미니플젝
저희 프로젝트는 재료를 입력하면 레시피를 생성해주는 ai 서비스입니다.
제가 맡은 역할입니다.

제 생각에 이런 시나리오가 될 것같습니다.
임베딩 하는분이 데이터를 임베딩해서 DB를 만들어놓습니다.
저는 해당 DB에서 자료를 찾아분석을합니다. + GPT API를 사용하여 적절한 답변을 만듭니다
우선 db는 나중에 붙혀보고 어떤 api를 사용할지 찾아봐야 할 것같아요
답정너입니다.
gpt-4o mini 저렴하고 성능도 괜찮다고 들었어요 이걸 사용하면될 것 같아요
그럼 실제로 한번 사용하는 연습을 해볼께요
그전에 깃먼저 연동을 해놓읍시다
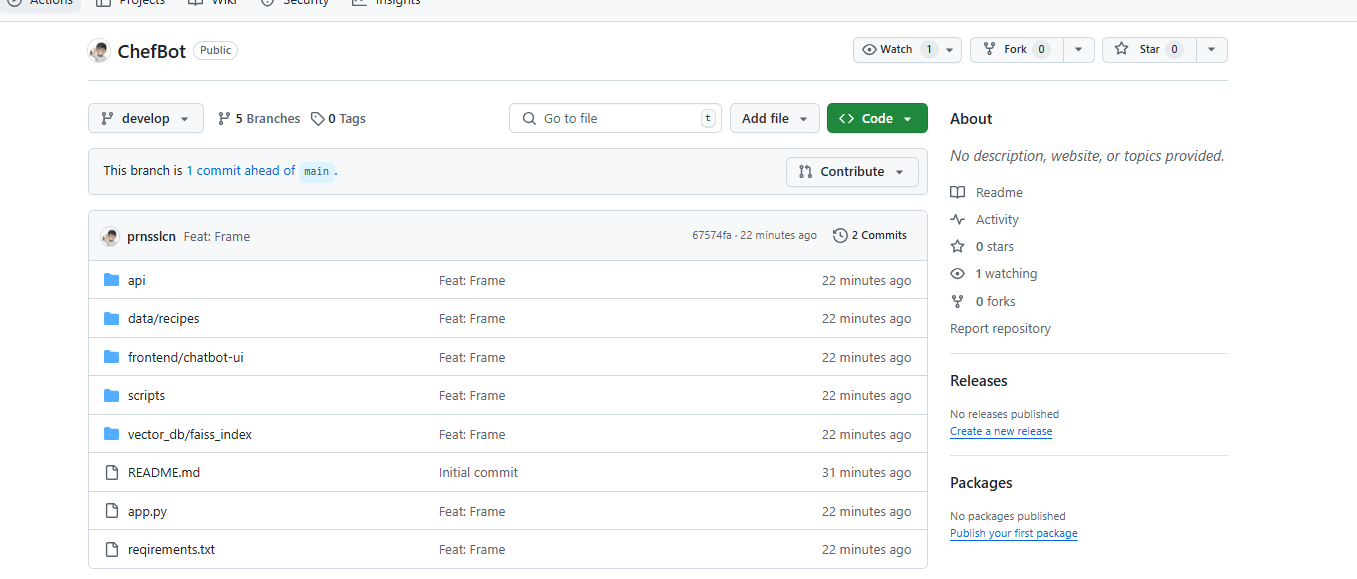
팀원분이 디렉토리 구조를 잡아놨어요 땡큐
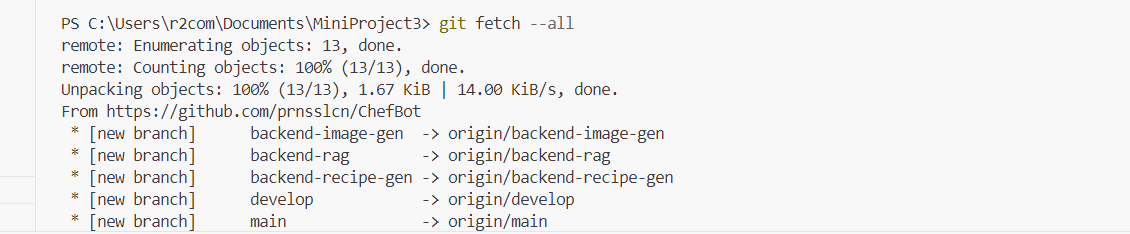
git remote를 이용하여 원격 저장소와 연동후
fetch 명령을 통해서 현재 원격 저장소 정보를업데이트
헤드 브랜치로나오는 것은 local에는 브랜치가 없다는뜻입니다

