체를 별도의 etcd 인스턴스에 저장
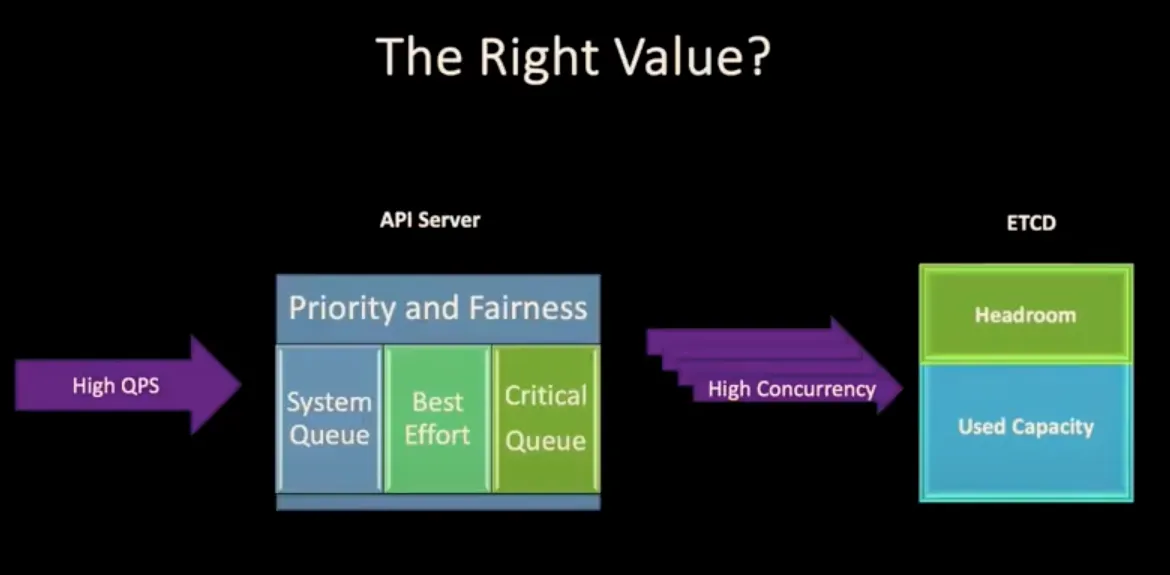
2. K8S API Server 성능 분석
2.1 API Server 요청 처리 과정
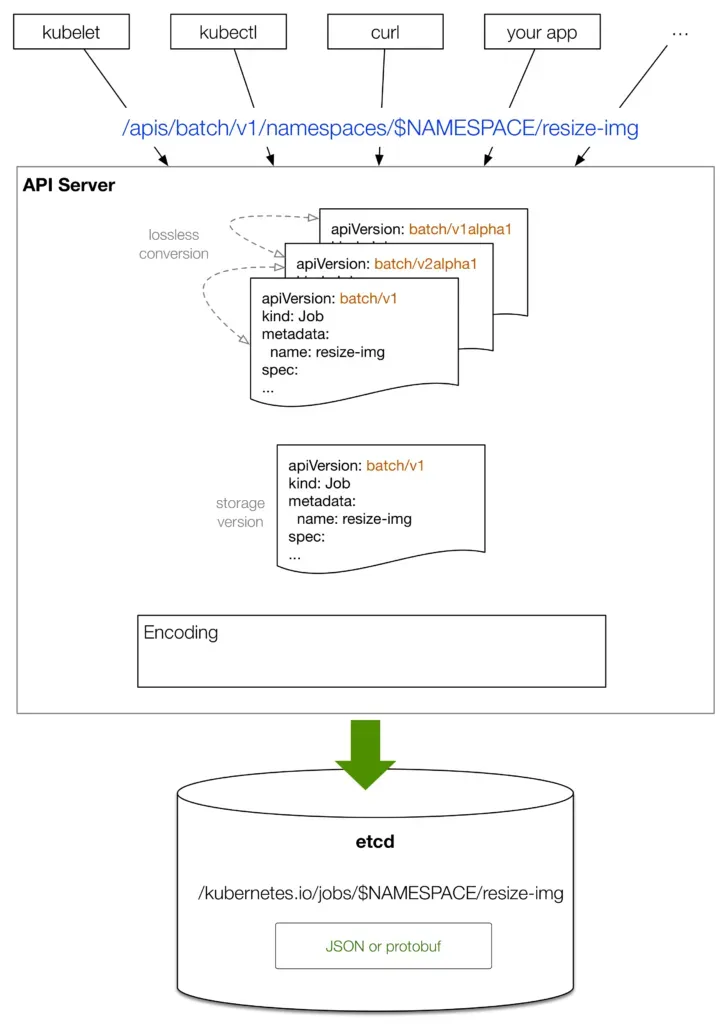
파드 조회 시 메모리 사용 패턴
# 100개 파드 조회
curl -o /dev/null -s -w 'Total: %{time_total}s\n' 127.0.0.1:8001/api/v1/pods?limit=100
# Total: 0.031002s (31ms)
# 10,000개 파드 조회
curl -o /dev/null -s -w 'Total: %{time_total}s\n' 127.0.0.1:8001/api/v1/pods?limit=10000
# Total: 2.131027s (2,131ms) - 100개 대비 약 70배
# 응답 크기
# 100개: 0.45MB
# 10,000개: 44.4MB메모리 사용량 급증 문제
# etcd 메모리 사용 패턴
# 요청당 30-60MB 메모리 필요
# 10,000개 Pod 조회 시 약 35MB (Protobuf 저장 크기와 유사)
# kube-apiserver 메모리 사용 패턴
# 요청당 100MB 내외 메모리 필요
# JSON 변환 과정에서 추가 메모리 소비
# 다운로드 크기(44.4MB)의 약 2.5배2.2 동시 요청 시 OOM 문제
문제 시나리오
# 100개 동시 요청 테스트
ab -c 100 -n 100 127.0.0.1:8001/api/v1/pods
# 결과
# kube-apiserver: 1GB → 6GB (30초 내) → OOM Killed
# etcd: 200MB → 6GB → GC 후 327MB로 감소발생 조건
1. 한 번에 조회 가능한 리소스 개수가 매우 많음
2. 해당 리소스를 조회하는 요청이 매우 많음
주요 발생 사례
- 비활성화된 Pod이 많고 노드 개수가 많은 환경
- Airflow, Kubeflow 등에서 완료된 Job Pod을 삭제하지 않는 경우
- kubelet, kube-proxy, CNI agent 등이 동시에 재연결 시도
3. 성능 최적화 방안
3.1 API 관점 해결법
1) Limit & Continue 활용
# kubectl이 실제로 사용하는 방식
kubectl get po -v6
# GET https://127.0.0.1:6443/api/v1/namespaces/default/pods?limit=500
# 이후 continue 토큰으로 페이징 처리2) ResourceVersion & ResourceVersionMatch
# etcd 부하 감소를 위한 캐시 활용
# resourceVersion="0"으로 요청 시 kube-apiserver 캐시에서 응답
curl 127.0.0.1:8001/api/v1/pods?resourceVersion=0
