기본 세팅
- 작업 디렉토리 변경
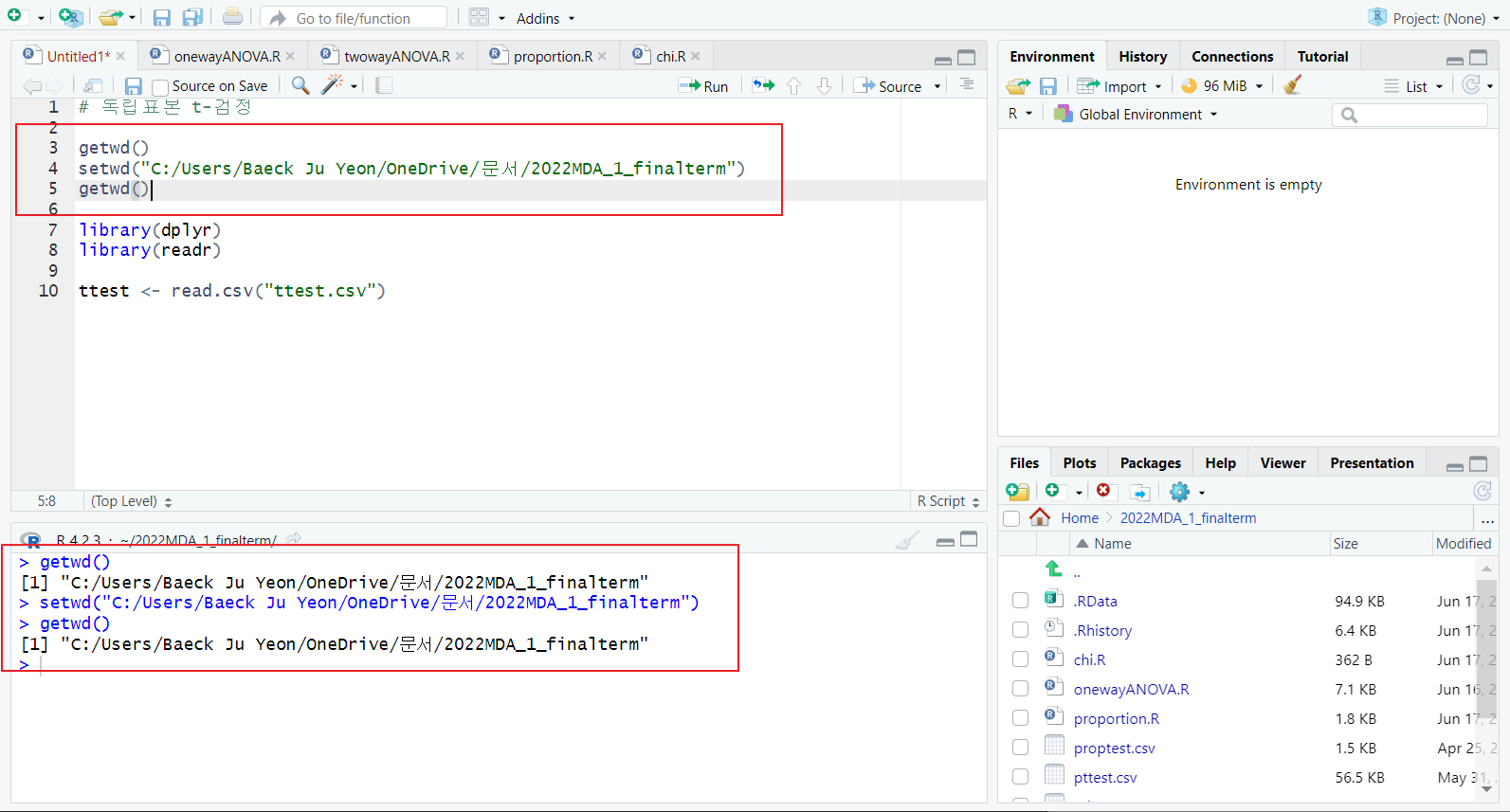
getwd(): 현재 작업중인 디렉토리 콘솔에 출력
setwd("작업할 디렉토리 주소"): "작업할 디렉토리 주소"로 이동
- 라이브러리 함수 미리 세팅
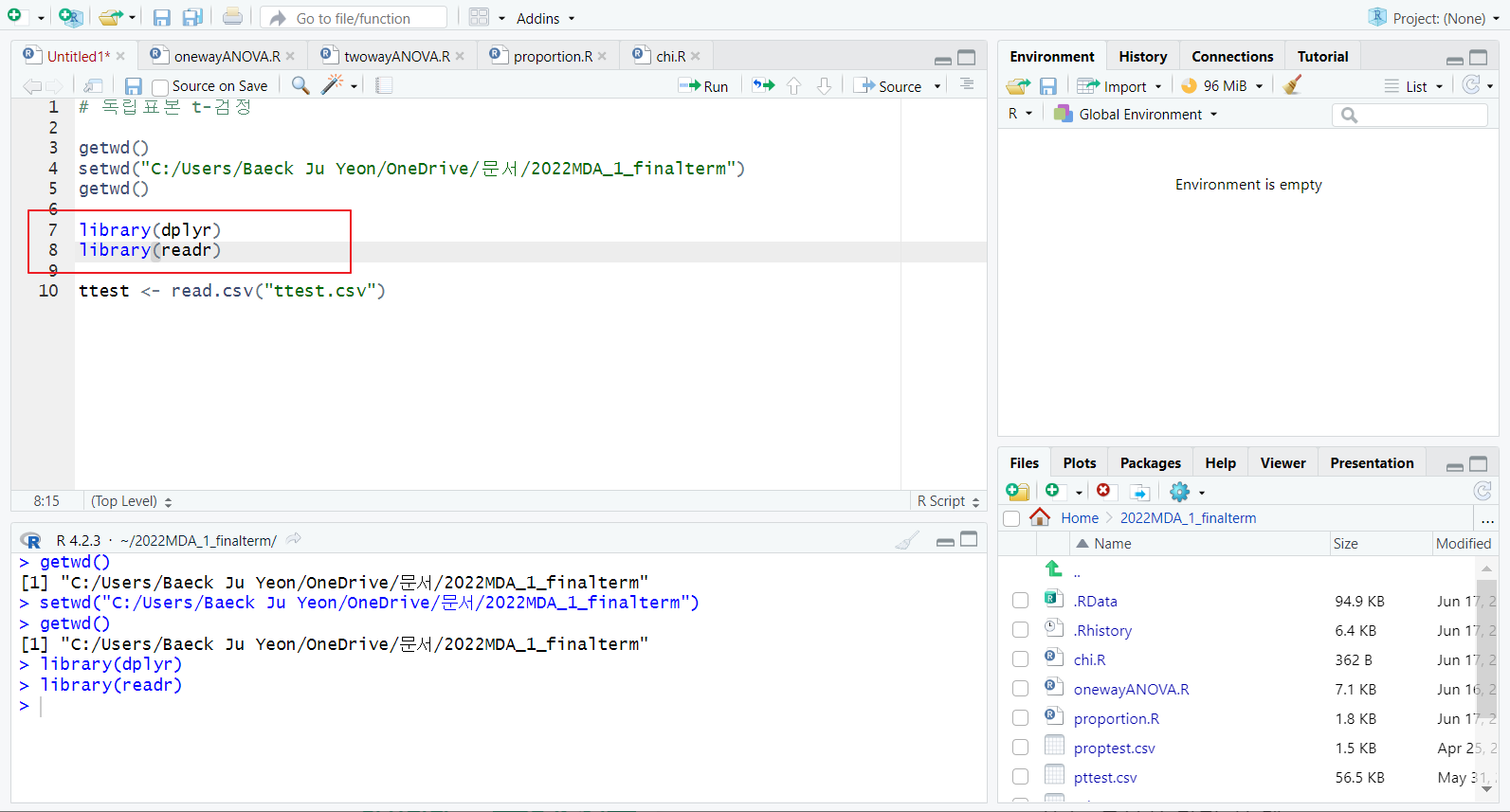
readr: read.csv 함수
dplyr: glimpse 함수, mutate 함수
psych: describe 함수
forcats:
car: leveneTest 함수 (등분산 조건 확인)
agricolae: duncan.test 함수 (등분산 가정 시 테스트)
dunn.test: dunn.test 함수 (이분산 가정 시 테스트)
예제1.
STEP0. 데이터 전처리