local에 브랜치를 만들었습니다.
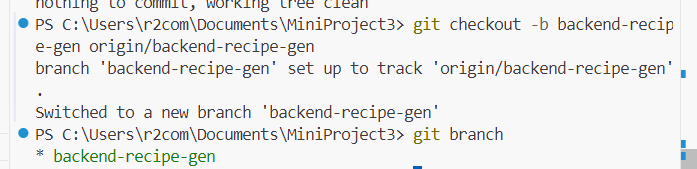
마찬가지로 develop 브랜치도 가져와서
merge 해버리기

디렉토리 구조완료
이제작업을 시작해봐요 해당구조에서
목표 디렉토리구조 확인
openAI-api 사용해보기
제가 사용해야할 .py파일도 만들어두셨네요
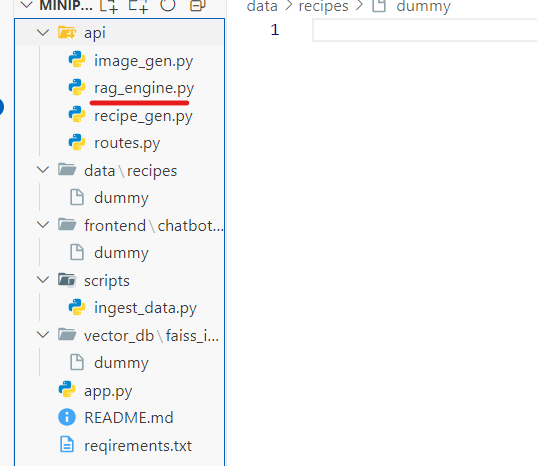
MiniProject3/
├── api/ # 📌 백엔드(API) - Python 기반 REST API
├── data/ # 📌 데이터 저장소 (레시피 데이터 포함)
│ └── recipes/ # └ 레시피 관련 데이터 폴더
├── frontend/ # 📌 프론트엔드 (사용자 UI)
│ └── chatbot-ui/ # └ 챗봇 UI 관련 코드
├── scripts/ # 📌 유틸리티 & 자동화 스크립트
└── vector_db/ # 📌 벡터 데이터베이스 (FAISS 기반)
└── faiss_index/ # └ FAISS 인덱스 저장 폴더
📌 유틸리티 & 자동화 스크립트란?
유틸리티(Utility) & 자동화 스크립트는 프로젝트에서 반복적이거나 번거로운 작업을 자동으로 실행하는 코드입니다.
유틸리티(Utility): 프로젝트에서 자주 사용되는 공용 함수, 도구
키등록
.env파일을만들어요
상위 폴더에서 .env파일을 읽어옵니다

일겅오는 함수 작성
터미널에서 실행시켰는데 제대로 잘출력되요
모델생성
랭체인, 오픈ai관련 모듈을 설치하고 import 해줘요
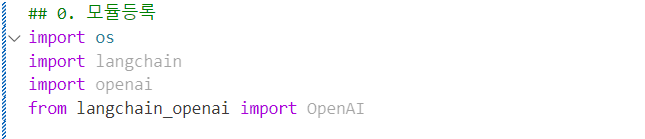
키등록해주고 모델생성