# 결과: etcd는 영향받지 않음
# etcd: 164MB 유지
# kube-apiserver: 여전히 OOM 가능3) API Priority and Fairness (APF)
# FlowSchema 정의
apiVersion: flowcontrol.apiserver.k8s.io/v1beta3
kind: FlowSchema
metadata:
name: cilium-pods
spec:
distinguisherMethod:
type: ByUser
matchingPrecedence: 1000
priorityLevelConfiguration:
name: cilium-pods
rules:
- resourceRules:
- apiGroups:
- "cilium.io"
clusterScope: true
namespaces:
- "*"
resources:
- "*"
verbs:
- "list"
subjects:
- group:
name: system:serviceaccounts:d8-cni-cilium
kind: Group
---
# PriorityLevelConfiguration 정의
apiVersion: flowcontrol.apiserver.k8s.io/v1beta3
kind: PriorityLevelConfiguration
metadata:
name: cilium-pods
spec:
type: Limited
limited:
nominalConcurrencyShares: 5
limitResponse:
queuing:
handSize: 4
queueLengthLimit: 50
queues: 16
type: Queue3.2 운영 관점 해결법
불필요한 리소스 정리
- 완료된 Job/Pod 자동 삭제 설정
- TTL Controller 활용
- 정기적인 리소스 정리 스크립트 운영
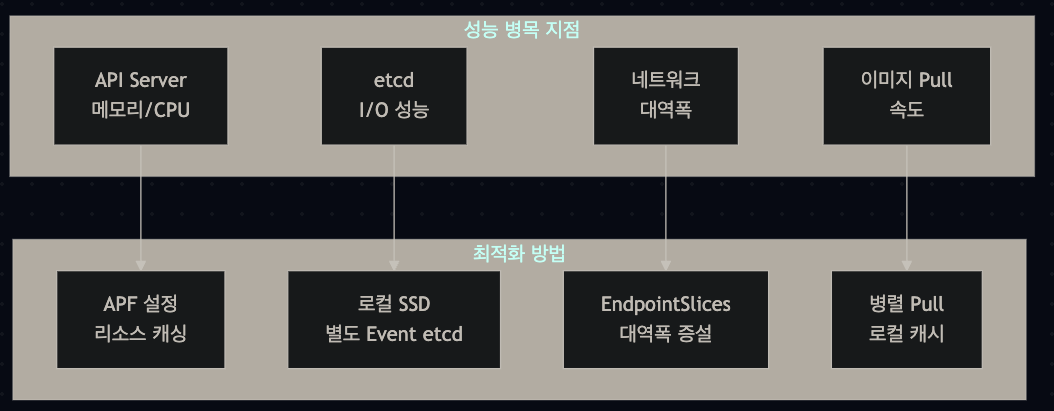
4. 실제 대규모 클러스터 운영 사례
4.1 OpenAI 사례: 2,500 → 7,500 노드
주요 이슈 및 해결
1) etcd 성능 문제 (500노드)
- 문제: kubectl 사용 시 잦은 timeout 발생
- 원인: etcd 쓰기 작업에서 수백 ms spike
- 해결: 네트워크 스토리지 → 로컬 SSD로 이전
- 결과: 지연 200us 감소, 1000노드까지 안정 운영
2) API 서버 과부하 (1000노드)
- 문제: etcd 높은 지연 시간 재발생
- 원인: kube-apiserver가 etcd로부터 500MB/s 이상 읽기
- 분석: Fluentd, Datadog이 모든 노드에서 API 질의
- 해결:
- 에이전트들의 API 질의 빈도 감소
- Event API를 별도 etcd 클러스터로 분리
- API 서버 10대로 확장
3) 도커 이미지 Pull 문제
- 문제: 17GB 게임 이미지 다운로드 시 다른 파드 영향
- 해결:
# kubelet 설정 변경 --serialize-image-pulls=false # 병렬 이미지 풀 활성화 --image-pull-progress-deadline=30m # 기본 1분 → 30분 - 추가: Docker root 디렉터리를 로컬 SSD로 이전
4) ARP Cache 고갈
-
문제:
neighbor table overflow에러 발생 -
해결: 커널 파라미터 조정
# /etc/sysctl.conf net.ipv4.neigh.default.gc_thresh1 = 80000 # Soft GC 시작 net.ipv4.neigh.default.gc_thresh2 = 90000 # 적극적 GC net.ipv4.neigh.default.gc_thresh3 = 100000 # 절대 최대치 # 적용 sysctl -w net.ipv4.neigh.default.gc_thresh1=80000 sysctl -w net.ipv4.neigh.default.gc_thresh2=90000 sysctl -w net.ipv4.neigh.default.gc_thresh3=100000
4.2 7,500 노드 운영 시 추가 최적화
API Server 최적화
- 전용 노드에서 실행 (5개 API 서버, 5개 etcd)
- 노드당 70GB 힙 메모리 사용
- 네트워크 대역폭: 평균 1GB/s 필요
- EndpointSlices 도입으로 부하 1/1000 감소
5. 성능 모니터링 메트릭
5.1 API Server 메트릭
[사진] - API Server 주요 메트릭 대시보드
QPS (Queries Per Second) 모니터링
# API 서버 QPS by 리소스/동사/응답코드
sum by(resource, verb, code) (
rate(apiserver_request_total{job="apiserver"}[5m])
)
# 상위 3개 리소스별 QPS
topk(3, sum by(resource) (
rate(apiserver_request_total{resource=~".+"}[5m])
))
# 4xx, 5xx 오류율
sum by(code) (
rate(apiserver_request_total{code=~"[45].."}[1m])
)
# 읽기 요청 성공률
sum(rate(apiserver_request_total{code=~"20.*",verb=~"GET|LIST"}[5m]))
/
sum(rate(apiserver_request_total{verb=~"GET|LIST"}[5m]))