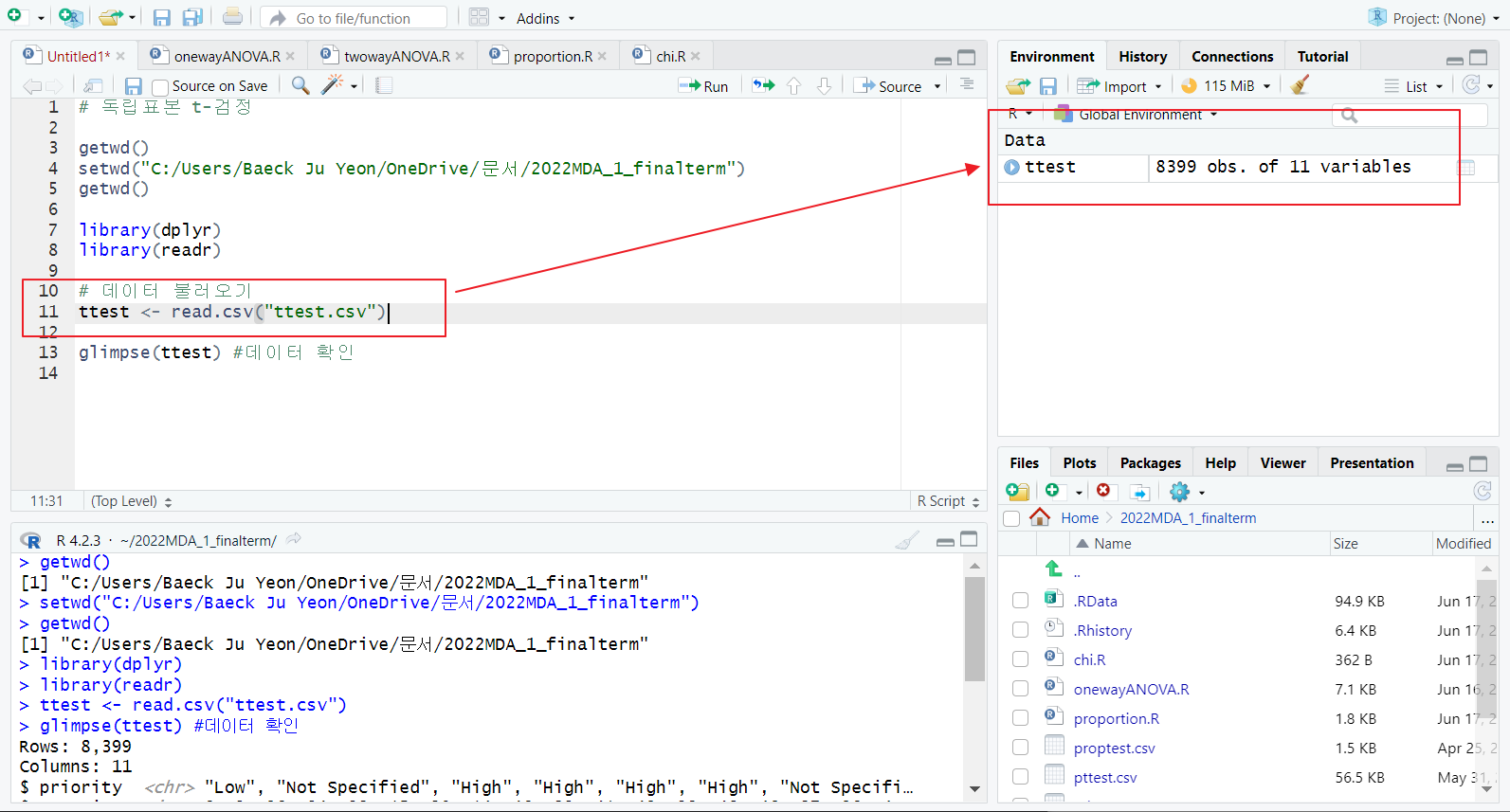
[1] 데이터 불러오기
-
read.csv 함수(readr 패키지);
-
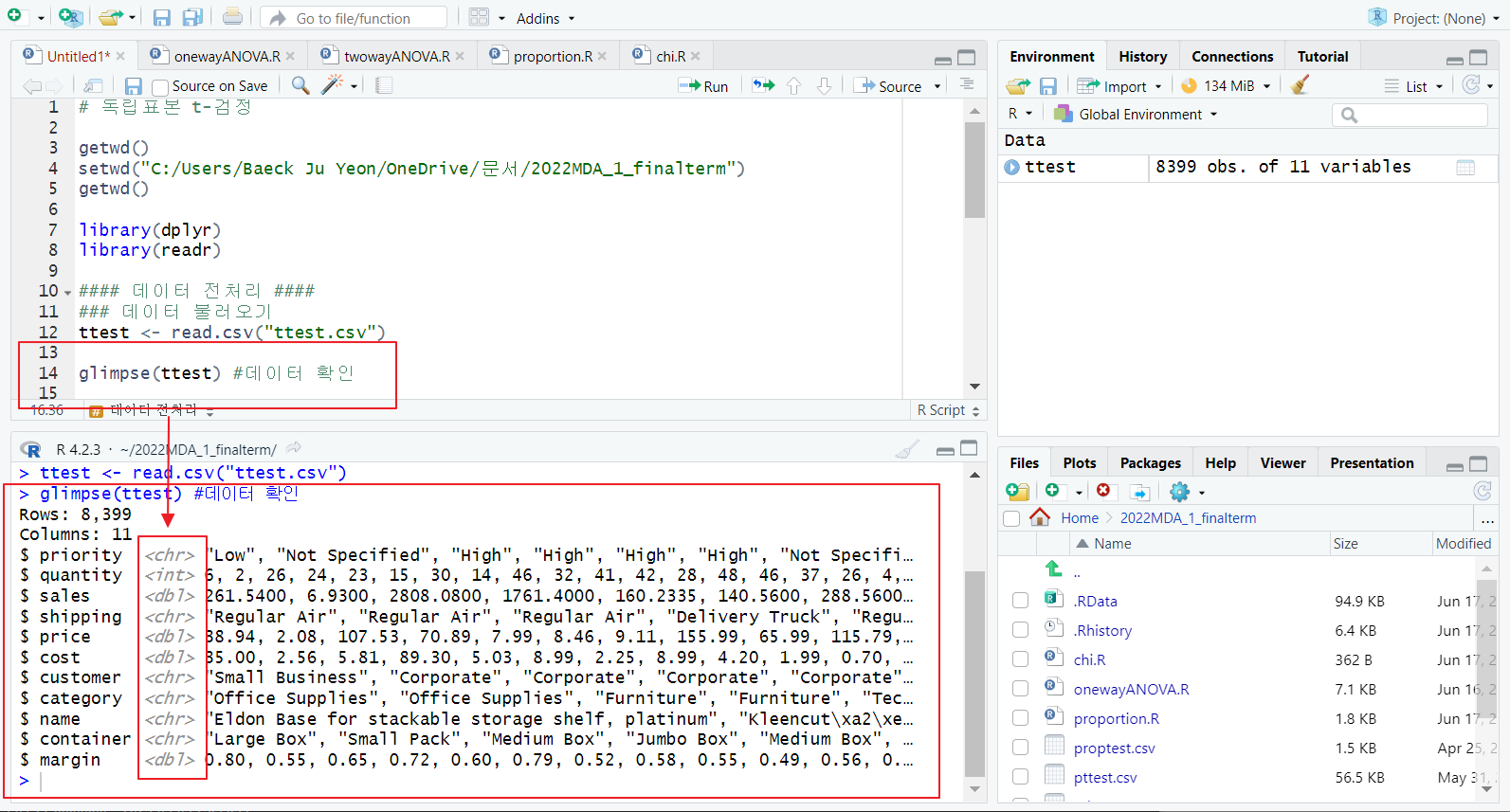
glimpse 함수(dplyr 패키지); 데이터 타입 확인
-
n_distinct 함수; chr 타입의 종류 확인
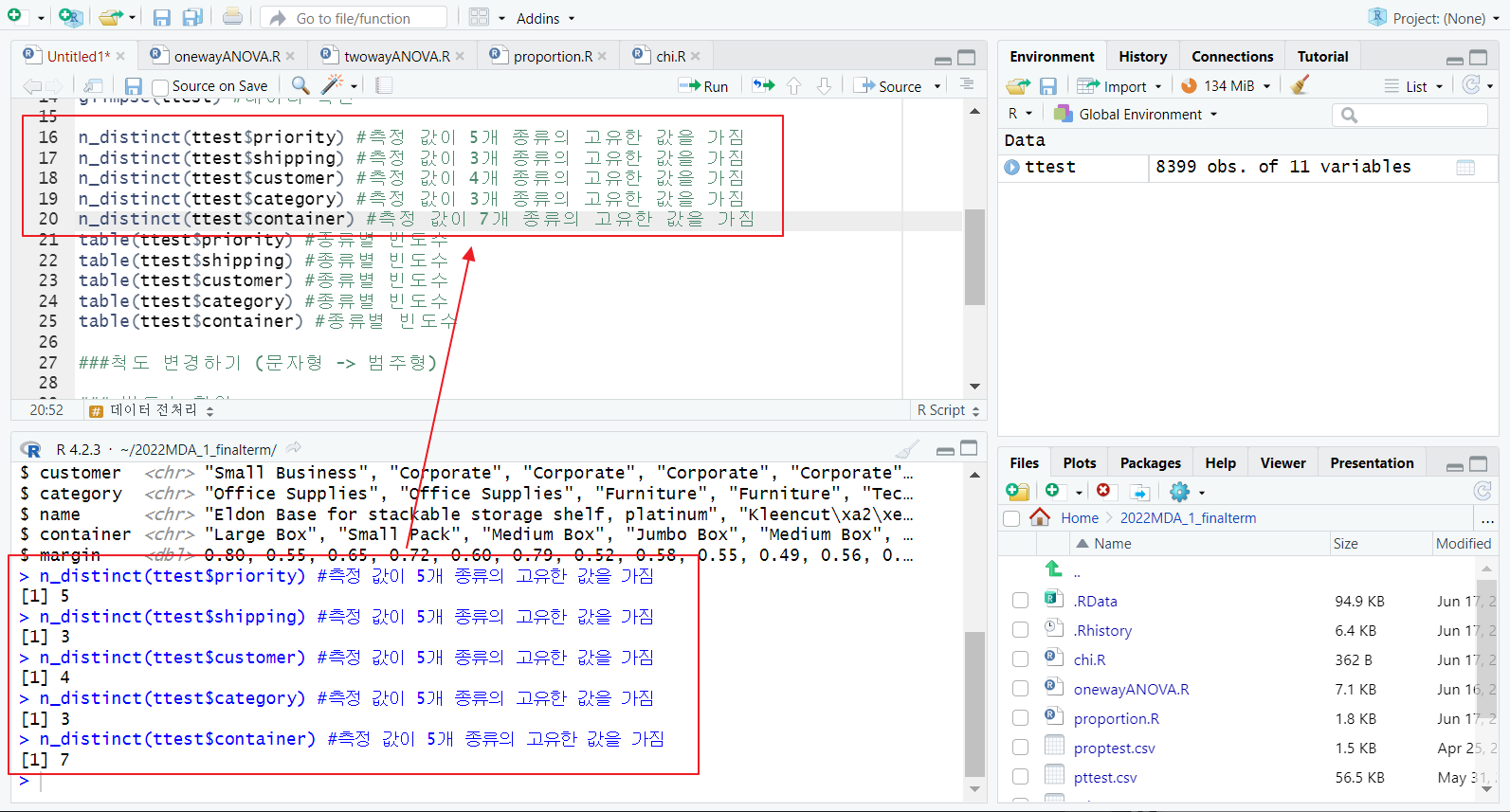
-
table 함수; 종류별 빈도수 확인
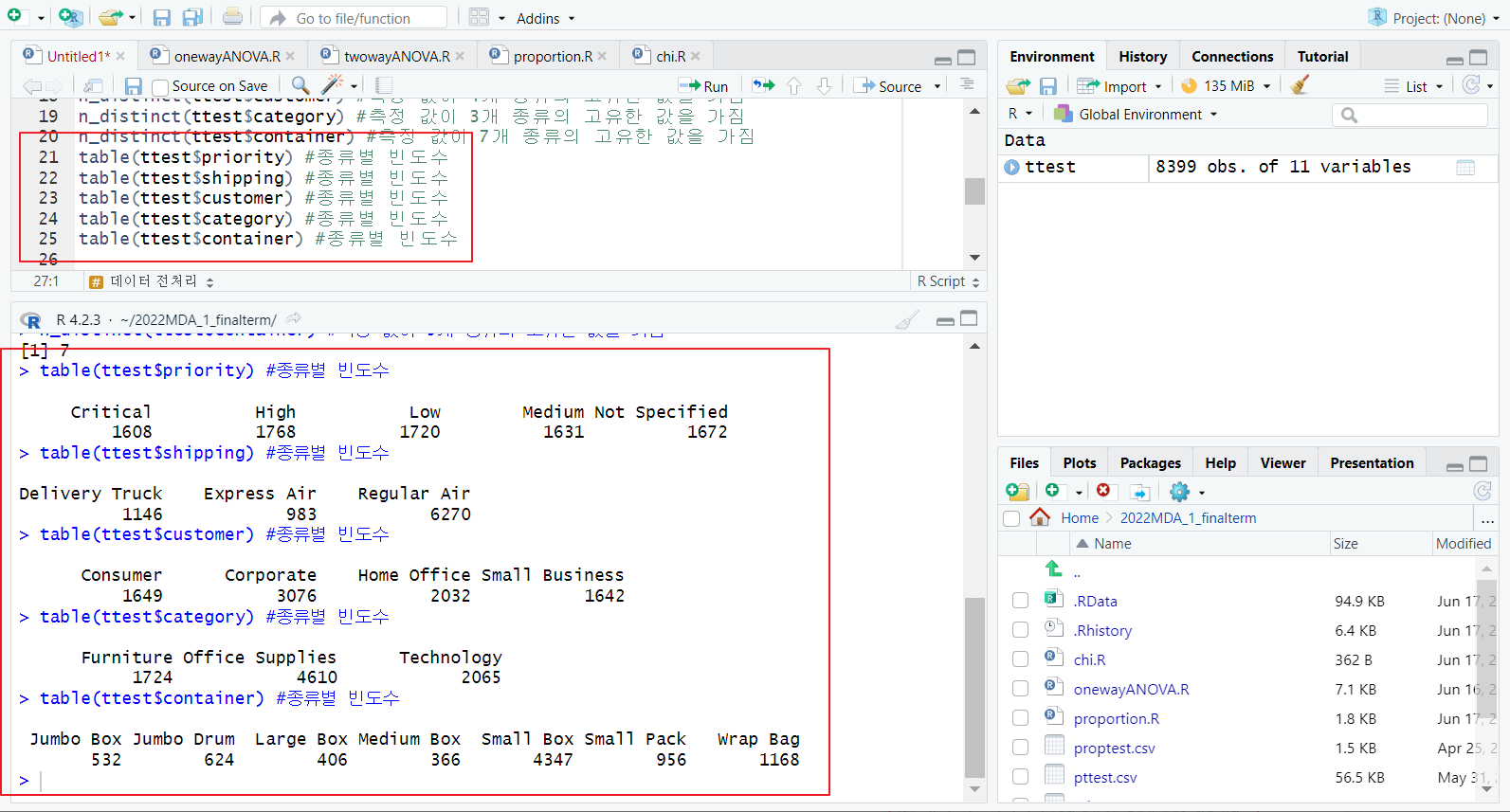
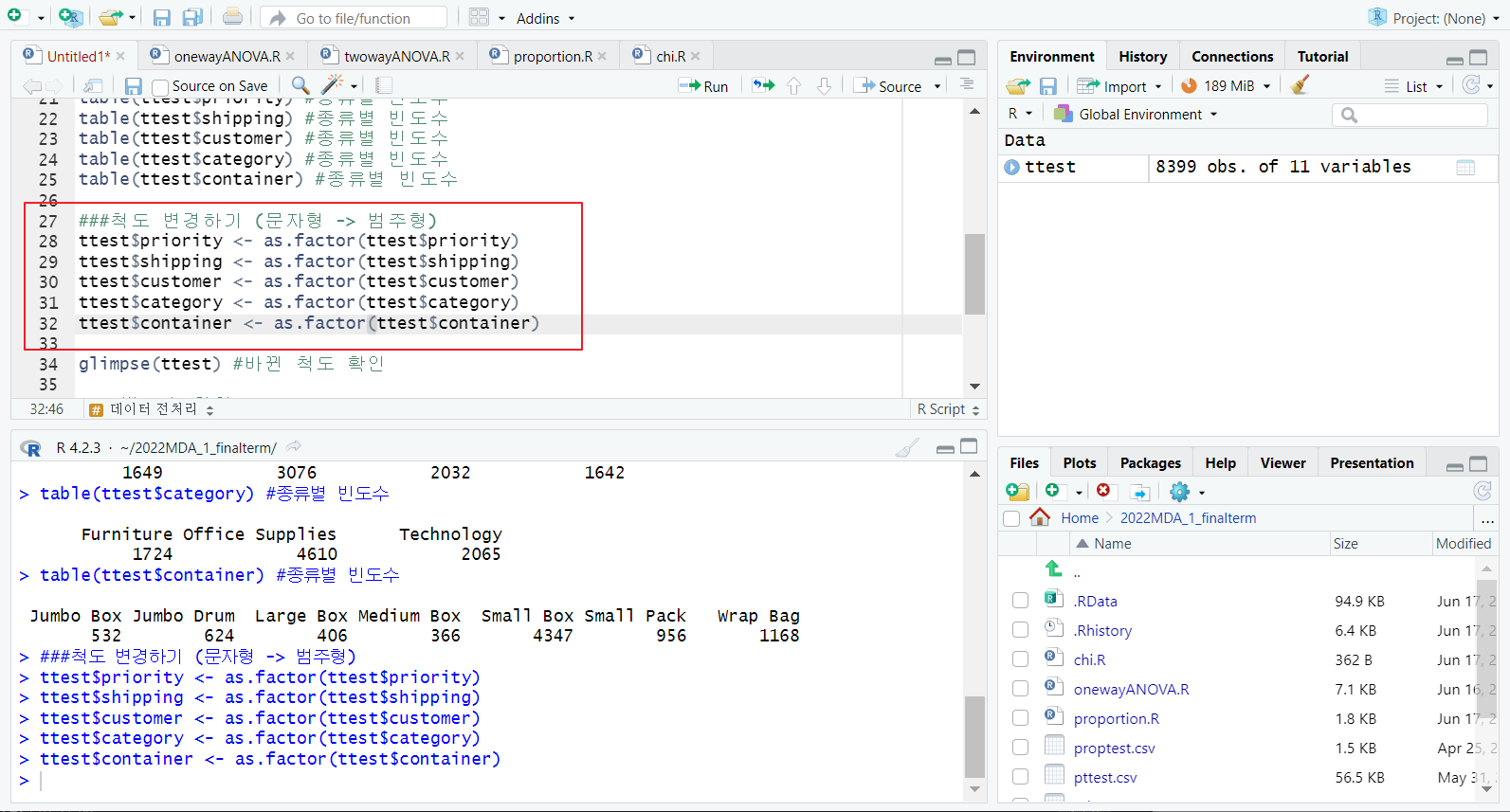
[2] 척도 변경하기 (문자형 -> 범주형)
-
as.factor 함수; 문자형 -> 범주형 척도 변경
-
glimpse 함수; 바뀐 척도 확인