텍스트 입력

출력

잘출력되네요

여기까지가 기본틀이고 이제 기능들을 추가하면될 것 같아요
사용할수있는 옵션 나열
MaxMarginalRelevanceExampleSelector
- 다양성을 최적화하여, 유사한 답변예시를 기반으로 선택 조합한다
Memory(단기)
- 대화 내용 기억
- 단기기억 : 랭체인등 활용
- 장기기억 : 백터 디비 활용 -> 질의때 해당 내용을 포함하여 구성 => 전체? 부분? 요약? 등등 선택의 문제
- 대화내용에 대한 AI에게 환기
LLM 스트리밍
- 결과를 한번에 받지 않고, 나오는 즉시 전송 (계속해서 답변을 하는것처럼 보이는 방식)
- LLM이 결과를 출력하는 스타일 => "다음 단어를 예측" 응답
- 결과는 한번에 생성되는것이 아닌, 순차적으로 생성된다!! -> 스트리밍 가능함
라마인덱스
- 기존 LLM 한계(혹은 제한된점, 문제점)
- 공식적으로는 private 한 데이터 답변 x
- RAG로 해결 (검색증강생성)
- 공식적으로는 private 한 데이터 답변 x
- 특징
- 내부적으로 랭체인 사용
RAG
- 특징
- 검색 증강 생성
- 외부에 존재하는(사내, 특정 분야 전문 내용등 => LLM이 학습 하지 않았던 지식) 내용을 기반으로 정보 검색
- 외부 데이터이는 통상적으로 백터 디비로 저장
- 모든 클라우드 회사, 파이어스, 파이콘, ...
- 가장 큰 잠재력을 가진 분야로 체크
- 해당 내용을 기반으로 LLM의 추론행위를 활용 => AI의 최적 기능을 활용
나열하면서 살펴보니 뭘해야하는지 살짝 이해가됬습니다.
그러니까 임베딩하시는분 데이터를 벡터화해서 저장하면
제가 꺼내서 쿼리문을 작성하면되는겁니다.
✅ 목표:
1️⃣ 다양성을 최적화 (MaxMarginalRelevanceExampleSelector)
2️⃣ 대화 내용을 기억 (단기 & 장기 기억)
3️⃣ 스트리밍 방식으로 응답
4️⃣ 벡터 데이터베이스에서 데이터를 검색하여 포함
추가정보
📌 라마인덱스(LlamaIndex)와 RAG(Retrieval-Augmented Generation, 검색 증강 생성)의 관계
🔹 LlamaIndex(구 GPT Index) 와 RAG 는 GPT 모델이 외부 데이터에 접근하여 보다 정확한 응답을 생성할 수 있도록 하는 기술입니다.
🔹 RAG는 검색된 정보를 활용해 답변을 생성하는 개념(방법론)이고, LlamaIndex는 이를 구현하는 프레임워크(도구)입니다.
LangChain이 RAG에 사용되는 이유
✅ LangChain은 RAG를 쉽게 구현할 수 있도록 돕는 프레임워크
✅ 벡터 DB 연동, 임베딩, LLM 호출, 체인 로직 등을 쉽게 연결
LangChain은 "AI의 역할을 나눠서 연결하는 프레임워크"
일단 제가 벡터 데이터베이스를 읽어오는 부분을 해야하기때문에 임의로 벡터디비에 데이터를 저장해볼께요
faiss 설치