# 쓰기 요청 성공률
sum(rate(apiserver_request_total{code=~"20.*",verb!~"GET|LIST|WATCH|CONNECT"}[5m]))
/
sum(rate(apiserver_request_total{verb!~"GET|LIST|WATCH|CONNECT"}[5m]))요청 지연시간 분석
# P90 지연시간 by 동사
histogram_quantile(0.90,
sum(rate(apiserver_request_duration_seconds_bucket[5m])) by (verb, le)
)
# 가장 느린 요청들
sort_desc(
histogram_quantile(0.99,
sum(rate(apiserver_request_duration_seconds_bucket[5m])) by (verb, le)
)
)
# Admission Controller 지연시간
histogram_quantile(0.99,
sum by(le, name, operation, rejected, type) (
rate(apiserver_admission_controller_admission_duration_seconds_bucket{type="admit"}[5m])
)
)
# CPU 사용량
irate(process_cpu_seconds_total{job=~"apiserver|kube-controller-manager|kube-scheduler|kube-etcd"}[1m])5.2 etcd와 API Server 간 메트릭
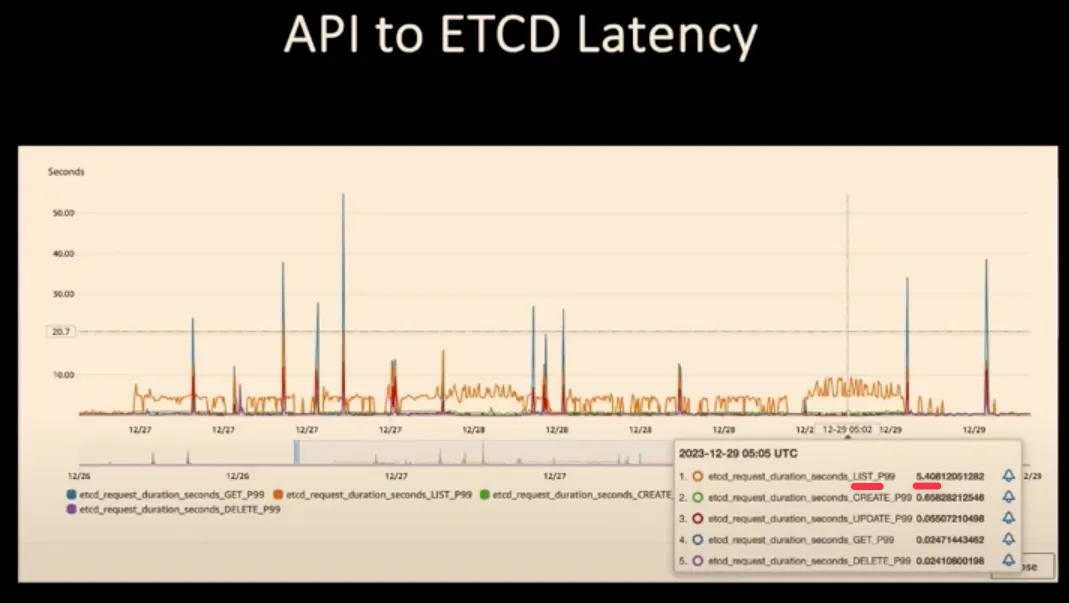
# etcd 요청 지연시간 by 작업 타입
histogram_quantile(0.99,
sum by(le, operation, type) (
rate(etcd_request_duration_seconds_bucket[1m])
)
)
# etcd 요청 증가율
sum by(operation, type) (
increase(etcd_request_duration_seconds_count[1m])
)5.3 클라이언트 관점 메트릭
# 클라이언트 관점 API 요청 지연시간
histogram_quantile(0.99,
sum by(le, service, verb) (
rate(rest_client_request_duration_seconds_bucket{job=~"kube-controller-manager|kube-scheduler|kubelet"}[1m])
)
)
# 클라이언트별 QPS
sum by(method, container, code) (
rate(rest_client_requests_total{job=~"kube-controller-manager|kube-scheduler|kubelet"}[1m])
