저번 글([JPA] @Transactional과 synchronized를 동시에 사용할 때의 DB 동기화 이슈)에 이어 이번엔 왜 멀티 쓰레드 환경에서 하나의 트랜잭션에서 하나의 row 데이터에 접근하여 데이터를 변경하는 쿼리를 날리고(flush), 다른 트랜잭션에서 같은 데이터 row에 접근했을 때 변경되지 않은 데이터 값을 가져오는지 알아보기 위해 MVCC에 대해 알아보고 MySQL이 어떻게 동시성 제어를 하는지 보도록 한다.
MVCC?
- Multi Version Concurrency Control의 약자로 다중 버전 동시성 제어라고 한다.
- Locking의 성능 문제 때문에 탄생하게 되었다.
- Lock을 사용하지 않고 일관된 읽기를 제공하는 것이 주 목적이다.
- 사용자는 MVCC에서 데이터에 접근할 때 Snapshot을 읽는다.
- 이 Snapshot에 대해선 변경이 완료(commit) 될 때 까진 다른 사용자는 볼 수 없다.
- 사용자가 데이터를 업데이트하면 새로운 버전의 데이터를 버퍼에 넣는다.
- 이전 버전의 데이터는 undo영역에 생성된다.
- 사용자는 latest version의 데이터만 읽는다.
- locking 방식을 사용하지 않아 성능 상의 이점이 있다.
- 사용하지 않는 데이터(not latest data)를 정리하는 시스템이 필요하다.
- 데이터 버전이 충돌하게 되면 애플리케이션에서 처리해야 한다.
Update/Delete 쿼리가 들어왔을 때 시나리오
이제 MySQL을 DBMS로 사용하고, 다음과 같은 상황에 놓여있다고 생각해보자.
먼저 다음과 같은 쿼리가 DB에 전달되고, 트랜잭션 종료 및 commit을 한다.
insert into member (m_id, m_name, m_value) values (12, '홍길동', '서울');이제 하나의 쓰레드에서 트랜잭션을 시작해 다음처럼 update 쿼리를 날린(flush)다.
update member m set m_area = '경기' where m_id = 12;그리고 나서 다른 쓰레드의 트랜잭션이 다음과 같이 select를 실행한다.
select * from member where m_id = 12;결과가 어떻게 될까??
| m_id | m_name | m_area |
|---|---|---|
| 12 | 홍길동 | 경기 |
위처럼 생각했다면 이 글을 읽기 잘했다!
결과는 다음과 같다.
| m_id | m_name | m_area |
|---|---|---|
| 12 | 홍길동 | 서울 |
이유를 보기에 앞서 사용자 요청 및 쿼리 처리 과정을 간단하게 보자.
사용자 요청 응답 과정
사용자에 대한 요청(쿼리)가 처리되는 과정을 간략히 보면
- MySQL Connector(JDBC)에 요청이 옴
- 사용자 쓰레드가 할당되고 요청이 MySQL 엔진에 전달
- 쿼리 파서와 전처리기에서 SQL 요청의 문법 오류 검증 및 접근 권한 검증
- 옵티마이저가 쿼리 최적화
- 실행 엔진이 스토리지 엔진에서 제공하는 핸들러 API를 호출해 쿼리를 수행
- 결과 반환
InnoDB의 Update/Delete 쿼리 처리 과정
다음으로 InnoDB의 쿼리 처리 과정을 간략히 보자.
- 요청이 들어오면 시스템 장애를 대응하기 위해(시스템 복구를 위해) Redo 로그에 요청 내용 기록
- 버퍼 풀에 요청에 대한 내용을 기록
- 변경되기 전 데이터는 index와 함께 Undo 로그에 복사
- 종료
- 트랜잭션 정상 종료 및 커밋 시 버퍼 풀에 있는 내용을 디스크에 저장
- 트랜잭션 롤백 시 Undo 로그에 기록된 내용을 다시 복원
InnoDB는 이와 같이 버퍼 풀, Undo 로그를 통해서 MVCC를 지원한다.