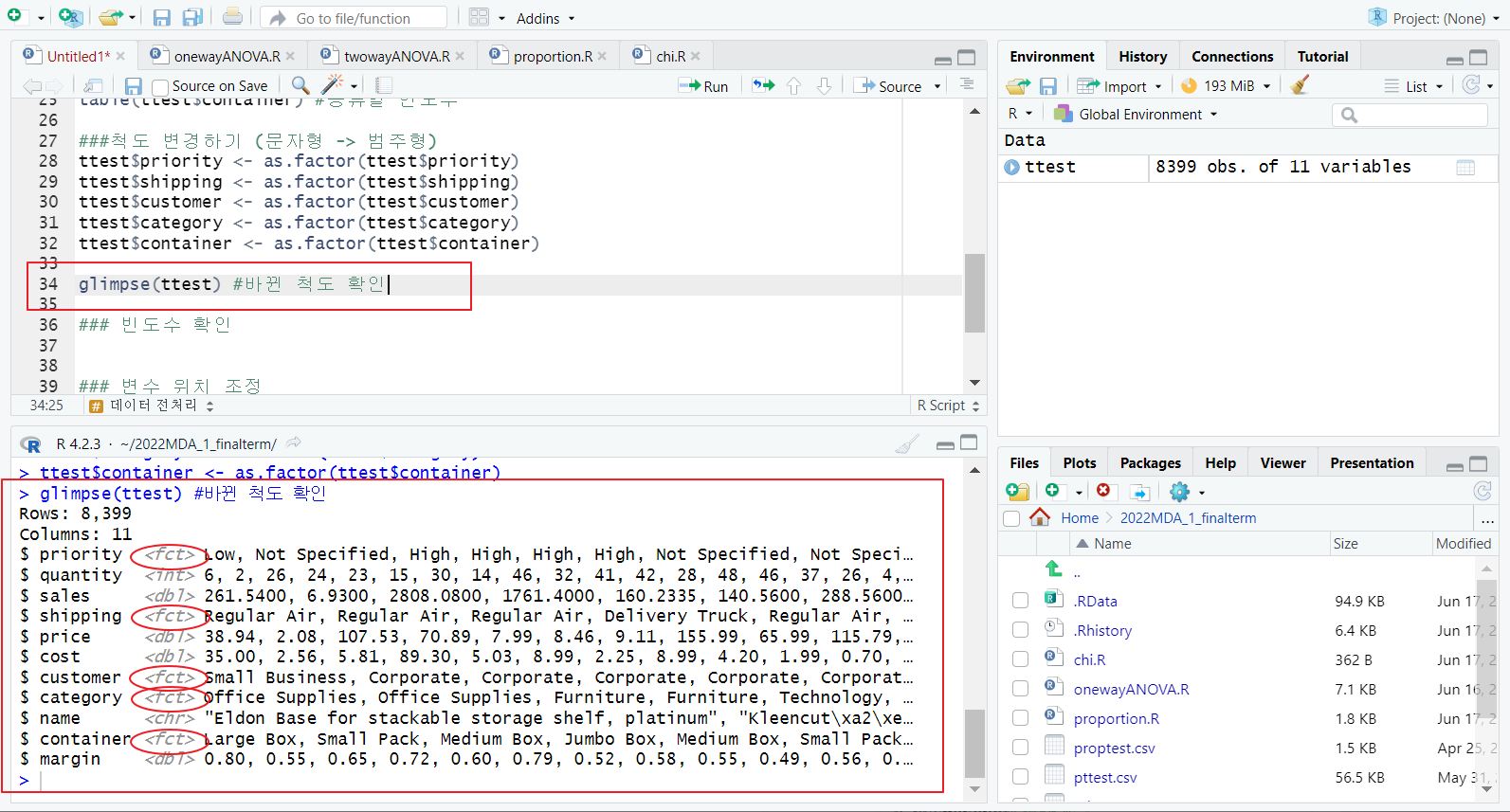
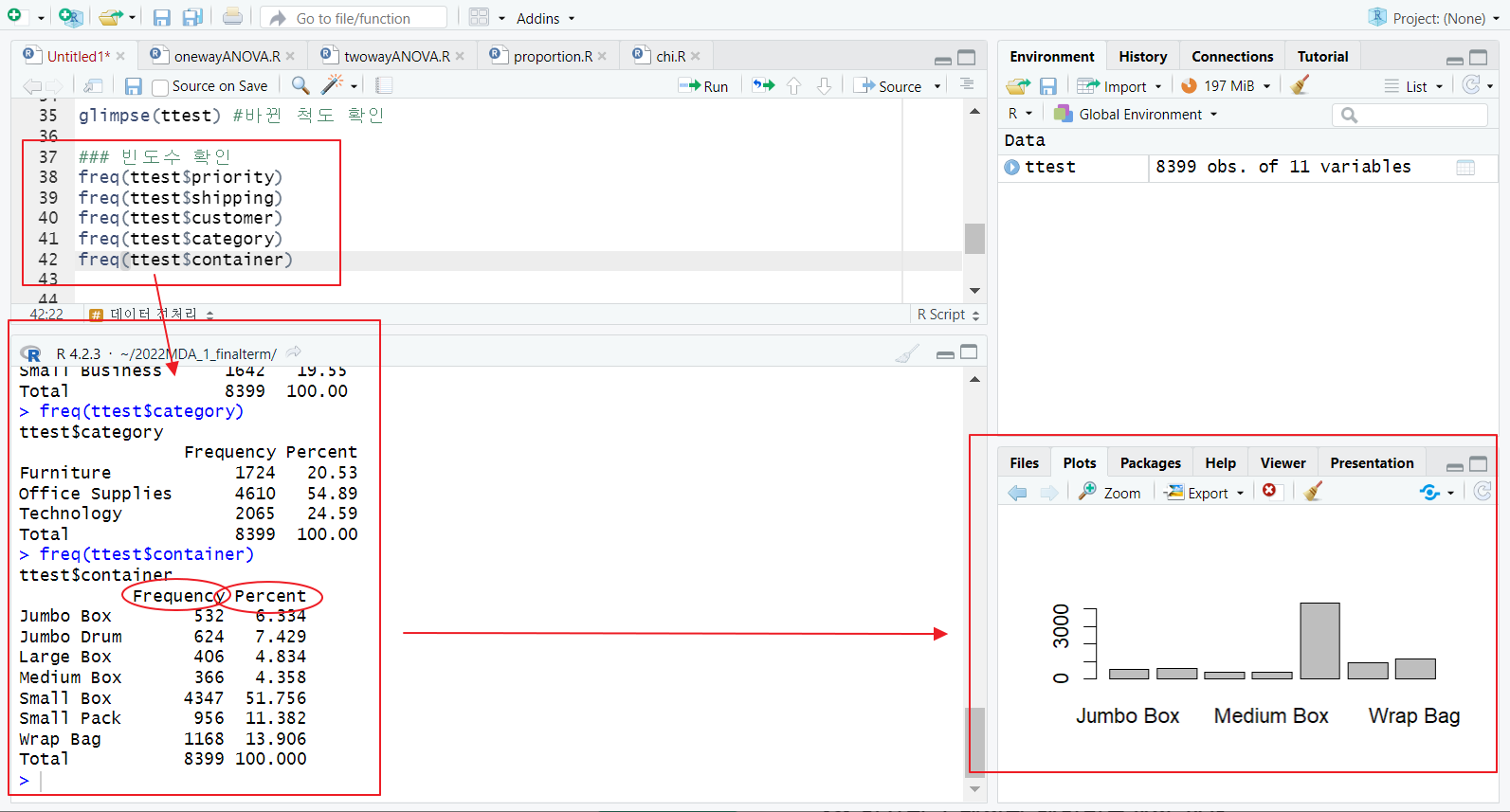
[3] 빈도수 확인
- freq 함수(descr 패키지); factor 함수에서 범주별 빈도(Frequency), 비율(Percent) 확인
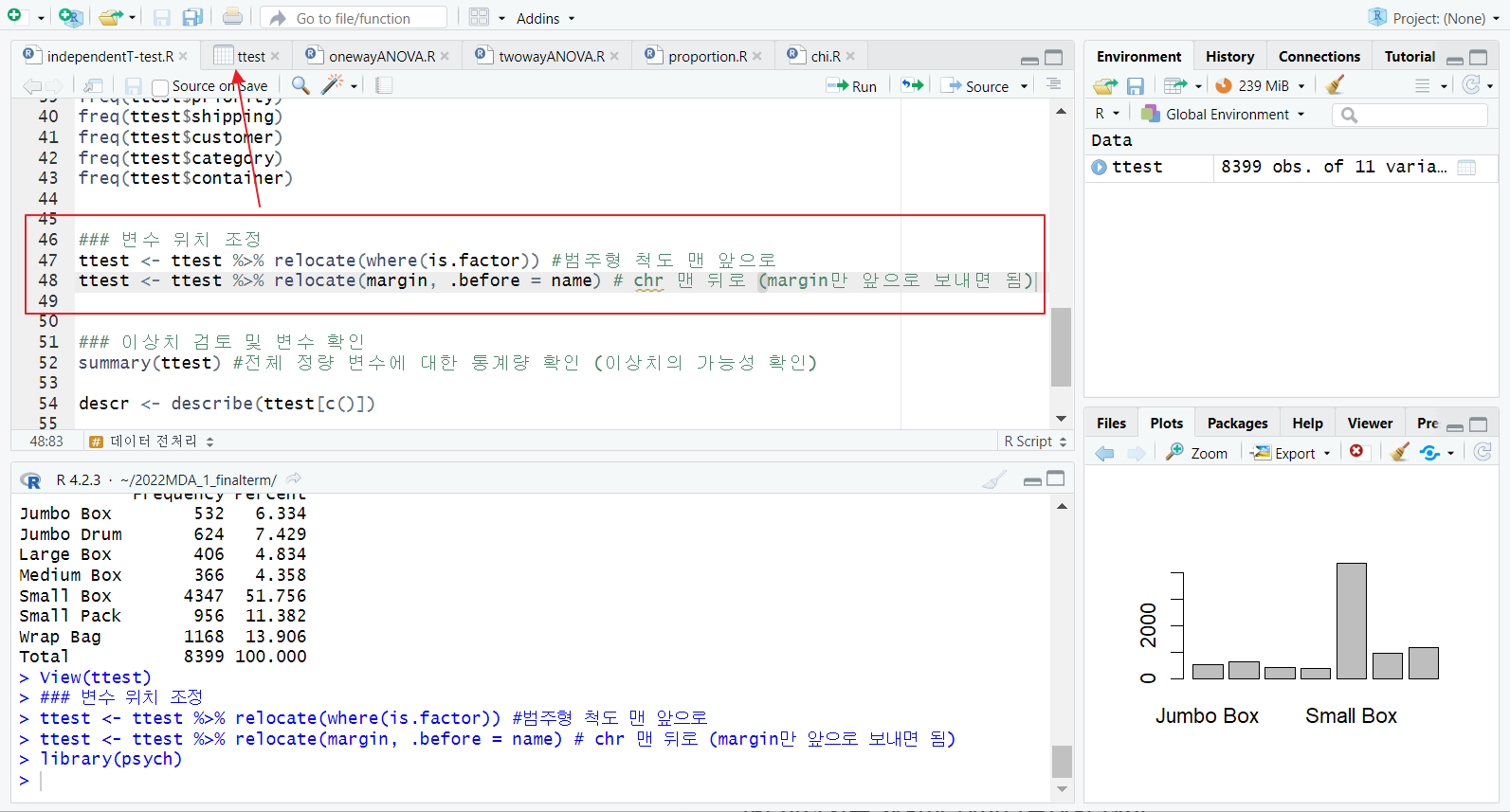
[4] 변수 위치 조정
- relocate 함수(dplyr 패키지); 범주형 척도 - 정량적 척도 - 문자형 순서시키기
[5] 이상치 검토 및 변수 확인
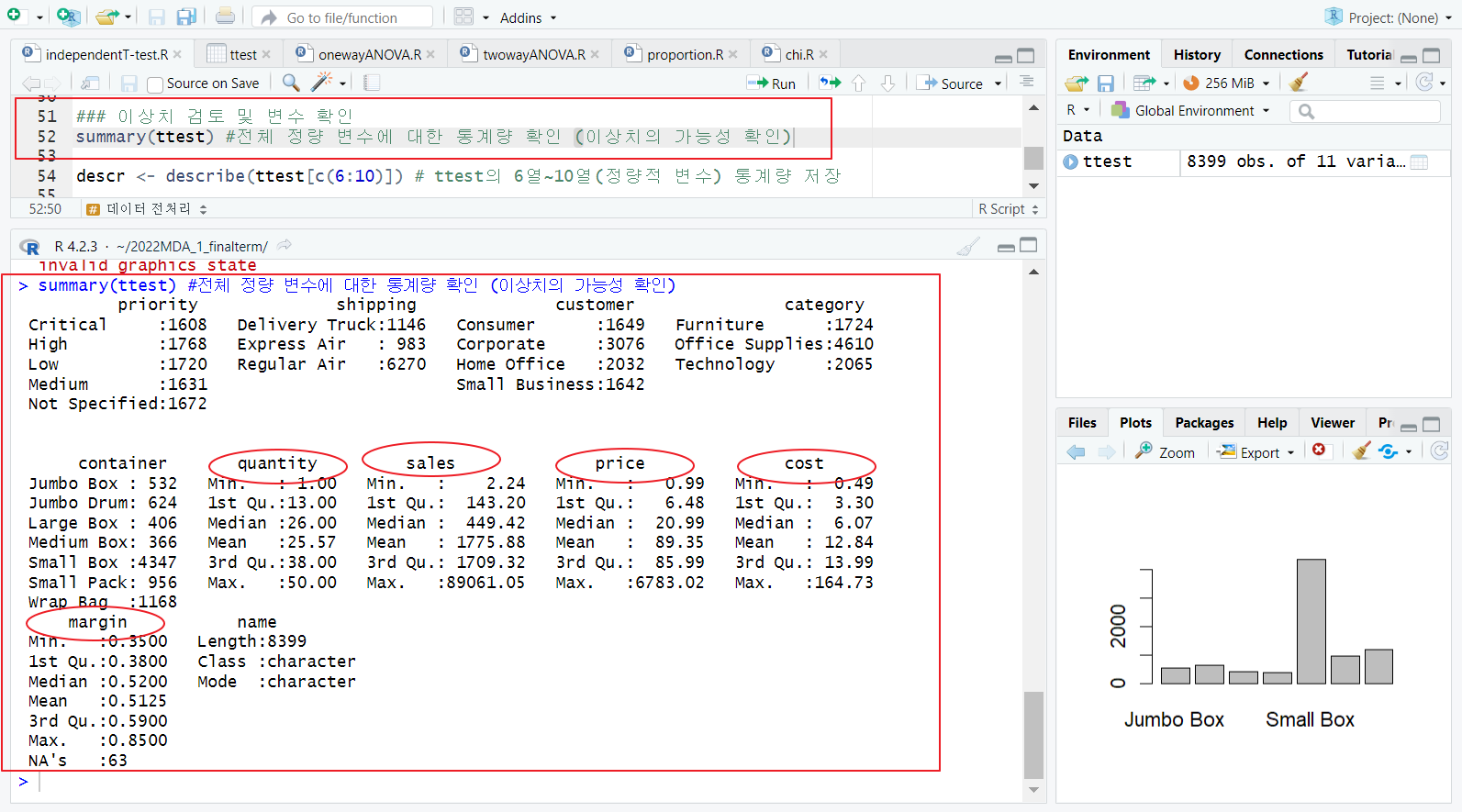
- summary 함수
- 3rd qutile, max 차이 큼 = 뒤가 long-tail로 쭉 늘어질 것을 예상할 수 있음