)5.4 Work Queue 메트릭
# Work Queue 추가율
sum by(name) (
rate(workqueue_adds_total{job=~"apiserver|kube-controller-manager|scheduler|kubelet",
name=~"garbage_collector_graph_changes|admission_quota_controller|endpoint|
endpoint_slice|endpoint_slice_mirroring|deployment|replicaset|
AvailableConditionController"}[1m])
)
# Work Queue 지연시간
histogram_quantile(0.99,
sum by(name, le) (
rate(workqueue_queue_duration_seconds_bucket{job=~"kube-controller-manager",
name=~"deployment|replicaset|endpoint|endpoint_slice|endpoint_slice_mirroring"}[5m])
)
)
# Work Queue 깊이
workqueue_depth{job="kube-controller-manager"}6. K8S 성능 최적화 권장사항
🌐 Cilium Performance
1. 네트워크 성능 측정
1.1 iperf3를 통한 대역폭 테스트
iperf3 서버/클라이언트 배포
# iperf3 서버 및 클라이언트 배포
cat <<EOF | kubectl apply -f -
apiVersion: apps/v1
kind: Deployment
metadata:
name: iperf3-server
spec:
selector:
matchLabels:
app: iperf3-server
replicas: 1
template:
metadata:
labels:
app: iperf3-server
spec:
containers:
- name: iperf3-server
image: networkstatic/iperf3
args: ["-s"]
ports:
- containerPort: 5201
---
apiVersion: v1
kind: Service
metadata:
name: iperf3-server
spec:
selector:
app: iperf3-server
ports:
- name: tcp-service
protocol: TCP
port: 5201
targetPort: 5201
- name: udp-service
protocol: UDP
port: 5201
targetPort: 5201
type: ClusterIP
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: iperf3-client