RAG에 사용될 llamaindex도 설치

1. 2. 3. 4. 5. 는 다른 팀원분이 해야하는 역할인것 같습니다
제가 해야할역할은 6. 7. 을 하는것 입니다.
그렇지만 어처피 두루두루 알고있어야 할 것 같아 전부 진행해볼께요
## 모듈등록
import os
import faiss
import langchain
import openai
from langchain_openai import OpenAI
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
from llama_index.core import Document
from llama_index.core import GPTVectorStoreIndex
# 라마인덱스, faiss 연동
from llama_index.core import StorageContext, GPTVectorStoreIndex
from llama_index.vector_stores.faiss import FaissVectorStore
## api 키등록
# os - 파일경로 조작 , __file__ 현재 실행중인 Python 파일의 전체경로를 나타냄
env_path = os.path.join(os.path.dirname(os.path.dirname(os.path.dirname(__file__))), ".env")
print(env_path)
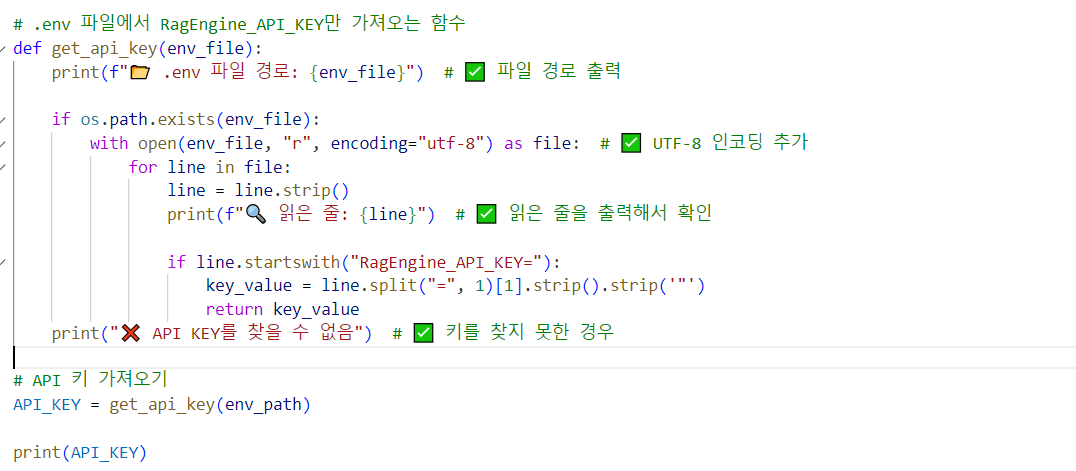
def get_api_key(env_file):
if os.path.exists(env_file):
with open(env_file, "r", encoding="utf-8") as file: # UTF-8 인코딩 추가
for line in file:
line = line.strip()
# print(f"{line}") // 제대로 읽었는지 확인
if line.startswith("OPENAI_API_KEY="):
key_value = line.split("=", 1)[1].strip().strip("'").strip('"') # 작은따옴표 & 큰따옴표 제거
return key_value
print("API KEY를 찾을 수 없음") # 키를 찾지 못한 경우
return None
# API 키 가져오기
API_KEY = get_api_key(env_path)
os.environ["OPENAI_API_KEY"] = API_KEY
# 1. 데이터 로드
documents = SimpleDirectoryReader(input_dir="C:/Users/r2com/Documents/MiniProject3/data/recipes").load_data()
print(f"📂 {len(documents)}개의 문서를 로드했습니다.")
# 2. FAISS 벡터 DB 초기화
embedding_dim = 1536 # OpenAI Embeddings 차원 수
faiss_index = faiss.IndexFlatL2(embedding_dim)
# 3. LLamaIndex에서 FAISS와 연동하여 벡터 DB 생성
vector_store = FaissVectorStore(faiss_index=faiss_index) # FAISS를 벡터 저장소로 사용
storage_context = StorageContext.from_defaults(vector_store=vector_store)
# 4. LLamaIndex를 이용하여 문서를 벡터화하고 FAISS에 저장
index = GPTVectorStoreIndex.from_documents(
documents,
storage_context=storage_context
)
print("✅ FAISS 벡터 DB 저장 완료!")
# 5. FAISS 인덱스 저장
faiss.write_index(faiss_index, "C:/Users/r2com/Documents/MiniProject3/vector_db/recipes_faiss.index")
print("✅ FAISS 인덱스 파일 저장 완료!")
# 6. 쿼리 엔진 생성
query_engine = index.as_query_engine()
# 7. 사용자 질의 수행
query = "비밀의 방에 있는 물건은?"
response = query_engine.query(query)
print(f"🔍 질문: {query}")
print(f"🤖 응답: {response}")-
처음에 사용할 데이터를 로드해온다음에
-
FAISS 벡터 DB를 사용하기위해 초기화해놓고
-
FAISS는 기본적으로 LlamaIndex와 직접 연동되지 않으므로, 변환이 필요함
-
로드한 문서를 OpenAI 임베딩을 사용해 벡터화하고, FAISS에 저장
-
해당 인덱스를저장한다음 저장하는이유는 또 사용하기위해서일태고
-
이제 벡터 DB에서 검색할 수 있도록 쿼리 엔진을 생성
-
수행
FAISS + GPT
## 모듈등록
import os
import faiss
import langchain