- 3rd qutile, max 차이 큼 = 뒤가 long-tail로 쭉 늘어질 것을 예상할 수 있음
-
describe 함수(psych 패키지)
- 정량적 변수에 대해서만 기술통계량 적용 가능

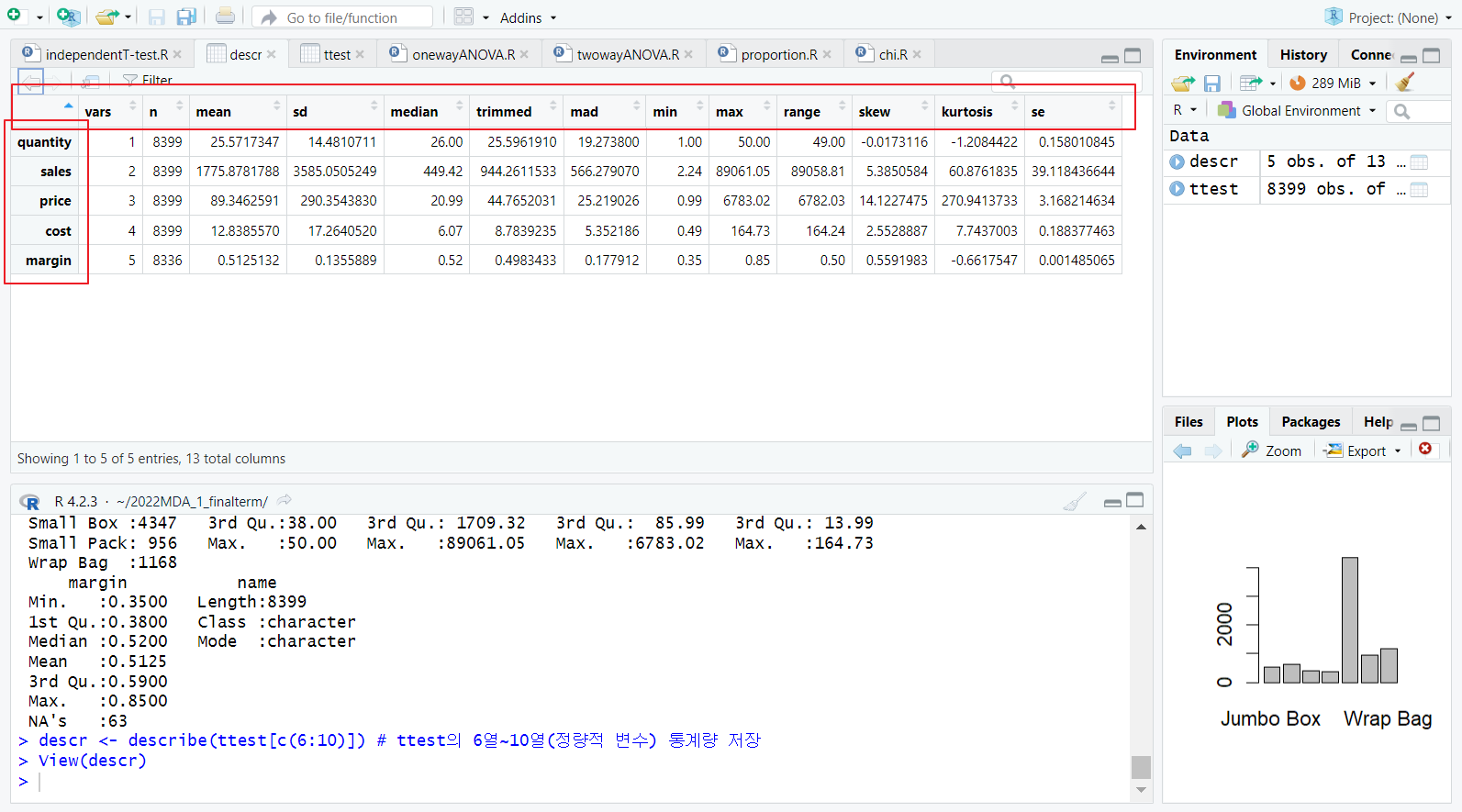
- 정량적 변수에 대해서만 기술통계량 적용 가능
-
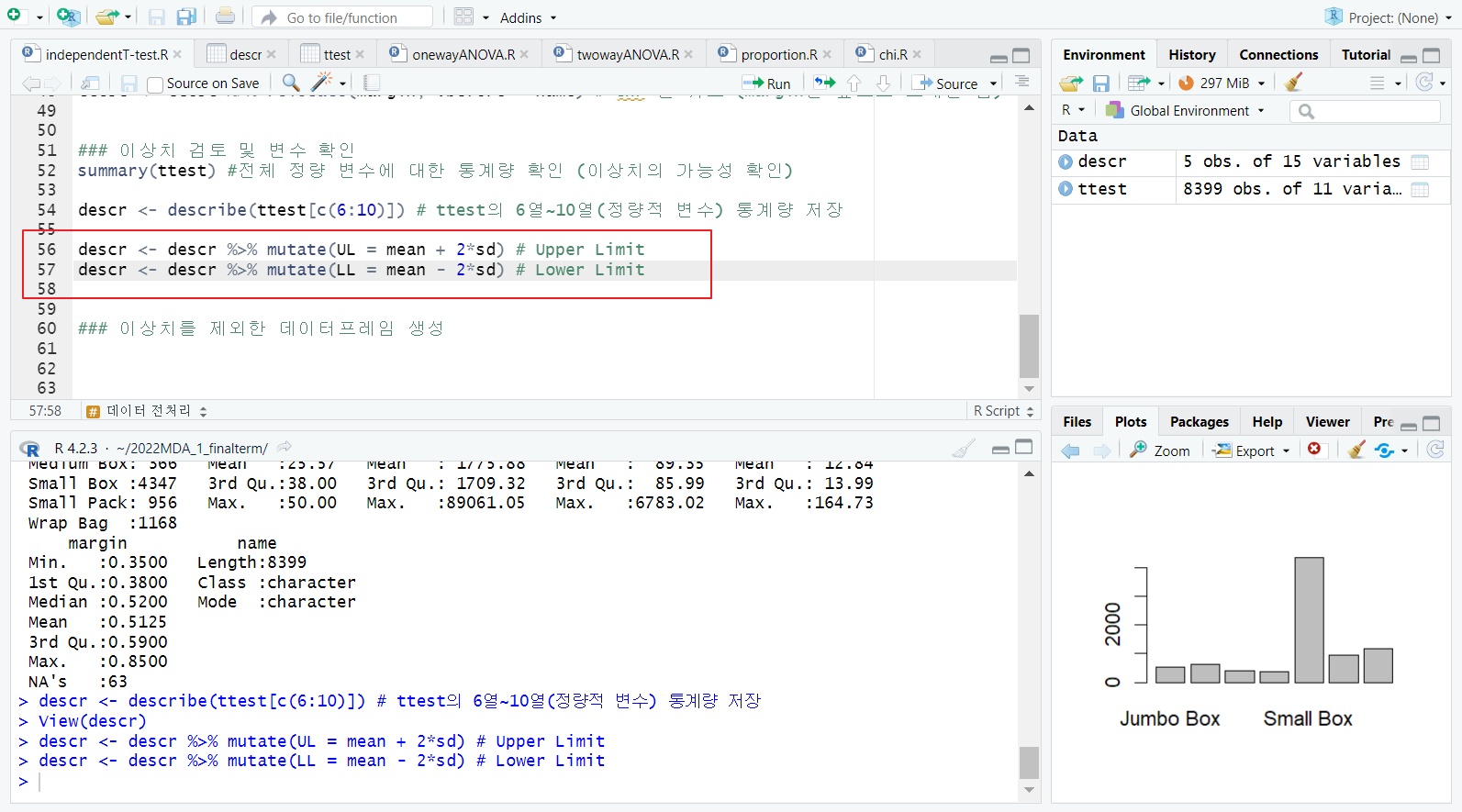
mutate 함수; 새로운 변수 추가
- 이상치 = mean +- 2*sd
- min, max 와 UL, LL 벗어나는지 비교
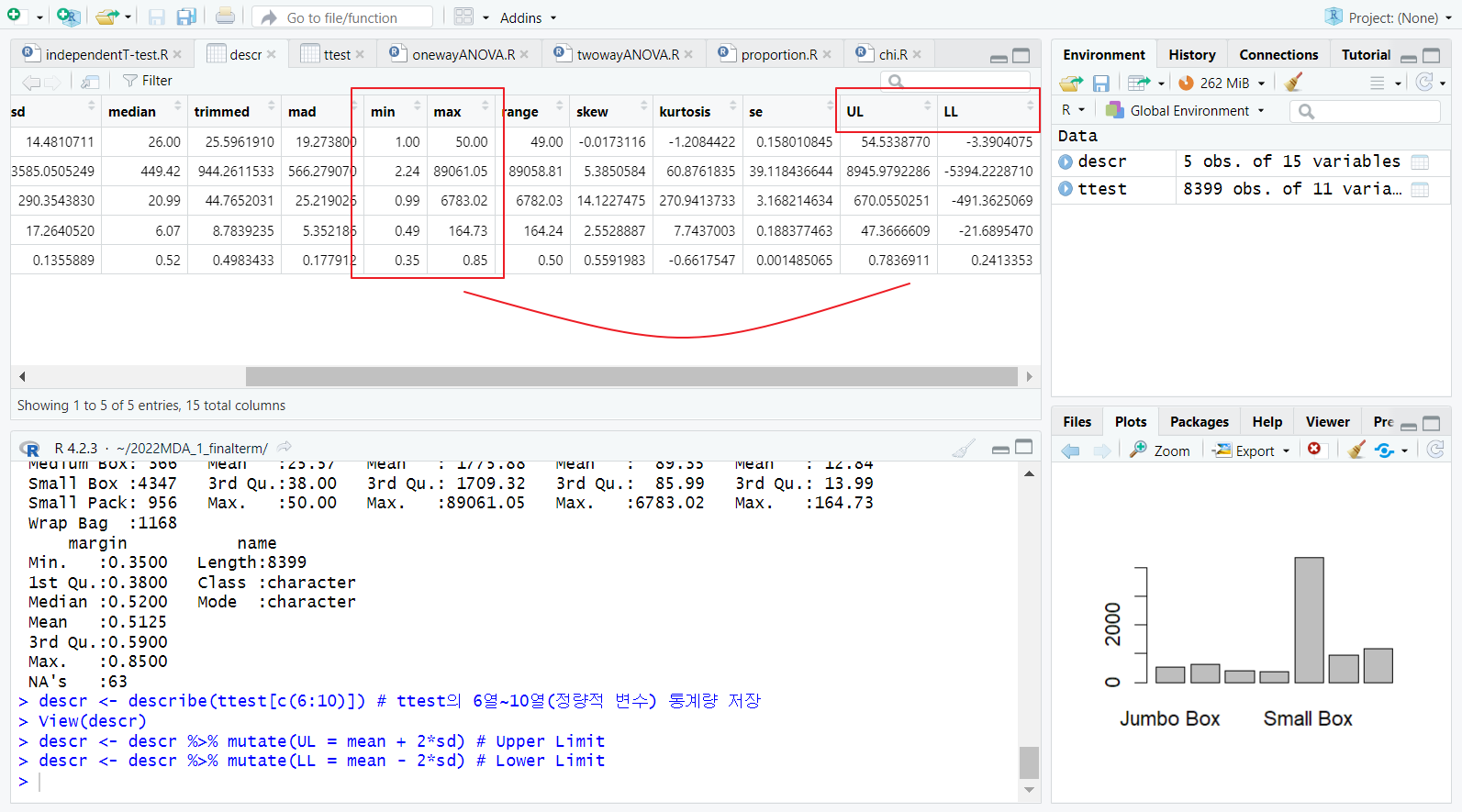
-
table 함수; 이상치 벗어나는 항목 몇 개 인지 확인
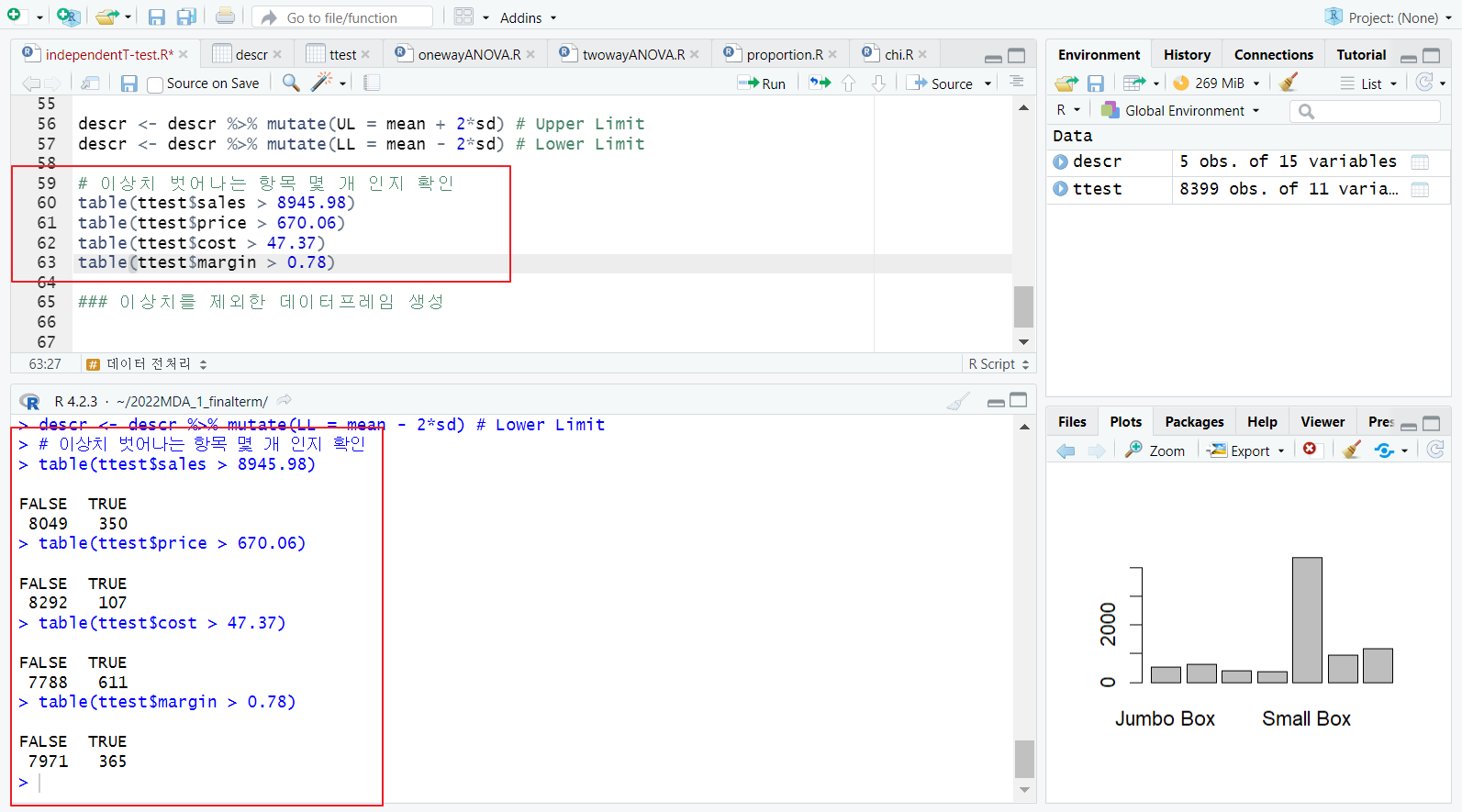
[6] 이상치를 제외한 데이터프레임 생성