spec:
selector:
matchLabels:
app: iperf3-client
replicas: 1
template:
metadata:
labels:
app: iperf3-client
spec:
containers:
- name: iperf3-client
image: networkstatic/iperf3
command: ["sleep"]
args: ["infinity"]
EOF
# 파드 배포 확인
kubectl get deploy,svc,pod -owide
# 서버 로그 확인
kubectl logs -l app=iperf3-server -f성능 테스트 시나리오
# 1. TCP 기본 테스트 (5초)
kubectl exec -it deploy/iperf3-client -- iperf3 -c iperf3-server -t 5
# 2. UDP 테스트 (20Gbps 대역폭)
kubectl exec -it deploy/iperf3-client -- iperf3 -c iperf3-server -u -b 20G
# 3. 양방향 테스트
kubectl exec -it deploy/iperf3-client -- iperf3 -c iperf3-server -t 5 --bidir
# 결과 예시:
# Client→Server TX: 53.6 Gbps
# Server→Client RX: 39.9 Gbps
# Retransmit: TX=11, RX=14
# 4. 다중 스트림 테스트 (2개 병렬)
kubectl exec -it deploy/iperf3-client -- iperf3 -c iperf3-server -t 10 -P 2
# 리소스 정리
kubectl delete deploy iperf3-server iperf3-client && kubectl delete svc iperf3-server2. Cilium Connectivity Test
2.1 기능 검증 테스트
# Connectivity test 실행
cilium connectivity test --debug
# 테스트 항목 (총 122개)
# - no-policies: 정책 없는 상태에서의 연결성
# - allow-all-except-world: 외부 차단 정책
# - client-ingress: 인그레스 정책
# - all-egress-deny: 이그레스 거부 정책
# - host-firewall: 호스트 방화벽
# - l7-policy: L7 정책
# - pod-to-pod-encryption: 암호화 통신
# - dns-policies: DNS 정책
# 특정 테스트만 실행
cilium connectivity test --test="no-policies,client-ingress"