import openai
from langchain_openai import OpenAI
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
from llama_index.core import Document
from llama_index.core import GPTVectorStoreIndex
# 라마인덱스, faiss 연동
from llama_index.core import StorageContext, GPTVectorStoreIndex
from llama_index.vector_stores.faiss import FaissVectorStore
from llama_index.llms.openai import OpenAI
## api 키등록
# os - 파일경로 조작 , __file__ 현재 실행중인 Python 파일의 전체경로를 나타냄
env_path = os.path.join(os.path.dirname(os.path.dirname(os.path.dirname(__file__))), ".env")
print(env_path)
def get_api_key(env_file):
if os.path.exists(env_file):
with open(env_file, "r", encoding="utf-8") as file: # UTF-8 인코딩 추가
for line in file:
line = line.strip()
# print(f"{line}") // 제대로 읽었는지 확인
if line.startswith("OPENAI_API_KEY="):
key_value = line.split("=", 1)[1].strip().strip("'").strip('"') # 작은따옴표 & 큰따옴표 제거
return key_value
print("API KEY를 찾을 수 없음") # 키를 찾지 못한 경우
return None
# API 키 가져오기
API_KEY = get_api_key(env_path)
os.environ["OPENAI_API_KEY"] = API_KEY
# 1. 데이터 로드
documents = SimpleDirectoryReader(input_dir="C:/Users/r2com/Documents/MiniProject3/data/recipes").load_data()
print(f"📂 {len(documents)}개의 문서를 로드했습니다.")
# 2. FAISS 벡터 DB 초기화
embedding_dim = 1536 # OpenAI Embeddings 차원 수
faiss_index = faiss.IndexFlatL2(embedding_dim)
# 3. LLamaIndex에서 FAISS와 연동하여 벡터 DB 생성
vector_store = FaissVectorStore(faiss_index=faiss_index) # FAISS를 벡터 저장소로 사용
storage_context = StorageContext.from_defaults(vector_store=vector_store)
# 4. LLamaIndex를 이용하여 문서를 벡터화하고 FAISS에 저장
index = GPTVectorStoreIndex.from_documents(
documents,
storage_context=storage_context
)
print("✅ FAISS 벡터 DB 저장 완료!")
# 5. FAISS 인덱스 저장
save_dir = "C:/Users/r2com/Documents/MiniProject3/vector_db"
os.makedirs(save_dir, exist_ok=True)
faiss.write_index(faiss_index, os.path.join(save_dir, "recipes_faiss.index"))
print("✅ FAISS 인덱스 파일 저장 완료!")
# 6. GPT 모델 설정
llm = OpenAI(model="gpt-4o-mini")
# 7. LlamaIndex에서 OpenAI LLM을 사용하여 질의 응답 처리
query_engine = index.as_query_engine(llm=llm)
# 8. 사용자 질문 실행
query = "비밀의 방에 있는 물건은?"
response = query_engine.query(query)
print(f"🔍 질문: {query}")
print(f"🤖 GPT 응답: {response}")- 데이터를 로드해오고
- 파이스벡터의 데이터베이스를 초기화한다음에
- 라마인덱스에서 파이스데이터베이스를 사용할수 있도록만들고
- 라마인덱스를 이용해서 읽어온 데이터를 벡터화한다음에 파이스데이터베이스에 저장을 하고
- 그리고 파이스데이터베이스 인덱스를 저장한다음에
- 사용할 지피티 모델을 설정하고
- 라마인덱스에서 지피티를 사용할 수있도록 쿼리문앤진을만들고
- 질의응답
즉, FAISS를 사용하면 GPT가 모든 문서를 직접 분석할 필요 없이, 관련 문서만 바탕으로 더 빠르고 정확한 응답을 제공할 수 있음!
5시 40분 일단 여까이!