- filter 함수; 이상치 제외한 새로운 데이터프레임 생성
- 행의 개수 8399->7117 (이상치 제거된만큼)
STEP1 가설 수립
독립변수(customer), 종속변수(sales)
- 네 가지 customer 유형으로 나누었을 때 sales 평균 비교
H0 : 뮤HO - 뮤CS = 0
Ha : 뮤HO - 뮤CS != 0
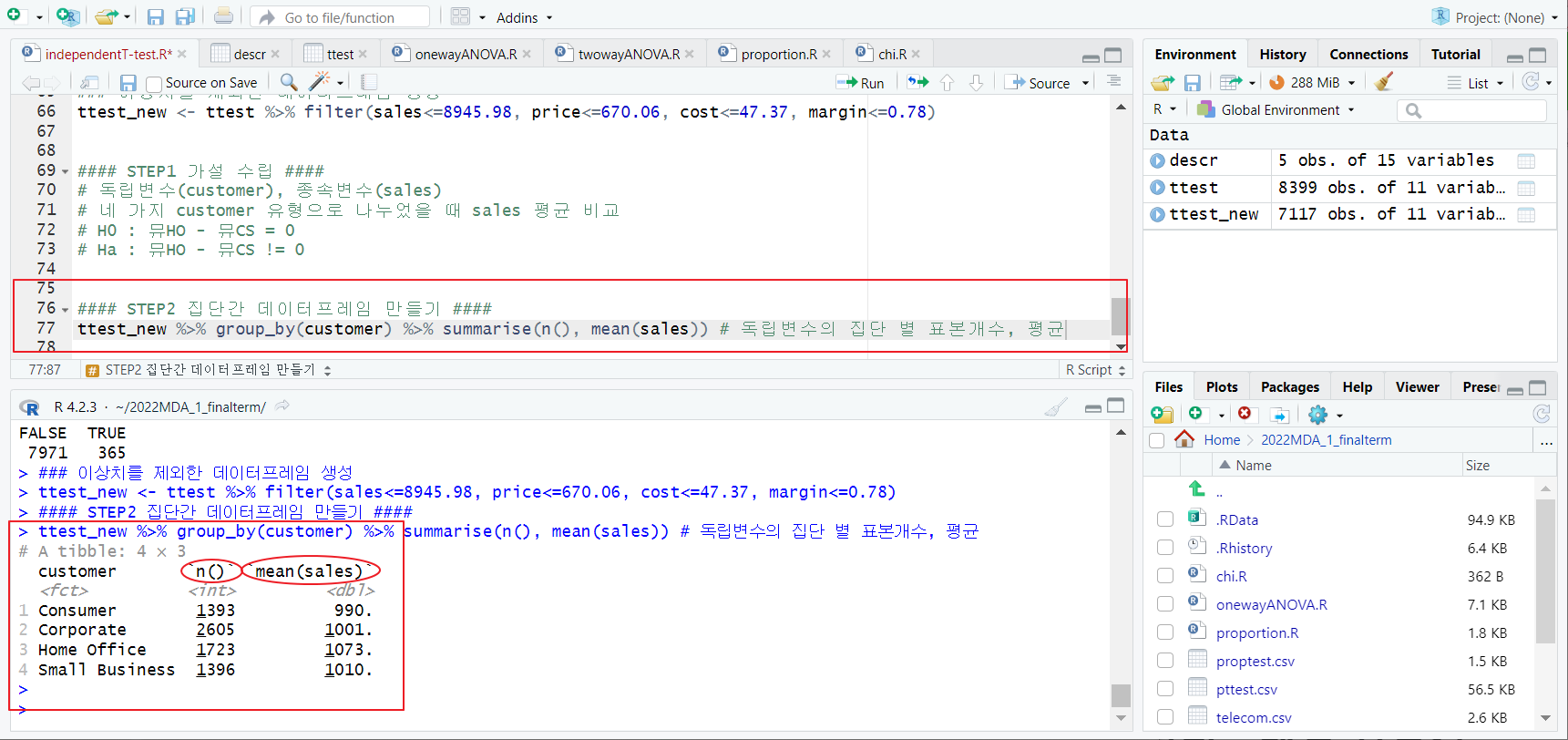
STEP2 집단 간 데이터프레임 만들기
-
group_by, summarise 함수; 독립변수의 집단 별 표본개수, 평균
- 표본을 대상으로 뮤CS = 990, 뮤HO = 1073 일 때, 모집단에서도 유의미한 차이인가?
- 표본을 대상으로 뮤CS = 990, 뮤HO = 1073 일 때, 모집단에서도 유의미한 차이인가?