# 테스트 네임스페이스 정리
kubectl delete ns cilium-test-12.2 성능 측정 테스트
# 성능 테스트 플래그
cilium connectivity perf -h
# 주요 옵션:
# --duration: 테스트 지속 시간 (기본 10s)
# --samples: 테스트 반복 횟수 (기본 1)
# --streams: 병렬 스트림 수 (기본 4)
# --msg-size: UDP 메시지 크기 (기본 1024)
# 기본 성능 테스트
cilium connectivity perf
# 확장 성능 테스트
cilium connectivity perf \
--duration 30s \
--samples 3 \
--streams 8 \
--other-node \
--pod-net \
--host-net3. Cilium 성능 최적화
3.1 BPF Map 크기 최적화
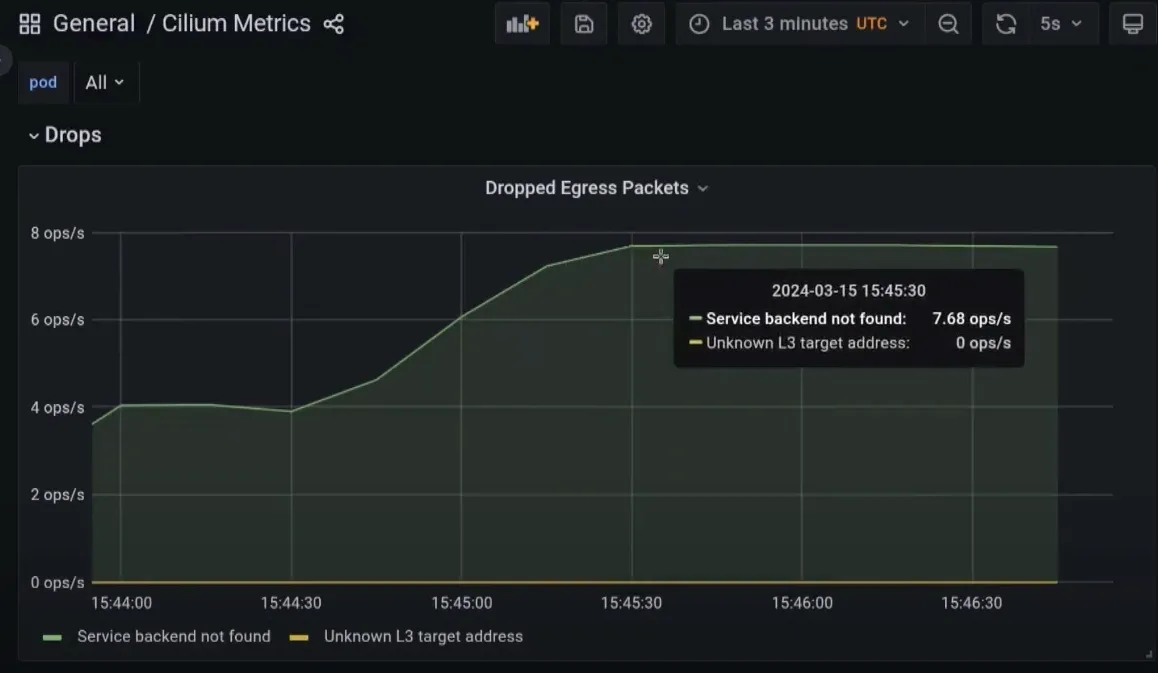
문제 상황 예시
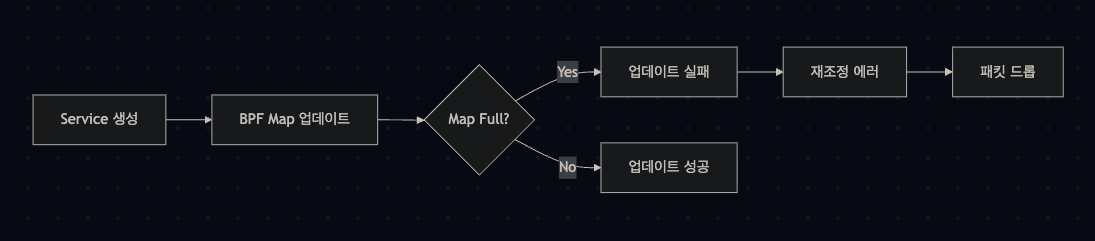
BPF Map 상태 확인
# Cilium 상태 상세 확인
kubectl exec -it -n kube-system ds/cilium -- cilium status --verbose
# BPF Map 압력 확인
kubectl exec -it -n kube-system ds/cilium -- cilium bpf metrics list
# Service Map 상태 확인
kubectl exec -it -n kube-system ds/cilium -- cilium statedb service4
# Map 크기 확인
kubectl exec -it -n kube-system ds/cilium -- cilium bpf map listBPF Map 크기 조정
# Helm 값 업데이트
helm upgrade cilium cilium/cilium \
--namespace kube-system \
--reuse-values \
--set bpf.mapDynamicSizeRatio=0.005 \
--set bpf.lbMapMax=65536 \
--set bpf.natMax=524288 \
--set bpf.neighMax=524288 \
--set bpf.policyMapMax=163843.2 Cilium 메트릭 분석
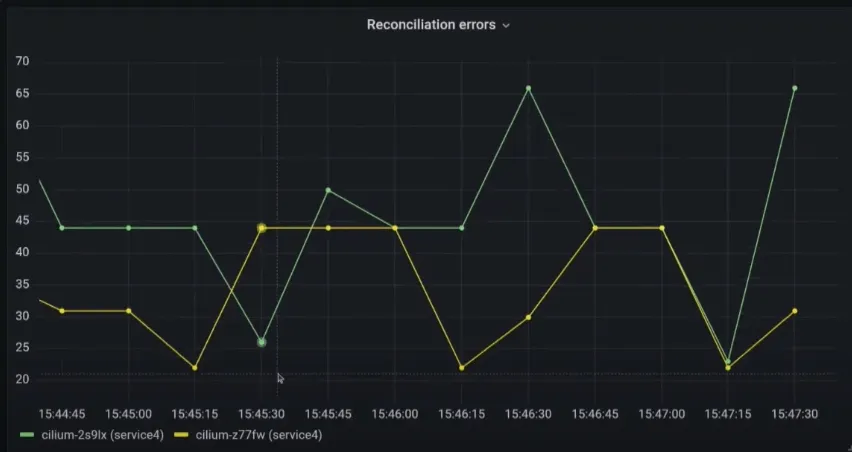
주요 모니터링 메트릭
# BPF Map 작업 수
topk(5, avg(rate(cilium_bpf_map_ops_total{k8s_app="cilium"}[5m])) by (pod, map_name, operation))
# BPF Map 압력
cilium_bpf_map_pressure{k8s_app="cilium"}