다시 위 시나리오로 돌아가서..
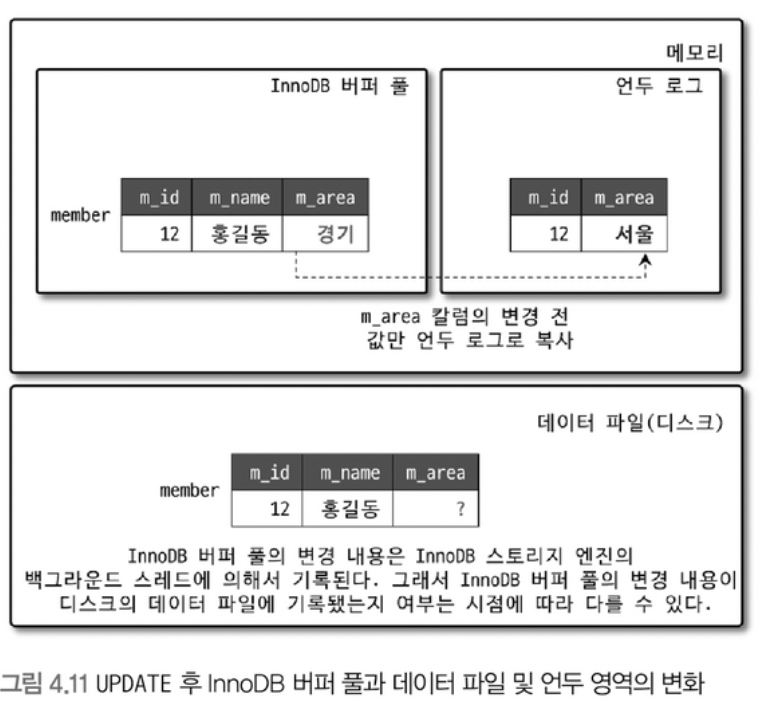
다시 위 시나리오로 돌아가 정리해보면
- 한 트랜잭션에서 flush한
update member m set m_area = '경기' where m_id = 12;는 InnoDB 버퍼 풀에 기록된다. - 업데이트 이전 데이터인 ‘서울’은 인덱스와 함께 Undo 로그에 복사된다.
- 컨텍스트 스위칭된 다른 쓰레드에서
select * from member where m_id = 12;쿼리를 날려 조회를 하면 업데이트 이전의 데이터인 ‘서울’이 조회가 된다.
그 이유는 다음과 같다.
- update쿼리를 날린 트랜잭션이 종료 및 커밋이 되지 않았기 때문이다.
- MySQL은 MVCC를 구현하는 InnoDB를 스토리지 엔진으로 사용하기 때문이다.
- MySQL의 Isolation Level의 Default값은 Repetable Read이기 때문이다.
만약 Isolation Level을 Read Uncommitted(Level 0)으로 설정한다면(하면 안되지만) 트랜잭션은 InnoDB 버퍼 풀에 있는 값을 읽을 것이다.
보통의 DBMS는 Default가 Read Committed(Level 1) 이상이다. 말 그대로 커밋된 데이터를 읽는데 MySQL은 Repeatable Read(Level 2)이기 때문에 컨텍스트 스위칭 되었던 다른 쓰레드에서는 버퍼 풀이 아닌 Undo Log에 있는 데이터를 읽어온다.
InnoDB의 특징
InnoDB의 특징을 간략히 보자면 다음과 같다.
- MySQL의 스토리지 엔진이다.(5.5 version 이후)
- primary key를 사용해 클러스터링 테이블(인덱스)를 지원한다.
- 외래키 설정을 지원한다.
- Redo Log, Undo Log, 레코드 단위 잠금을 통해 트랜잭션을 지원한다.
- 버퍼풀을 사용해 데이터를 캐싱한다.
Reference