-
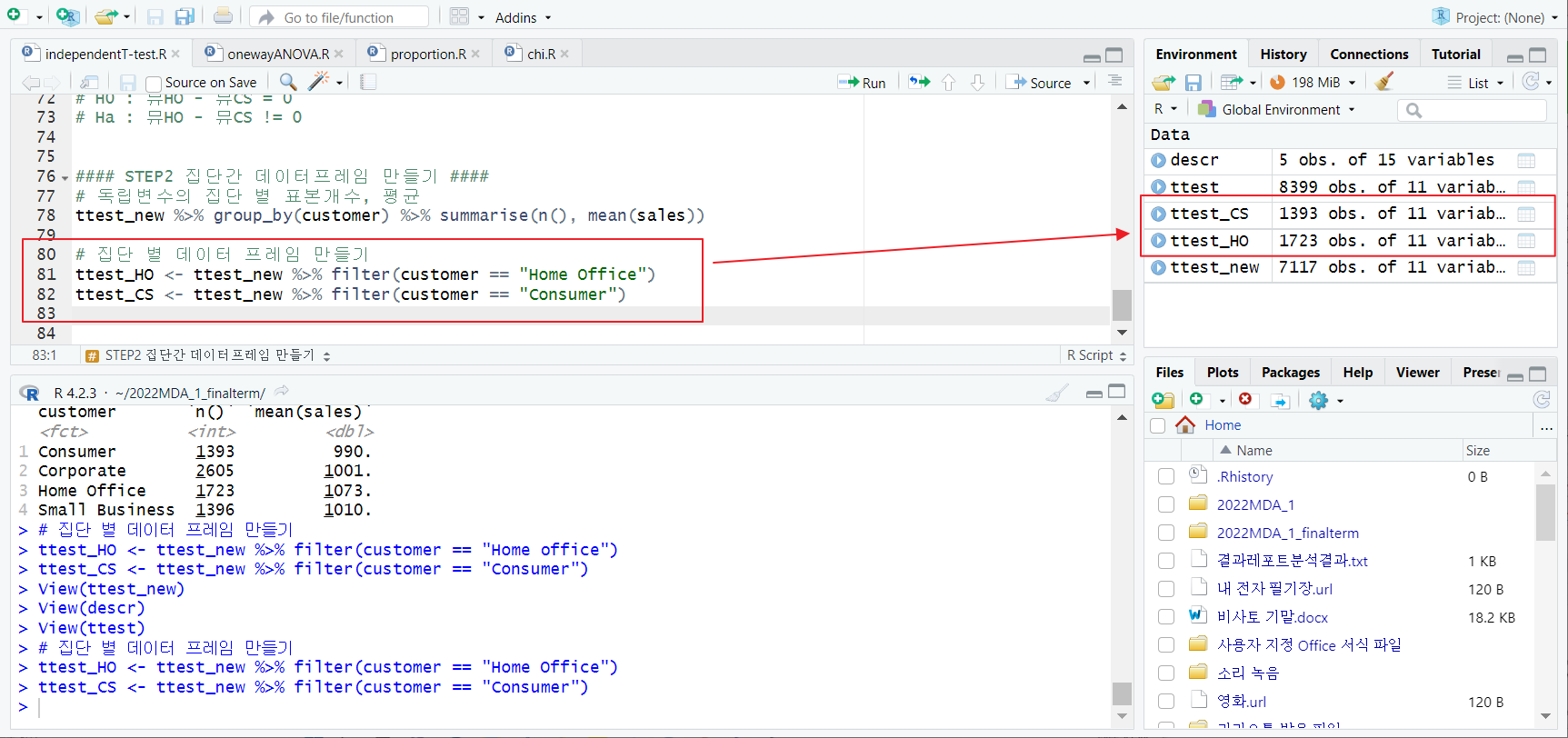
filter 함수; 집단 별 새로운 데이터프레임 생성
STEP3 정규성 조건 검토
- p-value가 유의하지 않아야(p-value > a) 정규성 조건 만족
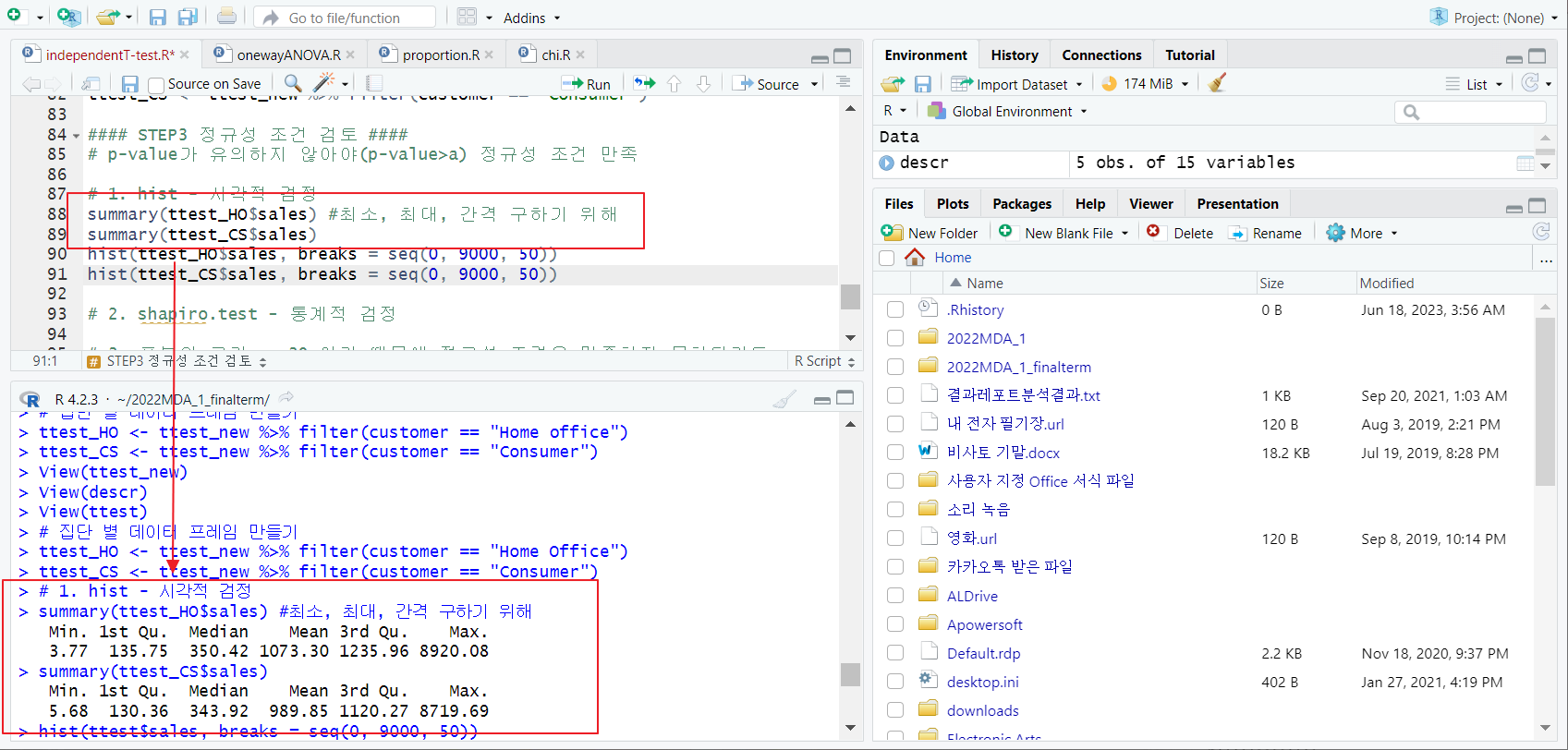
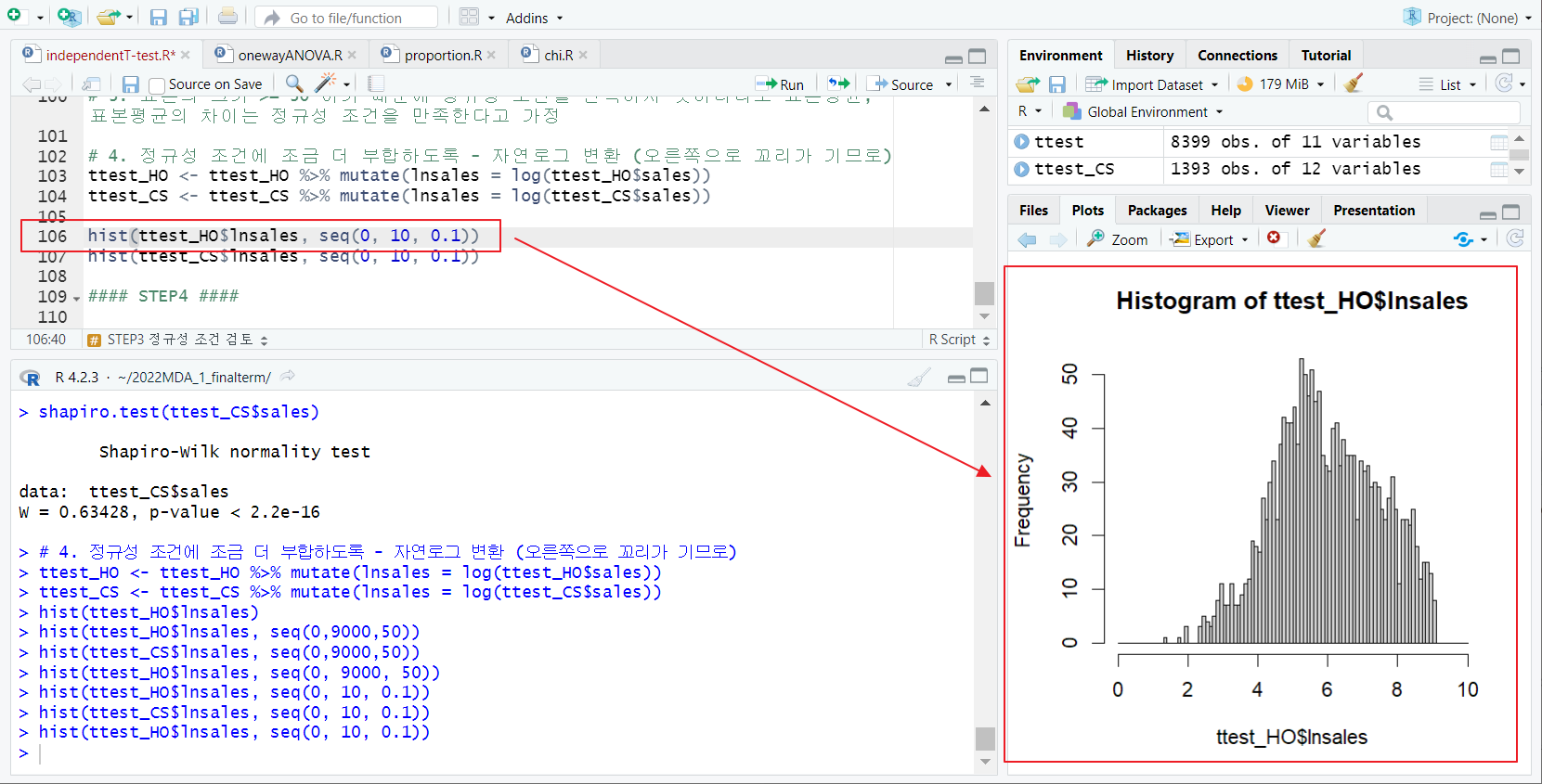
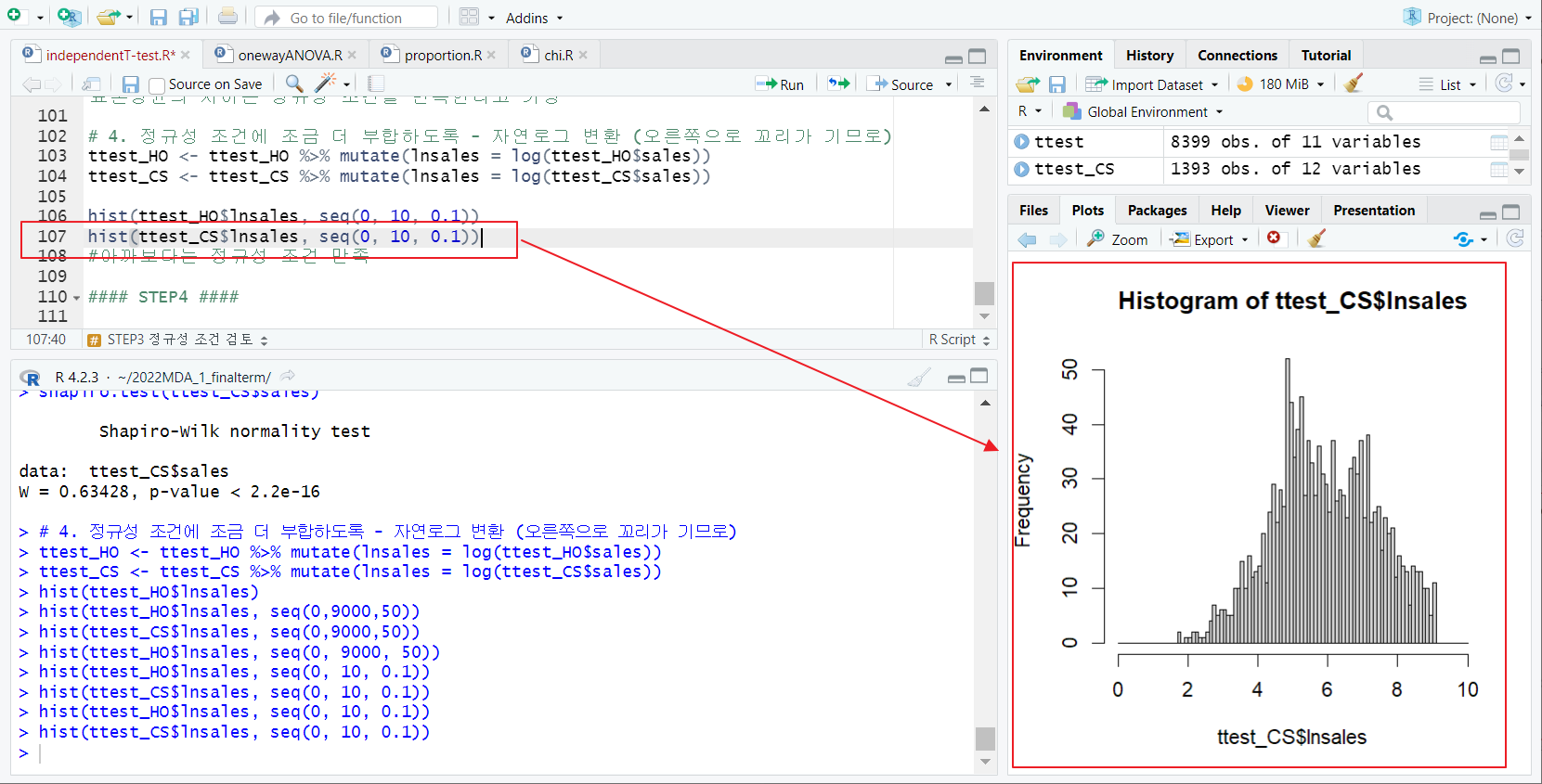
[1] hist - 시각적 검정
- summary 함수; 최소, 최대, 간격 구하기 위해
- hist 함수; 정규분포 시각적 확인
- 왼쪽으로 치우쳐 있음, 정규분포 x
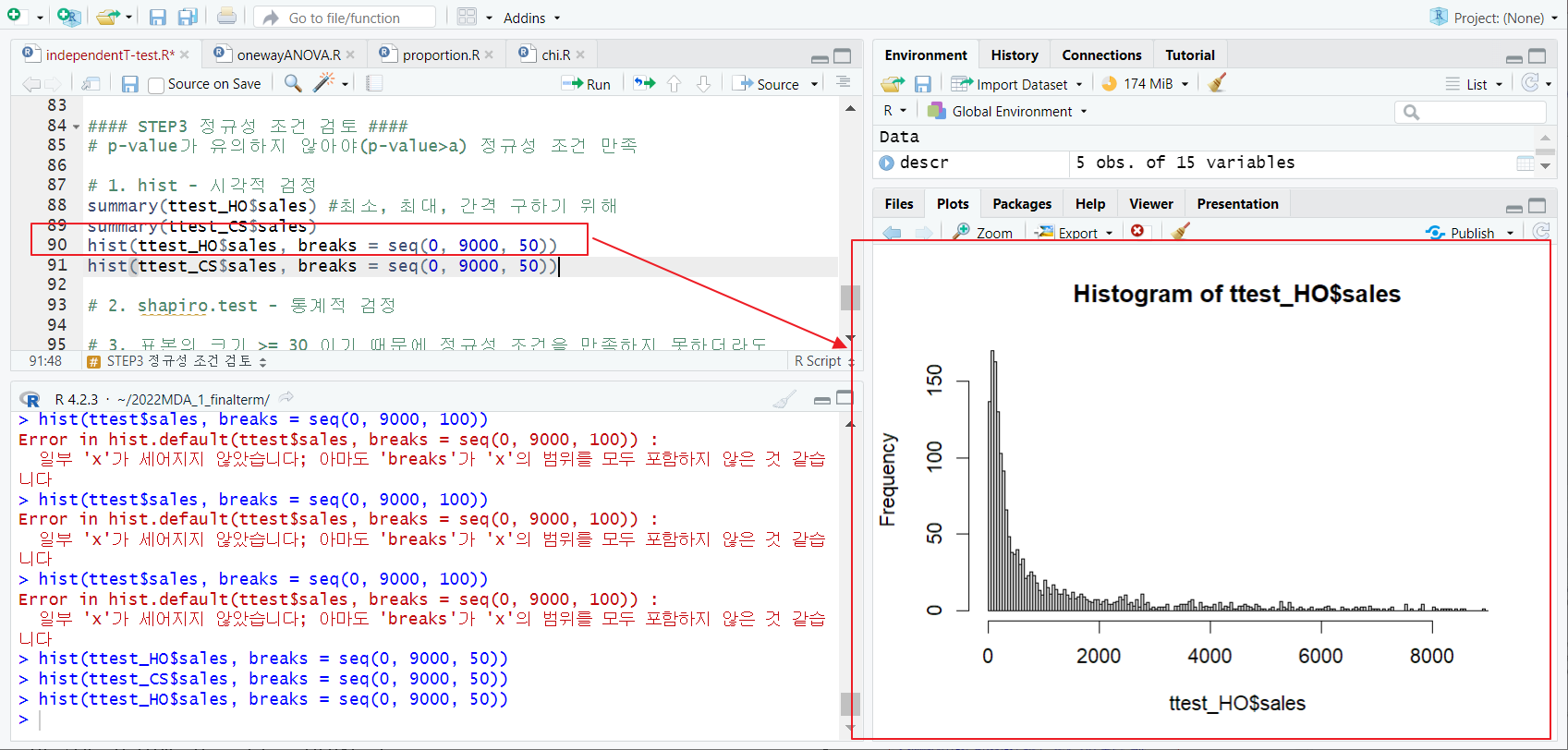
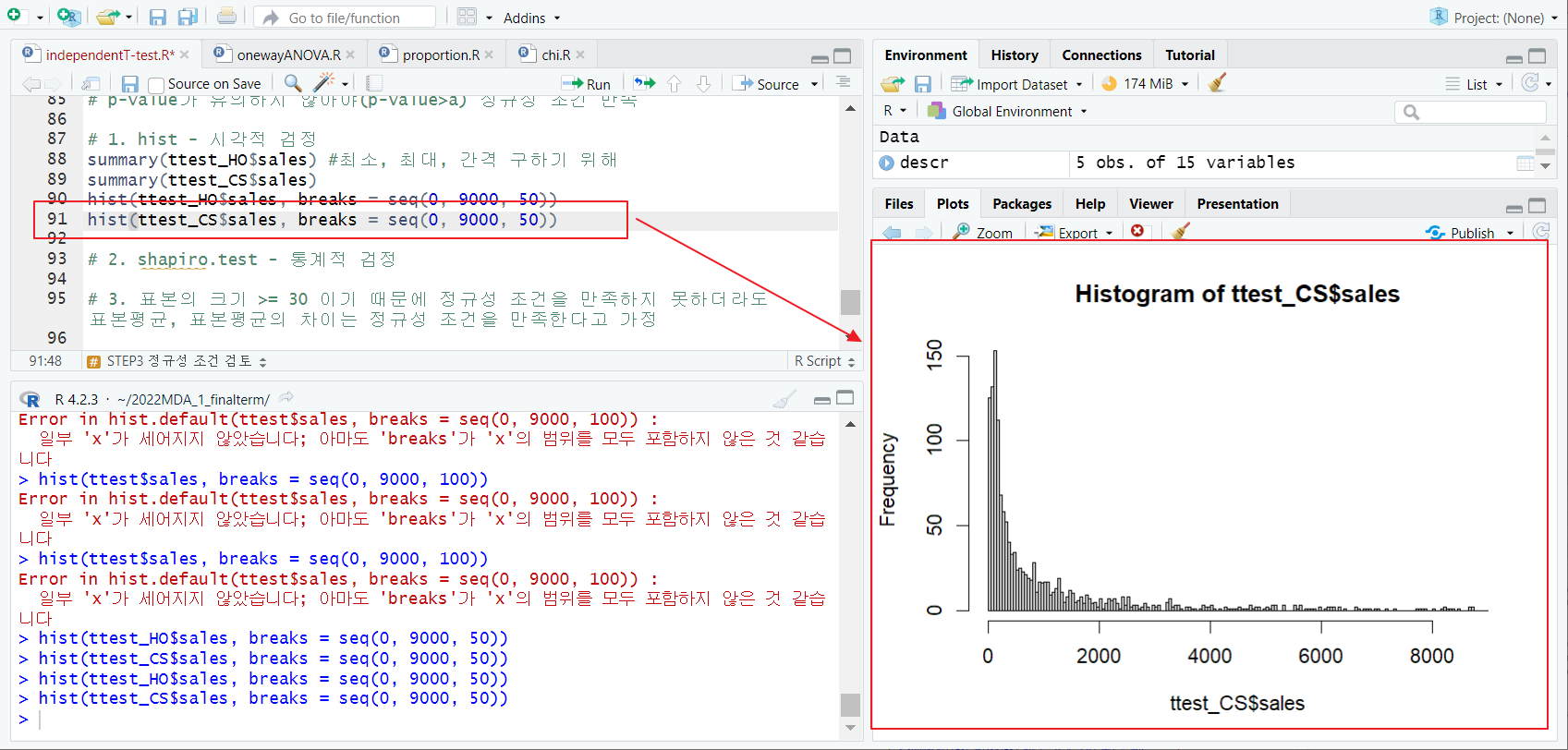