# 엔드포인트 재생성
rate(cilium_endpoint_regenerations_total[5m])
# 데이터플레인 에러
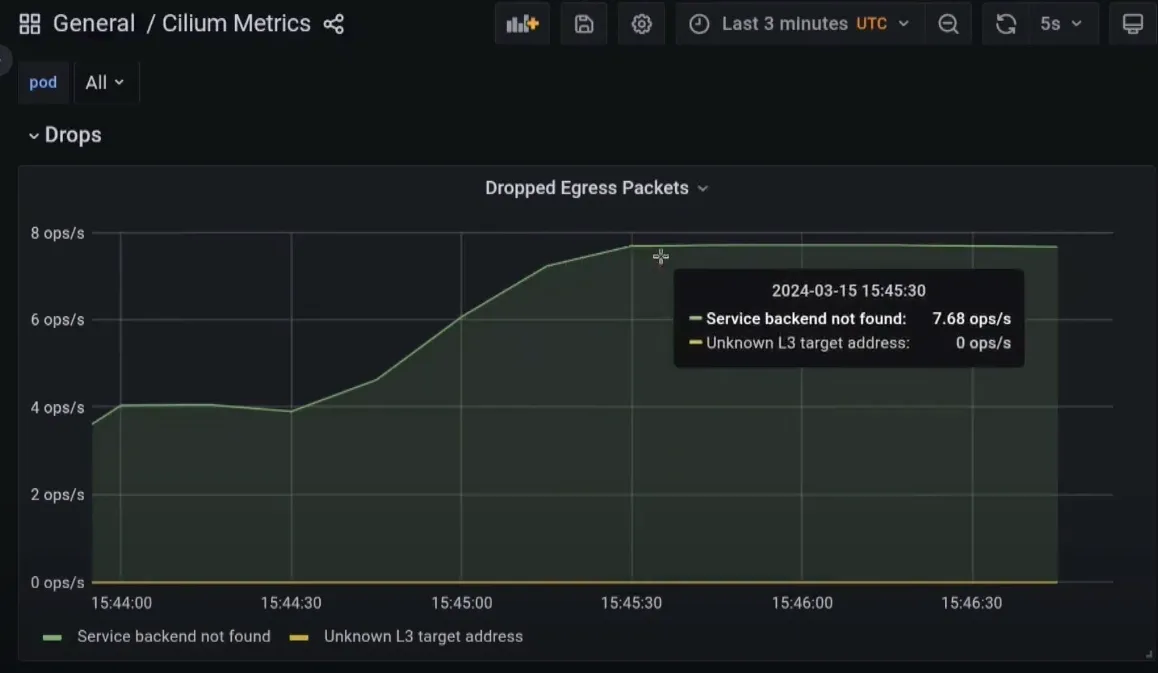
rate(cilium_datapath_errors_total[5m])
# 드롭된 패킷
rate(cilium_drop_total[5m])4. StateDB와 Reconciler 아키텍처
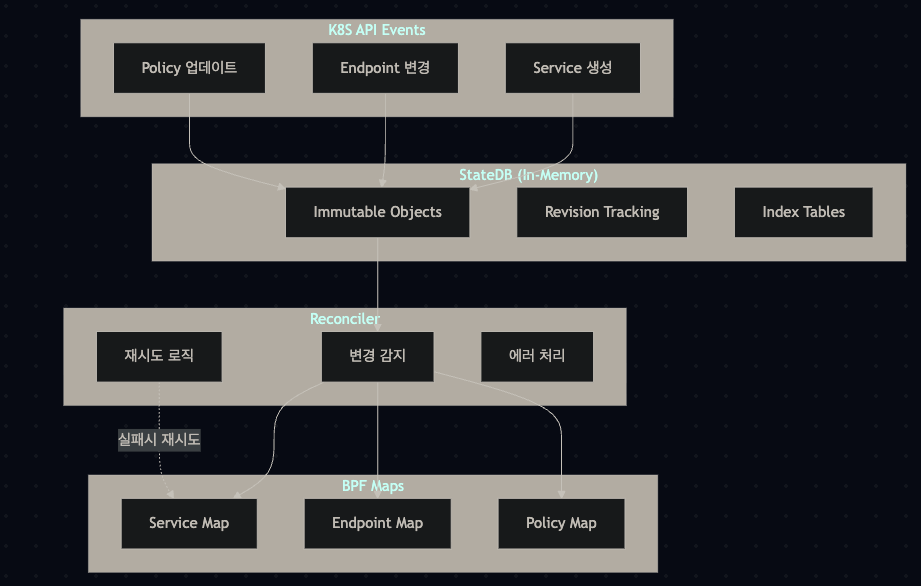
StateDB 특징
- In-memory transactional database: 메모리 기반 트랜잭션 DB
- Immutable radix trees: 불변 래딕스 트리로 버전 관리
- Channel-based notifications: 채널 기반 변경 알림
📚 추가 학습 리소스 및 참고 자료
1. K8S 성능 관련
공식 문서
블로그 및 발표자료
2. Cilium 성능 관련
공식 문서
발표 영상
3. 성능 테스트 도구
🎯 7주차 학습 요약
1. 핵심 성취 목표
K8S 성능 이해
- ✅ API Server의 메모리 사용 패턴과 OOM 문제 이해
- ✅ etcd 성능 병목 지점과 해결 방안 습득
- ✅ 대규모 클러스터 운영 시 고려사항 파악
- ✅ 성능 모니터링 메트릭 활용법 습득
Cilium 성능 최적화
- ✅ BPF Map 크기 조정 및 압력 모니터링
- ✅ StateDB와 Reconciler 아키텍처 이해
- ✅ 네트워크 성능 측정 및 분석
- ✅ Connectivity test를 통한 기능 검증
2. 실무 적용 가능한 기술
성능 테스트
- Kube-burner를 활용한 부하 테스트
- iperf3를 통한 네트워크 대역폭 측정
- PromQL을 활용한 성능 메트릭 분석
- 병목 지점 파악 및 최적화
클러스터 최적화
- API Server 리소스 적정 크기 산정
- etcd 성능 튜닝 (로컬 SSD, 분리 구성)
- kubelet 설정 최적화 (maxPods, 이미지 풀)
- 네트워크 최적화 (EndpointSlices 활용)
모니터링 구축
- Prometheus 기반 성능 메트릭 수집
- Grafana 대시보드 구성
- 알림 규칙 설정
- 장기 트렌드 분석
3. 도전 과제
- kube-burner 벤치마크 실행: 다양한 워크로드로 클러스터 한계 테스트
- 메트릭 기반 튜닝: 프로메테우스 메트릭을 활용한 성능 최적화
- 대규모 시뮬레이션: kwok을 활용한 수천 노드 시뮬레이션
이로써 K8S와 Cilium의 성능 측정, 분석, 최적화에 대한 종합적인 이해를 완성하였습니다. 대규모 클러스터 운영 시 발생할 수 있는 다양한 성능 문제들과 그 해결 방안을 실습을 통해 체득했습니다.