- 왼쪽으로 치우쳐 있음, 정규분포 x
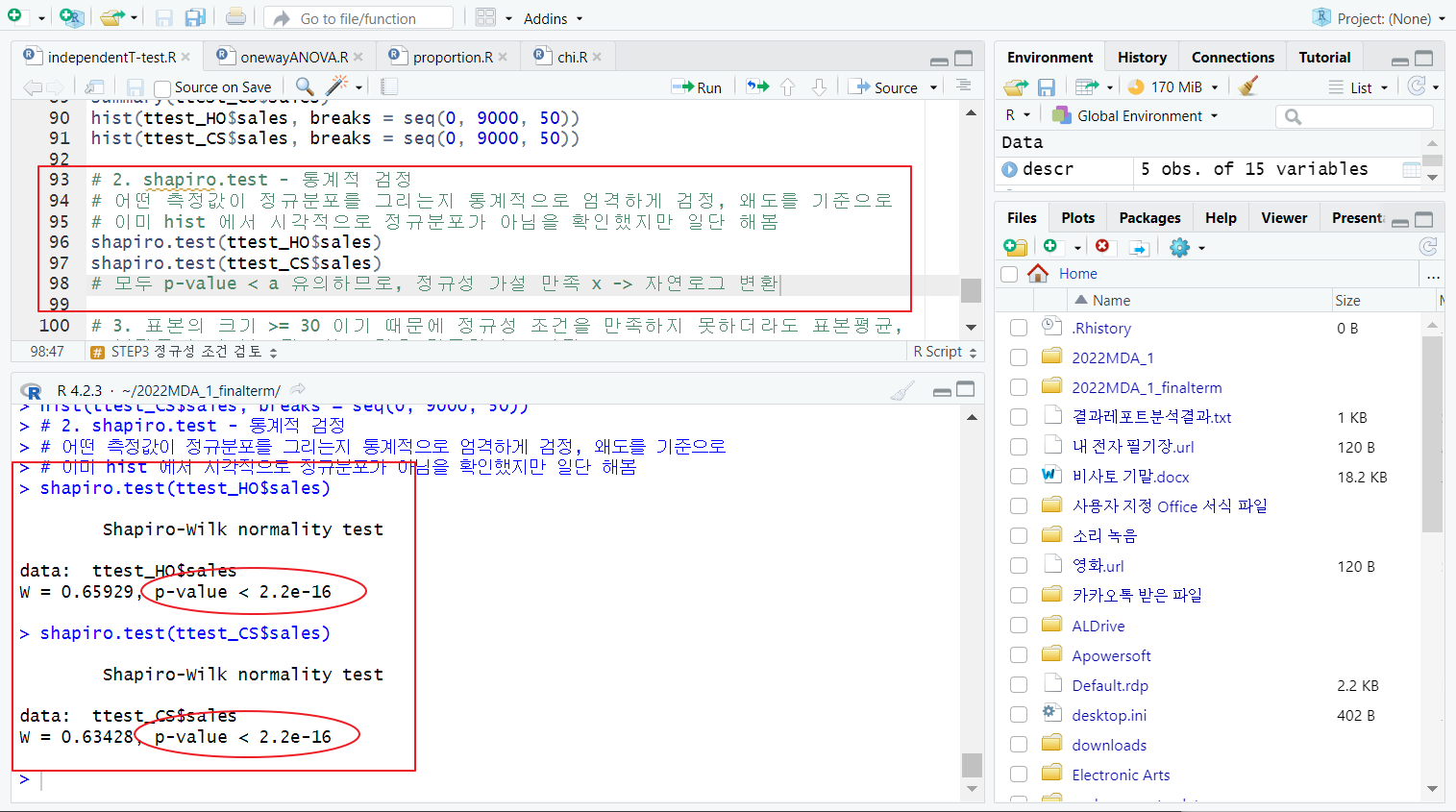
[2] shapiro.test - 통계적 검정
- shapiro.test 함수(내장 함수); 어떤 측정값이 정규분포를 그리는지 통계적으로 엄격하게 검정, 왜도를 기준으로
- 이미 hist 에서 시각적으로 정규분포가 아님을 확인했지만 일단 해봄
- 이미 hist 에서 시각적으로 정규분포가 아님을 확인했지만 일단 해봄
- 두 집단의 p-vaule 결과 모두 유의하므로(p-value < a), 정규성 가설 만족 x
[3] 표본의 크기 >= 30
- 이면 정규성 조건을 만족하지 못하더라도 중심극한정리(CLT) 표본평균, 표본평균의 차이는 정규성 조건을 만족한다고 가정
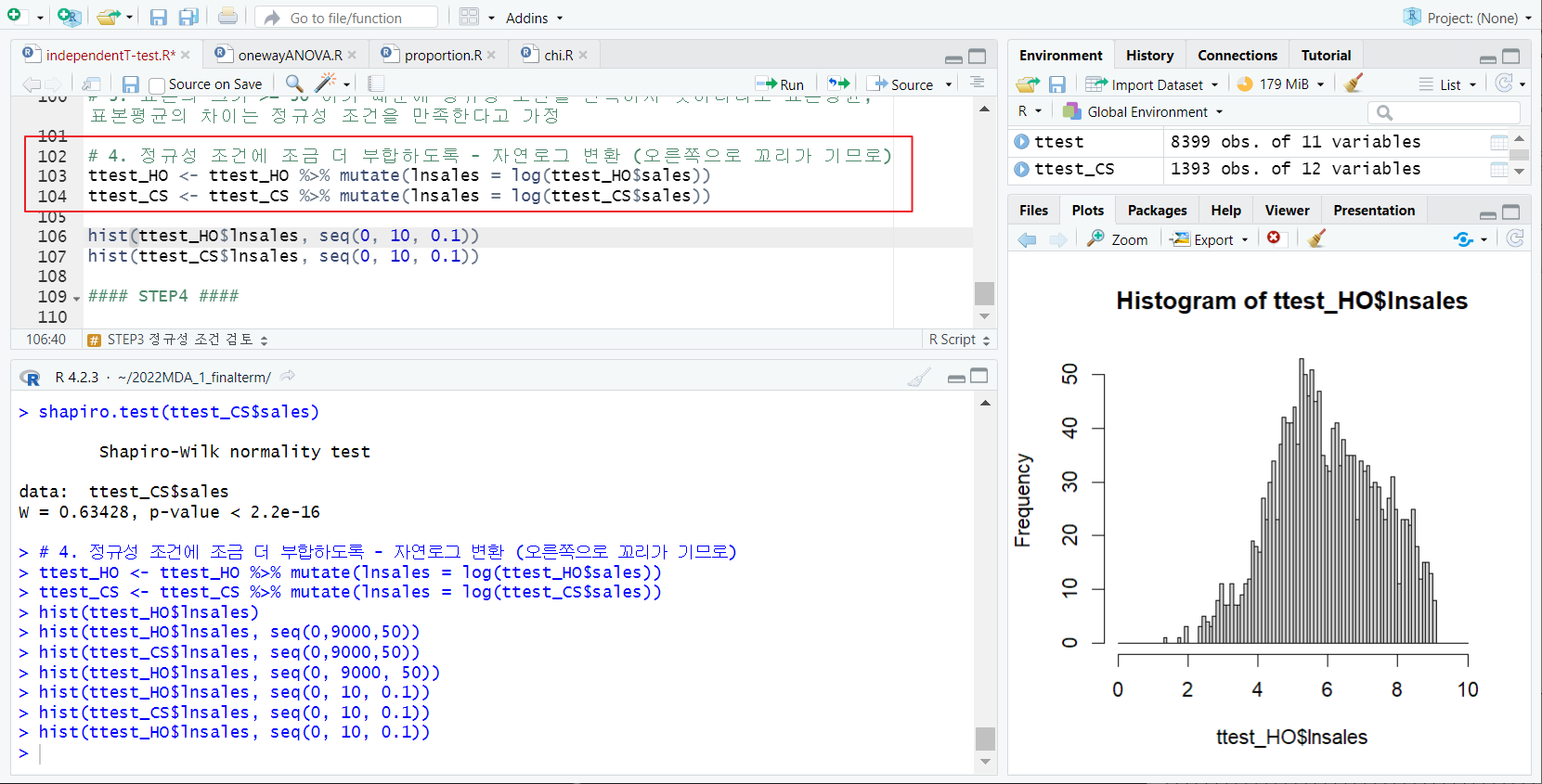
4. [4] 자연로그 변환 (오른쪽으로 꼬리가 기므로)
- 정규성 조건에 조금 더 부합하도록
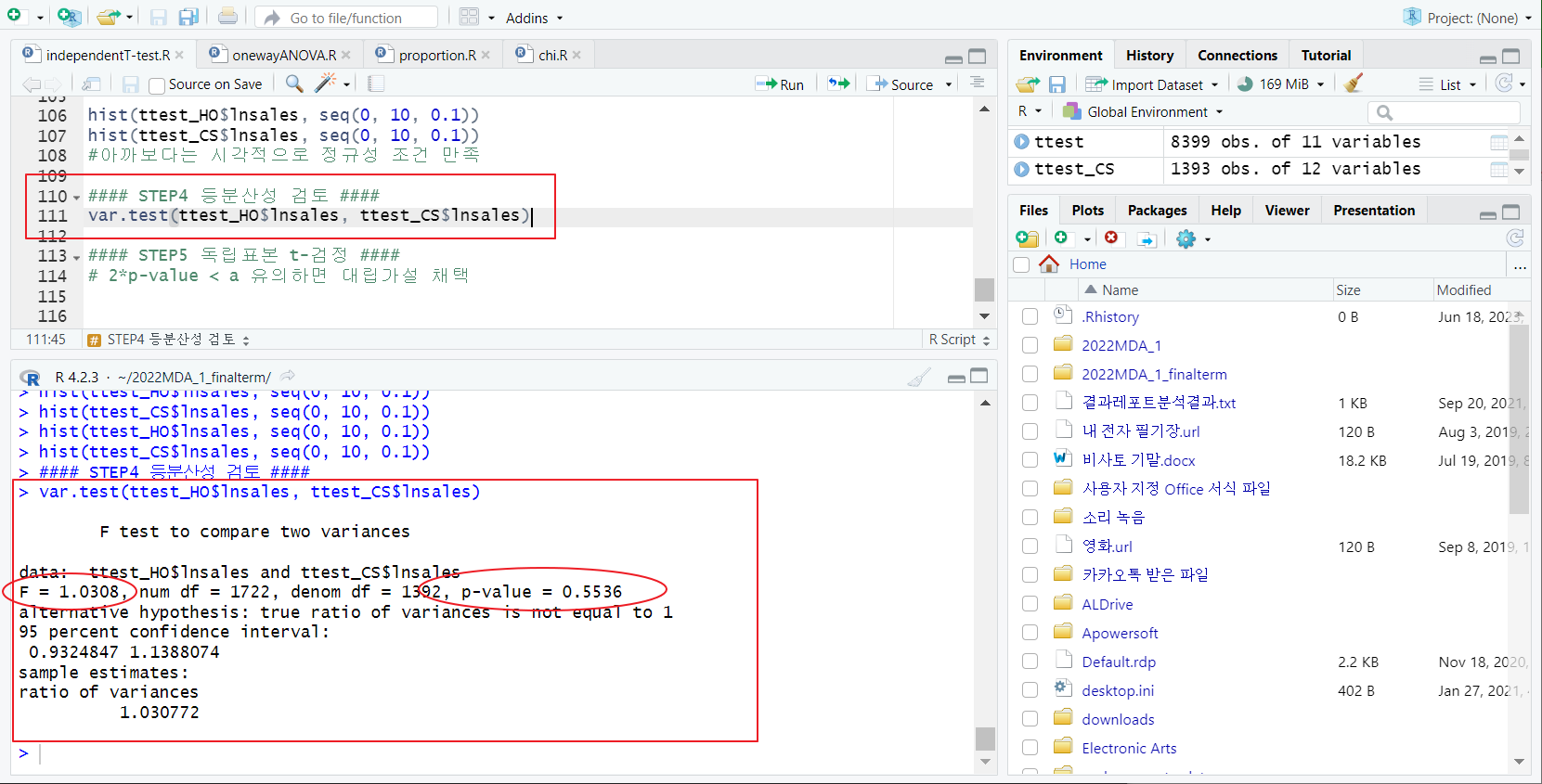
STEP4 등분산성 검토
- p-value가 유의하지 않아야 등분산성 조건 만족
- p-value > a : 등분산 t-검정
- p-value <= a : 이분산 t-검정
- var.test 함수(내장 함수); 등분산성 검토
- F-통계량 1에 매우 가깝
- (p-value > a) -> 등분산 t-검정
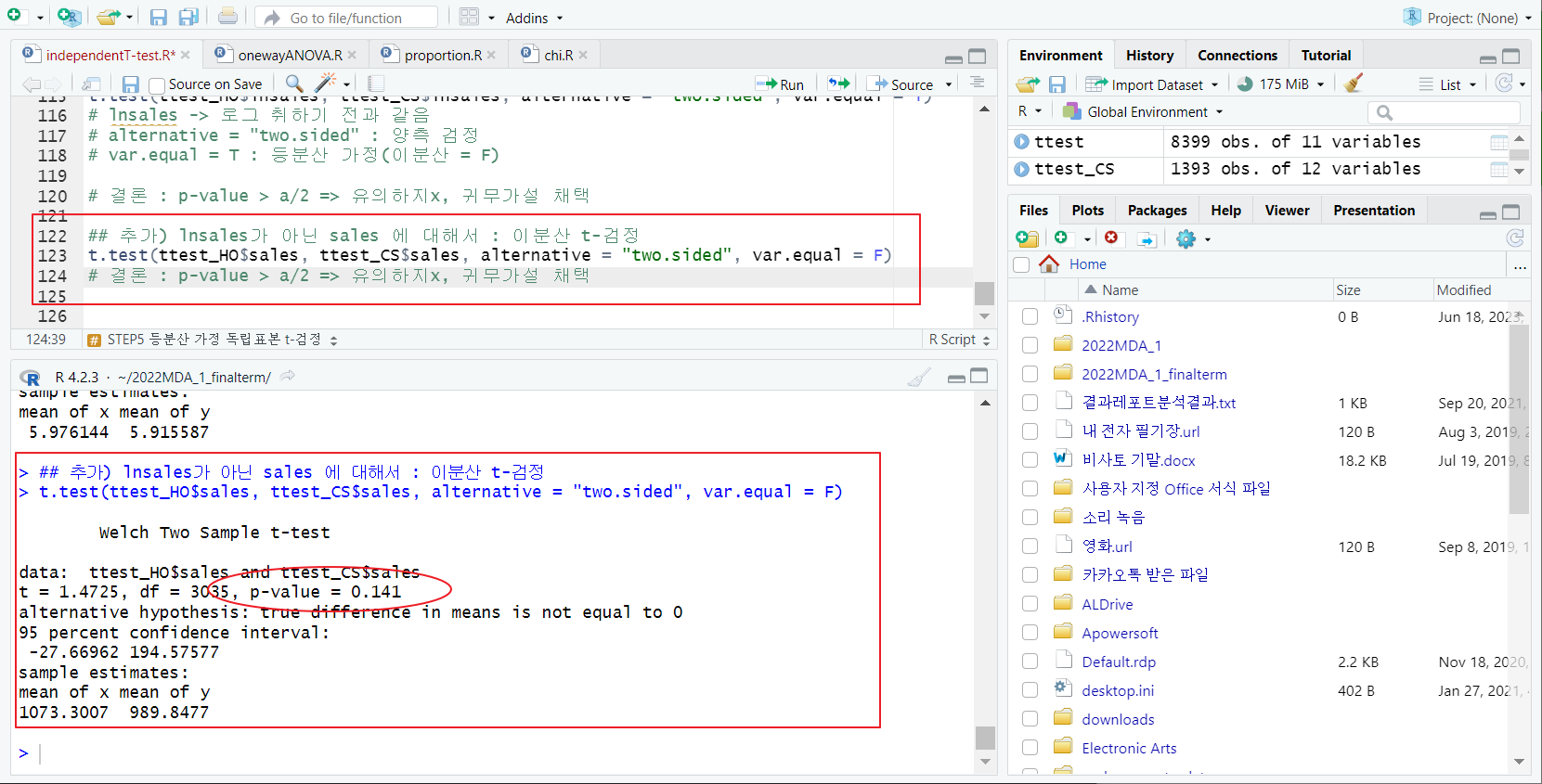
STEP5 독립표본 t-검정
- t.test 함수;
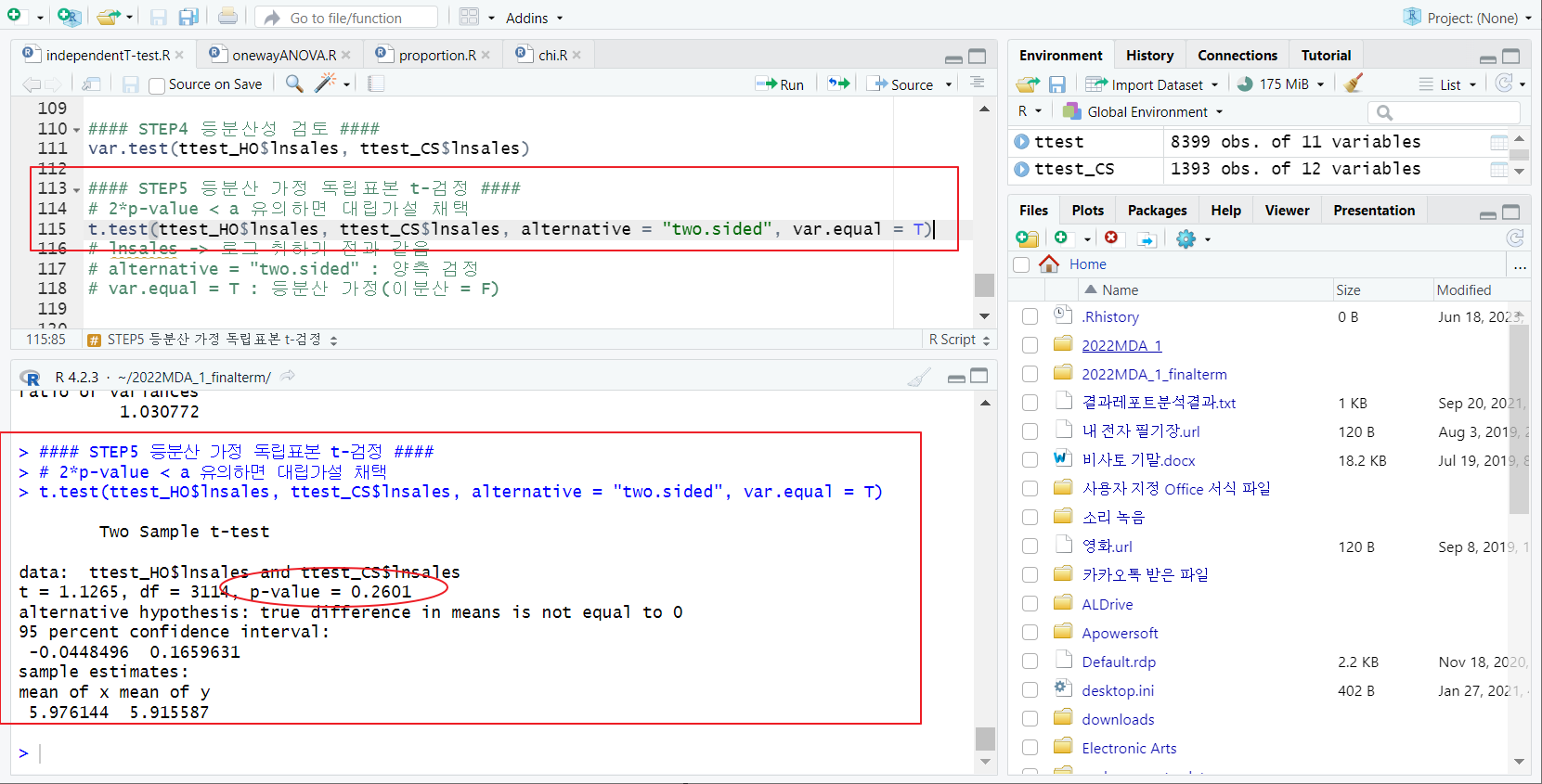
--> 결론 : p-value > a/2 => 유의하지x, 귀무가설 채택
추가)
- lnsales가 아닌 sales 에 대해서 : 이분산 t-검정

( •̀ ω •́ )✧